
Dans cet article, je vais parler de ma solution à la partie texte de la tâche
SNA Hackathon 2019 . Certaines des idées proposées seront utiles aux participants de la partie à temps plein du hackathon, qui se tiendra au bureau de Moscou du groupe Mail.ru du 30 mars au 1er avril. En outre, cette histoire peut intéresser les lecteurs qui résolvent les problèmes pratiques de l'apprentissage automatique. Comme je ne peux pas réclamer de prix (je travaille à Odnoklassniki), j'ai essayé de proposer la solution la plus simple, mais en même temps efficace et intéressante.
En lisant sur de nouveaux modèles d'apprentissage automatique, je veux comprendre comment l'auteur a raisonné en travaillant sur une tâche. Par conséquent, dans cet article, je vais essayer de justifier en détail tous les composants de ma solution. Dans la première partie, je parlerai de l'énoncé du problème et de ses limites. Dans le second - sur l'évolution du modèle. La troisième partie est consacrée aux résultats et à l'analyse du modèle. Enfin, dans les commentaires, je vais essayer de répondre à toutes les questions qui se sont posées. Les lecteurs impatients peuvent immédiatement regarder l'
architecture finale .
Défi
Les organisateurs du Hackathon ont suggéré que nous résolvions le problème de la formation d'une bande intelligente. Pour chaque utilisateur, il est nécessaire de trier l'ensemble des publications de manière à ce que le nombre maximal de publications auxquelles l'utilisateur définit la «classe» soit en haut de la liste. Pour configurer l'algorithme de classement, il était censé utiliser les données historiques du formulaire (utilisateur, poste, feedback). Le tableau donne une brève description des données de la partie texte et la notation que j'utiliserai dans cet article.
Source
| Désignation
| Tapez
| La description
|
|---|
l'utilisateur
| user_id
| catégorique
| identifiant utilisateur
|
poster
| post_id
| catégorique
| Identifiant du message
|
poster
| texte
| liste catégorique
| liste de mots normalisés
|
poster
| caractéristiques
| catégorique
| groupe de caractéristiques du poste (auteur, langue, etc.)
|
rétroaction
| rétroaction
| liste binaire
| diverses actions que l'utilisateur pourrait effectuer avec la publication (affichage, classe, commentaire, etc.)
|
Avant de commencer à construire le modèle, j'ai introduit plusieurs restrictions sur la future solution. Cela était nécessaire afin de satisfaire les exigences de simplicité et de praticité, mes intérêts et de réduire le nombre d'options possibles. Voici les plus importantes de ces limitations.
Prédiction de la probabilité de "classe" . J'ai immédiatement décidé de résoudre ce problème en tant que problème de classification. On pourrait appliquer les méthodes utilisées dans le classement, par exemple, pour prédire l'ordre par paires de messages. Mais j'ai opté pour une formulation plus simple, dans laquelle les messages sont triés en fonction de la probabilité prévue d'obtenir une "classe". Il convient de noter que l'approche décrite ci-dessous peut être développée pour formuler le classement.
Modèle monolithique . Malgré le fait que les ensembles modèles ont tendance à gagner des compétitions, le maintien d'un ensemble sur un système de combat est plus difficile qu'un modèle unique. De plus, je voulais avoir au moins quelques capacités d'interprétation non-boîte noire.
Graphique de calcul différenciable . Premièrement, les modèles de cette classe (réseaux de neurones) déterminent l'état de l'art dans de nombreuses tâches, y compris celles liées à l'
analyse des données textuelles . Deuxièmement, les frameworks modernes, dans mon cas
Apache MXNet , vous permettent de mettre en œuvre des architectures très diverses. Par conséquent, vous pouvez expérimenter différents modèles en modifiant seulement quelques lignes de code.
Travail minimum avec panneaux . Je voulais que le modèle soit facilement étendu avec de nouvelles données. Cela peut être nécessaire dans la partie à temps plein, où il y aura peu de temps pour préparer les panneaux. Par conséquent, j'ai choisi l'approche la plus simple pour identifier les attributs:
- les données binaires sont représentées par une étiquette avec une valeur de 1 ou 0;
- les données numériques restent telles quelles ou sont discrétisées en catégories;
- les données catégorielles sont présentées par plongements.
Après avoir décidé de la stratégie générale, j'ai commencé à essayer différents modèles.
Evolution du modèle
Le point de départ était l'approche de factorisation matricielle, souvent utilisée dans les tâches de recommandation:
pi,j= sigma(ui cdotvj)
Perte(yi,j,pi,j) rightarrowminu,v
Dans le langage des graphiques de calcul, cela signifie que l'estimation de la probabilité que l'utilisateur
i mette une «classe» sur le post
j est la sigmoïde du produit scalaire d'incorporation de l'identifiant utilisateur et de l'identifiant post. La même chose peut être exprimée par un diagramme:

Un tel modèle n'est pas très intéressant: il n'utilise pas toutes les fonctionnalités, n'est pas trop utile pour les identifiants basse fréquence, et souffre du problème d'un démarrage à froid. Mais, après avoir formulé la tâche sous la forme d'un graphe de calcul, nous avons «délié nos mains» et pouvons désormais résoudre les problèmes par étapes. Tout d'abord, pour les valeurs de basse fréquence, nous allons créer la seule incorporation
Out-Of-Vocabulary . Ensuite, débarrassez-vous de la nécessité d'avoir des plongements de la même dimension. Pour ce faire, nous remplaçons le produit scalaire par un perceptron peu profond, qui reçoit des caractéristiques concaténées en entrée. Le résultat est présenté dans le diagramme:

Une fois que nous nous sommes débarrassés d'une dimension fixe, rien ne nous empêche de commencer à ajouter de nouveaux attributs. Représentant le poste avec toutes sortes de caractéristiques (langue, auteur, texte, ...), nous allons résoudre le problème de démarrage à froid des messages. Le modèle apprendra, par exemple, qu'un utilisateur avec
user_id = 42 met des «classes» sur des messages en russe contenant le mot «tapis». À l'avenir, nous pourrons recommander à cet utilisateur tous les messages en russe sur les tapis, même s'ils n'apparaissent pas dans les données de formation. Pour l'intégration de texte, pour l'instant, nous allons simplement faire la moyenne des incorporations des mots qui y sont inclus. En conséquence, le modèle ressemble à ceci:
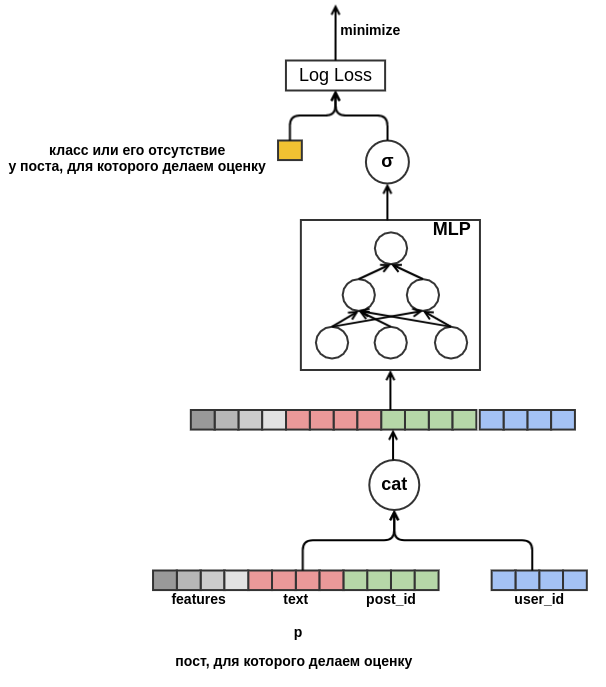
Enfin, je voudrais aborder le démarrage à froid des utilisateurs. Il serait possible de construire des fonctionnalités à partir de données historiques sur les vues utilisateur des publications. Cette approche ne satisfait pas la stratégie choisie: nous avons décidé de minimiser la création manuelle d'attributs. Par conséquent, j'ai fourni au modèle l'occasion d'apprendre indépendamment la présentation de l'utilisateur à partir de la séquence de messages consultés avant ce message pour lequel la probabilité de la «classe» est évaluée. Contrairement au message évalué, tous les commentaires sont connus pour chaque message de la séquence. Cela signifie que le modèle aura accès à des informations indiquant si l'utilisateur a défini les «publications» sur les publications précédentes ou, au contraire, les a supprimées du flux.

Il reste à décider comment combiner des séquences de poteaux de différentes longueurs en une représentation d'une largeur fixe. En tant que telle combinaison, j'ai utilisé la somme pondérée des représentations de chacun des postes. Sur le graphique, le poids du post
j est noté
α_j . Les poids ont été calculés à l'aide du mécanisme d'attention requête-valeur-clé, similaire à celui utilisé dans le
transformateur ou
NMT . Ainsi, la présentation apprise de l'utilisateur est également configurée pour le poste pour lequel l'évaluation est effectuée. Voici une partie du graphique responsable du calcul de
α_j :
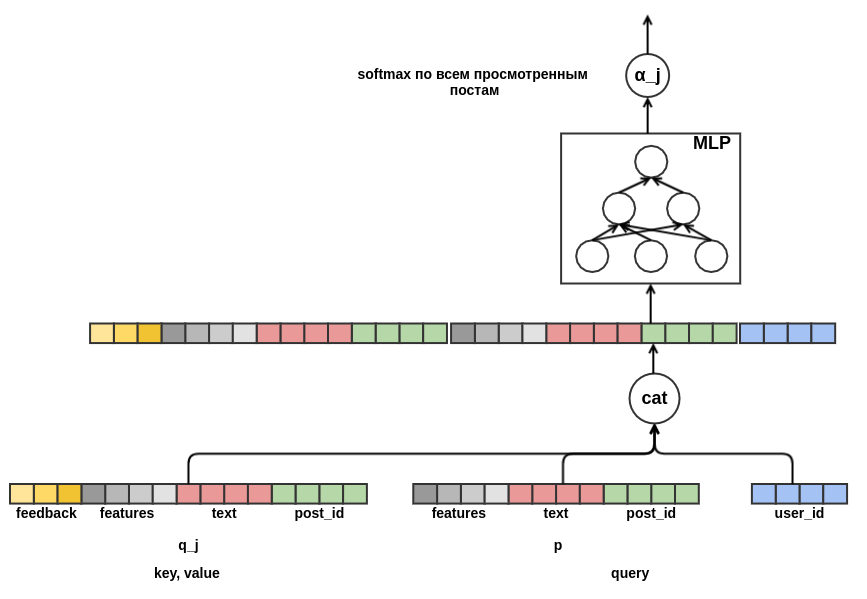
Après avoir
ressenti un chant de réjouissances, je suis devenu convaincu de l'efficacité de l'approche attentionnelle, il a été décidé d'utiliser l'attention dans la présentation des textes. Dans un souci d'économie de temps et de fer, j'ai décidé de ne pas utiliser l'auto-attention comme dans le même transformateur, mais de former directement les mots poids dans le texte, comme ceci:
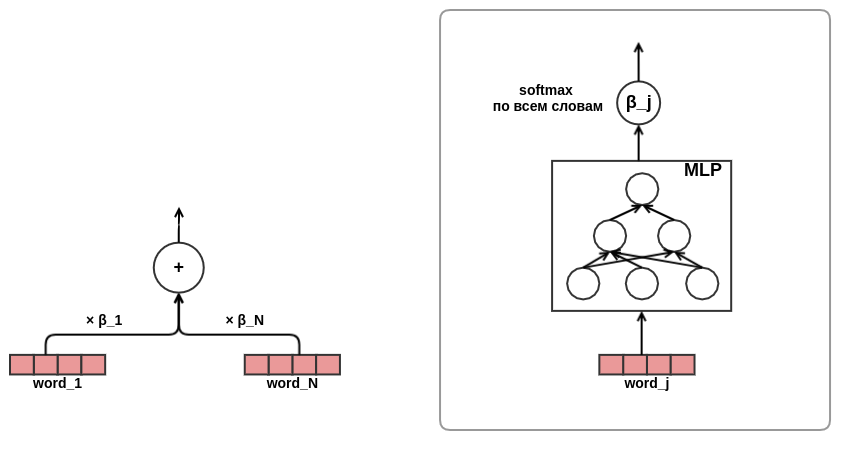
Sur ce point, le développement de l'architecture du modèle a été achevé. En conséquence, je suis passé de la factorisation matricielle classique à un modèle de séquence plutôt complexe.
Résultats et analyse
J'ai développé et débogué ma solution sur un septième des données sur un ordinateur portable avec 16 Go de mémoire et une carte graphique GeForce 930MX. Des expériences de données complètes ont été exécutées sur un serveur dédié avec 256 Go de mémoire et une carte Tesla T4. Pour l'optimisation, l'algorithme Adam avec les paramètres par défaut de MXNet a été utilisé. Le tableau montre les résultats pour un modèle dépouillé - la longueur de la séquence de messages était limitée à dix. Dans le concours soumis, j'ai utilisé des séquences d'une longueur de cinquante.
Modèle
| Perte de journal
| Amélioration de la ligne précédente
| Temps de formation
|
|---|
Aléatoire
| 0,4374 ± 0,0009
| | |
Perceptron
| 0,4330 ± 0,0010
| 0,0043 ± 0,0002
| 7 min
|
Perceptron avec signes
| 0,4119 ± 0,0008
| 0,0212 ± 0,0003
| 44 min
|
Perceptron avec une séquence de messages
| 0,3873 ± 0,0008
| 0,0247 ± 0,0003
| 4 heures 16 minutes
|
Perceptron avec une séquence de messages et d'attention dans les textes
| 0,3874 ± 0,0008
| 0,0001 ± 0,0001
| 4 heures 43 minutes
|
La dernière ligne s'est avérée pour moi la plus inattendue: utiliser l'attention dans la présentation des textes ne donne pas une amélioration visible du résultat. Je m'attendais à ce que le réseau d'attention apprenne le poids des mots dans les textes, quelque chose comme
idf . Peut-être que cela ne s'est pas produit, car les organisateurs ont retiré les mots vides à l'avance et des mots de même importance sont restés dans les listes préparées. Par conséquent, la pesée «intelligente» n'a pas donné d'avantage tangible par rapport à la moyenne simple. Une autre raison possible est que le réseau d'attention pour les mots était assez petit: il ne contenait qu'une seule couche cachée étroite. Peut-être manquait-elle de capacité de représentation pour apprendre quelque chose d'utile.
Le mécanisme d'attention requête-clé-valeur vous permet de regarder à l'intérieur du modèle et de savoir à quoi il «fait attention» lors de la prise de décision. Pour illustrer cela, j'ai
sélectionné quelques exemples:
, http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.16] 2016 2016 GZ8btjgY_Q0 https: - [0.16] . Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ - : - [0.09] - 5 - 5 O3qAop0A5Qs https://ww - [0.09] ... , - [0.22] Microsoft Windows — http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ - [0.20] , 6 . , ? http://ollston.ru/2018/02/08/buddisty-g
La première ligne affiche le texte du message qui doit être évalué, puis les messages précédemment consultés et le score d'attention correspondant. Avec soulagement, on remarque que le modèle a appris à ignorer le rembourrage. Le modèle considérait les publications comme les plus importantes sur les types d'âmes et sur Windows. Il faut garder à l'esprit que l'attention peut être soit positive (l'utilisateur répondra à un message sur une aura de la même manière qu'un message sur les types d'âmes) soit négative (nous évaluons un message sur une aura - par conséquent, la réaction ne sera pas la même que la réaction au message sur technologie). L'exemple suivant est l'attention «dans toute sa splendeur»:
- [0.20] 2018 (), , . - [0.08] ... !!! - [0.04] ))) - [0.18] ! , . 10 - [0.18] 2- , 5 , , 2 , . . - [0.07] ! - () - [0.03] "". . - [0.13] , - [0.05] , ... - [0.05] ...
Ici, le modèle a clairement vu le thème des vacances d'été. Même les enfants et les chatons ont disparu. L'exemple suivant montre que l'interprétation de l'attention n'est pas toujours possible. Parfois, même rien du tout n'est clair:
! - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.15] , ! !!! - [0.16] ! http://gifok.ru/dobryj-vecher/ - [0.20] http://gifq.ru/aforizmy/ - [0.25] . . - [0.15] , . : 800 250-300
Après avoir examiné un certain nombre de ces listes, j'ai conclu que le modèle était capable d'apprendre ce que j'attendais. La prochaine chose que j'ai faite a été d'examiner l'intégration des mots. Dans notre problème, nous ne pouvons pas nous attendre à ce que les incorporations se révèlent aussi belles que lors de l'apprentissage d'un
modèle de langage : nous essayons de prédire une variable plutôt bruyante, en outre, nous n'avons pas une petite fenêtre de contexte - les incorporations de tous les mots sont simplement moyennées sans tenir compte de leur ordre dans le texte. Exemples de jetons et de leurs voisins les plus proches dans l'espace d'intégration:
- : , , , , - : , , , , - : , , , , - : , , , , - : , , , ,
Une partie de cette liste est facile à expliquer (programme - bl), quelque chose est déroutant (iPhone - youki), mais en général, le résultat a de nouveau répondu à mes attentes.
Conclusion
J'aime l'approche de construction de modèles basés sur des graphes différenciables (
beaucoup sont d' accord ). Il vous permet de vous éloigner de la sélection manuelle fastidieuse des fonctionnalités et de vous concentrer sur la formulation correcte du problème et la conception d'architectures intéressantes. Et bien que mon modèle n'ait pris que la deuxième place dans la tâche de texte SNA Hackathon 2019, je suis très satisfait de ce résultat, compte tenu de sa simplicité et de ses options d'extension presque illimitées. Je suis sûr qu'à l'avenir, il y aura de plus en plus de modèles intéressants et applicables dans les systèmes de combat basés sur des idées similaires.