Aujourd'hui, je vais vous dire comment nous avons réussi à résoudre le problème du portage d'
applications de streaming structuré Spark vers
Kubernetes (K8s) et à mettre en œuvre le streaming CI.
Comment tout a commencé?
Le streaming est un élément clé de la plateforme FASTEN RUS BI. Les données en temps réel sont utilisées par l'équipe d'analyse des dates pour créer des rapports opérationnels.
Les applications de streaming sont implémentées à l'aide de
Spark Structured Streaming . Ce cadre fournit une API de transformation de données pratique qui répond à nos besoins en termes de rapidité d'améliorations.
Les flux eux-mêmes ont augmenté sur le cluster
AWS EMR . Ainsi, lors de la génération d'un nouveau flux vers le cluster, un script ssh a été présenté pour soumettre des travaux Spark, après quoi l'application a été lancée. Et au début, tout semblait nous convenir. Mais avec le nombre croissant de flux, le besoin de streaming CI est devenu de plus en plus évident, ce qui augmenterait l'autonomie de la commande d'analyse de date lors du lancement d'applications pour fournir des données sur de nouvelles entités.
Et maintenant, nous allons voir comment nous avons réussi à résoudre ce problème en portant le streaming sur Kubernetes.
Pourquoi Kubernetes?
Kubernetes, en tant que gestionnaire de ressources, répondait le mieux à nos besoins. Il s'agit d'un déploiement sans temps d'arrêt et d'une large gamme d'outils d'implémentation CI sur Kubernetes, y compris Helm. De plus, notre équipe avait une expertise suffisante dans la mise en œuvre des pipelines CI sur les K8. Par conséquent, le choix était évident.
Comment le modèle de gestion des applications Spark basé sur Kubernetes est-il organisé?

Le client exécute spark-submit sur les K8. Un module de pilote d'application est créé. Kubernetes Scheduler lie un pod à un nœud de cluster. Ensuite, le pilote envoie une demande de création de pods pour exécuter les exécutifs, les pods sont créés et attachés aux nœuds du cluster. Après cela, un ensemble standard d'opérations est effectué avec la conversion ultérieure du code d'application en DAG, la décomposition en étapes, la décomposition en tâches et leur exécution sur des exécutables.
Ce modèle fonctionne assez bien lors du démarrage manuel des applications Spark. Cependant, l'approche de lancement de spark-submit en dehors du cluster ne nous convenait pas en termes d'implémentation de CI. Il était nécessaire de trouver une solution qui permettrait à Spark de s'exécuter (effectuer la soumission d'étincelles) directement sur les nœuds du cluster. Et ici, le modèle Kubernetes Operator répondait pleinement à nos exigences.
Opérateur Kubernetes en tant que modèle de gestion du cycle de vie des applications Spark
Kubernetes Operator est un concept de gestion des applications d'état dans Kubernetes, proposé par
CoreOS , qui implique l'automatisation des tâches opérationnelles, telles que le déploiement d'applications, le redémarrage des applications en cas de fichiers, la mise à jour de la configuration des applications. L'un des principaux modèles d'opérateur Kubernetes est CRD (
CustomResourceDefinitions ), qui implique l'ajout de ressources personnalisées au cluster K8s, qui, à son tour, vous permet de travailler avec ces ressources comme avec les objets Kubernetes natifs.
L'opérateur est un démon qui vit dans le pod du cluster et répond à la création / modification de l'état d'une ressource personnalisée.
Considérez ce concept pour la gestion du cycle de vie des applications Spark.
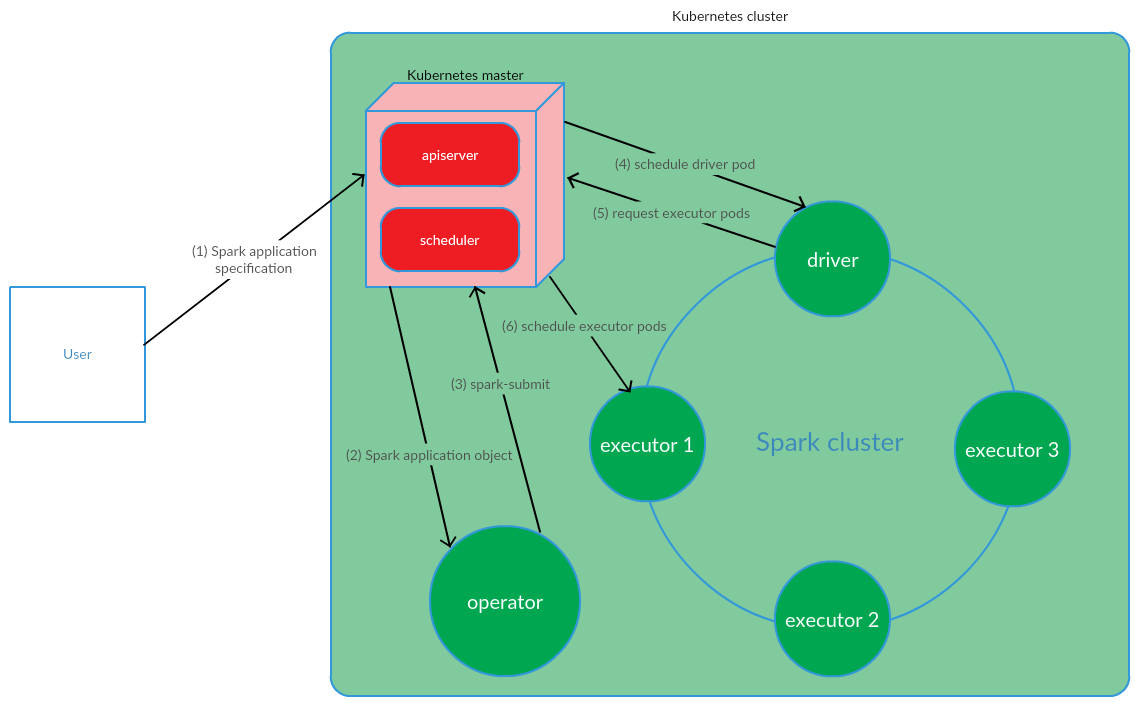
L'utilisateur exécute la commande kubectl apply -f spark-application.yaml, où spark-application.yaml est la spécification de l'application Spark. L'opérateur reçoit l'objet d'application Spark et exécute spark-submit.
Comme nous pouvons le voir, le modèle Kubernetes Operator implique de gérer le cycle de vie d'une application Spark directement dans le cluster Kubernetes, ce qui était un argument sérieux en faveur de ce modèle dans le cadre de la résolution de nos problèmes.
En tant qu'opérateur Kubernetes pour la gestion des applications de streaming, il a été décidé d'utiliser
spark-on-k8s-operator . Cet opérateur offre une API assez pratique, ainsi qu'une flexibilité dans la configuration de la politique de redémarrage pour les applications Spark (ce qui est assez important dans le contexte de la prise en charge des applications de streaming).
Implémentation CI
Pour implémenter le streaming CI,
GitLab CI / CD a été utilisé . Le déploiement des applications Spark sur les K8 a été réalisé à l'aide des outils
Helm .
Le pipeline lui-même comprend 2 étapes:
- test - la vérification de la syntaxe est effectuée, ainsi que le rendu des modèles Helm;
- deploy - déploiement d'applications de streaming vers les environnements de test (dev) et de produit (prod).
Examinons ces étapes plus en détail.
Au stade du test, le modèle de
barre d' application Spark (CRD -
SparkApplication ) est
rendu avec des valeurs spécifiques à l'environnement.
Les sections clés du modèle Helm sont les suivantes:
- étincelle:
- version - Version Apache Spark
- image - Image Docker utilisée
- nodeSelector - contient une liste (clé → valeur) correspondant aux étiquettes des foyers.
- Tolérances - indique la liste des tolérances de l'application Spark.
- mainClass - Classe d'application Spark
- applicationFile - chemin local où se trouve le bocal d'application Spark
- restartPolicy - Stratégie de redémarrage de l'application Spark
- Jamais - l'application Spark terminée ne redémarre pas
- Toujours - l'application Spark terminée redémarre quelle que soit la raison de l'arrêt.
- OnFailure - L'application Spark ne redémarre qu'en cas de fichier
- maxSubmissionRetries - nombre maximal de soumissions d'une application Spark
- pilote / exécuteur:
- cores - le nombre de noyaux alloués au pilote / exécuteur
- instances (utilisées uniquement pour la configuration des cadres) - le nombre de cadres
- memory - la quantité de mémoire allouée au processus pilote / exécuteur
- memoryOverhead - la quantité de mémoire hors segment allouée au pilote / exécuteur
- flux:
- name - nom de l'application de streaming
- arguments - arguments pour l'application de streaming
- sink - le chemin vers les jeux de données Data Lake sur S3
Après avoir rendu le modèle, les applications sont déployées dans l'environnement de test de développement à l'aide de Helm.
Élaboration du pipeline CI.
Ensuite, nous lançons le travail deploy-prod - lancement d'applications en production.
Nous sommes convaincus de la réussite de l'emploi.
Comme nous pouvons le voir ci-dessous, les applications sont en cours d'exécution, les pods sont à l'état RUNNING.

Conclusion
Le portage d'applications de streaming structuré Spark sur K8 et l'implémentation ultérieure de CI nous ont permis d'automatiser le lancement de flux pour la livraison de données à de nouvelles entités. Pour augmenter le flux suivant, il suffit de préparer une demande de fusion avec une description de la configuration de l'application Spark dans le fichier de valeurs yaml et lorsque le travail deploy-prod démarre, la livraison des données à Data Lake (S3) sera lancée. Cette solution garantissait l'autonomie de la commande d'analyse de date lors de l'exécution de tâches liées à l'ajout de nouvelles entités au référentiel. De plus, le portage de la diffusion en continu sur K8 et, en particulier, la gestion des applications Spark à l'aide de l'opérateur spark-on-k8s de Kubernetes Operator a considérablement augmenté la résilience de la diffusion. Mais plus à ce sujet dans le prochain article.