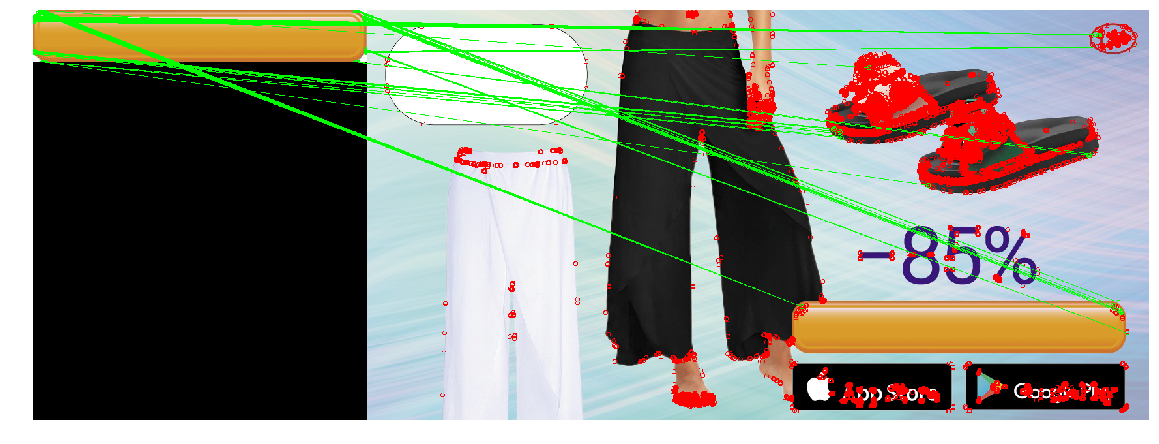
Nous sommes engagés dans l'achat de trafic auprès d'Adwords (une plateforme publicitaire de Google). L'une des tâches régulières dans ce domaine est la création de nouvelles bannières. Les tests montrent que les bannières perdent de leur efficacité au fil du temps, à mesure que les utilisateurs s'habituent à la bannière; Les saisons et les tendances changent. En outre, nous avons pour objectif de capturer différentes niches d'audience et les bannières étroitement ciblées fonctionnent mieux.
Dans le cadre de l'entrée dans de nouveaux pays, la question de la localisation des bannières s'est posée. Pour chaque bannière, vous devez créer des versions dans différentes langues et avec différentes devises. Vous pouvez demander aux concepteurs de le faire, mais ce travail manuel ajoutera une charge supplémentaire à une ressource déjà rare.
Cela ressemble à une tâche facile à automatiser. Pour ce faire, il suffit de créer un programme qui imposera à la bannière vierge le prix localisé pour le "prix" et l'appel à l'action (une phrase comme "acheter maintenant") sur le bouton. Si l'impression de texte dans une image est assez simple, il n'est pas toujours facile de déterminer où vous devez le mettre. Peppercorns ajoute que le bouton est disponible en différentes couleurs et est de forme légèrement différente.
Cet article est dédié à: comment trouver l'objet spécifié dans l'image? Les méthodes populaires seront triées; Domaines d'application, fonctionnalités, avantages et inconvénients. Les méthodes ci-dessus peuvent être utilisées à d'autres fins: développement de programmes pour les caméras de sécurité, automatisation du test de l'interface utilisateur, etc. Les difficultés décrites peuvent être trouvées dans d'autres tâches et les méthodes utilisées peuvent être utilisées à d'autres fins. Par exemple, le détecteur Canny Edge est souvent utilisé pour prétraiter des images, et le nombre de points clés peut être utilisé pour évaluer la «complexité» visuelle d'une image.
J'espère que les solutions décrites reconstitueront votre arsenal d'outils et d'astuces pour résoudre les problèmes.
Le code est en Python 3.6 ( référentiel ); Bibliothèque OpenCV requise. Le lecteur est censé comprendre les bases de l'algèbre linéaire et de la vision par ordinateur.
Nous nous concentrerons sur la recherche du bouton lui-même. Nous nous souviendrons de la recherche d'étiquettes de prix (car la recherche d'un rectangle peut également être résolue de manière plus simple), mais omettons-la, car la solution aura le même aspect.
Correspondance de modèle
La première pensée qui vient à l'esprit est pourquoi ne pas simplement chercher et trouver dans l'image la région qui ressemble le plus à un bouton en termes de différence de couleur de pixel? C'est ce qui rend la correspondance de modèle - une méthode basée sur la recherche d'espace sur l'image qui ressemble le plus au modèle. La «similitude» d'une image est définie par une métrique spécifique. En d'autres termes, le modèle est «superposé» à l'image et la différence entre l'image et le modèle est prise en compte. La position du modèle à laquelle cet écart sera minime et indiquera l'emplacement de l'objet souhaité.
Vous pouvez utiliser différentes options comme métrique, par exemple, la somme des différences au carré entre un modèle et une image (somme des différences au carré, SSD), ou utiliser la corrélation croisée (CCORR). Soit f et g l'image et le motif de dimensions (k, l) et (m, n), respectivement (nous ignorerons les canaux de couleur pour l'instant); i, j - position sur l'image à laquelle nous avons "attaché" le modèle.
S S D i , j = s u m a = 0 .. m , b = 0 .. n ( f i + a , j + b - g a , b ) 2
CCORRi,j= suma=0..m,b=0..n(fi+a,j+b cdotga,b)2
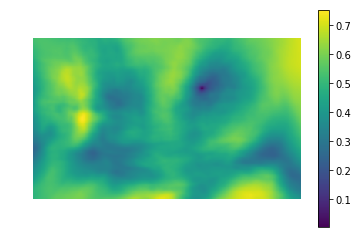
Essayons d'appliquer la différence de carrés pour trouver un chaton

Dans l'image

(photo prise de PETA Caring for Cats).
L'image de gauche est la valeur métrique de la similitude de l'endroit dans l'image avec le modèle (c'est-à-dire les valeurs SSD pour différents i, j). La zone sombre est l'endroit où la différence est minime. Ceci est un pointeur vers l'endroit qui ressemble le plus à un modèle - dans l'image de droite, cet endroit est entouré.

La corrélation croisée est en fait une convolution de deux images. Les convolutions peuvent être mises en œuvre rapidement à l'aide de la transformée de Fourier rapide. Selon le théorème de convolution, après la transformée de Fourier, la convolution se transforme en une simple multiplication élémentaire:
CCORRi,j=f circledastg=IFFT(FFT(f circledastg))=IFFT(FFT(f) cdotFFT(g))
O Where circledast - opérateur de convolution. De cette façon, nous pouvons calculer rapidement la corrélation croisée. Cela donne la complexité globale de O (kllog (kl) + mnlog (mn)) , par rapport à O (klmn) lorsqu'il est implémenté de front. Le carré de la différence peut également être réalisé par convolution, car après l'ouverture des crochets, il se transformera en différence entre la somme des carrés des valeurs de pixels de l'image et la corrélation croisée:
SSDi,j= suma=0..m,b=0..n(fi+a,j+b−ga,b)2=
= suma=0..m,b=0..nf2i+a,j+b−2fi+a,j+bga,b+g2a,b=
= suma=0..m,b=0..nf2i+a,j+b+g2a,b−2CCORi,j
Les détails peuvent être vus dans cette présentation .
Passons à la mise en œuvre. Heureusement, des collègues du département Nizhny Novgorod d'Intel ont pris soin de nous en créant la bibliothèque OpenCV, elle implémente déjà une recherche de modèle en utilisant la méthode matchTemplate (en passant, elle utilise l'implémentation via FFT, bien que cela ne soit pas mentionné dans la documentation), en utilisant différentes mesures de divergence :
- CV_TM_SQDIFF - la somme des carrés de la différence des valeurs des pixels
- CV_TM_SQDIFF_NORMED - la somme du carré des différences de couleur, normalisée à la plage 0..1.
- CV_TM_CCORR - la somme des produits élément par élément du modèle et du segment d'image
- CV_TM_CCORR_NORMED - la somme des éléments fonctionne, normalisée à la plage -1..1.
- CV_TM_CCOEFF - corrélation croisée d'images sans moyenne
- CV_TM_CCOEFF_NORMED - corrélation croisée entre images sans moyenne, normalisée à -1..1 (corrélation de Pearson)
Nous les utiliserons pour trouver un chaton:

On peut voir que seul TM_CCORR n'a pas rempli sa tâche. Ceci est compréhensible: puisqu'il s'agit d'un produit scalaire, la plus grande valeur de cette métrique sera lors de la comparaison d'un modèle avec un rectangle blanc.
Vous pouvez remarquer que ces mesures nécessitent une correspondance de motifs pixel par pixel dans l'image souhaitée. Toute déviation du gamma, de la lumière ou de la taille entraînera l'échec des méthodes. Permettez-moi de vous rappeler que c'est exactement notre cas: les boutons peuvent être de tailles et de couleurs différentes.
Le problème des différentes couleurs et de la lumière peut être résolu en appliquant un filtre de détection de bord. Cette méthode ne laisse que des informations sur l'endroit où l'image a subi des changements de couleur nets. Appliquons Canny Edge Detector (nous allons l'analyser un peu plus loin) aux boutons de différentes couleurs et luminosité. À gauche, les bannières d'origine et à droite, le résultat de l'application du filtre Canny.

Dans notre cas, il existe également un problème de tailles différentes, mais il a déjà été résolu. La transformation log-polaire transforme une image en un espace dans lequel le zoom et la rotation apparaîtront comme un décalage. En utilisant cette transformation, nous pouvons restaurer l'échelle et l'angle. Après cela, en mettant à l'échelle et en faisant pivoter le modèle, vous pouvez trouver la position du modèle dans l'image d'origine. Vous pouvez également utiliser la FFT tout au long de cette procédure, comme décrit dans Une technique basée sur la FFT pour la traduction, la rotation et l'enregistrement d'images invariantes d'échelle . Dans la littérature, le cas est considéré lorsque les modèles horizontal et vertical sont modifiés proportionnellement, tandis que le facteur d'échelle varie dans de petites limites (2,0 ... 0,8). Malheureusement, le redimensionnement d'un bouton peut être volumineux et disproportionné, ce qui peut conduire à un résultat incorrect.
Nous appliquons la construction résultante (filtre Canny, restituant uniquement l'échelle par la transformation log-polaire, obtenant la position en trouvant l'endroit avec l'écart quadratique minimum), pour trouver le bouton sur trois images. Nous utiliserons le gros bouton jaune comme modèle:

En même temps, les boutons sur les bannières seront de différents types, couleurs et tailles:

Dans le cas du redimensionnement du bouton, la méthode n'a pas fonctionné correctement. Cela est dû au fait que la méthode implique de redimensionner les boutons dans le même nombre de fois horizontalement et verticalement. Mais ce n'est pas toujours le cas. Dans l'image de droite, la taille du bouton n'a pas changé verticalement, mais horizontalement a considérablement diminué. Si le redimensionnement est trop important, les distorsions causées par la transformation log-polaire rendent la recherche instable. À cet égard, la méthode n'a pas pu détecter le bouton dans le troisième cas.
Détection de points clés
Vous pouvez essayer une approche différente: au lieu de rechercher le bouton entier, trouvons ses parties typiques, par exemple les coins du bouton ou les éléments de bordure (il y a un trait décoratif le long du contour du bouton). Il semble que trouver des coins et une bordure soit plus facile, car ce sont de petits objets (et donc simples). Ce qui se trouve entre les quatre coins et la bordure sera un bouton. La classe de méthodes de recherche de points clés est appelée «détection de points clés» et les algorithmes de comparaison et de recherche d'images à l'aide de points clés sont appelés «correspondance de points clés». La recherche d'un motif dans une image revient à appliquer un algorithme pour détecter les points clés d'un motif et d'une image, et à comparer les points clés d'un motif et d'une image.
Habituellement, les «points clés» sont automatiquement trouvés en trouvant des pixels dont l'environnement a certaines propriétés. De nombreuses méthodes et critères de recherche ont été inventés. Tous ces algorithmes sont des heuristiques qui trouvent en règle générale certains éléments d'image caractéristiques - des angles ou des changements de couleur nets. Un bon détecteur devrait fonctionner rapidement et être résistant aux transformations d'image (lors du changement d'image, les points clés ne devraient pas cesser d'être / de bouger).
Détecteur de coin Harris
L'un des algorithmes les plus élémentaires est le détecteur de coin Harris . Pour l'image (ici et plus loin, nous considérons que nous fonctionnons avec une «intensité» - une image traduite en niveaux de gris), il essaie de trouver des points au voisinage desquels les différences d'intensité sont supérieures à un certain seuil. L'algorithme ressemble à ceci:
De l'intensité I sont des dérivées le long des axes x et y ( Ix et Iy respectivement). Ils peuvent être trouvés, par exemple, en appliquant le filtre Sobel.
Pour un pixel, considérons le carré Ix carré Iy et travaille Ix et Iy . Certaines sources les étiquettent comme Ixx , Ixy et Ixy - ce qui n'ajoute pas de clarté, car on pourrait penser que ce sont les deuxièmes dérivées de l'intensité (et ce n'est pas le cas).
Pour chaque pixel, nous considérons les sommes dans un certain voisinage (plus de 1 pixel) avec les caractéristiques suivantes:
A= sumx,yw(x,y)IxIx
B= sumx,yw(x,y)IxIy
C= sumx,yw(x,y)IyIy
Comme dans la détection de modèle, cette procédure pour les grandes fenêtres peut être effectuée efficacement en utilisant le théorème de convolution.
Pour chaque pixel, calculez la valeur star heuristique R
R=Det(H)−k(Tr(H))2=(AB−C2)−k(A+B)2
Valeur k sélectionnés empiriquement dans la plage [0,04, 0,06] Si R un pixel a un certain seuil, puis le voisinage w ce pixel contient un angle, et nous le marquons comme un point clé.
La formule précédente peut créer des grappes de points clés côte à côte, auquel cas il vaut la peine de les supprimer. Cela peut être fait en vérifiant pour chaque point s'il a une valeur R maximum parmi les voisins immédiats. Sinon, le point clé est filtré. Cette procédure est appelée suppression non maximale .
star Formule R donc choisi pour une raison. A,B,C - composantes du tenseur structurel - matrice décrivant le comportement du gradient au voisinage:
H = \ begin {pmatrix} A & C \\ C & B \ end {pmatrix}
H = \ begin {pmatrix} A & C \\ C & B \ end {pmatrix}
Cette matrice est similaire à bien des égards à sa matrice de covariance. Par exemple, ce sont toutes les deux des matrices positivement semi-définies, mais la similitude ne se limite pas à cela. Permettez-moi de vous rappeler que la matrice de covariance a une interprétation géométrique. Les vecteurs propres de la matrice de covariance indiquent les directions de la plus grande variance des données source (sur lesquelles la covariance a été calculée), et les valeurs propres indiquent la dispersion le long de l'axe

Image tirée de http://www.visiondummy.com/2014/04/geometric-interpretation-covariance-matrix/
Les valeurs propres du tenseur structurel se comportent également de la même manière: elles décrivent la propagation des gradients. Sur une surface plane, les valeurs propres du tenseur structurel seront faibles (car la propagation des gradients eux-mêmes sera faible). Les valeurs propres du tenseur structurel construit sur une image avec un visage varieront considérablement: un nombre sera grand (et correspondra à son propre vecteur dirigé perpendiculairement au visage), et le second sera petit. Sur le tenseur angulaire, les deux valeurs propres seront grandes. Sur cette base, nous pouvons construire une heuristique ( lambda1, lambda2 Sont les valeurs propres du tenseur structurel).
R= lambda1 lambda2−k( lambda1+ lambda2)2
La valeur de cette heuristique sera grande lorsque les deux valeurs propres sont grandes.
La somme des valeurs propres est la trace de la matrice, qui peut être calculée comme la somme des éléments sur la diagonale (et si vous regardez les formules A et B, il devient clair que c'est aussi la somme des carrés des longueurs des gradients dans la région):
lambda1+ lambda2=Tr(H)=A+B
Le produit des valeurs propres est le déterminant d'une matrice, qui est également facile à écrire dans le cas de 2x2:
lambda1 lambda2=Det(H)=AB−C2
Ainsi, nous pouvons calculer efficacement R , l'exprimant en termes de composants du tenseur structurel.
Rapide
La méthode de Harris est bonne, mais il existe de nombreuses alternatives. Nous ne considérerons pas tout de la même manière que la méthode ci-dessus, nous ne mentionnerons que quelques-uns populaires pour montrer des astuces intéressantes et les comparer en action.

Pixels vérifiés par l'algorithme FAST
Une alternative à la méthode de Harris est FAST . Comme son nom l'indique, FAST est beaucoup plus rapide que la méthode ci-dessus. Cet algorithme essaie de trouver les points qui se trouvent sur les bords et les coins des objets, c'est-à-dire dans les endroits de différence de contraste. Leur emplacement est le suivant: FAST construit un cercle de rayon R autour du pixel candidat et vérifie s'il a un segment continu de pixels de longueur t qui est plus sombre (ou plus clair) du pixel candidat par K unités. Si cette condition est remplie, le pixel est alors considéré comme un «point clé». Pour certains t, nous pouvons implémenter cette heuristique efficacement en ajoutant quelques vérifications préliminaires qui couperont les pixels qui sont garantis comme étant non-coins. Par exemple, lorsque R=3 et t=12 , il suffit de vérifier s'il y a 3 pixels consécutifs parmi les 4 pixels extrêmes qui sont strictement plus foncés / plus clairs que le centre de K (dans l'image - 1, 5, 9, 13). Cette condition vous permet de couper efficacement les candidats qui ne sont certainement pas des points clés.
SIFT
Les deux algorithmes précédents ne résistent pas au redimensionnement d'image. Ils ne vous permettent pas de trouver un modèle dans l'image si l'échelle de l'objet a été modifiée. SIFT (Transformation de caractéristique invariante à l'échelle) offre une solution à ce problème. Prenez l'image à partir de laquelle nous extrayons les points clés et commençons à réduire progressivement sa taille avec un petit pas, et pour chaque option d'échelle, nous trouverons les points clés. La mise à l'échelle est une procédure difficile, mais sa réduction de 2/4/8 / ... peut être effectuée efficacement en sautant les pixels (dans SIFT, ces multiples échelles sont appelées «octaves»). Les échelles intermédiaires peuvent être approximées en appliquant un bleuâtre gaussien avec une taille de noyau différente à l'image. Comme nous l'avons décrit ci-dessus, cela peut être effectué de manière efficace sur le plan informatique. Le résultat ressemblera si nous réduisons d'abord l'image puis l'agrandissons à sa taille d'origine - de petits détails sont perdus, l'image devient «floue».
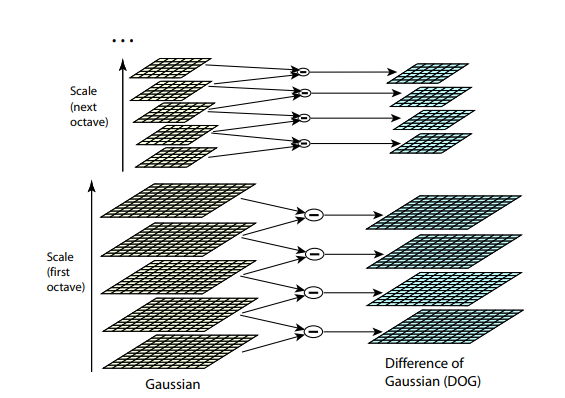
Après cette procédure, nous calculons la différence entre les échelles voisines. De grandes valeurs (en valeur absolue) dans cette différence se produiront si certains petits détails cessent d'être visibles au niveau d'échelle suivant, ou, inversement, le niveau d'échelle suivant commence à capturer une partie qui n'était pas visible au niveau précédent. Cette technique est appelée DoG, Difference of Gaussian. Nous pouvons supposer que la grande importance de cette différence est déjà un signal qu'il y a quelque chose d'intéressant à cet endroit sur l'image. Mais nous nous intéressons à l'échelle pour laquelle ce point clé sera le plus expressif. Pour ce faire, nous considérerons un point clé non seulement comme un point qui diffère de son environnement, mais qui diffère également le plus fortement entre différentes échelles d'image. En d'autres termes, nous choisirons un point clé non seulement dans l'espace X et Y, mais dans l'espace (X,Y,échelle) . Dans SIFT, cela se fait en trouvant des points dans le DoG (Difference of Gaussians), qui sont des hauts ou des bas locaux dans  cube d'espace (X,Y,échelle) autour d'elle:
cube d'espace (X,Y,échelle) autour d'elle:
Des algorithmes pour trouver des points clés et construire des descripteurs SIFT et SURF sont brevetés. Autrement dit, pour leur utilisation commerciale, il est nécessaire d'obtenir une licence. C'est pourquoi ils ne sont pas disponibles à partir du package opencv principal, mais uniquement à partir d'un package opencv_contrib distinct. Cependant, jusqu'à présent, nos recherches sont de nature purement académique, donc rien ne nous empêche de participer au SIFT en comparaison.
Descripteurs
Essayons d'appliquer une sorte de détecteur (par exemple, Harris) au modèle et à l'image.


Après avoir trouvé les points clés de l'image et du modèle, vous devez en quelque sorte les comparer les uns aux autres. Permettez-moi de vous rappeler que jusqu'à présent, nous n'avons extrait que les positions des points clés. Ce que ce point signifie (par exemple, dans quelle direction l'angle trouvé est dirigé), nous n'avons pas encore déterminé. Et une telle description peut aider à comparer les points et les motifs de l'image les uns avec les autres. Certains points du modèle dans l'image peuvent être déplacés par des distorsions, recouvertes par d'autres objets, il ne semble donc pas fiable de se fier uniquement à la position des points les uns par rapport aux autres. Par conséquent, prenons un voisinage pour chaque point clé pour construire une certaine description (descripteur), qui nous permet ensuite de prendre quelques points (un point du modèle, un de l'image) et comparer leur similitude.
BREF
(.. 0 1), , XOR , . ? , N . , i- , , — i- 1. N. - (, — ), : , “”. , ( ). BRIEF .

. . , GII .
, , (.. , , ). OpenCV .
SIFT
SIFT , . SIFT 1616 , 44 . ( , ). 8 (, -, , ..). — 8 , , . . , 8- . 128 ( 4*4 = 16 , 8 ). .
Comparaison
( — , ), - :

— . ?
, . , , . , , , , . ? BRIEF, , , . , BRIEF 1/16 . SIFT — - 1/4 .
SIFT.
Maintenant, nous appliquons toutes les connaissances acquises pour résoudre notre problème. Dans notre cas, les exigences pour le détecteur de points clés sont suffisantes: nous n'avons pas besoin d'invariance pour redimensionner, ainsi que des performances extrêmement élevées. Comparez les trois détecteurs.
| Détecteur de coin Harris | Rapide | SIFT |
|---|
 |  |  |
 |  |  |
 |  |  |
SIFT a trouvé extrêmement peu de points clés sur le bouton. Cela est compréhensible - le bouton est un objet assez petit et plat, et le zoom n'aide pas à trouver les points clés.
De plus, aucun détecteur n'a géré le troisième cas. Ceci est explicable et attendu. En règle générale, les méthodes ci-dessus sont utilisées pour rechercher un objet à partir d'un modèle dans une image où il peut être partiellement masqué, pivoté ou légèrement déformé. Dans notre cas, nous voulons trouver non pas exactement le même objet , mais un objet assez similaire au modèle (bouton) . C'est une tâche légèrement différente. Ainsi, la modification de la forme du bouton lui-même (par exemple, le rayon d'arrondi des coins ou l'épaisseur du cadre de points) modifie les points clés en eux et leurs descripteurs. De plus, les points clés seront situés dans le coin du bouton. En raison de la position sur le bord, les points seront instables: leur emplacement exact et leurs descripteurs sont affectés par ce qui est dessiné à côté du bouton.
Conclusion - la méthode est bonne et remplit correctement les situations lorsque l'objet souhaité est tourné, sa taille est modifiée ou l'objet est partiellement caché (ce qui est bon pour trouver des objets complexes ou une étiquette de prix, par exemple). Cependant, s'il y a peu de points sur l'objet qui peuvent être «capturés», ou si la forme de l'objet change trop, les points clés et eux sur le modèle et l'image peuvent ne pas coïncider. En outre, un arrière-plan avec beaucoup de petits détails peut déplacer les "points clés" ou changer leurs descripteurs.
Nous pouvons trouver une correspondance qui utilise les coordonnées des points clés. Au lieu de rechercher des paires de points sur le modèle et l'image, dont le voisinage est similaire, vous pouvez rechercher de tels ensembles de points, l'interposition de points clés sur le modèle et l'image sera similaire. Dans le cas général, il s'agit d'une tâche assez compliquée (à la fois sur le plan informatique et du point de vue de la programmation), en particulier dans une situation où certains points peuvent être décalés ou absents. Mais, étant donné que nous avons des points clés - des angles, il nous suffit de trouver des groupes qui formeront grossièrement un rectangle des proportions souhaitées, et à l'intérieur desquels il n'y aura pas de points clés. Nous arrivons progressivement à la méthode suivante:
Détection de contour
Habituellement, un bouton est une sorte d'objet rectangulaire (parfois avec des coins arrondis), dont les côtés sont parallèles aux axes de coordonnées. Essayons ensuite de distinguer les zones de différence de contraste (bords), et parmi elles, nous trouverons des visages dont les contours sont similaires au contour de l'objet dont nous avons besoin. Cette méthode est appelée détection de contour.
Détection des contours
Contrairement à la détection des points clés, nous nous intéressons non seulement aux angles des points clés, mais également aux arêtes. Cependant, les idées de base que nous pouvons tirer de là. Lissez l'image avec un filtre gaussien et comme dans le détecteur de coin Harris. Ensuite, nous calculons les dérivées de l'intensité Je x et Je y . Comme nous n'avons pas besoin de distinguer les angles des bords, nous n'avons pas besoin de considérer le tenseur structurel - il suffit de calculer la force du gradient: I l = I 2 x + I 2 y (au fait, c'est la racine de T r ( H ) , ou à partir de la somme de la diagonale du tenseur structurel). Après cela, nous ne laissons que des pixels qui sont des maxima locaux en termes de Je l (en utilisant la suppression non maximale déjà considérée), mais comme paramètre local, nous choisirons non pas 8 pixels voisins, mais les pixels de ces 8, vers lesquels je suis dirigé, et du côté opposé:
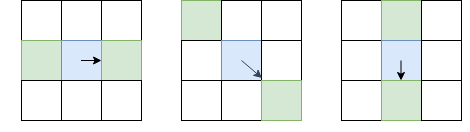
Le pixel en question est bleu, la flèche est de direction I. Les pixels verts sont ceux qui seront pris en compte lors de la suppression non maximale.
Un tel choix inhabituel de pixels pour la comparaison est dû au fait que nous ne voulons pas faire de lacunes dans la bordure. Dans l'image de gauche, le visage va de haut en bas, et comme la suppression non maximale ne comparera pas les intensités avec les pixels au-dessus et en dessous du bleu, nous obtenons un visage continu.
De toute évidence, une suppression non maximale ne suffit pas et vous devez appliquer une sorte de filtrage pour supprimer les bords avec Il trop bas. Pour ce faire, nous appliquons la technique du «double seuillage»: nous supprimons tous les pixels avec Il, avec une intensité de dégradé inférieure au seuil bas, et assignons tous les pixels au-dessus du seuil haut à «bords forts». Les pixels dans lesquels la force du gradient se situe entre Bas et Haut seront appelés «bords faibles», nous ne les laissons que s'ils sont connectés à des «bords forts»:
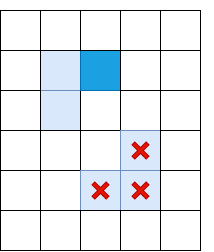
Le bleu clair indique les «côtes faibles», le bleu foncé - fort. Les côtes de la partie inférieure sont tamisées, car elles ne sont reliées à aucune côte forte.
Nous venons de décrire Canny Edge Detector. Il est extrêmement largement utilisé à ce jour comme une procédure simple et rapide qui vous permet de retrouver les contours des objets.
Suivi des frontières
L'action suivante consiste à sélectionner les contours de la carte avec les visages trouvés. Trouvez les composants associés (îlots de pixels adjacents qui ont passé toutes les vérifications) et vérifiez chacun d'eux, à quel point il ressemble à un bouton. Après avoir appliqué la suppression non maximale dans Canny, nous avons la garantie que les bords auront une épaisseur d'un pixel, mais comptons-y. Pour chaque pixel qui a été affecté à un visage, et à côté duquel se trouve un pixel non-visage, nous l'assignons à une «bordure». En passant d'un pixel de la frontière à un autre, nous revenons soit au même pixel (puis nous avons trouvé le chemin), soit à une impasse (alors vous pouvez essayer de revenir en arrière s'il y avait une fourchette quelque part le long du chemin):

L'algorithme de suivi de bordure complet, prenant en compte différents cas de bord (par exemple, lorsqu'un objet avec une face épaisse a généré deux contours, interne et externe), est décrit ici . Après avoir appliqué cet algorithme, nous aurons un ensemble de contours qui pourraient potentiellement être des boutons.
Filtrage des chemins
Comment savoir que notre circuit est un bouton? Pour les rectangles et les polygones, il existe une excellente méthode basée sur la simplification du contour . Il suffit de «réduire» progressivement les côtes, si elles sont presque sur une ligne droite, puis de calculer le nombre de côtes restantes et de vérifier les angles entre elles. Malheureusement, pour notre cas, ces méthodes ne conviennent pas - notre rectangle a des coins arrondis. En outre, il existe une correspondance de contour pour les figures à géométrie complexe - mais cela ne nous concerne pas non plus, car nous n'avons qu'un rectangle (des exemples avec un contour humain sont donnés dans l'article). Par conséquent, il est préférable de créer un filtre basé sur les propriétés de la figure elle-même. Nous savons que:
- Le bouton est suffisamment grand (zone supérieure à 100 pixels)
- Les côtés sont parallèles aux axes de coordonnées
- Le rapport de l'aire de la figure à l'aire du rectangle englobant doit être assez proche de l'unité. Nous avons fixé le seuil à 0,8, car le bouton est un rectangle avec des côtés parallèles aux axes de coordonnées, et les 20% manquants sont les coins arrondis.
De plus, de l'expérience de l'utilisation de détecteurs de points clés, nous nous souvenons qu'il peut y avoir des problèmes avec des situations où il y a un objet de contraste sous le bouton. Par conséquent, après avoir appliqué Canny, nous floutons les bords pour fermer les petits trous qui pourraient survenir de tels objets.
Nous appliquons l'approche résultante:

L'application de filtre Canny (image 2) a trouvé la forme nécessaire, mais en raison de la forme complexe du bouton et du gradient, de nombreux contours ont été trouvés à la fois, et en raison d'une suppression non maximale, certains d'entre eux n'ont pas été fermés. L'application de flou (3 images) a résolu le problème.
Approche de test
Exécutez la recherche de contours dans l'image résultante. Colorez les contours qui ont réussi le test en rouge. S'il y en a plusieurs, nous devons choisir l'option la plus réussie parmi eux. Nous sélectionnons le contour de la plus grande zone et le peignons en vert.
|  |
|  |
|  |
|
Le design résultant a trouvé des boutons sur les images de test. Une course sur toutes les bannières a montré qu'occasionnellement (1 cas sur ~ 20), au lieu d'un bouton, il sélectionne des dés rectangulaires d'iOS Appstore et de Google Apps, ou d'autres objets rectangulaires (cas de téléphone). Par conséquent, en ajoutant la possibilité d'indiquer manuellement la position dans ce cas rare d'une détermination incorrecte, nous avons implémenté cette option dans l'outil de localisation.
Conclusion
Pour résumer. Le CV «classique» sans apprentissage approfondi fonctionne toujours, et sur cette base, vous pouvez résoudre des problèmes. Ils sont sans prétention et ne nécessitent pas une grande quantité de données balisées, un matériel puissant et ils sont plus faciles à déboguer. Cependant, ils introduisent des hypothèses supplémentaires et, par conséquent, avec leur aide, tous les problèmes ne peuvent pas être résolus efficacement.
- La mise en correspondance de modèles est le moyen le plus simple, basé sur la recherche d'un endroit dans l'image qui est le plus similaire (par une métrique simple) à un modèle. Efficace avec une correspondance pixel par pixel. Il peut être rendu résistant aux plis et aux petits changements de taille, mais avec des changements importants, il peut ne pas fonctionner correctement.
- Détection / correspondance de points clés - trouvez les points clés, faites correspondre les points de l'image et du modèle. Les détecteurs sont résistants aux rotations, au zoom (en fonction du détecteur et du descripteur sélectionnés) et à l'adaptation - aux chevauchements partiels. Mais cette méthode ne fonctionne bien que s'il y a suffisamment de «points clés» dans l'objet, et les paramètres régionaux du modèle et des points d'image coïncident assez bien (c'est-à-dire le même objet sur le modèle et l'image).
- Détection de contour - trouver les contours des objets et trouver un contour similaire au contour de l'objet souhaité. Cette solution ne prend en compte que la forme de l'objet et ignore son contenu et sa couleur (qui peuvent être à la fois un plus et un moins).
Un lecteur averti peut remarquer que notre problème peut être résolu à l'aide de méthodes modernes de vision par ordinateur. Par exemple, le réseau YOLO renvoie la boîte englobante de l'objet souhaité - et c'est ce qui nous intéresse. Oui, nous avons testé et lancé avec succès une solution basée sur le deep learning - mais comme une deuxième itération (déjà après le lancement et le démarrage de l'outil de localisation). Ces solutions sont plus résistantes aux modifications des paramètres des boutons et ont de nombreuses propriétés positives: par exemple, au lieu de sélectionner des seuils et des paramètres avec vos mains, vous pouvez simplement ajouter des exemples de bannières sur lesquelles le réseau se trompe (Active Learning) dans le kit de formation. L'utilisation de l'apprentissage en profondeur pour notre tâche a ses problèmes et ses points intéressants. Par exemple, de nombreuses méthodes modernes de vision par ordinateur nécessitent un grand nombre d'images annotées, mais nous n'avions pas de balisage (comme dans de nombreux cas réels), et le nombre total de bannières différentes ne dépasse pas plusieurs milliers. Par conséquent, nous avons décidé de disposer nous-mêmes un petit nombre d'images et d'écrire un générateur qui créera d'autres bannières similaires sur leur base. Dans ce sens, il existe de nombreuses astuces intéressantes . Il existe de nombreux autres pièges, et la tâche même de déterminer la position d'un objet de vision par ordinateur est vaste et comporte de nombreuses solutions. Par conséquent, il a été décidé de limiter le champ de vision de l'article, et les décisions basées sur le deep learning n'ont pas été prises en compte.
Le code avec des blocs-notes qui implémentent les méthodes décrites et dessinent des images de l'article peut être trouvé dans le référentiel ).