
Le monde moderne est tout simplement inconcevable sans l'utilisation de systèmes distribués. Même l'application mobile la plus simple dispose d'une API via laquelle elle se connecte au stockage cloud. Cependant, la conception de systèmes distribués est toujours un art, pas une science exacte. La nécessité d'apporter une base sérieuse à cela est attendue depuis longtemps, et si vous voulez gagner en confiance dans la création, le support et le fonctionnement des systèmes distribués - commencez par ce livre!
Brendan Burns, spécialiste réputé des technologies cloud et de Kubernetes, établit dans ce petit travail le minimum absolu nécessaire à la bonne conception des systèmes distribués. Ce livre décrit les modèles sans âge de la conception de systèmes distribués. Il vous aidera non seulement à créer de tels systèmes à partir de zéro, mais aussi à convertir efficacement ceux existants.
Extrait. Motif de décorateur. Convertir une demande ou une réponse
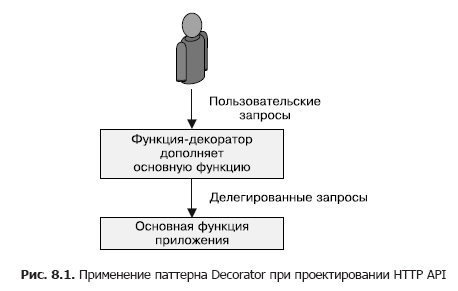
FaaS est idéal lorsque vous avez besoin de fonctions simples qui traitent les données d'entrée, puis les transfèrent vers d'autres services. Ce type de modèle peut être utilisé pour étendre ou décorer des requêtes HTTP envoyées ou reçues par un autre service. Ce modèle est schématisé sur la Fig. 8.1.
Soit dit en passant, dans les langages de programmation, il existe plusieurs analogies avec ce modèle. En particulier, Python a des décorateurs de fonction qui sont fonctionnellement similaires aux décorateurs de demande ou de réponse. Étant donné que les transformations de décoration ne stockent pas l'état et sont souvent ajoutées ex facto au fur et à mesure que le service se développe, elles sont parfaitement adaptées à la mise en œuvre en tant que FaaS. De plus, la légèreté FaaS signifie que vous pouvez expérimenter avec différents décorateurs jusqu'à ce que vous en trouviez un qui s'intègre plus étroitement au service.
L'ajout de valeurs par défaut aux paramètres d'entrée des demandes d'API HTTP RESTful illustre les avantages du modèle Decorator. De nombreuses demandes d'API contiennent des champs qui doivent être remplis avec des valeurs raisonnables s'ils n'ont pas été spécifiés par l'appelant. Par exemple, vous souhaitez que le champ soit défini par défaut sur true. Ceci est difficile à réaliser avec JSON classique, car le champ vide par défaut est null, ce qui est généralement interprété comme faux. Pour résoudre ce problème, vous pouvez ajouter la logique de substitution des valeurs par défaut devant le serveur API ou dans le code d'application (par exemple, si (champ == null) champ = vrai). Cependant, ces deux approches ne sont pas optimales, car le mécanisme de substitution par défaut est conceptuellement indépendant du traitement des demandes. Au lieu de cela, nous pouvons utiliser le modèle FaaS Decorator, qui transforme la demande entre l'utilisateur et la mise en œuvre du service.
Compte tenu de ce qui a été dit précédemment dans la section sur les modèles à nœud unique, vous vous demandez peut-être pourquoi nous n'avons pas conçu le service de substitution par défaut sous la forme d'un conteneur d'adaptateur. Cette approche est logique, mais cela signifie également que la mise à l'échelle du service de recherche par défaut et la mise à l'échelle du service API lui-même deviennent dépendantes l'une de l'autre. La substitution de valeurs par défaut est une opération facile à calculer, et pour cela, vous n'aurez probablement pas besoin de nombreuses instances du service.
Dans les exemples de ce chapitre, nous utiliserons le framework FaaS kubeless (https://github.com/kubeless/kubeless). Kubeless est déployé au-dessus du service d'orchestrateur de conteneurs Kubernetes. Si vous avez déjà préparé le cluster Kubernetes, continuez l'installation de Kubeless, qui peut être téléchargé à partir du site correspondant (https://github.com/kubeless/kubeless/releases). Une fois que vous avez l'exécutable kubeless, vous pouvez l'installer dans le cluster avec la commande kubeless install.
Kubeless est installé en tant que module complémentaire de l'API Kubernetes tiers. Cela signifie qu'après l'installation, il peut être utilisé dans le cadre de l'outil de ligne de commande kubectl. Par exemple, les fonctions déployées dans le cluster peuvent être vues en exécutant la commande kubectl get functions. Aucune fonction n'est actuellement déployée dans votre cluster.
Atelier Substitution des valeurs par défaut avant le traitement de la demande
Vous pouvez démontrer l'utilité du modèle Decorator dans FaaS par l'exemple de la substitution de valeurs par défaut dans un appel RESTful pour des paramètres dont les valeurs n'ont pas été définies par l'utilisateur. Avec FaaS, c'est assez simple. La fonction de recherche par défaut est écrite en Python:
# -, # def handler(context): # obj = context.json # "name" , # if obj.get("name", None) is None: obj["name"] = random_name() # 'color', # 'blue' if obj.get("color", None) is None: obj["color"] = "blue" # API- # # return call_my_api(obj)
Enregistrez cette fonction dans un fichier appelé defaults.py. N'oubliez pas de remplacer l'appel call_my_api par l'API souhaitée. Cette fonction de substitution par défaut peut être enregistrée en tant que fonction sans noyau avec la commande suivante:
kubeless function deploy add-defaults \ --runtime python27 \ --handler defaults.handler \ --from-file defaults.py \ --trigger-http
Pour le tester, vous pouvez utiliser l'outil kubeless:
kubeless function call add-defaults --data '{"name": "foo"}'
Le modèle Decorator montre à quel point il est facile d'adapter et d'étendre les API existantes avec des fonctionnalités supplémentaires telles que la validation ou la substitution de valeurs par défaut.
Gestion des événements
La plupart des systèmes sont orientés vers les requêtes - ils traitent des flux continus de demandes d'utilisateurs et d'API. Malgré cela, il existe de nombreux systèmes orientés événements. La différence entre la demande et l'événement, me semble-t-il, réside dans le concept de la session. Les demandes font partie d'un processus d'interaction plus large (session). Dans le cas général, chaque demande d'utilisateur fait partie du processus d'interaction avec une application Web ou l'API dans son ensemble. Je vois les événements comme plus «ponctuels», de nature asynchrone. Les événements sont importants et doivent être traités en conséquence, mais ils sont arrachés au contexte principal de l'interaction et la réponse ne survient qu'après un certain temps. Un exemple d'événement est l'abonnement d'un utilisateur à un certain service, ce qui entraînera l'envoi d'une lettre de salutation; télécharger un fichier dans un dossier partagé, ce qui entraînera l'envoi de notifications à tous les utilisateurs de ce dossier; ou même préparer l'ordinateur pour un redémarrage, qui informera l'opérateur ou le système automatisé qu'une action appropriée est requise.
Étant donné que ces événements sont largement indépendants et n'ont pas d'état interne et que leur fréquence est très variable, ils conviennent parfaitement pour travailler dans des architectures FaaS orientées événement. Ils sont souvent déployés à côté du serveur d'applications «de combat» pour fournir des capacités supplémentaires ou pour le traitement en arrière-plan des données en réponse aux événements émergents. De plus, comme de nouveaux types d'événements traités sont constamment ajoutés au service, la simplicité du déploiement de la fonction les rend adaptés à la mise en œuvre de gestionnaires d'événements. Et comme chaque événement est conceptuellement indépendant des autres, l'affaiblissement forcé des relations au sein d'un système construit sur la base de fonctions nous permet de réduire sa complexité conceptuelle, permettant au développeur de se concentrer sur les étapes nécessaires pour traiter un seul type spécifique d'événement.
Un exemple spécifique d'intégration d'un composant orienté événement dans un service existant est la mise en œuvre de l'authentification à deux facteurs. Dans ce cas, l'événement sera la connexion de l'utilisateur au système. Un service peut générer un événement pour cette action et le transmettre à une fonction de gestionnaire. Le processeur, sur la base du code transmis et des coordonnées de l'utilisateur, lui enverra un code d'authentification sous forme de SMS.
Atelier Implémentation de l'authentification à deux facteurs
L'authentification à deux facteurs indique que pour que l'utilisateur puisse accéder au système, il a besoin de quelque chose qu'il connaît (par exemple, un mot de passe) et de quelque chose qu'il possède (par exemple, un numéro de téléphone). L'authentification à deux facteurs est bien meilleure qu'un simple mot de passe, car un attaquant devra voler à la fois votre mot de passe et votre numéro de téléphone pour y accéder.
Lors de la planification de la mise en œuvre de l'authentification à deux facteurs, vous devez traiter une demande de génération d'un code aléatoire, l'enregistrer auprès du service de connexion et envoyer un message à l'utilisateur. Vous pouvez ajouter du code qui implémente cette fonctionnalité directement dans le service de connexion lui-même. Cela complique le système, le rend plus monolithique. L'envoi d'un message doit se faire simultanément avec le code générant la page web de connexion, ce qui peut introduire un certain retard. Ce délai dégrade la qualité de l'interaction de l'utilisateur avec le système.
Il serait préférable de créer un service FaaS qui générerait un nombre aléatoire de manière asynchrone, l'enregistrerait avec le service de connexion et l'enverrait au téléphone de l'utilisateur. Ainsi, le serveur de connexion peut simplement exécuter une demande asynchrone au service FaaS, qui en parallèle effectuera la tâche relativement lente d'enregistrement et d'envoi du code.
Pour voir comment cela fonctionne, considérez le code suivant:
def two_factor(context): # code = random.randint(1 00000, 9 99999) # user = context.json["user"] register_code_with_login_service(user, code) # Twillio account = "my-account-sid" token = "my-token" client = twilio.rest.Client(account, token) user_number = context.json["phoneNumber"] msg = ", {}, : {}.".format(user, code) message = client.api.account.messages.create(to=user_number, from_="+1 20652 51212", body=msg) return {"status": "ok"}
Enregistrez ensuite FaaS dans kubeless:
kubeless function deploy add-two-factor \ --runtime python27 \ --handler two_factor.two_factor \ --from-file two_factor.py \ --trigger-http
Une instance de cette fonction peut être générée de manière asynchrone à partir du code JavaScript côté client après que l'utilisateur a entré le mot de passe correct. L'interface Web peut afficher immédiatement la page de saisie du code, et l'utilisateur, dès réception du code, peut l'informer du service de connexion dans lequel ce code est déjà enregistré.
Ainsi, l'approche FaaS a grandement facilité le développement d'un service simple, asynchrone et orienté événement qui est lancé lorsqu'un utilisateur se connecte au système.
Convoyeurs d'événements
Il existe un certain nombre d'applications qui, en fait, sont plus faciles à considérer comme un pipeline d'événements à couplage lâche. Les pipelines d'événements ressemblent souvent aux bons vieux organigrammes. Ils peuvent être représentés comme un graphique dirigé de synchronisation des événements associés. Dans le cadre du modèle Event Pipeline, les nœuds correspondent à des fonctions et les arcs qui les connectent correspondent à des requêtes HTTP ou à d'autres types d'appels réseau.
Entre les éléments du conteneur, en règle générale, il n'y a pas d'état général, mais il peut y avoir un contexte commun ou un autre point de référence, sur la base duquel la recherche dans le référentiel sera effectuée.
Quelle est la différence entre un tel pipeline et une architecture de microservices? Il existe deux différences importantes. La première différence, et la plus importante, entre les fonctions de service et les services en cours d'exécution est que les pipelines d'événements sont essentiellement pilotés par les événements. L'architecture de microservice, au contraire, implique un ensemble de services fonctionnant en permanence. De plus, les pipelines d'événements peuvent être asynchrones et lier une variété d'événements. Il est difficile d'imaginer comment l'approbation de l'application Jira peut être intégrée dans une application de microservice. En même temps, il est facile d'imaginer comment il s'intègre dans le pipeline d'événements.
Par exemple, considérons un pipeline dans lequel l'événement source est le chargement de code dans un système de contrôle de version. Cet événement provoque une reconstruction de code. L'assemblage peut prendre plusieurs minutes, après quoi un événement est généré qui déclenche la fonction de test de l'application assemblée. En fonction du succès de l'assemblage, la fonction de test effectue différentes actions. Si l'assemblage a réussi, une application est créée, qui doit être approuvée par la personne pour que la nouvelle version de l'application soit opérationnelle. La fermeture de l'application sert de signal pour la mise en service de la nouvelle version. Si l'assemblage a échoué, Jira fait une demande pour l'erreur détectée et le pipeline se ferme.
Atelier Implémentation d'un pipeline pour enregistrer un nouvel utilisateur
Considérez la tâche d'implémenter une séquence d'actions pour enregistrer un nouvel utilisateur. Lors de la création d'un nouveau compte, toute une série d'actions sont toujours effectuées, par exemple l'envoi d'un e-mail de bienvenue. Il existe également un certain nombre d'actions qui peuvent ne pas être effectuées à chaque fois, par exemple, en vous abonnant à une newsletter par courrier électronique sur les nouvelles versions d'un produit (également appelé spam).
Une approche consiste à créer un service monolithique pour créer de nouveaux comptes. Avec cette approche, une équipe de développement est responsable de l'ensemble du service, qui est également déployé dans son ensemble. Cela rend difficile la réalisation d'expériences et la modification du processus d'interaction de l'utilisateur avec l'application.
Considérez l'implémentation de la connexion utilisateur comme un pipeline d'événements de plusieurs services FaaS. Avec cette séparation, la fonction de création d'utilisateur n'a aucune idée de ce qui se passe lors de la connexion de l'utilisateur. Elle a deux listes:
- une liste d'actions nécessaires (par exemple, l'envoi d'un e-mail de bienvenue);
- une liste d'actions facultatives (par exemple, s'abonner à une newsletter).
Chacune de ces actions est également implémentée en tant que FaaS, et la liste d'actions n'est rien de plus qu'une liste de fonctions de rappel HTTP. Par conséquent, la fonction de création d'utilisateur a la forme suivante:
def create_user(context): # for key, value in required.items(): call_function(value.webhook, context.json) # # for key, value in optional.items(): if context.json.get(key, None) is not None: call_function(value.webhook, context.json)
Chacun des gestionnaires peut désormais également être implémenté selon le principe FaaS:
def email_user(context): # user = context.json['username'] msg = ', {}, , !".format(user) send_email(msg, contex.json['email]) def subscribe_user(context): # email = context.json['email'] subscribe_user(email)
Décomposé de cette manière, le service FaaS devient beaucoup plus simple, contient moins de lignes de code et se concentre sur la mise en œuvre d'une fonction spécifique. L'approche microservice simplifie l'écriture de code, mais peut entraîner des difficultés de déploiement et de gestion de trois microservices différents. Ici, l'approche FaaS fait ses preuves dans toute sa splendeur, car du fait de son utilisation, il devient très simple de gérer de petits morceaux de code. La visualisation du processus de création d'un utilisateur sous la forme d'un pipeline d'événements nous permet de comprendre en termes généraux ce qui se passe exactement lorsqu'un utilisateur se connecte, simplement en suivant le changement de contexte d'une fonction à l'autre au sein du pipeline.
»Plus d'informations sur le livre sont disponibles sur
le site Web de l'éditeur»
Contenu»
Extrait20% de réduction sur les coupons pour les créateurs -
Modèles de conceptionLors du paiement de la version papier du livre, une version électronique du livre est envoyée par e-mail.