En utilisant un exemple de description de l'implémentation de l'algorithme de chiffrement conformément à GOST 28147–89 construit sur le réseau Feistel, l'article montre les capacités du processeur double cœur BE-T1000 (aka Baikal-T1) et des tests comparatifs de l'implémentation de l'algorithme sont effectués à l'aide de calculs vectoriels avec et sans coprocesseur SIMD. Ici, nous allons démontrer l'utilisation du bloc SIMD pour la tâche de chiffrement conformément à GOST 28147-89, mode ECB.
Cet article a été écrit l'année dernière pour la revue Electronic Components par Alexei Kolotnikov , un programmeur de premier plan chez Baikal Electronics. Et comme il n'y a pas beaucoup de lecteurs dans ce magazine et que l'article est utile pour ceux qui sont professionnellement impliqués dans la cryptographie, je le publie ici avec la permission de l'auteur et de ses petits ajouts.
Le processeur Baikal-T1 et le bloc SIMD à l'intérieur
Le processeur Baikal-T1 comprend un système bicœur multiprocesseur de la famille MIPS32 P5600, ainsi qu'un ensemble d'interfaces haute vitesse pour l'échange de données et basse vitesse pour le contrôle des périphériques. Voici le schéma structurel de ce processeur:
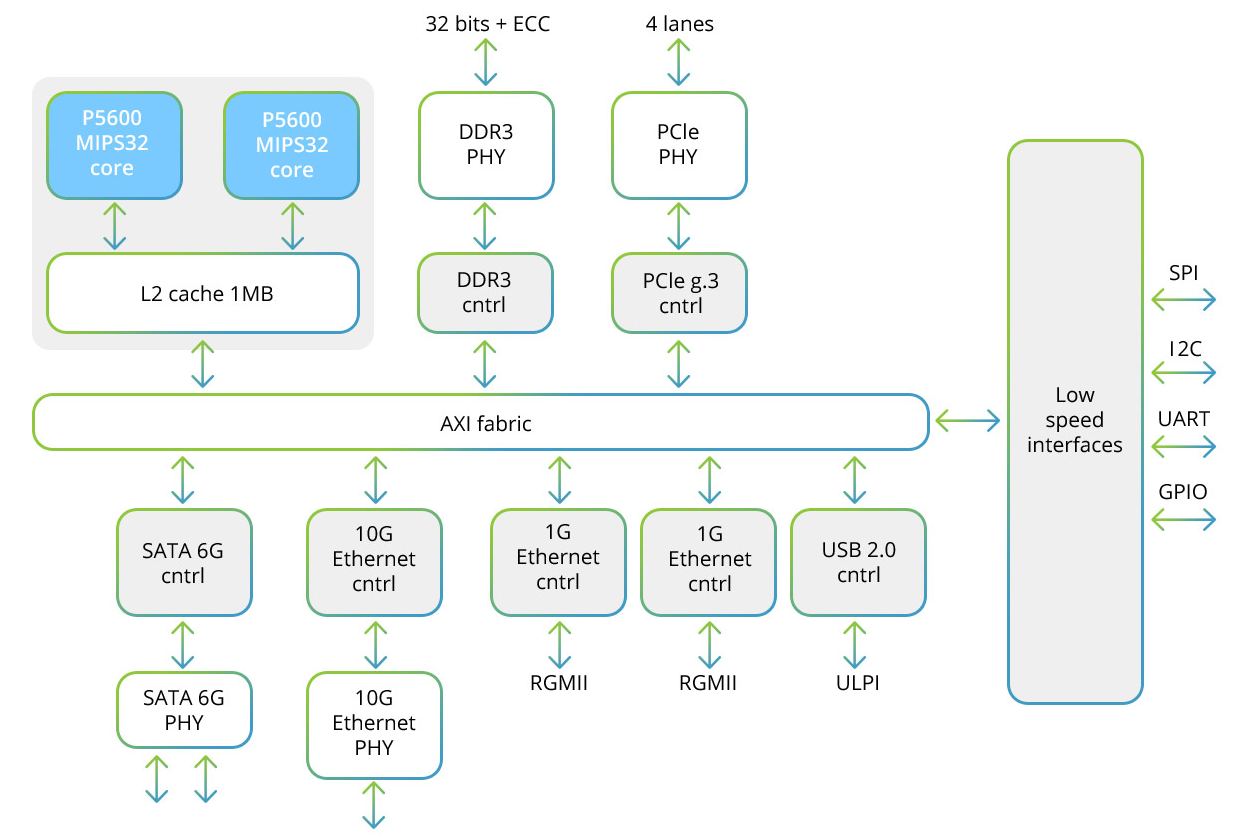
Chacun des deux cœurs comprend un bloc SIMD qui vous permet de travailler avec des vecteurs 128 bits. Lors de l'utilisation de la méthode SIMD, plusieurs échantillons sont traités,
et le vecteur entier, qui peut contenir plusieurs échantillons, c'est-à-dire qu'une commande est immédiatement appliquée à l'ensemble du vecteur (tableau) de données. Ainsi, dans un cycle de commande, plusieurs échantillons sont traités. Le processeur utilise le bloc MIPS32 SIMD, qui vous permet de travailler avec 32 morceaux de registres 128 bits.
Chaque registre peut contenir des vecteurs des dimensions suivantes: 8 × 16; 16 × 8; 4 × 32 ou
2 × 64 bits. Il est possible d'utiliser plus de 150 instructions pour le traitement des données: entier, virgule flottante et virgule fixe, y compris les opérations au niveau du bit, les opérations de comparaison et les opérations de conversion.
La technologie MIPS SIMD très détaillée a été décrite par SparF dans l'article "La technologie MIPS SIMD et le processeur Baikal-T1" .
Évaluation de l'efficacité de l'informatique vectorielle
Le coprocesseur arithmétique du processeur Baikal-T1 combine un processeur traditionnel à virgule flottante et un processeur SIMD parallèle, axé sur le traitement efficace des vecteurs et des signaux numérisés. Une évaluation indépendante des performances du coprocesseur vectoriel SIMD a été réalisée en 2017 par SparF lors de la rédaction de l'article «Technologie MIPS SIMD et processeur Baïkal-T1» . Si vous le souhaitez, ces mesures peuvent être répétées, effectuées indépendamment en se connectant à un support distant avec un processeur .
Ensuite, la tâche de test consistait à décoder la vidéo encodée à l'aide des bibliothèques gratuites x264 (clip de démonstration H.264) et x265 (fichier vidéo HEVC), avec des captures d'écran prises à intervalles réguliers. Comme prévu, une augmentation notable des performances du cœur du processeur sur les tâches FFmpeg avec l'utilisation des capacités matérielles SIMD a été notée:

Brève description de l'algorithme GOST 28147-89
Ici, nous ne noterons que les principales caractéristiques pour comprendre le code et l'optimisation:
- L'algorithme est construit sur le réseau Feistel.

- L'algorithme se compose de 32 tours.
- Un tour consiste à mélanger une clé et à remplacer 8 parties de 4 bits dans un tableau par un décalage de 11 bits.
Une description détaillée de l'algorithme de conversion d'informations conformément à GOST 28147-89 est donnée dans la norme d'État de l'URSS .
Implémentation de l'algorithme GOST 28147-89 sans utiliser de bloc SIMD
À des fins de comparaison, les algorithmes ont été initialement mis en œuvre à l'aide de commandes standard «non vectorisées».
Le code assembleur MIPS proposé ici vous permet de crypter un bloc de 64 bits en 450 ns (ou ~ 150 Mb / s) à une fréquence nominale du processeur de 1200 MHz. Un seul noyau est impliqué dans les calculs.
La préparation d'une table de remplacement implique de la développer en une représentation 32 bits pour accélérer le travail du tour: au lieu de remplacer quatre bits par un masquage et un décalage à l'avance
le tableau préparé remplace huit bits chacun.
uint8_t sbox_test[8][16] = { {0x9, 0x6, 0x3, 0x2, 0x8, 0xb, 0x1, 0x7, 0xa, 0x4, 0xe, 0xf, 0xc, 0x0, 0xd, 0x5}, {0x3, 0x7, 0xe, 0x9, 0x8, 0xa, 0xf, 0x0, 0x5, 0x2, 0x6, 0xc, 0xb, 0x4, 0xd, 0x1}, {0xe, 0x4, 0x6, 0x2, 0xb, 0x3, 0xd, 0x8, 0xc, 0xf, 0x5, 0xa, 0x0, 0x7, 0x1, 0x9}, {0xe, 0x7, 0xa, 0xc, 0xd, 0x1, 0x3, 0x9, 0x0, 0x2, 0xb, 0x4, 0xf, 0x8, 0x5, 0x6}, {0xb, 0x5, 0x1, 0x9, 0x8, 0xd, 0xf, 0x0, 0xe, 0x4, 0x2, 0x3, 0xc, 0x7, 0xa, 0x6}, {0x3, 0xa, 0xd, 0xc, 0x1, 0x2, 0x0, 0xb, 0x7, 0x5, 0x9, 0x4, 0x8, 0xf, 0xe, 0x6}, {0x1, 0xd, 0x2, 0x9, 0x7, 0xa, 0x6, 0x0, 0x8, 0xc, 0x4, 0x5, 0xf, 0x3, 0xb, 0xe}, {0xb, 0xa, 0xf, 0x5, 0x0, 0xc, 0xe, 0x8, 0x6, 0x2, 0x3, 0x9, 0x1, 0x7, 0xd, 0x4} }; uint32_t sbox_cvt[4*256]; for (i = 0; i < 256; ++i) { uint32_t p; p = sbox[7][i >> 4] << 4 | sbox[6][i & 15]; p = p << 24; p = p << 11 | p >> 21; sbox_cvt[i] = p; // S87 p = sbox[5][i >> 4] << 4 | sbox[4][i & 15]; p = p << 16; p = p << 11 | p >> 21; sbox_cvt[256 + i] = p; // S65 p = sbox[3][i >> 4] << 4 | sbox[2][i & 15]; p = p << 8; p = p << 11 | p >> 21; sbox_cvt[256 * 2 + i] = p; // S43 p = sbox[1][i >> 4] << 4 | sbox[0][i & 15]; p = p << 11 | p >> 21; sbox_cvt[256 * 3 + i] = p; // S21 }
Le chiffrement par bloc est 32 fois une répétition du tour à l'aide de la clé.
// input: a0 - &in, a1 - &out, a2 - &key, a3 - &sbox_cvt LEAF(gost_encrypt_block_asm) .set reorder lw n1, (a0) // n1, IN lw n2, 4(a0) // n2, IN + 4 lw t0, (a2) // key[0] -> t0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 7 gostround n1, n2, 6 gostround n2, n1, 5 gostround n1, n2, 4 gostround n2, n1, 3 gostround n1, n2, 2 gostround n2, n1, 1 gostround n1, n2, 0 gostround n2, n1, 0 1: sw n2, (a1) sw n1, 4(a1) jr ra nop END(gost_encrypt_block_asm)
Un tour de table étalé n'est qu'un échange de table.
.macro gostround x_in, x_out, rkey addu t8, t0, \x_in /* key[0] + n1 = x */ lw t0, \rkey * 4 (a2) /* next key to t0 */ ext t2, t8, 24, 8 /* get bits [24,31] */ ext t3, t8, 16, 8 /* get bits [16,23] */ ext t4, t8, 8, 8 /* get bits [8,15] */ ext t5, t8, 0, 8 /* get bits [0, 7] */ sll t2, t2, 2 /* convert to dw offset */ sll t3, t3, 2 /* convert to dw offset */ sll t4, t4, 2 /* convert to dw offset */ sll t5, t5, 2 /* convert to dw offset */ addu t2, t2, a3 /* add sbox_cvt */ addu t3, t3, a3 /* add sbox_cvt */ addu t4, t4, a3 /* add sbox_cvt */ addu t5, t5, a3 /* add sbox_cvt */ lw t6, (t2) /* sbox[x[3]] -> t2 */ lw t7, 256*4(t3) /* sbox[256 + x[2]] -> t3 */ lw t9, 256*2*4(t4) /* sbox[256 *2 + x[1]] -> t4 */ lw t1, 256*3*4(t5) /* sbox[256 *3 + x[0]] -> t5 */ or t2, t7, t6 /* | */ or t3, t1, t9 /* | */ or t2, t2, t3 /* | */ xor \x_out, \x_out, t2 /* n2 ^= f(...) */ .endm
Implémentation de l'algorithme GOST 28147-89 à l'aide d'un bloc SIMD
Le code proposé ci-dessous vous permet de chiffrer simultanément quatre blocs de 64 bits par 720 ns (soit ~ 350 Mbit / s) dans les mêmes conditions: fréquence du processeur 1200 MHz, un cœur.
Le remplacement est effectué en deux quadruples et immédiatement en 4 blocs avec l'instruction de shuffle et le masquage subséquent des quatre significatifs.
Extension d'une table de substitution
for(i = 0; i < 16; ++i) { sbox_cvt_simd[i] = (sbox[7][i] << 4) | sbox[0][i]; // $w8 [7 0] sbox_cvt_simd[16 + i] = (sbox[1][i] << 4) | sbox[6][i]; // $w9 [6 1] sbox_cvt_simd[32 + i] = (sbox[5][i] << 4) | sbox[2][i]; // $w10[5 2] sbox_cvt_simd[48 + i] = (sbox[3][i] << 4) | sbox[4][i]; // $w11[3 4] }
Initialisation des masques.
l0123: .int 0x0f0f0f0f .int 0xf000000f /* substitute from $w8 [7 0] mask in w12*/ .int 0x0f0000f0 /* substitute from $w9 [6 1] mask in w13*/ .int 0x00f00f00 /* substitute from $w10 [5 2] mask in w14*/ .int 0x000ff000 /* substitute from $w11 [4 3] mask in w15*/ .int 0x000f000f /* mask $w16 x N x N */ .int 0x0f000f00 /* mask $w17 N x N x */ LEAF(gost_prepare_asm) .set reorder .set msa la t1, l0123 /* masks */ lw t2, (t1) lw t3, 4(t1) lw t4, 8(t1) lw t5, 12(t1) lw t6, 16(t1) lw t7, 20(t1) lw t8, 24(t1) fill.w $w2, t2 /* 0f0f0f0f -> w2 */ fill.w $w12, t3 /* f000000f -> w12*/ fill.w $w13, t4 /* 0f0000f0 -> w13*/ fill.w $w14, t5 /* 00f00f00 -> w14*/ fill.w $w15, t6 /* 000ff000 -> w15*/ fill.w $w16, t7 /* 000f000f -> w16*/ fill.w $w17, t8 /* 0f000f00 -> w17*/ ld.b $w8, (a0) /* load sbox */ ld.b $w9, 16(a0) ld.b $w10, 32(a0) ld.b $w11, 48(a0) jr ra nop END(gost_prepare_asm)
Chiffrement à 4 blocs
LEAF(gost_encrypt_4block_asm) .set reorder .set msa lw t1, (a0) // n1, IN lw t2, 4(a0) // n2, IN + 4 lw t3, 8(a0) // n1, IN + 8 lw t4, 12(a0) // n2, IN + 12 lw t5, 16(a0) // n1, IN + 16 lw t6, 20(a0) // n2, IN + 20 lw t7, 24(a0) // n1, IN + 24 lw t8, 28(a0) // n2, IN + 28 lw t0, (a2) // key[0] -> t0 insert.w ns1[0],t1 insert.w ns2[0],t2 insert.w ns1[1],t3 insert.w ns2[1],t4 insert.w ns1[2],t5 insert.w ns2[2],t6 insert.w ns1[3],t7 insert.w ns2[3],t8 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 0 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 0 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 7 gostround4 ns1, ns2, 6 gostround4 ns2, ns1, 5 gostround4 ns1, ns2, 4 gostround4 ns2, ns1, 3 gostround4 ns1, ns2, 2 gostround4 ns2, ns1, 1 gostround4 ns1, ns2, 0 gostround4 ns2, ns1, 0 1: copy_s.w t1,ns2[0] copy_s.w t2,ns1[0] copy_s.w t3,ns2[1] copy_s.w t4,ns1[1] copy_s.w t5,ns2[2] copy_s.w t6,ns1[2] copy_s.w t7,ns2[3] copy_s.w t8,ns1[3] sw t1, (a1) // n2, OUT sw t2, 4(a1) // n1, OUT + 4 sw t3, 8(a1) // n2, OUT + 8 sw t4, 12(a1) // n1, OUT + 12 sw t5, 16(a1) // n2, OUT + 16 sw t6, 20(a1) // n1, OUT + 20 sw t7, 24(a1) // n2, OUT + 24 sw t8, 28(a1) // n1, OUT + 28 jr ra nop END(gost_encrypt_4block_asm)
Arrondi à l'aide des commandes de bloc SIMD avec calcul de 4 blocs simultanément
.macro gostround4 x_in, x_out, rkey fill.w $w0, t0 /* key -> Vi */ addv.w $w1, $w0, \x_in /* key[0] + n1 = x */ srli.b $w3, $w1, 4 /* $w1 >> 4 */ and.v $w4, $w1, $w16 /* x 4 x 0*/ and.v $w5, $w1, $w17 /* 6 x 2 x*/ and.v $w6, $w3, $w17 /* 7 x 3 x */ and.v $w7, $w3, $w16 /* x 5 x 1 */ lw t0, \rkey * 4(a2) /* next key -> t0 */ or.v $w4, $w6, $w4 /* 7 4 3 0 */ or.v $w5, $w5, $w7 /* 6 5 2 1 */ move.v $w6, $w5 /* 6 5 2 1 */ move.v $w7, $w4 /* 7 4 3 0 */ /* 7 xx 0 */ /* 6 xx 1 */ /* x 5 2 x */ /* x 4 3 x */ vshf.b $w4, $w8, $w8 /* substitute $w8 [7 0] */ and.v $w4, $w4, $w12 vshf.b $w5, $w9, $w9 /* substitute $w9 [6 1] */ and.v $w5, $w5, $w13 vshf.b $w6, $w10, $w10 /* substitute $w10 [5 2] */ and.v $w6, $w6, $w14 vshf.b $w7, $w11, $w11 /* substitute $w11 [4 3] */ and.v $w7, $w7, $w15 or.v $w4, $w4, $w5 or.v $w6, $w6, $w7 or.v $w4, $w4, $w6 srli.w $w1, $w4, 21 /* $w4 >> 21 */ slli.w $w3, $w4, 11 /* $w4 << 11 */ or.v $w1, $w1, $w3 xor.v \x_out, \x_out, $w1 .endm
Brèves conclusions
L'utilisation du bloc SIMD du processeur Baikal-T1 permet d'atteindre un taux de conversion des données d'environ 350 Mbit / s selon les algorithmes GOST 28147-89, ce qui est deux fois et demi (!) Fois plus élevé que l'implémentation sur les commandes standard. Étant donné que ce processeur possède deux cœurs, il est théoriquement possible de crypter un flux à une vitesse de ~ 700 Mbps. Au moins, l'implémentation test d'IPsec, avec cryptage selon GOST 28147-89, a montré un débit de canal de ~ 400 Mbps sur un duplex.