Bonjour, Habr!
Je travaille pour une société de jeux qui développe des jeux en ligne. Actuellement, tous nos jeux sont divisés en plusieurs «marchés» (un «marché» par pays) et dans chaque «marché» il y a une douzaine de mondes entre lesquels les joueurs sont répartis lors de l'inscription (enfin, ou parfois ils peuvent le choisir eux-mêmes). Chaque monde possède une base de données et un ou plusieurs serveurs Web / d'applications. Ainsi, la charge est divisée et distribuée à travers les mondes / serveurs presque également, et en conséquence, nous obtenons le maximum en ligne de joueurs 6K-8K (c'est le maximum, la plupart du temps plusieurs fois moins) et 200-300 demandes par heure de grande écoute par monde.
Une telle structure avec la division des joueurs en marchés et mondes devient obsolète; les joueurs veulent quelque chose de mondial. Lors des derniers matchs, nous avons cessé de diviser les gens par pays et laissé seulement un / deux marchés (Amérique et Europe), mais toujours avec de nombreux mondes dans chacun. La prochaine étape sera le développement de jeux avec une nouvelle architecture et l'unification de tous les joueurs dans un seul monde avec
une seule base de données .
Aujourd’hui, je voulais parler un peu de la façon dont j’étais chargé de vérifier si l’ensemble (et 50 à 200 000 utilisateurs à la fois) de l’un de nos jeux populaires «envoyait» jouer au prochain jeu basé sur la nouvelle architecture et si l'ensemble du système, en particulier la base de données (
PostgreSQL 11 ), peut pratiquement supporter une telle charge et, s'il ne le peut pas, savoir où est notre maximum. Je vais vous parler un peu des problèmes qui sont survenus et des décisions à prendre pour préparer à tester autant d'utilisateurs, du processus lui-même et des résultats.
Intro
Dans le passé, chez
InnoGames GmbH, chaque équipe de jeu a créé un projet de jeu à leur goût et à leur couleur, en utilisant souvent différentes technologies, langages de programmation et bases de données. De plus, nous avons de nombreux systèmes externes chargés des paiements, de l'envoi de notifications push, du marketing et plus encore. Pour travailler avec ces systèmes, les développeurs ont également créé leurs interfaces uniques du mieux qu'ils pouvaient.
Actuellement, dans le secteur des jeux mobiles, beaucoup d'
argent et, par conséquent, beaucoup de concurrence. Il est très important ici de le récupérer de chaque dollar dépensé en marketing et un peu plus d'en haut, donc toutes les sociétés de jeux «clôturent» très souvent les jeux même au stade des tests fermés, si elles ne répondent pas aux attentes analytiques. En conséquence, perdre du temps sur l'invention de la roue suivante n'est pas rentable, il a donc été décidé de créer une plate-forme unifiée qui fournira aux développeurs une solution prête à l'emploi pour l'intégration avec tous les systèmes externes, une base de données avec réplication et toutes les meilleures pratiques. Tout ce dont les développeurs ont besoin, c'est de développer et de «mettre» un bon jeu en plus et de ne pas perdre de temps sur un développement non lié au jeu lui-même.
Cette plateforme s'appelle
GameStarter :

Donc, au fait. Tous les futurs jeux InnoGames seront construits sur cette plate-forme, qui dispose de deux bases de données - maître et jeu (PostgreSQL 11). Master stocke des informations de base sur les joueurs (login, mot de passe, etc.) et ne participe, principalement, qu'au processus de connexion / enregistrement dans le jeu lui-même. Jeu - la base de données du jeu lui-même, où, en conséquence, toutes les données et entités du jeu sont stockées, ce qui est le cœur du jeu, où toute la charge ira.
Ainsi, la question s'est posée de savoir si toute cette structure pouvait supporter un nombre d'utilisateurs potentiel égal au maximum en ligne de l'un de nos jeux les plus populaires.
Défi
La tâche elle-même était la suivante: vérifier si la base de données (PostgreSQL 11), avec la réplication activée, peut supporter toute la charge que nous avons actuellement dans le jeu le plus chargé, ayant à sa disposition tout l'hyperviseur PowerEdge M630 (HV).
Je précise que la tâche pour le moment n'était
que de vérifier , en utilisant les configurations de base de données existantes, que nous avons formées en tenant compte des meilleures pratiques et de notre propre expérience.
Je dirai tout de suite la base de données, et l'ensemble du système s'est bien montré, à l'exception de quelques points. Mais ce projet de jeu particulier était au stade de prototype et à l'avenir, avec la complication des mécanismes de jeu, les demandes à la base de données deviendront plus compliquées et la charge elle-même pourrait augmenter considérablement et sa nature pourrait changer. Pour éviter cela, il est nécessaire de tester de manière itérative le projet avec chaque étape plus ou moins importante. L'automatisation de la possibilité d'exécuter ce type de tests avec quelques centaines de milliers d'utilisateurs est devenue la tâche principale à ce stade.
Le profil
Comme tout test de charge, tout commence par un profil de charge.
Notre valeur potentielle CCU60 (CCU est le nombre maximum d'utilisateurs pendant une certaine période de temps, dans ce cas 60 minutes) est supposée être de
250 000 utilisateurs. Le nombre d'utilisateurs virtuels (VU) compétitifs est inférieur à celui du CCU60 et les analystes ont suggéré qu'il peut être divisé en deux en toute sécurité. Arrondissez et acceptez
150 000 VU compétitifs.
Le nombre total de requêtes par seconde provient d'un jeu plutôt chargé:
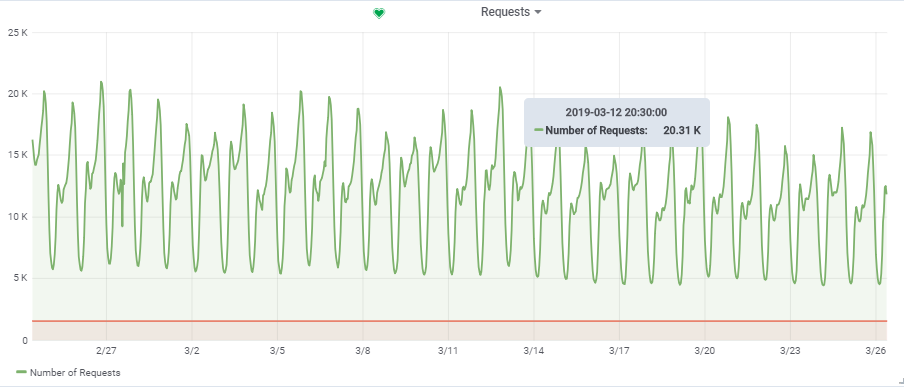
Ainsi, notre charge cible est de ~
20 000 requêtes / s à
150 000 VU.
La structure
Caractéristiques du «stand»
Dans un
article précédent
, j'ai déjà parlé de l'automatisation de l'ensemble du processus de test de charge. De plus, je vais peut-être me répéter un peu, mais je vais vous dire quelques points plus en détail.

Dans le diagramme, les carrés bleus sont nos hyperviseurs (HV), un nuage composé de nombreux serveurs (Dell M620 - M640). Sur chaque HV, une dizaine de machines virtuelles (VM) sont lancées via KVM (web / app et db dans le mix). Lors de la création d'une nouvelle machine virtuelle, l'équilibrage et la recherche dans l'ensemble des paramètres d'un HV approprié se produisent et on ne sait pas initialement sur quel serveur il sera.
Base de données (Game DB):
Mais pour notre objectif db1, nous avons réservé un
targer_hypervisor HV
séparé basé sur le M630.
Brève caractéristiques de targer_hypervisor:
Dell M_630
Nom du modèle: Intel® Xeon® CPU E5-2680 v3 @ 2.50GHz
Processeur (s): 48
Fil (s) par noyau: 2
Noyau (s) par socket: 12
Prise (s): 2
RAM: 128 Go
Debian GNU / Linux 9 (stretch)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
Spécifications détailléesDebian GNU / Linux 9 (stretch)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
lscpu
Architecture: x86_64
Mode (s) opérationnel (s) du processeur: 32 bits, 64 bits
Ordre des octets: Little Endian
Processeur (s): 48
Liste des processeurs en ligne: 0-47
Fil (s) par noyau: 2
Noyau (s) par socket: 12
Prise (s): 2
Nœud (s) NUMA: 2
ID du fournisseur: GenuineIntel
Famille de CPU: 6
Modèle: 63
Nom du modèle: Intel® Xeon® CPU E5-2680 v3 @ 2.50GHz
Étape: 2
CPU MHz: 1309.356
CPU max MHz: 3300,0000
CPU min MHz: 1200,0000
BogoMIPS: 4988.42
Virtualisation: VT-x
Cache L1d: 32 Ko
Cache L1i: 32 Ko
Cache L2: 256 Ko
Cache L3: 30720 Ko
NUMA node0 CPU (s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42 44,46
Processeur (s) NUMA node1: 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43 , 45,47
Drapeaux: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant qtsopmopcopts bts bts smx is TM2 SSSE3 SDBG fma CX16 xtpr PDCM PCID dca sse4_1 sse4_2 x2apic movbe POPCNT tsc_deadline_timer aes xsave AVX F16C rdrand lahf_lm abm EPB invpcid_single SSBD CCRI ibpb stibp kaiser tpr_shadow vnmi FlexPriority ept VPID fsgsbase tsc_adjust BMI1 AVX2 EPEOA bmi2 erms invpcid cqm xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts flush_l1d
/ usr / bin / qemu-system-x86_64 --version
Émulateur QEMU version 2.8.1 (Debian 1: 2.8 + dfsg-6 + deb9u5)
Copyright © 2003-2016 Fabrice Bellard et les développeurs du projet QEMU
Brève caractéristiques de db1:
Architecture: x86_64
Processeur (s): 48
RAM: 64 Go
4.9.0-8-amd64 # 1 SMP Debian 4.9.144-3.1 (2019-02-19) x86_64 GNU / Linux
Debian GNU / Linux 9 (stretch)
psql (PostgreSQL) 11.2 (Debian 11.2-1.pgdg90 + 1)
Configuration PostgreSQL avec quelques explicationsseq_page_cost = 1.0
random_page_cost = 1.1 # Nous avons un SSD
inclure «/etc/postgresql/11/main/extension.conf»
log_line_prefix = '% t [% p-% l]% q% u @% h'
log_checkpoints = on
log_lock_waits = on
log_statement = ddl
log_min_duration_statement = 100
log_temp_files = 0
autovacuum_max_workers = 5
autovacuum_naptime = 10s
autovacuum_vacuum_cost_delay = 20ms
vacuum_cost_limit = 2000
maintenance_work_mem = 128 Mo
synchronous_commit = off
checkpoint_timeout = 30min
listen_addresses = '*'
work_mem = 32 Mo
effective_cache_size = 26214 Mo # 50% de la mémoire disponible
shared_buffers = 16384 Mo # 25% de la mémoire disponible
max_wal_size = 15 Go
min_wal_size = 80 Mo
wal_level = hot_standby
max_wal_senders = 10
wal_compression = on
archive_mode = on
archive_command = '/ bin / true'
archive_timeout = 1800
hot_standby = on
wal_log_hints = on
hot_standby_feedback = on
hot_standby_feedback est
désactivé par défaut, nous l'avons allumé, mais il a dû être désactivé plus tard pour effectuer un test réussi. J'expliquerai plus tard pourquoi.
Les principales tables actives de la base de données (construction, production, game_entity, building, core_inventory_player_resource, survivor) sont préremplies de données (environ 80 Go) à l'aide d'un script bash.
Réplication:
SELECT * FROM pg_stat_replication; pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state -----+----------+---------+---------------------+--------------+---------------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------ 759 | 17035 | repmgr | xl1db2 | xxxx | xl1db2 | 51142 | 2019-01-27 08:56:44.581758+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000393 | 00:00:00.001159 | 00:00:00.001313 | 0 | async 977 | 17035 | repmgr | xl1db3 |xxxxx | xl1db3 | 42888 | 2019-01-27 08:57:03.232969+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000373 | 00:00:00.000798 | 00:00:00.000919 | 0 | async
Serveur d'application
Ensuite, sur des HV productifs (prod_hypervisors) de différentes configurations et capacités, 15 serveurs d'applications ont été lancés: 8 cœurs, 4 Go. La principale chose que l'on peut dire: openjdk 11.0.1 2018-10-16, printemps, interaction avec la base de données via
hikari (hikari.maximum-pool-size: 50)
Environnement de test de stress
L'ensemble de l'environnement de test de charge se compose d'un serveur principal
admin.loadtest et de plusieurs serveurs
generatorN.loadtest (dans ce cas, il y en avait 14).
generatorN.loadtest - VM «brute» Debian Linux 9, avec Java 8. installé 32 noyaux / 32 gigaoctets. Ils sont situés sur des HV non productifs afin de ne pas tuer accidentellement les performances des VM importantes.
admin.loadtest -
Machine virtuelle Debian Linux 9, 16 cœurs / 16 concerts, il exécute Jenkins, JLTC et d'autres logiciels supplémentaires sans importance.
JLTC -
centre de test de charge jmeter . Un système en Py / Django qui contrôle et automatise le lancement des tests, ainsi que l'analyse des résultats.
Schéma de lancement du test

Le processus d'exécution du test ressemble à ceci:
- Le test est lancé depuis Jenkins . Sélectionnez le Job requis, puis vous devez entrer les paramètres de test souhaités:
- DURATION - durée du test
- RAMPUP - temps «d'échauffement»
- THREAD_COUNT_TOTAL - le nombre souhaité d'utilisateurs virtuels (VU) ou de threads
- TARGET_RESPONSE_TIME est un paramètre important, afin de ne pas surcharger l'ensemble du système à l'aide de celui-ci, nous définissons le temps de réponse souhaité.En conséquence, le test maintiendra la charge à un niveau auquel le temps de réponse de l'ensemble du système ne sera pas supérieur à celui spécifié.
- Lancement
- Jenkins clone le plan de test de Gitlab, l'envoie à JLTC.
- JLTC fonctionne un peu avec un plan de test (par exemple, insère un écrivain simple CSV).
- JLTC calcule le nombre requis de serveurs Jmeter pour exécuter le nombre souhaité de VU (THREAD_COUNT_TOTAL).
- JLTC se connecte à chaque générateur de loadgeneratorN et démarre le serveur jmeter.
Pendant le test, le
client JMeter génère un fichier CSV avec les résultats. Ainsi, pendant le test, la quantité de données et la taille de ce fichier augmentent à un rythme
insensé , et il ne peut pas être utilisé pour l'analyse après le test -
Daemon a été inventé (comme une expérience), qui l'analyse
«à la volée» .
Plan de test
Vous pouvez télécharger le plan de test
ici .
Après l'enregistrement / la connexion, les utilisateurs travaillent dans le module
Comportement , qui se compose de plusieurs
contrôleurs de débit qui spécifient la probabilité d'une fonction de jeu particulière. Dans chaque contrôleur de débit, il existe un
contrôleur de module , qui fait référence au module correspondant qui implémente la fonction.
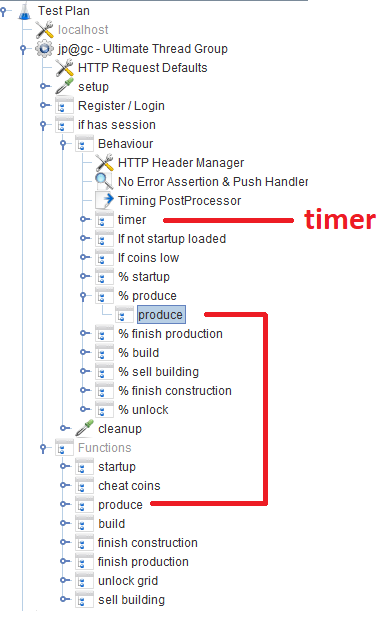
Hors sujet
Pendant le développement du script, nous avons essayé d'utiliser Groovy au maximum, et grâce à notre programmeur Java, j'ai découvert quelques astuces pour moi-même (peut-être que cela sera utile pour quelqu'un):
VU / Threads
Lorsqu'un utilisateur entre le nombre souhaité de VU à l'aide du paramètre THREAD_COUNT_TOTAL lors de la configuration du travail dans Jenkins, il est nécessaire de démarrer le nombre requis de serveurs Jmeter et de répartir le nombre final de VU entre eux. Cette partie appartient au JLTC dans la partie appelée
contrôleur / provision .
Essentiellement, l'algorithme est le suivant:
- Nous divisons le nombre souhaité de threads VU_num en 200-300 threads et en fonction de la taille plus ou moins adéquate -Xmsm -Xmxm, nous déterminons la valeur de mémoire requise pour un serveur jmeter required_memory_for_jri (JRI - j'appelle l'instance distante Jmeter, au lieu de Jmeter-server).
- De threads_num et required_memory_for_jri nous trouvons le nombre total de jmeter-server: target_amount_jri et la valeur totale de la mémoire requise : required_memory_total .
- Nous trions tous les générateurs de loadgeneratorN un par un et démarrons le nombre maximum de serveurs jmeter en fonction de la mémoire disponible. Tant que le nombre d'instances de current_amount_jri en cours d'exécution n'est pas égal à target_amount_jri.
- (Si le nombre de générateurs et la mémoire totale ne suffisent pas, ajoutez-en un nouveau dans le pool)
- Nous nous connectons à chaque générateur, en utilisant netstat, nous nous souvenons de tous les ports occupés, et nous exécutons sur des ports aléatoires (qui sont inoccupés) le nombre requis de serveurs jmeter:
netstat_cmd= 'netstat -tulpn | grep LISTEN' stdin, stdout, stderr = ssh.exec_command(cmd1) used_ports = [] netstat_output = str(stdout.readlines()) ports = re.findall('\d+\.\d+\.\d+\.\d+\:(\d+)', netstat_output) ports_ipv6 = re.findall('\:\:\:(\d+)', netstat_output) p.wait() for port in ports: used_ports.append(int(port)) for port in ports_ipv6: used_ports.append(int(port)) ssh.close() for i in range(1, possible_jris_on_host + 1): port = int(random.randint(10000, 20000)) while port in used_ports: port = int(random.randint(10000, 20000))
- Nous collectons tous les serveurs jmeter en cours d'exécution en une seule fois au format adresse: port, par exemple générateur13: 15576, générateur9: 14015, générateur11: 19152, générateur14: 12125, générateur2: 17602
- La liste résultante et threads_per_host sont envoyés au client JMeter lorsque le test démarre:
REMOTE_TESTING_FLAG=" -R $REMOTE_HOSTS_STRING" java -jar -Xms7g -Xmx7g -Xss228k $JMETER_DIR/bin/ApacheJMeter.jar -Jserver.rmi.ssl.disable=true -n -t $TEST_PLAN -j $WORKSPACE/loadtest.log -GTHREAD_COUNT=$THREADS_PER_HOST $OTHER_VARS $REMOTE_TESTING_FLAG -Jjmeter.save.saveservice.default_delimiter=,
Dans notre cas, le test a eu lieu simultanément à partir de 300 serveurs Jmeter, 500 threads chacun, le format de lancement d'un serveur Jmeter avec des paramètres Java ressemblait à ceci:
nohup java -server -Xms1200m -Xmx1200m -Xss228k -XX:+DisableExplicitGC -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ScavengeBeforeFullGC -XX:+CMSScavengeBeforeRemark -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Stack=false -jar "/tmp/jmeter-JwKse5nY/bin/ApacheJMeter.jar" -Jserver.rmi.ssl.disable=true "-Djava.rmi.server.hostname=generator12.loadtest.ig.local" -Duser.dir=/tmp/jmeter-JwKse5nY/bin/ -Dserver_port=13114 -s -Jpoll=49 > /dev/null 2>&1
50ms
La tâche consiste à déterminer dans quelle mesure notre base de données peut supporter, plutôt que de la surcharger et l'ensemble du système dans un état critique. Avec autant de serveurs Jmeter, vous devez en quelque sorte maintenir la charge à un certain niveau et ne pas tuer tout le système. Le paramètre
TARGET_RESPONSE_TIME spécifié lors du démarrage du test en est responsable. Nous avons convenu que
50 ms est le temps de réponse optimal dont le système devrait être responsable.
Dans JMeter, par défaut, il existe de nombreux temporisateurs différents qui vous permettent de contrôler le débit, mais on ne sait pas où l'obtenir dans notre cas. Mais il y a
JSR223-Timer avec lequel vous pouvez trouver quelque chose en utilisant le
temps de réponse du système
actuel . Le temporisateur lui-même est dans le bloc de
comportement principal:

Analyse des résultats (démon)
En plus des graphiques dans Grafana, il est également nécessaire d'avoir des résultats de test agrégés afin que les tests puissent ensuite être comparés dans JLTC.
Un tel test génère 16 000 à 20 000 requêtes par seconde, il est facile de calculer qu'en 4 heures, il génère un fichier CSV de quelques centaines de Go, il était donc nécessaire de créer un travail qui analyse les données toutes les minutes, les envoie à la base de données et nettoie le fichier principal.
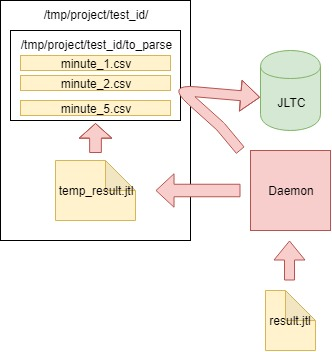
L'algorithme est le suivant:
- Nous lisons les données du fichier CSV result.jtl généré par le client jmeter, l'enregistrons et nettoyons le fichier (vous devez le nettoyer correctement, sinon le fichier vide aura le même FD avec la même taille):
with open(jmeter_results_file, 'r+') as f: rows = f.readlines() f.seek(0) f.truncate(0) f.writelines(rows[-1])
- Nous écrivons les données lues dans le fichier temporaire temp_result.jtl :
rows_num = len(rows) open(temp_result_filename, 'w').writelines(rows[0:rows_num])
- Nous lisons le fichier temp_result.jtl . Nous distribuons les données lues "en quelques minutes":
for r in f.readlines(): row = r.split(',') if len(row[0]) == 13: ts_c = int(row[0]) dt_c = datetime.datetime.fromtimestamp(ts_c/1000) minutes_data.setdefault(dt_c.strftime('%Y_%m_%d_%H_%M'), []).append(r)
- Les données pour chaque minute de minutes_data sont écrites dans le fichier correspondant dans le dossier to_parse / . (ainsi, pour le moment, chaque minute du test a son propre fichier de données, puis lors de l'agrégation , peu importe l'ordre dans lequel les données sont entrées dans chaque fichier):
for key, value in minutes_data.iteritems():
- En cours de route, nous analysons les fichiers dans le dossier to_parse et si l'un d'eux n'a pas changé en une minute, ce fichier est un candidat pour l'analyse des données, l'agrégation et l'envoi à la base de données JLTC:
for filename in os.listdir(temp_to_parse_path): data_file = os.path.join(temp_to_parse_path, filename) file_mod_time = os.stat(data_file).st_mtime last_time = (time.time() - file_mod_time) if last_time > 60: logger.info('[DAEMON] File {} was not modified since 1min, adding to parse list.'.format(data_file)) files_to_parse.append(data_file)
- S'il existe de tels fichiers (un ou plusieurs), alors nous les envoyons analysés à la fonction parse_csv_data (chaque fichier en parallèle):
for f in files_to_parse: logger.info('[DAEMON THREAD] Parse {}.'.format(f)) t = threading.Thread( target=parse_csv_data, args=( f, jmeter_results_file_fields, test, data_resolution)) t.start() threads.append(t) for t in threads: t.join()
Le démon lui-même dans cron.d démarre chaque minute:
le démon démarre chaque minute avec cron.d:
* * * * * root sleep 21 && /usr/bin/python /var/lib/jltc/manage.py daemon
Ainsi, le fichier avec les résultats ne gonfle pas à des tailles inconcevables, mais est analysé
à la volée et effacé.
Résultats
L'appli
Nos 150 000 joueurs virtuels:

Le test tente de «faire correspondre» le temps de réponse de 50 ms, de sorte que la charge elle-même saute constamment dans la région entre 16 000 et 18 000 requêtes / c:
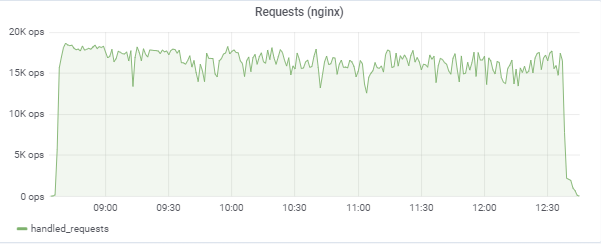
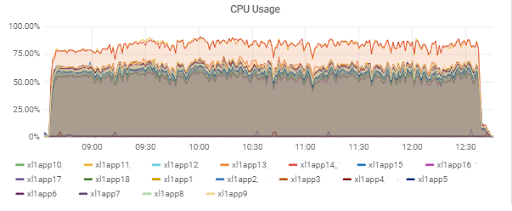
Charge du serveur d'applications (15 applications). Deux serveurs sont «malchanceux» d'être sur le M620 plus lent:
Temps de réponse de la base de données (pour les serveurs d'applications):

Base de données
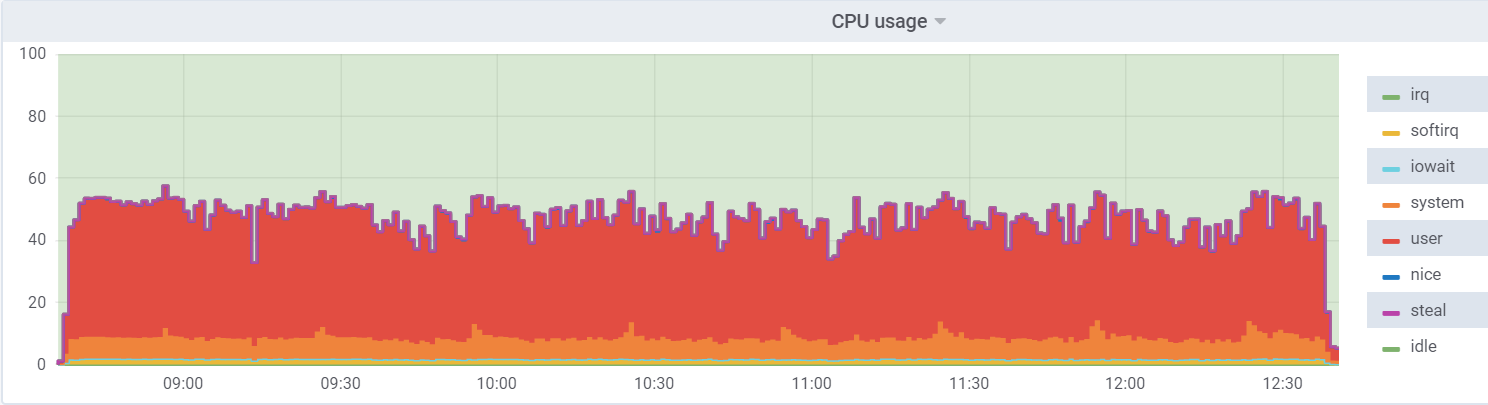
Utilisation du processeur sur db1 (VM):
Utilisation du processeur sur l'hyperviseur:
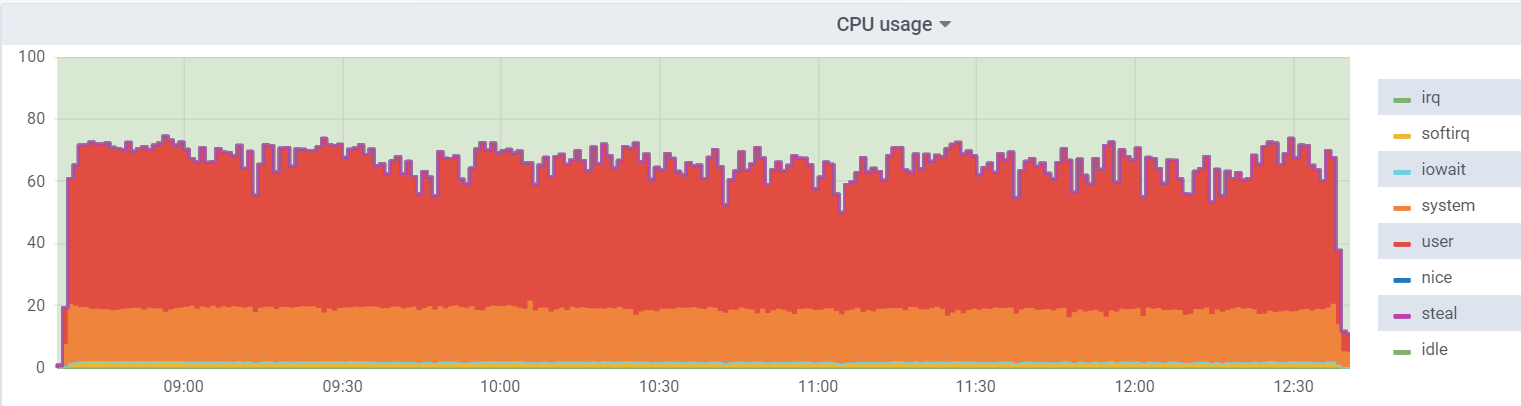
La charge sur la machine virtuelle est plus faible, car elle estime qu'elle dispose de 48 cœurs réels, en fait, il y a 24 cœurs
hyperthreading sur l'hyperviseur.
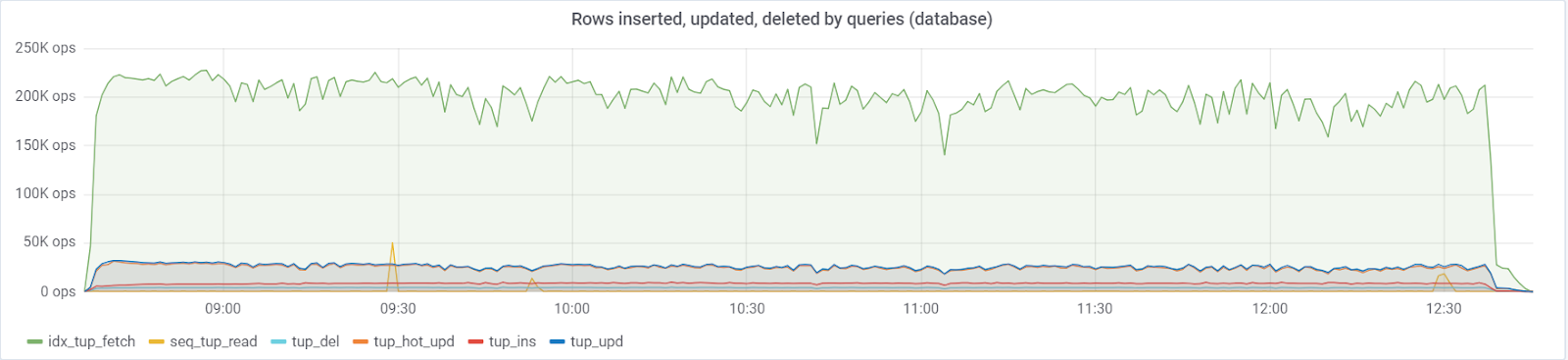
Un
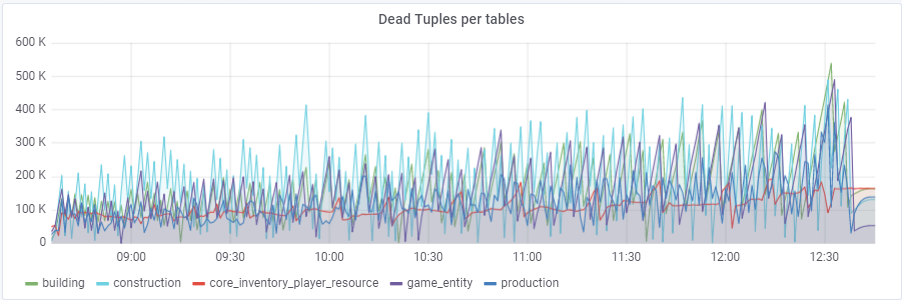
maximum de ~ 250 000 requêtes / s va à la base de données, composée de (83% de sélections, 3% - insertions, 11,6% - mises à jour (90% HOT), 1,6% suppressions):

Avec une valeur par défaut
autovacuum_vacuum_scale_factor = 0,2, le nombre de tuples morts a augmenté très rapidement avec le test (avec l'augmentation de la taille des tables), ce qui a conduit plusieurs fois à de courts problèmes de performances de la base de données qui ont ruiné plusieurs fois l'ensemble du test. J'ai dû «apprivoiser» cette croissance pour certaines tables en attribuant des valeurs personnelles à ce paramètre autovacuum_vacuum_scale_factor:
ALTER TABLE ... SET (autovacuum_vacuum_scale_factor = ...)ALTER TABLE construction SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE production SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE building SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE building SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE core_inventory_player_resource SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE survivor SET (autovacuum_vacuum_scale_factor = 0,01);
ALTER TABLE survivor SET (autovacuum_analyze_scale_factor = 0.01);
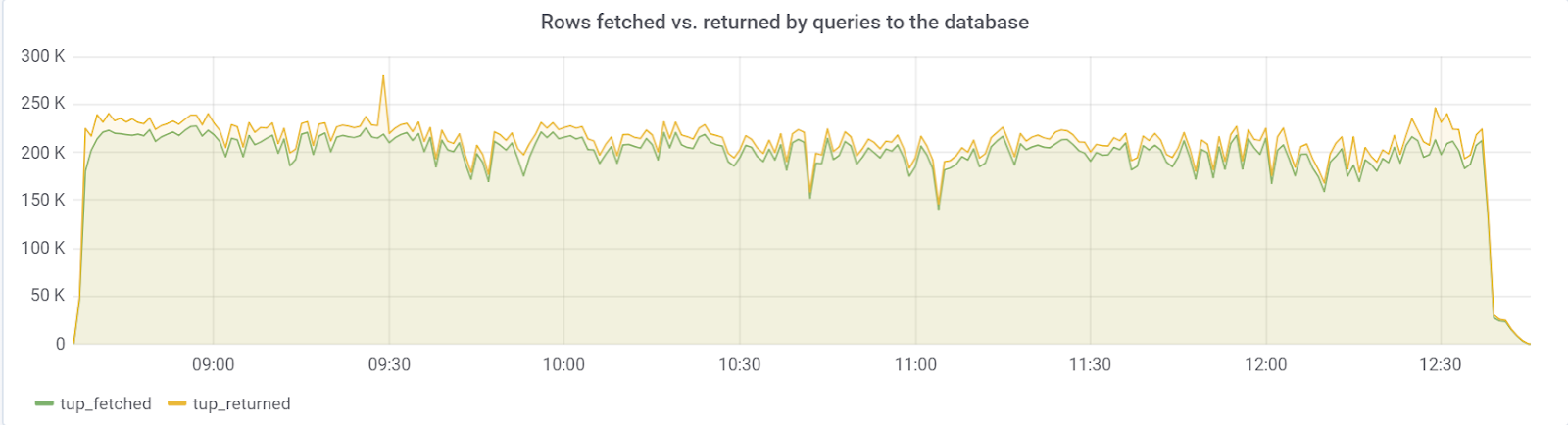
Idéalement, row_fetched devrait être proche de row_returned, ce que nous observons heureusement:
hot_standby_feedback
Le problème
venait du paramètre
hot_standby_feedback , qui peut considérablement affecter les performances du serveur
principal si ses serveurs de
secours n'ont pas le temps d'appliquer les modifications des fichiers WAL. La documentation (https://postgrespro.ru/docs/postgrespro/11/runtime-config-replication) indique qu'elle «détermine si le serveur de secours à chaud notifiera le maître ou l'esclave supérieur des demandes qu'il exécute actuellement». Par défaut, il est désactivé, mais il a été activé dans notre configuration. Ce qui a entraîné de tristes conséquences, s'il y a 2 serveurs de secours et que le décalage de réplication pendant le chargement est différent de zéro (pour diverses raisons), vous pouvez observer une telle image, ce qui peut conduire à l'effondrement de l'ensemble du test:
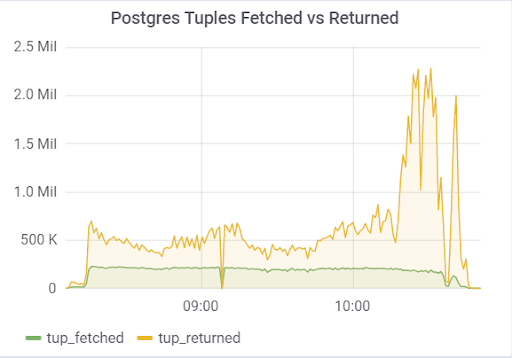

Cela est dû au fait que lorsque hot_standby_feedback est activé, VACUUM ne souhaite pas supprimer les tuples «morts» si les serveurs de secours sont en retard dans leur ID de transaction pour éviter les conflits de réplication. Article détaillé
Ce que fait vraiment hot_standby_feedback dans PostgreSQL :
xl1_game=# VACUUM VERBOSE core_inventory_player_resource; INFO: vacuuming "public.core_inventory_player_resource" INFO: scanned index "core_inventory_player_resource_pkey" to remove 62869 row versions DETAIL: CPU: user: 1.37 s, system: 0.58 s, elapsed: 4.20 s ………... INFO: "core_inventory_player_resource": found 13682 removable, 7257082 nonremovable row versions in 71842 out of 650753 pages <b>DETAIL: 3427824 dead row versions cannot be removed yet, oldest xmin: 3810193429</b> There were 1920498 unused item pointers. Skipped 8 pages due to buffer pins, 520953 frozen pages. 0 pages are entirely empty. CPU: user: 4.55 s, system: 1.46 s, elapsed: 11.74 s.
Un si grand nombre de tuples morts mène à l'image ci-dessus. Voici deux tests, avec hot_standby_feedback activé et désactivé:
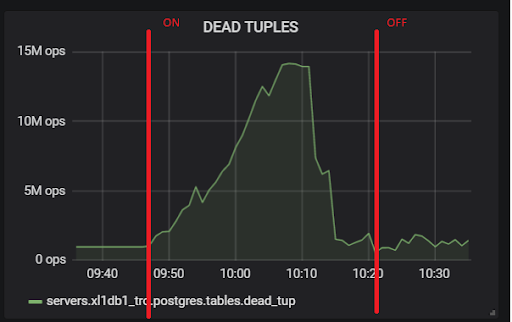
Et c'est notre retard de réplication pendant le test, avec lequel il sera nécessaire de faire quelque chose à l'avenir:
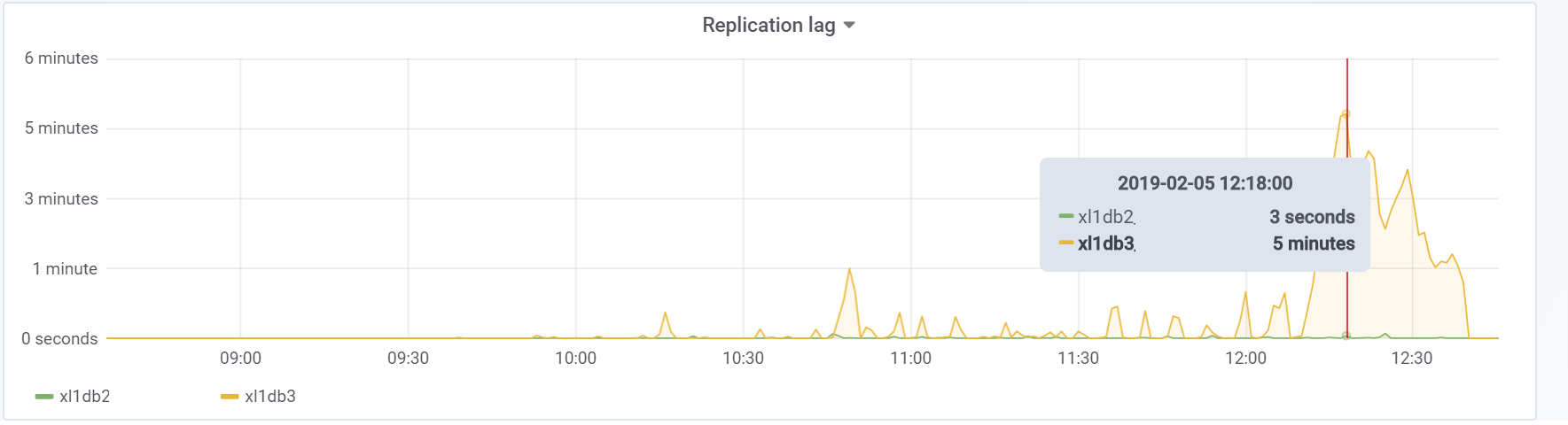
Conclusion
Ce test, heureusement (ou malheureusement pour le contenu de l'article) a montré qu'à ce stade du prototype du jeu, il est tout à fait possible d'absorber la charge souhaitée de la part des utilisateurs, ce qui est suffisant pour donner le feu vert pour la poursuite du prototypage et du développement. Dans les étapes ultérieures du développement, il est nécessaire de suivre les règles de base (pour garder la simplicité des requêtes exécutées, pour éviter une surabondance d'index, ainsi que des lectures non indexées, etc.) et surtout, tester le projet à chaque étape importante du développement pour trouver et résoudre les problèmes comme peut être plus tôt. Peut-être bientôt, j'écrirai un article car nous avons déjà résolu des problèmes spécifiques.
Bonne chance à tous!
Notre
GitHub au cas où;)