
La base de données de séries chronologiques (TSDB) dans Prometheus 2 est un excellent exemple d'une solution d'ingénierie qui offre des améliorations majeures par rapport au stockage v2 dans Prometheus 1 en termes de vitesse de stockage des données et d'exécution des requêtes, d'efficacité des ressources. Nous avons implémenté Prometheus 2 dans Percona Monitoring and Management (PMM), et j'ai eu l'occasion de comprendre les performances de Prometheus 2 TSDB. Dans cet article, je parlerai des résultats de ces observations.
Charge de travail moyenne de Prometheus
Pour ceux qui sont habitués à gérer des bases de données primaires, la charge de travail régulière de Prometheus est assez curieuse. La vitesse d'accumulation des données tend vers une valeur stable: généralement, les services que vous surveillez envoient environ le même nombre de métriques, et l'infrastructure change relativement lentement.
Les demandes d'informations peuvent provenir de différentes sources. Certains d'entre eux, comme les alertes, recherchent également une valeur stable et prévisible. D'autres, comme les requêtes des utilisateurs, peuvent provoquer des pics, bien que cela ne soit pas typique de la plupart de la charge.
Test de charge
Pendant les tests, je me suis concentré sur la capacité à accumuler des données. J'ai déployé Prometheus 2.3.2 compilé avec Go 1.10.1 (dans le cadre de PMM 1.14) sur le service Linode en utilisant ce script:
StackScript . Pour la génération de charge la plus réaliste, en utilisant ce
StackScript, j'ai lancé plusieurs nœuds MySQL avec une charge réelle (Sysbench TPC-C Test), chacun émulant 10 nœuds Linux / MySQL.
Tous les tests suivants ont été effectués sur un serveur Linode avec huit cœurs virtuels et 32 Go de mémoire, sur lequel 20 simulations de charge de surveillance de deux cents instances MySQL ont été lancées. Ou, en termes de Prométhée, 800 cibles, 440 éraflures par seconde, 380 000 échantillons par seconde et 1,7 million de séries chronologiques actives.
La conception
L'approche habituelle des bases de données traditionnelles, y compris celle utilisée par Prometheus 1.x, est
la limite de mémoire . S'il ne suffit pas de supporter la charge, vous rencontrerez des retards importants et certaines demandes ne seront pas satisfaites.
L'utilisation de la mémoire dans Prometheus 2 est configurée à l'aide de la clé
storage.tsdb.min-block-duration , qui détermine la durée pendant laquelle les enregistrements seront stockés en mémoire avant le vidage sur le disque (par défaut, il s'agit de 2 heures). La quantité de mémoire nécessaire dépendra du nombre de séries chronologiques, d'étiquettes et de l'intensité de la collecte de données (scrap) au total avec le flux d'entrée net. En termes d'espace disque, Prometheus vise à utiliser 3 octets par enregistrement (échantillon). En revanche, les besoins en mémoire sont beaucoup plus élevés.
Malgré le fait qu'il est possible de configurer la taille du bloc, il n'est pas recommandé de le configurer manuellement, vous êtes donc confronté à la nécessité de donner à Prometheus autant de mémoire qu'il le demande pour votre charge.
S'il n'y a pas assez de mémoire pour prendre en charge le flux de métriques entrant, Prometheus tombera de mémoire ou le tueur OOM l'atteindra.
L'ajout de swap pour retarder le crash lorsque Prometheus manque de mémoire n'aide pas vraiment, car l'utilisation de cette fonctionnalité entraîne une consommation de mémoire explosive. Je pense que le truc c'est Go, son garbage collector et comment ça marche avec swap.
Une autre approche intéressante consiste à définir le bloc de tête pour qu'il soit réinitialisé sur le disque à un moment précis, au lieu de le compter dès le début du processus.
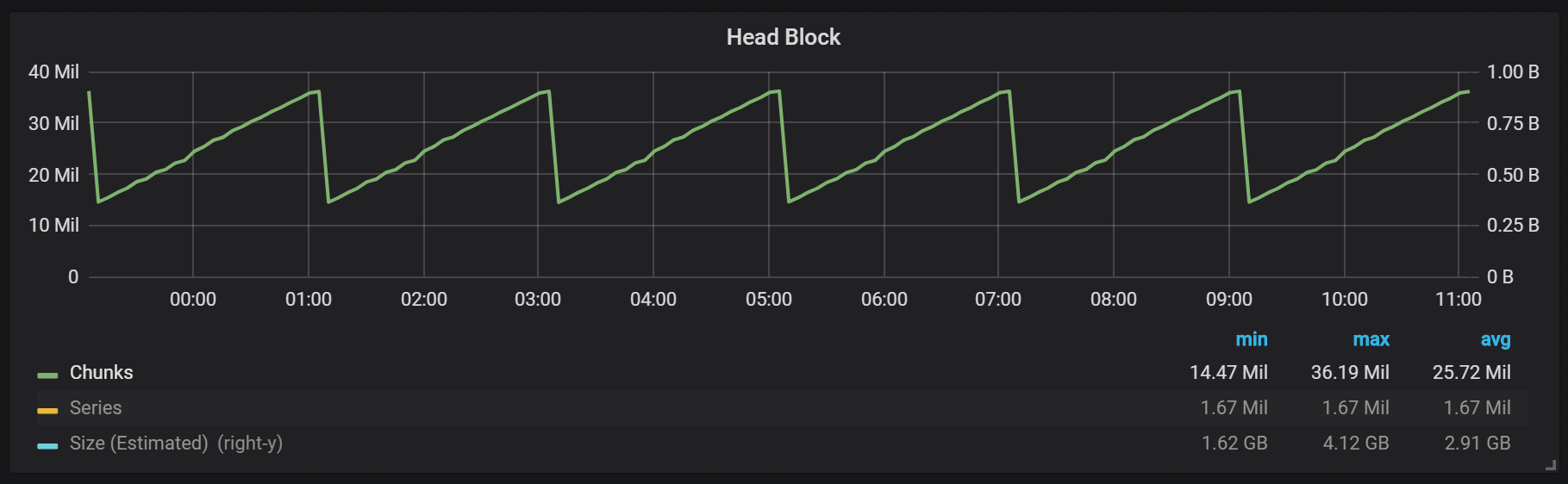
Comme vous pouvez le voir sur le graphique, les vidages de disque se produisent toutes les deux heures. Si vous modifiez le paramètre de durée minimale de bloc à une heure, ces décharges se produisent toutes les heures, en commençant dans une demi-heure.
Si vous souhaitez utiliser ceci et d'autres graphiques dans votre installation Prometheus, vous pouvez utiliser ce tableau de bord . Il a été développé pour PMM, mais, avec des modifications mineures, convient à toute installation de Prometheus.Nous avons un bloc actif appelé bloc de tête, qui est stocké en mémoire; les blocs contenant des données plus anciennes sont accessibles via
mmap() . Cela élimine la nécessité de configurer le cache séparément, mais signifie également que vous devez laisser suffisamment d'espace pour le cache du système d'exploitation si vous souhaitez effectuer des demandes de données plus anciennes que le bloc principal.
Cela signifie également que la consommation de mémoire virtuelle Prometheus sera assez élevée, ce qui ne vaut pas la peine de s'inquiéter.

Un autre point de conception intéressant est l'utilisation de WAL (écriture anticipée du journal). Comme vous pouvez le voir dans la documentation de stockage, Prometheus utilise WAL pour éviter les pertes dues aux chutes. Les mécanismes spécifiques pour assurer la survie des données, malheureusement, ne sont pas bien documentés. La version 2.3.2 de Prometheus vide le WAL sur le disque toutes les 10 secondes, et ce paramètre n'est pas configurable par l'utilisateur.
Joints (compactages)
Prometheus TSDB est conçu à l'image d'un référentiel LSM (Log Structured Merge - une arborescence structurée de journaux avec fusion): le bloc de tête est périodiquement vidé sur le disque, tandis que le mécanisme de compression combine plusieurs blocs ensemble pour empêcher l'analyse de trop de blocs lors des requêtes. Ici, vous pouvez voir le nombre de blocs que j'ai observés sur le système de test après une journée de travail.
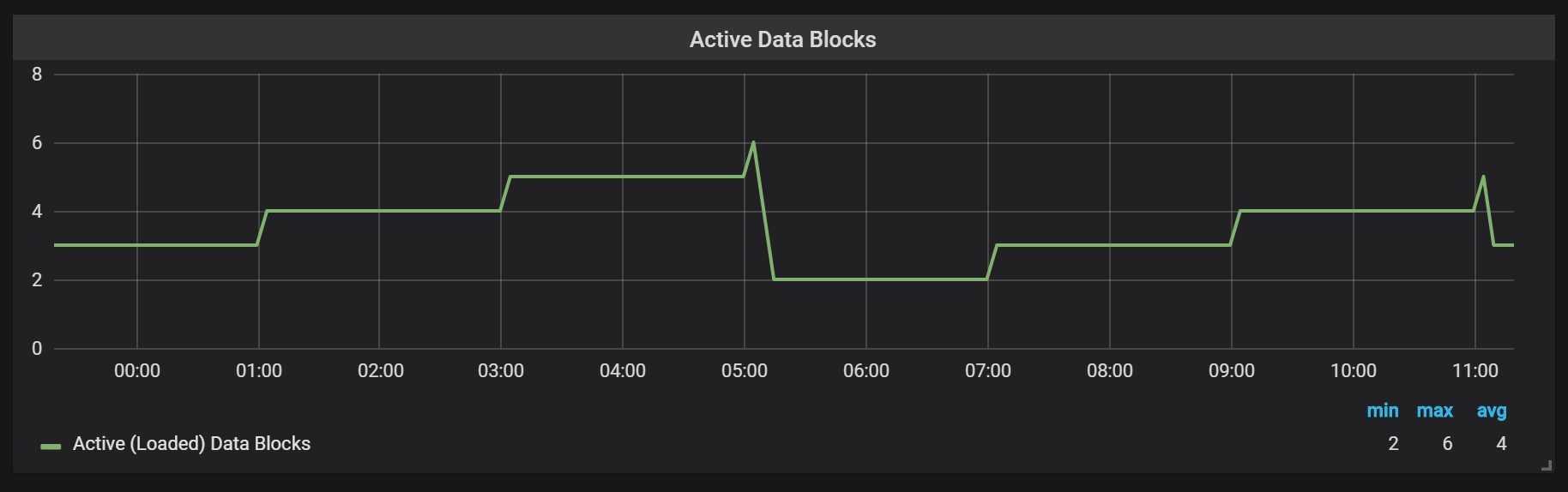
Si vous souhaitez en savoir plus sur le référentiel, vous pouvez étudier le fichier meta.json, qui contient des informations sur les blocs disponibles et leur apparence.
{ "ulid": "01CPZDPD1D9R019JS87TPV5MPE", "minTime": 1536472800000, "maxTime": 1536494400000, "stats": { "numSamples": 8292128378, "numSeries": 1673622, "numChunks": 69528220 }, "compaction": { "level": 2, "sources": [ "01CPYRY9MS465Y5ETM3SXFBV7X", "01CPYZT0WRJ1JB1P0DP80VY5KJ", "01CPZ6NR4Q3PDP3E57HEH760XS" ], "parents": [ { "ulid": "01CPYRY9MS465Y5ETM3SXFBV7X", "minTime": 1536472800000, "maxTime": 1536480000000 }, { "ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ", "minTime": 1536480000000, "maxTime": 1536487200000 }, { "ulid": "01CPZ6NR4Q3PDP3E57HEH760XS", "minTime": 1536487200000, "maxTime": 1536494400000 } ] }, "version": 1 }
Les phoques de Prométhée sont liés au moment où un bloc de tête a été vidé sur le disque. À ce stade, plusieurs de ces opérations peuvent être effectuées.
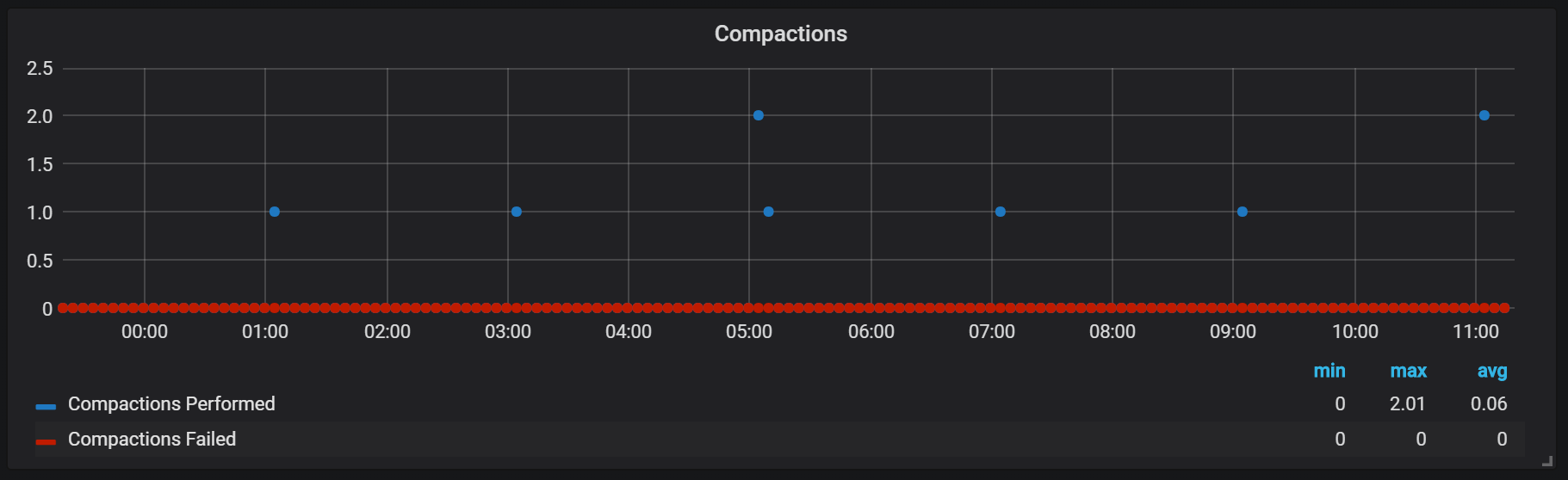
Apparemment, les scellés sont illimités de quelque manière que ce soit et peuvent provoquer de grands sauts d'E / S disque lors de l'exécution.

Pointes de téléchargement du processeur

Bien sûr, cela affecte négativement la vitesse du système, et est également un sérieux défi pour le stockage LSM: comment créer des scellés pour prendre en charge des vitesses de requête élevées et ne pas causer trop de surcharge?
L'utilisation de la mémoire dans le processus de compactage semble également très intéressante.

Nous pouvons voir comment, après le compactage, la plupart de la mémoire change d'état de Cached à Free: cela signifie que des informations potentiellement précieuses ont été supprimées de là. Il est curieux de savoir si
fadvice() ou une autre technique de minimisation est utilisée ici, ou est-ce dû au fait que le cache a été libéré des blocs détruits lors du compactage?
Récupération après incident
La reprise après sinistre prend du temps et elle est justifiée. Pour un flux entrant d'un million d'enregistrements par seconde, j'ai dû attendre environ 25 minutes pendant la restauration en tenant compte du disque SSD.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)" level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)" level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))" level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)" level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090 level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..." level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0 level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363 level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started" level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."
Le principal problème du processus de récupération est une consommation élevée de mémoire. Malgré le fait que dans une situation normale, le serveur peut fonctionner de manière stable avec la même quantité de mémoire, lorsqu'il se bloque, il peut ne pas augmenter en raison de MOO. La seule solution que j'ai trouvée était de désactiver la collecte de données, d'augmenter le serveur, de lui permettre de récupérer et de redémarrer avec la collection déjà activée.
Réchauffer
Un autre comportement dont il faut se souvenir pendant l'échauffement est le rapport entre une faible productivité et une consommation élevée de ressources juste après le démarrage. Pendant certains démarrages, mais pas tous, j'ai observé une charge sérieuse sur le processeur et la mémoire.
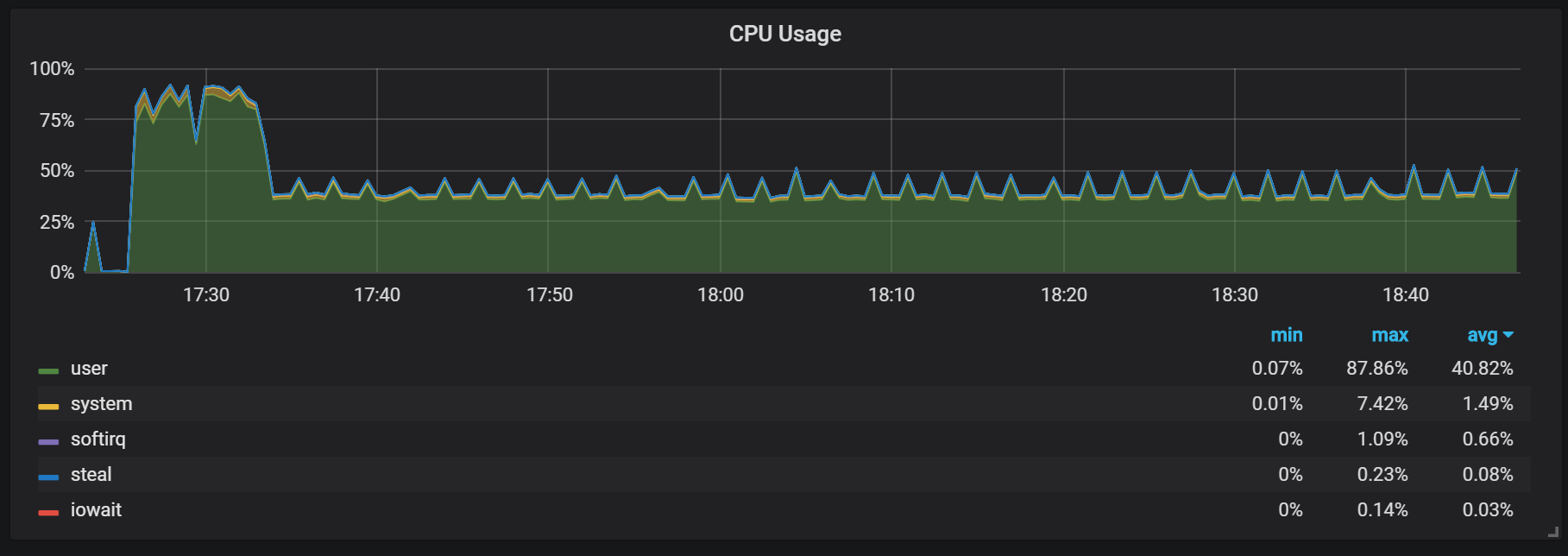

Les pertes de mémoire indiquent que Prometheus ne peut pas configurer tous les frais dès le départ et que certaines informations sont perdues.
Je n'ai pas trouvé les raisons exactes de la charge élevée sur le processeur et la mémoire. Je soupçonne que cela est dû à la création de nouvelles séries temporelles dans le bloc de tête avec une fréquence élevée.
Pics de charge CPU
En plus des joints, qui créent une charge d'E / S assez élevée, j'ai remarqué de sérieux sauts de charge sur le processeur toutes les deux minutes. Les rafales durent plus longtemps avec un flux entrant élevé et il semble qu'elles soient causées par le garbage collector Go, au moins certains noyaux sont entièrement chargés.

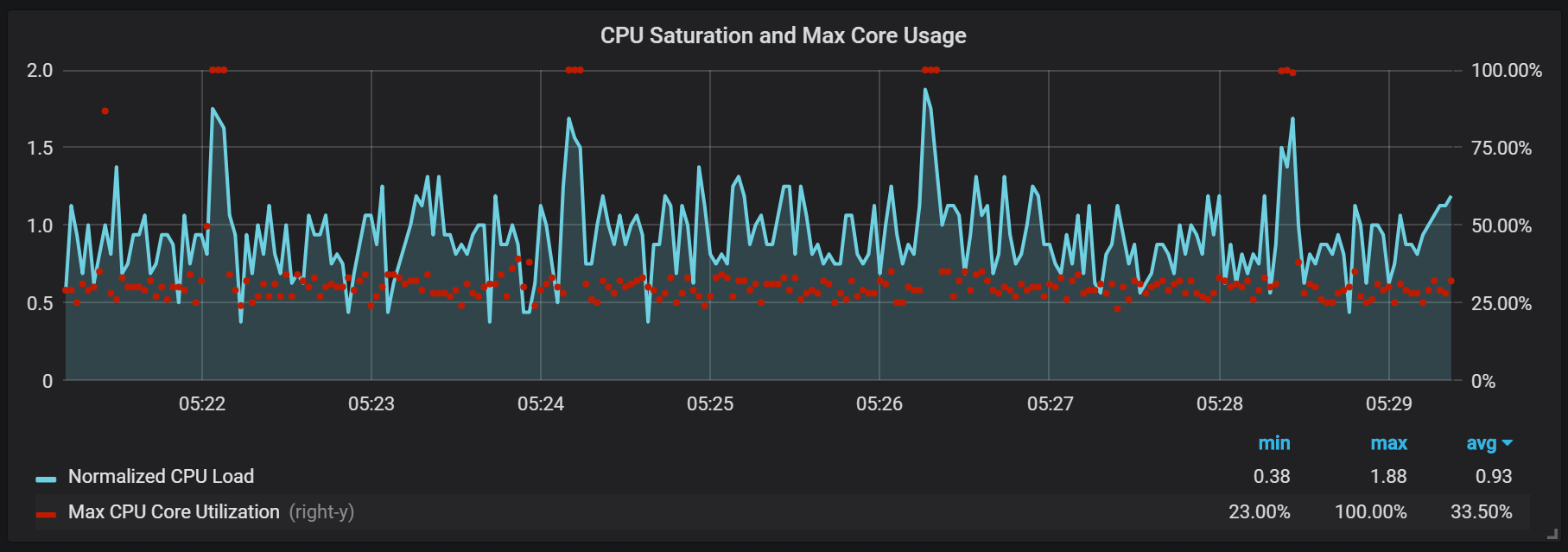
Ces sauts ne sont pas si insignifiants. Il semble que lorsqu'ils se produisent, le point d'entrée interne et les métriques Prometheus deviennent inaccessibles, ce qui entraîne des lacunes dans les données aux mêmes intervalles de temps.
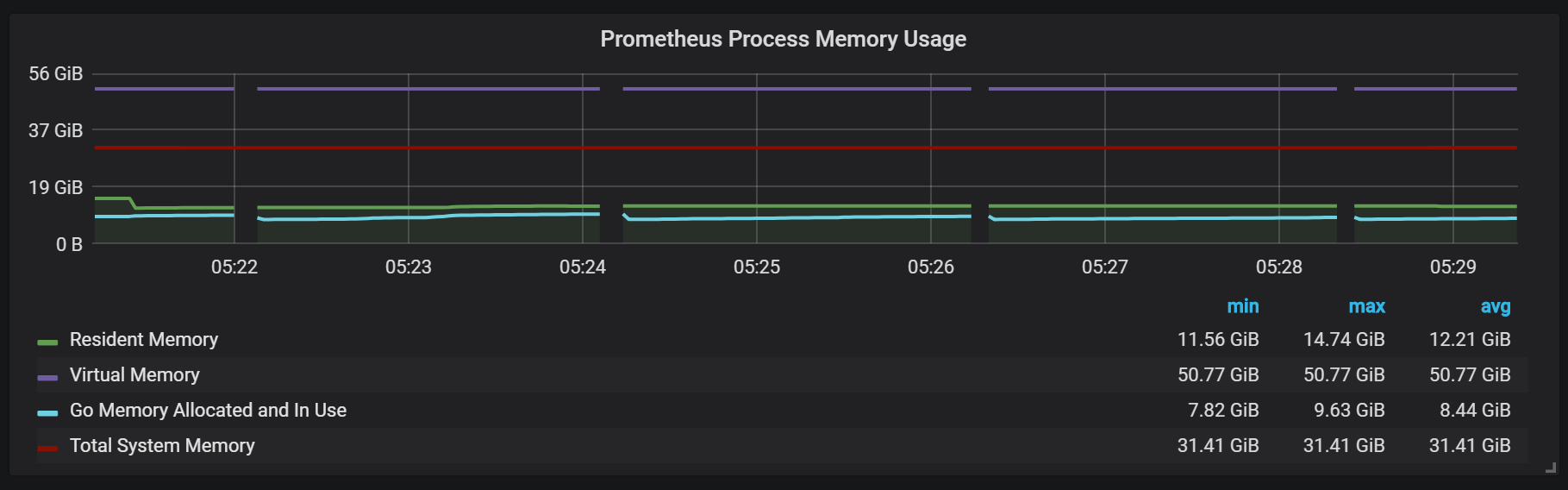
Vous pouvez également remarquer que l'exportateur Prometheus se ferme pendant une seconde.
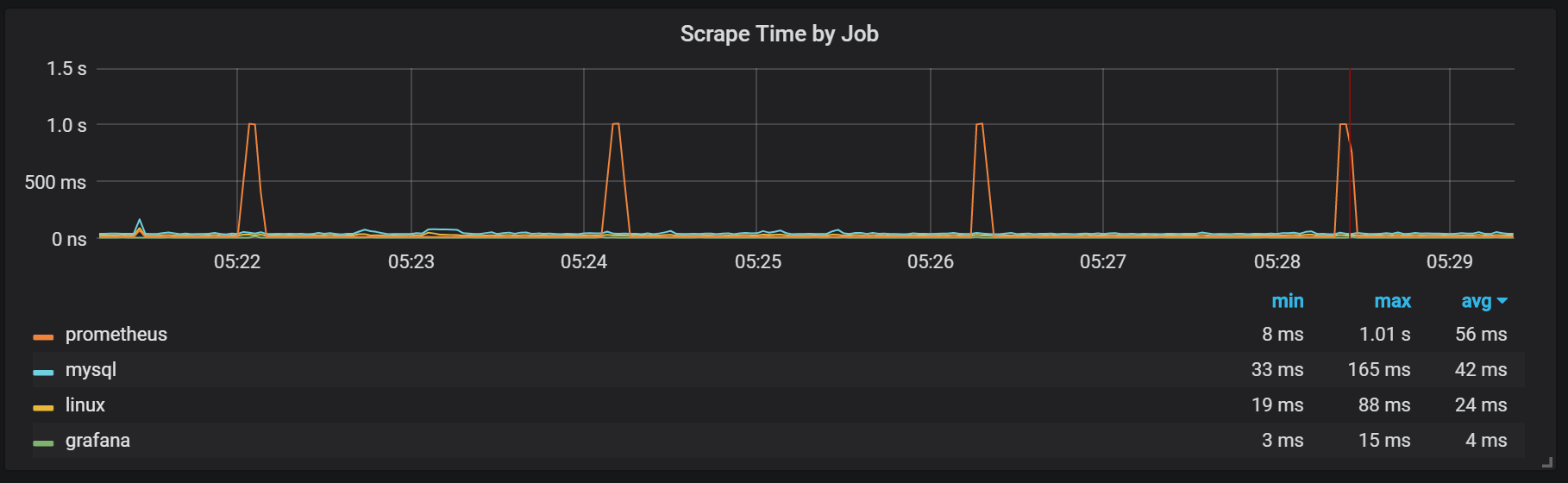
Nous pouvons voir des corrélations avec le garbage collection (GC).

Conclusion
TSDB dans Prometheus 2 est rapide, capable de gérer des millions de séries chronologiques et en même temps avec des milliers d'enregistrements par seconde en utilisant un matériel assez modeste. L'utilisation du processeur et des E / S disque est également impressionnante. Mon exemple a montré jusqu'à 200 000 métriques par seconde par cœur utilisé.
Pour planifier l'extension, vous devez vous rappeler des volumes de mémoire suffisants, et cela devrait être de la mémoire réelle. La quantité de mémoire utilisée que j'ai observée était d'environ 5 Go pour 100 000 entrées par seconde du flux entrant, ce qui, combiné au cache du système d'exploitation, représentait environ 8 Go de mémoire occupée.
Bien sûr, il reste encore beaucoup de travail pour apprivoiser les rafales d'E / S de processeur et de disque, et cela n'est pas surprenant étant donné la jeunesse du TSDB Prometheus 2 par rapport à InnoDB, TokuDB, RocksDB, WiredTiger, mais ils ont tous eu des problèmes similaires au début du cycle de vie.