
La logique des machines est impeccable, elles ne font pas d'erreurs si leur algorithme fonctionne correctement et les paramètres réglés correspondent aux normes nécessaires. Demandez à la voiture de choisir un itinéraire du point A au point B, et elle construira la plus optimale, en tenant compte de la distance, de la consommation de carburant, de la présence de stations-service, etc. Ceci est un pur calcul. La voiture ne dira pas: "Allons sur cette route, je ressens mieux cette route." Peut-être que les voitures sont meilleures que nous dans la vitesse des calculs, mais l'intuition est toujours l'un de nos atouts. L'humanité a passé des décennies à créer une machine semblable au cerveau humain. Mais y a-t-il tant de points communs entre eux? Aujourd'hui, nous examinerons une étude dans laquelle des scientifiques, doutant de la "vision" inégalée des machines sur la base de réseaux de neurones convolutifs, ont mené une expérience pour tromper un système de reconnaissance d'objets en utilisant un algorithme dont la tâche était de créer des images "fausses". Dans quelle mesure l'activité de sabotage de l'algorithme a-t-elle réussi, les gens ont-ils mieux géré la reconnaissance que les voitures et qu'est-ce que cette étude apportera à l'avenir de cette technologie? Nous trouverons des réponses dans le rapport des scientifiques. Allons-y.
Base d'étude
Les technologies de reconnaissance d'objets utilisant des réseaux de neurones convolutifs (SNS) permettent à la machine, en gros, de distinguer un cygne du nombre 9 ou un chat d'un vélo. Cette technologie se développe assez rapidement et est actuellement appliquée dans divers domaines, dont le plus évident est la production de véhicules sans pilote. Beaucoup sont d'avis que le SCN du système de reconnaissance des objets peut être considéré comme un modèle de vision humaine. Cependant, cette déclaration est trop forte, en raison du facteur humain. Le truc, c'est que tromper une voiture s'est avéré plus facile que de tromper une personne (du moins en matière de reconnaissance d'objets). Les systèmes SNA sont très vulnérables aux effets d'algorithmes malveillants (hostiles, si vous le souhaitez), ce qui les empêchera à tous égards d'exécuter correctement leur tâche, créant des images qui seront incorrectement classées par le système SNA.
Les chercheurs divisent ces images en deux catégories: «tromper» (changer complètement la cible) et «embarrassant» (changer partiellement la cible). Les premières sont des images dénuées de sens qui sont reconnues par le système comme quelque chose de familier. Par exemple, un ensemble de lignes peut être classé comme un «baseball» et le bruit numérique multicolore comme un «tatou». La deuxième catégorie d'images («embarrassantes») sont des images qui, dans des conditions normales, seraient classées correctement, mais l'algorithme malveillant les déforme légèrement, exagérant en disant, aux yeux du système SNA. Par exemple, le numéro manuscrit 6 sera classé numéro 5 en raison d'un petit complément de plusieurs pixels.
Imaginez ce que peuvent faire de tels algorithmes. Il vaut la peine d'échanger la classification des panneaux routiers pour le transport autonome et les accidents seront inévitables.
Voici les «fausses» images qui trompent le système SNA, entraînées à reconnaître les objets, et comment un système similaire les a classées.
 Image n ° 1
Image n ° 1Explication de la série:
- et - images "frauduleuses" codées indirectement;
- b - images "frauduleuses" directement codées;
- c - images «embarrassantes», obligeant le système à classer un chiffre comme un autre;
- d - L'attaque LaVAN (bruit contradictoire / malveillant localisé et visible) peut conduire à une classification incorrecte, même lorsque le «bruit» n'est localisé qu'en un point (dans le coin inférieur droit).
- e - objets tridimensionnels mal classés sous différents angles.
La chose la plus curieuse à ce sujet est qu'une personne peut ne pas succomber à duper un algorithme malveillant et classer correctement les images, en fonction de l'intuition. Auparavant, comme le disent les scientifiques, personne n'a fait de comparaison pratique des capacités d'une machine et d'une personne dans une expérience pour contrer des algorithmes malveillants de fausses images. C'est ce que les chercheurs ont décidé de faire.
Pour cela, plusieurs images réalisées par des algorithmes malveillants ont été préparées. Les sujets ont été informés que la machine classait ces images (de face) comme des objets familiers, c'est-à-dire la machine ne les a pas reconnus correctement. La tâche des sujets était de déterminer exactement comment la machine classait ces images, c'est-à-dire ce qu'ils pensent que la machine a vu dans les images, est-ce que cette classification est vraie, etc.
Au total, 8 expériences ont été réalisées, dans lesquelles 5 types d'images malveillantes créées sans prise en compte de la vision humaine ont été utilisées. En d'autres termes, ils sont créés par machine pour machine. Les résultats de ces expériences se sont avérés très divertissants, mais nous ne les gâterons pas et ne considérerons pas tout dans l'ordre.
Résultats de l'expérience
Expérience n ° 1: tromper les images avec des balises non valides
Dans la première expérience, 48 images trompées ont été utilisées, créées par l'algorithme pour contrer le système de reconnaissance basé sur le SNA appelé AlexNet. Ce système a classé ces images comme «équipement» et «beignet» (
2a ).
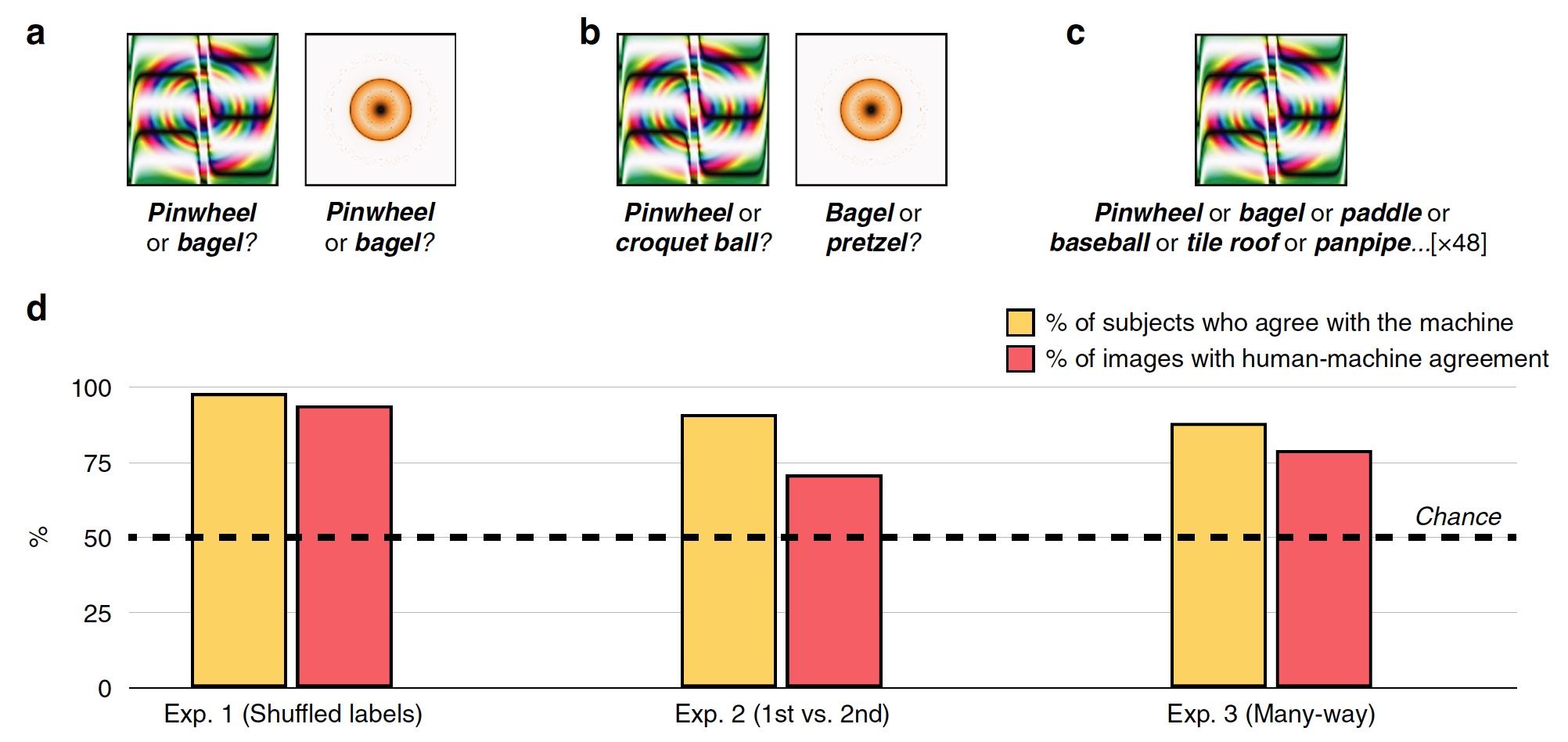 Image n ° 2
Image n ° 2Au cours de chaque tentative, la personne testée, dont 200 personnes, a vu une image dupante et deux marques, soit étiquettes de classification: étiquette SNS système et aléatoire parmi les 47 autres images. Les sujets devaient choisir l'étiquette créée par la machine.
En conséquence, la plupart des sujets ont choisi de choisir une étiquette créée par la machine, plutôt qu'une étiquette d'un algorithme malveillant. Précision de classification, c.-à-d. le degré de consentement du sujet avec la machine était de 74%. Statistiquement, 98% des sujets ont choisi des étiquettes de machine à un niveau supérieur à l'aléatoire statistique (
2d , «% des sujets sont d'accord avec la machine»). 94% des images montraient un alignement homme-machine très élevé, c'est-à-dire que sur 48, seules 3 images étaient classées par des personnes différemment d'une machine.
Ainsi, les sujets ont montré qu'une personne est capable de partager une image réelle et un imbécile, c'est-à-dire d'agir selon un programme basé sur le SCN.
Expérience n ° 2: premier choix contre deuxième
Les chercheurs ont posé la question - en raison de quels sujets ont-ils pu reconnaître si bien les images et les séparer des marques erronées et des images dupes? Les sujets ont peut-être noté l'anneau orange-jaune comme un «beignet», car en réalité le beignet a exactement cette forme et à peu près la même couleur. En reconnaissance, des associations et des choix intuitifs basés sur l'expérience et les connaissances pourraient aider une personne.
Pour vérifier cela, l'étiquette aléatoire a été remplacée par celle qui a été sélectionnée par la machine comme deuxième option de classification possible. Par exemple, AlexNet a classé l'anneau orange-jaune comme un «beignet», et la deuxième option pour ce programme était «bretzel».
Les sujets ont été confrontés à la tâche de choisir la première marque de la machine ou celle qui occupait la deuxième place pour les 48 images (
2 ).
Le graphique au centre de l'image
2d montre les résultats de ce test: 91% des sujets ont choisi la première version de l'étiquette, et le niveau de correspondance homme-machine était de 71%.
Expérience n ° 3: classification multi-thread
Les expériences décrites ci-dessus sont assez simples compte tenu du fait que les sujets ont le choix entre deux réponses possibles (balise machine et balise aléatoire). En fait, la machine en cours de reconnaissance d'image parcourt des centaines voire des milliers d'options d'étiquettes avant de choisir la plus adaptée.
Dans ce test, toutes les notes pour 48 images étaient immédiatement devant les sujets. Ils devaient choisir parmi cet ensemble le plus adapté à chaque image.
En conséquence, 88% des sujets ont choisi exactement les mêmes étiquettes que la machine, et le degré de coordination était de 79%. Un fait intéressant est que même en choisissant la mauvaise étiquette que la machine a choisie, les sujets dans 63% de ces cas ont choisi l'une des 5 meilleures étiquettes. Autrement dit, toutes les marques sur la voiture sont ordonnées dans une liste des plus appropriées aux plus inappropriées (exemple exagéré: «bagel», «bretzel», «anneau en caoutchouc», «pneu», etc. jusqu'à «faucon dans le ciel nocturne» )
Expérience n ° 3b: "qu'est-ce que c'est?"
Dans ce test, les scientifiques ont légèrement modifié les règles. Au lieu de leur demander de «deviner» quelle étiquette la machine choisira pour une image particulière, on a simplement demandé aux sujets ce qu'ils voyaient devant eux.
Les systèmes de reconnaissance basés sur des réseaux de neurones convolutifs sélectionnent l'étiquette appropriée pour une image particulière. Il s'agit d'un processus assez clair et logique. Dans ce test, les sujets présentent une pensée intuitive.
En conséquence, 90% des sujets ont choisi une étiquette, qui a également été choisie par la machine. L'alignement homme-machine parmi les images était de 81%.
Expérience 4: Bruit statique de la télévision
Les scientifiques notent que dans les expériences précédentes, les images sont inhabituelles, mais elles ont des caractéristiques distinctes qui peuvent inciter les sujets à faire le bon (ou le mauvais) choix d'étiquette. Par exemple, l'image «baseball» n'est pas une balle, mais il y a des lignes et des couleurs qui sont présentes sur une vraie balle de baseball. Il s'agit d'une caractéristique distinctive frappante. Mais si l'image n'a pas de telles caractéristiques, mais est essentiellement un bruit statique, une personne peut-elle reconnaître au moins quelque chose dessus? C'est ce qu'il a été décidé de vérifier.
 Image n ° 3a
Image n ° 3aDans ce test, il y avait 8 images avec des statiques devant les sujets, que le système SNS reconnaît comme un objet spécifique (par exemple, un oiseau-zaryanka). De plus, devant les sujets, il y avait une étiquette et des images normales associées (8 images de statiques, 1 étiquette «zaryanka» et 5 photos de cet oiseau). Le sujet du test devait sélectionner 1 image sur 8 de l'électricité statique qui convenait le mieux à l'une ou l'autre étiquette.
Vous pouvez vous tester. Ci-dessus, vous voyez un exemple d'un tel test. Laquelle des trois images convient le mieux au tag «zaryanka» et pourquoi?
81% des sujets ont choisi l'étiquette choisie par la machine. Dans le même temps, 75% des images ont été étiquetées par les sujets avec l'étiquette la plus appropriée de l'avis de la machine (à partir d'un certain nombre d'options, comme nous l'avons mentionné précédemment).
Pour ce test particulier, vous pouvez avoir des questions, tout comme le mien. Le fait est que dans la statique proposée (ci-dessus), je vois personnellement trois caractéristiques prononcées qui les distinguent les unes des autres. Et seulement dans une image, cette fonctionnalité ressemble fortement à la même zaryanka (je pense que vous comprenez quelle image des trois). Par conséquent, mon opinion personnelle et très subjective est qu'un tel test n'est pas particulièrement indicatif. Bien que peut-être parmi d'autres options pour les images statiques étaient vraiment indiscernables et méconnaissables.
Expérience n ° 5: chiffres «douteux»
Les tests décrits ci-dessus étaient basés sur des images qui ne peuvent pas être immédiatement entièrement et sans aucun doute classées comme l'un ou l'autre objet. Il y a toujours une fraction de doute. Les images trompeuses sont assez simples dans leur travail - gâcher l'image au-delà de la reconnaissance. Mais il existe un deuxième type d'algorithmes malveillants qui n'ajoutent (ou suppriment) qu'un petit détail dans l'image, ce qui peut complètement violer le système de reconnaissance par le système SNA. Ajoutez quelques pixels et le chiffre 6 se transforme comme par magie en chiffre 5 (
1s ).
Les scientifiques considèrent ces algorithmes comme l'un des plus dangereux. Vous pouvez légèrement modifier l'étiquette d'image et le véhicule sans pilote considère incorrectement le panneau de limitation de vitesse (par exemple, 75 au lieu de 45), ce qui peut entraîner de tristes conséquences.
 Image # 3b
Image # 3bDans ce test, les scientifiques ont suggéré que les sujets choisissent la mauvaise réponse, mais plutôt la mauvaise. Dans le test, 100 images numériques modifiées par un algorithme malveillant ont été utilisées (le LeNet SNA a changé leur classification, c'est-à-dire que l'algorithme malveillant a fonctionné avec succès). Les sujets devaient dire quel chiffre à leur avis la machine voyait. Comme prévu, 89% des sujets ont réussi ce test.
Expérience 6: photos et "distorsion" localisée
Les scientifiques notent que non seulement des systèmes de reconnaissance d'objets se développent, mais également des algorithmes malveillants qui les empêchent de le faire. Auparavant, pour que l'image soit classée incorrectement, il fallait déformer (changer, supprimer, endommager, etc.) 14% de tous les pixels de l'image cible. Maintenant, ce chiffre est devenu beaucoup plus petit. Il suffit d'ajouter une petite image à l'intérieur de la cible et le classement sera violé.
 Image n ° 4
Image n ° 4Dans ce test, un algorithme LaVAN malveillant assez récent a été utilisé, qui place une petite image localisée à un point sur la photo cible. En conséquence, le système de reconnaissance d'objets peut reconnaître le métro comme une boîte de lait (
4a ). Les caractéristiques les plus importantes de cet algorithme sont précisément la faible proportion de pixels endommagés (seulement 2%) de l'image cible et l'absence de la nécessité de la déformer dans son intégralité ou la partie principale (la plus importante) de celle-ci.
Dans le test, 22 images endommagées par LaVAN ont été utilisées (le système de reconnaissance SNA Inception V3 a été piraté avec succès par cet algorithme). Les sujets étaient censés classer l'encart malveillant sur la photo. 87% des sujets ont réussi à le faire.
Expérience 7: objets tridimensionnels
Les images que nous avons vues précédemment sont en deux dimensions, comme toute photo, photo ou coupure de journal. La plupart des algorithmes malveillants manipulent avec succès de telles images. Cependant, ces ravageurs ne peuvent fonctionner que sous certaines conditions, c'est-à-dire qu'ils ont un certain nombre de limitations:
- complexité: uniquement des images en deux dimensions;
- application pratique: les modifications malveillantes ne sont possibles que sur les systèmes qui lisent les images numériques reçues, et non les images des capteurs et des capteurs;
- stabilité: une attaque malveillante perd de sa force si vous faites pivoter une image bidimensionnelle (redimensionner, recadrer, affiner, etc.);
- les gens: nous voyons le monde et les objets qui nous entourent en 3D sous différents angles, sous différents éclairages, et non sous la forme d'images numériques bidimensionnelles prises sous un seul angle.
Mais, comme nous le savons, les progrès n'ont pas épargné les algorithmes malveillants. Parmi eux figurait celui qui est capable non seulement de déformer les images bidimensionnelles, mais aussi les images tridimensionnelles, ce qui conduit à une classification incorrecte par le système de reconnaissance d'objets. Lors de l'utilisation d'un logiciel pour les graphiques en trois dimensions, un tel algorithme induit en erreur les classificateurs basés sur le SNA (dans ce cas, le programme Inception V3) à partir de différentes distances et angles de vue. La chose la plus surprenante est que de telles images 3D trompeuses peuvent être imprimées sur une imprimante appropriée, c'est-à-dire créer un véritable objet physique, et le système de reconnaissance d'objets ne le classera toujours pas correctement (par exemple, une orange comme perceuse électrique). Et tout cela grâce à des changements mineurs dans la texture de l'image cible (
4b ).
Pour un système de reconnaissance d'objets, un tel algorithme malveillant est un adversaire sérieux. Mais l'homme n'est pas une machine, il voit et pense différemment. Dans ce test, avant les sujets, il y avait des images d'objets tridimensionnels dans lesquels il y avait les changements de texture décrits ci-dessus sous trois angles. Les sujets ont également reçu la note correcte et erronée. Ils devaient déterminer quelles étiquettes sont correctes, lesquelles ne le sont pas et pourquoi, c'est-à-dire si les sujets testés voient des changements de texture dans les images.
En conséquence, 83% des sujets ont réussi la tâche.
Pour une connaissance plus détaillée des nuances de l'étude, je vous recommande fortement de consulter le
rapport des scientifiques .
Et sur
ce lien, vous trouverez les fichiers d'images, de données et de code qui ont été utilisés dans l'étude.
Épilogue
Les travaux menés ont permis aux scientifiques de tirer une conclusion simple et assez évidente: l'intuition humaine peut être une source de données très importantes et un outil pour prendre la bonne décision et / ou la perception de l'information. Une personne est en mesure de comprendre intuitivement comment le système de reconnaissance d'objets se comportera, quelles étiquettes il choisira et pourquoi.
Les raisons pour lesquelles il est plus facile pour une personne de voir une image réelle et de la reconnaître correctement plusieurs. Le plus évident est la méthode d'obtention de l'information: la machine reçoit une image sous forme numérique, et une personne la voit de ses propres yeux. Pour une machine, une image est un ensemble de données dont vous pouvez modifier la classification. Pour nous, l'image d'une rame de métro sera toujours une rame de métro, pas une canette de lait, car nous la voyons.
Les scientifiques soulignent également que ces tests sont difficiles à évaluer, car une personne n'est pas une machine et une machine n'est pas une personne. Par exemple, les chercheurs parlent du test avec un «beignet» et une «roue». Ces images sont similaires au «beignet» et à la «roue», car le système de reconnaissance les classe de cette façon. Une personne voit qu'elle ressemble à un «beignet» et à une «roue», mais ce n'est pas le cas. Il s'agit de la différence fondamentale dans la perception des informations visuelles entre une personne et un programme.
Merci de votre attention, restez curieux et bonne semaine de travail, les gars.
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbit / s jusqu'à l'été gratuitement lorsque vous payez pour une période de six mois, vous pouvez commander
ici .
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?