TL; DR: Il y a quatre ans, j'ai quitté Google avec l'idée d'un nouvel outil de surveillance des serveurs. L'idée était de combiner les fonctions habituellement isolées de
collecte et d'analyse de journaux, de collecte de métriques, d'
alertes et d'un tableau de bord en un seul service. L'un des principes - le service doit être très
rapide , offrant aux développeurs un travail facile, interactif et agréable. Cela nécessite de traiter des ensembles de données de plusieurs gigaoctets en une fraction de seconde, sans dépasser le budget. Les outils existants pour travailler avec les journaux sont souvent lents et maladroits, nous avons donc été confrontés à une bonne tâche: développer correctement un outil pour donner aux utilisateurs de nouvelles sensations du travail.
Cet article décrit comment nous, chez Scalyr, avons résolu ce problème en appliquant les méthodes de la vieille école, l'approche par force brute, en éliminant les couches redondantes et en évitant les structures de données complexes. Vous pouvez appliquer ces leçons à vos propres tâches d'ingénierie.
La force de la vieille école
L'analyse des journaux commence généralement par une recherche: recherchez tous les messages correspondant à un certain modèle. Dans Scalyr, ce sont des dizaines ou des centaines de gigaoctets de journaux provenant de nombreux serveurs. Les approches modernes impliquent généralement la construction d'une structure de données complexe optimisée pour la recherche. Bien sûr, je l'ai vu sur Google, où ils sont assez bons dans de telles choses. Mais nous avons opté pour une approche beaucoup plus grossière: le balayage linéaire des journaux. Et cela a fonctionné - nous fournissons une interface de recherche d'un ordre de grandeur plus rapide que celle des concurrents (voir animation à la fin).
L'idée clé est que les processeurs modernes sont vraiment très rapides dans des opérations simples et directes. Ceci est facilement ignoré dans les systèmes complexes à plusieurs couches qui dépendent de la vitesse d'E / S et des opérations réseau, et de tels systèmes sont très courants aujourd'hui. Ainsi, nous avons développé une conception qui minimise le nombre de couches et l'excès de déchets. Avec plusieurs processeurs et serveurs en parallèle, la vitesse de recherche atteint 1 To par seconde.
Principales conclusions de cet article:
- La recherche approximative est une approche viable pour résoudre des problèmes réels à grande échelle.
- La force brute est une technique de conception, pas une libération du travail. Comme toute technique, elle est mieux adaptée à certains problèmes qu'à d'autres et peut être mal ou bien mise en œuvre.
- La force brute est particulièrement bonne pour des performances stables .
- L'utilisation efficace de la force brute nécessite une optimisation du code et l'utilisation en temps opportun de ressources suffisantes. Il convient si vos serveurs sont soumis à de lourdes charges de travail non utilisateur et que les opérations utilisateur restent une priorité.
- Les performances dépendent de la conception de l'ensemble du système, et pas seulement de l'algorithme de boucle interne.
(Cet article décrit comment rechercher des données en mémoire. Dans la plupart des cas, lorsqu'un utilisateur recherche des journaux, les serveurs Scalyr les ont déjà mis en cache. Dans l'article suivant, nous discuterons de la recherche de journaux non mis en cache. Les mêmes principes s'appliquent: code efficace, méthode de force brute avec de gros calculs ressources).
Méthode de la force brute
Traditionnellement, une recherche dans un grand ensemble de données se fait à l'aide d'un index de mots clés. Telle qu'appliquée aux journaux du serveur, cela signifie rechercher chaque mot unique dans le journal. Pour chaque mot, vous devez faire une liste de toutes les inclusions. Cela facilite la recherche de tous les messages avec ce mot, par exemple, "erreur", "firefox" ou "transaction_16851951" - il suffit de regarder dans l'index.
J'ai utilisé cette approche sur Google et cela a bien fonctionné. Mais dans Scalyr, nous regardons dans les journaux octet par octet.
Pourquoi? D'un point de vue algorithmique abstrait, les index de mots-clés sont beaucoup plus efficaces qu'une recherche brute. Cependant, nous ne vendons pas d'algorithmes, nous vendons des performances. Et les performances ne sont pas seulement des algorithmes, mais aussi de l'ingénierie des systèmes. Il faut tout considérer: la quantité de données, le type de recherche, le matériel disponible et le contexte logiciel. Nous avons décidé que pour notre problème particulier, une option comme «grep» est meilleure qu'un indice.
Les index sont excellents, mais ils ont des limites. Un mot est facile à trouver. Mais trouver des messages en quelques mots, comme «googlebot» et «404», est déjà beaucoup plus compliqué. La recherche de phrases comme «exception non capturée» nécessite un index plus lourd qui enregistre non seulement tous les messages avec ce mot, mais aussi l'emplacement spécifique du mot.
La vraie difficulté vient quand vous ne cherchez pas de mots. Supposons que vous souhaitiez voir la quantité de trafic provenant des robots. La première pensée est de rechercher dans les journaux le mot «bot». Vous trouverez donc quelques bots: Googlebot, Bingbot et bien d'autres. Mais ici, «bot» n'est pas un mot, mais en fait partie. Si nous recherchons «bot» dans l'index, nous ne trouverons pas de messages avec le mot «Googlebot». Si vous vérifiez chaque mot dans l'index, puis recherchez dans l'index les mots-clés trouvés, la recherche ralentira considérablement. En conséquence, certains programmes pour travailler avec des journaux ne permettent pas de rechercher dans certaines parties d'un mot ou (au mieux) permettent d'utiliser une syntaxe spéciale avec des performances inférieures. Nous voulons éviter cela.
Un autre problème est la ponctuation. Vous souhaitez trouver toutes les demandes provenant de
50.168.29.7 ? Qu'en est-il du débogage des journaux contenant
[error] ? Les index sautent généralement la ponctuation.
Enfin, les ingénieurs aiment les outils puissants, et parfois un problème ne peut être résolu qu'avec une expression régulière. L'index des mots clés n'est pas très approprié pour cela.
De plus, les index
sont complexes . Chaque message doit être ajouté à plusieurs listes de mots clés. Ces listes doivent toujours être conservées dans un format convivial pour la recherche. Les requêtes contenant des phrases, des fragments de mots ou des expressions régulières doivent être traduites en opérations avec plusieurs listes et les résultats analysés et combinés pour obtenir un ensemble de résultats. Dans le cadre d'un service multi-utilisateurs à grande échelle, cette complexité crée des problèmes de performances qui ne sont pas visibles lors de l'analyse des algorithmes.
Les index de mots-clés prennent également beaucoup d'espace et le stockage est le principal élément de coût dans le système de gestion des journaux.
D'un autre côté, une grande puissance de calcul peut être dépensée pour chaque recherche. Nos utilisateurs apprécient les recherches à grande vitesse pour les requêtes uniques, mais ces requêtes sont relativement rares. Pour les requêtes de recherche typiques, par exemple, pour le tableau de bord, nous utilisons des techniques spéciales (nous les décrirons dans le prochain article). Les autres requêtes sont assez rares, vous devez donc rarement en traiter plusieurs à la fois. Mais cela ne signifie pas que nos serveurs ne sont pas occupés: ils sont occupés par le travail de réception, d'analyse et de compression des nouveaux messages, d'évaluation des alertes, de compression des anciennes données, etc. Ainsi, nous avons une offre assez importante de processeurs qui peuvent être utilisés pour répondre aux demandes.
La force brute fonctionne si vous avez un problème de force brute (et beaucoup de force)
La force brute fonctionne mieux sur des tâches simples avec de petites boucles internes. Souvent, vous pouvez optimiser la boucle intérieure pour travailler à des vitesses très élevées. Si le code est complexe, il est beaucoup plus difficile de l'optimiser.
Initialement, notre code de recherche avait une boucle interne assez grande. Nous stockons des messages sur des pages 4K; chaque page contient des messages (en UTF-8) et des métadonnées pour chaque message. Les métadonnées sont une structure dans laquelle la longueur de la valeur, l'ID du message interne et d'autres champs sont codés. La boucle de recherche ressemblait à ceci:

Il s'agit d'une option simplifiée par rapport au code réel. Mais même ici, vous pouvez voir plusieurs placements d'objets, des copies de données et des appels de fonction. La JVM optimise assez bien les appels de fonction et alloue des objets éphémères, donc ce code a mieux fonctionné que nous ne le méritions. Pendant les tests, les clients l'ont utilisé avec succès. Mais à la fin, nous sommes passés à un nouveau niveau.
(Vous pouvez vous demander pourquoi nous stockons des messages dans ce format avec des pages 4K, du texte et des métadonnées, plutôt que de travailler directement avec les journaux. Il existe de nombreuses raisons pour lesquelles le moteur Scalyr interne ressemble plus à une base de données distribuée qu'à système de fichiers La recherche de texte est souvent combinée avec des filtres de style SGBD dans les champs après l'analyse des journaux. Nous pouvons rechercher plusieurs milliers de journaux en même temps, et les fichiers texte simples ne conviennent pas à notre contrôle transactionnel, répliqué et distribué données).
Initialement, il semblait qu'un tel code n'était pas très adapté à l'optimisation sous la méthode de la force brute. Le «vrai travail» dans
String.indexOf() ne dominait même pas le profil CPU. Autrement dit, l'optimisation de cette seule méthode n'apporterait pas d'effet significatif.
Il se trouve que nous stockons des métadonnées au début de chaque page, et le texte de tous les messages en UTF-8 est compressé à l'autre extrémité. Profitant de cela, nous avons réécrit la boucle de recherche sur toute la page à la fois:
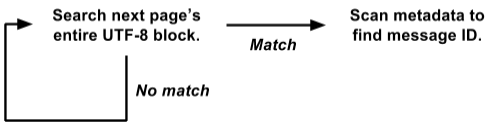
Cette version fonctionne directement sur la vue d'
raw byte[] et recherche tous les messages à la fois sur la page 4K entière.
C'est beaucoup plus facile à optimiser pour la force brute. Le cycle de recherche interne est appelé simultanément pour la page 4K entière, et non séparément pour chaque message. Il n'y a pas de copie de données, pas de sélection d'objets. Et les opérations plus complexes avec des métadonnées sont appelées uniquement avec un résultat positif, et non pour chaque message. Ainsi, nous avons éliminé une tonne de frais généraux et le reste de la charge est concentré dans un petit cycle de recherche interne, ce qui est bien adapté pour une optimisation supplémentaire.
Notre algorithme de recherche actuel est basé sur la
grande idée de Leonid Volnitsky . Il est similaire à l'algorithme de Boyer-Moore avec le saut de la longueur de la chaîne de recherche à chaque étape. La principale différence est qu'il vérifie deux octets à la fois pour minimiser les fausses correspondances.
Notre implémentation nécessite la création d'une table de recherche de 64 Ko pour chaque recherche, mais cela n'a aucun sens par rapport aux gigaoctets de données que nous recherchons. La boucle interne traite plusieurs gigaoctets par seconde sur un seul cœur. En pratique, les performances stables sont d'environ 1,25 Go par seconde sur chaque cœur, et il y a un potentiel d'amélioration. Vous pouvez éliminer une partie de la surcharge en dehors de la boucle interne, et nous prévoyons d'expérimenter avec la boucle interne en C au lieu de Java.
Appliquer la force
Nous avons discuté du fait que les recherches dans les journaux peuvent être mises en œuvre «à peu près», mais de quel «pouvoir» disposons-nous? Beaucoup.
1 cœur : lorsqu'il est utilisé correctement, un cœur d'un processeur moderne est assez puissant en soi.
8 cœurs : nous travaillons actuellement sur des serveurs SSD Amazon hi1.4xlarge et i2.4xlarge, chacun ayant 8 cœurs (16 threads). Comme mentionné ci-dessus, ces noyaux sont généralement occupés par des opérations en arrière-plan. Lorsque l'utilisateur effectue une recherche, les opérations d'arrière-plan sont interrompues, libérant les 8 cœurs pour la recherche. La recherche se termine généralement en une fraction de seconde, après quoi le travail en arrière-plan reprend (le programme du contrôleur garantit qu'un barrage de requêtes de recherche n'interfère pas avec le travail en arrière-plan important).
16 cœurs : pour plus de fiabilité, nous organisons les serveurs en groupes maître / esclave. Chaque maître a un serveur SSD et un subordonné EBS. Si le serveur principal tombe en panne, le serveur sur le SSD prend immédiatement sa place. Presque tout le temps, le maître et l'esclave fonctionnent bien, donc chaque bloc de données est consultable sur deux serveurs différents (le serveur EBS esclave a un processeur faible, donc nous ne le considérons pas). Nous répartissons la tâche entre eux, de sorte que nous avons un total de 16 cœurs disponibles.
De nombreux cœurs : dans un avenir proche, nous distribuerons les données entre les serveurs afin qu'ils participent tous au traitement de chaque demande non triviale. Chaque noyau fonctionnera. [Remarque:
nous avons mis en œuvre le plan et augmenté la vitesse de recherche à 1 To / s, voir la note à la fin de l'article ].
La simplicité assure la fiabilité
Un autre avantage de la force brute est sa performance relativement stable. En règle générale, la recherche n'est pas trop sensible aux détails de la tâche et de l'ensemble de données (je pense que c'est pourquoi elle est appelée "grossière").
L'index de mots-clés produit parfois des résultats incroyablement rapides, mais dans d'autres cas, ce n'est pas le cas. Supposons que vous disposiez de 50 Go de journaux dans lesquels le terme «customer_5987235982» apparaît exactement trois fois. Une recherche par ce terme compte trois emplacements directement à partir de l'index et se termine instantanément. Mais une recherche générique complexe peut analyser des milliers de mots-clés et prendre beaucoup de temps.
D'un autre côté, les recherches par force brute pour n'importe quelle requête sont effectuées à plus ou moins la même vitesse. La recherche de mots longs est meilleure, mais même la recherche d'un seul caractère est assez rapide.
La simplicité de la méthode de la force brute signifie que sa productivité est proche du maximum théorique. Il existe moins d'options pour une surcharge de disque inattendue, un conflit de verrouillage, des poursuites de pointeur et des milliers d'autres raisons d'échecs. Je viens de regarder les requêtes faites par les utilisateurs Scalyr la semaine dernière sur notre serveur le plus occupé. Il y a eu 14 000 demandes. Exactement huit d'entre eux ont pris plus d'une seconde; 99% effectué en 111 millisecondes (si vous n'avez pas utilisé les outils d'analyse de journal, croyez-moi:
c'est rapide ).
Des performances stables et fiables sont importantes pour la commodité d'utilisation du service. S'il ralentit périodiquement, les utilisateurs le percevront comme peu fiable et hésiteront à l'utiliser.
Recherche de journaux en action
Voici une petite animation qui montre Scalyr en train de chercher en action. Nous avons un compte de démonstration où nous importons chaque événement dans chaque référentiel Github public. Dans cette démo, j'étudie les données de la semaine: environ 600 Mo de logs bruts.
La vidéo a été enregistrée en direct, sans préparation particulière, sur mon bureau (à environ 5000 kilomètres du serveur). Les performances que vous constaterez sont en grande partie dues à l'
optimisation du client web , ainsi qu'au backend rapide et fiable. Chaque fois qu'il y a une pause sans l'indicateur de «chargement», je la mets en pause pour que vous puissiez lire sur quoi je vais cliquer.

En conclusion
Lors du traitement de grandes quantités de données, il est important de choisir un bon algorithme, mais «bon» ne signifie pas «fantaisie». Réfléchissez à la façon dont votre code fonctionnera dans la pratique. Certains facteurs qui peuvent être d'une grande importance dans le monde réel sortent de l'analyse théorique des algorithmes. Les algorithmes plus simples sont plus faciles à optimiser et sont plus stables dans les situations limites.
Pensez également au contexte dans lequel le code s'exécutera. Dans notre cas, nous avons besoin de serveurs suffisamment puissants pour gérer les tâches d'arrière-plan. Les utilisateurs initient relativement rarement une recherche, nous pouvons donc emprunter tout un groupe de serveurs pendant la courte période nécessaire pour terminer chaque recherche.
En utilisant la force brute, nous avons implémenté une recherche rapide, fiable et flexible sur un ensemble de journaux. Nous espérons que ces idées seront utiles pour vos projets.
Modifier: le
titre et le texte sont passés de «Recherche à 20 Go par seconde» à «Recherche à 1 To par seconde» pour refléter l'augmentation des performances au cours des dernières années. Cette augmentation de la vitesse est principalement due à un changement dans le type et le nombre de serveurs EC2 que nous élevons aujourd'hui pour servir la clientèle accrue. Dans un avenir proche, des changements devraient permettre une nouvelle augmentation sensible de l'efficacité au travail, et nous attendons avec impatience l'occasion d'en parler.