Dans la
première partie de l' histoire, basée sur une
présentation de Dmitry Stogov de Zend Technologies sur HighLoad ++, nous avons compris la structure interne de PHP. Nous avons appris en détail et de première main quels changements dans les structures de données de base ont permis à PHP 7 d'accélérer plus de deux fois. Cela aurait pu être arrêté, mais déjà dans la version 7.1, les développeurs sont allés beaucoup plus loin, car ils avaient encore de nombreuses idées d'optimisation.
L'expérience accumulée de travail sur JIT avant les sept peut maintenant être interprétée, en regardant les résultats dans 7.0 sans JIT et les résultats de HHVM avec JIT. En PHP 7.1, il a été décidé de ne pas travailler avec JIT, mais à nouveau de se tourner vers l'interpréteur. Si plus tôt l'optimisation concernait l'interpréteur, alors dans cet article, nous examinerons l'optimisation du bytecode, en utilisant l'inférence de type qui a été implémentée pour notre JIT.
Sous la coupe, Dmitry Stogov montrera comment tout cela fonctionne, en utilisant un exemple simple.
Optimisation du bytecode
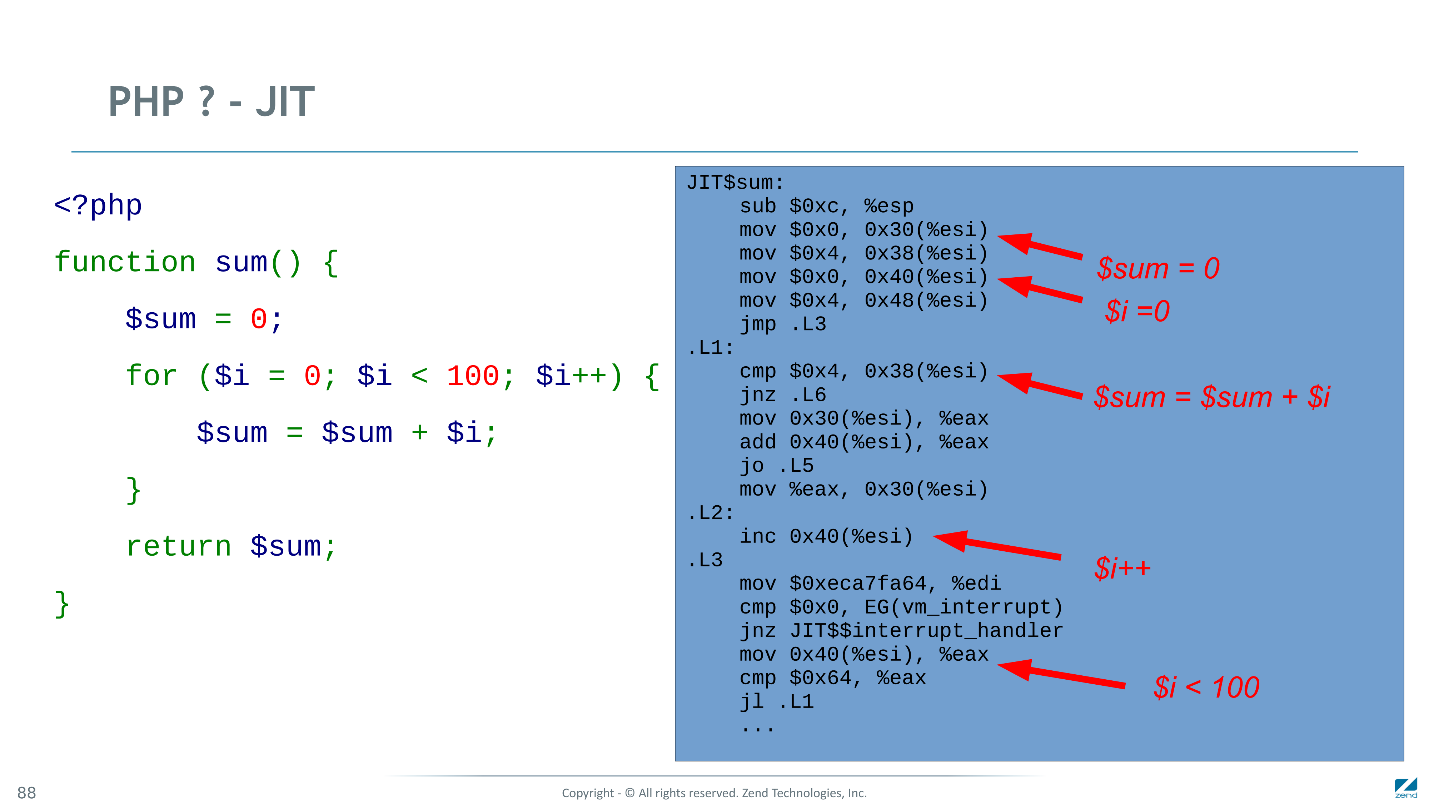
Ci-dessous se trouve le bytecode dans lequel le compilateur PHP standard compile la fonction. Il est en un seul passage - rapide et stupide, mais capable de faire à nouveau son travail sur chaque demande HTTP (si OPcache n'est pas connecté).

Optimisations OPcache
Avec l'avènement d'OPcache, nous avons commencé à l'optimiser. Certaines méthodes d'optimisation
sont intégrées depuis longtemps dans OPcache , par exemple, les méthodes d'optimisation de la fente - lorsque nous regardons le code à travers le judas, recherchons des modèles familiers et les remplaçons par des heuristiques. Ces méthodes continuent d'être utilisées dans 7.0. Par exemple, nous avons deux opérations: addition et affectation.

Ils peuvent être combinés en une seule opération d'affectation composée, qui effectue l'addition directement sur le résultat:
ASSIGN_ADD $sum, $i . Un autre exemple est une variable post-incrémentation qui pourrait théoriquement retourner une sorte de résultat.

Il peut ne pas s'agir d'une valeur scalaire et doit être supprimé. Pour ce faire, utilisez l'instruction
FREE suit. Mais si vous le changez en pré-incrémentation, l'instruction
FREE n'est pas requise.

À la fin, il y a deux instructions
RETURN : la première est une réflexion directe de l'instruction RETURN dans le texte source, et la seconde est ajoutée par un compilateur stupide avec une parenthèse fermante. Ce code ne sera jamais atteint et peut être supprimé.
Il ne reste que quatre instructions dans la boucle. Il semble qu'il n'y ait rien de plus à optimiser, mais pas pour nous.
Regardez le
$i++ et son instruction correspondante - le pré-incrément
PRE_INC . Chaque fois qu'il est exécuté:
- besoin de vérifier quel type de variable est venu;
- si elle
is_long ; - effectuer l'incrémentation;
- vérifier le débordement;
- passez au suivant;
- peut-être vérifier l'exception.
Mais une personne, en regardant simplement le code PHP, verra que la variable
$i se situe dans la plage de 0 à 100, et il ne peut y avoir de débordement, des vérifications de type ne sont pas nécessaires, et il ne peut y avoir aucune exception non plus.
En PHP 7.1, nous avons essayé d'apprendre au compilateur à comprendre cela .
Optimisation du graphique de flux de contrôle

Pour ce faire, vous devez déduire des types et pour entrer des types, vous devez d'abord créer une représentation formelle des flux de données que l'ordinateur comprend. Mais nous commencerons par construire un graphe de flux de contrôle, un graphe de dépendance de contrôle. Initialement, nous divisons le code en blocs de base - un ensemble d'instructions avec une entrée et une sortie. Par conséquent, nous coupons le code aux endroits où la transition se produit, c'est-à-dire les étiquettes L0, L1. Nous le coupons également après les opérateurs de branche conditionnels et inconditionnels, puis le connectons avec des arcs qui montrent les dépendances pour le contrôle.

Nous avons donc obtenu CFG.
Optimisation du formulaire d'attribution unique statique
Eh bien, maintenant nous avons besoin d'une dépendance aux données. Pour ce faire, nous utilisons le formulaire d'attribution unique statique - une représentation populaire dans le monde de l'optimisation des compilateurs. Cela implique que la valeur de chaque variable ne peut être attribuée qu'une seule fois.

Pour chaque variable, nous ajoutons un indice ou un numéro de réincarnation. Dans chaque endroit où l'affectation a lieu, nous mettons un nouvel index, et où nous les utilisons - jusqu'aux points d'interrogation, car il n'est pas encore connu partout. Par exemple, dans l'instruction
IS_SMALLER $ je peux provenir à la fois du bloc L0 avec le numéro 4 et du premier bloc avec le numéro 2.
Pour résoudre ce problème, le SSA introduit
la pseudo-fonction Phi , qui, si nécessaire, est insérée au début du bloc basic->, prend toutes sortes d'indices d'une variable qui sont venus au bloc de base à partir de différents endroits, et crée une nouvelle réincarnation de la variable. Ce sont ces variables qui sont utilisées plus tard pour éliminer l'ambiguïté.

En remplaçant tous les points d'interrogation de cette manière, nous allons créer SSA.
Optimisation de type
Nous en déduisons maintenant les types - comme si nous essayions d'exécuter ce code directement sur la gestion.

Dans le premier bloc, les variables reçoivent des valeurs constantes - des zéros, et nous savons avec certitude que ces variables seront de type long. Ensuite, la fonction Phi. Long arrive à l'entrée, et nous ne connaissons pas les valeurs des autres variables provenant d'autres branches.

Nous pensons que la sortie phi () sera longue.

Nous distribuons plus loin. Nous arrivons à des fonctions spécifiques, par exemple,
ASSIGN_ADD et
PRE_INC . Additionnez deux longs. Le résultat peut être long ou double en cas de débordement.

Ces valeurs tombent à nouveau dans la fonction Phi, l'union des ensembles de types possibles arrivant sur différentes branches se produit. Eh bien et ainsi de suite, nous continuons à nous étendre jusqu'à ce que nous arrivions à un point fixe et que tout se calme.

Nous avons obtenu un ensemble possible de valeurs de type à chaque point du programme. C'est déjà bien. L'ordinateur sait déjà que
$i ne peut être que long ou double et peut exclure certaines vérifications inutiles. Mais nous savons que le double
$i ne peut pas l'être. Comment le savons-nous? Et nous voyons une condition qui limite la croissance de
$i dans le cycle à un éventuel débordement. Nous apprendrons à l'ordinateur à voir cela.
Optimisation de la propagation de la plage
Dans l'instruction
PRE_INC nous n'avons jamais découvert que i ne peut être qu'un entier - cela coûte long ou double. Cela se produit car nous n'avons pas essayé de déduire des plages possibles. Ensuite, nous pourrions répondre à la question de savoir s'il y aura débordement ou non.
Cette sortie des plages est effectuée de manière similaire, mais légèrement plus complexe. En conséquence, nous obtenons une plage fixe de variables
$i avec les indices 2, 4, 6 7, et maintenant nous pouvons dire avec confiance que l'incrément
$i ne conduira pas à un débordement.

En combinant ces deux résultats, nous pouvons dire avec certitude que la double variable
$i ne
$i jamais devenir.

Tout ce que nous avons obtenu n'est pas encore l'optimisation, ce sont des informations pour l'optimisation! Considérez l'
ASSIGN_ADD . D'une manière générale, l'ancienne valeur de la somme qui est venue à cette instruction pourrait être, par exemple, un objet. Ensuite, après l'ajout, l'ancienne valeur aurait dû être supprimée. Mais dans notre cas, nous savons avec certitude qu'il existe une valeur scalaire longue ou double. Aucune destruction n'est requise, nous pouvons remplacer
ASSIGN_ADD par
ADD - une instruction plus facile.
ADD utilise la variable
sum à la fois comme argument et comme valeur.

Pour les opérations de pré-incrémentation, nous savons avec certitude que l'opérande est toujours long et qu'aucun débordement ne peut se produire. Nous utilisons un gestionnaire hautement spécialisé pour cette instruction, qui effectuera uniquement les actions nécessaires sans aucun contrôle.

Comparez maintenant la variable à la fin de la boucle. Nous savons que la valeur de la variable ne sera que longue - vous pouvez immédiatement vérifier cette valeur en la comparant à cent. Si auparavant, nous avons enregistré le résultat de la vérification dans une variable temporaire, puis vérifié à nouveau la variable temporaire pour vrai / faux, cela peut maintenant être fait avec une instruction, c'est-à-dire simplifiée.

Résultat du bytecode par rapport à l'original.

Il ne reste que 3 instructions dans le cycle, et deux d'entre elles sont hautement spécialisées. En conséquence, le code à droite est
3 fois plus rapide que l' original.
Manipulateurs hautement spécialisés
Tout
gestionnaire d'analyse PHP n'est qu'une fonction C. À gauche, un gestionnaire standard et en haut à droite, un gestionnaire hautement spécialisé. Celui de gauche vérifie: le type de l'opérande, si un débordement s'est produit, si une exception s'est produite. Le bon en ajoute un et c'est tout. Il se traduit par 4 instructions machine. Si nous allions plus loin et faisions JIT, alors nous n'aurions besoin que d'une instruction unique
incl .

Et ensuite?
Nous continuons d'augmenter la vitesse de la branche PHP 7 sans JIT.
PHP 7.1 sera à nouveau 60% plus rapide sur les tests de synthèse typiques, mais sur les applications réelles, cela ne donne presque pas de gain - seulement 1-2% sur WordPress. Ce n'est pas particulièrement intéressant. Depuis août 2016, lorsque la branche 7.1 a été gelée pour des changements majeurs, nous avons recommencé à travailler sur JIT pour PHP 7.2 ou plutôt PHP 8.
Dans une nouvelle tentative, nous utilisons
DynAsm pour générer le code, qui a été développé par Mike Paul
pour LuaJIT-2 . C'est bien car il
génère du code très rapidement : le fait que les minutes aient été compilées dans la version JIT sur LLVM se passe désormais en 0,1-0,2 s. Déjà aujourd'hui, l'
accélération sur bench.php sur JIT est 75 fois plus rapide que PHP 5.
Il n'y a pas d'accélération sur les applications réelles, et c'est le prochain défi pour nous. En partie, nous avons obtenu le code optimal, mais après avoir compilé trop de scripts PHP, nous avons obstrué le cache du processeur, donc cela n'a pas fonctionné plus rapidement. Et non la vitesse du code était un goulot d'étranglement dans les applications réelles ...
Peut-être que DynAsm peut être utilisé pour compiler uniquement certaines fonctions qui seront sélectionnées soit par un programmeur soit par des heuristiques basées sur des compteurs - combien de fois une fonction a été appelée, combien de fois les cycles y sont répétés, etc.
Voici le code machine que notre JIT génère pour le même exemple. De nombreuses instructions sont compilées de manière optimale: incrémentation en une instruction CPU, initialisation variable en constantes en deux. Lorsque les types ne sont pas hachurés, vous devez vous embêter un peu plus.
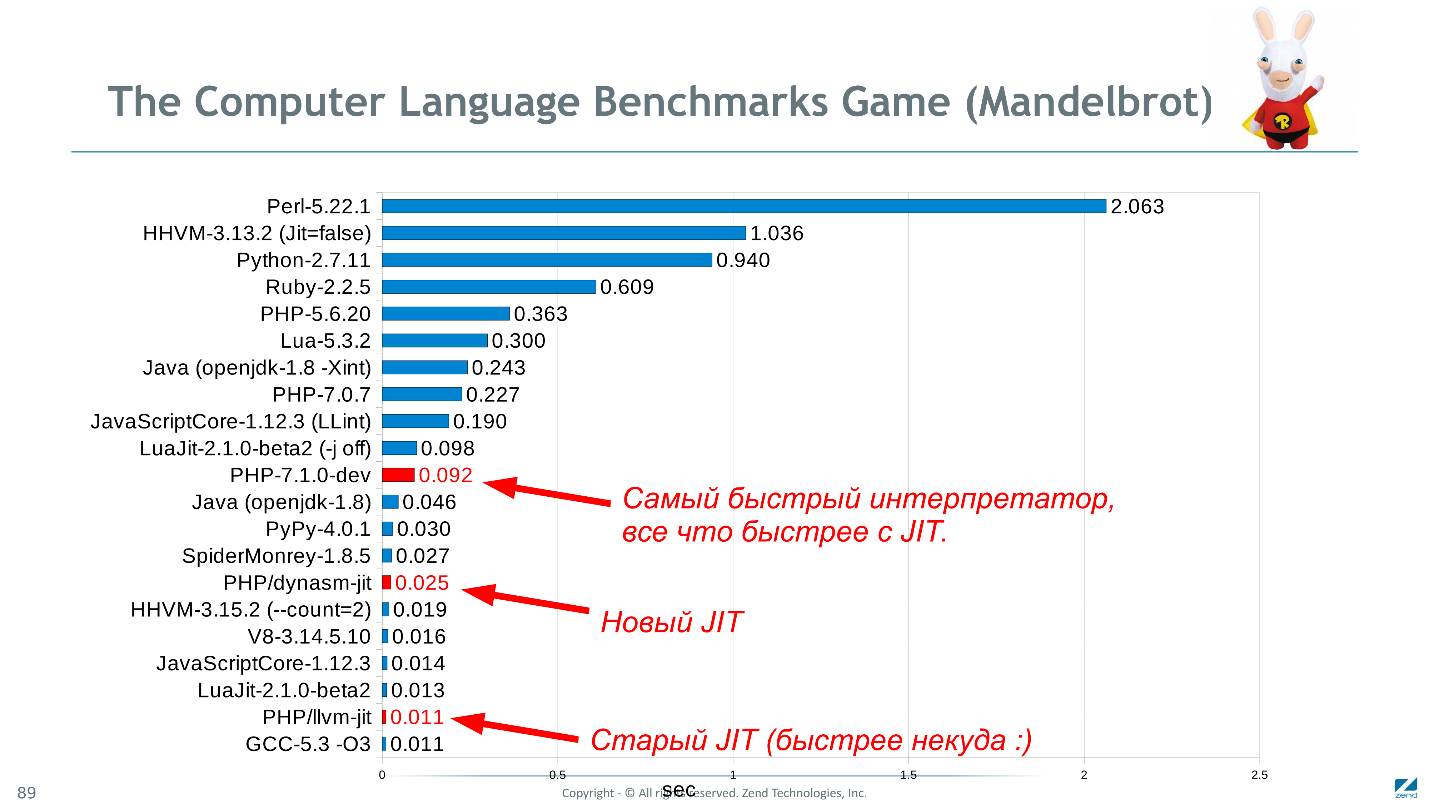
En revenant à l'image du titre, PHP, en comparaison avec des langages similaires dans le test de Mandelbrot, montre de très bons résultats (bien que les données soient pertinentes fin 2016).
Le diagramme montre le temps d'exécution en secondes, moins c'est mieux.Peut-être que
Mandelbrot n'est pas le meilleur test. Il est informatique, mais simple et implémenté de manière égale dans toutes les langues. Ce serait bien de savoir à quelle vitesse Wordpress fonctionnerait en C ++, mais il n'y a pratiquement aucune bizarrerie prête à le réécrire juste pour vérifier, et même répéter toutes les perversions du code PHP. Si vous avez des idées pour un ensemble de références plus adéquat - suggérez.
Nous nous rencontrerons à PHP Russie le 17 mai , nous discuterons des perspectives et du développement de l'écosystème et de l'expérience d'utilisation de PHP pour des projets vraiment complexes et sympas. Déjà avec nous:
Bien sûr, c'est loin d'être tout. Oui, et l'appel à communications est toujours fermé, jusqu'au 1er avril, nous attendons les candidatures de ceux qui sont capables d'appliquer des approches modernes et les meilleures pratiques afin de mettre en œuvre des services PHP sympas. N'ayez pas peur de la concurrence avec des conférenciers éminents - nous recherchons de l'expérience dans l'utilisation de ce qu'ils font dans de vrais projets et vous aiderons à montrer les avantages de vos cas.