Lorsque vous travaillez avec plusieurs clients à la fois, il devient nécessaire d'analyser rapidement un grand nombre d'informations dans différents comptes et rapports. Lorsqu'il y a plus de 10 clients, le marketeur n'a plus le temps de surveiller en permanence les statistiques. Mais il y a un moyen.
Dans cet article, je vais vous expliquer comment surveiller les comptes publicitaires à l'aide de l'API et de Python.
À la sortie, nous recevrons une demande à l'API Yandex.Direct, avec laquelle nous recevrons des statistiques sur les campagnes publicitaires et serons en mesure de traiter ces données.
Pour cela, nous avons besoin de:
- Obtenez le jeton d'API Yandex Direct
- Écrire une demande de serveur
- Importer des données dans DataFrame
Importer des bibliothèques
Vous devez importer les bibliothèques utilisées dans la requête, ainsi que les pandas et DataFrame.
Toutes les importations ressembleront à ceci:
import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame
Réception du jeton
En ce moment, je ne peux pas dire mieux que la documentation de l'API Direct, donc je vais laisser un lien.
(
Instructions pour obtenir un jeton )
Nous écrivons une demande au serveur API Yandex.Direct
Copiez la demande depuis la documentation de l'APIModifiez la demande.- Prescrire votre token et vous connecter
Jeton.
token = 'blaBlaBLAblaBLABLABLAblabla'
Se connecter
clientLogin = 'e-66666666'
- Nous ajustons le corps de la demande pour nous-mêmes.
De cela
body = { "params": { "SelectionCriteria": { "DateFrom": "_", "DateTo": "_" }, "FieldNames": [ "Date", "CampaignName", "LocationOfPresenceName", "Impressions", "Clicks", "Cost" ], "ReportName": u("_"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "CUSTOM_DATE", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO"
Le faire
body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": « ", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } }
Dans
SelectionCriteria, nous écrivons comment nous allons sélectionner les données. Par défaut, 2 dates y sont inscrites, mais afin de ne pas avoir à les modifier constamment, nous remplacerons la période par «5 derniers jours».
Nous définissons le filtre pour les données . Ceci est principalement nécessaire pour ne pas obtenir de valeurs vides. Le problème est que Direct affiche les données manquantes sous la forme de deux inconvénients, en raison desquels le type de données de la colonne entière change, après quoi vous ne pouvez pas effectuer d'opérations mathématiques sans gestes inutiles.
FieldNames Nous écrivons ici les données dont vous avez besoin. J'ai enregistré les champs que j'utilise pour l'analyse, votre liste peut différer.
ReportType Le type de rapport est écrit dans ce champ, pour les campagnes ce rapport est nécessaire.
Vous devriez obtenir quelque chose comme ça.
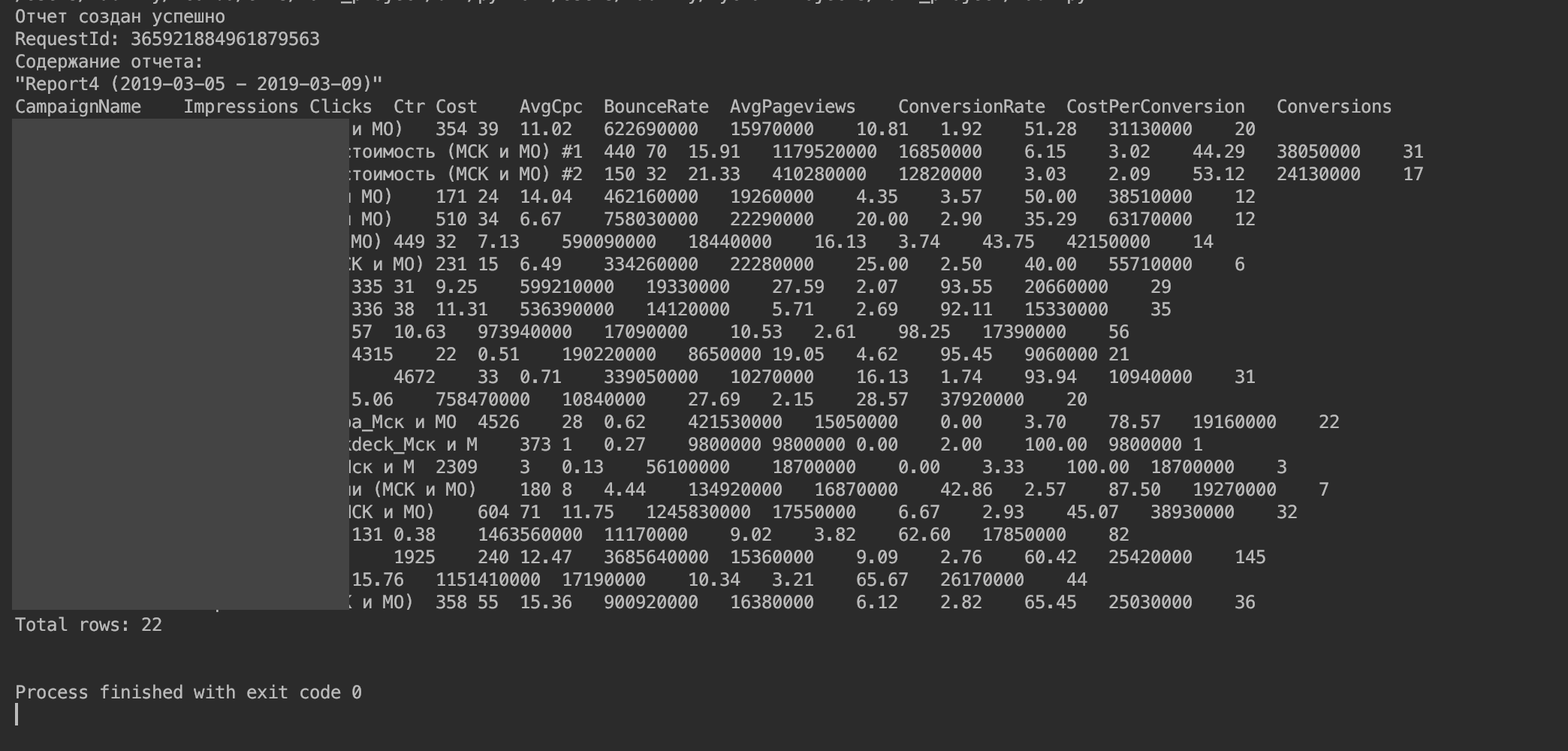
5. Importez les données dans un DataFrame.
(Un DataFrame est probablement la façon la plus appropriée de travailler avec ces données.)
J'ai pu implémenter cette fonction en écrivant et en lisant un fichier csv.
Nous trouvons dans la requête la pièce qui est responsable de la sortie des statistiques - c'est «req.text».
Nous supprimons la sortie standard du programme pour l'écriture dans le fichier. Pour ce faire, modifiez toutes les conclusions du code 200.
print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print(" : \n{}».format(u(req.text)))
Le:
format(u(req.text))
Maintenant, importez la réponse du serveur dans le DataFrame.
file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,)
Pas à pas:
- Ouvrez (et créez automatiquement) le fichier cashe.csv pour l'écriture
- Nous y écrivons la réponse du serveur
- Fermez le fichier
- Ouvrez le fichier en tant que DataFrame (spécifiez le nom du fichier, dans quelle ligne se trouvent les en-têtes de table, quel est le diviseur entre les données, dans quelle colonne se trouve l'index)
Il s'est avéré ce qui suit:
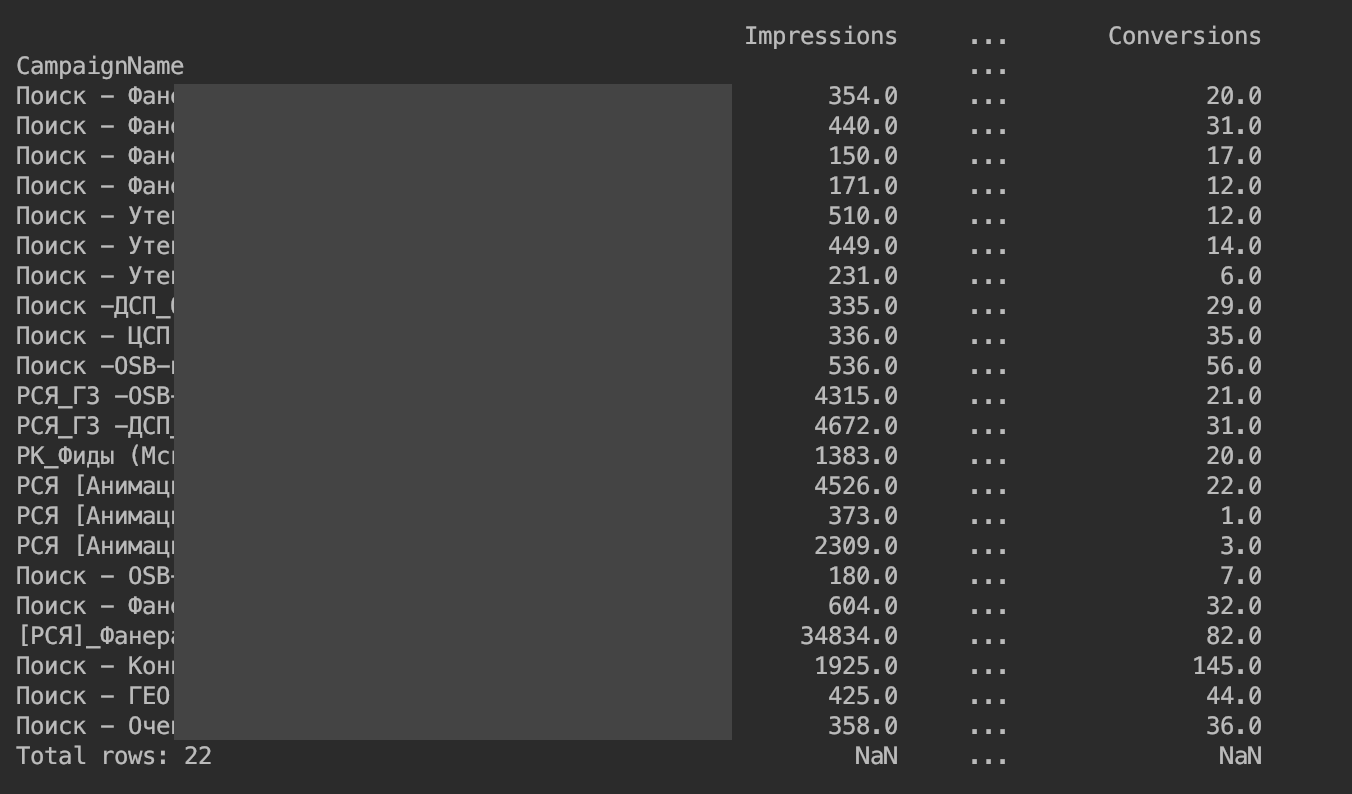
Nous supprimons la restriction sur la sortie des colonnes:
pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1)
Maintenant, tout est montré:
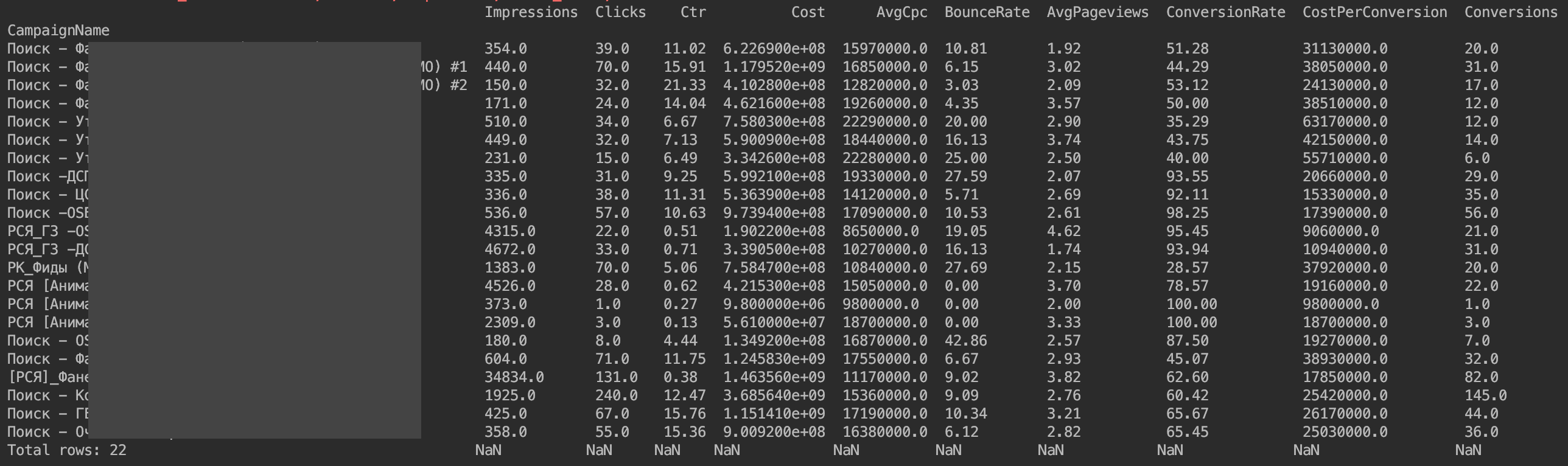
Le seul problème est que les valeurs monétaires ne sont pas affichées comme elles le souhaiteraient. Ce sont les fonctionnalités de l'implémentation de l'API Yandex.Direct. Il suffit de diviser les valeurs monétaires par 1 000 000.
f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000
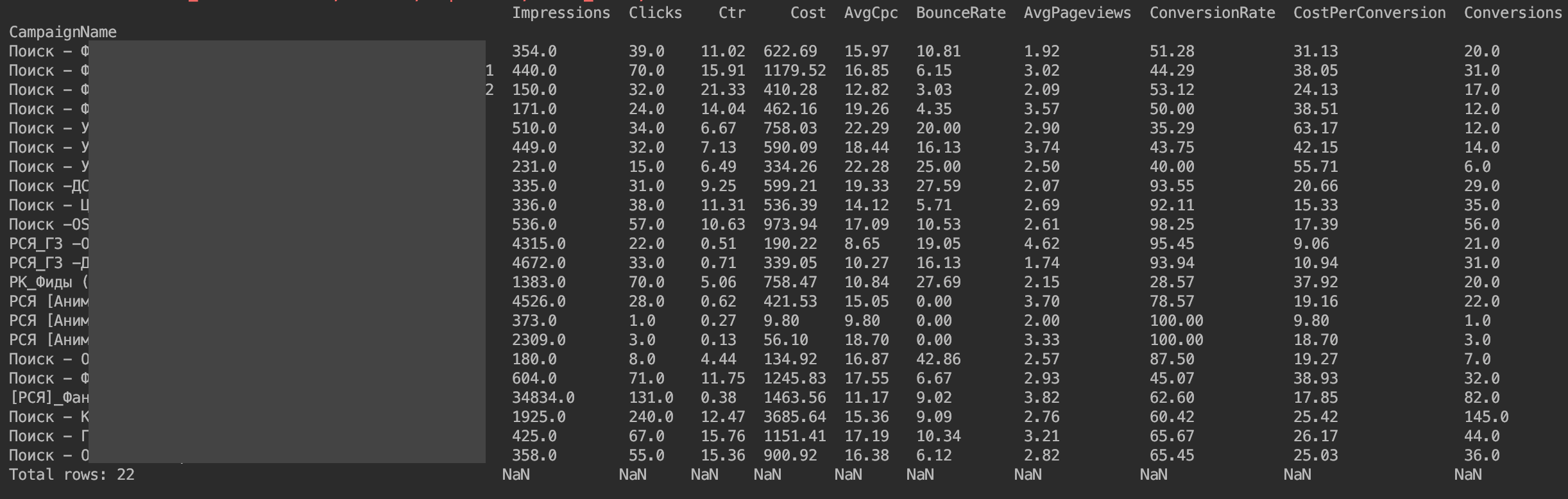
Je suggère également de trier immédiatement en fonction du nombre de clics
f=f.sort_values(by=['Clicks'], ascending=False)
Nous avons donc préparé DataFrame pour l'analyse
Pour ma part, j'ai écrit des demandes de statistiques similaires par jour et par campagne, afin d'être toujours au courant des écarts de trafic et de comprendre où l'écart s'est produit approximativement.
Merci de votre attention.
Code de fin: import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1) # UTF-8 Python 3, Python 2 import sys if sys.version_info < (3,): def u(x): try: return x.encode("utf8") except UnicodeDecodeError: return x else: def u(x): if type(x) == type(b''): return x.decode('utf8') else: return x # --- --- # Reports JSON- () ReportsURL = 'https://api.direct.yandex.com/json/v5/reports' # OAuth- , token = ' ' # # , clientLogin = ' ' # --- --- # HTTP- headers = { # OAuth-. Bearer "Authorization": "Bearer " + token, # "Client-Login": clientLogin, # "Accept-Language": "ru", # "processingMode": "auto" # # "returnMoneyInMicros": "false", # # "skipReportHeader": "true", # # "skipColumnHeader": "true", # # "skipReportSummary": "true" } # body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } } # JSON body = json.dumps(body, indent=4) # --- --- # HTTP- 200, # HTTP- 201 202, while True: try: req = requests.post(ReportsURL, body, headers=headers) req.encoding = 'utf-8' # UTF-8 if req.status_code == 400: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(u(body))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 200: format(u(req.text)) break elif req.status_code == 201: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 202: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 500: print(" . , ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 502: print(" .") print(", - .") print("JSON- : {}".format(body)) print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break else: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(body)) print("JSON- : \n{}".format(u(req.json()))) break # , API except ConnectionError: # print(" API") # break # - except: # print(" ") # break file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,) f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000 f=f.sort_values(by=['Clicks'], ascending=False) print(f)