Nous continuons à publier des vidéos et des transcriptions des meilleurs reportages de la conférence
PGConf.Russia 2019 . Un rapport d'Oleg Bartunov sur le thème «Postgres professionnels» a ouvert la partie plénière de la conférence. Il révèle l'histoire du SGBD Postgres, la contribution russe au développement, les caractéristiques de l'architecture.
Documents précédents de cette série: «Erreurs typiques lors de l'utilisation de PostgreSQL» par Ivan Frolkov, parties
1 et
2 .

Je vais parler des Postgres professionnels. Veuillez ne pas confondre avec l'entreprise que je représente actuellement - Postgres Professional.

Je vais vraiment parler de la façon dont Postgres, qui a commencé comme un développement académique amateur, est devenu professionnel - la façon dont nous le voyons maintenant. Je ne ferai qu'exprimer mon opinion personnelle, elle ne reflète pas l'opinion de notre entreprise ni d'aucun groupe.

Il se trouve que j'utilise et ne fais pas d'extraits de Postgres, mais en continu de 1995 à nos jours. Toute son histoire s'est passée sous mes yeux, je participe aux principaux événements.
L'histoire
Sur cette diapositive, j'ai brièvement décrit les projets auxquels j'ai participé. Beaucoup d'entre eux vous sont familiers. Et je vais tout de suite commencer l’histoire de Postgres avec une image que j’ai peinte il y a de nombreuses années et puis je l’ai dessinée - le nombre de versions augmente et augmente. Il reflète l'évolution des bases de données relationnelles. À gauche, si quelqu'un ne le sait pas, c'est
Michael Stonebreaker , qui s'appelle le père de Postgres. Voici nos premiers développeurs "nucléaires". La personne assise à droite est Vadim Mikheev de Krasnoyarsk, il a été l'un des premiers développeurs principaux.
Je vais commencer l'histoire du modèle relationnel avec IBM, qui a apporté une énorme contribution à l'industrie. C'est IBM qui a travaillé pour
Edgar Codd , le premier livre blanc sur
IBM System R est sorti de ses entrailles - c'était la première base de données relationnelle. Mike Stonebreaker travaillait à l'époque à Burkeley. Il a lu cet article et a pris feu avec ses gars: nous devons créer une base de données.

En ces années - au début des années 70 - comme vous le pensez, il n'y avait pas beaucoup d'ordinateurs. Il y avait un PDP-11 pour tout le département d'informatique de Berkeley, et tous les étudiants et professeurs se sont battus pour le temps machine. Cette machine était principalement utilisée pour les calculs. J'ai moi-même travaillé comme ça quand j'étais jeune: vous donnez une tâche à l'opérateur, il la démarre. Mais les étudiants et les développeurs voulaient un travail interactif. C'était notre rêve - s'asseoir à la télécommande, entrer dans les programmes, les déboguer. Et lorsque Mike Stonebreaker et ses amis ont fait la première base, ils l'ont appelé
Ingres - le système de récupération Grafic interactif. Les gens ne comprenaient pas: pourquoi interactif? Et ce n'est que le rêve de ses développeurs qui s'est réalisé. Ils avaient un client de console avec lequel ils pouvaient travailler avec Ingres. Il a donné beaucoup de notre industrie. Voyez-vous combien de flèches il y a d'Ingres? Ce sont les bases de données qu'il a influencées, qui ont falsifié son code. Michael Stonebreaker avait de nombreux étudiants en développement qui ont quitté puis développé
Sybase et
MS SQL ,
NonStop SQL ,
Illustra ,
Informix .
Quand Ingres a tellement développé qu'il est devenu commercialement intéressant,
Illustra a été formé (c'était en 1992), et le code du SGBD
Illustra a été acheté par
Informix , qui a ensuite été mangé par
IBM , et donc le code est allé à
DB2 . Mais qu'est-ce qui a intéressé
IBM à
Ingres ? Tout d'abord, l'extensibilité - ces idées révolutionnaires que Michael Stonebreaker a énoncées dès le début, pensant que la base de données devrait être prête à résoudre tous les problèmes commerciaux. Et pour cela, il est nécessaire que vous puissiez ajouter vos types de données, méthodes d'accès et fonctions à la base de données. Pour nous, postgresistes, cela semble naturel. En ces années, ce fut une révolution. Depuis l'époque d'Ingres et Postgres, ces fonctionnalités, cette fonctionnalité sont devenues la norme de facto pour toutes les bases de données relationnelles. Maintenant, toutes les bases de données ont des fonctions utilisateur, et lorsque Stonebreaker a écrit que les fonctions utilisateur étaient nécessaires,
Oracle , par exemple, a crié que c'était dangereux, et que cela ne pouvait pas être fait car les utilisateurs pouvaient endommager les données. Nous voyons maintenant que des fonctions définies par l'utilisateur existent dans toutes les bases de données, que vous pouvez créer vos propres agrégats et types de données.

Postgres s'est développé comme un développement académique, ce qui signifie: il y a un professeur, il a une bourse de développement, des étudiants et des étudiants diplômés qui travaillent avec lui. Une base sérieuse, prête pour la production, ne peut se faire comme ça. Cependant, la dernière version de Berkeley -
Postgres95 - a déjà ajouté
SQL . Les étudiants développeurs à cette époque ont déjà commencé à travailler chez Illustra, ont créé Informix et ont perdu tout intérêt pour le projet. Ils ont dit: nous avons Postgres95, prenez-le qui en a besoin! Je me souviens très bien de tout cela car j'étais moi-même de ceux qui ont reçu cette lettre: il y avait une liste de diffusion, et il y avait moins de 400 abonnés. La communauté
Postgres95 a commencé avec ces 400 personnes. Nous avons tous voté ensemble pour prendre ce projet. Nous avons trouvé un passionné qui a récupéré le serveur CVS et nous avons tout traîné au Panama, car les serveurs étaient là.
L'histoire de
PostgreSQL [simplement Postgres ci-après] commence avec la version 6.0, puisque les versions 1, 4, 5 étaient toujours Postgres95. Le 3 avril 1997, notre logo est apparu - un éléphant. Avant cela, nous avions différents animaux. Sur ma page, par exemple,
il y avait un guépard depuis longtemps , laissant entendre que Postgres est très rapide. Ensuite, une question a été soulevée dans la liste de diffusion: notre grande base de données a besoin d'un animal sérieux. Et quelqu'un a écrit: que ce soit un éléphant. Tout le monde a voté ensemble, puis nos gars de Saint-Pétersbourg ont dessiné ce logo. Au départ, c'était un éléphant dans un diamant - si vous creusez plus profondément dans une machine à voyager dans le temps, vous le verrez. L'éléphant a été choisi car les éléphants ont une très bonne mémoire. Même Agatha Christie a une histoire «Les éléphants peuvent se souvenir»: l'éléphant est très vengeur, il s'est souvenu de l'infraction pendant environ cinquante ans, puis a écrasé le délinquant. Le diamant a ensuite été séparé, le motif vectorisé, et le résultat a été cet éléphant. C'est donc l'une des premières contributions russes à Postgres.

Cheetah a remplacé Elephant dans le diamant:

Stades de développement de Postgres
La première tâche a été de stabiliser son travail. La communauté a adopté le code source pour les développeurs universitaires. Qu'est-ce qui n'était pas là! Ils ont commencé à pelleter tout cela pour compiler décemment. Sur cette diapositive, j'ai souligné l'année 1997, version 6.1 - l'internationalisation y figurait. Je l'ai souligné non pas parce que je l'ai fait moi-même (c'était vraiment mon premier patch), mais parce que c'était une étape importante. Vous êtes déjà habitué au fait que Postgres fonctionne avec n'importe quelle langue, dans n'importe quel lieu - partout dans le monde. Et puis il n'a compris que l'ASCII, c'est-à-dire pas de 8 bits, pas de langues européennes, pas de russe. Après avoir découvert cela, en suivant les principes de l'open source, je viens de prendre et de prendre en charge les paramètres régionaux. Et grâce à ce travail, Postgres est entré dans le monde. Après moi, le japonais
Tatsuo Ishii a pris en charge les encodages multi-octets, et Postgres est devenu véritablement mondial.
En 2005,
le support de
Windows a été introduit. Je me souviens de ces débats houleux quand ils en discutaient dans la liste de diffusion. Tous les développeurs étaient des gens normaux, ils travaillaient sous
Unix . Vous applaudissez en ce moment, et de la même manière les gens ont réagi alors. Et voté contre. Cela a duré des années. De plus,
SRA Computers a sorti son
Powergres , un port natif de Windows, quelques années plus tôt. Mais c'était un produit purement japonais. Lorsqu'en 2005, dans la 8e version, nous avons obtenu le support de Windows, il s'est avéré que c'était une étape importante: la communauté était gonflée. Il y avait beaucoup de gens et beaucoup de questions stupides, mais la communauté est devenue grande, nous avons attrapé des utilisateurs de vinduzovye.
En 2010, nous avions une réplication intégrée. C'est une douleur. Je me souviens combien d'années les gens ont lutté pour que la réplication soit à Postgres. Au début, tout le monde a dit: nous n'avons pas besoin de réplication, ce n'est pas une question de base de données, c'est une question d'utilitaires externes. Si quelqu'un se souvient,
Slony a fait Jan Wieck. Soit dit en passant, les «éléphants» provenaient également de la langue russe: Jan m'a demandé combien «d'éléphants» seraient en russe, et j'ai répondu: «éléphants». Il a donc créé Slony. Ces éléphants fonctionnaient comme une réplication logique des déclencheurs, leur configuration était un cauchemar - les vétérans s'en souviennent. De plus, tout le monde a écouté pendant longtemps
Tom Lane , qui, je m'en souviens, a crié désespérément: pourquoi devrions-nous compliquer le code avec la réplication si cela peut être fait en dehors de la base? Mais en conséquence, la réplication en ligne est toujours apparue. Cela a immédiatement généré un grand nombre d'utilisateurs d'entreprise, car avant cela, ces utilisateurs ont dit: comment pouvons-nous même vivre sans réplication? C'est impossible!
En 2014, jsonb est apparu. C'est mon travail,
Fedor Sigaev et
Alexander Korotkov . Et les gens ont également crié: pourquoi en avons-nous besoin? En général, nous avions déjà le magasin, que nous avons fait en 2003, et en 2006, il est entré à Postgres. Les gens l'ont utilisé à merveille dans le monde entier, l'ont adoré, et si vous tapez
hstore sur google, une énorme quantité de documents est apparue. Extension très populaire. Et nous avons fortement promu l'idée de données non structurées dans Postgres. Dès le début de mon travail, cela m'intéressait juste et quand nous avons fait
jsonb , j'ai reçu beaucoup de lettres de remerciements et de questions. Et la communauté a
des utilisateurs
NoSQL ! Avant jsonb, les personnes zombifiées par battage médiatique se sont tournées vers la valeur-clé de la base de données. En même temps, ils ont été forcés de sacrifier l'intégrité, l'identité
ACID . Et nous leur avons donné l'opportunité, sans rien sacrifier, de travailler avec leur belle json. La communauté s'est de nouveau fortement développée.
En 2016, nous avons obtenu l'exécution de requêtes parallèles. Si quelqu'un ne le sait pas, ce n'est bien sûr pas pour
OLTP. Si vous avez une machine chargée, tous les noyaux sont déjà occupés. L'exécution de requêtes simultanées est précieuse pour
les utilisateurs
OLAP . Et ils l'ont apprécié, c'est-à-dire qu'un certain nombre d'utilisateurs
OLAP ont commencé à arriver dans la communauté.
Viennent ensuite les processus cumulatifs. En 2017, nous avons reçu la réplication logique et le partitionnement déclaratif - c'était aussi une étape importante et sérieuse car la réplication logique a permis de créer des systèmes très, très intéressants, les gens ont eu une liberté illimitée pour leur imagination et ont commencé à créer des clusters. En utilisant le partitionnement déclaratif, il est devenu possible de ne pas créer de partitions manuellement, mais en utilisant SQL.
En 2018, dans la 11e version, nous avons obtenu
JIT . Qui ne sait pas, c'est le compilateur Just In Time: vous compilez des requêtes, et cela peut vraiment accélérer considérablement l'exécution. Ceci est important pour accélérer les requêtes lentes car les requêtes rapides sont déjà rapides et les frais généraux pour la compilation sont toujours importants.
En 2019, la chose la plus fondamentale à laquelle nous nous attendons est le
stockage enfichable, une API permettant aux développeurs de créer leurs propres référentiels, dont un exemple est
zheap - le référentiel
qu'EnterpriseDB développe.
Et voici notre développement: SQL / JSON. J'espérais vraiment que
Sasha Korotkov l' engagerait avant la conférence, mais il y avait des problèmes là-bas, et maintenant nous espérons que nous obtiendrons tout de même
SQL / JSON cette année. Les gens l'attendent depuis deux ans [une partie importante du correctif SQL / JSON: jsonpath a été validée maintenant, cela est décrit en détail
ici ].

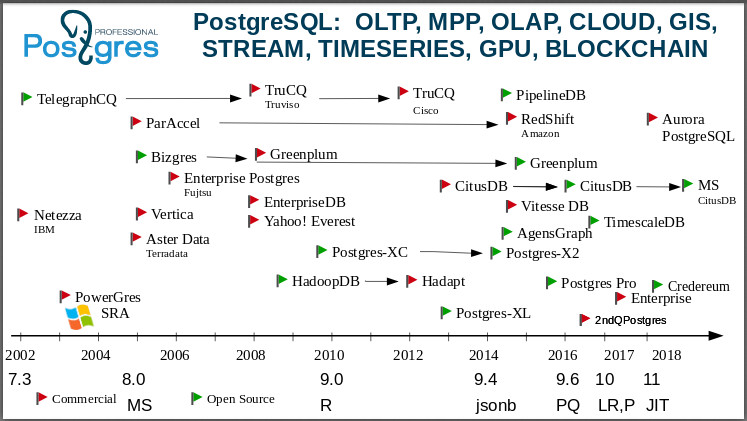
Ensuite, je passe à une diapositive qui montre: Postgres est une base de données universelle. Vous pouvez étudier cette image pendant des heures, raconter un tas d'histoires sur l'émergence d'entreprises, le rachat, la mort d'entreprises. Je commencerai en l'an 2000. L'une des premières fourches de Postgres est IBM
Netezza . Imaginez: le «Blue Giant» a pris le code Postgres et construit une base pour OLAP pour supporter sa BI!
Voici un fork de
TelegraphCQ : déjà en 2000, les gens ont créé une base de données de streaming basée sur Postgres à Berkeley. Si quelqu'un ne le sait pas, il s'agit d'une base de données qui ne s'intéresse pas aux données elles-mêmes, mais à leurs agrégats. Maintenant, il y a beaucoup de tâches où vous n'avez pas besoin de connaître chaque valeur, par exemple la température à un moment donné, mais vous avez besoin d'une valeur moyenne dans cette région. Et dans TelegraphCQ, ils ont pris cette idée (également née à Berkeley), l'une des idées les plus avancées de l'époque, et ont développé une base basée sur Postgres. Il a ensuite évolué et, en 2008, sur la base de cela, un produit commercial a été lancé - la base
TruCQ , dont le propriétaire est désormais
Cisco .
J'ai oublié de dire que toutes les fourches ne sont pas sur cette page, il y en a deux fois plus. J'ai choisi le plus important et le plus intéressant pour ne pas encombrer l'image. La
page wiki postgresql répertorie toutes les fourches. Qui connaît une base de données open source qui aurait autant de fourches? Il n'y a pas de telles bases.
Postgres diffère des autres bases de données non seulement par sa fonctionnalité, mais aussi par le fait
une communauté très intéressante, il accepte normalement les fourches. Dans le monde de l'open source, c'est généralement accepté: j'ai fait un fork parce que j'étais offensé - vous ne m'avez pas soutenu, j'ai donc décidé de mener mon propre développement. Dans le monde post-grec, l'apparition d'une fourchette signifie: certaines personnes ou une entreprise ont décidé de faire un prototype et de tester la fonctionnalité qu'ils ont inventée, pour expérimenter. Et si vous avez de la chance, créez une base commerciale qui peut être vendue aux clients, offrez-leur un service, etc. En même temps, en règle générale, les développeurs de toutes ces fourches rendent leurs réalisations et leurs correctifs à la communauté. Le produit de notre entreprise est également un fork, et il est clair que nous avons renvoyé un tas de patchs à la communauté. Dans la dernière version, la 11e, nous avons renvoyé plus de 100 correctifs à la communauté. Si vous regardez ses notes de version, alors il y aura 25 noms de nos employés. Il s'agit d'un comportement communautaire normal. Nous utilisons la version communautaire et fabriquons notre fourchette afin de tester nos idées ou de donner des fonctionnalités aux clients avant que la communauté mûrisse pour son adoption. Forks dans la communauté Postgres est le bienvenu.
Le célèbre
Vertica est venu du
C-Store - également issu de Postgres. Certaines personnes affirment que Vertica n'avait pas du tout de code source Postgres, mais uniquement le support du protocole postgres. Néanmoins, il est de coutume de le classer comme une fourche post-grecque.
Greenplum . Vous pouvez maintenant le télécharger et l'utiliser en tant que cluster. Il provient de
Bizgres , une base de données massivement parallèle. Ensuite, il a été acheté par Greenplum, est devenu et est resté longtemps commercial. Mais vous voyez que vers 2015, ils ont réalisé que le monde a changé: le monde évolue vers des protocoles ouverts, des communautés ouvertes, des bases de données ouvertes. Et ils ont ouvert les codes Greenplum. Maintenant, ils rattrapent activement Postgres parce qu'ils ont pris beaucoup de retard, bien sûr. Ils ont bougé à 8,2, et maintenant ils disent qu'ils ont rattrapé 9,6.
Nous aimons et n'aimons pas tous
Amazon . Vous savez comment cela s'est produit. C'est arrivé sous mes yeux. Il y avait une entreprise, il y avait
ParAccel avec le traitement vectoriel, également sur Postgres - un produit communautaire, ouvert. En 2012, le rusé Amazon a acheté le code source et a littéralement annoncé six mois plus tard que nous avions désormais
RDS sur Amazon. Nous leur avons alors demandé, ils ont longtemps hésité, mais il s'est avéré que c'était Postgres. RDS vit toujours, et c'est l'un des services les plus populaires d'Amazon, ils ont environ 7 000 bases qui y tournent. Mais ils ne se sont pas calmés à ce sujet, et en 2010, Amazon Aurora est apparu - Postgres 10 avec une histoire réécrite qui est directement cousue dans l'infrastructure d'Amazon, dans leur stockage distribué.
Jetez un œil à
Teradata .
OLAP , une grande et bonne vieille société d'analyse. Après le G8 [PostgreSQL 8.0],
Aster Data est apparu.
Hadoop : nous avons Postgres sur Hadoop -
HadoopDB . Après un certain temps, il est devenu une base
Hadapt fermée appartenant à
Teradata . Si vous voyez Hadapt, sachez ce que Postgres est à l'intérieur.
Un destin très intéressant avec
Citus . Tout le monde sait qu'il s'agit de Postgres distribué pour l'analyse en ligne. Il ne prend pas en charge les transactions.
Citus Data était une startup et Citus était une source fermée, une base de données distincte. Après un certain temps, les gens ont réalisé qu'il valait mieux vivre avec la communauté, s'ouvrir. Et ils ont fait beaucoup pour devenir juste une extension de Postgres. De plus, ils ont déjà commencé à faire des affaires sur la fourniture de leurs services cloud. Vous le savez tous déjà:
MS Citus est écrit ici parce que
Microsoft les a achetés, il y a littéralement deux semaines. Probablement, afin de prendre en charge Postgres sur son
Azure , c'est-à-dire que Microsoft joue également ces jeux. Postgres fonctionne sur Azure et l'équipe de développement Citus a rejoint les développeurs MS.
En général, les processus d'achat d'entreprises post-gres se sont récemment intensifiés. Juste après que Microsoft a acheté Citus, une autre société postgres,
credativ , a acheté
OmniTI pour renforcer sa présence sur le marché. Ce sont deux sociétés solides et bien connues. Et Amazon a acheté
OpenSCG . Le monde des postgres est en train de changer, et je vais vous montrer pourquoi il y a tant d'intérêt pour Postgres.
Le
célèbre TimescaleDB était également une base de données distincte, mais c'est maintenant une extension: vous prenez Postgres et installez timescaledb comme une extension et obtenez une base de données qui casse toutes sortes de bases de données spécialisées.
Il y a aussi Postgres XL, il y a des clusters qui se développent.
Ici en 2015, j'ai mis notre fourche:
Postgres Pro . Nous avons
Postgres Pro Enterprise , il existe une version certifiée, nous prenons en charge
1C et nous sommes reconnus par
1C . Si quelqu'un veut essayer Postgres Pro Enterprise, vous pouvez prendre le kit de distribution gratuitement et si vous en avez besoin pour le travail, vous pouvez l'acheter.
Nous avons créé
Credereum , une base de données prototype avec le support de la blockchain. Maintenant, nous attendons que les gens mûrissent pour commencer à l'utiliser.
Voyez à quel point l'image est grande et intéressante. Je ne parle même pas de
Yahoo! Everest avec stockage sur colonne, avec des pétaoctets de données dans Yahoo! - c'était la 2008e année. Ils ont même parrainé notre conférence au Canada, sont venus là-bas, quelque part j'ai même une chemise de là :)
Il y a aussi
PipelineDB . Il a également commencé comme une base de données fermée, mais maintenant ce n'est plus qu'une extension. Nous voyons que Citus, TimescaleDB et PipelineDB sont comme des bases de données distinctes, mais en même temps, ils existent en tant qu'extensions, c'est-à-dire que vous prenez le Postgres standard et compilez l'extension. PipelineDB est une continuation de l'idée de bases de données de flux. Vous souhaitez travailler avec des flux?
Prenez Postgres, prenez PipelineDB et vous pouvez travailler.De plus, il existe des extensions qui vous permettent de travailler avec le GPU . Voir le titre? J'ai montré qu'il existe un écosystème qui couvre un grand nombre de types de données et de charges différents. Par conséquent, nous disons que Postgres est une base de données universelle.Base de contacts préférés
 La diapositive suivante a de grands noms. Tous les nuages les plus célèbres du monde prennent en charge Postgres. En Russie, Postgres est soutenu par de grandes entreprises publiques. Ils l'utilisent et nous les servons en tant que clients.
La diapositive suivante a de grands noms. Tous les nuages les plus célèbres du monde prennent en charge Postgres. En Russie, Postgres est soutenu par de grandes entreprises publiques. Ils l'utilisent et nous les servons en tant que clients. Il existe déjà de nombreuses extensions et de nombreuses applications, Postgres est donc la bonne base de données à partir de laquelle le projet démarre. Je dis toujours aux startups: les gars, vous n'avez pas besoin de prendre la base de données NoSQL . Je comprends que vous le vouliez vraiment, mais commencez par Postgres. Si vous n'en avez pas assez, vous pouvez toujours décrocher un service et le confier à une base de données spécialisée. En plus de l'universalité, Postgres a un autre avantage: une licence BSD très libérale, qui vous permet de tout faire avec votre base de données.Tout ce que vous voyez sur cette diapositive est accessible car Postgres est une base de données extensible, et cette extensibilité est intégrée immédiatement, directement dans l'architecture de la base de données. Lorsque Michael Stonebreaker a écrit sur Postgres dans son premier article à son sujet (il a été écrit par lui en 1984, je cite ici un article de 1987), il a déjà parlé de l'extensibilité en tant que composant le plus important de la fonctionnalité de base de données. Et cela, comme on dit, a déjà été testé par le temps. Vous pouvez ajouter vos propres fonctions, vos types de données, opérateurs, accès aux index (c'est-à-dire les méthodes d'accès optimisées), vous pouvez écrire vos procédures dans un très grand nombre de langues. Nous avons un wrapper de données étrangères ( FDW ), c'est-à-dire des interfaces pour travailler avec différents référentiels, fichiers, vous pouvez vous connecter à Oracle , MySQLet d'autres bases.Je veux donner un exemple de ma propre expérience personnelle. J'ai travaillé avec Postgres et quand quelque chose manquait dans Postgres, mes collègues et moi avons simplement ajouté cette fonctionnalité. Nous avions besoin de travailler, par exemple, avec la langue russe, et nous avons créé une locale 8 bits. C'était un projet Rambler . Au fait, il était alors dans le top 5. Ramblera été le premier grand projet mondial à être lancé sur Postgres. Les tableaux dans Postgres étaient dès le début, mais ils étaient tels que rien ne pouvait être fait avec eux, c'était juste une ligne de texte dans laquelle les tableaux étaient stockés. Nous avons ajouté des opérateurs, créé des index et maintenant les tableaux font partie intégrante de la fonctionnalité Postgres, et beaucoup d'entre vous les utilisent sans se soucier de leur rapidité - et c'est très bien. Ils disaient que les tableaux ne sont plus un modèle relationnel traditionnel, ils ne satisfont pas aux formes normales classiques. Maintenant, les gens sont déjà habitués à utiliser des tableaux.
Il existe déjà de nombreuses extensions et de nombreuses applications, Postgres est donc la bonne base de données à partir de laquelle le projet démarre. Je dis toujours aux startups: les gars, vous n'avez pas besoin de prendre la base de données NoSQL . Je comprends que vous le vouliez vraiment, mais commencez par Postgres. Si vous n'en avez pas assez, vous pouvez toujours décrocher un service et le confier à une base de données spécialisée. En plus de l'universalité, Postgres a un autre avantage: une licence BSD très libérale, qui vous permet de tout faire avec votre base de données.Tout ce que vous voyez sur cette diapositive est accessible car Postgres est une base de données extensible, et cette extensibilité est intégrée immédiatement, directement dans l'architecture de la base de données. Lorsque Michael Stonebreaker a écrit sur Postgres dans son premier article à son sujet (il a été écrit par lui en 1984, je cite ici un article de 1987), il a déjà parlé de l'extensibilité en tant que composant le plus important de la fonctionnalité de base de données. Et cela, comme on dit, a déjà été testé par le temps. Vous pouvez ajouter vos propres fonctions, vos types de données, opérateurs, accès aux index (c'est-à-dire les méthodes d'accès optimisées), vous pouvez écrire vos procédures dans un très grand nombre de langues. Nous avons un wrapper de données étrangères ( FDW ), c'est-à-dire des interfaces pour travailler avec différents référentiels, fichiers, vous pouvez vous connecter à Oracle , MySQLet d'autres bases.Je veux donner un exemple de ma propre expérience personnelle. J'ai travaillé avec Postgres et quand quelque chose manquait dans Postgres, mes collègues et moi avons simplement ajouté cette fonctionnalité. Nous avions besoin de travailler, par exemple, avec la langue russe, et nous avons créé une locale 8 bits. C'était un projet Rambler . Au fait, il était alors dans le top 5. Ramblera été le premier grand projet mondial à être lancé sur Postgres. Les tableaux dans Postgres étaient dès le début, mais ils étaient tels que rien ne pouvait être fait avec eux, c'était juste une ligne de texte dans laquelle les tableaux étaient stockés. Nous avons ajouté des opérateurs, créé des index et maintenant les tableaux font partie intégrante de la fonctionnalité Postgres, et beaucoup d'entre vous les utilisent sans se soucier de leur rapidité - et c'est très bien. Ils disaient que les tableaux ne sont plus un modèle relationnel traditionnel, ils ne satisfont pas aux formes normales classiques. Maintenant, les gens sont déjà habitués à utiliser des tableaux. Lorsque nous avions besoin d'une recherche en texte intégral, nous l'avons fait. Lorsque nous avions besoin de stocker des données de nature différente, nous avons créé l'extension hstore, et de nombreuses personnes ont commencé à l'utiliser: cela a permis de créer des schémas de base de données flexibles afin de pouvoir être de plus en plus rapide. Nous avons créé un index GIN pour que la recherche en texte intégral fonctionne rapidement. Nous avons fait des trigrammes ( pg_trgm ). Made NoSQL. Et tout cela est dans ma mémoire, tous mes propres besoins.
Lorsque nous avions besoin d'une recherche en texte intégral, nous l'avons fait. Lorsque nous avions besoin de stocker des données de nature différente, nous avons créé l'extension hstore, et de nombreuses personnes ont commencé à l'utiliser: cela a permis de créer des schémas de base de données flexibles afin de pouvoir être de plus en plus rapide. Nous avons créé un index GIN pour que la recherche en texte intégral fonctionne rapidement. Nous avons fait des trigrammes ( pg_trgm ). Made NoSQL. Et tout cela est dans ma mémoire, tous mes propres besoins. L'extensibilité fait de Postgres une base de données unique, une base de données universelle avec laquelle vous pouvez commencer à travailler et ne pas avoir peur de vous retrouver sans support. Regardez combien de personnes nous avons ici - c'est déjà un marché! Malgré le fait que les bases de données graphiques, les bases de données documentaires, les séries chronologiques et ainsi de suite sont désormais très recherchées: la plupart utilisent encore des bases de données relationnelles. Ils dominent, c'est 75% du marché des bases de données, et le reste sont des bases de données exotiques, un peu par rapport aux bases de données relationnelles.
L'extensibilité fait de Postgres une base de données unique, une base de données universelle avec laquelle vous pouvez commencer à travailler et ne pas avoir peur de vous retrouver sans support. Regardez combien de personnes nous avons ici - c'est déjà un marché! Malgré le fait que les bases de données graphiques, les bases de données documentaires, les séries chronologiques et ainsi de suite sont désormais très recherchées: la plupart utilisent encore des bases de données relationnelles. Ils dominent, c'est 75% du marché des bases de données, et le reste sont des bases de données exotiques, un peu par rapport aux bases de données relationnelles. Si vous regardez le rapport des bases de données open source à commercial, puis,selon DB-moteurs, nous verrons que le nombre de bases de données open source est presque égal au nombre de bases de données commerciales. Et nous constatons que les bases de données open source (ligne bleue) se développent et que les bases de données commerciales (rouge) sont en baisse. C'est la direction du développement de toute la communauté informatique, la direction de l'ouverture. Maintenant, bien sûr, il est indécent de faire référence à Gartner , mais je le dirai quand même: ils prédisent que d'ici 2022, 70% utiliseront des bases de données ouvertes et jusqu'à 50% des systèmes existants migreront vers l'open source.Regardez ce pomosomère: on voit que Postgres s'appelle la base de données de 2018. L'année dernière, elle a également été la première expertise indépendante de DB-Engines. Le classement montre que Postgres est vraiment en avance sur le reste. C'est en termes absolus à la 4ème place, mais regardez comment ça pousse. Bien sûr. Sur la diapositive, il s'agit d'une ligne bleue. Le reste - MySQL, Oracle, MS SQL - s'équilibre à son niveau ou commence à se plier.
Si vous regardez le rapport des bases de données open source à commercial, puis,selon DB-moteurs, nous verrons que le nombre de bases de données open source est presque égal au nombre de bases de données commerciales. Et nous constatons que les bases de données open source (ligne bleue) se développent et que les bases de données commerciales (rouge) sont en baisse. C'est la direction du développement de toute la communauté informatique, la direction de l'ouverture. Maintenant, bien sûr, il est indécent de faire référence à Gartner , mais je le dirai quand même: ils prédisent que d'ici 2022, 70% utiliseront des bases de données ouvertes et jusqu'à 50% des systèmes existants migreront vers l'open source.Regardez ce pomosomère: on voit que Postgres s'appelle la base de données de 2018. L'année dernière, elle a également été la première expertise indépendante de DB-Engines. Le classement montre que Postgres est vraiment en avance sur le reste. C'est en termes absolus à la 4ème place, mais regardez comment ça pousse. Bien sûr. Sur la diapositive, il s'agit d'une ligne bleue. Le reste - MySQL, Oracle, MS SQL - s'équilibre à son niveau ou commence à se plier. Hacker News - vous l'avez probablement tous lu ou Y Combinator- des sondages y sont effectués périodiquement, les entreprises y publient leurs offres d'emploi et depuis quelque temps elles réalisent des statistiques. Vous voyez qu'à partir de 2014, Postgres est en avance sur tout le monde. C'était le 1er MySQL, mais Postgres a lentement grandi, et maintenant parmi toute la communauté des hackers (dans le bon sens du terme), il prévaut et se développe encore.
Hacker News - vous l'avez probablement tous lu ou Y Combinator- des sondages y sont effectués périodiquement, les entreprises y publient leurs offres d'emploi et depuis quelque temps elles réalisent des statistiques. Vous voyez qu'à partir de 2014, Postgres est en avance sur tout le monde. C'était le 1er MySQL, mais Postgres a lentement grandi, et maintenant parmi toute la communauté des hackers (dans le bon sens du terme), il prévaut et se développe encore. Le débordement de la pile , aussi, chaque conduite des enquêtes de l'année. Par le plus utilisé, notre Postgres est en bonne troisième place. Par les plus aimés - le deuxième. Ceci est une base de données préférée. Redis n'est pas une base de données relationnelle, mais Postgres relationnel est un favori. Je n'ai pas donné ici l' image la plus redoutée- la base de données la plus terrible, mais vous devinez probablement qui vient en premier. "Base X", comme ils aiment l'appeler en Russie.
Le débordement de la pile , aussi, chaque conduite des enquêtes de l'année. Par le plus utilisé, notre Postgres est en bonne troisième place. Par les plus aimés - le deuxième. Ceci est une base de données préférée. Redis n'est pas une base de données relationnelle, mais Postgres relationnel est un favori. Je n'ai pas donné ici l' image la plus redoutée- la base de données la plus terrible, mais vous devinez probablement qui vient en premier. "Base X", comme ils aiment l'appeler en Russie. Il y a une revue en Russie, une enquête sur nous tous lors de la conférence HighLoad ++ respectée . Elle n'a pas été menée par nous, elle a été faite par Oleg Bunin . Il s'est avéré: en Russie, la base de données Postgres n ° 1.
Il y a une revue en Russie, une enquête sur nous tous lors de la conférence HighLoad ++ respectée . Elle n'a pas été menée par nous, elle a été faite par Oleg Bunin . Il s'est avéré: en Russie, la base de données Postgres n ° 1. Nous demandons à HH.ru pour la deuxième fois de partager avec nous les statistiques de l'emploi de Postgres. Il y a 9 ans, Postgres était 10 fois derrière Oracle, tout le monde criait: donnez-nous des oracleistes. Et nous voyons que l'année dernière nous avons rattrapé notre retard, puis en 2018 il y a eu une croissance. Et si vous vous demandez où trouver un emploi, alors voyez: 2 000 postes vacants sur HH.ru sont Postgres. Ne vous inquiétez pas, assez de travail.
Nous demandons à HH.ru pour la deuxième fois de partager avec nous les statistiques de l'emploi de Postgres. Il y a 9 ans, Postgres était 10 fois derrière Oracle, tout le monde criait: donnez-nous des oracleistes. Et nous voyons que l'année dernière nous avons rattrapé notre retard, puis en 2018 il y a eu une croissance. Et si vous vous demandez où trouver un emploi, alors voyez: 2 000 postes vacants sur HH.ru sont Postgres. Ne vous inquiétez pas, assez de travail. Afin de le rendre plus facile à voir, j'ai pris une photo où j'ai montré les postes vacants Postgres concernant les postes Oracle. Il y en avait moins, à partir de 2018, ils sont déjà à égalité, et maintenant Postgres est déjà devenu un peu plus. Jusqu'à présent, il est un peu déprimant que le nombre absolu de postes vacants Oracle augmente également, ce qui ne devrait pas l'être en principe. Mais, comme on dit, nous sommes assis près de la rive et regardons: quand le cadavre ennemi passera-t-il? Nous faisons juste notre travail.
Afin de le rendre plus facile à voir, j'ai pris une photo où j'ai montré les postes vacants Postgres concernant les postes Oracle. Il y en avait moins, à partir de 2018, ils sont déjà à égalité, et maintenant Postgres est déjà devenu un peu plus. Jusqu'à présent, il est un peu déprimant que le nombre absolu de postes vacants Oracle augmente également, ce qui ne devrait pas l'être en principe. Mais, comme on dit, nous sommes assis près de la rive et regardons: quand le cadavre ennemi passera-t-il? Nous faisons juste notre travail.
Communauté russe Postgres
C'est la communauté la plus organisée de Russie, je n'ai jamais rencontré de telles personnes. Beaucoup de ressources, de chats, où nous communiquons tous sur les affaires. Nous organisons des conférences - deux grandes conférences: à Saint-Pétersbourg et à Moscou, des immeubles d'habitation, nous participons à toutes les grandes conférences internationales, organisons des cours. En fait, ce sont des cours communautaires. Ils ont été préparés par notre entreprise, mais ils sont librement accessibles à chacun d'entre vous, regardez sur youtube notre chaîne ou allez sur notre site internet dans la section "Education", il y a des cours DBA1 , DBA2 , DBA3 , des cours de développement à télécharger gratuitement .Et maintenant, nous lançons la certification - c'est ce que les entreprises demandent, elles veulent avoir des spécialistes certifiés. Et l'employeur le saura: vous êtes un spécialiste certifié.
En fait, ce sont des cours communautaires. Ils ont été préparés par notre entreprise, mais ils sont librement accessibles à chacun d'entre vous, regardez sur youtube notre chaîne ou allez sur notre site internet dans la section "Education", il y a des cours DBA1 , DBA2 , DBA3 , des cours de développement à télécharger gratuitement .Et maintenant, nous lançons la certification - c'est ce que les entreprises demandent, elles veulent avoir des spécialistes certifiés. Et l'employeur le saura: vous êtes un spécialiste certifié. Ils demandent souvent: combien de Postgres russes? La question est un peu déplacée: Postgres est international. Mais je vais parler un peu du drapeau russe. Vous voyez sur la diapositive ce que Vadim Mikheev a fait . Ceux qui connaissent Postgres comprennent que MVCC , WAL , VACUUM et ainsi de suite signifient pour cette base . C'est toute la contribution russe. Il existe maintenant trois principaux développeurs de Postgres, dont deux sont des committers. Sur la diapositive, vous voyez que beaucoup a été fait. Si vous regardez les principales fonctionnalités des notes de version, vous verrez notre contribution. La contribution russe est suffisamment importante. Nous avons travaillé dès le début et continuons à travailler avec la communauté - déjà au niveau de la campagne.
Ils demandent souvent: combien de Postgres russes? La question est un peu déplacée: Postgres est international. Mais je vais parler un peu du drapeau russe. Vous voyez sur la diapositive ce que Vadim Mikheev a fait . Ceux qui connaissent Postgres comprennent que MVCC , WAL , VACUUM et ainsi de suite signifient pour cette base . C'est toute la contribution russe. Il existe maintenant trois principaux développeurs de Postgres, dont deux sont des committers. Sur la diapositive, vous voyez que beaucoup a été fait. Si vous regardez les principales fonctionnalités des notes de version, vous verrez notre contribution. La contribution russe est suffisamment importante. Nous avons travaillé dès le début et continuons à travailler avec la communauté - déjà au niveau de la campagne. Et la contribution de l'entreprise, ce sont les livres. Nous avons 2 cours universitaires Postgres. Vous pouvez aller au magasin et acheter ces livres, vous pouvez enseigner à ces cours, passer des examens, etc. Nous avons des livres pour débutants qui sont distribués, y compris ici. Bon livre très utile. Nous l'avons même traduit en anglais.
Et la contribution de l'entreprise, ce sont les livres. Nous avons 2 cours universitaires Postgres. Vous pouvez aller au magasin et acheter ces livres, vous pouvez enseigner à ces cours, passer des examens, etc. Nous avons des livres pour débutants qui sont distribués, y compris ici. Bon livre très utile. Nous l'avons même traduit en anglais.Postgres professionnels
Passons à la principale. Academic Postgres, quand il a commencé, a été conçu pour plusieurs dizaines d'utilisateurs. La communauté Postgres95 comptait moins de 400 personnes. La communauté était principalement composée de développeurs et de quelques utilisateurs supplémentaires. En même temps - un détail intéressant - les développeurs étaient principalement à la fois des clients et des entrepreneurs. Par exemple, quand j'en avais besoin, j'ai développé pour moi-même et, en même temps, partagé avec tout le monde. Autrement dit, la communauté se développait pour la communauté.
À partir de l'an 2000, un peu plus tôt, les premières sociétés post-Grace ont commencé à apparaître:
GreatBridge ,
2ndQuadrant ,
EDB . Ils ont déjà embauché des développeurs à temps plein qui travaillaient pour la communauté. Les premières fourches d'entreprise et les premiers personnalisateurs d'entreprise sont apparus. Cela a conduit au fait qu'en 2015, le nombre principal - et presque tous les principaux développeurs - étaient déjà organisés dans certaines entreprises. En 2015, notre entreprise a été créée: nous étions les derniers développeurs indépendants gratuits. Maintenant, il n'y a pratiquement plus de telles personnes. La communauté postgres a changé, elle est devenue une entreprise, et maintenant ces entreprises sont le moteur du développement. C'est bien parce que ces entreprises réalisent ce dont l'entreprise a besoin. La communauté est un frein dans le bon sens: elle teste des fonctionnalités, condamne ou accepte de nouvelles fonctionnalités, elle nous unit tous. Et Postgres est devenu
prêt pour l'entreprise , les grandes entreprises sont heureuses de l'utiliser, il est devenu professionnel.

Cette diapositive concerne l'avenir, tel que je le vois. Avec l'avènement du
stockage enfichable , de nouveaux référentiels apparaîtront:
ajout uniquement ,
lecture seule ,
stockage en colonnes - tout ce que vous voulez (par exemple, je rêve de parquet). Il y aura un support pour les opérations vectorielles. Aujourd'hui, en passant, il y aura un rapport à leur sujet. La blockchain sera prise en charge. Il n'y a pas moyen d'y échapper, car nous passons à l'économie numérique, aux technologies sans papier. Vous devrez utiliser des signatures électroniques et vous devrez être en mesure d'authentifier votre base de données, assurez-vous que personne n'a rien changé, et la blockchain est très appropriée pour cela.


Suivant:
Postgres adaptatif . C'est un sujet un peu triste pour vous, mais il est encore assez loin de vous. Le fait est que DBA, d'une manière générale, est une ressource coûteuse, et bientôt les bases de données n'en auront plus besoin. Les bases seront suffisamment intelligentes et se configureront et s'ajusteront elles-mêmes. Mais ce sera probablement dans dix ans. Nous avons encore beaucoup de temps.

Et il est clair que dans Postgres, il y aura un support natif pour les nuages, le stockage en nuage - sans cela, nous ne pouvons tout simplement pas survivre. Et, bien sûr, la voici, la dernière diapositive:
TOUT CE DONT VOUS AVEZ BESOIN EST POSTGRES!

Merci de votre attention.