
Source de l'image: www.nikonsmallworld.com
L'anti-plagiat est un moteur de recherche spécialisé, qui a déjà été écrit plus tôt . Et tout moteur de recherche, quoi qu'on en dise, pour fonctionner rapidement, a besoin de son propre index, qui prend en compte toutes les fonctionnalités de la zone de recherche. Dans mon premier article sur Habr, je parlerai de l'implémentation actuelle de notre index de recherche, de l'historique de son développement et des raisons de choisir l'une ou l'autre solution. Les algorithmes .NET efficaces ne sont pas un mythe, mais une réalité difficile et productive. Nous allons plonger dans le monde du hachage, de la compression au niveau du bit et des caches prioritaires à plusieurs niveaux. Et si vous avez besoin d'une recherche plus rapide que O (1) ?
Si quelqu'un d'autre ne sait pas où se trouvent les bardeaux sur cette photo, bienvenue ...
Bardeaux, index et pourquoi les chercher
Un bardeau est un morceau de texte de quelques mots. Les bardeaux se chevauchent, d'où le nom (anglais, bardeaux - écailles, carrelage). Leur taille spécifique est un secret ouvert - 4 mots. Ou 5? Ça dépend. Cependant, même cette valeur donne peu et dépend de la composition des mots vides, de l'algorithme de normalisation des mots et d'autres détails non significatifs dans le cadre de cet article. En fin de compte, nous calculons le hachage 64 bits sur la base de ce bardeau, que nous appellerons le bardeau à l'avenir.
Selon le texte du document, vous pouvez créer de nombreux bardeaux, dont le nombre est comparable au nombre de mots du document:
texte: chaîne → bardeaux: uint64 []
Si plusieurs bardeaux coïncident dans deux documents, nous supposons que les documents se croisent. Plus il y a de bardeaux, plus le texte est identique dans cette paire de documents. L'index recherche les documents qui ont le plus grand nombre d'intersections avec le document en cours de vérification.

Source de l'image: Wikipedia
L'index des bardeaux vous permet d'effectuer deux opérations principales:
Indexez les bardeaux de documents avec leurs identifiants:
index.Add (docId, bardeaux)
Recherchez et affichez une liste classée d'identifiants pour les documents qui se chevauchent:
index.Search (bardeaux) → (docId, partition) []
L'algorithme de classement, je crois, mérite un article séparé en général, nous ne l'écrirons donc pas ici.
L'index des bardeaux est très différent de ses homologues en texte intégral bien connus, tels que Sphinx, Elastic ou plus grand: Google, Yandex, etc. ... D'une part, il ne nécessite aucune PNL et autres joies de la vie. Tout le traitement de texte est supprimé et n'affecte pas le processus, ainsi que la séquence de bardeaux dans le texte. D'un autre côté, la requête de recherche n'est pas un mot ou une phrase de plusieurs mots, mais jusqu'à plusieurs centaines de milliers de hachages , qui ont tous une importance globale, et non séparément.
En théorie, vous pouvez utiliser l'index de texte intégral en remplacement de l'index de bardeaux, mais les différences sont trop importantes. Le moyen le plus simple d'utiliser un stockage de valeur-clé bien connu, cela sera mentionné ci-dessous. Nous scions notre implémentation de vélo , qui s'appelle - ShingleIndex.
Pourquoi nous dérange-t-on ainsi? Mais pourquoi.
- Volumes :
- Il y a beaucoup de documents. Nous en avons maintenant environ 650 millions, et cette année il y en aura évidemment plus;
- Le nombre de bardeaux uniques augmente à pas de géant et atteint déjà des centaines de milliards. Nous attendons un billion.
- Vitesse :
- Pendant la journée, pendant la session d'été, plus de 300 000 documents sont vérifiés via le système anti-plagiat . C'est un peu par rapport aux standards des moteurs de recherche populaires, mais ça garde le ton;
- Pour une vérification réussie de l'unicité des documents, le nombre de documents indexés doit être supérieur de plusieurs ordres de grandeur aux documents contrôlés. La version actuelle de notre index peut en moyenne se remplir à une vitesse de plus de 4000 documents moyens par seconde.
Et tout cela sur une seule machine! Oui, nous pouvons reproduire , nous approchons progressivement du partage dynamique sur un cluster, mais de 2005 à ce jour, l'index sur une machine avec un soin particulier a pu faire face à toutes les difficultés ci-dessus.
Expérience étrange
Cependant, maintenant nous sommes tellement expérimentés. Qu'on le veuille ou non, mais nous aussi, nous avons grandi et avons essayé différentes choses au cours de la croissance, dont il est amusant de se souvenir maintenant.
Source de l'image: Wikipedia
Tout d'abord, un lecteur inexpérimenté voudrait utiliser une base de données SQL. Vous n'êtes pas les seuls à le penser, l'implémentation SQL nous a bien servi depuis plusieurs années pour implémenter de très petites collections. Néanmoins, l'attention s'est immédiatement portée sur des millions de documents, j'ai donc dû aller plus loin.
Comme vous le savez, personne n'aime les vélos, et LevelDB n'était pas encore dans le domaine public, donc en 2010, nos yeux sont tombés sur BerkeleyDB. Tout est cool - une base de valeurs-clés intégrée persistante avec des méthodes d'accès btree et de hachage appropriées et une longue histoire. Tout avec elle était merveilleux, mais:
- Dans le cas d'une implémentation de hachage, lorsqu'elle a atteint un volume de 2 Go, elle a tout simplement chuté. Oui, nous travaillions toujours en mode 32 bits;
- L'implémentation de l'arbre B + a fonctionné de manière stable, mais avec des volumes de plus de quelques gigaoctets, la vitesse de recherche a commencé à chuter de manière significative.
Nous devons admettre que nous n'avons jamais trouvé de moyen de l'adapter à notre tâche. Peut-être que le problème est lié aux liaisons .net, qui devaient encore être terminées. L'implémentation BDB a finalement été utilisée en remplacement de SQL comme index intermédiaire avant de remplir le principal.
Le temps a passé. En 2014, ils ont essayé LMDB et LevelDB, mais ne l'ont pas mis en œuvre. Les gars de notre département de recherche anti-plagiat ont utilisé RocksDB comme index. À première vue, c'était une trouvaille. Mais la lente reconstitution et la vitesse de recherche médiocre, même à de petits volumes, ont tout mis à néant.
Nous avons fait tout ce qui précède, tout en développant notre propre index personnalisé. En conséquence, il est devenu si bon à résoudre nos problèmes que nous avons abandonné les «bouchons» précédents et nous sommes concentrés sur l'amélioration de celui-ci, que nous utilisons maintenant dans la production partout.
Couches d'index
En fin de compte, qu'avons-nous maintenant? En fait, l'indice des bardeaux est constitué de plusieurs couches (tableaux) avec des éléments de longueur constante - de 0 à 128 bits - qui ne dépendent pas seulement de la couche et ne sont pas nécessairement des multiples de huit.
Chacune des couches joue un rôle. Certains accélèrent la recherche, certains économisent de l'espace et certains ne sont jamais utilisés, mais sont vraiment nécessaires. Nous allons essayer de les décrire afin d'augmenter leur efficacité totale dans la recherche.

Source de l'image: Wikipedia
1. Tableau d'index
Sans perte de généralité, nous allons maintenant considérer qu'un seul bardeau est affecté au document,
(docId → bardeau)
Nous allons échanger les éléments de la paire (inverser, car l'index est en fait "inversé"!),
(bardeau → docId)
Trier par les valeurs des bardeaux et former un calque. Parce que les tailles du bardeau et l'identifiant du document sont constants, maintenant quiconque comprend la recherche binaire peut trouver une paire au-delà des lectures O (logn) du fichier. Beaucoup, beaucoup. Mais c'est mieux que juste O (n) .
Si le document a plusieurs bardeaux, il y aura plusieurs paires de ce type dans le document. S'il y a plusieurs documents avec le même bardeau, cela ne changera pas non plus beaucoup - il y aura plusieurs paires d'affilée avec le même bardeau. Dans ces deux cas, la recherche durera un temps comparable.
2. Tableau de groupes
Nous divisons soigneusement les éléments de l'indice de l'étape précédente en groupes de toute manière pratique. Par exemple, pour qu'ils s'intègrent dans le secteur du cluster, le bloc d' unité d'allocation (lecture, 4096 octets), en tenant compte du nombre de bits et d'autres astuces, formera un dictionnaire efficace. Nous obtenons un tableau simple de positions de ces groupes:
group_map (hash (shingle)) -> group_position.
Lors de la recherche d'un bardeau, nous allons maintenant d'abord rechercher la position du groupe dans ce dictionnaire, puis décharger le groupe et rechercher directement en mémoire. L'ensemble de l'opération nécessite deux lectures.
Le dictionnaire de positions de groupe prend plusieurs ordres de grandeur de moins d'espace que l'index lui-même, il peut souvent être simplement déchargé en mémoire. Ainsi, il n'y aura pas deux lectures, mais une. Total, O (1) .
3. Filtre Bloom
Lors des entretiens, les candidats résolvent souvent des problèmes en émettant des solutions uniques avec O (n ^ 2) ou même O (2 ^ n) . Mais nous ne faisons pas de bêtises. Y a-t-il O (0) dans le monde, c'est ça la question? Essayons sans grand espoir de résultat ...
Passons au sujet. Si l'élève est bien fait et a écrit le travail lui-même, ou simplement qu'il n'y a pas de texte, mais des déchets, alors une partie importante de ses bardeaux sera unique et ne sera pas trouvée dans l'index. Une telle structure de données comme le filtre Bloom est bien connue dans le monde. Avant de chercher, vérifiez le bardeau dessus. S'il n'y a pas de bardeau dans l'index, alors vous ne pouvez pas regarder plus loin, sinon allez plus loin.
Le filtre Bloom lui-même est assez simple, mais cela n'a aucun sens d'utiliser un vecteur de hachage avec nos volumes. Il suffit d'utiliser une lecture +1 dans le filtre Bloom. Cela donne -1 ou -2 lectures des étapes suivantes, dans le cas où le bardeau est unique et qu'il n'y avait pas de faux positif dans le filtre. Surveillez vos mains!
La probabilité d'une erreur de filtre Bloom est définie lors de la construction; la probabilité d'un bardeau inconnu est déterminée par l'honnêteté de l'élève. Des calculs simples peuvent aboutir à la dépendance suivante:
- Si nous faisons confiance à l'honnêteté des gens (c'est-à-dire, en fait, le document est original), alors la vitesse de recherche diminuera;
- Si le document est clairement assemblé, la vitesse de recherche augmentera, mais nous avons besoin de beaucoup de mémoire.
Avec la confiance des étudiants, nous avons le principe de «faire confiance, mais vérifier», et la pratique montre qu'il y a toujours un profit du filtre Bloom.
Étant donné que cette structure de données est également plus petite que l'index lui-même et peut être mise en cache, dans le meilleur des cas, elle vous permet de supprimer le bardeau sans aucun accès au disque.
4. Queues lourdes
Il y a des bardeaux qui se trouvent presque partout. Leur part dans le nombre total est faible, mais lors de la construction de l'indice dans la première étape, dans la seconde, des groupes de dizaines et de centaines de Mo peuvent être obtenus. Nous les mémoriserons séparément et nous les éliminerons immédiatement de la requête de recherche.
Lorsque cette étape triviale a été utilisée pour la première fois en 2011, la taille de l'index a été divisée par deux et la recherche elle-même a été accélérée.
5. Autres queues
Même ainsi, un bardeau peut contenir de nombreux documents. Et c'est normal. Des dizaines, des centaines, des milliers ... Les garder à l'intérieur de l'index principal devient non rentable, ils peuvent aussi ne pas s'intégrer dans le groupe, ce qui fait gonfler le volume du dictionnaire des positions du groupe. Mettez-les dans une séquence distincte avec un stockage plus efficace. Selon les statistiques, une telle décision est plus que justifiée. De plus, divers packages au niveau du bit peuvent réduire le nombre d'accès au disque et réduire le volume de l'index.
Par conséquent, pour faciliter la maintenance, nous imprimons toutes ces couches en un seul gros fichier: un morceau. Il y a dix couches de ce type. Mais une partie n'est pas utilisée dans la recherche, une partie est très petite et est toujours stockée en mémoire, une partie est activement mise en cache si nécessaire / possible.
Au combat, le plus souvent, la recherche d'un bardeau se résume à une ou deux lectures de fichiers aléatoires. Dans le pire des cas, vous devez en faire trois. Toutes les couches sont efficacement (parfois au niveau du bit) des tableaux d'éléments de longueur constante. Telle est la normalisation. Le temps de déballage est insignifiant par rapport au prix du volume total pendant le stockage et à la possibilité de mieux mettre en cache.
Lors de la construction, les tailles des couches sont principalement calculées à l'avance, écrites séquentiellement, donc cette procédure est assez rapide.
Comment y êtes-vous arrivé, ne saviez pas où
2010 , . , . , .

Source de l'image: Wikipedia
Initialement, notre index était composé de deux parties - une constante, décrite ci-dessus, et une temporaire, dont le rôle était soit SQL, soit BDB, ou son propre journal de mise à jour. Parfois, par exemple, une fois par mois (et parfois un an), le temporaire est trié, filtré et fusionné avec le principal. Le résultat a été unifié et les deux anciens ont été supprimés. Si celui temporaire ne pouvait pas rentrer dans la RAM, la procédure passait par un tri externe.
Cette procédure était plutôt gênante, elle a commencé en mode semi-manuel et a nécessité de réécrire l'intégralité du fichier d'index à partir de zéro. Réécrire des centaines de gigaoctets pour quelques millions de documents - enfin, tant pis, je vous le dis ...
Souvenirs du passé ...SSD. , 31 SSD wcf- . , . , .
Pour que le SSD ne soit pas particulièrement tendu et que l'indice soit mis à jour plus souvent, en 2012, nous avons impliqué une chaîne de plusieurs morceaux, des morceaux selon le schéma suivant:

Ici, l'index est constitué d'une chaîne du même type de morceaux, à l'exception du tout premier. Le premier, l'addon, était un journal en annexe uniquement avec un index dans la RAM. Les morceaux suivants ont augmenté de taille (et d'âge) jusqu'au tout dernier (zéro, principal, racine, ...).
Note aux cyclistes ...Parfois, vous ne devriez pas être à court d'écrire du code et même pas penser, mais juste le google plus en profondeur. Jusqu'à la notation, le diagramme est similaire à celui de l'article de 1996
«L'arbre de fusion à structure logarithmique» :
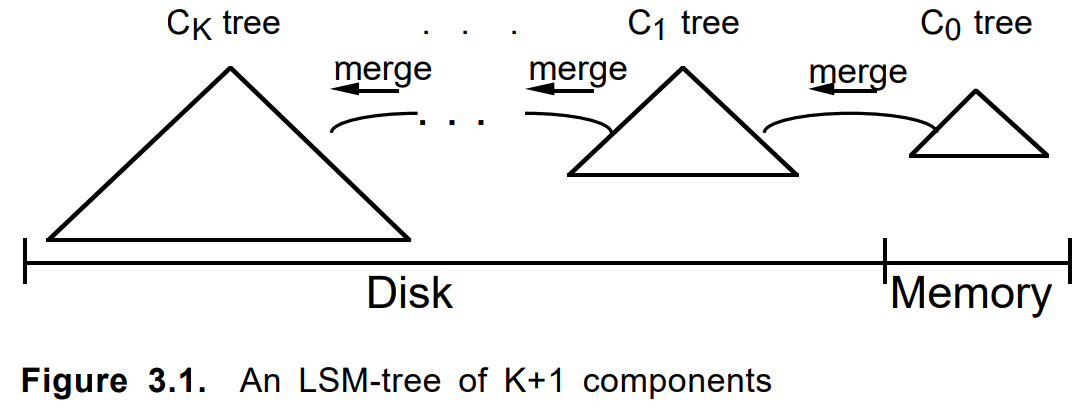
Lors de l'ajout d'un document, il a d'abord été plié en un addon. Quand il était plein ou selon d'autres critères, un morceau permanent a été construit dessus. Les plusieurs morceaux voisins, si nécessaire, ont fusionné en un nouveau, et les originaux ont été supprimés. La mise à jour ou la suppression d'un document a fonctionné de la même manière.
Critères de fusion, longueur de chaîne, algorithme de contournement, prise en compte des éléments supprimés et des mises à jour, d'autres paramètres ont été ajustés. L'approche elle-même a été impliquée dans plusieurs tâches similaires et a pris la forme d'un cadre LSM interne distinct sur un .net propre. Vers la même époque, LevelDB est devenu populaire.
Petite remarque sur l'arbre LSMLSM-Tree est un algorithme assez intéressant, avec une bonne justification. Mais, à mon humble avis, il y avait une certaine confusion dans le sens du terme arbre. Dans l'
article d' origine
, il s'agissait d'une chaîne d'arbres capables de transférer des branches. Dans les implémentations modernes, ce n'est pas toujours le cas. Ainsi, notre framework a finalement été nommé LsmChain, c'est-à-dire la chaîne lsm de morceaux.
L'algorithme LSM dans notre cas présente des fonctionnalités très adaptées:
- insertion / suppression / mise à jour instantanée,
- charge réduite sur les SSD lors de la mise à jour,
- format de morceaux simplifié,
- recherche sélective uniquement sur les anciens / nouveaux morceaux,
- sauvegarde triviale
- ce que l'âme veut d'autre.
- ...
En général, il est parfois utile d'inventer des vélos pour l'auto-développement.
Macro, micro, nano optimisation
Et enfin, nous partagerons des conseils techniques sur la façon dont nous, dans l' antiplagiat, faisons de telles choses sur .Net (et pas seulement dessus).
Notez à l'avance que souvent tout dépend beaucoup de votre matériel, de vos données ou de votre mode d'utilisation. Après avoir tordu à un endroit, nous volons hors du cache du processeur, à un autre - nous rencontrons la bande passante de l'interface SATA, au troisième - nous commençons à accrocher dans le GC. Et quelque part dans l'inefficacité de la mise en œuvre d'un appel système spécifique.

Source de l'image: Wikipedia
Travailler avec un fichier
Le problème d'accès au fichier n'est pas unique chez nous. Il existe un fichier exaoctet de plusieurs téraoctets dont le volume est plusieurs fois supérieur à la quantité de RAM. La tâche consiste à lire le million dispersé autour de lui de quelques petites valeurs aléatoires. Et pour le faire rapidement, efficacement et à peu de frais. Nous devons serrer, comparer et penser beaucoup.
Commençons par un simple. Pour lire l'octet précieux dont vous avez besoin:
- Ouvrir un fichier (nouveau FileStream);
- Déplacez-vous à la position souhaitée (position ou recherche, aucune différence);
- Lisez le tableau d'octets souhaité (Lecture);
- Fermez le fichier (Dispose).
Et c'est mauvais, car c'est long et morne. Par essais, erreurs et pas répétés sur le râteau, nous avons identifié l'algorithme d'actions suivant:
Ouverture unique, lecture multiple
Si cette séquence se fait au niveau du front, pour chaque requête sur le disque, alors on se pliera rapidement. Chacun de ces éléments fait l'objet d'une requête auprès du noyau du système d'exploitation, ce qui est coûteux.
De toute évidence, vous devez ouvrir le fichier une fois et lire séquentiellement tous les millions de nos valeurs, ce que nous faisons
Rien de plus
Obtenir la taille du fichier, sa position actuelle est également une opération assez difficile. Même si le fichier n'a pas changé.
Toutes les requêtes telles que l'obtention de la taille du fichier ou de sa position actuelle doivent être évitées.
Filestreampool
Ensuite. Hélas, FileStream est essentiellement monothread. Si vous souhaitez lire un fichier en parallèle, vous devrez créer / fermer de nouveaux flux de fichiers.
Jusqu'à ce que vous créiez quelque chose comme aiosync, vous devez inventer vos propres vélos.
Mon conseil est de créer un pool de flux de fichiers par fichier. Cela évitera de perdre du temps à ouvrir / fermer un fichier. Et si vous le combinez avec ThreadPool et prenez en compte le fait que le SSD émet ses mégaIOPS avec un multithreading puissant ... Eh bien, vous me comprenez.
Unité d'allocation
Ensuite. Les dispositifs de stockage (HDD, SSD, Optane) et le système de fichiers fonctionnent avec des fichiers au niveau du bloc (cluster, secteur, unité d'allocation). Ils peuvent ne pas correspondre, mais maintenant, il s'agit presque toujours de 4096 octets. La lecture d'un ou deux octets à la frontière de deux de ces blocs dans un SSD est environ une fois et demie plus lente qu'à l'intérieur du bloc lui-même.
Vous devez organiser vos données de sorte que les éléments soustraits soient dans les limites du bloc de secteur de cluster .
Pas de tampon.
Ensuite. FileStream utilise par défaut un tampon de 4096 octets. Et la mauvaise nouvelle est que vous ne pouvez pas l'éteindre. Cependant, si vous lisez plus de données que la taille du tampon, ce dernier sera ignoré.
Pour une lecture aléatoire, vous devez définir le tampon sur 1 octet (cela ne fonctionnera pas moins) et puis considérer qu'il n'est pas utilisé.
Utilisez un tampon.
En plus des relevés aléatoires, il existe également des relevés séquentiels. Ici, le tampon peut déjà devenir utile si vous ne voulez pas tout lire en même temps. Je vous conseille de commencer par cet article . La taille du tampon à définir dépend du fait que le fichier se trouve sur le disque dur ou sur le SSD. Dans le premier cas, 1 Mo sera optimal; dans le second, 4 Ko standard suffiront. Si la taille de la zone de données à lire est comparable à ces valeurs, il est préférable de la soustraire immédiatement, en sautant le tampon, comme dans le cas d'une lecture aléatoire. Les gros tampons n'apporteront pas de profit en vitesse, mais commenceront à frapper sur GC.
Lors de la lecture séquentielle de gros morceaux du fichier, vous devez définir le tampon sur 1 Mo pour le disque dur et 4 Ko pour le SSD. Ça dépend.
MMF vs FileStream
En 2011, un conseil a été donné à MemoryMappedFile, car ce mécanisme a été mis en œuvre depuis .Net Framework v4.0. Tout d'abord, ils l'ont utilisé lors de la mise en cache du filtre Bloom, ce qui était déjà gênant en mode 32 bits en raison de la limitation de 4 Go. Mais en entrant dans le monde du 64 bits, j'en voulais plus. Les premiers tests ont été impressionnants. Mise en cache gratuite, vitesse extraordinaire, interface de lecture de structure pratique. Mais il y avait des problèmes:
- Tout d'abord, curieusement, la vitesse. Si les données sont déjà mises en cache, alors tout va bien. Si ce n'est pas le cas, la lecture d'un octet du fichier s'est accompagnée d'une «remontée» d'une quantité de données beaucoup plus importante qu'elle ne le serait avec une lecture régulière.
- Deuxièmement, curieusement, la mémoire. Lorsqu'elle est chauffée, la mémoire partagée se développe, l'ensemble de travail - non, ce qui est logique. Mais alors les processus voisins commencent à ne pas se comporter très bien. Ils peuvent être échangés ou tomber accidentellement d'OoM. Le volume occupé par le MMF en RAM, hélas, ne peut pas être contrôlé. Et le profit du cache dans le cas où le fichier lisible est supérieur de quelques ordres de grandeur à la mémoire devient insignifiant.
Le deuxième problème pourrait encore être combattu. Il disparaît si l'index fonctionne dans Docker ou sur une machine virtuelle dédiée. Mais le problème de vitesse a été fatal.
En conséquence, le MMF a été abandonné un peu plus que complètement. La mise en cache dans l'anti-plagiat a commencé à se faire sous une forme explicite, si possible en gardant en mémoire les couches les plus fréquemment utilisées aux priorités et limites données.

Source de l'image: Wikipedia
Bits / octets
Pas d'octets le monde est un. Parfois, vous devez descendre au niveau du bit.
Par exemple: supposons que vous ayez un billion de numéros partiellement ordonnés, désireux d'enregistrer et de lire fréquemment. Comment travailler avec tout ça?
- BinaryWriter.Write simple? - rapide mais lent. La taille compte. La lecture à froid dépend principalement de la taille du fichier.
- Une autre variante de VarInt? - rapide mais lent. La cohérence est importante. Le volume commence à dépendre des données, ce qui nécessite une mémoire supplémentaire pour le positionnement.
- Emballage de bits? - rapide mais lent. Vous devez contrôler plus soigneusement vos mains.
Il n'y a pas de solution idéale, mais dans le cas spécifique, la simple compression de la plage de 32 bits au nécessaire pour stocker les queues a économisé 12% de plus (des dizaines de Go!) Que VarInt (ne sauvegardant que la différence des voisins, bien sûr), et cela plusieurs fois option de base.
Un autre exemple. Vous avez un lien dans un fichier vers un tableau de nombres. Lien 64 bits, fichier par téraoctet. Tout semble ok. Parfois, il y a beaucoup de nombres dans le tableau, parfois peu. Souvent un peu. Très souvent. Ensuite, prenez et stockez tout le tableau dans le lien lui-même. Bénéfice Emballez soigneusement mais n'oubliez pas.
Struct, dangereux, batching, micro-opts
Eh bien et d'autres microoptimisation. Je n'écrirai pas ici sur le banal "ça vaut la peine d'enregistrer la longueur du tableau dans une boucle" ou "qui est plus rapide, pour ou pour chaque".
Il y a deux règles simples, et nous y adhérerons: 1. "tout comparer", 2. "plus de référence".
Struct . Utilisé partout. N'expédiez pas GC. Et, comme c'est à la mode aujourd'hui, nous avons également notre propre ValueList méga-rapide.
Dangereux . Autorise les structures mapit (et unmap) à un tableau d'octets lorsqu'il est utilisé. Ainsi, nous n'avons pas besoin de moyens de sérialisation séparés. Il est vrai que l'épinglage et la défragmentation du tas posent des questions, mais jusqu'à présent, cela n'a pas été montré. Ça dépend.
Batching . Le travail avec de nombreux éléments doit se faire via des packs / groupes / blocs. Fichier lecture / écriture, transfert entre fonctions. Un problème distinct est la taille de ces packs. Habituellement, il existe un optimum et sa taille est souvent comprise entre 1 Ko et 8 Mo (taille du cache du processeur, taille du cluster, taille de la page, taille de quelque chose d'autre). Essayez de parcourir la fonction IEnumerable <byte> ou IEnumerable <byte [1024]> et ressentez la différence.
Pooling . Chaque fois que vous écrivez «nouveau», un chaton meurt quelque part. Une fois le nouvel octet [ 85000 ] - et le tracteur a roulé une tonne d'oies. S'il n'est pas possible d'utiliser stackalloc, créez un pool d'objets et réutilisez-le à nouveau.
Inline . Comment créer deux fonctions au lieu d'une peut tout accélérer dix fois? C'est simple. Plus la taille du corps de la fonction (méthode) est petite, plus elle sera probablement en ligne. Malheureusement, dans le monde dotnet, il n'y a toujours aucun moyen de faire une inline partielle, donc si vous avez une fonction chaude qui sort dans 99% des cas après avoir traité les premières lignes, et les cent lignes restantes vont traiter le 1% restant, puis le diviser en toute sécurité en deux (ou trois), portant la queue lourde dans une fonction distincte.
Quoi d'autre?
Span <T> , Memory <T> - prometteur. Le code sera plus simple et peut-être un peu plus rapide. Nous attendons la sortie de .Net Core v3.0 et Std v2.1 pour passer à eux, car notre noyau sur .Net Std v2.0, qui ne prend normalement pas en charge les étendues.
Async / wait - jusqu'à présent controversé. Les tests de référence de lecture aléatoire les plus simples ont montré que la consommation du processeur diminue, mais la vitesse de lecture diminue également. Doit regarder. Nous ne l’utilisons pas encore dans l’index.
Conclusion
J'espère que mon éloignement vous fera plaisir de comprendre la beauté de certaines décisions. Nous aimons vraiment notre indice. Il est efficace, beau code, fonctionne très bien. Une solution hautement spécialisée au cœur du système, lieu critique de son travail, est meilleure que la solution générale. Notre système de contrôle de version se souvient des insertions d'assembleur en code C ++. Maintenant, il y a quatre avantages - seulement C # pur, seulement .Net. Nous y écrivons même les algorithmes de recherche les plus complexes et nous ne le regrettons pas du tout. Avec l'avènement de .Net Core, la transition vers Docker, le chemin vers un avenir DevOps brillant est devenu plus facile et plus clair. En avant est la solution du problème de la partition et de la réplication dynamiques sans réduire l'efficacité et la beauté de la solution.
Merci à tous ceux qui ont lu jusqu'à la fin. Pour toutes les divergences et autres incohérences, veuillez écrire des commentaires. Je serai heureux de tout conseil raisonnable et réfutation dans les commentaires.