Préface
Cet article n'est pas très similaire à ceux qui ont été publiés plus tôt sur l'analyse d'Internet dans certains pays, car je n'ai pas poursuivi les objectifs de l'analyse en masse d'un segment spécifique d'Internet à la recherche de ports ouverts et de la présence des vulnérabilités les plus populaires car il est contraire à la loi.
J'avais plutôt un intérêt légèrement différent - essayer d'identifier tous les sites pertinents dans la zone de domaine BY en utilisant différentes méthodes, déterminer la pile de technologies utilisées, à travers des services comme Shodan, VirusTotal, etc. pour effectuer une reconnaissance passive sur IP et des ports ouverts et, dans l'appendice, collecter un peu d'autres utiles des informations pour la formation de quelques statistiques générales sur le niveau de sécurité des sites et des utilisateurs.
Introduction et notre boîte à outils
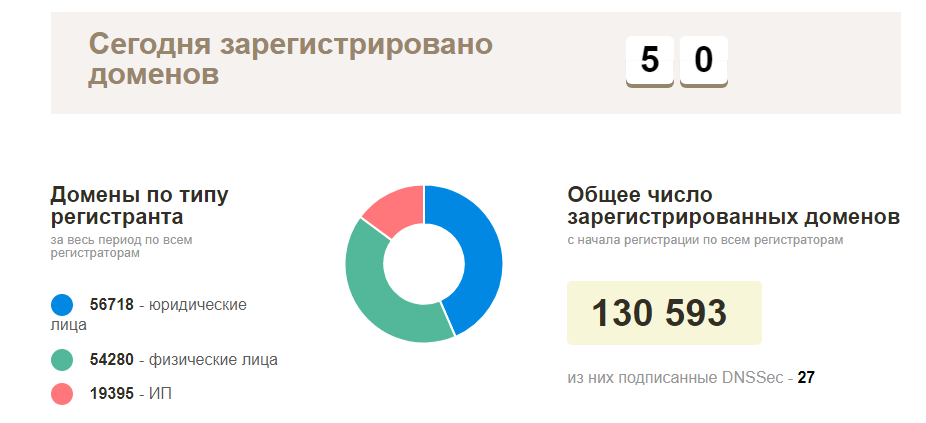
Le plan au tout début était simple - contactez votre registraire local pour une liste des domaines enregistrés actuels, puis vérifiez tout pour la disponibilité et commencez à explorer les sites qui fonctionnent. En réalité, tout s'est avéré beaucoup plus compliqué - ce type d'informations était naturel, personne ne voulait le fournir, à l'exception de la page de statistiques officielles des noms de domaine enregistrés dans la zone BY (environ 130 mille domaines). S'il n'y a pas de telles informations, vous devez les collecter vous-même.
En termes d'outils, en fait, tout est assez simple - nous regardons vers l'open source, vous pouvez toujours ajouter quelque chose, terminer quelques béquilles minimales. Parmi les plus populaires, les outils suivants ont été utilisés:
Début des activités: point de départ
Comme introduction, comme je l'ai déjà dit, idéalement, les noms de domaine étaient appropriés, mais où puis-je les obtenir? Nous devons partir de quelque chose de plus simple, dans ce cas, les adresses IP nous conviennent, mais encore une fois - avec les recherches inversées, il n'est pas toujours possible d'attraper tous les domaines, et lors de la collecte des noms d'hôtes - ce n'est pas toujours le bon domaine. À ce stade, j'ai commencé à réfléchir à des scénarios possibles pour collecter ce type d'informations, encore une fois - le fait que notre budget était de 5 $ pour la location de VPS a été pris en compte, tout le reste devrait être gratuit.
Nos sources potentielles d'information:
- Adresses IP (site ip2location )
- Recherchez les domaines par la deuxième partie de l'adresse e-mail (mais où les obtenir?
- Certains bureaux d'enregistrement / hébergeurs peuvent nous fournir ces informations sous forme de sous-domaines
- Sous-domaines et leur inversion subséquente (Sublist3r et Aquatone peuvent aider ici)
- Bruteforce et entrée manuelle (longue, morne, mais possible, même si je n'ai pas utilisé cette option)
Je vais prendre un peu d'avance et dire qu'avec cette approche, j'ai réussi à collecter environ 50 000 domaines et sites uniques, respectivement (je n'ai pas réussi à tout traiter). S'il continuait à collecter activement des informations, alors en moins d'un mois de travail, mon convoyeur aurait certainement maîtrisé l'intégralité de la base de données, ou la majeure partie.
Passons aux choses sérieuses
Dans les articles précédents, les informations sur les adresses IP ont été extraites du site IP2LOCATION, pour des raisons évidentes, je n'ai pas rencontré ces articles (car toutes les actions ont eu lieu beaucoup plus tôt), mais je suis également venu vers cette ressource. Certes, dans mon cas, l'approche était différente - j'ai décidé de ne pas prendre la base de données localement pour moi et de ne pas extraire les informations du CSV, mais j'ai décidé de surveiller les modifications directement sur le site, sur une base continue et comme base principale d'où tous les scripts suivants prendront des objectifs - fait un tableau avec Adresses IP dans différents formats: CIDR, liste «de» et «à», marque de pays (juste au cas où), numéro AS, description AS.
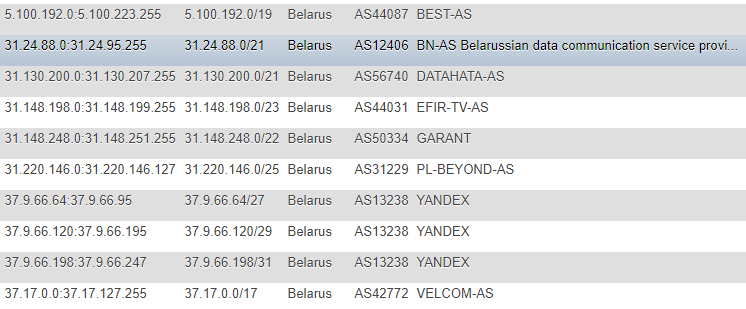
Le format n'est pas le plus optimal, mais j'étais assez satisfait de la démo et de la promotion ponctuelle, et afin de ne pas opter pour des informations auxiliaires comme l'ASN sur une base continue, j'ai décidé de le connecter également à la maison. Pour obtenir ces informations, je me suis tourné vers le service
IpToASN , ils ont une API pratique (avec restrictions), que vous avez en fait juste besoin d'intégrer en vous.
Code d'analyse IPfunction ipList() { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://lite.ip2location.com/belarus-ip-address-ranges"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $ipList = curl_exec($ch); curl_close ($ch); preg_match_all("/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\<\/td\>\s+\<td\>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/", $ipList, $matches); return $matches[0]; } function iprange2cidr($ipStart, $ipEnd){ if (is_string($ipStart) || is_string($ipEnd)){ $start = ip2long($ipStart); $end = ip2long($ipEnd); } else{ $start = $ipStart; $end = $ipEnd; } $result = array(); while($end >= $start){ $maxSize = 32; while ($maxSize > 0){ $mask = hexdec(iMask($maxSize - 1)); $maskBase = $start & $mask; if($maskBase != $start) break; $maxSize--; } $x = log($end - $start + 1)/log(2); $maxDiff = floor(32 - floor($x)); if($maxSize < $maxDiff){ $maxSize = $maxDiff; } $ip = long2ip($start); array_push($result, "$ip/$maxSize"); $start += pow(2, (32-$maxSize)); } return $result; } $getIpList = ipList(); foreach($getIpList as $item) { $cidr = iprange2cidr($ip[0], $ip[1]); }
Après avoir découvert l'IP, nous devons, hélas, exécuter toute notre base de données via les services de recherche inversée - c'est impossible, sauf pour l'argent.
Parmi les services qui sont excellents pour cela et pratiques à utiliser, je veux en mentionner deux:
- VirusTotal - limite sur la fréquence des appels à partir d'une seule clé API
- Hackertarget.com (leur API) - limite sur le nombre de hits d'une IP
En contournant les limites, les options suivantes ont été obtenues:
- Dans le premier cas, l'un des scénarios consiste à supporter des délais d'attente de 15 secondes, au total, nous aurons 4 appels par minute, ce qui peut considérablement affecter notre vitesse et dans cette situation, il sera utile d'utiliser 2-3 de ces touches, et je recommanderais de recourir à la même pour proxy et changer d'agent utilisateur.
- Dans le deuxième cas, j'ai écrit un script pour l'analyse automatique de la base de données proxy basée sur des informations accessibles au public, leur validation et leur utilisation ultérieure (mais plus tard, j'ai laissé cette option parce que VirusTotal était également suffisant en substance)
Nous allons plus loin et nous nous dirigeons en douceur vers les adresses e-mail. Ils peuvent également être une source d'informations utiles, mais où les collecter? Il n'a pas fallu longtemps pour trouver une solution, car les utilisateurs détiennent peu dans notre segment de sites personnels, et la plupart d'entre eux sont des organisations - les sites Web de profil comme les répertoires de magasins en ligne, les forums et les marchés conditionnels nous conviendront.
Par exemple, une inspection rapide de l'un de ces sites a montré que de nombreux utilisateurs ajoutent leur e-mail directement à leur profil public et, par conséquent, cette entreprise peut être soigneusement analysée pour une utilisation future.
Je n'entrerai pas dans les détails de l'analyse de chaque site, il est plus pratique de deviner l'ID utilisateur par force brute, il est plus facile d'analyser un plan de site, d'obtenir des informations sur les pages de l'entreprise à partir de celui-ci, puis de collecter des adresses auprès d'eux. Après avoir collecté les adresses, il nous reste à effectuer plusieurs opérations simples en les triant immédiatement par zone de domaine, en conservant les «queues» et en les exécutant pour exclure les doublons de la base de données existante.
À ce stade, je crois qu'avec la formation de la portée, nous pouvons terminer et passer à l'intelligence. L'intelligence, comme nous le savons déjà, peut être de deux types - active et passive, dans notre cas - l'approche passive sera la plus pertinente. Mais là encore, le simple accès au site sur le port 80 ou 443 sans charge malveillante et l'exploitation des vulnérabilités est une action tout à fait légitime. Notre intérêt est les réponses du serveur à une seule demande, dans certains cas, il peut y avoir deux demandes (redirection de http vers https), dans des cas plus rares, jusqu'à trois (lorsque www est utilisé).
Intelligence
En utilisant ces informations comme domaine, nous pouvons collecter les données suivantes:
- Enregistrements DNS (NS, MX, TXT)
- En-têtes de réponse
- Identifier la pile technologique utilisée
- Comprenez par quel protocole le site fonctionne.
- Essayez d'identifier les ports ouverts (basés sur la base de données Shodan / Censys) sans analyse directe
- Essayez d'identifier les vulnérabilités sur la base de la corrélation des informations de Shodan / Censys avec la base de données Vulners
- Est-ce dans la base de données malveillantes de la navigation sécurisée Google
- Collectez les adresses e-mail par domaine, ainsi que les correspondances déjà trouvées et vérifiez par Have I Been Pwned, en plus - lien vers les réseaux sociaux
- Un domaine est dans certains cas non seulement le visage de l'entreprise, mais aussi le produit de ses activités, des adresses e-mail pour l'inscription sur les services, etc., respectivement - vous pouvez rechercher des informations qui leur sont associées sur des ressources comme GitHub, Pastebin, Google Dorks (Google CSE )
Vous pouvez toujours aller de l'avant et profiter de l'option masscan ou nmap, zmap, en les configurant d'abord via Tor avec un lancement dans un temps aléatoire ou même à partir de plusieurs instances, mais nous avons d'autres objectifs et le nom implique que je n'ai pas fait de scans directs.
Nous collectons les enregistrements DNS, vérifions la possibilité d'amplification des requêtes et des erreurs de configuration comme AXFR:
Un exemple de collecte d'enregistrements de serveur NS dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'
Exemple de collecte d'enregistrements MX (voir NS, remplacez simplement 'ns' par 'mx'
Vérifiez AXFR (il existe de nombreuses solutions ici, voici une autre béquille, mais pas de sécurité, utilisée pour visualiser les sorties) $digNs = trim(shell_exec("dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'")); $ns = explode("\n", $digNs); foreach($ns as $target) { $axfr = trim(shell_exec("dig -t axfr $domain @$target | awk '{print $1}' | sed 's/\.$//g'")); $axfr = preg_replace("/\;/", "", $axfr); if(!empty(trim($axfr))) { $axfr = preg_replace("/\;/", "", $axfr); $res = json_encode(explode("\n", trim($axfr)));
Vérifiez l'amplification DNS dig +short test.openresolver.com TXT @$dns
Dans mon cas, les serveurs NS ont été pris dans la base de données, donc à la fin de la variable, vous pouvez remplacer n'importe quel serveur en fait. En ce qui concerne l'exactitude des résultats de ce service, je ne peux pas être sûr que tout fonctionne bien là-bas et les résultats sont toujours valides, mais j'espère que la plupart des résultats sont réels.
Si pour quelque raison que ce soit, nous devons conserver une URL finale à part entière vers le site, j'ai utilisé cURL pour cela:
curl -I -L $target | awk '/Location/{print $2}'
Il parcourra lui-même l'intégralité de la redirection et affichera la dernière, c'est-à-dire URL actuelle du site. Dans mon cas, cela a été extrêmement utile pour l'utilisation ultérieure d'outils tels que WhatWeb.
Pourquoi devrions-nous l'utiliser? Afin de déterminer le système d'exploitation, le serveur Web, le site CMS utilisé, certains en-têtes, des modules supplémentaires tels que les bibliothèques / frameworks JS / HTML, ainsi que le titre du site par lequel vous pouvez ensuite essayer de filtrer par le même domaine d'activité.
Dans ce cas, une option très pratique consiste à exporter les résultats du fonctionnement de l'outil au format XML pour une analyse ultérieure et à les importer dans la base de données s'il est prévu de les traiter tous plus tard.
whatweb --no-errors https://www.mywebsite.com --log-xml=results.xml
Pour ma part, j'ai créé JSON à la suite de la sortie et l'ai déjà mis dans la base de données.
En parlant d'en-têtes, vous pouvez faire presque la même chose avec cURL ordinaire en exécutant une requête du formulaire:
curl -I https://www.mywebsite.com
Dans les en-têtes, récupérez des informations sur le CMS et les serveurs Web à l'aide d'expressions régulières, par exemple.
En plus de l'utile, nous pouvons également mettre en évidence la possibilité de collecter des informations sur les ports ouverts en utilisant Shodan puis en utilisant les données déjà obtenues, effectuer une vérification de la base de données Vulners à l'aide de leur API (les liens vers les services sont donnés dans l'en-tête). Bien sûr, il peut y avoir des problèmes de précision dans ce scénario, mais ce n'est pas une analyse directe avec validation manuelle, mais un "jonglage" banal de données provenant de sources tierces, mais au moins c'est mieux que rien du tout.
Fonction PHP pour Shodan function shodanHost($host) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://api.shodan.io/shodan/host/".$host."?key=<YOUR_API_KEY>"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $shodanResponse = curl_exec($ch); curl_close ($ch); return json_decode($shodanResponse); }
Un exemple d'une telle analyse comparative # 1 Oui, depuis qu'ils ont commencé à parler de l'API, alors les Vulner ont des limites et la solution la plus optimale serait d'utiliser leur script Python, tout fonctionnera bien sans torsion-torsions, dans le cas de PHP, j'ai rencontré quelques petites difficultés (encore une fois, ajoutez. les délais d'attente ont sauvé la situation).
L'un des derniers tests - nous étudierons les informations sur le pare-feu utilisé avec un script tel que "wafw00f". En testant ce merveilleux outil, j'ai remarqué une chose intéressante: ce n'était pas toujours la première fois qu'il était possible de déterminer le type de pare-feu utilisé.
Pour voir quels types de pare-feu wafw00f peut potentiellement détecter, vous pouvez entrer la commande suivante:
wafw00f -l
Pour déterminer le type de pare-feu - wafw00f analyse les en-têtes de réponse du serveur après l'envoi d'une demande standard au site, si cette tentative n'est pas suffisante, elle génère bien une demande de test simple supplémentaire, et si cela ne suffit pas à nouveau - la troisième méthode opère sur les données après les deux premières tentatives .
Parce que pour les statistiques, en fait, nous n'avons pas besoin de toute la réponse, nous coupons tous les excès avec une expression régulière et ne laissons que le nom pare-feu:
/is\sbehind\sa\s(.+?)\n/
Eh bien, comme je l'ai écrit plus tôt - en plus des informations sur le domaine et le site, les informations sur les adresses e-mail et les réseaux sociaux ont également été mises à jour en mode passif:
Statistiques par e-mail définies en fonction du domaine Un exemple de détermination de la liaison des réseaux sociaux à l'adresse e-mail Le moyen le plus simple était de gérer la validation des adresses sur Twitter (2 voies), avec Facebook (1 voie) à cet égard, il s'est avéré être un peu plus compliqué en raison d'un système légèrement plus complexe pour générer une véritable session utilisateur.
Passons aux statistiques sèches.
Statistiques DNS
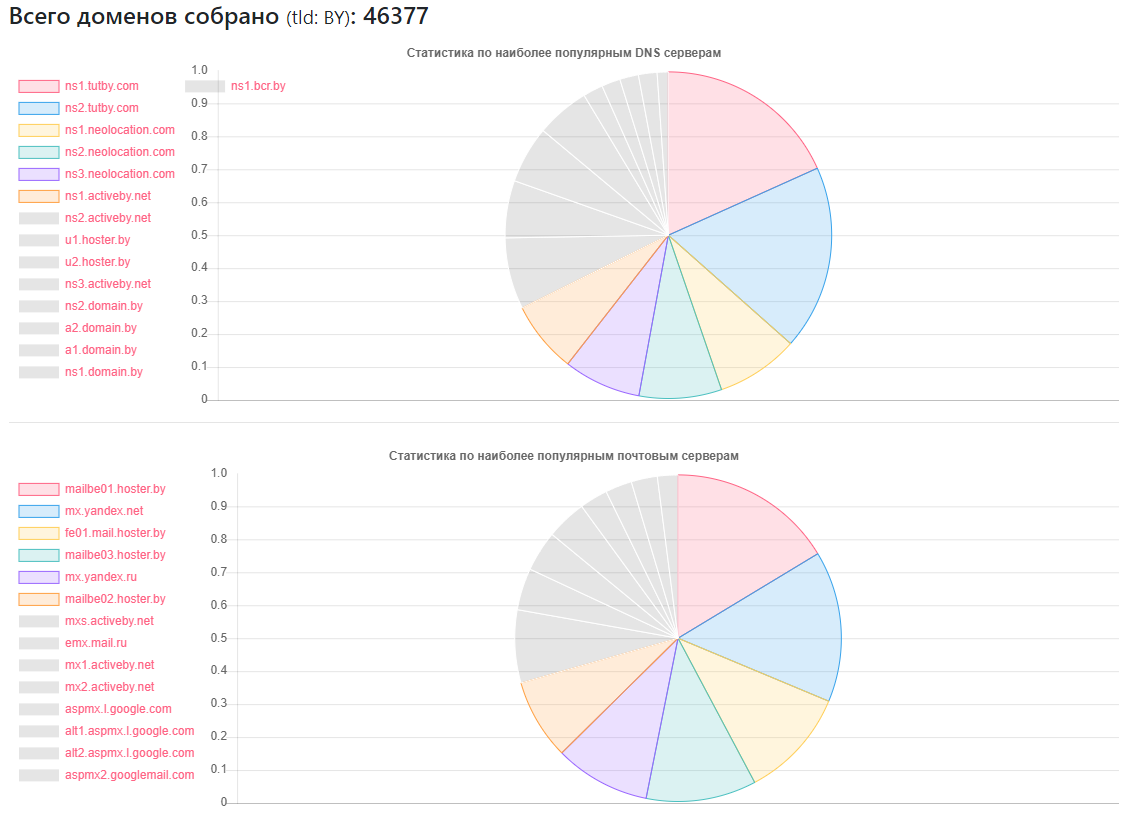 Fournisseur - combien de sites
Fournisseur - combien de sitesns1.tutby.com: 10899
ns2.tutby.com: 10899
ns1.neolocation.com: 4877
ns2.neolocation.com: 4873
ns3.neolocation.com: 4572
ns1.activeby.net: 4231
ns2.activeby.net: 4229
u1.hoster.by: 3382
u2.hoster.by: 3378
DNS unique trouvé: 2462
Serveurs MX (mail) uniques: 9175 (en plus des services populaires, il y a un nombre suffisant d'administrateurs qui utilisent leurs propres services de messagerie)
Affecté par le transfert de zone DNS: 1011
Affecté par l'amplification DNS: 531
Peu de fans CloudFlare: 375 (sur la base des enregistrements NS utilisés)
Statistiques CMS
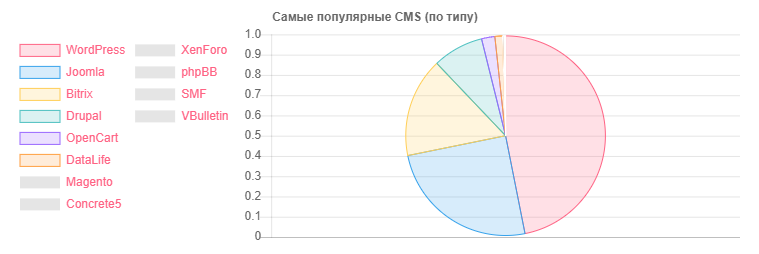 CMS - Quantité
CMS - QuantitéWordPress: 5118
Joomla: 2722
Bitrix: 1757
Drupal: 898
OpenCart: 235
DataLife: 133
Magento: 32
- Installations WordPress potentiellement vulnérables: 2977
- Installations potentiellement vulnérables de Joomla: 212
- En utilisant le service Google SafeBrowsing, il a été possible d'identifier des sites potentiellement dangereux ou infectés: environ 10 000 (à des moments différents, quelqu'un a réparé, quelqu'un a apparemment cassé, les statistiques ne sont pas entièrement objectives)
- À propos de HTTP et HTTPS - moins de la moitié des sites du volume trouvé utilisent ce dernier, mais compte tenu du fait que ma base de données n'est pas complète, mais seulement 40% du nombre total, il est fort possible que la plupart de la seconde moitié des sites puissent et communiquent via HTTPS .
Statistiques du pare-feu:
 Pare-feu - Numéro
Pare-feu - NuméroModSecurity: 4354
IBM Web App Security: 126
Meilleure sécurité WP: 110
CloudFlare: 104
Imperva SecureSphere: 45
Juniper WebApp Secure: 45
Statistiques du serveur Web
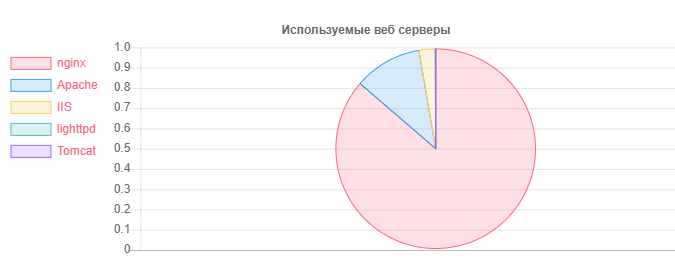 Serveur Web - Numéro
Serveur Web - NuméroNginx: 31752
Apache: 4042
IIS: 959
Installations obsolètes et potentiellement vulnérables de Nginx: 20966
Installations obsolètes et potentiellement vulnérables d'Apache: 995
Malgré le fait que hoster.by soit le leader dans les domaines et l'hébergement, par exemple, en général, Open Contact s'est également distingué, mais la vérité est dans le nombre de sites sur une IP:
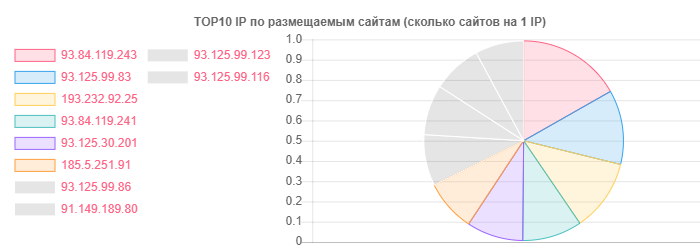 IP - Sites
IP - Sites93.84.119.243: 556
93.125.99.83: 399
193.232.92.25: 386
Par e-mail, les statistiques détaillées ont vraiment décidé de ne pas être extraites, non triées par zone de domaine, mais plutôt, il était intéressant de voir l'emplacement des utilisateurs par rapport à des fournisseurs spécifiques:
- Sur le service TUT.BY: 38282
- Sur le service Yandex (par | ru): 28127
- Sur le service Gmail: 33452
- Lié à Facebook: 866
- Lié à Twitter: 652
- En vedette dans les fuites selon HIBP: 7844
- L'intelligence passive a permis d'identifier plus de 13 000 adresses e-mail
Comme vous pouvez le voir, l'image globale est assez positive, en particulier l'utilisation active de nginx de la part des hébergeurs. Cela est peut-être en grande partie dû au type d'hébergement partagé populaire parmi les utilisateurs ordinaires.
Du fait que je n'aimais pas vraiment ça - il y a un nombre suffisant de fournisseurs d'hébergement de la main du milieu qui ont remarqué des erreurs comme AXFR, utilisé des versions obsolètes de SSH et Apache et quelques autres problèmes mineurs. Ici, bien sûr, plus de lumière sur la situation pourrait être apportée par la phase active, mais pour le moment, en vertu de notre législation, il me semble que c'est impossible, et je ne voudrais pas vraiment m'engager dans les rangs des ravageurs pour de telles questions.
L'image de l'e-mail est généralement plutôt rose, si vous pouvez l'appeler ainsi. Oh oui, où le fournisseur TUT.BY est indiqué - cela signifiait utiliser le domaine, car Ce service fonctionne sur la base de Yandex.
Conclusion
En conclusion, je peux dire une chose - même avec les résultats disponibles, vous pouvez rapidement comprendre qu'il y a beaucoup de travail pour les spécialistes impliqués dans le nettoyage des sites contre les virus, la configuration du WAF et la configuration / l'ajout de différents CMS.
Eh bien, sérieusement, comme dans les deux articles précédents, nous voyons que les problèmes existent à des niveaux absolument différents dans absolument tous les segments de l'Internet et des pays, et certains d'entre eux proposent même une étude à distance de la question, sans utiliser de méthodes offensantes, etc. e. utiliser des informations accessibles au public pour collecter les compétences spéciales qui ne sont pas requises.