
Dans le dernier article, nous avons examiné les fondements théoriques de l'architecture réactive. Il est temps de parler des flux de données, des moyens de mettre en œuvre des systèmes réactifs Erlang / Elixir et des modèles de messagerie en eux:
- Demander une réponse
- Réponse fragmentée à la demande
- Réponse avec demande
- Publier-s'abonner
- Publication-abonnement inversé
- Répartition des tâches
SOA, MSA et messagerie
SOA, MSA - architectures système qui définissent les règles de construction des systèmes, tandis que la messagerie fournit des primitives pour leur mise en œuvre.
Je ne veux pas promouvoir telle ou telle architecture des systèmes de construction. Je suis pour l'utilisation des pratiques les plus efficaces et utiles pour un projet et une entreprise particuliers. Quel que soit le paradigme que nous choisissons, il est préférable de créer des blocs système avec un œil sur la voie Unix: des composants avec une connectivité minimale qui sont responsables d'entités individuelles. Les méthodes API effectuent les actions les plus simples avec les entités.
Messagerie - comme son nom l'indique, est un courtier de messages. Son objectif principal est de recevoir et de transmettre des messages. Il est responsable des interfaces d'envoi des informations, de la formation des canaux logiques de transmission des informations au sein du système, du routage et de l'équilibrage, ainsi que du traitement des défaillances au niveau du système.
La messagerie en cours de développement n'essaie pas de concurrencer ou de remplacer rabbitmq. Ses principales caractéristiques:
- Distribution
Des points d'échange peuvent être créés sur tous les nœuds du cluster, le plus près possible du code qui les utilise. - Simplicité.
Concentrez-vous sur la minimisation du code standard et de l'utilisabilité. - La meilleure performance.
Nous n'essayons pas de répéter la fonctionnalité de rabbitmq, mais seulement de mettre en évidence la couche architecturale et de transport, qui est aussi simple que possible dans OTP, minimisant les coûts. - Souplesse.
Chaque service peut combiner de nombreux modèles d'échange. - Tolérance aux pannes inhérente à la conception.
- Évolutivité.
La messagerie grandit avec l'application. À mesure que la charge augmente, vous pouvez déplacer les points d'échange vers des machines individuelles.
Remarque. Du point de vue de l'organisation du code, les méta-projets sont bien adaptés aux systèmes complexes avec Erlang / Elixir. Tout le code de projet est dans un référentiel - un projet cadre. Dans le même temps, les microservices sont aussi isolés que possible et effectuent des opérations simples qui sont responsables d'une entité distincte. Avec cette approche, il est facile de prendre en charge l'API de l'ensemble du système, il suffit d'apporter des modifications, il est pratique d'écrire des unités et des tests d'intégration.
Les composants du système interagissent directement ou via un courtier. Du point de vue de la messagerie, chaque service comporte plusieurs phases de vie:
- Initialisation du service.
À ce stade, la configuration et le lancement du processus d'exécution du service et des dépendances ont lieu. - Création d'un point d'échange.
Le service peut utiliser le point d'échange statique spécifié dans la configuration du nœud ou créer des points d'échange de manière dynamique. - Inscription au service.
Pour que le service puisse répondre aux demandes, il doit être enregistré au point d'échange. - Fonctionnement normal.
Le service produit un travail utile. - Arrêtez.
Il existe 2 types d'arrêt: régulier et d'urgence. Avec un service régulier, il se déconnecte du point d'échange et s'arrête. En cas d'urgence, la messagerie exécute l'un des scénarios de basculement.
Cela semble assez compliqué, mais tout n'est pas si effrayant dans le code. Des exemples de code avec commentaires seront donnés dans l'analyse des modèles un peu plus tard.
Échanges
Un point d'échange est un processus de messagerie qui implémente la logique d'interaction avec des composants dans un modèle de messagerie. Dans tous les exemples ci-dessous, les composants interagissent via des points d'échange, dont la combinaison forme une messagerie.
Modèles d'échange de messages (MPE)
À l'échelle mondiale, les modèles de partage peuvent être divisés en deux sens et unidirectionnel. Les premiers impliquent une réponse au message reçu, les seconds non. Un exemple classique d'un modèle bidirectionnel dans une architecture client-serveur est le modèle de demande-réponse. Considérez le modèle et ses modifications.
Demande - réponse ou RPC
RPC est utilisé lorsque nous devons obtenir une réponse d'un autre processus. Ce processus peut être lancé sur le même site ou situé sur un continent différent. Vous trouverez ci-dessous un schéma de l'interaction du client et du serveur via la messagerie.
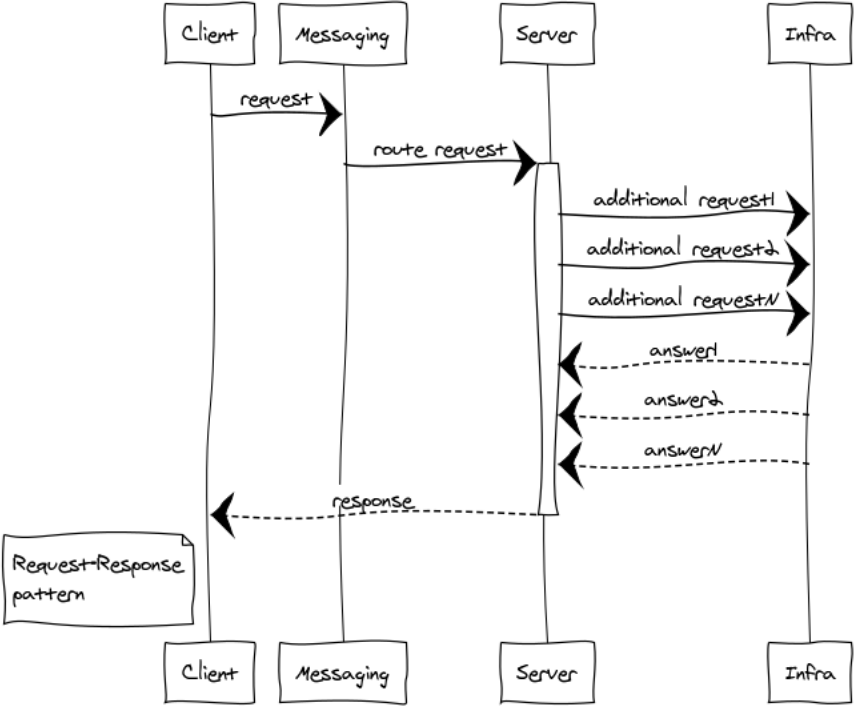
La messagerie étant totalement asynchrone, pour le client l'échange est divisé en 2 phases:
Demande de soumission
messaging:request(Exchange, ResponseMatchingTag, RequestDefinition, HandlerProcess).
Exchange - un nom unique pour le point d'échange
ResponseMatchingTag - L'étiquette locale pour gérer la réponse. Par exemple, dans le cas d'envoi de plusieurs demandes identiques appartenant à différents utilisateurs.
RequestDefinition - corps de la demande
HandlerProcess - Gestionnaire PID. Ce processus recevra une réponse du serveur.
Traitement des réponses
handle_info(#'$msg'{exchange = EXCHANGE, tag = ResponseMatchingTag,message = ResponsePayload}, State)
ResponsePayload - réponse du serveur.
Pour le serveur, le processus comprend également 2 phases:
- Initialisation du point d'échange
- Traitement des demandes entrantes
Illustrons ce modèle avec du code. Supposons que nous ayons besoin d'implémenter un service simple qui fournit la seule méthode d'heure exacte.
Code serveur
Retirez la définition de l'API de service dans api.hrl:
Définissez un contrôleur de service dans time_controller.erl
Code client
Pour envoyer une demande à un service, vous pouvez appeler l'API de demande de messagerie n'importe où dans le client:
case messaging:request(?EXCHANGE, tag, #time_req{opts = #{}}, self()) of ok -> ok; _ ->
Dans un système distribué, la configuration des composants peut être très différente et au moment de la demande, la messagerie peut ne pas encore démarrer, ou le contrôleur de service ne sera pas prêt à répondre à la demande. Par conséquent, nous devons vérifier la réponse de la messagerie et gérer le cas d'échec.
Après l'envoi réussi, le client recevra une réponse ou une erreur du service.
Gérez les deux cas dans handle_info:
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time{unixtime = Utime}}}, State) -> ?debugVal(Utime), {noreply, State}; handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time_error{code = ErrorCode}}}, State) -> ?debugVal({error, ErrorCode}), {noreply, State};
Réponse fragmentée à la demande
Mieux vaut ne pas autoriser la transmission de gros messages. La réactivité et le fonctionnement stable de l'ensemble du système en dépendent. Si la réponse à la demande prend beaucoup de mémoire, la décomposition en plusieurs parties est obligatoire.
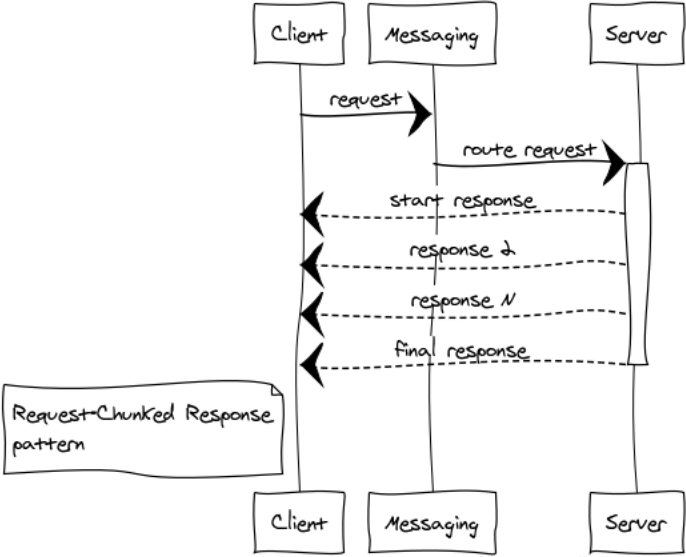
Je vais donner quelques exemples de tels cas:
- Les composants échangent des données binaires, telles que des fichiers. La décomposition de la réponse en petites parties permet de travailler efficacement avec des fichiers de toute taille et de ne pas rattraper les débordements de mémoire.
- Inscriptions. Par exemple, nous devons sélectionner tous les enregistrements d'une énorme table dans la base de données et les transférer vers un autre composant.
J'appelle ces réponses une locomotive. Dans tous les cas, 1024 messages de 1 Mo sont meilleurs qu'un seul message de 1 Go.
Dans le cluster Erlang, nous obtenons un gain supplémentaire - réduisant la charge sur le point d'échange et le réseau, car les réponses sont immédiatement envoyées au destinataire, contournant le point d'échange.
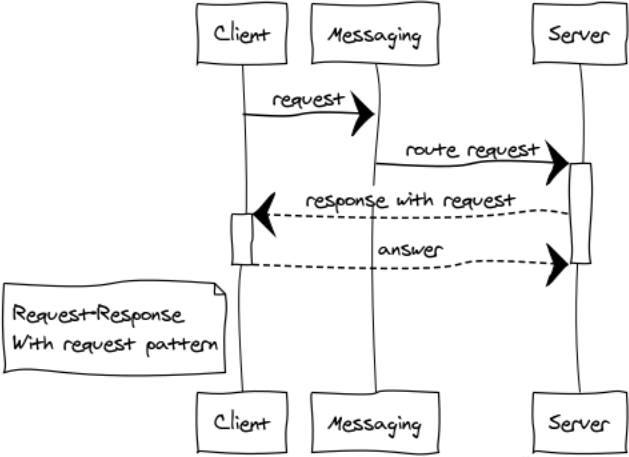
Réponse avec demande
Il s'agit d'une modification assez rare du modèle RPC pour la création de systèmes interactifs.
Publier-s'abonner (arbre de distribution des données)
Les systèmes orientés événements fournissent des données aux consommateurs lorsque les données sont disponibles. Ainsi, les systèmes sont plus enclins à pousser des modèles qu'à tirer ou à interroger. Cette fonctionnalité vous permet de ne pas gaspiller des ressources en interrogeant et en attendant constamment des données.
La figure montre le processus de distribution d'un message aux consommateurs abonnés à un sujet spécifique.
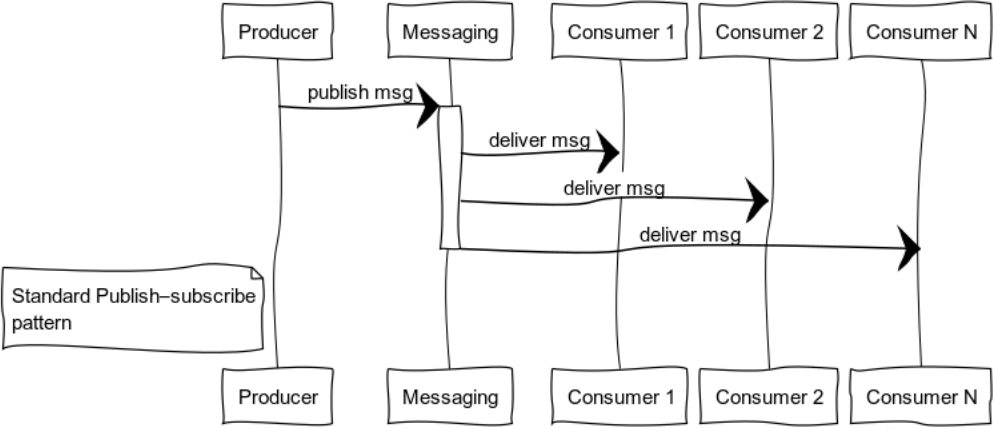
Des exemples classiques de l'utilisation de ce modèle sont la distribution de l'État: le monde du jeu dans les jeux informatiques, les données du marché sur les échanges, les informations utiles dans les flux de données.
Considérez le code d'abonné:
init(_Args) ->
La source peut appeler la fonction de post-publication à tout endroit approprié:
messaging:publish_message(Exchange, Key, Message).
Exchange - le nom du point d'échange,
Clé - clé de routage
Message - charge utile
Publication-abonnement inversé
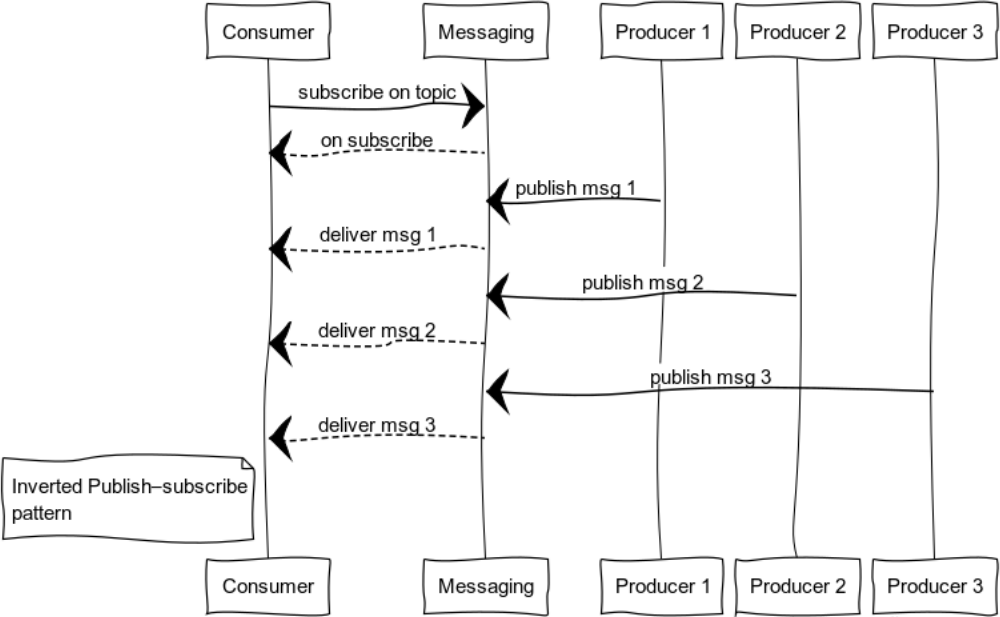
En développant pub-sub, vous pouvez obtenir un modèle pratique pour la journalisation. L'ensemble des sources et des consommateurs peut être complètement différent. La figure montre un cas avec un consommateur et plusieurs sources.
Modèle de distribution des tâches
Dans presque tous les projets, des tâches de traitement différé surviennent, telles que la génération de rapports, l'envoi de notifications, la réception de données de systèmes tiers. Le débit d'un système qui effectue ces tâches est facilement évolutif en ajoutant des gestionnaires. Il ne nous reste plus qu'à former un cluster de gestionnaires et à répartir uniformément les tâches entre eux.
Considérez les situations qui surviennent avec l'exemple de 3 gestionnaires. Même au stade de la répartition des tâches, la question de l'équité de la répartition et du débordement des processeurs se pose. La distribution à tour de rôle sera responsable de la justice, et afin d'éviter une situation de débordement de gestionnaires, nous introduisons la restriction prefetch_limit . Dans les modes transitoires, prefetch_limit empêchera un gestionnaire de recevoir toutes les tâches.
La messagerie gère les files d'attente et la priorité de traitement. Les gestionnaires reçoivent des tâches à mesure qu'elles deviennent disponibles. La tâche peut réussir ou échouer:
messaging:ack(Tack) - appelé en cas de succès de traitement des messagesmessaging:nack(Tack) - appelé dans toutes les situations d'urgence. Après le retour de la tâche, la messagerie la transférera à un autre gestionnaire.
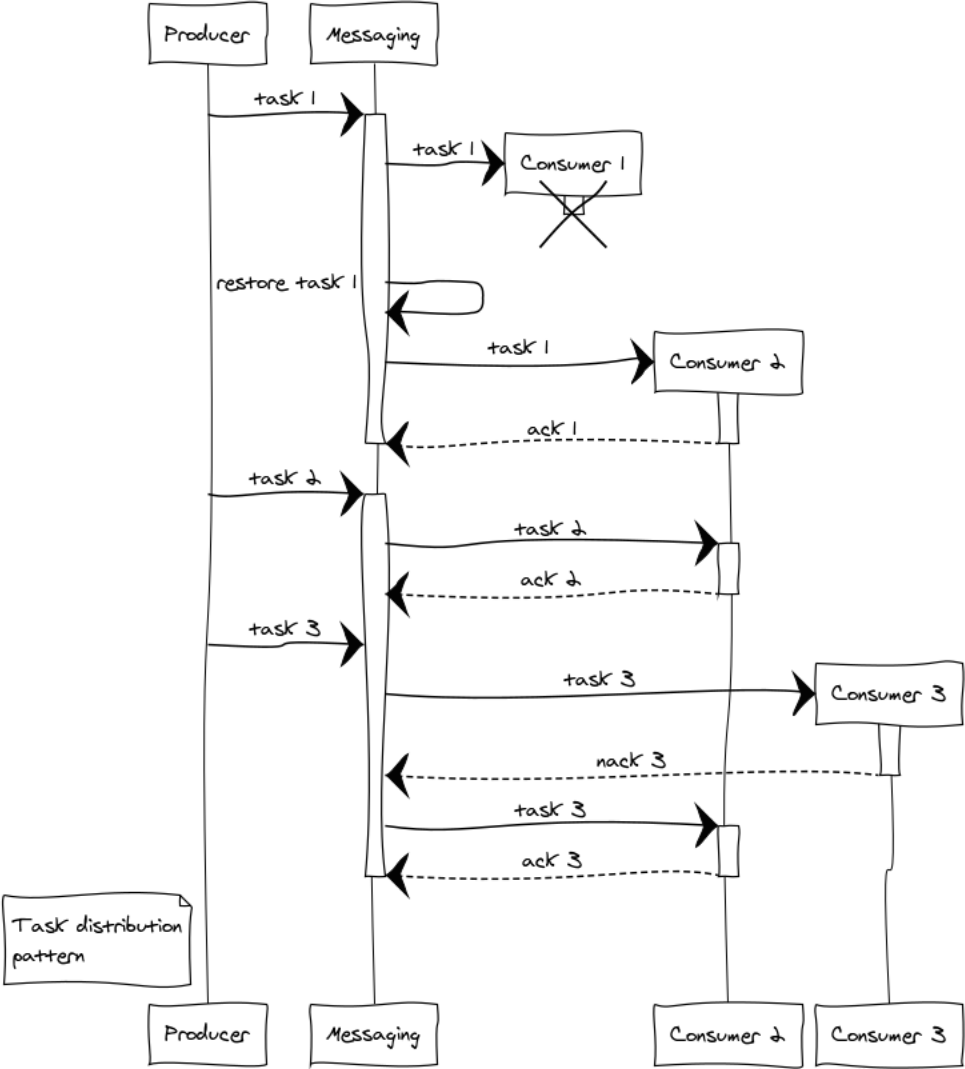
Supposons qu'une défaillance complexe se soit produite lors du traitement de trois tâches: le gestionnaire 1, après avoir reçu la tâche, s'est écrasé avant de pouvoir communiquer avec le point d'échange. Dans ce cas, le point d'échange après l'expiration du délai d'expiration de l'acquittement transférera le travail à un autre gestionnaire. Le gestionnaire 3, pour une raison quelconque, a abandonné la tâche et l'a envoyée nack. Par conséquent, la tâche a également été transmise à un autre gestionnaire qui l'a terminée avec succès.
Résultat préliminaire
Nous avons démonté les blocs de construction de base des systèmes distribués et avons acquis une compréhension de base de leur application dans Erlang / Elixir.
En combinant des modèles de base, vous pouvez créer des paradigmes complexes pour résoudre les problèmes émergents.
Dans la dernière partie du cycle, nous examinerons les problèmes généraux d'organisation des services, de routage et d'équilibrage, et nous parlerons également du côté pratique de l'évolutivité et de la tolérance aux pannes des systèmes.
La fin de la deuxième partie.
Photo Marius Christensen
Illustrations préparées par websequencediagrams.com