Le troisième article de la série et une petite branche de la série principale - cette fois, je vais montrer comment fonctionne la bibliothèque de tests d'intégration de Spring et comment elle fonctionne, ce qui se passe lorsque le test démarre et comment vous pouvez affiner l'application et son environnement pour le test.
J'ai été invité à écrire cet article par un commentaire Hixon10 sur la façon d'utiliser une vraie base, telle que Postgres, dans un test d'intégration. L'auteur du commentaire a suggéré d'utiliser la bibliothèque tout-inclus pratique embedded-database-spring-test . Et j'ai déjà ajouté un paragraphe et un exemple d'utilisation dans le code, mais j'ai réfléchi. Bien sûr, prendre une bibliothèque prête à l'emploi est correct et bon, mais si l'objectif est de comprendre comment écrire des tests pour une application Spring, il sera plus utile de montrer comment implémenter vous-même la même fonctionnalité. Tout d'abord, c'est une excellente raison de parler de ce qui se cache sous le capot du Spring Test . Et deuxièmement, je crois que vous ne pouvez pas compter sur des bibliothèques tierces, si vous ne comprenez pas comment elles sont organisées à l'intérieur, cela ne fait que renforcer le mythe de la "magie" de la technologie.
Cette fois, il n'y aura pas de fonctionnalité utilisateur, mais il y aura un problème qui doit être résolu - je veux démarrer la vraie base de données sur un port aléatoire et connecter automatiquement l'application à cette base de données temporaire, et après les tests, j'arrête et je supprime la base de données.
Au début, comme déjà de coutume, un peu de théorie. Aux personnes qui ne sont pas trop familières avec les concepts de bin, de contexte, de configuration, je recommande de rafraîchir les connaissances, par exemple, dans mon article Le verso de Spring / Habr .
Test de printemps
Spring Test est l'une des bibliothèques incluses dans Spring Framework, en fait tout ce qui est décrit dans la section documentation sur les tests d'intégration est à peu près tout. Les quatre tâches principales que la bibliothèque résout sont:
- Gérer les conteneurs Spring IoC et leur mise en cache entre les tests
- Fournir une injection de dépendance pour les classes de test
- Fournir une gestion des transactions adaptée aux tests d'intégration
- Fournir un ensemble de classes de base pour aider le développeur à écrire des tests d'intégration
Je recommande fortement de lire la documentation officielle, elle dit beaucoup de choses utiles et intéressantes. Ici, je vais vous donner un aperçu rapide et quelques conseils pratiques qui sont utiles à garder à l'esprit.
Test du cycle de vie
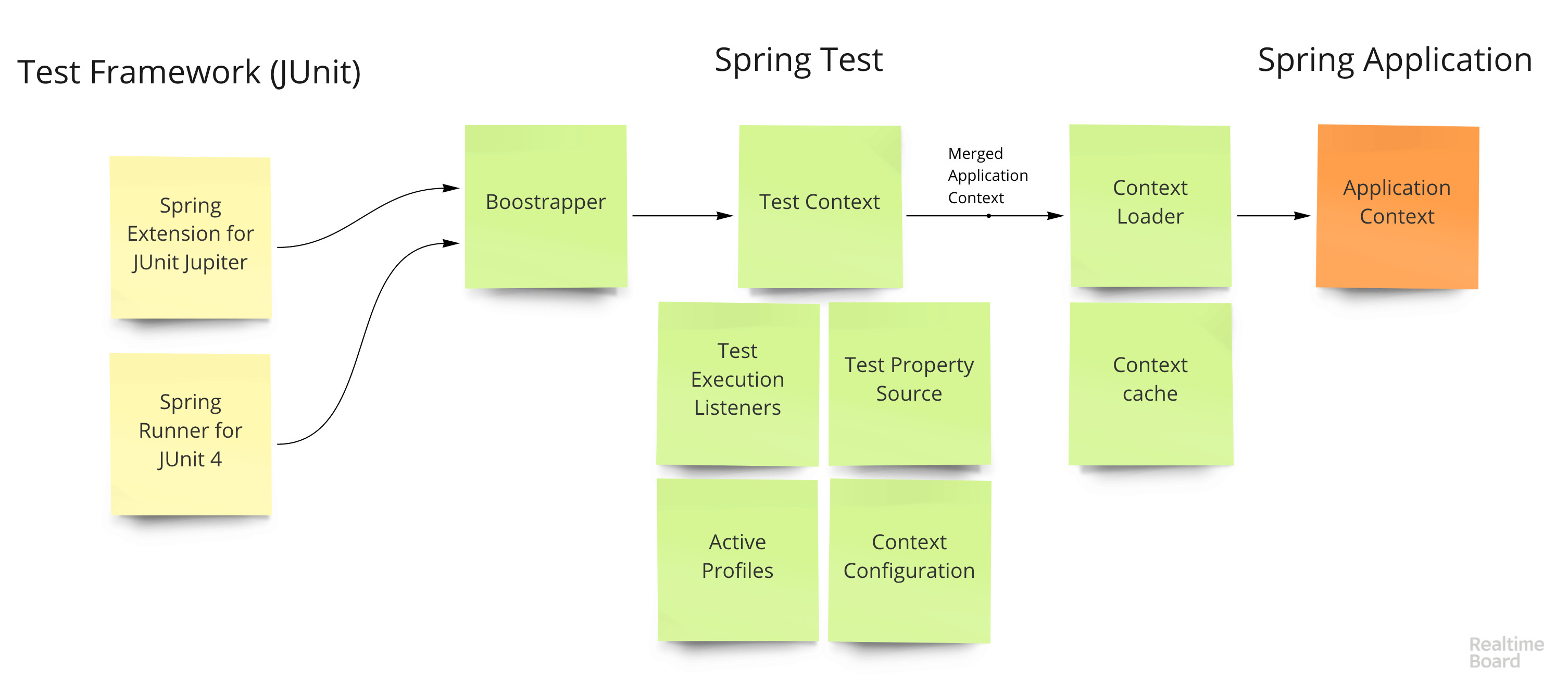
Le cycle de vie d'un test ressemble à ceci:
- L'extension du framework de test (
SpringRunner pour JUnit 4 et SpringExtension pour JUnit 5) appelle Test Context Bootstrapper - Boostrapper crée
TestContext - la classe principale qui stocke l'état actuel du test et de l'application TestContext configure différents hooks (comme le démarrage de transactions avant le test et la restauration après), injecte des dépendances dans les classes de test (tous les champs @Autowired sur les classes de test) et crée des contextes- Un contexte est créé à l'aide du chargeur de contexte - il prend la configuration de base de l'application et la fusionne avec la configuration de test (propriétés chevauchées, profils, bacs, initialiseurs, etc.)
- Le contexte est mis en cache à l'aide d'une clé composite qui décrit entièrement l'application - un ensemble de bacs, de propriétés, etc.
- Essais
Tout le sale boulot de la gestion des tests se fait, en fait, par spring-test , et le Spring Boot Test à son tour, ajoute plusieurs classes d'assistance, comme les familiers @DataJpaTest et @SpringBootTest , des utilitaires utiles comme TestPropertyValues pour changer dynamiquement les propriétés du contexte. Il vous permet également d'exécuter l'application comme un vrai serveur Web ou comme un environnement simulé (sans accès via HTTP), il est pratique d'effacer les composants du système à l'aide de @MockBean , etc.
Mise en cache du contexte
Peut-être l'un des sujets très obscurs des tests d'intégration qui soulève de nombreuses questions et idées fausses est la mise en cache du contexte (voir paragraphe 5 ci-dessus) entre les tests et son effet sur la vitesse des tests. Un commentaire que j'entends souvent est que les tests d'intégration sont "lents" et "exécutent l'application pour chaque test". Donc, ils fonctionnent - mais pas pour chaque test. Chaque contexte (c'est-à-dire l'instance d'application) sera réutilisé au maximum, c'est-à-dire si 10 tests utilisent la même configuration d'application, l'application démarrera une fois pour les 10 tests. Que signifie la "même configuration" de l'application? Pour Spring Test, cela signifie que l'ensemble des beans, classes de configuration, profils, propriétés, etc., n'a pas changé. En pratique, cela signifie que, par exemple, ces deux tests utiliseront le même contexte:
@SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class FirstTest { } @SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class SecondTest { }
Le nombre de contextes dans le cache est limité à 32 - en outre, selon le principe LRSU, l'un d'eux sera supprimé du cache.
Qu'est-ce qui peut empêcher le Spring Test de réutiliser le contexte du cache et d'en créer un nouveau?
@DirtiesContext
L'option la plus simple est que si le test est marqué d'annotations, le contexte ne sera pas mis en cache. Cela peut être utile si le test modifie l'état de l'application et que vous souhaitez la "réinitialiser".
@MockBean
Une option très peu évidente, je l'ai même rendue séparément - @MockBean remplace le vrai bean en contexte par une maquette qui peut être testée via Mockito (dans les articles suivants, je montrerai comment l'utiliser). Le point clé est que cette annotation modifie l'ensemble de beans dans l'application et force Spring Test à créer un nouveau contexte. Si nous prenons l'exemple précédent, par exemple, deux contextes seront déjà créés ici:
@SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class FirstTest { } @SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class SecondTest { @MockBean CakeFinder cakeFinderMock; }
@TestPropertySource
Toute modification de propriété modifie automatiquement la clé de cache et un nouveau contexte est créé.
@ActiveProfiles
La modification des profils actifs affectera également le cache.
@ContextConfiguration
Et bien sûr, tout changement de configuration créera également un nouveau contexte.
Nous commençons la base
Alors maintenant, avec toutes ces connaissances, nous allons essayer décoller comprendre comment et où exécuter la base de données. Il n'y a pas une seule bonne réponse ici, cela dépend des exigences, mais vous pouvez penser à deux options:
- Exécutez une fois avant tous les tests de la classe.
- Exécutez une instance aléatoire et une base de données distincte pour chaque contexte mis en cache (potentiellement plus d'une classe).
Selon les besoins, vous pouvez choisir n'importe quelle option. Si dans mon cas, Postgres démarre relativement rapidement et que la deuxième option semble appropriée, alors la première peut convenir à quelque chose de plus difficile.
La première option n'est pas liée à Spring, mais plutôt à un framework de test. Par exemple, vous pouvez créer votre extension pour JUnit 5 .
Si vous rassemblez toutes les connaissances sur la bibliothèque de test, les contextes et la mise en cache, la tâche se résume à ce qui suit: lors de la création d'un nouveau contexte d'application, vous devez exécuter la base de données sur un port aléatoire et transférer les données de connexion au contexte .
ApplicationContextInitializer interface ApplicationContextInitializer est responsable de l'exécution des actions avec le contexte avant le lancement dans Spring.
ApplicationContextInitializer
L'interface n'a qu'une seule méthode d' initialize , qui est exécutée avant le "démarrage" du contexte (c'est-à-dire avant l'appel de la méthode de refresh ) et vous permet d'apporter des modifications au contexte - ajouter des bacs, des propriétés.
Dans mon cas, la classe ressemble à ceci:
public class EmbeddedPostgresInitializer implements ApplicationContextInitializer<GenericApplicationContext> { @Override public void initialize(GenericApplicationContext applicationContext) { EmbeddedPostgres postgres = new EmbeddedPostgres(); try { String url = postgres.start(); TestPropertyValues values = TestPropertyValues.of( "spring.test.database.replace=none", "spring.datasource.url=" + url, "spring.datasource.driver-class-name=org.postgresql.Driver", "spring.jpa.hibernate.ddl-auto=create"); values.applyTo(applicationContext); applicationContext.registerBean(EmbeddedPostgres.class, () -> postgres, beanDefinition -> beanDefinition.setDestroyMethodName("stop")); } catch (IOException e) { throw new RuntimeException(e); } } }
La première chose qui se produit ici est que Postgres intégré est lancé à partir de la bibliothèque yandex-qatools / postgresql-embedded . Ensuite, un ensemble de propriétés est créé - l'URL JDBC pour la base nouvellement lancée, le type de pilote et le comportement Hibernate pour le schéma (créer automatiquement). Une chose non évidente est seulement spring.test.database.replace=none - c'est ce que nous disons à DataJpaTest que nous n'avons pas besoin d'essayer de se connecter à la base de données intégrée, comme H2, et nous n'avons pas besoin de remplacer le bac DataSource (cela fonctionne).
Et un autre point important est application.registerBean(…) . En général, ce bean ne peut bien sûr pas être enregistré - si personne ne l'utilise dans l'application, il n'est pas particulièrement nécessaire. L'enregistrement n'est nécessaire que pour spécifier la méthode destroy que Spring appellera lorsque le contexte sera détruit, et dans mon cas, cette méthode appellera postgres.stop() et arrêtera la base de données.
En général, c'est tout, la magie s'est terminée, le cas échéant. Je vais maintenant enregistrer cet initialiseur dans un contexte de test:
@DataJpaTest @ContextConfiguration(initializers = EmbeddedPostgresInitializer.class) ...
Ou même pour plus de commodité, vous pouvez créer votre propre annotation, car nous aimons tous les annotations!
@Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @DataJpaTest @ContextConfiguration(initializers = EmbeddedPostgresInitializer.class) public @interface EmbeddedPostgresTest { }
Désormais, tout test annoté par @EmbeddedPostgrestTest démarrera la base de données sur un port aléatoire et avec un nom aléatoire, configurera Spring pour se connecter à cette base de données et l'arrêtera à la fin du test.
@EmbeddedPostgresTest class JpaCakeFinderTestWithEmbeddedPostgres { ... }
Conclusion
Je voulais montrer qu'il n'y a pas de magie mystérieuse au printemps, il y a juste beaucoup de mécanismes internes «intelligents» et flexibles, mais en les connaissant, vous pouvez obtenir un contrôle complet sur les tests et l'application elle-même. En général, dans les projets de combat, je ne motive pas tout le monde à écrire leurs propres méthodes et classes pour configurer l'environnement d'intégration pour les tests, s'il existe une solution toute faite, alors vous pouvez la prendre. Bien que si toute la méthode consiste en 5 lignes de code, il est probablement superflu de faire glisser la dépendance dans le projet, en particulier de ne pas comprendre l'implémentation.
Liens vers d'autres articles de la série