Nous concluons la série d'articles consacrés aux règles de corrélation qui sortent du cadre. Nous nous sommes fixé pour objectif de formuler une approche qui nous permettrait de créer des règles de corrélation qui peuvent fonctionner «prêtes à l'emploi» avec un minimum de faux positifs.
Image: Marketing logicielTous les points clés de l'article sont disponibles en
conclusion , au même endroit cette méthodologie est présentée sous forme de
diagramme graphique.
Brièvement sur ce qui était dans les articles précédents: ils ont décrit à quoi devrait ressembler un ensemble de champs d'un événement normalisé - un
schéma ; quel système de
catégorisation des événements utiliser; comment, à l'aide d'un système de catégorisation et d'un schéma, unifier le
processus de normalisation des événements. Nous avons également examiné le
contexte de la mise en œuvre des règles de corrélation et examiné ce que SIEM devrait savoir sur le système automatisé (AS) qu'il surveille, et pourquoi.
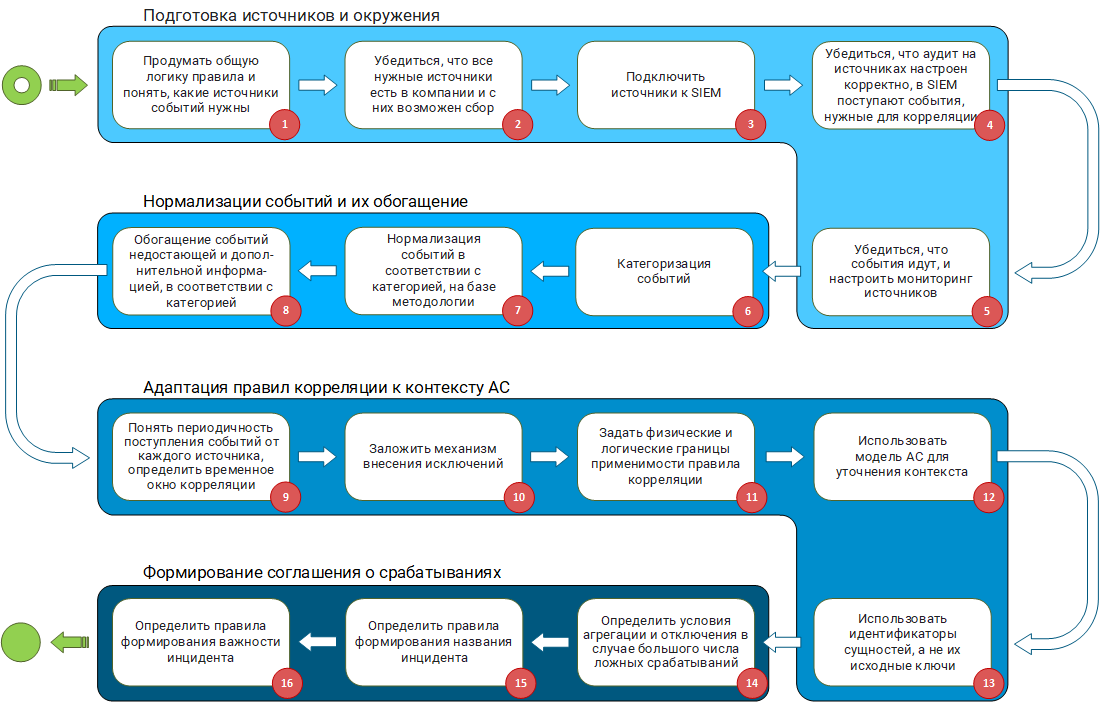
Toutes les approches et le raisonnement ci-dessus sont les blocs à partir desquels la méthodologie pour développer des règles de corrélation est construite. Il est temps de les assembler et de regarder l'ensemble du tableau.
L'ensemble de la méthodologie d'élaboration des règles de corrélation se compose de quatre blocs:
- préparation des sources et des environs;
- normalisation des événements et leur enrichissement;
- adaptation des règles de corrélation au contexte de l'AS;
- formation d'un accord sur les positifs.
Préparation des sources et des environnements
Les règles de corrélation fonctionnent sur les événements qui génèrent des sources. À cet égard, il est extrêmement important que les sources requises pour les règles de corrélation soient présentes dans les haut-parleurs et soient correctement configurées.
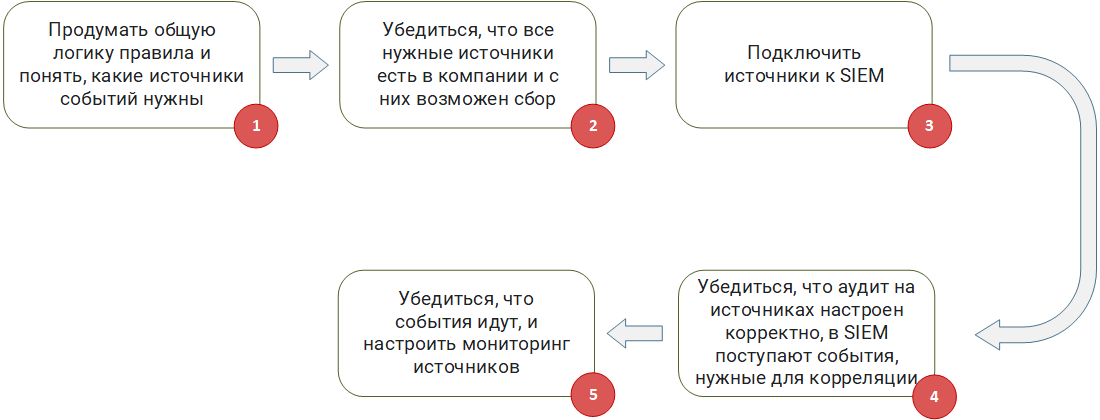 Préparation des sources et des environnementsÉtape 1
Préparation des sources et des environnementsÉtape 1 :
Réfléchissez à la logique générale de la règle et comprenez quelles sources d'événements sont nécessaires. Si vous développez à partir de zéro ou prenez une
règle de corrélation
Sigma prête à l'emploi, vous devez comprendre en fonction des événements à partir de quelles sources cela fonctionnera.
Étape 2 :
Assurez-vous que toutes les sources nécessaires se trouvent dans l'entreprise et qu'elles peuvent être collectées. Une situation est possible lorsqu'une règle opère sur une chaîne d'événements provenant de plusieurs sources du formulaire (événement A de la source 1) - (événement B de la source 2) - (événement C de la source 3) pendant 5 minutes. Si votre entreprise n'a pas au moins une source, une telle règle devient inutile, car elle ne fonctionnera jamais. Vous devez comprendre si, en principe, il est possible de collecter des événements auprès des sources nécessaires et si votre SIEM peut les fournir. Par exemple, la source écrit des événements dans un fichier, mais le fichier est chiffré ou une base de données non standard est utilisée sur la source pour le stockage, dont l'accès ne peut pas être assuré via le pilote ODBC / JDBC standard.
Étape 3 :
connectez les sources au SIEM. Peu importe à quel point cela peut sembler banal, mais à cette étape, il est nécessaire de mettre en œuvre la collecte d'événements. Il y a souvent de nombreux problèmes. Par exemple, des problèmes d'organisation, lorsque la direction informatique interdit catégoriquement la connexion aux systèmes critiques. Ou technique, sans paramètres supplémentaires, l'agent SIEM (SmartConnector, Universal Forwarder), lors de la collecte des événements, «tue» simplement la source, conduisant à un déni de service. Cela peut souvent être observé lors de la connexion de SGBD très chargés à SIEM.
Étape 4 :
Assurez-vous que l'audit sur les sources est correctement configuré, les événements nécessaires à la corrélation sont reçus dans SIEM. Les règles de corrélation attendent certains types d'événements. Ils doivent être générés par la source. Il arrive souvent que pour générer les événements nécessaires aux règles, la source doit être configurée en plus: l'audit avancé est activé et la sortie du journal dans un certain format est configurée.
L'activation de l'audit étendu affecte souvent la quantité de flux d'événements (EPS) reçus dans le SIEM de la source. Étant donné que la source elle-même et le SIEM relèvent de la responsabilité de différents services, il y a toujours un risque que l'audit étendu soit désactivé et, par conséquent, les types d'événements nécessaires cessent d'arriver au SIEM. Ce problème peut être partiellement détecté en surveillant le flux d'événements pour chaque source, ou plutôt en surveillant les changements dans les événements par seconde (EPS).
Étape 5 :
Vérifiez que les événements sont en cours et configurez la surveillance des sources. Dans toute infrastructure, tôt ou tard, des défaillances du réseau ou de la source elle-même apparaissent. À ce stade, SIEM perd le contact avec la source et ne peut pas recevoir d'événements. Si la source est passive et écrit ses journaux dans un fichier ou une base de données, les événements ne seront pas perdus en cas d'échec, et SIEM pourra les recevoir lorsque la communication sera rétablie. Si la source est active et envoie des événements à SIEM, par exemple, via syslog, sans les enregistrer ailleurs, les événements seront perdus en cas d'échec et votre règle de corrélation ne fonctionnera tout simplement pas, car l'événement souhaité n'attendra pas. En creusant plus profondément, vous pouvez voir que, même lorsque vous travaillez avec une source passive, lors de la restauration de la communication après une défaillance, rien ne garantit que les règles de corrélation fonctionneront, en particulier celles qui fonctionnent avec des fenêtres temporelles. Considérez l'exemple de règle décrit ci-dessus: (événement A de la source 1) - (événement B de la source 2) - (événement C de la source 3) pendant 5 minutes. Si une défaillance se produit après l'événement B et que la connexion est rétablie dans une heure, la corrélation ne fonctionnera pas, car l'événement C n'arrivera pas dans les 5 minutes attendues.
En gardant ces fonctionnalités à l'esprit, vous devez configurer la surveillance des sources à partir desquelles les événements sont collectés. Ce suivi doit surveiller la disponibilité des sources, la ponctualité de l'arrivée des événements à partir de celles-ci, la puissance du flux des événements collectés (EPS).
Le déclenchement du système de surveillance est la première cloche qui parle de l'apparition d'un facteur négatif affectant les performances de tout ou partie des règles de corrélation.
Normalisation des événements et leur enrichissement
La collecte des événements nécessaires à la corrélation ne suffit pas. Les événements arrivant au SIEM doivent être normalisés en stricte conformité avec les règles acceptées. Nous avons écrit sur les problèmes de normalisation et la formation d'une méthodologie de normalisation dans un
article séparé. En général, ce bloc peut être caractérisé comme une lutte contre les déchets entrants, les déchets
sortants (
GIGO ).
 Normalisation et enrichissement des événementsÉtape 6
Normalisation et enrichissement des événementsÉtape 6 et
étape 7 :
Catégorisation des événements et normalisation des événements en fonction de la catégorie, sur la base de la méthodologie. Nous ne nous attarderons pas sur eux en détail, puisque nous avons examiné ces étapes en détail dans l'article
«Méthodologie de normalisation des événements» .
Étape 8 :
Enrichissement des événements avec des informations manquantes et supplémentaires, conformément à la catégorie. Souvent, les événements entrants ne contiennent pas toujours les informations nécessaires pour que les règles de corrélation fonctionnent. Par exemple, un événement ne contient que l'adresse IP de l'hôte, mais il n'y a aucune information sur son nom de domaine complet ou son nom d'hôte. Autre exemple: un événement contient un ID utilisateur, mais il n'y a pas de nom d'utilisateur dans l'événement. Dans ce cas, les informations nécessaires doivent être extraites de sources externes - bases de données, contrôleurs de domaine ou autres répertoires et ajoutées à l'événement.
Il est important de noter que la catégorisation des événements se produit au tout début - avant la normalisation. En plus du fait que la catégorie définit les règles de normalisation de l'événement, elle définit également la liste des données qui doivent être recherchées dans des sources externes si elles ne se trouvent pas dans l'événement lui-même.
Adapter les règles de corrélation au contexte AS
Après avoir préparé les données d'entrée (événements) et procédé au développement de règles de corrélation, il est nécessaire de prendre en compte les spécificités des événements entrants, l'AS lui-même et sa variabilité. Pour en savoir plus, consultez l'article
«Modèle de système en tant que contexte des règles de corrélation» .
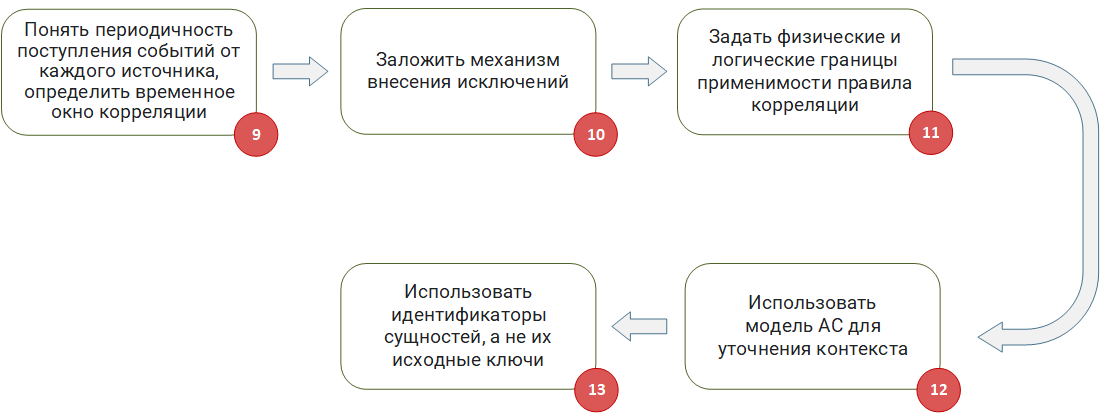 Adapter les règles de corrélation au contexte ASÉtape 9
Adapter les règles de corrélation au contexte ASÉtape 9 :
Comprendre la fréquence des événements de chaque source, déterminer la fenêtre de temps pour la corrélation. Très souvent, les règles de corrélation utilisent des fenêtres temporelles lorsqu'il est nécessaire de prévoir l'arrivée d'un certain événement dans un intervalle de temps donné. Lors de l'élaboration de telles règles, il est important de tenir compte du retard dans la réception des événements. Ils sont généralement causés par deux facteurs.
Premièrement , la source elle-même peut ne pas écrire immédiatement les événements dans la base de données, dans un fichier ou l'envoyer via syslog. Le temps de ce retard doit être estimé et pris en compte dans la règle.
Deuxièmement , il y a un retard dans la livraison des événements au SIEM. Par exemple, la collecte d'événements de la base de données est configurée de sorte que la demande d'événements soit effectuée toutes les 10 minutes, bien sûr, que la fenêtre de corrélation de 5 minutes n'est pas la meilleure solution dans cette situation.
Le problème est aggravé lorsqu'il est nécessaire de développer une règle de corrélation qui fonctionne avec les événements de plusieurs sources à la fois. Dans ce cas, il est important de comprendre qu'ils peuvent avoir des délais de livraison différents. Dans le pire des cas, les événements viendront dans un ordre aléatoire avec une violation de la chronologie. Dans une telle situation, le développeur des règles de corrélation doit clairement comprendre à quel moment le SIEM réalise la corrélation (au moment de l'événement ou quand l'événement est arrivé dans SIEM). Je note que la corrélation dans l'heure d'arrivée des événements est l'option la plus simple et la plus courante sur le plan technique pour traiter les événements en mode pseudo-temps réel. Cependant, cette option ne fait qu'exacerber les problèmes ci-dessus et ne les résout pas.
Si votre SIEM fournit une corrélation dans le temps de l'événement, il existe très probablement des mécanismes de réorganisation des événements qui peuvent restaurer la chronologie réelle des événements.
Dans le cas où vous comprenez que la fenêtre temporelle est trop grande pour effectuer une corrélation sur le flux, vous devez utiliser le mécanisme de rétro-corrélation, dans lequel les événements déjà enregistrés sont sélectionnés dans la base de données SIEM selon le calendrier et parcourent les règles de corrélation.
Étape 10 :
Établir un mécanisme d'exception. Dans le monde réel, il y aura toujours un objet avec un comportement spécial qui ne devrait pas être géré par une règle de corrélation spécifique, car cela conduit à un faux positif. Par conséquent, au stade de l'élaboration des règles, des mécanismes devraient être mis en place pour ajouter de tels objets aux exceptions. Par exemple, si votre règle fonctionne avec les adresses IP des machines, vous avez besoin d'une liste de tableaux dans laquelle vous pouvez ajouter des adresses pour lesquelles la règle ne fonctionnera pas. De même, si une règle fonctionne avec des connexions utilisateur ou des noms de processus, il est nécessaire de travailler au préalable avec des listes d'exclusion de table dans la logique de la règle.
Cette approche vous permettra d'ajouter automatiquement ou manuellement des objets aux exceptions sans avoir à réécrire le corps de la règle.
Étape 11 :
Définissez les limites physiques et logiques de l'applicabilité de la règle de corrélation. Lors de l'élaboration d'une règle de corrélation, il est important de comprendre initialement les limites d'applicabilité (portée) de la règle et si elles existent. Lors de l'élaboration de la logique et du débogage de la règle, il est nécessaire de se concentrer sur les spécificités de ce domaine. Si une règle commence à travailler avec des données qui dépassent le cadre de cette zone, la probabilité de faux positifs augmente.
Deux types de portée peuvent être distingués: physique et logique. La portée physique correspond aux réseaux de l'entreprise et adjacents, et la zone logique correspond aux parties de l'AS, des applications métier ou des processus métier. Exemples de zone physique: segment DMZ, sous-réseaux internes et externes, réseaux d'accès à distance. Exemples de la portée logique des règles: ACS TP, comptabilité, segment PCI DSS, segment PD ou simplement des rôles d'équipement spécifiques - contrôleurs de domaine, commutateurs d'accès, routeurs principaux.
Vous pouvez définir des étendues pour les règles de corrélation via des listes de tableaux. Ils peuvent être remplis manuellement ou automatiquement. Si vous trouvez du temps dans votre entreprise pour la gestion d'actifs (Asset management), alors toutes les données nécessaires peuvent déjà être contenues dans le modèle AS créé dans SIEM. La génération automatique de telles listes tabulaires vous permet d'inclure dynamiquement dans le périmètre de nouveaux actifs qui apparaissent dans l'entreprise. Par exemple, si vous disposiez d'une règle qui fonctionnait exclusivement avec des contrôleurs de domaine, l'ajout d'un nouveau contrôleur à la forêt de domaine sera corrigé dans le modèle et tombera dans le champ d'application de votre règle.
En général, les listes de tableaux utilisées pour les exceptions peuvent être considérées comme des listes noires et les listes responsables de la portée des règles comme des listes blanches.
Étape 12 :
Utilisez le modèle de haut-parleur pour clarifier le contexte. Dans le processus de développement d'une règle de corrélation qui identifie les actions malveillantes, il est important de s'assurer qu'elles peuvent réellement être mises en œuvre. Si cela n'est pas pris en compte, le déclenchement de la règle qui a révélé l'attaque potentielle se révélera faux, car ce type d'attaque peut tout simplement ne pas s'appliquer à votre infrastructure. Je vais expliquer avec un exemple:
- Supposons que nous ayons une règle de corrélation qui détecte les connexions RDP distantes aux serveurs.
- Le pare-feu affiche une tentative de connexion au port TCP 3389 du serveur myserver.local.
- La règle se déclenche et vous commencez à analyser un incident potentiel avec une priorité élevée.
Au cours de l'enquête, vous découvrez rapidement que sur myserver.local 3389, il est fermé et n'a jamais été ouvert par aucun service et Linux est là. C'est un faux positif qui vous a pris du temps pour enquêter.
Autre exemple: IPS envoie un événement déclencheur de signature lorsqu'une tentative est faite pour exploiter la vulnérabilité CVE-2017-0144, cependant, au cours de l'enquête, il s'avère que le correctif correspondant est installé sur la machine attaquée et il n'est pas nécessaire de répondre à un tel incident avec la plus haute priorité.
L'utilisation des données du modèle d'enceinte aidera à régler ce problème.
Étape 13 :
utilisez des identifiants d'entité, pas leurs clés source. Comme déjà décrit dans l'article
«Modèle système en tant que contexte de règles de corrélation», l' adresse IP, le nom de domaine complet et même le MAC d'un actif peuvent changer. Ainsi, si vous utilisez les identifiants de source de l'actif dans la règle de corrélation ou la liste des tables, après un certain temps, il y a de fortes chances de recevoir des faux positifs pour une raison complètement banale, par exemple, le serveur DHCP a simplement délivré cette IP à une autre machine.
Si votre SIEM dispose d'un mécanisme pour identifier les actifs, suivre leurs modifications et vous permettre de fonctionner avec leurs identifiants, vous devez utiliser des identifiants, pas les clés source de l'actif.
Formation d'un accord positif
À l'approche du dernier bloc de création de la règle de corrélation, nous rappelons que le résultat de la règle est un incident évoqué dans SIEM. Les professionnels responsables doivent répondre à un tel incident. Bien que le but de cette série d'articles ne comprenne pas l'examen du processus de réponse aux incidents, il convient de noter qu'une partie des informations sur l'incident est déjà générée au stade de la création de la règle de corrélation correspondante.
Ensuite, nous considérons les points de base à prendre en compte lors de la configuration des paramètres de déclenchement de la règle de corrélation et de génération d'un incident.
 Formation d'un accord positifÉtape 14
Formation d'un accord positifÉtape 14 :
Déterminez les conditions d'agrégation et d'arrêt en cas de grand nombre de faux positifs. Au stade du débogage, et en cours de fonctionnement, si vous n'adhérez pas à cette technique :), de fausses alarmes des règles peuvent se produire. C'est bien s'il y a un ou deux voyages par jour, mais qu'en est-il si une règle a des milliers ou des dizaines de milliers de voyages? Bien sûr, cela suggère que la règle doit être développée davantage. Cependant, il est nécessaire de veiller à ce que dans de telles situations un faux positif aussi massif:
- Cela n'a pas affecté les performances SIEM.
- Parmi la masse des faux positifs, les incidents vraiment importants n'ont pas été perdus. Il existe même un type d'attaque distinct visant à cacher la principale activité malveillante derrière de nombreuses fausses activités .
Des problèmes de ce type peuvent être résolus si, lors de la création d'une règle de corrélation au niveau de l'ensemble du système dans son ensemble ou pour chaque règle séparément, des conditions d'agrégation des incidents et des conditions d'arrêt d'urgence de la règle sont définies.
Le mécanisme d'agrégation des incidents permettra de ne pas créer des millions d'incidents identiques, mais de «coller» de nouveaux incidents à un, à condition qu'ils soient identiques. Dans les cas extrêmes, lorsque même l'agrégation d'incidents donne une charge importante, il est recommandé de configurer la désactivation automatique de la règle de corrélation en cas de dépassement d'un nombre donné d'opérations par unité de temps (minute, heure, jour).
Étape 15 :
Définissez les règles de génération du nom de l'incident. Cet élément est souvent négligé, surtout s'ils ne développent pas de règles pour leur entreprise, par exemple, si une entreprise tierce est responsable de la mise en œuvre du SIEM et de l'élaboration des règles. Le nom de la règle de corrélation, ainsi que l'incident qu'elle a généré, doivent être courts et refléter clairement l'essence d'une règle particulière.
Si plusieurs personnes utilisent des règles d'incidents et de corrélation dans votre entreprise, il est recommandé de développer des règles de dénomination. Ils doivent être compris et acceptés par toute l'équipe travaillant avec SIEM.
Étape 16 :
Définissez les règles pour déterminer l'importance de l'incident. La plupart des solutions SIEM à la dernière étape de la création d'un incident vous permettent de définir son importance et sa signification. Certaines décisions calculent même automatiquement l'importance, en fonction du contexte de l'incident et des objets impliqués.
Dans le cas où votre SIEM effectue un calcul exclusivement automatique de l'importance des incidents, il est utile de déterminer sur la base de quoi et par quelle formule il est calculé. Par exemple, si l'importance est calculée sur la base de l'importance des actifs impliqués dans l'incident, vous devez prendre au sérieux les problèmes de gestion d'actifs dans une entreprise à l'avance.
Si vous définissez manuellement l'importance d'un incident, il est recommandé de développer une formule de calcul qui tienne compte au moins des éléments suivants:
- L'importance de la portée dans laquelle la règle fonctionne. Par exemple, un incident dans la zone critique des systèmes de la mission peut être plus critique que si le même incident exact s'est produit dans la zone des systèmes critiques de l'entreprise.
- L'importance des actifs et des comptes d'utilisateurs impliqués dans l'incident.
- La récurrence de cet incident dans l'entreprise.
De même, comme dans la dénomination des incidents, il est important que toutes les parties intéressées comprennent clairement et également les règles selon lesquelles l'importance d'un incident se forme.
Conclusions
En résumant les résultats de notre série d'articles, je note qu'il est possible, à mon avis, de créer des règles de corrélation qui fonctionnent hors de la boîte. La solution peut être une fusion d'approches organisationnelles et techniques. Le SIEM lui-même doit être capable de faire quelque chose, mais les spécialistes qui l'exploitent doivent le faire et le savoir.
Pour résumer:
- La méthode se compose des blocs suivants:
- Préparation des sources et des environnements.
- Normalisation des événements et leur enrichissement.
- Adaptation des règles de corrélation au contexte AS.
- Formation d'un accord sur les positifs.
- Chaque unité a des composantes organisationnelles et techniques.
- , SIEM, .
- , , SIEM-.
- . .
 , « »
, « », , . — . .
:SIEM: « ». 1: ?SIEM: « ». 2. «»SIEM: « ». Partie 3.1. SIEM: « ». 3.2.SIEM: « ». 4.SIEM: « ». 5. (
)