 Publié par Denis Tsyplakov , architecte de solutions, DataArt
Publié par Denis Tsyplakov , architecte de solutions, DataArtÉnoncé du problème
L'un des problèmes lors de la construction d'architectures de microservices et en particulier lors de la migration d'une architecture monolithique vers des microservices est souvent les transactions. Chaque microservice est responsable de son propre groupe de fonctions, contrôle éventuellement les données associées à ce groupe et peut répondre aux demandes des utilisateurs de manière autonome ou en envoyant des demandes à d'autres microservices. Tout cela fonctionne bien jusqu'à ce que nous devions garantir la cohérence des données contrôlées par différents microservices.
Par exemple, notre application fonctionne dans une grande boutique en ligne. Entre autres, nous avons trois secteurs d'activité distincts, faiblement interconnectés:
- Entrepôt - quoi, où, comment et pendant combien de temps il a été stocké, combien de marchandises d'un certain type sont actuellement en stock, etc.
- Envoi de marchandises - emballage, expédition, suivi de livraison, analyse des réclamations concernant son retard, etc.
- Maintenir des rapports douaniers sur la circulation des marchandises si les marchandises sont expédiées à l'étranger (en fait, je ne sais pas si dans ce cas il est nécessaire de rédiger quelque chose de spécial, mais je vais quand même connecter les services de l'État au processus pour ajouter du drame).
Chacun de ces trois domaines comprend de nombreuses fonctions disjointes et peut être représenté comme plusieurs microservices.
Il y a un problème. Supposons qu'une personne a acheté un produit, l'a emballé et l'a envoyé par courrier. Entre autres, nous devons indiquer qu'il y a une unité de marchandises en moins dans l'entrepôt, pour noter que le processus de livraison des marchandises a commencé, et si les marchandises sont envoyées, par exemple, en Chine, pour s'occuper des papiers pour les douanes. Si l'application se bloque (par exemple, un nœud se bloque) à la deuxième ou à la troisième étape du processus, nos données vont devenir incohérentes, et seuls quelques-uns de ces échecs peuvent entraîner des problèmes plutôt désagréables pour l'entreprise (par exemple, une visite d'agents des douanes).
Dans une architecture monolithique classique de ce type, le problème est résolu simplement et avec élégance par des transactions dans la base de données. Mais que faire si nous utilisons des microservices? Même si nous utilisons la même base de données de tous les services (ce qui n'est pas très élégant, mais dans notre cas c'est possible), travailler avec cette base de données provient de différents processus, et nous ne pourrons pas étirer la transaction entre les processus.
Des solutions
Le problème a plusieurs solutions:
- Curieusement, le problème peut parfois être ignoré. Si nous savons qu'un échec ne se produit pas plus d'une fois par mois et que l'élimination manuelle des conséquences coûte de l'argent acceptable pour l'entreprise, vous ne pouvez pas prêter attention au problème, même s'il peut sembler laid. Je ne sais pas s’il est possible d’ignorer les prétentions du service des douanes, mais on peut supposer que dans certaines circonstances, cela est possible.
- La compensation (il ne s'agit pas d'une compensation monétaire aux douanes, par exemple, vous avez payé une amende) est un groupe de différentes étapes qui compliquent la séquence de traitement, mais vous permettent de détecter et de traiter un processus ayant échoué. Par exemple, avant de commencer l'opération, nous écrivons à un service spécial que nous commençons l'opération d'expédition, et à la fin nous marquons que tout s'est bien terminé. Ensuite, nous vérifions périodiquement s'il y a des opérations en attente, et s'il y en a, en regardant les trois bases de données, nous essayons de mettre les données dans un état cohérent. Il s'agit d'une méthode complètement fonctionnelle, mais qui complique considérablement la logique de traitement, et le faire pour chaque opération est assez pénible.
- Les transactions en deux phases, à proprement parler, la spécification XA +, qui vous permet de créer des transactions distribuées par rapport aux applications, est un mécanisme très lourd que peu de gens aiment et, surtout, peu de gens peuvent configurer. De plus, avec des microservices légers, il est idéologiquement faiblement compatible.
- En principe, une transaction est un cas particulier du problème du consensus, et de nombreux systèmes de consensus distribués peuvent être utilisés pour résoudre le problème (en gros, tout ce qui est google avec les mots clés paxos, raft, zookeeper, etcd, consul). Mais dans l'application pratique de données étendues et ramifiées sur l'activité de l'entrepôt, tout cela semble encore plus compliqué que les transactions en deux phases.
- Files d'attente et cohérence éventuelle (cohérence à long terme) - nous divisons la tâche en trois tâches asynchrones, traitons séquentiellement les données, les transmettons entre les services de la file d'attente à la file d'attente et utilisons le mécanisme de confirmation de livraison. Dans ce cas, le code n'est pas très compliqué, mais il y a quelques points à garder à l'esprit:
- La file d'attente garantit la livraison "une ou plusieurs fois", c'est-à-dire que lors de la remise du même message, le service doit gérer correctement cette situation et ne pas expédier les marchandises deux fois. Cela peut être fait, par exemple, via l'UUID unique de la commande.
- Les données à un moment donné seront légèrement incohérentes. C'est-à-dire que les marchandises disparaîtront d'abord de l'entrepôt et seulement alors, avec un léger retard, une commande pour son expédition sera créée. Plus tard, les données douanières seront traitées. Dans notre exemple, cela est tout à fait normal et ne cause pas de problèmes pour l'entreprise, mais il y a des cas où un tel comportement de données peut être très désagréable.
- Si, par conséquent, le tout premier service doit renvoyer des données à l'utilisateur, la séquence d'appels qui délivre finalement les données au navigateur de l'utilisateur peut être assez simple. Le principal problème est que le navigateur envoie des demandes de manière synchrone et attend généralement une réponse synchrone. Si vous effectuez un traitement de demande asynchrone, vous devez créer une livraison asynchrone de la réponse au navigateur. Classiquement, cela se fait soit via des sockets Web, soit via des demandes périodiques de nouveaux événements du navigateur au serveur. Il existe des mécanismes, tels que SocksJS, par exemple, qui simplifient certains aspects de la création de ce lien, mais il y aura toujours une complexité supplémentaire.
Dans la plupart des cas, cette dernière option est la plus acceptable. Cela ne complique pas beaucoup la demande de traitement, bien qu'il fonctionne plusieurs fois plus longtemps, mais, en règle générale, cela est acceptable pour ce type d'opération. Cela nécessite également une organisation des données légèrement plus complexe pour couper les demandes répétées, mais il n'y a rien de super compliqué à ce sujet non plus.
Schématiquement, l'une des options de traitement des transactions à l'aide de files d'attente et de cohérence éventuelle peut ressembler à ceci:
- L'utilisateur a effectué un achat, un message à ce sujet est envoyé dans la file d'attente (par exemple, un cluster RabbitMQ ou, si nous travaillons dans Google Cloud Platform - Pub / Sub). La file d'attente est persistante, garantit la livraison une ou plusieurs fois et est transactionnelle, c'est-à-dire que si le service traitant le message tombe soudainement, le message ne sera pas perdu, mais sera remis à une nouvelle instance du service.
- Le message arrive au service, qui marque les marchandises dans l'entrepôt comme étant préparées pour l'expédition et envoie à son tour le message «Les marchandises sont prêtes pour l'expédition» à la file d'attente.
- À l'étape suivante, le service responsable de l'expédition reçoit un message de préparation à l'expédition, crée une tâche d'expédition, puis envoie un message «l'expédition des marchandises est planifiée».
- Le service suivant, après avoir reçu un message indiquant que l'expédition est prévue, lance le processus de paperasse pour les douanes.
De plus, chaque message reçu par le service est vérifié pour son caractère unique, et si un message avec un tel UUID a déjà été traité, il est ignoré.
Ici, la ou les bases de données à chaque instant sont dans un état légèrement incohérent, c'est-à-dire que les marchandises dans l'entrepôt sont déjà marquées comme étant en cours de livraison, mais la tâche de livraison elle-même n'est pas encore là, elle apparaîtra dans une seconde ou deux. Mais en même temps, nous avons 99,999% (en fait, ce nombre est égal au niveau de fiabilité du service de file d'attente) garantit que la tâche d'envoi apparaîtra. Pour la plupart des entreprises, cela est acceptable.
De quoi parle l'article alors?
Dans l'article, je veux parler d'une autre façon de résoudre le problème de transactionnalité dans les applications de microservices. Malgré le fait que les microservices fonctionnent mieux lorsque chaque service a sa propre base de données, pour les systèmes de petite et moyenne taille, toutes les données, en règle générale, s'intègrent facilement dans une base de données relationnelle moderne. Cela est vrai pour presque tous les systèmes d'entreprise internes. Autrement dit, nous n'avons souvent pas strictement besoin de partager des données entre différentes machines physiques. Nous pouvons stocker des données de différents microservices dans des groupes de tables non liés de la même base de données. Cela est particulièrement pratique si vous divisez une ancienne application monolithique en services et que vous avez déjà divisé le code, mais les données résident toujours dans la même base de données. Cependant, le problème du fractionnement des transactions persiste - la transaction est étroitement liée à la connexion réseau et, par conséquent, au processus qui a ouvert cette connexion, et nous avons des processus distincts. Comment être
Ci-dessus, j'ai décrit plusieurs façons courantes de résoudre le problème, mais je veux en outre proposer une autre façon pour un cas spécial, lorsque toutes les données sont dans la même base de données. Je
ne recommande pas d'essayer d'implémenter cette méthode
dans ce projet , mais c'est assez curieux pour moi
de la présenter dans l'article. Eh bien, tout d'un coup, cela sera utile dans certains cas particuliers.
Son essence est très simple. Une transaction est associée à une connexion réseau et la base de données ne sait pas vraiment qui se trouve à cette extrémité de la connexion réseau ouverte. Elle s'en fiche, l'essentiel est que les bonnes commandes soient envoyées au socket. Il est clair que généralement un socket appartient exclusivement à un processus côté client, mais je vois au moins trois façons de contourner ce problème.
1. Modifiez le code de la base de données
Au niveau du code de base de données pour les bases de données, dont nous pouvons changer le code, en créant notre propre assemblage de base de données, nous implémentons le mécanisme de transfert des transactions entre les connexions. Comment cela peut fonctionner du point de vue du client:
- Nous commençons la transaction, faisons quelques changements, il est temps de transférer la transaction au service suivant.
- Nous demandons à la base de données de nous donner l'UUID de la transaction et d'attendre N secondes. Si pendant ce temps une autre connexion avec cet UUID ne vient pas, annulez la transaction, si c'est le cas, transférez toutes les structures de données associées à la transaction vers la nouvelle connexion et continuez à travailler avec elle.
- Nous transmettons l'UUID au service suivant (c'est-à-dire à un autre processus, éventuellement à une autre machine virtuelle).
- Dans ce document, ouvrez une connexion et exécutez la commande DB - poursuivez la transaction avec l'UUID spécifié.
- Nous continuons à travailler avec la base de données dans le cadre d'une transaction lancée par un autre processus.
Cette méthode est la plus légère à utiliser, mais nécessite une modification du code de la base de données, les programmeurs d'application ne le font généralement pas, elle nécessite beaucoup de compétences spéciales. Très probablement, il sera nécessaire de transférer des données entre les processus de base de données et les bases de données, dont le code peut être modifié en toute sécurité en gros, un - PostgreSQL. De plus, cela ne fonctionnera que pour les serveurs non gérés, vous ne l’utiliserez pas dans RDS ou Cloud SQL.
Schématiquement, cela ressemble à ceci:

2. Manipulation des prises
La deuxième chose qui me vient à l'esprit est la manipulation subtile des connexions à la base de données par les sockets. Nous pouvons créer un «proxy de socket inversé», qui dirige les commandes provenant de plusieurs clients vers un port spécifique dans un flux de commandes vers la base de données.
En fait, cette application est très similaire à pgBouncer, seulement, en plus de ses fonctionnalités standard, elle effectue certaines manipulations avec le flux d'octets des clients et peut remplacer un client par un autre sur commande.
Je n'aime pas beaucoup cette méthode, pour sa mise en œuvre il faut nettoyer les paquets binaires circulant entre le serveur et les clients. Et cela nécessite encore beaucoup de programmation système. Je l'ai apporté uniquement pour être complet.
3. Passerelle JDBC
Nous pouvons créer un pilote JDBC de passerelle - nous prenons le pilote JDBC standard pour une base de données spécifique, que ce soit PostgreSQL. Nous encapsulons la classe et créons des interfaces HTTP pour toutes ses méthodes externes (pas HTTP, mais la différence est petite). Ensuite, nous créons un autre pilote JDBC - une façade, qui redirige tous les appels de méthode vers la passerelle JDBC. En fait, nous scions le pilote existant en deux moitiés et connectons ces moitiés sur le réseau. Nous obtenons le diagramme de composants suivant:
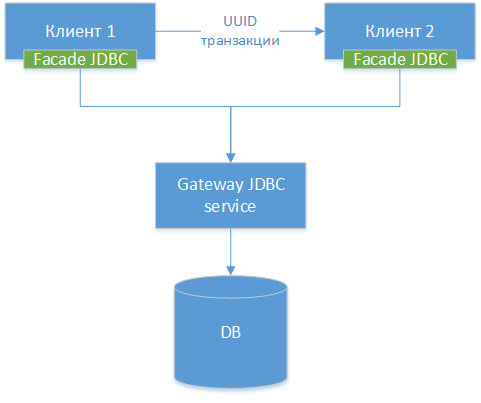 NB!: Comme nous pouvons le voir, les trois options sont similaires, la seule différence est à quel niveau nous transférons la connexion et quels outils nous utilisons pour cela.
NB!: Comme nous pouvons le voir, les trois options sont similaires, la seule différence est à quel niveau nous transférons la connexion et quels outils nous utilisons pour cela.
Après cela, nous apprenons à notre pilote à faire essentiellement la même astuce avec la transaction UUID décrite dans la méthode 1.
Dans le code d'application Java, l'utilisation de cette méthode peut ressembler à ceci.
Service A - début de la transaction
Vous trouverez ci-dessous le code d'un service qui démarre une transaction, apporte des modifications à la base de données et la transmet à un autre service pour la terminer. Dans le code, nous utilisons le travail direct avec les classes JDBC. Bien sûr, personne ne le fait en 2019, mais pour des raisons de simplicité, le code est simplifié.
Service B - finalisation de la transaction
Interaction avec d'autres composants et cadres
Considérez les effets secondaires possibles d'une telle solution architecturale.
Pool de connexions
Étant donné qu'en réalité, nous aurons un véritable pool de connexions à l'intérieur de la passerelle JDBC - il est préférable de désactiver les pools de connexions dans les services, car ils captureront et maintiendront une connexion à l'intérieur du service qui pourrait être utilisée par un autre service.
De plus, après avoir reçu l'UUID et attendu le transfert vers un autre processus, la connexion devient essentiellement inopérante, et du point de vue du frontend JDBC, elle se ferme automatiquement, et du point de vue de la passerelle JDBC, elle doit être maintenue sans donner à personne d'autre que qui viendra avec l'UUID souhaité.
En d'autres termes, la double gestion du pool de connexions dans la passerelle JDBC et au sein de chacun des services peut produire des erreurs subtiles et désagréables.
Jpa
Avec JPA, je vois deux problèmes possibles:
- Gestion des transactions. Lors de la validation d'un JPA, le moteur peut penser qu'il a enregistré toutes les données, alors qu'il n'a pas été enregistré. Très probablement, la gestion manuelle des transactions et flush () avant de transférer la transaction devraient résoudre le problème.
- Le cache de deuxième niveau est susceptible de ne pas fonctionner correctement, mais dans les systèmes distribués, son utilisation est en tout cas limitée.
Transactions de printemps
Le mécanisme de gestion des transactions Spring, peut-être, ne peut pas être activé, et vous devrez les gérer manuellement. Je suis presque sûr qu'il peut être développé - par exemple, pour écrire une étendue personnalisée - mais pour dire avec certitude, nous devons étudier comment l'extension Spring Transactions y est organisée, mais je n'y ai pas encore cherché.
Avantages et inconvénients
Avantages
- Ne nécessite pratiquement pas de modification du code monolithique existant lors du sciage.
- Vous pouvez écrire des transactions interserveurs complexes sans pratiquement aucune complexité de code.
- Vous permet de faire une trace interservices de l'exécution des transactions.
- La solution est assez flexible, vous pouvez utiliser des transactions classiques où la distribution n'est pas requise et partager la transaction uniquement pour les opérations où une interaction interservices est requise.
- L'équipe de projet n'est pas tenue de maîtriser de force les nouvelles technologies. Les nouvelles technologies sont bien sûr bonnes, mais la tâche - il est impératif et urgent (jusqu'à hier!) D'enseigner à 20 développeurs le concept de construction de systèmes réactifs - peut être très simple. Cependant, rien ne garantit que les 20 personnes termineront la formation à temps.
Inconvénients
- Non évolutif et, en fait, non modulaire au niveau de la base de données, contrairement à une solution en file d'attente. Vous avez toujours une base de données dans laquelle toutes les requêtes et l'ensemble de la charge convergent. En ce sens, la solution est sans issue: si vous souhaitez par la suite augmenter la charge ou rendre la solution modulaire en fonction des données, vous devrez tout refaire.
- Vous devez être très prudent lors du transfert d'une transaction entre des processus, en particulier des processus écrits dans des frameworks. Les sessions ont leurs propres paramètres et, pour différents cadres, un changement soudain de connexion avec la base de données peut entraîner un fonctionnement incorrect. Voir, par exemple, les paramètres de session et les transactions pour PostgreSQL.
- Quand j'ai dit l'idée dans le chat de notre architecte local sur DataArt, la première chose que mes collègues m'ont demandé était de savoir si je buvais (non, je ne buvais pas!). Mais j'avoue que l'idée, disons, n'est pas la plus répandue, et si vous la mettez en œuvre dans votre projet, elle semblera très inhabituelle pour ses autres participants.
- Nécessite un pilote JDBC personnalisé. L'écrire prend du temps, vous devez le déboguer, y rechercher des erreurs, y compris celles causées par des erreurs de communication réseau, etc.
Avertissement
Je vous préviens encore une fois:
n'essayez pas de répéter cette astuce chez vous dans ce projet, à moins d'avoir une explication très claire de la raison pour laquelle vous en avez besoin et des preuves convaincantes qu'il n'y a pas d'autre moyen du tout.
Tout à partir du premier avril!