L'article est publié au nom de John Akhaltsev , Jiga
Aujourd'hui, Tinkoff.ru n'est pas seulement une banque, c'est une entreprise informatique. Il fournit non seulement des services bancaires, mais construit également un écosystème autour d'eux.
Chez Tinkoff.ru, nous concluons un partenariat avec divers services pour améliorer la qualité du service client et aider à devenir de meilleurs services. Par exemple, nous avons effectué des tests de charge et une analyse des performances de l'un de ces services qui ont aidé à trouver des goulots d'étranglement dans le système, notamment Transparent Huge Pages dans les configurations OS.
Si vous voulez savoir comment effectuer une analyse des performances du système et ce qui en est ressorti, alors bienvenue chez cat.
Description du problème
À l'heure actuelle, l'architecture de service est la suivante:
- Serveur Web Nginx pour gérer les connexions http
- Php-fpm pour le contrôle des processus php
- Redis pour la mise en cache
- PostgreSQL pour le stockage des données
- Solution de guichet unique
Le principal problème que nous avons trouvé lors de la prochaine vente sous forte charge était la forte utilisation du processeur, tandis que le temps du processeur en mode noyau (heure système) augmentait et était plus long que le temps en mode utilisateur (temps utilisateur).
- Temps utilisateur - le temps que le processeur consacre aux tâches de l'utilisateur. C'est la principale chose que vous payez lors de l'achat d'un processeur.
- Heure système - la quantité de temps que le système passe sur la pagination, la modification des contextes, le lancement de tâches planifiées et d'autres tâches système.
Détermination des caractéristiques principales du système
Pour commencer, nous avons collecté un circuit de charge avec des ressources proches de la productivité, et compilé un profil de charge correspondant à une charge normale sur une journée type.
Gatling version 3 a été choisi comme outil de décorticage, et le décorticage lui-même a été effectué à l'intérieur du réseau local via gitlab-runner. La localisation des agents et des cibles dans un réseau local est due à la réduction des coûts du réseau, nous nous concentrons donc sur la vérification de l'exécution du code lui-même, et non sur les performances de l'infrastructure sur laquelle le système est déployé.
Lors de la détermination des caractéristiques principales du système, un scénario avec une charge augmentant linéairement avec une configuration http convient:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
À ce stade, nous avons implémenté un script pour ouvrir la page principale et télécharger toutes les ressources

Les résultats de ce test ont montré une performance maximale de 1500 rps, une nouvelle augmentation de l'intensité de la charge a conduit à une dégradation du système associée à une augmentation du temps softirq.


Softirq est un mécanisme d'interruption retardée et est décrit dans le fichier kernel / softirq.s. Dans le même temps, ils martèlent la file d'attente d'instructions au processeur, les empêchant de faire des calculs utiles en mode utilisateur. Les gestionnaires d'interruptions peuvent également retarder le travail supplémentaire avec les paquets réseau dans les threads du système d'exploitation (heure système). Un bref aperçu du travail de la pile réseau et des optimisations peut être trouvé dans un article séparé .
La suspicion du problème principal n'a pas été confirmée, car il y avait un temps système beaucoup plus long sur la prod avec moins d'activité réseau.
Scripts utilisateur
L'étape suivante consistait à développer des scripts personnalisés et à ajouter quelque chose de plus que simplement ouvrir une page avec des images. Le profil comprend des opérations lourdes, qui impliquaient pleinement le code du site et la base de données, et non un serveur Web qui fournit des ressources statiques.
Le test à charge stable a été lancé à une intensité inférieure au maximum, une transition de redirection a été ajoutée à la configuration:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
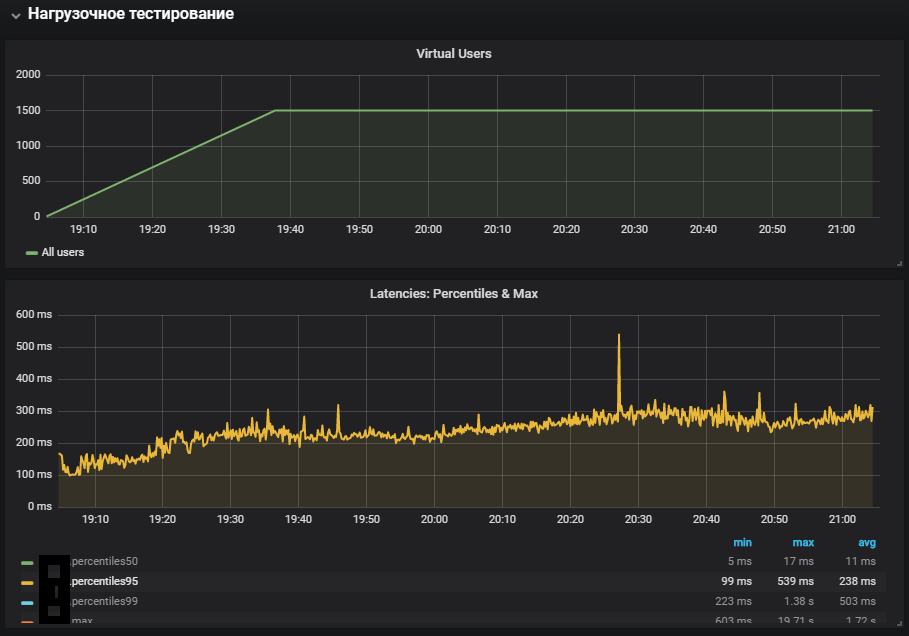

L'utilisation la plus complète des systèmes a montré une augmentation de la métrique de temps du système, ainsi que sa croissance pendant le test de stabilité. Le problème avec l'environnement de production a été reproduit.
Réseautage avec Redis
Lors de l'analyse des problèmes, il est très important de surveiller tous les composants du système afin de comprendre comment il fonctionne et quel impact la charge fournie a sur lui.
Avec l'avènement de la surveillance Redis, il est devenu possible de regarder non pas les métriques générales du système, mais ses composants spécifiques. Le scénario des tests de résistance a également été modifié, ce qui, associé à une surveillance supplémentaire, a aidé à aborder la localisation du problème.

Dans la surveillance, Redis a vu une image similaire avec l'utilisation du processeur, ou plutôt, le temps système est beaucoup plus long que le temps de l'utilisateur, tandis que l'utilisation principale du processeur était dans l'opération SET, c'est-à-dire l'allocation de RAM pour stocker la valeur.

Pour éliminer l'effet de l'interaction du réseau avec Redis, il a été décidé de tester l'hypothèse et de basculer Redis vers un socket UNIX au lieu d'un socket tcp. Cela a été fait directement dans le cadre par lequel php-fpm se connecte à la base de données. Dans le fichier /yiisoft/yii/framework/caching/CRedisCache.php, nous avons remplacé la ligne de host: port par le code dur redis.sock. En savoir plus sur les performances des sockets dans l'article .
protected function connect() { $this->_socket=@stream_socket_client(
Malheureusement, cela n'a pas eu beaucoup d'effet. L'utilisation du processeur s'est un peu stabilisée, mais n'a pas résolu notre problème - la majeure partie de l'utilisation du processeur était dans le calcul en mode noyau.
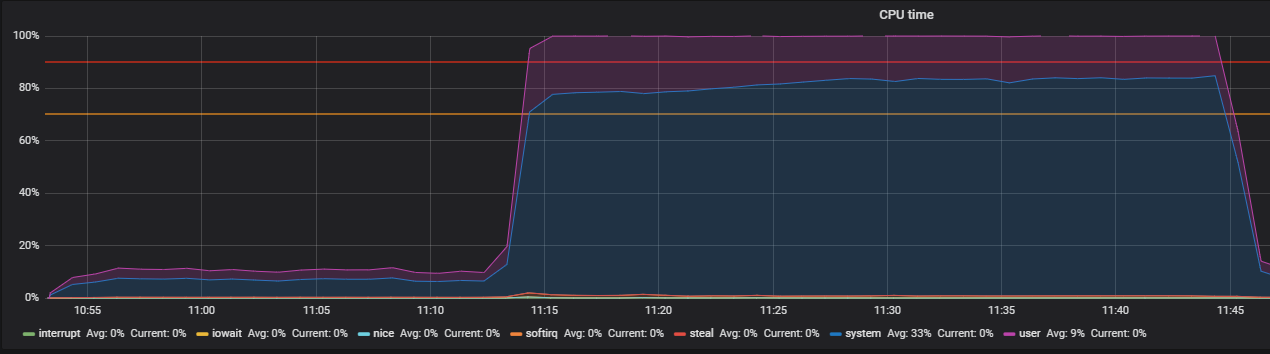
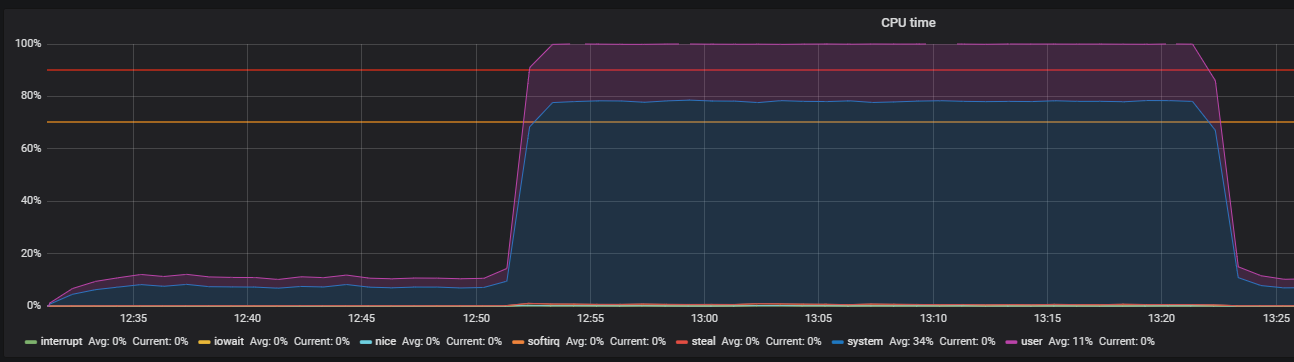
Benchmark en utilisant le stress et en identifiant les problèmes de THP
L'utilitaire de stress a aidé à localiser le problème - un générateur de charge de travail simple pour les systèmes POSIX, qui peut charger des composants système individuels, par exemple, CPU, mémoire, IO.
Les tests sont supposés sur la version matérielle et OS:
Ubuntu 18.04.1 LTS
12 CPU Intel® Xeon®
L'utilitaire est installé à l'aide de la commande:
sudo apt-get install stress
Nous examinons comment le CPU est utilisé sous charge, exécutons un test qui crée des travailleurs pour calculer les racines carrées avec une durée de 300 secondes:
-c, --cpu N spawn N workers spinning on sqrt() > stress --cpu 12 --timeout 300s stress: info: [39881] dispatching hogs: 12 cpu, 0 io, 0 vm, 0 hdd
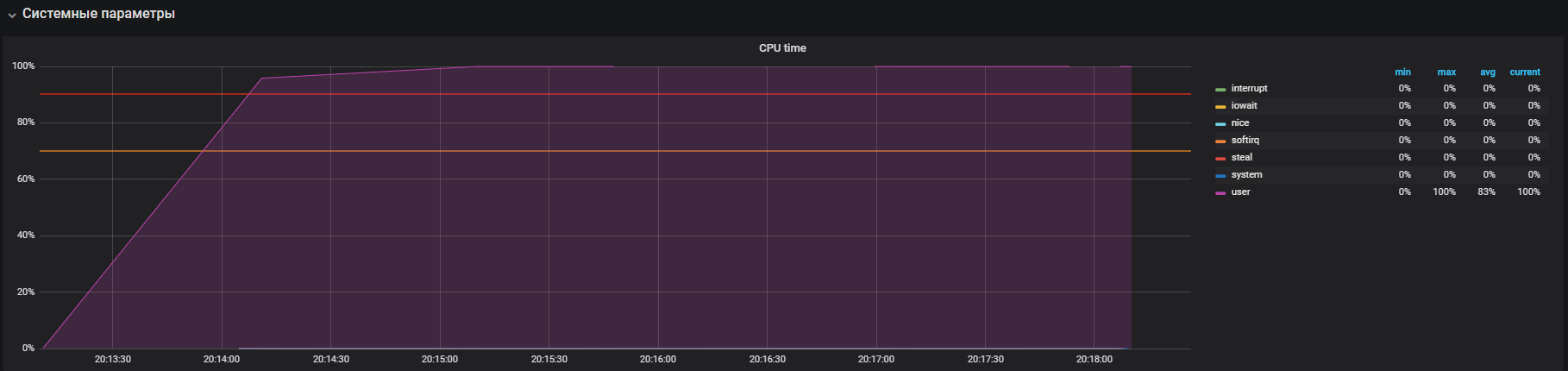
Le graphique montre l'utilisation complète en mode utilisateur - cela signifie que tous les cœurs de processeur sont chargés et que des calculs utiles sont effectués, pas des appels de service système.
L'étape suivante consiste à utiliser les ressources lorsque vous travaillez intensivement avec io. Exécutez le test pendant 300 secondes avec la création de 12 travailleurs qui exécutent sync (). La commande de synchronisation écrit les données mises en mémoire tampon sur le disque. Le noyau stocke les données en mémoire pour éviter les opérations de lecture et d'écriture fréquentes (généralement lentes) sur le disque. La commande sync () garantit que tout ce qui est stocké en mémoire est écrit sur le disque.
-i, --io N spawn N workers spinning on sync() > stress --io 12 --timeout 300s stress: info: [39907] dispatching hogs: 0 cpu, 0 io, 0 vm, 12 hdd

Nous voyons que le processeur est principalement engagé dans le traitement des appels en mode noyau et un peu en iowait, vous pouvez également voir> 35k ops écrit sur le disque. Ce comportement est similaire à un problème de temps système élevé, dont nous analysons les causes. Mais ici, il y a plusieurs différences: ce sont des iowait et les iops sont plus grands que sur le circuit productif, respectivement, cela ne correspond pas à notre cas.
Il est temps de vérifier votre mémoire. Nous lançons 20 travailleurs qui alloueront et libéreront de la mémoire pendant 300 secondes à l'aide de la commande:
-m, --vm N spawn N workers spinning on malloc()/free() > stress -m 20 --timeout 300s stress: info: [39954] dispatching hogs: 0 cpu, 0 io, 20 vm, 0 hdd
On voit immédiatement la forte utilisation du CPU en mode système et un peu en mode utilisateur, ainsi que l'utilisation de RAM de plus de 2 Go.
Ce cas est très similaire au problème avec le prod, ce qui est confirmé par l'utilisation importante de la mémoire lors des tests de charge. Par conséquent, le problème doit être recherché dans l'opération de mémoire. L'allocation et la libération de mémoire se produisent respectivement à l'aide de malloc et d'appels gratuits, qui seront éventuellement traités par les appels système du noyau, ce qui signifie qu'ils seront affichés dans l'utilisation du processeur comme heure système.
Dans la plupart des systèmes d'exploitation modernes, la mémoire virtuelle est organisée à l'aide de la pagination, avec cette approche, toute la zone de mémoire est divisée en pages d'une longueur fixe, par exemple 4096 octets (par défaut pour de nombreuses plates-formes), et lors de l'allocation, par exemple, de 2 Go de mémoire, le gestionnaire de mémoire devra fonctionner plus de 500 000 pages. Dans cette approche, il existe de gros frais généraux de gestion et les technologies Huge Pages et Transparent Huge Pages ont été inventées pour les réduire, avec leur aide, vous pouvez augmenter la taille de la page, par exemple, à 2 Mo, ce qui réduira considérablement le nombre de pages dans le tas de mémoire. La différence technologique réside uniquement dans le fait que pour les pages Huge, nous devons explicitement configurer l'environnement et enseigner au programme comment les utiliser, tandis que Transparent Huge Pages fonctionne «de manière transparente» pour les programmes.
THP et résolution de problèmes
Si vous recherchez des informations Google sur les pages immenses transparentes, vous pouvez voir dans les résultats de recherche un grand nombre de pages avec les questions "Comment désactiver THP".
Il s'est avéré que cette fonctionnalité «cool» a été introduite par la société Red Hat dans le noyau Linux, l'essence de la fonctionnalité est que les applications peuvent fonctionner de manière transparente avec la mémoire, comme si elles fonctionnaient avec une vraie page énorme. Selon les benchmarks, THP accélère l'application abstraite de 10%, vous pouvez voir plus de détails dans la présentation, mais en réalité tout est différent. Dans certains cas, le THP entraîne une augmentation déraisonnable de la consommation du processeur dans les systèmes. Pour plus d'informations, voir les recommandations d'Oracle.
Nous allons vérifier notre paramètre. Comme il s'est avéré, THP est activé par défaut, nous le désactivons avec la commande:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
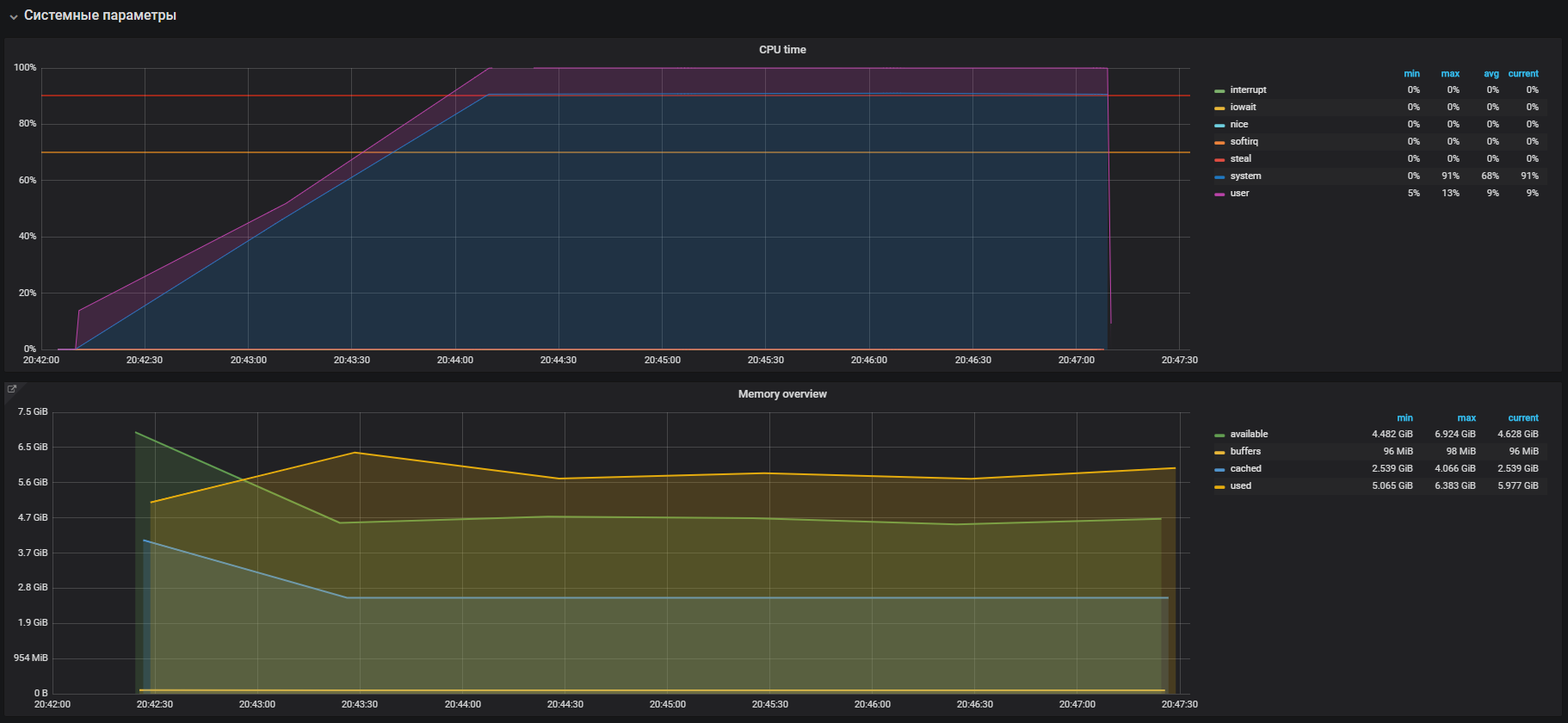
Nous confirmons avec le test avant de désactiver THP et après, sur le profil de charge:
setUp( MainScenario.inject( rampUsers(150) during (200 seconds)), Peak.inject( nothingFor(20 minutes), rampUsers(5000) during (30 minutes)) ).protocols(httpConfig)

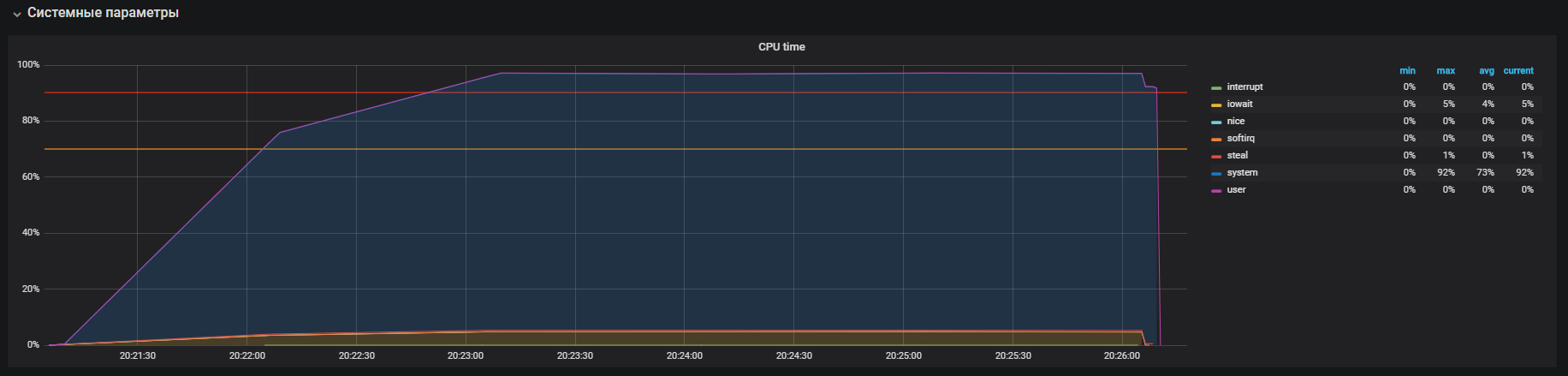
Nous avons regardé cette image avant d'éteindre THP

Après avoir désactivé THP, nous pouvons observer une utilisation déjà réduite des ressources.
Le problème principal a été localisé. La raison a été activée par défaut dans le système d'exploitation
mécanisme de grandes pages transparentes. Après avoir désactivé l'option THP, l'utilisation du processeur en mode système a diminué d'au moins 2 fois, ce qui a libéré des ressources pour le mode utilisateur. Lors de l'analyse du problème principal, des «goulots d'étranglement» d'interaction avec la pile réseau de l'OS et de Redis ont également été découverts, ce qui justifie une étude plus approfondie. Mais c'est une histoire complètement différente.
Conclusion
En conclusion, je voudrais donner quelques conseils pour réussir la recherche de problèmes de performances:
- Avant de rechercher les performances d'un système, comprenez soigneusement son architecture et les interactions des composants.
- Configurez la surveillance de tous les composants du système et effectuez le suivi. S'il n'y a pas suffisamment de mesures standard, approfondissez et développez.
- Lisez les manuels sur les systèmes utilisés.
- Vérifiez les paramètres par défaut dans les fichiers de configuration du système d'exploitation et des composants système.