Annonce
Chers collègues, au milieu de l'été, je prévois de publier une autre série d'articles sur la conception de systèmes de files d'attente: «VTrade Experiment» - une tentative d'écrire un cadre pour les systèmes de trading. Le cycle analysera la théorie et la pratique de la construction d'un échange, d'une vente aux enchères et d'un magasin. À la fin de l'article, je vous propose de voter pour les sujets qui vous intéressent le plus.

Ceci est le dernier article du cycle d'application réactive distribuée d'Erlang / Elixir. Dans le premier article, vous trouverez les fondements théoriques de l'architecture réactive. Le deuxième article illustre les modèles et mécanismes de base pour la construction de tels systèmes.
Aujourd'hui, nous aborderons les questions du développement de la base de code et des projets en général.
Organisation de service
Dans la vie réelle, lors du développement d'un service, vous devez souvent combiner plusieurs modèles d'interaction dans un seul contrôleur. Par exemple, le service utilisateurs, qui résout les tâches de gestion des profils utilisateur pour un projet, doit répondre aux demandes de demande et signaler les mises à jour de profil via pub-sub. Ce cas est assez simple: derrière la messagerie, il y a un contrôleur qui implémente la logique du service et publie des mises à jour.
La situation est compliquée lorsque nous devons implémenter un service distribué tolérant aux pannes. Supposons que les exigences des utilisateurs aient changé:
- maintenant le service doit traiter les requêtes sur 5 nœuds du cluster,
- être en mesure d'effectuer des tâches de traitement en arrière-plan,
- et être en mesure de gérer dynamiquement vos listes d'abonnement de mise à jour de profil.
Remarque: Nous ne considérons pas la question d'un stockage et d'une réplication cohérents des données. Supposons que ces problèmes ont été résolus plus tôt et que le système dispose déjà d'une couche de stockage fiable et évolutive, et que les gestionnaires disposent de mécanismes pour interagir avec elle.
La description formelle du service aux utilisateurs est devenue plus compliquée. Du point de vue d'un programmeur, l'utilisation des modifications de messagerie est minime. Pour satisfaire la première exigence, nous devons ajuster l'équilibrage sur le point d'échange req-resp.
La nécessité de gérer des tâches d'arrière-plan se pose souvent. Chez les utilisateurs, cela peut être la vérification des documents utilisateur, le traitement du multimédia téléchargé ou la synchronisation des données avec les services sociaux. les réseaux. Ces tâches doivent être réparties d'une manière ou d'une autre au sein du cluster et contrôler la progression. Par conséquent, nous avons deux solutions: soit utiliser le modèle de distribution des tâches de l'article précédent, soit, s'il ne convient pas, écrire un planificateur de tâches personnalisé qui nous sera nécessaire pour gérer le pool de gestionnaires.
Le point 3 nécessite une extension du modèle pub-sub. Et pour la mise en œuvre, après avoir créé le point d'échange pub-sub, nous devons également lancer le contrôleur de ce point dans le cadre de notre service. Ainsi, nous semblons prendre la logique du traitement de l'abonnement et du désabonnement de la couche de messagerie dans l'implémentation des utilisateurs.
En conséquence, la décomposition de la tâche a montré que pour répondre aux exigences, nous devons exécuter 5 instances de service sur différents nœuds et créer une entité supplémentaire - le contrôleur pub-sub responsable de l'abonnement.
Pour exécuter 5 gestionnaires, vous n'avez pas besoin de modifier le code de service. La seule action supplémentaire consiste à mettre en place des règles d'équilibrage au point d'échange, dont nous parlerons un peu plus loin.
Il y avait aussi une complexité supplémentaire: le contrôleur pub-sub et le planificateur de tâches personnalisé devraient fonctionner en une seule copie. Encore une fois, le service de messagerie, comme élément fondamental, devrait fournir un mécanisme de sélection d'un leader.
Choix du leader
Dans les systèmes distribués, le choix d'un leader est le processus de nomination du seul processus responsable de la planification du traitement distribué d'une charge.
Dans les systèmes qui ne sont pas sujets à la centralisation, des algorithmes de consensus universels, tels que les paxos ou les radeaux, sont utilisés.
Étant donné que la messagerie est un courtier et un élément central, il connaît tous les contrôleurs de services - candidats à la direction. La messagerie peut désigner un leader sans vote.
Après le démarrage et la connexion au point d'échange, tous les services reçoivent le message système #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers} . Si LeaderPid correspond au pid processus en cours, il est affecté en tant que leader et la liste des Servers inclut tous les nœuds et leurs paramètres.
Lorsqu'un nouveau nœud de cluster apparaît et se déconnecte, tous les contrôleurs de service reçoivent #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} et #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} respectivement.
Ainsi, tous les composants sont conscients de tous les changements et, à tout moment, dans le cluster, un leader est garanti.
Intermédiaires
Pour la mise en œuvre de processus complexes de traitement distribué, ainsi que pour l'optimisation d'une architecture existante, il est commode d'utiliser des intermédiaires.
Afin de ne pas modifier le code des services et de résoudre, par exemple, les tâches de traitement supplémentaire, de routage ou de journalisation des messages, vous pouvez activer un processeur proxy avant le service, qui effectuera tout le travail supplémentaire.
Un exemple classique d'optimisation pub-sub est une application distribuée avec un cœur de métier qui génère des événements de mise à jour, par exemple, un changement du prix du marché, et une couche d'accès - N serveurs qui fournissent des API Websocket pour les clients Web.
Si vous décidez de «front», le service client est le suivant:
- le client établit des connexions avec la plateforme. Côté serveur, mettant fin au trafic, le processus desservant cette connexion démarre.
- Dans le cadre du processus de service, l'autorisation et l'abonnement aux mises à jour ont lieu. Le processus appelle la méthode d'abonnement pour les rubriques.
- une fois que l'événement est généré dans le noyau, il est transmis aux processus desservant les connexions.
Imaginez que nous avons 50 000 abonnés au sujet «actualités». Les abonnés sont répartis uniformément sur 5 serveurs. En conséquence, chaque mise à jour, arrivant au point d'échange, sera répliquée 50 000 fois: 10 000 fois sur chaque serveur, en fonction du nombre d'abonnés. Pas tout à fait un schéma efficace, n'est-ce pas?
Pour améliorer la situation, nous introduisons un proxy portant le même nom avec le point d'échange. Le registraire de nom global devrait être en mesure de renvoyer le processus le plus proche par son nom, c'est important.
Exécutez ce proxy sur les serveurs de la couche d'accès, et tous nos processus desservant l'API Websocket y souscriront, et non au point d'échange pub-sub d'origine dans le noyau. Le proxy s'abonne au noyau uniquement dans le cas d'un abonnement unique et réplique le message entrant à tous ses abonnés.
En conséquence, 5 messages seront envoyés entre le noyau et les serveurs d'accès, au lieu de 50 000.
Routage et équilibrage
Req-resp
Dans l'implémentation de messagerie actuelle, il existe 7 stratégies de distribution de requêtes:
default . La demande est transmise à tous les contrôleurs.round-robin . Itère et distribue cycliquement les requêtes entre les contrôleurs.consensus . Les contrôleurs servant le service sont divisés en chefs et partisans. Les demandes ne sont transmises qu'au chef de file.consensus & round-robin . Il y a un leader dans le groupe, mais les demandes sont réparties entre tous les membres.sticky . La fonction de hachage est calculée et affectée à un gestionnaire spécifique. Les demandes suivantes avec cette signature sont envoyées au même gestionnaire.sticky-fun . Lorsque le point d'échange est initialisé, la fonction de calcul de hachage pour l'équilibrage sticky est en outre transférée.fun . Il est similaire à sticky-fun, seulement en plus vous pouvez le rediriger, le rejeter ou le prétraiter.
La stratégie de distribution est définie lors de l'initialisation du point d'échange.
En plus d'équilibrer la messagerie, vous pouvez baliser les entités. Tenez compte des types de balises dans le système:
- Balise de connexion. Vous permet de comprendre par quelle connexion les événements sont arrivés. Utilisé lorsque le processus du contrôleur se connecte au même point d'échange, mais avec des clés de routage différentes.
- Étiquette de service. Permet un service unique pour regrouper les processeurs et étendre les capacités de routage et d'équilibrage. Pour le modèle req-resp, le routage est linéaire. Nous envoyons une demande au point d'échange, puis elle la transmet au service. Mais si nous devons diviser les gestionnaires en groupes logiques, le fractionnement est effectué à l'aide de balises. Lors de la spécification d'une balise, la demande sera dirigée vers un groupe spécifique de contrôleurs.
- Demande d'étiquette. Permet de distinguer les réponses. Puisque notre système est asynchrone, pour traiter les réponses de service, vous devez pouvoir spécifier un RequestTag lors de l'envoi d'une demande. De là, nous pouvons comprendre la réponse à laquelle la demande nous est parvenue.
Sous pub
Pour pub-sub, les choses sont un peu plus faciles. Nous avons un point d'échange pour lequel les messages sont publiés. Le point d'échange distribue des messages entre les abonnés qui s'abonnent aux clés de routage dont ils ont besoin (on peut dire que c'est un analogue à ceux-ci).
Évolutivité et résilience
L'évolutivité du système dans son ensemble dépend du degré d'évolutivité des couches et des composants du système:
- Les services sont mis à l'échelle en ajoutant des nœuds supplémentaires au cluster avec des gestionnaires pour ce service. Pendant le fonctionnement d'essai, vous pouvez choisir la politique d'équilibrage optimale.
- Le service de messagerie lui-même au sein d'un cluster unique est généralement mis à l'échelle en déplaçant des points d'échange spécialement chargés vers des nœuds de cluster individuels, ou en ajoutant des processus proxy à des zones spécialement chargées du cluster.
- L'évolutivité de l'ensemble du système en tant que caractéristique dépend de la flexibilité de l'architecture et de la possibilité de combiner des clusters individuels en une entité logique commune.
La simplicité et la rapidité de la mise à l'échelle déterminent souvent le succès d'un projet. La messagerie dans ses performances actuelles croît avec l'application. Même si nous manquons d'un cluster de 50-60 voitures, nous pouvons recourir à la fédération. Malheureusement, le sujet de la fédération dépasse le cadre de cet article.
Réservation
Dans l'analyse de l'équilibrage de charge, nous avons déjà discuté de la réservation des contrôleurs de service. Cependant, la messagerie doit également être réservée. En cas de panne d'un nœud ou d'une machine, la messagerie devrait récupérer automatiquement et dès que possible.
Dans mes projets, j'utilise des nœuds supplémentaires qui récupèrent la charge en cas de chute. Erlang dispose d'une implémentation standard en mode distribué pour les applications OTP. Le mode distribué, en fait, effectue la récupération en cas d'échec en lançant l'application bloquée sur un autre nœud précédemment lancé. Le processus est transparent, après un échec, l'application se déplace automatiquement vers le nœud de basculement. Vous pouvez en savoir plus sur cette fonctionnalité ici .
Performances
Essayons de comparer au moins approximativement les performances de rabbitmq et de notre messagerie personnalisée.
J'ai trouvé les résultats officiels du test rabbitmq de l'équipe openstack.
Dans la clause 6.14.1.2.1.2.2. Le document original présente le résultat de RPC CAST:
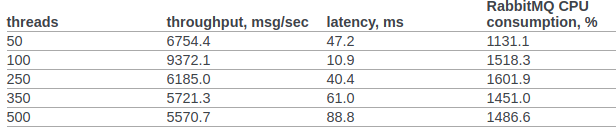
Auparavant, nous n'effectuions aucun réglage supplémentaire pour le noyau du système d'exploitation ou la machine virtuelle erlang. Conditions d'essai:
- erl opte: + A1 + sbtu.
- Le test au sein d'un seul nœud erlang s'exécute sur un ordinateur portable avec un ancien i7 en performances mobiles.
- Les tests de cluster ont lieu sur des serveurs avec un réseau 10G.
- Le code fonctionne dans les conteneurs Docker. Réseau en mode NAT.
Code de test:
req_resp_bench(_) -> W = perftest:comprehensive(10000, fun() -> messaging:request(?EXCHANGE, default, ping, self()), receive #'$msg'{message = pong} -> ok after 5000 -> throw(timeout) end end ), true = lists:any(fun(E) -> E >= 30000 end, W), ok.
Scénario 1: le test s'exécute sur un ordinateur portable avec une ancienne exécution mobile i7. Le test, la messagerie et le service sont exécutés sur un nœud dans un conteneur Docker:
Sequential 10000 cycles in ~0 seconds (26987 cycles/s) Sequential 20000 cycles in ~1 seconds (26915 cycles/s) Sequential 100000 cycles in ~4 seconds (26957 cycles/s) Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s) Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s) Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s) Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)
Scénario 2 : 3 nœuds exécutés sur différentes machines sous docker (NAT).
Sequential 10000 cycles in ~1 seconds (8684 cycles/s) Sequential 20000 cycles in ~2 seconds (8424 cycles/s) Sequential 100000 cycles in ~12 seconds (8655 cycles/s) Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s) Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s) Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s) Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)
Dans tous les cas, l'utilisation du processeur n'a pas dépassé 250%
Résumé
J'espère que ce cycle ne ressemble pas à un dépotoir de conscience et mon expérience apportera de réels avantages à la fois aux chercheurs de systèmes distribués et aux praticiens qui sont au tout début du chemin de la construction d'architectures distribuées pour leurs systèmes d'entreprise et qui regardent Erlang / Elixir avec intérêt, mais en doutant est-ce que ça vaut le coup ...
Photo de @chuttersnap