Certaines entreprises, dont notre client, développent le produit via un réseau d'affiliation. Par exemple, les grandes boutiques en ligne sont intégrées à un service de livraison - vous commandez des marchandises et recevez rapidement un numéro de suivi pour le colis. Autre exemple - avec un billet d'avion, vous achetez une assurance ou un billet Aeroexpress.
Pour cela, une API est utilisée, qui doit être émise aux partenaires via l'API Gateway. Nous avons résolu ce problème. Cet article fournira des détails.
Éléments fournis: écosystème et portail API avec une interface où les utilisateurs sont enregistrés, reçoivent des informations, etc. Nous devons créer une API de passerelle pratique et fiable. Dans le processus, nous devions fournir
- Inscription
- Contrôle de connexion API
- Surveillance de la façon dont les utilisateurs utilisent le système final
- comptabilité des indicateurs commerciaux.
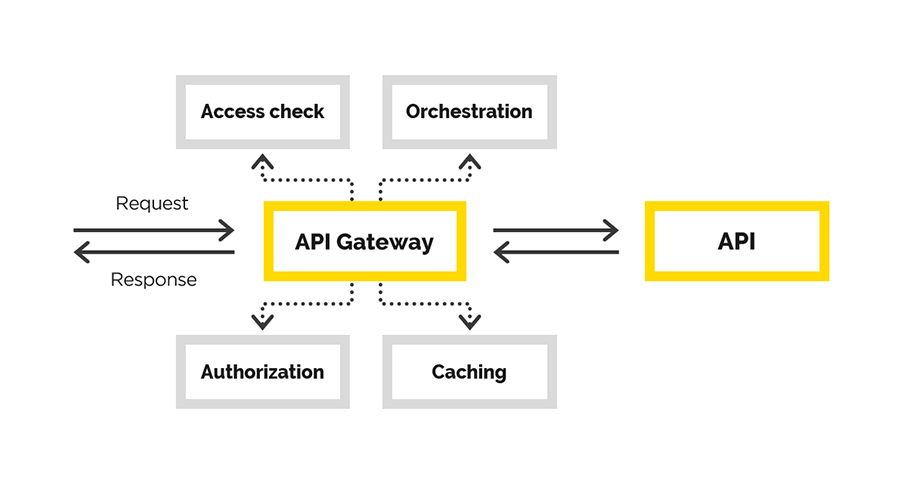
Dans l'article, nous parlerons de notre expérience dans la création de l'API Gateway, au cours de laquelle nous avons résolu les tâches suivantes:
- authentification des utilisateurs
- autorisation utilisateur
- modification de la demande d'origine,
- demander un mandataire
- post-traitement de la réponse.
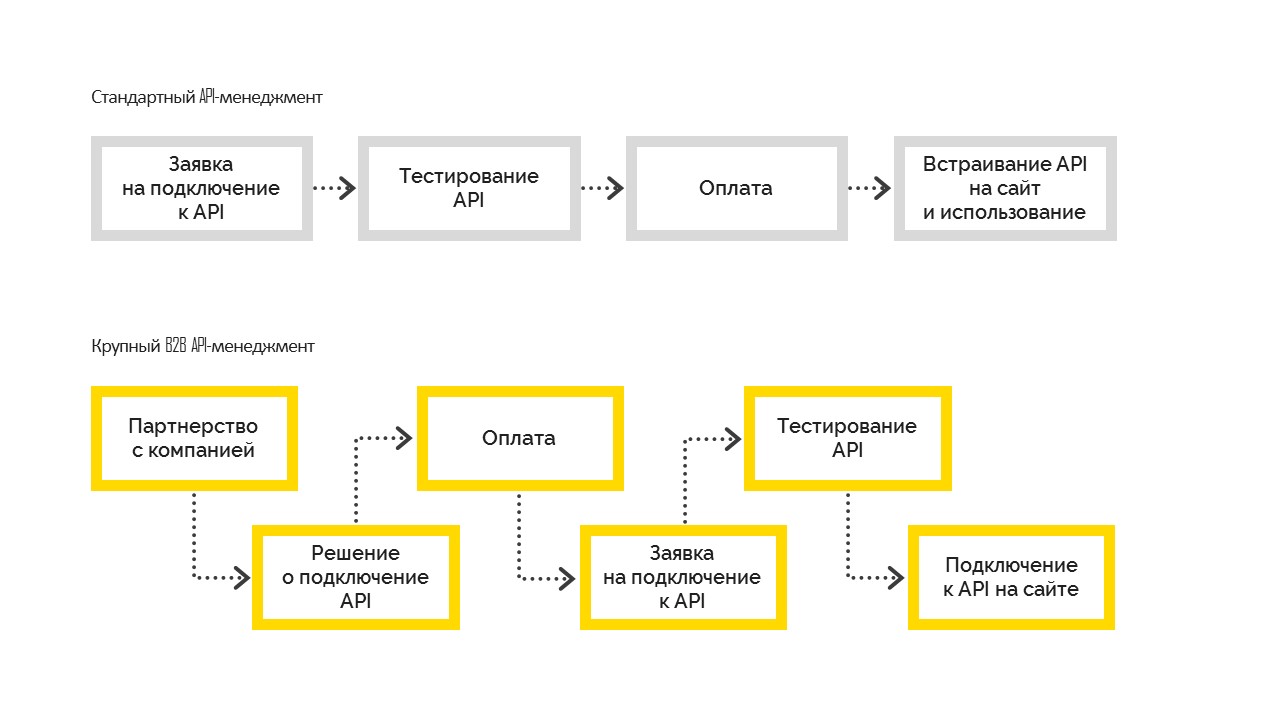
Il existe deux types de gestion des API:
1. Standard, qui fonctionne comme suit. Avant de se connecter, l'utilisateur teste les possibilités, puis paie et intègre sur son site. Le plus souvent, il est utilisé dans les petites et moyennes entreprises.
2. Une grande gestion d'API B2B, lorsque l'entreprise prend d'abord une décision commerciale concernant la connexion, devient une entreprise partenaire avec une obligation contractuelle, puis se connecte à l'API. Et après avoir réglé toutes les formalités, l'entreprise obtient un accès aux tests, passe les tests et entre dans les ventes. Mais cela n'est pas possible sans une décision de gestion de se connecter.
Notre décision
Dans cette partie, nous allons parler de la création de l'API Gateway.
Les utilisateurs finaux de la passerelle créée vers l'API sont les partenaires de nos clients. Pour chacun d'eux, nous avons déjà les contrats nécessaires. Nous aurons seulement besoin d'étendre la fonctionnalité, en notant l'accès accordé à la passerelle. En conséquence, un processus de connexion et de contrôle contrôlé est nécessaire.
Bien sûr, on pourrait prendre une solution prête à l'emploi pour résoudre la tâche de gestion des API et créer la passerelle API en particulier. Par exemple, il peut s'agir de la
gestion des API Azure . Cela ne nous convenait pas, car dans notre cas, nous avions déjà un portail API et un immense écosystème construit autour de lui. Tous les utilisateurs ont déjà été enregistrés, ils ont déjà compris où et comment obtenir les informations nécessaires. Les interfaces nécessaires existaient déjà dans le portail API, nous avions juste besoin de la passerelle API. En fait, nous avons commencé à le développer.
Ce que nous appelons l'API Gateway est une sorte de proxy. Ici encore, nous avions le choix - vous pouvez écrire votre proxy, ou vous pouvez choisir quelque chose de prêt à l'emploi. Dans ce cas, nous sommes allés dans la deuxième voie et avons choisi le bundle nginx + Lua. Pourquoi? Nous avions besoin d'un logiciel fiable et testé qui prend en charge la mise à l'échelle. Après l'implémentation, nous ne voulions pas vérifier l'exactitude de la logique métier et l'exactitude du proxy.
Tout serveur Web dispose d'un pipeline de traitement des demandes. Dans le cas de nginx, cela ressemble à ceci:

(diagramme de
GitHub Lua Nginx )
Notre objectif était de nous intégrer dans ce pipeline au moment où nous pouvons modifier la demande d'origine.
Nous voulons créer un proxy transparent afin que la demande reste fonctionnellement telle qu'elle est venue. Nous contrôlons uniquement l'accès à l'API finale, nous aidons la demande à y accéder. Dans le cas où la demande était incorrecte, l'API finale devrait afficher l'erreur, mais pas nous. La seule raison pour laquelle nous pouvons rejeter la demande est le manque d'accès au client.
Pour nginx, une
extension existe déjà sur
Lua . Lua est un langage de script, il est très léger et facile à apprendre. Ainsi, nous avons implémenté la logique nécessaire en utilisant Lua.
La configuration de nginx (analogie avec l'itinéraire de l'application), où tout le travail est effectué, est compréhensible. Il convient de noter ici la dernière directive - post_action.
location /middleware { more_clear_input_headers Accept-Encoding; lua_need_request_body on; rewrite_by_lua_file 'middleware/rewrite.lua'; access_by_lua_file 'middleware/access.lua'; proxy_pass https://someurl.com; body_filter_by_lua_file 'middleware/body_filter.lua'; post_action /process_session; }
Considérez ce qui se passe dans cette configuration:
more_clear_input_headers - efface la valeur des en-têtes spécifiés après la directive.
lua_need_request_body - contrôle s'il faut lire le corps source de la requête avant d'exécuter ou non les directives de réécriture / accès / accès_par_lua. Par défaut, nginx ne lit pas le corps de la demande client et si vous devez y accéder, cette directive doit être activée.
rewrite_by_lua_file - le chemin d'accès aux scripts, qui décrit la logique de modification de la demande
access_by_lua_file - le chemin d'accès au script, qui décrit la logique qui vérifie l'accès à la ressource.
proxy_pass - URL vers laquelle la demande sera envoyée par proxy.
body_filter_by_lua_file - le chemin d'accès au script, qui décrit la logique de filtrage de la demande avant de retourner au client.
Et enfin,
post_action est une directive officiellement non documentée qui peut être utilisée pour effectuer toute autre action après que la réponse a été donnée au client.
Ensuite, nous décrirons dans l'ordre comment nous avons résolu nos problèmes.
Autorisation / authentification et demande de modification
Se connecterNous avons construit l'autorisation et l'authentification à l'aide des accès par certificat. Il existe un certificat racine. Chaque nouveau client du client génère son certificat personnel avec lequel il peut accéder à l'API. Ce certificat est configuré dans la section du serveur de paramètres nginx.
ssl on; ssl_certificate /usr/local/openresty/nginx/ssl/cert.pem; ssl_certificate_key /usr/local/openresty/nginx/ssl/cert.pem; ssl_client_certificate /usr/local/openresty/nginx/ssl/ca.crt; ssl_verify_client on;
ModificationUne question légitime peut se poser: que faire d'un client certifié si nous voulons soudainement le déconnecter du système? Ne réémettez pas de certificats pour tous les autres clients.
Nous nous sommes donc approchés en douceur et avons abordé la tâche suivante - la modification de la demande d'origine. De manière générale, la demande initiale du client n'est pas valable pour le système final. L'une des tâches consiste à ajouter les pièces manquantes à la demande afin de la rendre valide. Le fait est que les données manquantes sont différentes pour chaque client. Nous savons que le client nous vient avec un certificat à partir duquel nous pouvons prendre une empreinte digitale et extraire les données client nécessaires de la base de données.
Si à un moment donné, vous devez déconnecter le client de notre service, ses données disparaîtront de la base de données et il ne pourra rien faire.
Travailler avec les données client
Nous devions garantir une haute disponibilité de la solution, en particulier la manière dont nous obtenons les données des clients. La difficulté est que la source de ces données est un service tiers qui ne garantit pas une vitesse ininterrompue et assez élevée.
Par conséquent, nous devions garantir une haute disponibilité des données clients. Comme outil, nous avons choisi
Hazelcast , qui nous fournit:
- accès rapide aux données
- la possibilité d'organiser un cluster de plusieurs nœuds avec des données répliquées sur différents nœuds.
Nous avons opté pour la stratégie de livraison de cache la plus simple:
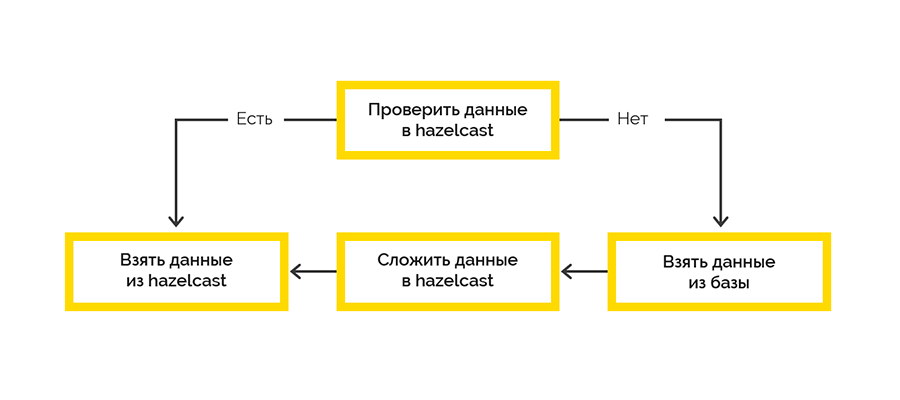
Le travail avec le système final se fait dans le cadre des sessions et il y a une limite sur le nombre maximum. Si le client n'a pas fermé la session, nous devrons le faire.
Les données de session ouvertes proviennent du système cible et sont initialement traitées du côté Lua. Nous avons décidé d'utiliser Hazelcast pour enregistrer ces données avec un écrivain .NET. Ensuite, à certains intervalles, nous vérifions le droit à la vie des séances ouvertes et fermons la faute.
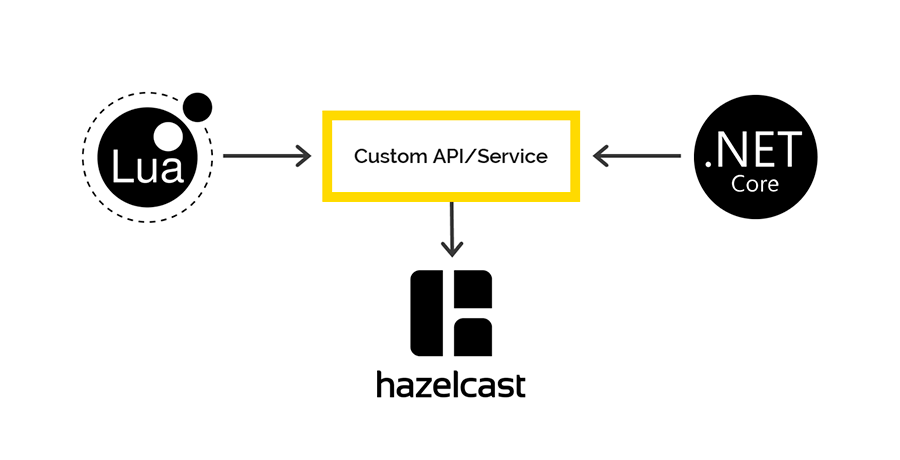
Accès à Hazelcast depuis Lua et .NET
Il n'y a pas de clients sur Lua pour travailler avec Hazelcast, mais Hazelcast a une API REST, que nous avons décidé d'utiliser. Pour .NET, il existe un
client via lequel nous avons prévu d'accéder aux données Hazelcast du côté .NET. Mais ça y était.

Lors de l'enregistrement des données via REST et de la récupération via le client .NET, différents sérialiseurs / désérialiseurs sont utilisés. Par conséquent, il est impossible de passer des données via REST, mais de passer par le client .NET et vice versa.
Si vous êtes intéressé, nous parlerons davantage de ce problème dans un article séparé. Spoiler - sur la shemka.
Journalisation et surveillance
Notre norme d'entreprise pour la connexion via .NET est Serilog, tous les journaux finissent dans Elasticsearch, et nous les analysons via Kibana. Je voulais faire quelque chose de similaire dans ce cas. Le seul
client à travailler avec Elastic sur Lua qui a été trouvé cassé au premier besoin. Et nous avons utilisé Fluentd.
Fluentd est une solution open source pour fournir une couche de journalisation d'application unique. Vous permet de collecter des journaux de différentes couches de l'application, puis de les traduire en une seule source.
L'API de passerelle fonctionne dans K8S, nous avons donc décidé d'ajouter le conteneur avec fluentd au même sous-type pour écrire les journaux sur le port tcp ouvert existant fluentd.
Nous avons également examiné le comportement de fluentd s'il n'avait aucun lien avec Elasticsearch. Pendant deux jours, les demandes ont été envoyées en continu à la passerelle, les journaux ont été envoyés à fluentd, mais IP Elastic a été banni de fluentd. Après la reconnexion, fluentd a parfaitement dépassé absolument tous les journaux d'Elastic.
Conclusion
L'approche choisie pour la mise en œuvre nous a permis de livrer un produit vraiment fonctionnel à l'environnement de combat en seulement 2,5 mois.
S'il vous arrive de faire de telles choses, nous vous conseillons d'abord de bien comprendre quel problème vous résolvez et quelles ressources vous avez déjà. Soyez conscient de la complexité de l'intégration avec les systèmes de gestion d'API existants.
Comprenez par vous-même ce que vous allez développer exactement - uniquement la logique métier du traitement des demandes ou, comme cela pourrait être le cas dans notre cas, l'ensemble du proxy. N'oubliez pas que tout ce que vous faites vous-même doit être soigneusement testé par la suite.