Bonjour mes amis. Fin avril, nous lançons un nouveau cours
«Sécurité des Systèmes d'Information» . Et maintenant, nous voulons partager avec vous une traduction de l'article, qui sera certainement très utile pour le cours. L'article original se
trouve ici .
L'article décrit les fondements clés, ils sont communs à tous les moteurs JavaScript, et pas seulement à la
V8 , sur laquelle les auteurs du moteur (
Benedict et
Matias ) travaillent. En tant que développeur JavaScript, je peux dire qu'une compréhension plus approfondie du fonctionnement du moteur JavaScript vous aidera à comprendre comment écrire du code efficace.

Remarque : si vous préférez regarder des présentations que lire des articles, regardez cette vidéo . Sinon, sautez-le et lisez la suite.
Moteur JavaScript de pipeline (pipeline)Tout commence par le fait que vous écrivez du code JavaScript. Après cela, le moteur JavaScript traite le code source et le présente comme un arbre de syntaxe abstraite (AST). Sur la base de l'AST construit, l'interpréteur peut enfin se mettre au travail et commencer à générer du bytecode. Super! C'est le moment où le moteur exécute le code JavaScript.

Pour le faire fonctionner plus rapidement, vous pouvez envoyer du bytecode au compilateur d'optimisation avec les données de profilage. Le compilateur d'optimisation émet certaines hypothèses sur la base des données de profilage, puis génère un code machine hautement optimisé.
Si à un moment donné les hypothèses s'avèrent incorrectes, le compilateur d'optimisation désoptimisera le code et retournera à l'étape de l'interpréteur.
Pipelines d'interprétation / compilateur dans les moteurs JavaScriptExaminons maintenant de plus près les parties du pipeline qui exécutent votre code JavaScript, à savoir où le code est interprété et optimisé, et examinons également quelques différences entre les principaux moteurs JavaScript.
Au cœur de tout se trouve un pipeline qui contient un interpréteur et un compilateur d'optimisation. L'interpréteur génère rapidement un bytecode non optimisé, le compilateur d'optimisation, à son tour, fonctionne plus longtemps, mais la sortie a un code machine hautement optimisé.
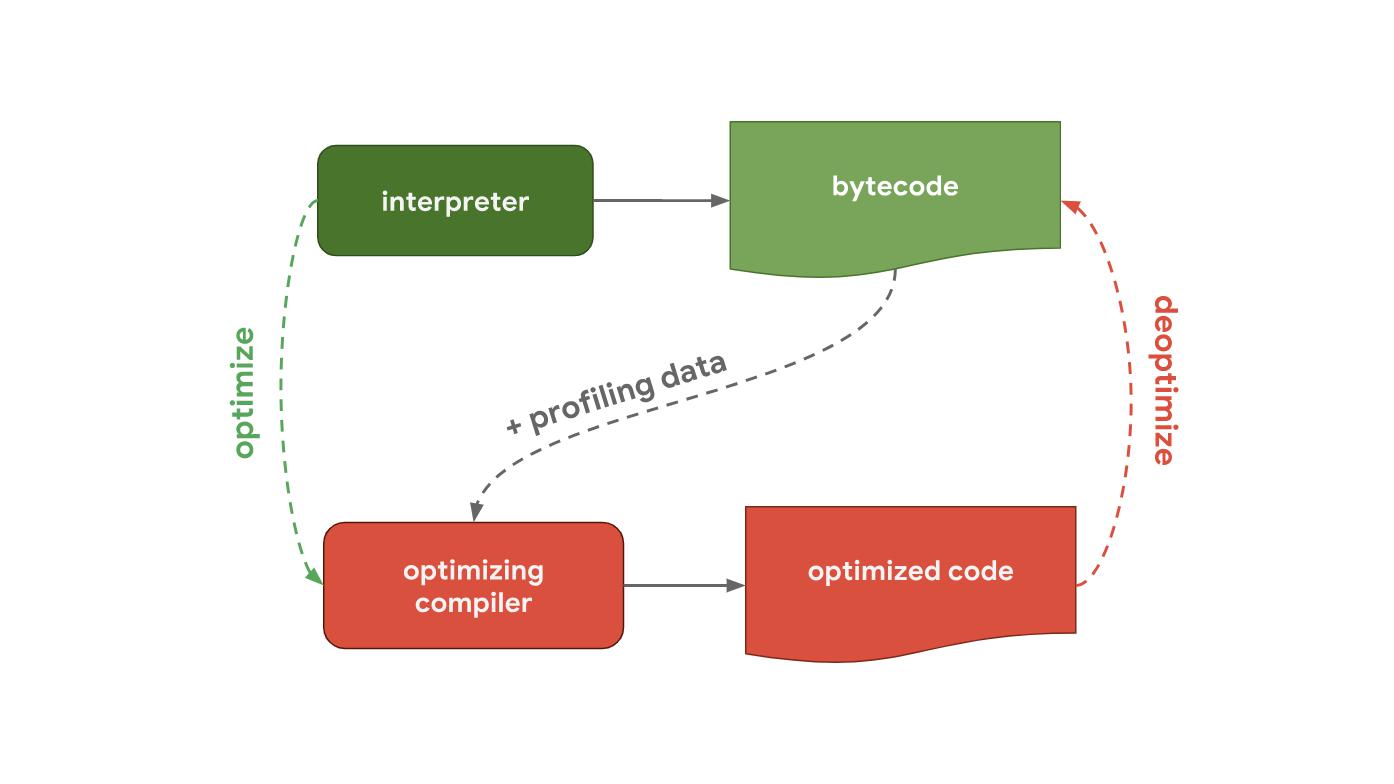
Ensuite, un pipeline qui montre comment fonctionne la V8, le moteur JavaScript utilisé par Chrome et Node.js.

L'interpréteur dans V8 est appelé Ignition, qui est responsable de la génération et de l'exécution du bytecode. Il collecte des données de profilage qui peuvent être utilisées pour accélérer l'exécution à l'étape suivante pendant le traitement du bytecode. Lorsqu'une fonction devient
chaude , par exemple, si elle démarre fréquemment, le bytecode généré et les données de profilage sont transférés vers le TurboFan, c'est-à-dire vers le compilateur d'optimisation pour générer un code machine hautement optimisé basé sur les données de profilage.

Par exemple, le moteur JavaScript SpiderMonkey de Mozilla, qui est utilisé dans Firefox et
SpiderNode , fonctionne un peu différemment. Il n'a pas un, mais deux compilateurs d'optimisation. L'interpréteur est optimisé en un compilateur de base (compilateur Baseline), qui produit du code optimisé. Avec les données de profilage collectées lors de l'exécution du code, le compilateur IonMonkey peut générer du code fortement optimisé. Si l'optimisation spéculative échoue, IonMonkey retourne au code de base.

Chakra - Le moteur JavaScript de Microsoft, utilisé dans Edge et
Node-ChakraCore , a une structure très similaire et utilise deux compilateurs d'optimisation. L'interpréteur est optimisé dans SimpleJIT (où JIT signifie «Just-In-Time compiler», qui produit un code quelque peu optimisé. Avec les données de profilage, FullJIT peut créer un code encore plus optimisé.
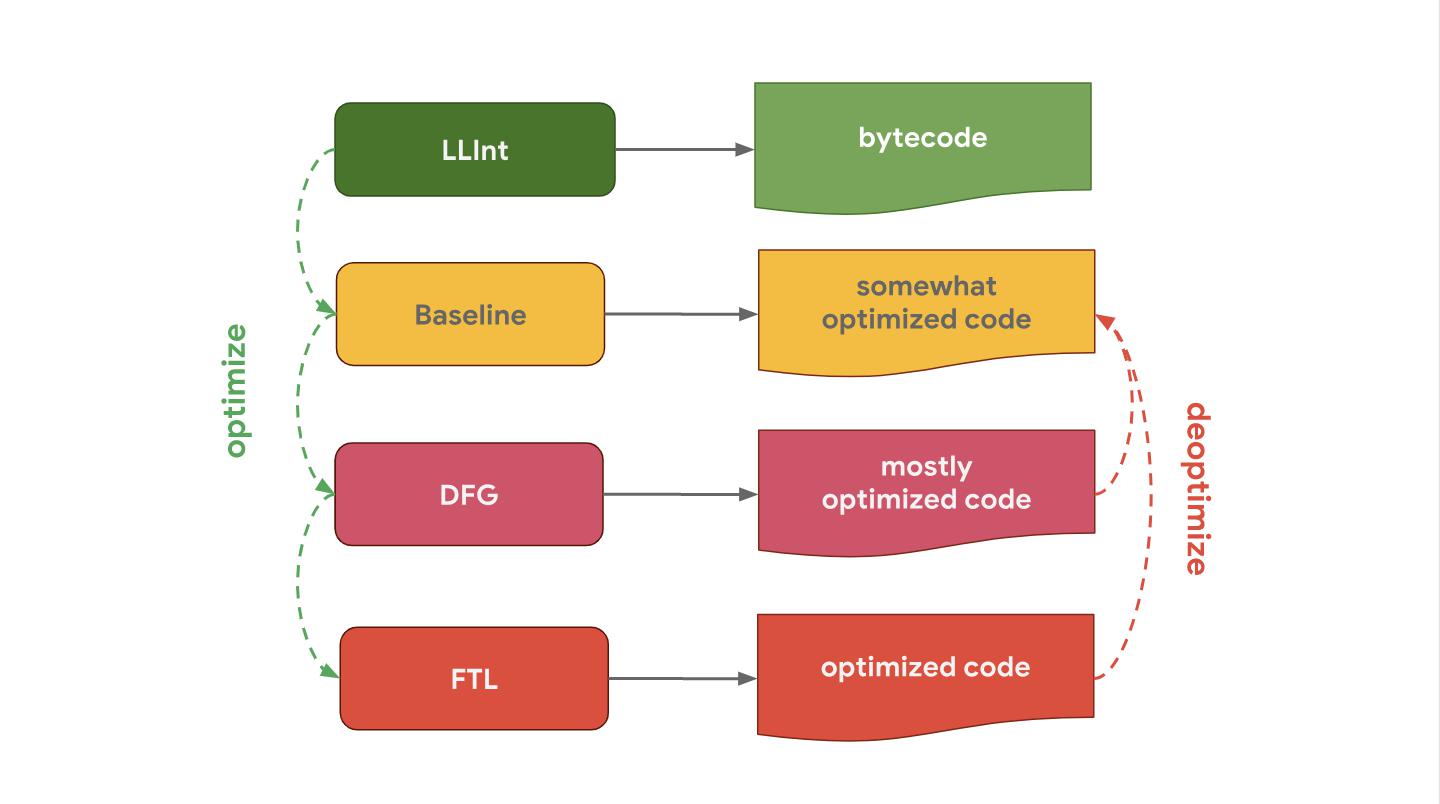
JavaScriptCore (en abrégé JSC), le moteur JavaScript d'Apple utilisé par Safari et React Native, a généralement trois compilateurs d'optimisation différents. LLInt est un interpréteur de bas niveau optimisé pour le compilateur de base, qui à son tour est optimisé pour le compilateur DFG (Data Flow Graph), et il est déjà optimisé pour le compilateur FTL (Faster Than Light).
Pourquoi certains moteurs ont-ils des compilateurs plus optimisants que d'autres? Il s'agit de compromis. L'interpréteur peut traiter rapidement le bytecode, mais le bytecode seul n'est pas particulièrement efficace. Le compilateur d'optimisation, en revanche, fonctionne un peu plus longtemps, mais produit un code machine plus efficace. C'est un compromis entre obtenir rapidement le code (interprète) ou attendre et exécuter le code avec des performances maximales (optimisation du compilateur). Certains moteurs choisissent d'ajouter plusieurs compilateurs d'optimisation avec différentes caractéristiques de temps et d'efficacité, ce qui vous permet de fournir le meilleur contrôle sur cette solution de compromis et de comprendre le coût des complications supplémentaires du périphérique interne. Un autre compromis est l'utilisation de la mémoire; consultez cet
article pour une meilleure compréhension.
Nous venons d'examiner les principales différences entre les pipelines de compilateur d'interpréteur et d'optimiseur pour divers moteurs JavaScript. Malgré ces différences de haut niveau, tous les moteurs JavaScript ont la même architecture: ils ont tous un analyseur et une sorte de pipeline interprète / compilateur.
Modèle d'objet JavaScriptVoyons ce que les autres moteurs JavaScript ont en commun et quelles astuces ils utilisent pour accélérer l'accès aux propriétés des objets JavaScript? Il s'avère que tous les moteurs principaux le font de manière similaire.
La spécification ECMAScript définit tous les objets comme des dictionnaires avec des clés de chaîne correspondant aux attributs de
propriété .

En plus de
[[Value]] -
[[Value]] , la spécification définit les propriétés suivantes:
[[Writable]] détermine si une propriété peut être réaffectée;[[Enumerable]] détermine si la propriété est affichée dans les boucles for-in;[[Configurable]] détermine si une propriété peut être supprimée.
La notation
[[ ]] semble étrange, mais c'est ainsi que la spécification décrit les propriétés en JavaScript. Vous pouvez toujours obtenir ces attributs de propriété pour tout objet et propriété donnés en JavaScript à l'aide de l'API
Object.getOwnPropertyDescriptor :
const object = { foo: 42 }; Object.getOwnPropertyDescriptor(object, 'foo');
Ok, donc JavaScript définit les objets. Et les tableaux?
Vous pouvez imaginer les tableaux comme des objets spéciaux. La seule différence est que les tableaux ont un traitement d'index spécial. Ici, un index de tableau est un terme spécial dans la spécification ECMAScript. JavaScript a des limites sur le nombre d'éléments dans un tableau - jusqu'à 2³² - 1. Un index de tableau est tout index disponible de cette plage, c'est-à-dire toute valeur entière de 0 à 2³² - 2.
Une autre différence est que les tableaux ont la propriété magique de la
length .
const array = ['a', 'b']; array.length;
Dans cet exemple, le tableau a une longueur de 2 au moment de la création. Ensuite, nous attribuons un autre élément à l'index 2 et la longueur augmente automatiquement.
JavaScript définit les tableaux ainsi que les objets. Par exemple, toutes les clés, y compris les indices de tableau, sont représentées explicitement sous forme de chaînes. Le premier élément du tableau est stocké sous la clé «0».

La propriété
length n'est qu'une autre propriété qui s'avère non énumérable et non configurable.
Dès qu'un élément est ajouté au tableau, JavaScript met automatiquement à jour l'attribut de la propriété
[[Value]] de la propriété
length .

En général, nous pouvons dire que les tableaux se comportent de manière similaire aux objets.
Optimisation de l'accès aux propriétésMaintenant que nous savons comment les objets sont définis en JavaScript, voyons comment les moteurs JavaScript vous permettent de travailler efficacement avec des objets.
Dans la vie de tous les jours, l'accès aux propriétés est l'opération la plus courante. Il est extrêmement important que le moteur le fasse rapidement.
const object = { foo: 'bar', baz: 'qux', };
FormulairesDans les programmes JavaScript, il est assez courant d'affecter les mêmes clés de propriété à de nombreux objets. Ils disent que ces objets ont la même
forme .
const object1 = { x: 1, y: 2 }; const object2 = { x: 3, y: 4 };
La mécanique commune est également l'accès à la propriété d'objets de la même forme:
function logX(object) { console.log(object.x);
Sachant cela, les moteurs JavaScript peuvent optimiser l'accès à la propriété d'un objet en fonction de sa forme. Voyez comment cela fonctionne.
Supposons que nous ayons un objet avec les propriétés x et y, il utilise la structure de données du dictionnaire, dont nous avons parlé plus tôt; il contient des chaînes de clés qui pointent vers leurs attributs respectifs.
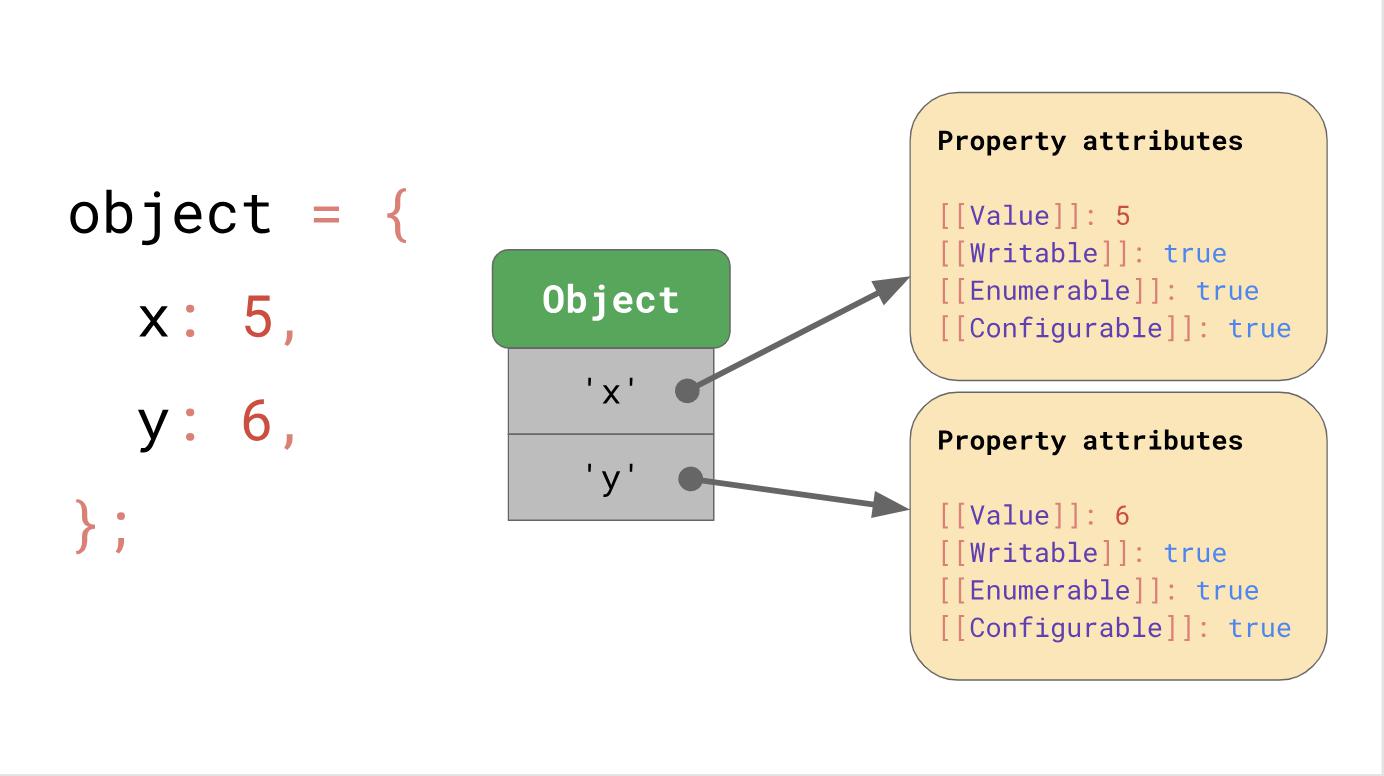
Si vous accédez à une propriété, telle que
object.y, le moteur JavaScript recherche un JSObject avec la clé
'y' , puis charge les attributs de propriété qui correspondent à cette requête et retourne finalement
[[Value]] .
Mais où ces attributs de propriété sont-ils stockés en mémoire? Faut-il les stocker dans le cadre d'un JSObject? Si nous le faisons, nous verrons plus d'objets de cette forme plus tard, auquel cas, c'est un gaspillage d'espace pour stocker un dictionnaire complet contenant les noms des propriétés et des attributs dans JSObject lui-même, car les noms de propriété sont répétés pour tous les objets de la même forme. Cela provoque beaucoup de duplication et conduit à une mauvaise allocation de la mémoire. Pour l'optimisation, les moteurs stockent la forme de l'objet séparément.

Cette
Shape contient tous les noms et attributs de propriété sauf
[[Value]] . Au lieu de cela, le formulaire contient les valeurs de décalage à l'intérieur du JSObject, de sorte que le moteur JavaScript sait où chercher les valeurs. Chaque JSObject avec un formulaire commun indique une instance spécifique du formulaire. Désormais, chaque JSObject ne doit stocker que des valeurs uniques à l'objet.
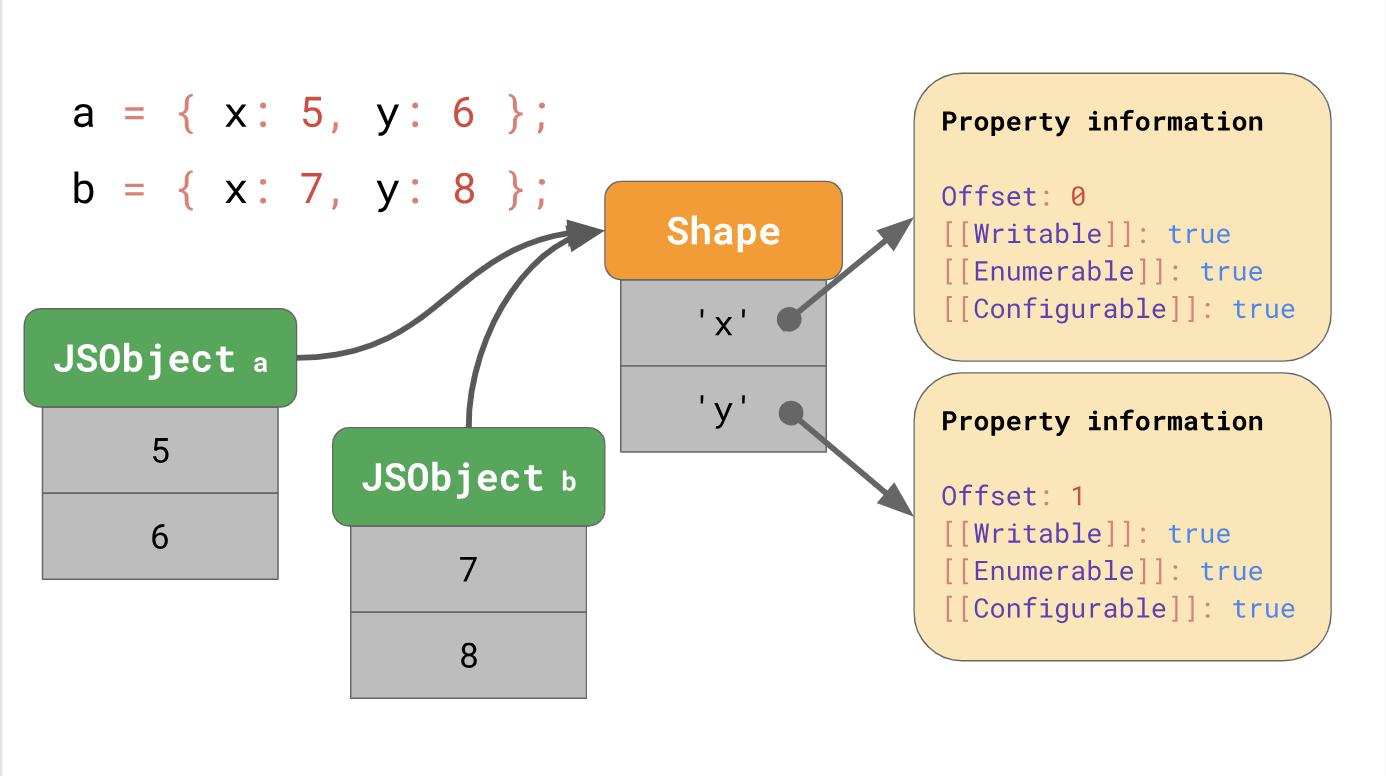
L'avantage devient évident dès que nous avons beaucoup d'objets. Leur nombre n'a pas d'importance, car s'ils ont un seul formulaire, nous n'enregistrons les informations sur le formulaire et la propriété qu'une seule fois.
Tous les moteurs JavaScript utilisent des formulaires comme moyen d'optimisation, mais ils ne les nomment pas directement en tant que
shapes :
- La documentation académique les appelle classes cachées (similaires aux classes JavaScript);
- V8 les appelle Maps;
- Chakra les appelle des types;
- JavaScriptCore les appelle Structures;
- SpiderMonkey les appelle des formes.
Dans cet article, nous continuons à les appeler des
shapes .
Chaînes de transition et arbresQue se passe-t-il si vous avez un objet d'une certaine forme, mais que vous lui ajoutez une nouvelle propriété? Comment le moteur JavaScript définit-il un nouveau formulaire?
const object = {}; object.x = 5; object.y = 6;
Les formulaires créent ce qu'on appelle des chaînes de transition dans le moteur JavaScript. Voici un exemple:
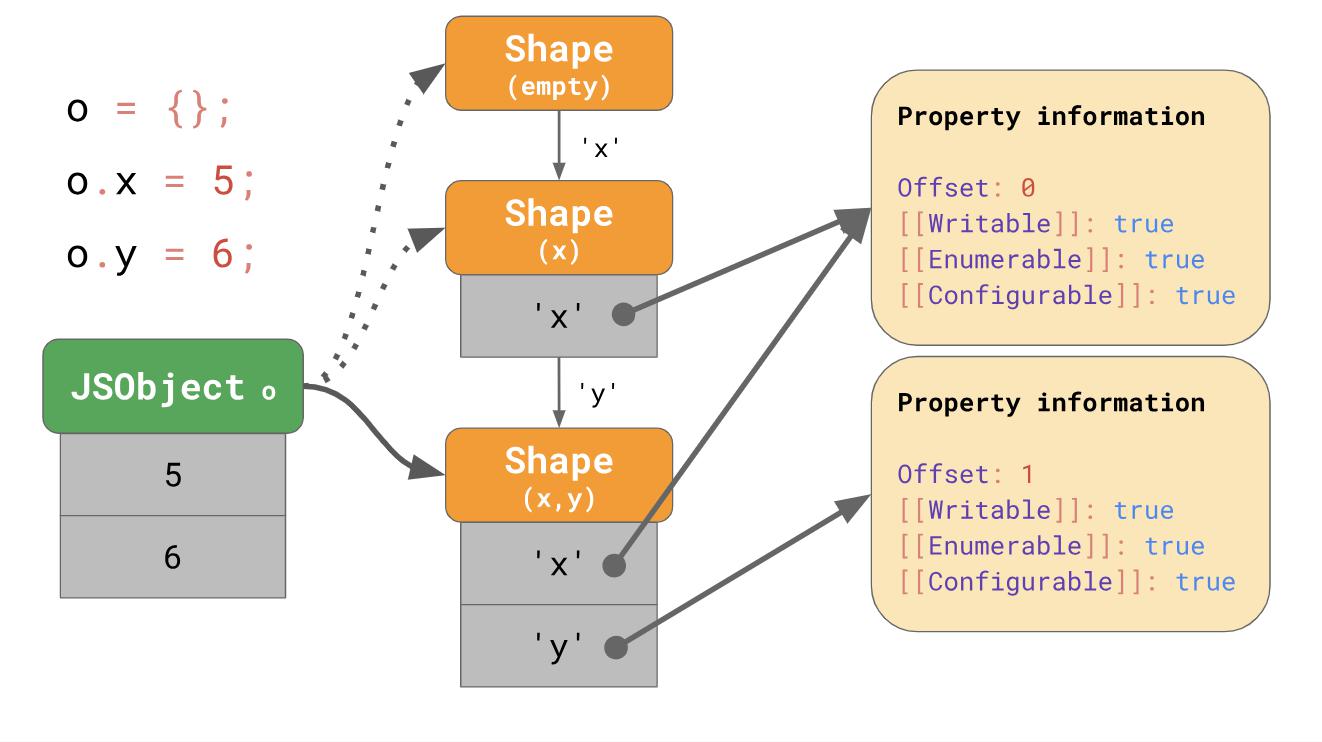
Un objet n'a initialement aucune propriété, il correspond à un formulaire vide. L'expression suivante ajoute la propriété
'x' avec une valeur de 5 à cet objet, puis le moteur passe au formulaire qui contient la propriété
'x' et la valeur 5 est ajoutée à JSObject au premier décalage 0. La ligne suivante ajoute la propriété
'y' , puis le moteur passe au suivant un formulaire qui contient déjà à la fois
'x' et
'y' , et ajoute également la valeur 6 à JSObject au décalage 1.
Remarque : La séquence dans laquelle les propriétés sont ajoutées affecte le formulaire. Par exemple, {x: 4, y: 5} donnera une forme différente de {y: 5, x: 4}.
Nous n'avons même pas besoin de stocker la table de propriétés entière pour chaque formulaire. Au lieu de cela, chaque formulaire a besoin de connaître uniquement une nouvelle propriété qu'ils essaient d'y inclure. Par exemple, dans ce cas, nous n'avons pas besoin de stocker des informations sur «x» sous cette dernière forme, car elles peuvent être trouvées plus tôt dans la chaîne. Pour que cela fonctionne, le formulaire fusionne avec son formulaire précédent.
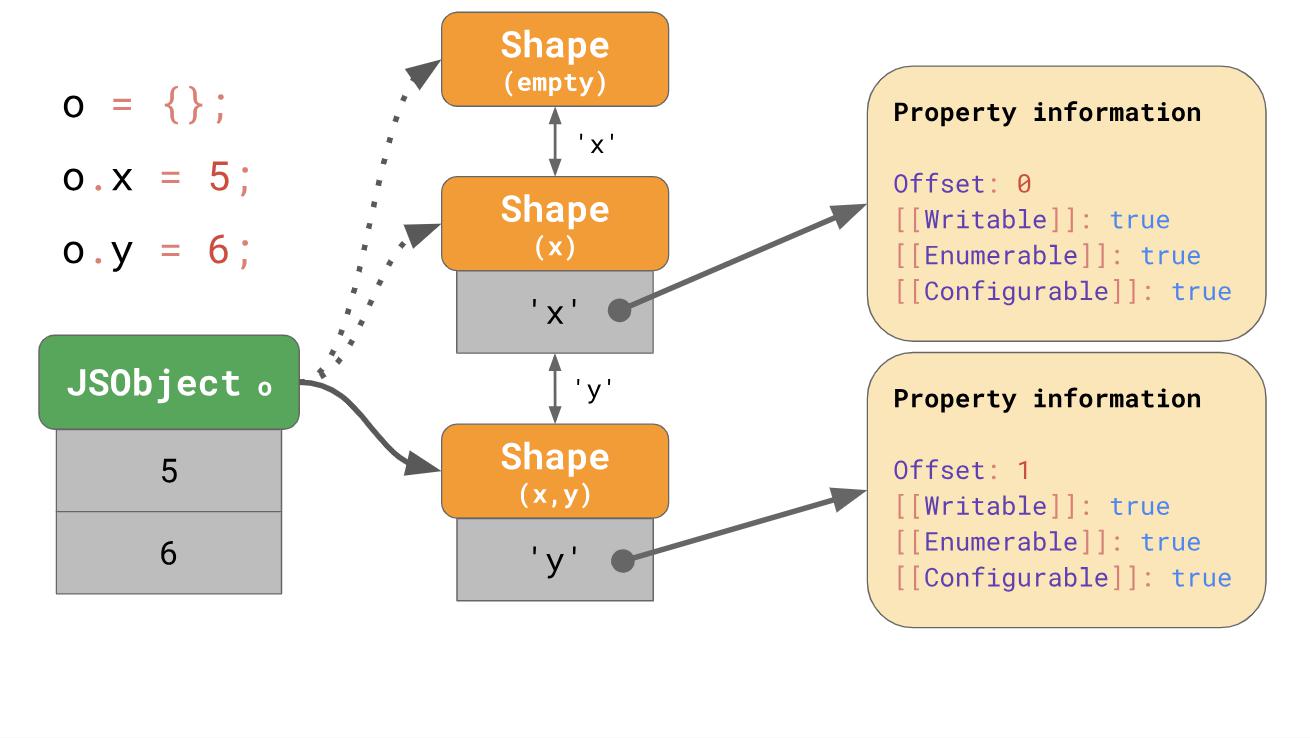
Si vous écrivez
ox dans votre code JavaScript, JavaScript recherchera la propriété
'x' long de la chaîne de transition jusqu'à ce qu'il détecte un formulaire qui contient déjà la propriété
'x' .
Mais que se passe-t-il s'il est impossible de créer une chaîne de transition? Par exemple, que se passe-t-il si vous avez deux objets vides et que vous leur ajoutez des propriétés différentes?
const object1 = {}; object1.x = 5; const object2 = {}; object2.y = 6;
Dans ce cas, une branche apparaît, et au lieu de la chaîne de transition, nous obtenons un arbre de transition:
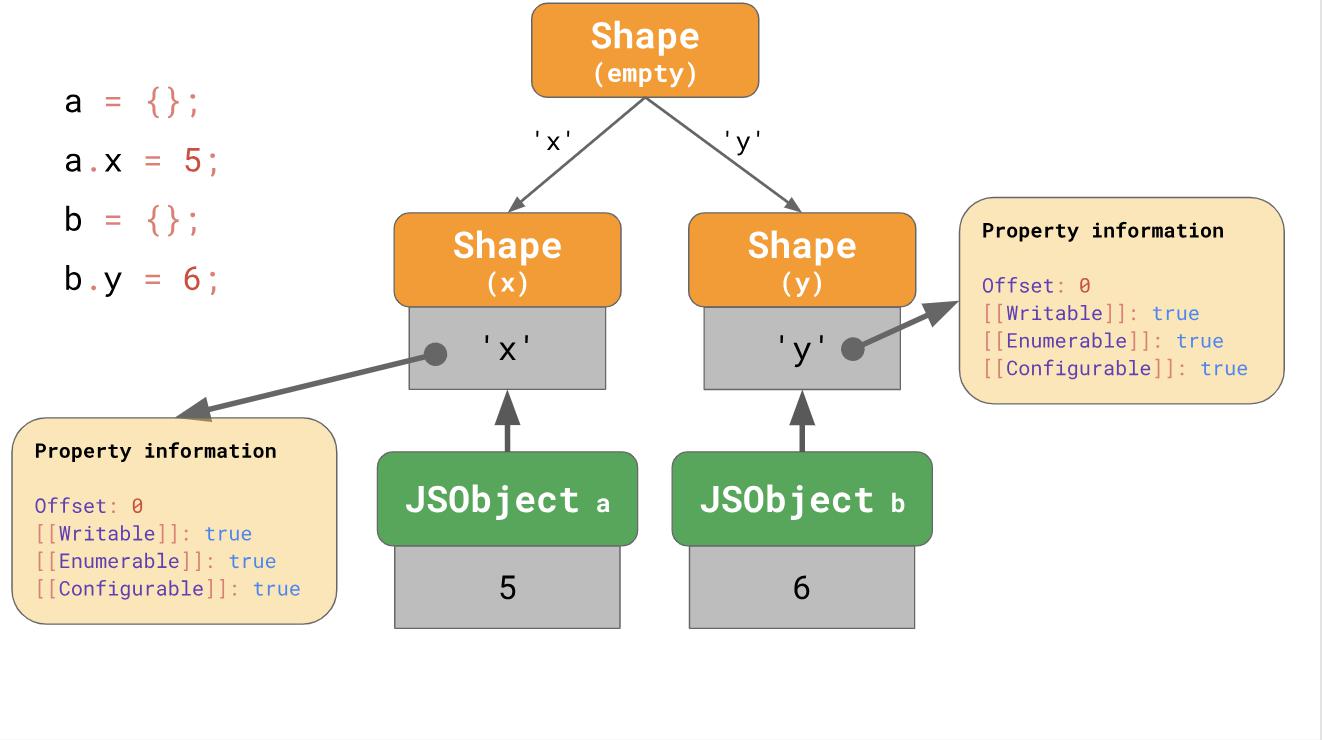
Nous créons un objet vide
a et y ajoutons la propriété
'x' . En conséquence, nous avons un
JSObject contenant une seule valeur et deux formulaires: vide et un formulaire avec une seule propriété
'x' .
Le deuxième exemple commence par le fait que nous avons un objet vide
b , mais ensuite nous ajoutons une autre propriété
'y' . En conséquence, nous obtenons ici deux chaînes de formes, mais à la fin, nous obtenons trois chaînes.
Est-ce à dire que nous commençons toujours par un formulaire vide? Pas forcément. Les moteurs utilisent une certaine optimisation des littéraux d'objet, qui contiennent déjà des propriétés. Disons que nous ajoutons x, en commençant par un littéral d'objet vide, ou que nous avons un littéral d'objet qui contient déjà
x :
const object1 = {}; object1.x = 5; const object2 = { x: 6 };
Dans le premier exemple, nous commençons avec un formulaire vide et passons à une chaîne qui contient également
x , comme nous l'avons vu précédemment.
Dans le cas de
object2 il est logique de créer directement des objets qui ont déjà x dès le début, plutôt que de commencer avec un objet vide et une transition.
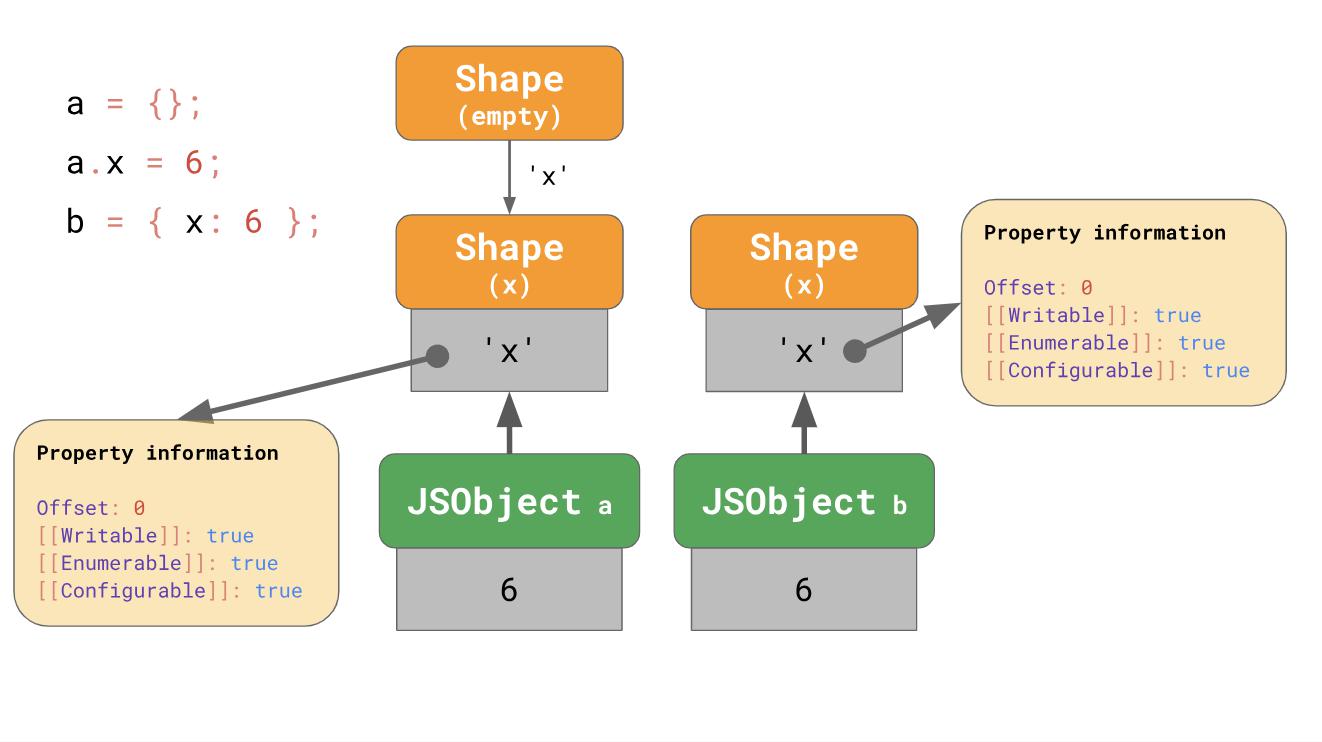
Le littéral d'un objet qui contient la propriété
'x' commence par un formulaire contenant
'x' dès le début, et le formulaire vide est effectivement ignoré. C'est (au moins) ce que font V8 et SpiderMonkey. L'optimisation raccourcit la chaîne de transition et facilite l'assemblage d'objets à partir de littéraux.
Le billet de blog de Benedict sur l'incroyable polymorphisme des applications sur
React explique comment de telles subtilités peuvent affecter les performances.
De plus, vous verrez un exemple de points d'un objet tridimensionnel avec les propriétés
'x' ,
'y' ,
'z' .
const point = {}; point.x = 4; point.y = 5; point.z = 6;
Comme vous l'avez compris précédemment, nous créons un objet avec trois formulaires en mémoire (sans compter le formulaire vide). Pour accéder à la propriété
'x' de cet objet, par exemple, si vous écrivez
point.x dans votre programme, le moteur JavaScript doit suivre une liste liée: en commençant par le formulaire tout en bas, puis en remontant progressivement vers le formulaire qui a
'x' tout en haut.
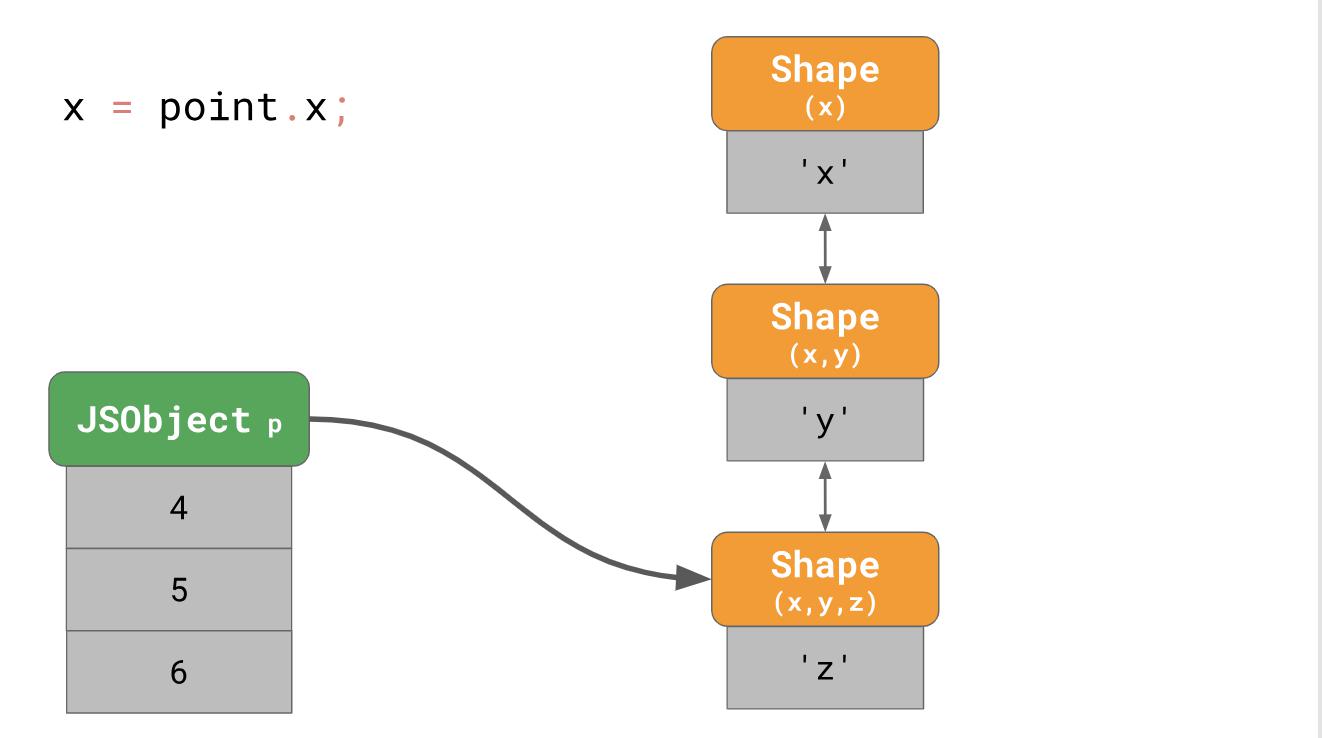
Cela se révèle très lentement, surtout si vous le faites souvent et avec beaucoup de propriétés de l'objet. Le temps de séjour d'une propriété est
O(n) , c'est-à-dire qu'il s'agit d'une fonction linéaire qui est en corrélation avec le nombre de propriétés de l'objet. Pour accélérer les recherches de propriétés, les moteurs JavaScript ajoutent une structure de données ShapeTable. ShapeTable est un dictionnaire où les clés sont mappées d'une certaine manière avec les formulaires et produisent la propriété souhaitée.
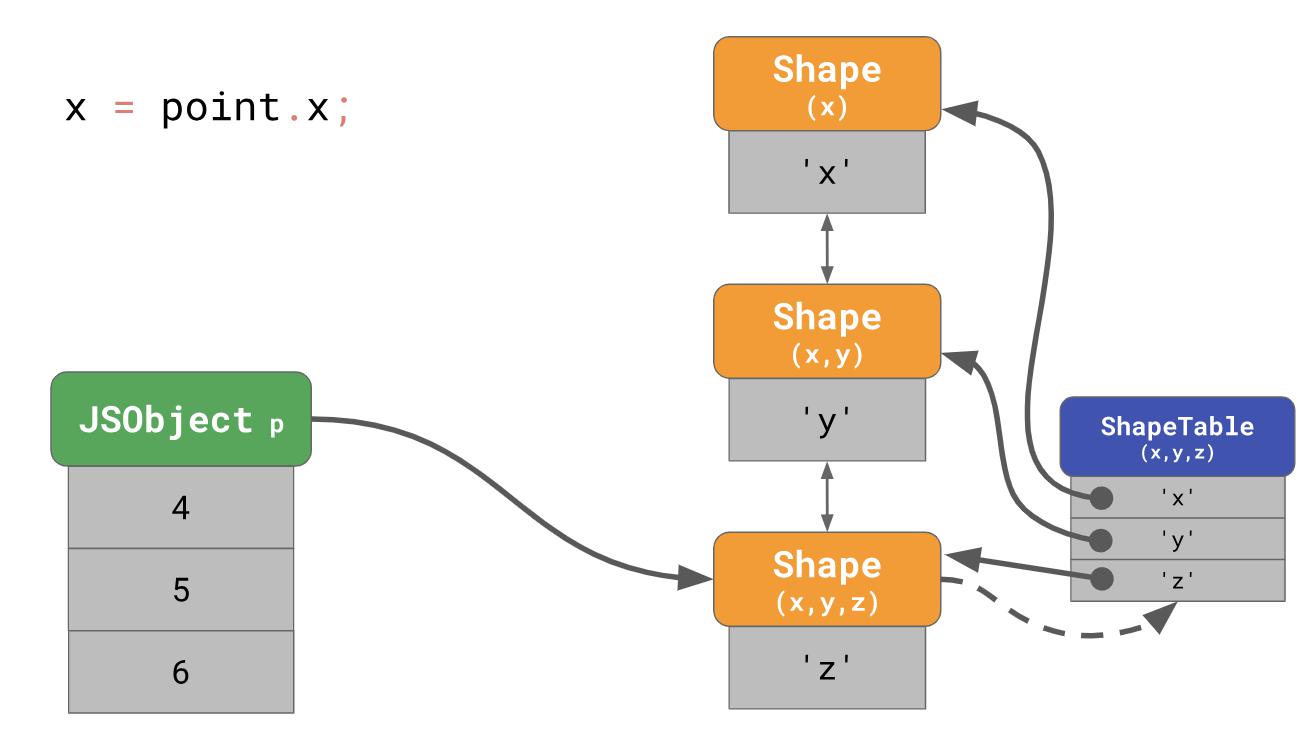
Attendez une seconde, maintenant nous retournons à la recherche de dictionnaire ... C'est exactement ce avec quoi nous avons commencé lorsque nous avons mis les formulaires en premier lieu! Alors, pourquoi nous soucions-nous même des formulaires?
Le fait est que les formulaires contribuent à une autre optimisation appelée
caches en ligne.Nous parlerons du concept de caches en ligne ou de circuits intégrés dans la
deuxième partie de l' article, et nous voulons maintenant vous inviter à un
webinaire ouvert gratuit , qui sera organisé par le célèbre analyste de virus et professeur à temps partiel,
Alexander Kolesnikov , le 9 avril.