Dans le domaine du développement d'applications multithreads ou distribuées très chargées, des discussions sur la programmation asynchrone se posent souvent. Aujourd'hui, nous allons plonger dans l'asynchronie en détail et étudier ce que c'est quand cela se produit, comment cela affecte le code et le langage de programmation que nous utilisons. Nous découvrirons pourquoi les Futures et les Promesses sont nécessaires, et aborderons les coroutines et les systèmes d'exploitation. Cela rendra les compromis qui surviennent pendant le développement de logiciels plus explicites.
Le matériel est basé sur une transcription d'un rapport d'Ivan Puzyrevsky, enseignant à la Yandex Data Analysis School.

Enregistrement vidéo
1. Contenu
2. Introduction
Bonjour à tous, je m'appelle Ivan Puzyrevsky, je travaille pour Yandex. Au cours des six dernières années, je me suis engagé dans l'infrastructure de stockage et de traitement des données, maintenant je suis passé au produit - à la recherche de voyages, d'hôtels et de billets. Depuis que je travaille depuis longtemps dans l'infrastructure, j'ai acquis pas mal d'expérience sur la façon d'écrire différentes applications chargées. Notre infrastructure fonctionne 24*7*365 heures sur 24*7*365 jours sur 7, sans interruption, en continu sur des milliers de machines. Naturellement, vous devez écrire du code pour qu'il fonctionne de manière fiable et efficace et résout les tâches que l'entreprise pose.
Aujourd'hui, nous allons parler d'asynchronie. Qu'est-ce que l'asynchronie? C'est un décalage entre quelque chose et quelque chose dans le temps. D'après cette description, il n'est généralement pas clair de quoi je vais parler aujourd'hui. Pour clarifier quelque peu le problème, j'ai besoin d'un exemple à la «Bonjour, monde!». L'asynchronie se produit généralement dans le contexte de l'écriture d'applications réseau, donc j'aurai un réseau analogique "Bonjour, monde!". Ceci est une application de ping-pong. Le code ressemble à ceci:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Je crée un socket, je lis une ligne à partir de là et vérifie s'il s'agit de ping, puis j'écris pong en réponse. Très simple et clair. Que se passe-t-il lorsque vous voyez ce code sur l'écran de votre ordinateur? Nous considérons ce code comme une séquence de ces étapes:
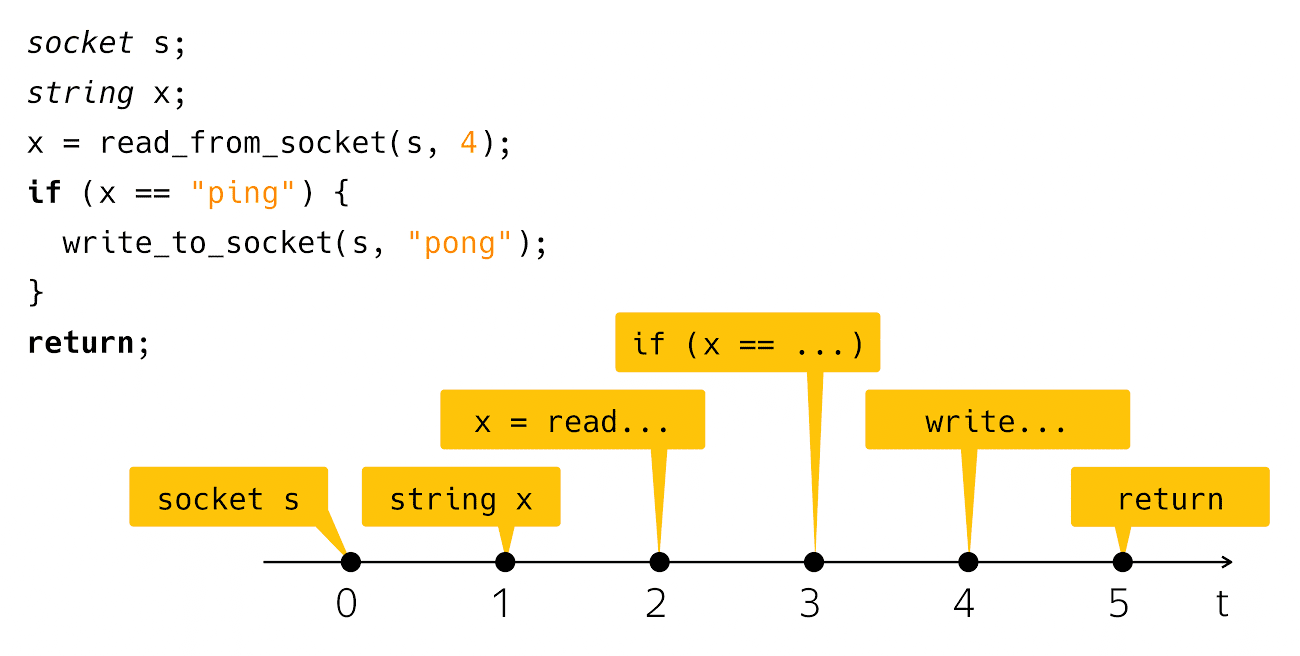
Du point de vue du temps physique réel, tout est un peu biaisé.

Ceux qui ont écrit et exécuté un tel code savent qu'après l'étape de lecture et après l'étape
l'écriture est un intervalle de temps assez perceptible lorsque notre programme semble ne rien faire du point de vue de notre code, mais sous le capot la machine fonctionne, que nous appelons «entrée-sortie».

Pendant les E / S, les paquets sont échangés sur le réseau et tous les travaux lourds et de bas niveau qui en découlent. Faisons une expérience de réflexion: prenons un tel programme, exécutez-le sur un processeur physique et prétendez que nous n'avons pas de système d'exploitation, que se passera-t-il? Le processeur ne peut pas s'arrêter, il continue de prendre des mesures sans suivre aucune instruction, gaspillant simplement de l'énergie en vain.
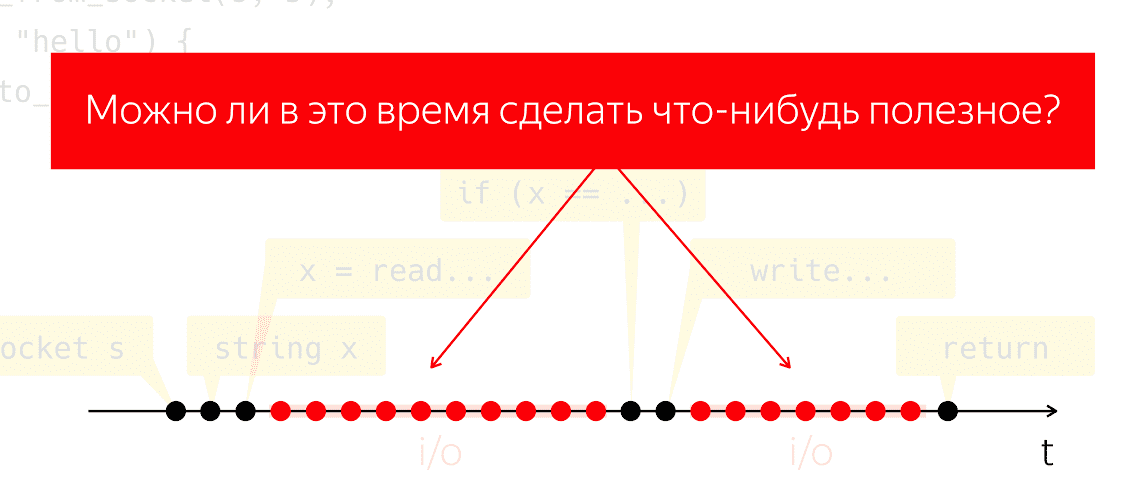
La question se pose de savoir si nous pouvons faire quelque chose d’utile pendant cette période. C'est une question très naturelle, dont la réponse nous permettrait d'économiser la puissance du processeur et de l'utiliser pour quelque chose d'utile, alors que notre application semble ne rien faire.
3. Concepts de base
3.1. Fil d'exécution
Comment pouvons-nous aborder cette tâche? Réconcilions les concepts. Je dirai "flux d'exécution", en référence à une séquence significative d'opérations ou d'étapes élémentaires. La signification sera déterminée par le contexte dans lequel je parle du flux d'exécution. Autrement dit, si nous parlons d'un algorithme à un seul thread (Aho-Korasik, recherche de graphes), alors cet algorithme lui-même est déjà un thread d'exécution. Il prend quelques mesures pour résoudre le problème.
Si je parle d'une base de données, alors un thread d'exécution peut faire partie des actions effectuées par la base de données pour servir une demande entrante. Il en va de même pour les serveurs Web. Si j'écris une sorte d'application mobile ou Web, pour servir les opérations d'un utilisateur, par exemple, en cliquant sur un bouton, les interactions réseau, l'interaction avec le stockage local, etc. La séquence de ces actions du point de vue de mon application mobile sera également un flux d'exécution significatif distinct. Du point de vue du système d'exploitation, un processus ou un thread de processus est également un thread d'exécution significatif.
3.2. Multitâche et simultanéité
La pierre angulaire de la productivité est la capacité de faire une telle astuce: lorsque j'ai un thread d'exécution qui contient des vides dans son analyse du temps physique, puis remplissez ces vides avec quelque chose d'utile - suivez les étapes des autres threads d'exécution.
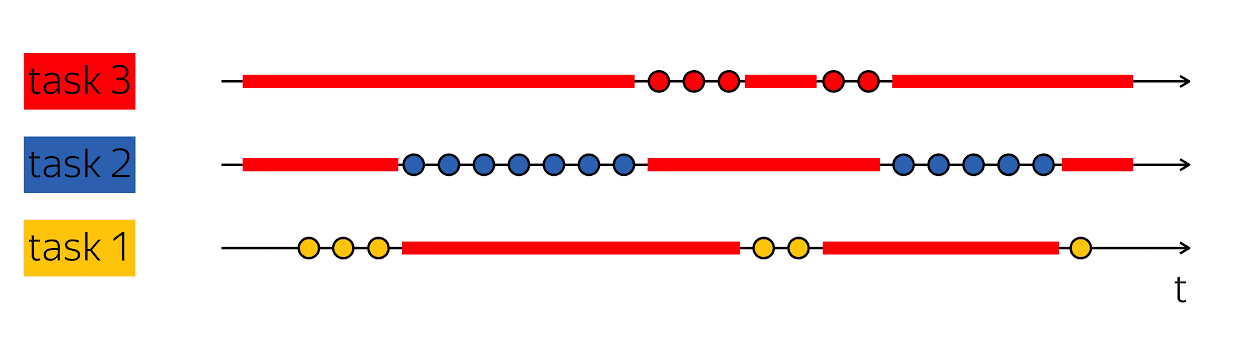
Les bases de données desservent généralement de nombreux clients en même temps. Si nous pouvons combiner le travail sur plusieurs threads d'exécution dans le cadre d'un thread d'exécution d'un niveau supérieur, alors cela s'appelle le multitâche. C'est-à-dire que le multitâche est lorsque j'exécute des actions dans le cadre d'un plus grand flux d'exécution qui sont subordonnées à la solution de tâches plus petites.
Il est important de ne pas confondre le concept de multitâche avec le parallélisme. Accès simultané -
ce sont des propriétés de l'environnement d'exécution, ce qui permet en une seule étape, en une seule étape, de progresser dans différents threads d'exécution. Si j'ai deux processeurs physiques, alors dans un cycle d'horloge, ils peuvent exécuter deux instructions. Si le programme s'exécute sur un processeur, il faudra deux cycles d'horloge pour exécuter les deux mêmes instructions.

Il est important de ne pas confondre ces concepts, car ils entrent dans différentes catégories. Le multitâche est une caractéristique de votre programme car il est structuré en interne comme un travail variable sur différentes tâches. La concurrence est une propriété de l'environnement d'exécution qui vous permet de travailler sur plusieurs tâches en un seul cycle d'horloge.
À bien des égards, le code asynchrone et l'écriture de code asynchrone consiste à écrire du code multitâche. La principale difficulté est de savoir comment j'encode les tâches et comment les gérer. Par conséquent, nous en parlerons aujourd'hui - écrire du code multitâche.
4. Blocage et attente

Commençons par un exemple simple. Retour au ping-pong:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Comme nous l'avons déjà évoqué, après les lignes lues et blanches le fil d'exécution s'endort, il est bloqué. Habituellement, nous disons «le flux est bloqué».
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Cela signifie que le flux d'exécution a atteint un point où tout événement est nécessaire pour le poursuivre. En particulier, dans le cas de notre application réseau, il est nécessaire que les données arrivent sur le réseau ou, inversement, nous avons un tampon gratuit pour écrire des données sur le réseau. Les événements peuvent être différents. Si nous parlons d'aspects temporels, nous pouvons attendre le déclenchement de la minuterie ou la fin d'un autre processus. Les événements ici sont une sorte de chose abstraite, à propos d'eux, il est important de comprendre qu'ils peuvent être attendus.

Lorsque nous écrivons du code simple, nous donnons implicitement le contrôle de l'attente des événements à un niveau supérieur. Dans notre cas, le système d'exploitation. Elle, en tant qu'entité d'un niveau supérieur, est responsable du choix de la tâche qui sera exécutée ensuite, et elle est également responsable du suivi de l'occurrence des événements.
Notre code, que nous écrivons en tant que développeur, est structuré en même temps en ce qui concerne le travail sur une tâche. L'extrait de code de l'exemple gère une connexion: il lit le ping d'une connexion et écrit le pong dans une connexion.
Le code est clair. Vous pouvez le lire et comprendre ce qu'il fait, comment cela fonctionne, quel problème il résout, quels invariants il a, etc. Dans le même temps, nous gérons très mal la planification des tâches dans un tel modèle. En général, les systèmes d'exploitation ont des concepts de priorités, mais si vous avez écrit des systèmes en temps réel doux, vous savez que les outils disponibles sous Linux ne sont pas suffisants pour créer suffisamment de systèmes en temps réel sains.
De plus, le système d'exploitation est une chose compliquée, et le changement de contexte de notre application vers le noyau coûte quelques microsecondes, ce qui, avec quelques calculs simples, nous donne une estimation d'environ 20 à 100 000 changements de contexte par seconde. Cela signifie que si nous écrivons un serveur Web, en une seconde, nous pouvons traiter environ 20 000 demandes, en supposant que le traitement des demandes est dix fois plus cher que le système.

4.1. Attente non bloquante
Si vous arrivez à la situation dont vous avez besoin pour travailler plus efficacement avec le réseau, alors vous commencez à chercher de l'aide sur Internet et à utiliser select / epoll. Sur Internet, il est écrit que si vous voulez servir des milliers de connexions en même temps, vous avez besoin d'epoll, car c'est un bon mécanisme, etc. Vous ouvrez la documentation et voyez quelque chose comme ceci:
int select(int nfds, fd_set* readfds, fd_set* writefds, fd_set* exceptfds, struct timeval* timeout); void FD_CLR(int fd, fd_set* set); int FD_ISSET(int fd, fd_set* set); void FD_SET(int fd, fd_set* set); void FD_ZERO(fd_set* set); int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event); int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
Fonctions dans lesquelles l'interface contient soit de nombreux descripteurs avec lesquels vous travaillez (dans le cas de select), soit de nombreux événements qui passent
à travers les frontières de votre application, le noyau du système d'exploitation que vous devez traiter (dans le cas d'epoll).
Il convient également d'ajouter que vous ne pouvez pas sélectionner / epoll, mais dans une bibliothèque telle que libuv, qui n'aura aucun événement dans l'API, mais aura de nombreux rappels. L'interface de la bibliothèque dira: "Cher ami, fournissez un rappel pour lire le socket, que j'appellerai lorsque les données apparaîtront."
int uv_timer_start(uv_timer_t* handle, uv_timer_cb cb, uint64_t timeout, uint64_t repeat); typedef void (*uv_timer_cb)(uv_timer_t* handle); int uv_read_start(uv_stream_t* stream, uv_alloc_cb alloc_cb, uv_read_cb read_cb); int uv_read_stop(uv_stream_t*); typedef void (*uv_read_cb)(uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf); int uv_write(uv_write_t* req, uv_stream_t* handle, const uv_buf_t bufs[], unsigned int nbufs, uv_write_cb cb); typedef void (*uv_write_cb)(uv_write_t* req, int status);
Qu'est-ce qui a changé par rapport à notre code synchrone dans le chapitre précédent? Le code est devenu asynchrone. Cela signifie que nous avons intégré la logique dans l'application pour déterminer le moment où les événements sont surveillés. Les appels select / epoll explicites sont les points où nous demandons au système d'exploitation des informations sur les événements qui se sont produits. Nous avons également pris en compte dans notre code d'application le choix de la tâche à effectuer ensuite.

À partir des exemples d'interfaces, vous pouvez voir qu'il existe essentiellement deux mécanismes pour introduire le multitâche. Une sorte de «pull» quand nous
nous faisons ressortir bon nombre des événements que nous attendons, puis nous réagissons d'une manière ou d'une autre à eux. Dans cette approche, il est facile d'amortir les frais généraux d'une unité
un événement et donc atteindre un débit élevé de communication sur l'ensemble des événements qui se sont produits. Habituellement, tous les éléments du réseau tels que l'interaction du noyau avec la carte réseau ou l'interaction entre vous et le système d'exploitation reposent sur des mécanismes d'interrogation.
La deuxième façon est un mécanisme de «poussée», lorsqu'une certaine entité externe entre clairement, interrompt le flux d'exécution et dit: «Maintenant, veuillez gérer l'événement qui vient d'arriver.» Il s'agit d'une approche avec des rappels, avec des signaux Unix, avec des interruptions au niveau du processeur, lorsqu'une entité externe envahit clairement votre thread d'exécution et dit: "Maintenant, s'il vous plaît, nous travaillons sur cet événement." Cette approche est apparue afin de réduire le délai entre la survenance d'un événement et sa réaction.
Pourquoi les développeurs C ++ qui écrivent et résolvent des problèmes d'application spécifiques peuvent-ils vouloir faire glisser un modèle d'événement dans notre code? Si nous glissons et déposons le travail sur de nombreuses tâches dans notre code et les gérons, alors en raison du manque de transition vers le noyau et vice versa, nous pouvons travailler un peu plus rapidement et effectuer des actions plus utiles par unité de temps.
À quoi cela mène-t-il en termes de code que nous écrivons? Prenez nginx, par exemple, un serveur HTTP hautes performances, très courant. Si vous lisez son code, il est construit sur un modèle asynchrone. Le code est assez difficile à lire. Lorsque vous vous demandez ce qui se passe exactement lors du traitement d'une seule requête HTTP, il s'avère qu'il y a beaucoup de fragments dans le code, espacés dans différents fichiers, à différents angles de la base de code. Chaque fragment effectue une petite quantité de travail dans le cadre du traitement de la requête HTTP entière. Par exemple:
static void ngx_http_request_handler(ngx_event_t *ev) { … if (c->close) { ngx_http_terminate_request(r, 0); return; } if (ev->write) { r->write_event_handler(r); } else { r->read_event_handler(r); } ... } typedef void (*ngx_http_event_handler_pt)(ngx_http_request_t *r); struct ngx_http_request_s { ngx_http_event_handler_pt read_event_handler; }; r->read_event_handler = ngx_http_request_empty_handler; r->read_event_handler = ngx_http_block_reading; r->read_event_handler = ngx_http_test_reading; r->read_event_handler = ngx_http_discarded_request_body_handler; r->read_event_handler = ngx_http_read_client_request_body_handler; r->read_event_handler = ngx_http_upstream_rd_check_broken_connection; r->read_event_handler = ngx_http_upstream_read_request_handler;
Il existe une structure de demande, qui est transmise au gestionnaire d'événements lorsque le socket signale un accès en lecture ou en écriture. De plus, ce gestionnaire bascule constamment au cours du programme en fonction de l'état du traitement de la demande. Soit nous lisons les en-têtes, soit nous lisons le corps de la demande, soit nous demandons des données en amont - en général, il existe de nombreux états différents.
Un tel code est difficile à lire car il est, en substance, décrit en termes de réaction aux événements. Nous sommes dans tel ou tel état et réagissons d'une certaine manière aux événements qui se sont produits. Il n'y a pas une image complète de l'ensemble du processus de traitement d'une demande HTTP.
Une autre option, qui est souvent utilisée en JavaScript, consiste à créer du code basé sur le rappel lorsque nous transférons notre rappel à l'appel d'interface, dans lequel il existe généralement un autre rappel imbriqué pour un événement, etc.
int LibuvStreamWrap::ReadStart() { return uv_read_start(stream(), [](uv_handle_t* handle, size_t suggested_size, uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(handle->data)->OnUvAlloc(suggested_size, buf); }, [](uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(stream->data)->OnUvRead(nread, buf); }); } for (p=data; p != data + len; p++) { ch = *p; reexecute: switch (CURRENT_STATE()) { case s_start_req_or_res: case s_res_or_resp_H: case s_res_HT: case s_res_HTT: case s_res_HTTP: case s_res_http_major: case s_res_http_dot:
Le code est à nouveau très fragmenté, il n'y a aucune compréhension de l'état actuel de la façon dont nous travaillons sur la demande. De nombreuses informations sont transmises par le biais de fermetures, et vous devez faire des efforts mentaux pour reconstruire la logique de traitement d'une seule demande.
Ainsi, en introduisant le multitâche dans notre code (la logique de choisir les tâches de travail et de les multiplexer), nous obtenons un code efficace et un contrôle sur la priorisation des tâches, mais nous en perdons beaucoup en lisibilité. Ce code est difficile à lire et difficile à maintenir.

Pourquoi? Supposons que j'ai un cas simple, par exemple, je lis un fichier et le transfère sur le réseau. Dans une version non bloquante, ce cas correspondra à une telle machine à états linéaires:
- État initial
- Commencez à lire un fichier,
- En attente d'une réponse du système de fichiers,
- Ecrire un fichier sur un socket,
- État final.
Supposons maintenant que je souhaite ajouter des informations de la base de données à ce fichier. Une option simple:
- état initial
- lire un fichier
- lire le dossier
- lecture de la base de données
- lire à partir de la base de données,
- Je travaille avec une prise
- écrit sur la prise.
Cela ressemble à un code linéaire, mais le nombre d'états a augmenté.
Ensuite, vous commencez à penser qu'il serait bien de paralléliser les deux étapes - la lecture d'un fichier et d'une base de données. Les miracles de la combinatoire commencent: vous êtes dans l'état initial, vous demandez à lire le fichier et les données de la base de données. Ensuite, vous pouvez soit arriver à un état où il y a des données de la base de données, mais il n'y a pas de fichier, ou vice versa - il y a des données du fichier, mais pas de la base de données. Ensuite, vous devez entrer dans un état où vous avez l'une des deux choses. Encore une fois, ce sont deux États. Ensuite, vous devez entrer dans un état où vous avez les deux ingrédients. Ensuite, écrivez-les dans la prise et ainsi de suite.
Plus l'application est complexe, plus il y a d'états, plus il y a de fragments de code à combiner dans votre tête. Inopportunément. Ou vous écrivez des nouilles de rappel, ce qui n'est pas pratique à lire. Si un système de branchement est écrit, il arrive un jour où vous ne pouvez plus le tolérer.
5. Futures / promesses
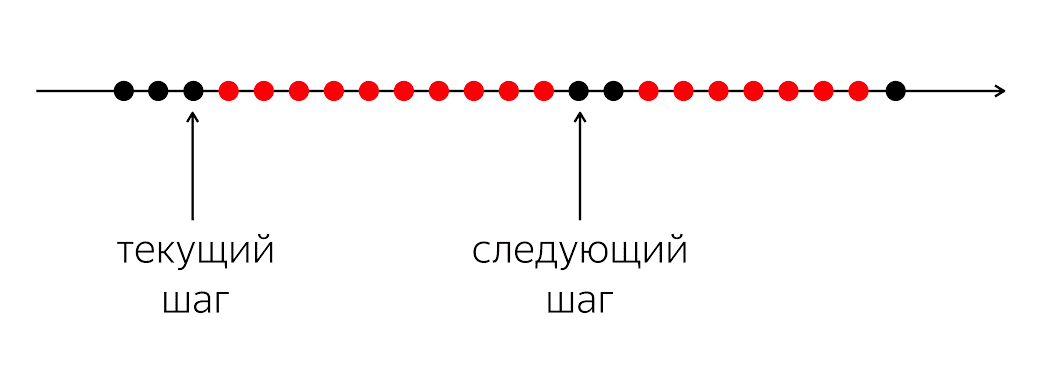
Pour résoudre le problème, vous devez regarder la situation plus facilement.

Il y a un programme, il a des cercles noirs et rouges. Notre flux d'exécution est constitué de cercles noirs; parfois ils sont alternés avec du rouge lorsque le flux ne peut pas continuer son travail. Le problème est que pour notre fil d'exécution noir, vous devez entrer dans le prochain cercle noir, qui ne sera pas connu quand.
Le problème est que lorsque nous écrivons du code dans un langage de programmation, nous expliquons à l'ordinateur ce qu'il faut faire maintenant. Un ordinateur est une chose relativement simple qui attend des instructions que nous écrivons dans le langage de programmation. Elle attend des instructions pour le prochain cercle, et dans notre langage de programmation, il n'y a pas assez d'argent pour dire: "À l'avenir, s'il se passe quelque chose, fais quelque chose."

Dans un langage de programmation, nous opérons avec des actions momentanées compréhensibles: appel d'une fonction, opérations arithmétiques, etc. Ils décrivent la prochaine étape suivante spécifique. Dans le même temps, pour traiter la logique d'application, il est nécessaire de décrire non pas la prochaine étape physique, mais la prochaine étape logique: que devons-nous faire lorsque des données de la base de données apparaissent, par exemple.
Par conséquent, nous avons besoin d'un mécanisme pour combiner ces fragments. Dans le cas où nous avons écrit du code synchrone, nous avons complètement caché la question sous le capot et déclaré que le système d'exploitation allait s'en occuper, lui permettre d'interrompre et de replanifier nos threads.
Au niveau 1, nous avons ouvert cette boîte de Pandore, et cela a apporté beaucoup de commutateurs, de cas, de conditions, de branches, d'états au code. Je voudrais un compromis pour que le code soit relativement lisible, mais conserve tous les avantages du niveau 1.
Heureusement pour nous, en 1988, les personnes impliquées dans les systèmes distribués, Barbara Liskov et Lyub Shirir, ont réalisé le problème et sont venues au besoin de changements linguistiques. Il est nécessaire d'ajouter au langage de programmation des constructions qui permettent d'exprimer des relations temporelles entre les événements - au moment présent dans le temps et à un moment incertain dans le futur.
Ce sont des promesses. Le concept est cool, mais il accumule de la poussière sur une étagère depuis vingt ans.Récemment, il a gagné en intérêt - par exemple, des camarades sur Twitter, lorsqu'ils ont refactorisé leur code de Ruby on Rails à Scala, ont imprégné ce concept assez profondément et ont décidé que tous les services seraient une fonction qui prend une demande et renvoie une réponse future. Vous pouvez lire l'article Votre serveur en tant que fonction. Un concept très cohérent, qui leur a permis de restructurer très rapidement l'ensemble du code.
Mais c'est Scala, mais que devons-nous faire, les développeurs C ++?
Nous avons besoin d'une certaine abstraction, appelons-la Future. Il s'agit d'un conteneur pour une valeur de type T avec la sémantique suivante: en ce moment, la valeur dans le conteneur peut être absente, mais dans le futur elle apparaîtra.
template <class T> class Future <T>
, , , . , «», , . Future «», Promise — «». ; , JavaScript, Promise — , Java – Future.
, . , , boost::future ( std::future) — , .
5.1. Future & Promise
template <class T> class Future { bool IsSet() const; const T& Get() const; T* TryGet() const; void Subscribe(std::function<void(const T&)> cb); template <class R> Future<R> Then( std::function<R(const T&)> f); template <class R> Future<R> Then( std::function<Future<R>(const T&)> f); }; template <class T> Future<T> MakeFuture(const T& value);
, , - , . , , , . , , — , , . Then, .
template <class T> class Promise { bool IsSet() const; void Set(const T& value); bool TrySet(const T& value); Future<T> ToFuture() const; }; template <class T> Promise<T> NewPromise();
. , . «, , , ».
5.2.
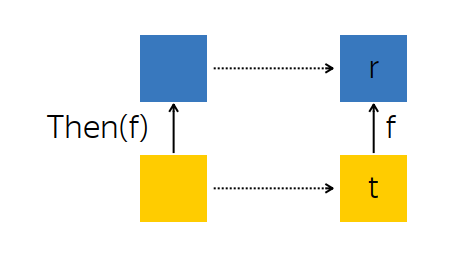
? , . Then — , .
, — future --, - t — . , , , f, - r.
t f. , , r.
: t, , r . :
template <class T> template <class R> Future<R> Future<T>::Then(std::function<R(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto r = f(t); promise.Set(r); }); return promise.ToFuture(); }
:
Promise R ,Future<T> t ,- ,
r = f(t) , r Promise ,Promise .
f , R , Future<R> , R . :
template <class T> template <class R> Future<R> Future<T>::Then(std::function<Future<R>(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto that = f(t); that.Subscribe([promise] (R r) { promise.Set(r); }); }); return promise.ToFuture(); }
, - t. f, r, . , , .

, Then :
Promise ,Subscribe -,Promise , Future .
, . , , , .
, , , -. , , -, Subscribe. , , , - . , .
5.3. Des exemples
AsyncComputeValue, GPU, . Then, , (2v+1) 2 .
Future<int> value = AsyncComputeValue();
. , : (2v+1) 2 . , .
, , . .
. : , ; ; .
Future<int> GetDbKey(); Future<string> LoadDbValue(int key); Future<void> SendToMars(string message); Future<void> ExploreOuterSpace() { return GetDbKey()
— ExploreOuterSpace. Then; — — , . ( ) . .
5.4. Any-
: Future , , . , , :
template <class T> Future<T> Any(Future<T> f1, Future<T> f2) { auto promise = NewPromise<T>(); f1.Subscribe([promise] (const T& t) { promise.TrySet(t); }); f2.Subscribe([promise] (const T& t) { promise.TrySet(t); }); return promise.ToFuture(); }
, Any-, Future : , . , , .
, , , , , . « DB1, DB2, — - ».
5.5. All-
. , , , ( T1 T2), T1 T2 , , .
template <class T1, class T2> Future<std::tuple<T1, T2>> All(Future<T1> f1, Future<T2> f2) { auto promise = NewPromise<std::tuple<T1, T2>>(); auto result = std::make_shared< std::tuple<T1, T2> >(); auto counter = std::make_shared< std::atomic<int> >(2); f1.Subscribe([promise, result, counter] (const T1& t1) { std::get<0>(*result) = t1; if (--(*counter) == 0) { promise.Set(*result)); } }); f2.Subscribe([promise, result, counter] (const T2& t2) { } return promise.ToFuture(); }
nginx. , , . nginx « », « », « » . All- , . .
5.6.
Future Promises — legacy-, . callback- , , : Future, , callback- Future.
: , Future .
6.
, , . .
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp);
. Request, - . , . , , , . , - .
, , . ? — , request payload, — , .
, Java Netty. , , . , , .
, GetRequest, QueryBackend, HandlePayload Reply , Future.
, , Future T — WaitFor.
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future);
:
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor(GetRequest()); auto pld = WaitFor(QueryBackend(req)); auto rsp = WaitFor(HandlePayload(pld)); WaitFor(Reply(req, rsp));
: Future, . . , . .
. . - 0, , , mutex+cvar future. . , .

6.1.
, . , , , , - , . , - .
— «» , , . . . : boost::asio boost::fiber.
, . Comment faire
6.2. WaitFor
, , boost::context, : , ; , . x86/64 , , .
, goto: , , , .
, - . Fiber — . +Future. , , Future, .
class Fiber { MachineContext context_; Future<void> future_; };
class Scheduler { void WaitFor(Future<void> future); void Loop(); MachineContext loop_context_; Fiber* current_fiber_; std::deque<Fiber*> run_queue_; };
Future , , , . : Loop, , , , , .
WaitFor?
thread_local Scheduler* ThisScheduler; template <class T> T WaitFor(Future<T> future) { ThisScheduler->WaitFor(future.As<void>()); return future.Get(); } void Scheduler::WaitFor(Future<void> future) { current_fiber_->future_ = future; SwitchContext(¤t_fiber_->context_, &loop_context_); }
: , - , , Future void, . .
Future<void> , , - .
WaitFor : : « Fiber Future», ( ) .
, :
ThisScheduler->WaitFor return future.Get() , .
? , Future, .
6.3.
- , , , - , . SwitchContext , 2 — .
void Scheduler::Loop() { while (true) {
? , , , Future, Future, , , .
void Scheduler::Loop() { while (true) {
, . :
WaitFor — .

Switch- .

Future ( ), , . - Fiber.

WaitFor Future , - , Future . :
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor( GetRequest()); auto pld = WaitFor( QueryBackend(req)); auto rsp = WaitFor( HandlePayload(pld)); WaitFor( Reply(req, rsp));
, , , . , , .
6.4. Coroutine TS
? — . Coroutine TS, , WaitFor CoroutineWait, CoroutineTS — - . , - . , Waiter Co, , .
7. ?
. , , , . , , , .
— . , . . , . , , , , .
- , , . , . , , .

, ? , .
. , , , , . . , , , , .
nginx, , , , , . , , , future promises.
, , , , , , , .
futures, promises actors. . , .
: , , , . , , , , . ? , .
Minute de publicité. 19-20 C++ Russia 2019. , , Grimm Rainer «Concurrency and parallelism in C++17 and C++20/23» , C++ . , . , , - .