Depuis l'année dernière, des hackathons ont commencé à être organisés dans notre entreprise. Le premier concours de ce type a été un grand succès, nous en avons parlé dans l'
article . Le deuxième hackathon a eu lieu en février 2019 et n'a pas été moins réussi. L'organisateur a récemment
écrit sur les objectifs de ce dernier.
Les participants se sont vu confier une tâche assez intéressante en toute liberté dans le choix d'une pile technologique pour sa mise en œuvre. Il était nécessaire de mettre en œuvre une plate-forme de décision pour un déploiement pratique des fonctions de notation des clients qui pourraient fonctionner sur un flux rapide d'applications, résister à de lourdes charges, et le système lui-même était facilement évolutif.
La tâche n'est pas anodine et peut être résolue de plusieurs manières, comme nous l'avons vu dans la démonstration des présentations finales des projets des participants. Il y avait 6 équipes de 5 personnes au hackathon, tous les participants avaient de bons projets, mais notre plateforme s'est avérée être la plus compétitive. Nous avons eu un projet très intéressant, dont je voudrais parler dans cet article.
Notre solution est une plate-forme basée sur une architecture sans serveur à l'intérieur de Kubernetes, ce qui réduit le temps nécessaire pour apporter de nouvelles fonctionnalités à la production. Il permet aux analystes d'écrire du code dans un environnement qui leur convient et de le déployer dans la prod sans la participation d'ingénieurs et de développeurs.
Qu'est-ce que la notation?
Tinkoff.ru, comme de nombreuses entreprises modernes, a un score client. La notation est un système d'évaluation des clients basé sur des méthodes statistiques d'analyse des données.
Par exemple, un client nous demande de lui accorder un prêt ou d'ouvrir un compte IP avec nous. Si nous prévoyons de lui accorder un prêt, alors vous devez évaluer sa solvabilité, et si le compte est du capital-investissement, alors vous devez être sûr que le client n'effectuera pas de transactions frauduleuses.
Ces décisions sont basées sur des modèles mathématiques qui analysent à la fois les données de l'application elle-même et les données de notre stockage. En plus de la notation, des méthodes statistiques similaires peuvent également être utilisées dans le travail du service pour générer des recommandations individuelles sur de nouveaux produits pour nos clients.
La méthode d'une telle évaluation peut recevoir une variété de données d'entrée. Et à un moment donné, nous pouvons ajouter un nouveau paramètre à l'entrée, ce qui, selon l'analyse des données historiques, augmentera la conversion de l'utilisation du service.
Nous stockons beaucoup de données sur les relations avec les clients et le volume de ces informations est en constante augmentation. Pour que la notation fonctionne, le traitement des données nécessite également des règles (ou des modèles mathématiques) qui vous permettent de décider rapidement qui approuver la demande, qui refuser et qui d'autre offrir quelques produits pour évaluer son intérêt potentiel.
Pour cette tâche, nous utilisons déjà le
système de prise de décision spécialisé
IBM WebSphere ILOG JRules BRMS , qui, sur la base des règles définies par les analystes, les technologues et les développeurs, décide d'approuver ou non un produit bancaire particulier à un client.
Il existe de nombreuses solutions prêtes à l'emploi sur le marché, à la fois des modèles de notation et des systèmes de prise de décision eux-mêmes. Nous utilisons l'un de ces systèmes dans notre entreprise. Mais l'entreprise se développe, se diversifie, le nombre de clients et le nombre de produits proposés augmentent, et parallèlement, des idées émergent sur la manière d'améliorer le processus décisionnel existant. Certes, les personnes travaillant avec le système existant ont de nombreuses idées sur la façon de le rendre plus simple, meilleur, plus pratique, mais parfois des idées de l'extérieur sont utiles. Afin de collecter des idées solides, un nouveau Hackathon a été organisé.
Tâche
Le hackathon a eu lieu le 23 février. Les participants se sont vus proposer une mission de combat: développer un système de prise de décision, qui devait remplir un certain nombre de conditions.
On nous a expliqué le fonctionnement du système existant et les difficultés rencontrées lors de son fonctionnement, ainsi que les objectifs commerciaux que la plate-forme en développement devrait poursuivre. Le système devrait avoir un délai de commercialisation rapide des règles en cours d'élaboration afin que le code de travail des analystes entre en production le plus rapidement possible. Et pour le flux entrant de demandes, le temps de prise de décision devrait tendre au minimum. En outre, le système développé devrait être en mesure de faire des ventes croisées afin de donner au client la possibilité d'acheter d'autres produits de la société s'ils sont approuvés par nous et un intérêt potentiel de la part du client.
Il est clair qu'en une nuit, il est impossible d'écrire un projet prêt à publier qui entrera certainement en production, et l'ensemble du système est assez difficile à couvrir, nous avons donc été invités à en mettre en œuvre au moins une partie. Un certain nombre d'exigences ont été établies que le prototype doit satisfaire. On pourrait essayer de couvrir toutes les exigences dans leur ensemble et d'élaborer en détail des sections individuelles de la plate-forme développée.
En ce qui concerne la technologie, tous les participants ont eu une totale liberté de choix. Il était possible d'utiliser tous les concepts et technologies: streaming de données, apprentissage automatique, sourcing d'événements, big data et autres.
Notre décision
Après une petite session de brainstorming, nous avons décidé que la solution FaaS serait idéale pour la tâche.
Pour cette solution, il était nécessaire de trouver un cadre sans serveur adapté à la mise en œuvre des règles du système décisionnel développé. Étant donné que Kubernetes est activement utilisé dans la gestion des infrastructures à Tinkoff, nous avons examiné plusieurs solutions prêtes à l'emploi basées sur celui-ci, j'en parlerai plus tard.
Pour trouver la solution la plus efficace, nous avons regardé le produit développé à travers les yeux de ses utilisateurs. Les principaux utilisateurs de notre système sont des analystes impliqués dans l'élaboration de règles. Les règles doivent être déployées sur le serveur ou, comme dans notre cas, déployées sur le cloud pour une prise de décision ultérieure. Du point de vue de l'analyste, le flux de travail est le suivant:
- L'analyste écrit un script, une règle ou un modèle ML basé sur les données du référentiel. Dans le cadre du hackathon, nous avons décidé d'utiliser Mongodb, mais le choix du système de stockage n'est pas important ici.
- Après avoir testé les règles développées sur les données historiques, l'analyste verse son code dans le panneau d'administration.
- Afin d'assurer la gestion des versions, tout le code ira aux référentiels Git.
- Grâce au panneau d'administration, il sera possible de déployer le code dans le cloud en tant que module fonctionnel sans serveur distinct.
Les données source des clients doivent passer par un service d'enrichissement spécialisé, conçu pour enrichir la demande initiale avec les données du référentiel. Il était important de mettre en œuvre ce service de manière à ce qu'il fonctionne avec un référentiel unique (à partir duquel l'analyste prend des données lors de l'élaboration des règles) afin de maintenir une structure de données unifiée.
Avant même le hackathon, nous avons décidé du framework Serverless que nous utiliserons. Il existe de nombreuses technologies sur le marché qui mettent en œuvre cette approche. Les solutions d'architecture Kubernetes les plus populaires sont Fission, Open FaaS et Kubeless. Il y a même un
bon article avec leur description et leur analyse comparative .
Après avoir pesé tous les avantages et les inconvénients, nous avons opté pour la
fission . Ce framework Serverless est assez facile à gérer et répond aux exigences de la tâche.
Pour travailler avec Fission, vous devez comprendre deux concepts de base: la fonction et l'environnement. La fonction (fonction) est un morceau de code écrit dans l'un des langages pour lesquels il existe un environnement de fission (environnement).
La liste des environnements implémentés dans le cadre de ce cadre comprend Python, JS, Go, JVM et de nombreux autres langages et technologies populaires.
Fission est également capable d'exécuter des fonctions, divisées en plusieurs fichiers, préemballés dans l'archive. L'opération de fission dans le cluster Kubernetes est fournie par des pods spécialisés, qui sont gérés par le framework lui-même. Pour interagir avec les modules de cluster, chaque fonction doit se voir attribuer un itinéraire, auquel vous pouvez transmettre des paramètres GET ou un corps de requête en cas de requête POST.
En conséquence, nous avons prévu d'obtenir une solution permettant aux analystes de déployer des scripts de règles développés sans la participation d'ingénieurs et de développeurs. L'approche décrite élimine également la nécessité pour les développeurs de réécrire le code des analystes dans une autre langue. Par exemple, pour le système décisionnel actuel que nous utilisons, nous devons écrire des règles dans des technologies et des langages à profil étroit, dont la portée est extrêmement limitée, et il existe également une forte dépendance à l'égard du serveur d'applications, car tous les projets de règles bancaires sont déployés dans un environnement unique. Par conséquent, pour le déploiement de nouvelles règles, il est nécessaire de libérer l'intégralité du système.
Dans la solution que nous avons proposée, il n'est pas nécessaire de libérer les règles, le code se déploie facilement en un clic de bouton. En outre, la gestion de l'infrastructure dans Kubernetes vous permet de ne pas penser à la charge et à la mise à l'échelle, ces problèmes sont résolus dès le départ. Et l'utilisation d'un seul entrepôt de données élimine la nécessité de comparer les données en temps réel avec les données historiques, ce qui simplifie le travail de l'analyste.
Qu'avons-nous obtenu
Depuis que nous sommes arrivés au hackathon avec une solution toute faite (dans nos fantasmes), il nous suffit de convertir toutes nos pensées en lignes de code.
La clé du succès de tout hackathon est la préparation et un plan bien conçu. Par conséquent, nous avons tout d'abord décidé des modules de notre architecture système et des technologies que nous utiliserons.
L'architecture de notre projet était la suivante:
Ce diagramme montre deux points d'entrée, un analyste (l'utilisateur principal de notre système) et un client.
Le processus de travail est structuré comme ceci. L'analyste développe la fonction de règle et la fonction d'enrichissement des données pour son modèle, enregistre son code dans le référentiel Git et déploie son modèle dans le cloud via l'application de l'administrateur. Considérez comment la fonction étendue sera appelée et prenez des décisions sur les demandes entrantes des clients:
- Le client remplissant un formulaire sur le site envoie sa demande au responsable du traitement. Une application arrive à l'entrée du système, selon laquelle une décision doit être prise, et est enregistrée dans la base de données dans sa forme originale.
- Ensuite, une demande brute est envoyée pour enrichissement, si nécessaire. Vous pouvez compléter la demande initiale avec des données provenant à la fois de services externes et du référentiel. La requête riche reçue est également stockée dans la base de données.
- La fonction analytique est lancée, qui reçoit une requête enrichie en entrée et donne une décision, qui est également enregistrée dans le référentiel.
En tant que stockage dans notre système, nous avons décidé d'utiliser MongoDB en vue du stockage documenté des données sous forme de documents JSON, car les services d'enrichissement, y compris la demande initiale, ont agrégé toutes les données via des contrôleurs REST.
Nous avons donc eu une journée pour mettre en œuvre la plateforme. Nous avons assez bien réparti les rôles, chaque membre de l'équipe avait son propre domaine de responsabilité dans notre projet:
- Le panneau d'administration frontal pour le travail de l'analyste à travers lequel il pouvait télécharger les règles à partir du système de contrôle de version des scripts écrits, choisir les options pour enrichir les données d'entrée et modifier les scripts de règles en ligne.
- Un panneau d'administration backend qui inclut une API REST pour l'intégration frontale et VCS.
- Mise en place d'une infrastructure dans Google Cloud et développement d'un service d'enrichissement des données sources.
- Le module d'intégration de l'application d'administration avec le framework Serverless pour le déploiement ultérieur des règles.
- Scripts de règles pour tester la santé de l'ensemble du système et agrégation d'analyses pour les applications entrantes (décisions prises) pour la démonstration finale.
Commençons dans l'ordre.
Notre frontend a été écrit en Angular 7 à l'aide du kit d'interface utilisateur bancaire. La version finale du panneau d'administration était la suivante:
Comme il n'y avait pas beaucoup de temps, nous avons essayé d'implémenter uniquement la fonctionnalité clé. Pour déployer une fonction dans le cluster Kubernetes, il était nécessaire de sélectionner un événement (un service pour lequel vous devez déployer une règle dans le cloud) et de coder le code de la fonction qui implémente la logique de décision. Pour chaque déploiement de la règle pour le service sélectionné, nous avons écrit un journal de cet événement. Dans le panneau d'administration, vous pouvez voir les journaux de tous les événements.
Tout le code de fonction était stocké dans un référentiel Git distant, qui devait également être défini dans le panneau d'administration. Pour versionner le code, toutes les fonctions ont été stockées dans différentes branches du référentiel. Le panneau d'administration offre également la possibilité d'apporter des ajustements aux scripts écrits afin qu'avant de déployer une fonction en production, vous puissiez non seulement vérifier le code écrit, mais également apporter les modifications nécessaires.
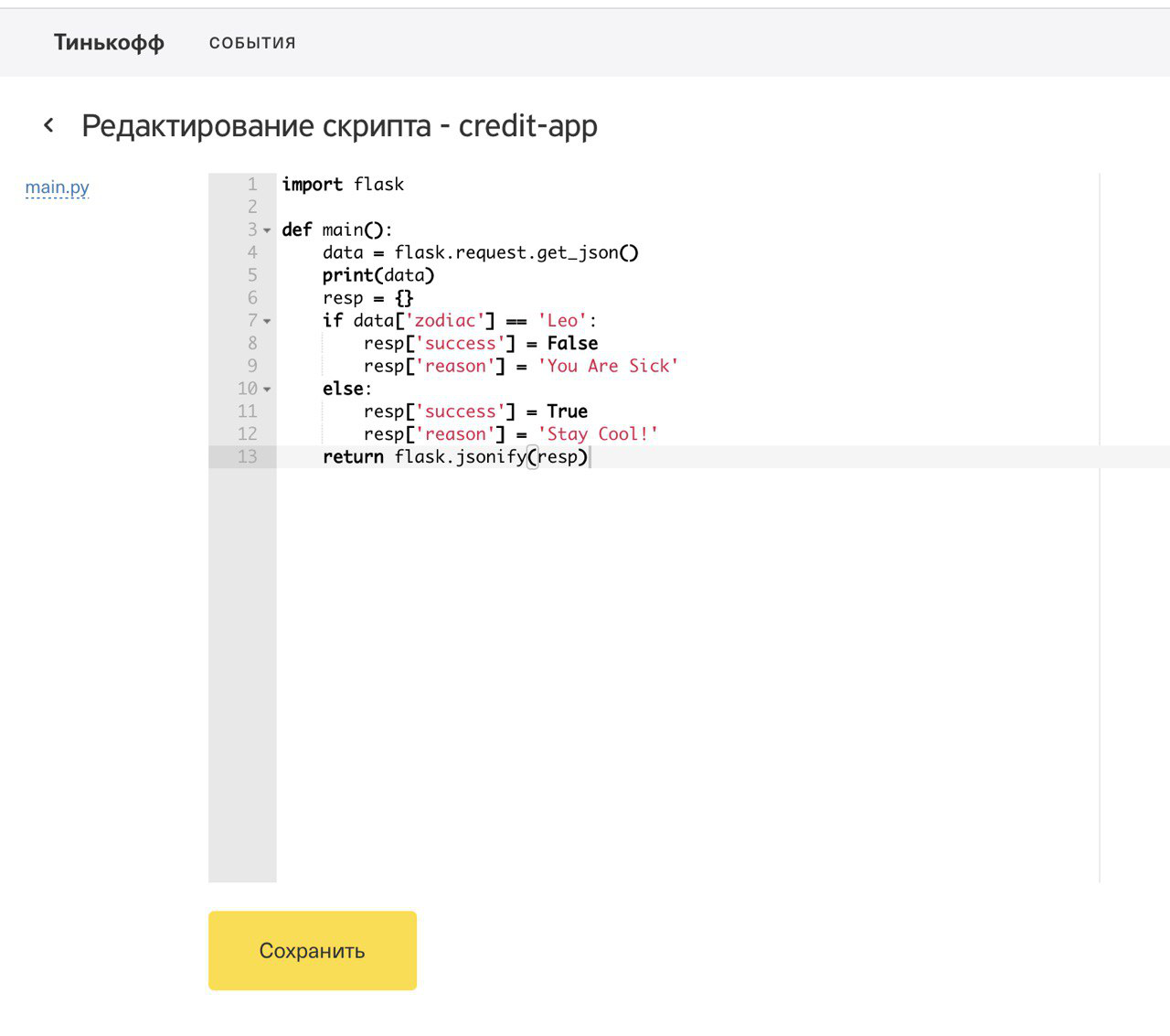
En plus des fonctions des règles, nous avons également réalisé la possibilité d'un enrichissement étape par étape des données source à l'aide des fonctions d'enrichissement, dont le code comprenait également des scripts dans lesquels vous pouviez vous rendre à l'entrepôt de données, appeler des services tiers et effectuer des calculs préliminaires. Pour démontrer notre solution, nous avons calculé le signe du zodiaque du client qui a quitté l'application et déterminé son opérateur mobile à l'aide d'un service REST tiers.
Le backend de la plateforme a été écrit en Java et implémenté en tant qu'application Spring Boot. Pour stocker les données d'administration, nous avions initialement prévu d'utiliser Postgres, mais, dans le cadre du hackathon, nous avons décidé de nous limiter à un simple H2, afin de gagner du temps. Sur le back-end, l'intégration avec Bitbucket a été implémentée pour versionner les fonctions d'enrichissement des requêtes et les scripts de règles. Pour s'intégrer aux référentiels Git distants, la
bibliothèque JGit a été utilisée , qui est une sorte de wrapper sur les commandes CLI qui vous permet d'exécuter toutes les instructions git à l'aide d'une interface de programme pratique. Nous avions donc deux référentiels distincts, pour les fonctions et règles d'enrichissement, et tous les scripts sont disposés dans des répertoires. Grâce à l'interface utilisateur, il était possible de sélectionner le dernier script de validation d'une branche de référentiel arbitraire. Lorsque vous apportez des modifications au code via le panneau d'administration, des validations du code modifié ont été créées dans les référentiels distants.
Pour mettre en œuvre notre idée, nous avions besoin d'une infrastructure adaptée. Nous avons décidé de déployer notre cluster Kubernetes dans le cloud. Notre choix est Google Cloud Platform. Le framework sans serveur Fless a été installé sur le cluster Kubernetes, que nous avons déployé sur Gcloud. Initialement, le service d'enrichissement des données sources a été implémenté par une application Java distincte enveloppée dans un pod à l'intérieur d'un cluster k8s. Mais après une démonstration préliminaire de notre projet au milieu du hackathon, il nous a été recommandé de rendre le service d'Enrichissement plus flexible afin de pouvoir choisir comment enrichir les données brutes des applications entrantes. Et nous n'avions pas d'autre choix que de rendre le service d'enrichissement également sans serveur.
Pour travailler avec Fission, nous avons utilisé la CLI de Fission, qui doit être installée au-dessus de la CLI de Kubernetes. Le déploiement de fonctions dans le cluster k8s est assez simple, il vous suffit d'affecter une route interne et une entrée pour la fonction afin d'autoriser le trafic entrant si un accès en dehors du cluster est requis. Le déploiement d'une fonction ne prend généralement pas plus de 10 secondes.
Présentation finale du projet et résumé
Pour démontrer le fonctionnement de notre système, nous avons placé sur un serveur distant un formulaire simple sur lequel vous pouvez demander l'un des produits de la banque. Pour la demande, vous deviez saisir vos initiales, votre date de naissance et votre numéro de téléphone.
Les données du formulaire client sont allées au responsable du traitement, qui a simultanément envoyé des demandes pour toutes les règles disponibles, pré-enrichi les données selon les conditions données et les stockant dans un stockage commun. Au total, nous avons déployé trois fonctions décisionnelles pour les applications entrantes et 4 services d'enrichissement des données. Après l'envoi de la candidature, le client a reçu notre solution:
En plus du refus ou de l'approbation, le client a également reçu une liste d'autres produits pour lesquels nous avons envoyé des demandes en parallèle. Nous avons donc démontré la possibilité de vente croisée sur notre plateforme.
Au total, 3 produits bancaires inventés étaient disponibles:
Au cours de chaque démonstration, nous avons déployé des fonctions préparées et des scripts d'enrichissement pour chaque service.
Chaque règle avait besoin de son propre ensemble de données d'entrée. Donc, pour approuver l'hypothèque, nous avons calculé le signe du zodiaque du client et l'avons associé à la logique du calendrier lunaire. Pour approuver le jouet, nous avons vérifié que le client était majeur et pour émettre un prêt, nous avons envoyé une demande à un service externe ouvert pour déterminer l'opérateur mobile, et nous avons pris une décision à ce sujet.
Nous avons essayé de rendre notre démonstration intéressante et interactive, toutes les personnes présentes pourraient entrer dans notre formulaire et vérifier la disponibilité de nos services imaginaires pour lui. Et à la toute fin de la présentation, nous avons démontré l'analyse des demandes reçues, où il a été montré combien de personnes ont utilisé notre service, le nombre d'approbations, de refus.
Pour collecter des analyses en ligne, nous avons également déployé l'outil de BI open source Metabase et l'avons vissé dans notre référentiel. La métabase vous permet de créer des écrans avec des analyses basées sur les données qui nous intéressent, il vous suffit d'enregistrer une connexion à la base de données, de sélectionner des tables (dans notre cas, des collectes de données, car nous avons utilisé MongoDB) et de spécifier les champs qui nous intéressent.
En conséquence, nous avons obtenu un bon prototype de la plateforme de prise de décision, et lors de la démonstration, chaque auditeur a pu personnellement tester ses performances. Une solution intéressante, un prototype prêt à l'emploi et une démonstration réussie nous ont permis de gagner, malgré la forte concurrence face aux autres équipes. Je suis sûr que sur le projet de chaque équipe, vous pouvez également écrire un article intéressant.