
Comme mentionné dans l'article de Radar Technology , Lamoda s'oriente activement vers une architecture de microservices. La plupart de nos services sont packagés à l'aide de Helm et déployés sur Kubernetes. Cette approche répond pleinement à nos besoins dans 99% des cas. Il reste 1% lorsque la fonctionnalité Kubernetes standard n'est pas suffisante, par exemple, lorsque vous devez configurer une sauvegarde ou une mise à jour de service pour un événement spécifique. Pour résoudre ce problème, nous utilisons le modèle d'opérateur. Dans cette série d'articles, moi - Grigory Mikhalkin, développeur de l'équipe R&D de Lamoda - parlerai des leçons que j'ai tirées de mon expérience dans le développement d'opérateurs K8 utilisant Operator Framework .
Qu'est-ce qu'un opérateur?
Une façon d'étendre les fonctionnalités de Kubernetes consiste à créer vos propres contrôleurs. Les principales abstractions dans Kubernetes sont les objets et les contrôleurs. Les objets décrivent l'état souhaité du cluster. Par exemple, un pod décrit quels conteneurs doivent être démarrés et les paramètres de démarrage, et l'objet ReplicaSet indique combien de répliques de ce pod doivent être lancées. Les contrôleurs contrôlent l'état du cluster en fonction de la description des objets, dans le cas décrit ci-dessus, le ReplicationController prendra en charge le nombre de répliques de pod spécifié dans le ReplicaSet. Avec l'aide de nouveaux contrôleurs, vous pouvez implémenter une logique supplémentaire, telle que l'envoi de notifications d'événements, la récupération après une panne ou la gestion de ressources tierces .
Un opérateur est une application kubernetes qui comprend un ou plusieurs contrôleurs desservant une ressource tierce. Le concept a été inventé par l'équipe CoreOS en 2016, et récemment, la popularité des opérateurs a augmenté rapidement. Vous pouvez essayer de trouver l'opérateur souhaité dans la liste sur kubedex (plus de 100 opérateurs publiquement disponibles sont répertoriés ici), ainsi que sur OperatorHub . Il existe 3 outils populaires pour le développement des opérateurs: Kubebuilder , Operator SDK et Metacontroller . Dans Lamoda, nous utilisons le SDK opérateur, nous en parlerons donc plus tard.
SDK opérateur
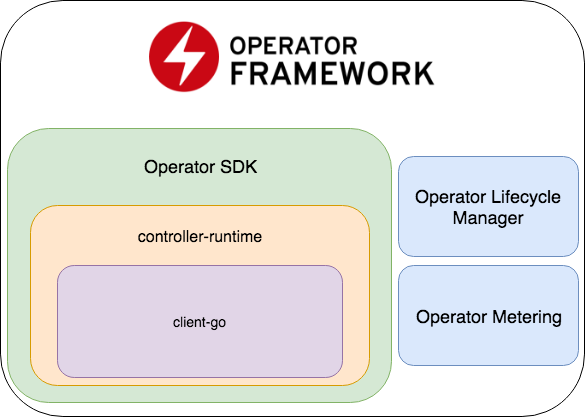
Operator SDK fait partie de Operator Framework, qui comprend deux parties plus importantes: Operator Lifecycle Manager et Operator Metering.
- Le SDK opérateur est un wrapper pour l' exécution du contrôleur , une bibliothèque populaire pour développer des contrôleurs (qui, à son tour, est un wrapper pour le client-go ), un générateur de code + un cadre pour écrire des tests E2E.
- Operator Lifecycle Manager - un cadre de gestion des opérateurs existants; résout les situations lorsque l'opérateur passe en mode zombie ou qu'une nouvelle version est déployée.
- Comptage de l'opérateur - comme son nom l'indique, il collecte des données sur le travail de l'opérateur et peut également générer des rapports en fonction de ceux-ci.
Créer un nouveau projet
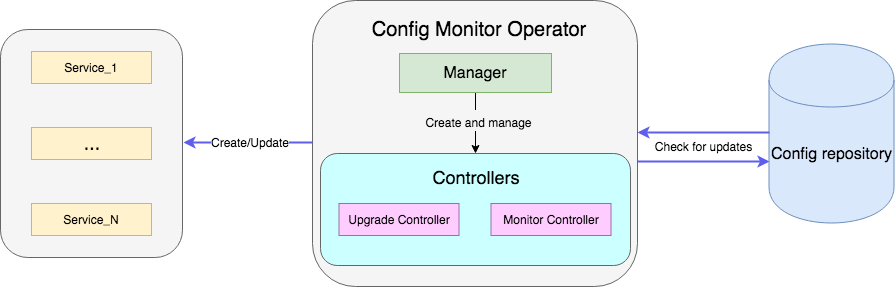
Un exemple est un opérateur qui surveille un fichier avec des configurations dans le référentiel et, une fois mis à jour, redémarre le déploiement du service avec de nouvelles configurations. L'exemple de code complet est disponible ici .
Créez un projet avec un nouvel opérateur:
operator-sdk new config-monitor
Le générateur de code créera du code pour l'opérateur travaillant dans l' espace de noms alloué. Cette approche est préférable à l'accès à l'ensemble du cluster, car en cas d'erreur les problèmes seront isolés dans le même espace de noms. L'opérateur à l' cluster-wide peut être généré en ajoutant --cluster-scoped . Les répertoires suivants seront situés à l'intérieur du projet créé:
- cmd - contient le
main package , dans lequel Manager initialisé et lancé; - deploy - contient les instructions de l'opérateur, du CRD et des objets nécessaires à la configuration de l'opérateur RBAC;
- pkg - voici notre code principal pour les nouveaux objets et contrôleurs.
Il n'y a qu'un seul fichier cmd/manager/main.go dans cmd/manager/main.go .
Extrait de code // Become the leader before proceeding err = leader.Become(ctx, "config-monitor-lock") if err != nil { log.Error(err, "") os.Exit(1) } // Create a new Cmd to provide shared dependencies and start components mgr, err := manager.New(cfg, manager.Options{ Namespace: namespace, MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort), }) ... // Setup Scheme for all resources if err := apis.AddToScheme(mgr.GetScheme()); err != nil { log.Error(err, "") os.Exit(1) } // Setup all Controllers if err := controller.AddToManager(mgr); err != nil { log.Error(err, "") os.Exit(1) } ... // Start the Cmd if err := mgr.Start(signals.SetupSignalHandler()); err != nil { log.Error(err, "Manager exited non-zero") os.Exit(1) }
Dans la première ligne: err = leader.Become(ctx, "config-monitor-lock") - un leader est sélectionné. Dans la plupart des scénarios, une seule instance active d'une instruction sur l'espace de noms / cluster est nécessaire. Par défaut, le SDK opérateur utilise la stratégie Leader pour la vie - la première instance lancée de l'opérateur restera leader jusqu'à ce qu'elle soit supprimée du cluster.
Une fois que cette instance d'opérateur a été nommée leader, un nouveau Manager est initialisé - mgr, err := manager.New(...) . Ses responsabilités incluent:
err := apis.AddToScheme(mgr.GetScheme()) - enregistrement de nouveaux schémas de ressources;err := controller.AddToManager(mgr) - enregistrement des contrôleurs;err := mgr.Start(signals.SetupSignalHandler()) - lance et contrôle les contrôleurs.
Pour le moment, nous n'avons ni nouvelles ressources, ni contrôleurs pour l'enregistrement. Vous pouvez ajouter une nouvelle ressource à l'aide de la commande:
operator-sdk add api --api-version=services.example.com/v1alpha1 --kind=MonitoredService
Cette commande ajoutera la définition du schéma de ressource MonitoredService au répertoire pkg/apis , ainsi que yaml avec la définition CRD dans deploy/crds . De tous les fichiers générés, vous devez modifier manuellement uniquement la définition de schéma dans monitoredservice_types.go . Le type MonitoredServiceSpec définit l'état souhaité de la ressource: ce que l'utilisateur spécifie dans yaml avec la définition de la ressource. Dans le contexte de notre opérateur, le champ Size détermine le nombre souhaité de répliques, ConfigRepo indique d'où les ConfigRepo actuelles peuvent être extraites. MonitoredServiceStatus détermine l'état observé de la ressource, par exemple, il stocke les noms des pods appartenant à cette ressource et les spec actuels.
Après avoir modifié le schéma, vous devez exécuter la commande:
operator-sdk generate k8s
Il mettra à jour la définition de CRD dans deploy/crds .
Créons maintenant la partie principale de notre opérateur, le contrôleur:
operator-sdk add controller --api-version=services.example.com/v1alpha1 --kind=Monitor
Le fichier monitor_controller.go apparaîtra dans le monitor_controller.go pkg/controller , dans lequel nous ajoutons la logique dont nous avons besoin.
Développement du contrôleur
Le contrôleur est l'unité de travail principale de l'opérateur. Dans notre cas, il existe deux contrôleurs:
- Contrôler le contrôleur surveille les changements de configuration du service;
- Le contrôleur de mise à niveau met à jour le service et le maintient dans l'état souhaité.
À sa base, le contrôleur est une boucle de contrôle, il surveille la file d'attente avec les événements auxquels il est abonné et les traite:
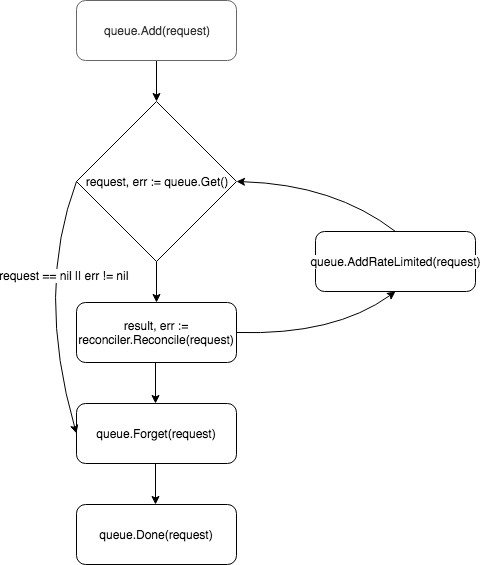
Un nouveau contrôleur est créé et enregistré par le gestionnaire dans la méthode add :
c, err := controller.New("monitor-controller", mgr, controller.Options{Reconciler: r})
En utilisant la méthode Watch , nous l'abonnons aux événements concernant la création d'une nouvelle ressource ou la mise à jour des Spec d'une ressource MonitoredService existante:
err = c.Watch(&source.Kind{Type: &servicesv1alpha1.MonitoredService{}}, &handler.EnqueueRequestForObject{}, common.CreateOrUpdateSpecPredicate)
Le type d'événement peut être configuré à l'aide des paramètres src et predicates . src accepte les objets de type Source .
Informer - interroge périodiquement l' apiserver pour les événements qui correspondent au filtre, s'il existe un tel événement, le place dans la file d'attente du contrôleur. Dans l' controller-runtime il s'agit d'un wrapper sur le SharedIndexInformer de client-go .Kind est également un wrapper sur SharedIndexInformer , mais, contrairement à Informer , il crée indépendamment une instance d'indicateur basée sur les paramètres passés (schéma de la ressource surveillée).Channel - accepte l'événement chan event.GenericEvent comme paramètre, les événements qui le traversent sont placés dans la file d'attente du contrôleur.
redicates attend des objets qui satisfont l'interface Predicate . En fait, il s'agit d'un filtre supplémentaire pour les événements, par exemple, lorsque vous filtrez UpdateEvent vous pouvez voir exactement quelles modifications ont été apportées à la spec ressource.
Lorsqu'un événement arrive, un EventHandler accepte - le deuxième argument de la méthode Watch - qui encapsule l'événement dans le format de requête attendu par le Reconciler :
EnqueueRequestForObject - crée une demande avec le nom et l'espace de noms de l'objet qui a provoqué l'événement;EnqueueRequestForOwner - crée une demande avec les données du parent de l'objet. Cela est nécessaire, par exemple, si le Pod contrôlé par les ressources Pod été supprimé et que vous devez commencer son remplacement;EnqueueRequestsFromMapFunc - prend en paramètre la fonction de map qui reçoit un événement (enveloppé dans MapObject ) et renvoie une liste de demandes. Un exemple lorsque ce gestionnaire est nécessaire - il y a un temporisateur, pour chaque tick dont vous devez extraire de nouvelles configurations pour tous les services disponibles.
Les demandes sont placées dans la file d'attente du contrôleur, et l'un des travailleurs (par défaut, le contrôleur en a une) extrait l'événement de la file d'attente et le transmet à Reconciler .
Reconciler implémente une seule méthode - Reconcile , qui contient la logique de base du traitement des événements:
méthode de réconciliation func (r *ReconcileMonitor) Reconcile(request reconcile.Request) (reconcile.Result, error) { reqLogger := log.WithValues("Request.Namespace", request.Namespace, "Request.Name", request.Name) reqLogger.Info("Checking updates in repo for MonitoredService") // fetch the Monitor instance instance := &servicesv1alpha1.MonitoredService{} err := r.client.Get(context.Background(), request.NamespacedName, instance) if err != nil { if errors.IsNotFound(err) { // Request object not found, could have been deleted after reconcile request. // Owned objects are automatically garbage collected. For additional cleanup logic use finalizers. // Return and don't requeue return reconcile.Result{}, nil } // Error reading the object - requeue the request. return reconcile.Result{}, err } // check if service's config was updated // if it was, send event to upgrade controller if podSpec, ok := r.isServiceConfigUpdated(instance); ok { // Update instance Spec instance.Status.PodSpec = *podSpec instance.Status.ConfigChanged = true err = r.client.Status().Update(context.Background(), instance) if err != nil { reqLogger.Error(err, "Failed to update service status", "Service.Namespace", instance.Namespace, "Service.Name", instance.Name) return reconcile.Result{}, err } r.eventsChan <- event.GenericEvent{Meta: &servicesv1alpha1.MonitoredService{}, Object: instance} } return reconcile.Result{}, nil }
La méthode accepte un objet Request avec le champ NamespacedName , par lequel la ressource peut être extraite du cache: r.client.Get(context.TODO(), request.NamespacedName, instance) . Dans l'exemple, une demande est ConfigRepo au fichier avec la configuration de service référencée par le champ ConfigRepo dans la spec ressource. Si la configuration est mise à jour, un nouvel événement du type GenericEvent est GenericEvent et envoyé au canal GenericEvent le contrôleur de Upgrade à niveau.
Après avoir traité la demande, Reconcile renvoie un objet de type Result et error . Si le champ Result est Requeue: true ou error != nil , le contrôleur renverra la demande dans la file d'attente à l'aide de la méthode queue.AddRateLimited . La demande sera renvoyée dans la file d'attente avec un délai, qui est déterminé par RateLimiter . Par défaut, ItemExponentialFailureRateLimiter utilisé, ce qui augmente le temps de retard de façon exponentielle avec une augmentation du nombre de «retours» de requêtes. Si le champ Requeue pas défini et qu'aucune erreur ne s'est produite lors du traitement de la demande, le contrôleur appellera la méthode Queue.Forget , qui supprimera la demande du cache de RateLimiter (réinitialisant ainsi le nombre de retours). À la fin du traitement de la demande, le contrôleur le supprime de la file d'attente à l'aide de la méthode Queue.Done .
Lancement de l'opérateur
Les composants de l'opérateur ont été décrits ci-dessus et une question demeure: comment le démarrer. Vous devez d'abord vous assurer que toutes les ressources nécessaires sont installées (pour les tests locaux, je recommande la configuration de minikube ):
# Setup Service Account kubectl create -f deploy/service_account.yaml # Setup RBAC kubectl create -f deploy/role.yaml kubectl create -f deploy/role_binding.yaml # Setup the CRD kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_crd.yaml # Setup custom resource kubectl create -f deploy/crds/services_v1alpha1_monitoredservice_cr.yaml
Une fois les conditions préalables remplies, il existe deux méthodes simples pour exécuter l'instruction à des fins de test. Le plus simple est de le démarrer en dehors du cluster à l'aide de la commande:
operator-sdk up local --namespace=default
La deuxième façon consiste à déployer l'opérateur dans le cluster. Vous devez d'abord créer une image Docker avec l'opérateur:
operator-sdk build config-monitor-operator:latest
Dans le fichier deploy/operator.yaml , remplacez REPLACE_IMAGE par config-monitor-operator:latest :
sed -i "" 's|REPLACE_IMAGE|config-monitor-operator:latest|g' deploy/operator.yaml
Créer un déploiement avec instruction:
kubectl create -f deploy/operator.yaml
Maintenant, dans la liste des Pod sur le cluster devrait apparaître Pod avec un service de test, et dans le deuxième cas - un autre avec un opérateur.
Au lieu d'une conclusion ou des meilleures pratiques
Les problèmes clés du développement des opérateurs pour le moment sont la faible documentation des outils et le manque de bonnes pratiques établies. Lorsqu'un nouveau développeur commence à développer un opérateur, il n'a nulle part où regarder pratiquement des exemples de mise en œuvre d'une exigence particulière, donc les erreurs sont inévitables. Voici quelques leçons que nous avons tirées de nos erreurs:
- S'il y a deux applications liées, vous devez éviter de vouloir les combiner avec un seul opérateur. Sinon, le principe des services de couplage lâche est violé.
- Vous devez vous rappeler de la séparation des préoccupations: vous ne devriez pas essayer d'implémenter toute la logique dans un seul contrôleur. Par exemple, il vaut la peine d'étendre les fonctions de surveillance des configurations et de création / mise à jour d'une ressource.
- Le blocage des appels doit être évité dans la méthode
Reconcile . Par exemple, vous pouvez extraire des configurations depuis une source externe, mais si l'opération est plus longue, créez un goroutine pour cela et renvoyez la demande à la file d'attente, en indiquant dans la réponse Requeue: true .
Dans les commentaires, il serait intéressant de connaître votre expérience dans le développement d'opérateurs. Et dans la partie suivante, nous parlerons des tests des opérateurs.