Le traitement du langage naturel n'est désormais plus utilisé que dans des secteurs très conservateurs. Dans la plupart des solutions technologiques, la reconnaissance et le traitement des langues «humaines» sont introduits depuis longtemps: c'est pourquoi l'IVR habituel avec des options de réponse codées en dur devient progressivement une chose du passé, les chatbots commencent à communiquer de manière plus adéquate sans la participation d'un opérateur en direct, les filtres de courrier fonctionnent avec un bang, etc. Comment est la reconnaissance de la parole enregistrée, c'est-à-dire du texte? Ou plutôt, quelle sera la base des techniques modernes de reconnaissance et de traitement? Notre traduction adaptée d'aujourd'hui répond bien à cela - sous la coupe, vous trouverez un longride qui comblera les lacunes sur les bases de la PNL. Bonne lecture!
Qu'est-ce que le traitement du langage naturel?
Traitement du langage naturel (ci-après - PNL) - le traitement du langage naturel est une sous-section de l'informatique et de l'IA consacrée à la façon dont les ordinateurs analysent les langues (humaines) naturelles. La PNL permet l'utilisation d'algorithmes d'apprentissage automatique pour le texte et la parole.
Par exemple, nous pouvons utiliser la PNL pour créer des systèmes tels que la reconnaissance vocale, la généralisation de documents, la traduction automatique, la détection de spam, la reconnaissance d'entités nommées, les réponses aux questions, la saisie automatique, la saisie de texte prédictive, etc.
Aujourd'hui, beaucoup d'entre nous ont des smartphones de reconnaissance vocale - ils utilisent la PNL pour comprendre notre discours. De plus, de nombreuses personnes utilisent des ordinateurs portables avec reconnaissance vocale intégrée dans le système d'exploitation.
Des exemples
Cortana
Windows dispose d'un assistant virtuel Cortana qui reconnaît la parole. Avec Cortana, vous pouvez créer des rappels, ouvrir des applications, envoyer des lettres, jouer à des jeux, connaître la météo, etc.
Siri
Siri est un assistant pour le système d'exploitation d'Apple: iOS, watchOS, macOS, HomePod et tvOS. De nombreuses fonctions fonctionnent également via la commande vocale: appeler / écrire à quelqu'un, envoyer un e-mail, régler une minuterie, prendre une photo, etc.
Gmail
Un service de messagerie bien connu peut détecter le spam afin qu'il n'entre pas dans la boîte de réception de votre boîte de réception.
Dialogflow
Une plateforme de Google qui vous permet de créer des bots NLP. Par exemple, vous pouvez créer un robot de commande de pizza
qui n'a pas besoin d'un système IVR à l'ancienne pour accepter votre commande .
Bibliothèque Python NLTK
NLTK (Natural Language Toolkit) est une plateforme leader pour la création de programmes NLP en Python. Il possède des interfaces faciles à utiliser pour de nombreux
corpus linguistiques , ainsi que des bibliothèques pour le traitement de texte pour la classification, la tokenisation, le
stemming , le
balisage , le filtrage et
le raisonnement sémantique . Eh bien, et ceci est un projet open source gratuit qui est développé avec l'aide de la communauté.
Nous utiliserons cet outil pour montrer les bases de la PNL. Pour tous les exemples suivants, je suppose que NLTK est déjà importé; cela peut être fait avec la
import nltkBases de la PNL pour le texte
Dans cet article, nous aborderons des sujets:
- Tokenisation par offres.
- Tokenisation par des mots.
- Lemmatisation et estampage du texte.
- Arrêtez les mots.
- Expressions régulières.
- Sac de mots .
- TF-IDF .
1. Tokenisation par offres
La tokenisation (parfois segmentation) des phrases est le processus de division d'une langue écrite en phrases composantes. L'idée semble assez simple. En anglais et dans d'autres langues, nous pouvons isoler une phrase chaque fois que nous trouvons un certain signe de ponctuation - un point.
Mais même en anglais, cette tâche n'est pas anodine, car le point est également utilisé dans les abréviations. Le tableau des abréviations peut grandement aider lors du traitement de texte pour éviter de placer les limites de phrase mal placées. Dans la plupart des cas, les bibliothèques sont utilisées pour cela, vous n'avez donc pas vraiment à vous soucier des détails d'implémentation.
Un exemple:Prenez un court texte sur le jeu de plateau de backgammon:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
Pour effectuer une tokenisation des offres à l'aide de NLTK, vous pouvez utiliser la méthode
nltk.sent_tokenize | text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice." |
| sentences = nltk.sent_tokenize(text) |
| for sentence in sentences: |
| print(sentence) |
| print() |
A la sortie, nous obtenons 3 phrases distinctes:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
2. Tokenisation selon les mots
La tokenisation (parfois segmentation) en fonction des mots est le processus de division des phrases en mots composants. En anglais et dans de nombreuses autres langues qui utilisent l'une ou l'autre version de l'alphabet latin, un espace est un bon séparateur de mots.
Cependant, des problèmes peuvent survenir si nous n'utilisons qu'un espace - en anglais, les noms composés sont écrits différemment et parfois séparés par des espaces. Et ici, les bibliothèques nous aident à nouveau.
Un exemple:Prenons les phrases de l'exemple précédent et appliquons-
nltk.word_tokenize méthode
nltk.word_tokenize | for sentence in sentences: |
| words = nltk.word_tokenize(sentence) |
| print(words) |
| print() |
Conclusion:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.'] ['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.'] ['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.']
3. Lemmatisation et estampillage du texte
Habituellement, les textes contiennent différentes formes grammaticales du même mot, et des mots à une racine peuvent également apparaître. La lemmatisation et la dérivation visent à rassembler toutes les formes de mots présentes dans une seule forme de vocabulaire normale.
Exemples:Apporter différentes formes de mots à un:
dog, dogs, dog's, dogs' => dog
La même chose, mais en référence à toute la phrase:
the boy's dogs are different sizes => the boy dog be differ size
La lemmatisation et la tige sont des cas particuliers de normalisation et diffèrent.
La racine est un processus heuristique grossier qui coupe «l'excès» de la racine des mots, ce qui entraîne souvent la perte de suffixes de construction de mots.
La lemmatisation est un processus plus subtil qui utilise le vocabulaire et l'analyse morphologique pour finalement amener le mot à sa forme canonique - le lemme.
La différence est que le stemmer (une implémentation spécifique de l'algorithme de stemming - commentaire du traducteur) fonctionne sans connaître le contexte et, par conséquent, ne comprend pas la différence entre des mots qui ont des significations différentes selon la partie du discours. Cependant, les Stemmers ont leurs propres avantages: ils sont plus faciles à mettre en œuvre et ils fonctionnent plus rapidement. De plus, une «précision» inférieure peut ne pas avoir d'importance dans certains cas.
Exemples:- Le mot bon est un lemme pour le mot meilleur. Stemmer ne verra pas cette connexion, car ici vous devez consulter le dictionnaire.
- Le jeu de mots est la forme de base du jeu de mots. Ici, à la fois la formation de racines et la lemmatisation se produiront.
- Le mot réunion peut être soit une forme normale d'un nom, soit une forme du verbe se rencontrer, selon le contexte. Contrairement à la racine, la lemmatisation essaiera de choisir le bon lemme en fonction du contexte.
Maintenant que nous savons quelle est la différence, regardons un exemple:
| from nltk.stem import PorterStemmer, WordNetLemmatizer |
| from nltk.corpus import wordnet |
| |
| def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos): |
| """ |
| Print the results of stemmind and lemmitization using the passed stemmer, lemmatizer, word and pos (part of speech) |
| """ |
| print("Stemmer:", stemmer.stem(word)) |
| print("Lemmatizer:", lemmatizer.lemmatize(word, pos)) |
| print() |
| |
| lemmatizer = WordNetLemmatizer() |
| stemmer = PorterStemmer() |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB) |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB) |
Conclusion:
Stemmer: seen Lemmatizer: see Stemmer: drove Lemmatizer: drive
4. Mots vides
Les mots vides sont des mots qui sont jetés hors du texte avant / après le traitement de texte. Lorsque nous appliquons l'apprentissage automatique aux textes, ces mots peuvent ajouter beaucoup de bruit, vous devez donc vous débarrasser des mots non pertinents.
Les mots vides sont généralement compris par des articles, des interjections, des unions, etc., qui ne portent pas de charge sémantique. Il faut comprendre qu'il n'y a pas de liste universelle de mots vides, tout dépend du cas particulier.
NLTK a une liste prédéfinie de mots vides. Avant la première utilisation, vous devrez le télécharger:
nltk.download(“stopwords”) . Après le téléchargement, vous pouvez importer le package des
stopwords et regarder les mots eux-mêmes:
| from nltk.corpus import stopwords |
| print(stopwords.words("english")) |
Conclusion:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
Considérez comment supprimer des mots vides d'une phrase:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [word for word in words if not word in stop_words] |
| print(without_stop_words) |
Conclusion:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
Si vous n'êtes pas familier avec les listes de compréhension, vous pouvez en savoir plus
ici . Voici une autre façon d'obtenir le même résultat:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [] |
| for word in words: |
| if word not in stop_words: |
| without_stop_words.append(word) |
| |
| print(without_stop_words) |
Cependant, n'oubliez pas que les compréhensions de liste sont plus rapides car elles sont optimisées - l'interpréteur révèle un modèle prédictif pendant la boucle.
Vous pouvez vous demander pourquoi nous avons converti la liste en
plusieurs . Un ensemble est un type de données abstrait qui peut stocker des valeurs uniques dans un ordre non défini. La recherche par ensemble est beaucoup plus rapide que la recherche dans une liste. Pour un petit nombre de mots, cela n'a pas d'importance, mais si nous parlons d'un grand nombre de mots, alors il est strictement recommandé d'utiliser des ensembles. Si vous voulez en savoir un peu plus sur le temps nécessaire pour effectuer diverses opérations, regardez
cette merveilleuse feuille de triche .
5. Expressions régulières.
Une expression régulière (regex, regexp, regex) est une séquence de caractères qui définit un modèle de recherche. Par exemple:
- . - tout caractère sauf le saut de ligne;
- \ w est un mot;
- \ d - un chiffre;
- \ s - un espace;
- \ W est un NON-Word;
- \ D - un non-chiffre;
- \ S - un non-espace;
- [abc] - trouve l'un des caractères spécifiés correspondant à l'un des a, b ou c;
- [^ abc] - trouve n'importe quel caractère sauf ceux spécifiés;
- [ag] - Recherche un personnage dans la plage de a à g.
Extrait de la
documentation Python :
Les expressions régulières utilisent la barre oblique inverse (\) pour indiquer des formes spéciales ou pour autoriser l'utilisation de caractères spéciaux. Cela contredit l'utilisation de la barre oblique inverse dans Python: par exemple, pour désigner littéralement la barre oblique inverse, vous devez écrire '\\\\' comme modèle de recherche, car l'expression régulière doit ressembler à \\ , où chaque barre oblique inverse doit être échappée.
La solution consiste à utiliser la notation de chaîne brute pour les modèles de recherche; les barres obliques inverses ne seront pas spécialement traitées si elles sont utilisées avec le préfixe 'r' . Ainsi, r”\n” est une chaîne à deux caractères ('\' 'n') et “\n” est une chaîne à un caractère (saut de ligne).
Nous pouvons utiliser des habitués pour filtrer davantage notre texte. Par exemple, vous pouvez supprimer tous les caractères qui ne sont pas des mots. Dans de nombreux cas, la ponctuation n'est pas nécessaire et est facile à retirer à l'aide d'habitués.
Le module
re en Python représente les opérations d'expression régulière. Nous pouvons utiliser la fonction
re.sub pour remplacer tout ce qui correspond au modèle de recherche par la chaîne spécifiée. Vous pouvez donc remplacer tous les non-mots par des espaces:
| import re |
| sentence = "The development of snowboarding was inspired by skateboarding, sledding, surfing and skiing." |
| pattern = r"[^\w]" |
| print(re.sub(pattern, " ", sentence)) |
Conclusion:
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing '
Les habitués sont un outil puissant qui peut être utilisé pour créer des motifs beaucoup plus complexes. Si vous voulez en savoir plus sur les expressions régulières, je peux recommander ces 2 applications Web:
regex ,
regex101 .
6. Sac de mots
Les algorithmes d'apprentissage automatique ne peuvent pas fonctionner directement avec du texte brut, vous devez donc convertir le texte en ensembles de nombres (vecteurs). C'est ce qu'on appelle l'
extraction de fonctionnalités .
Un sac de mots est une technique d'extraction de fonctionnalités simple et populaire utilisée lorsque vous travaillez avec du texte. Il décrit les occurrences de chaque mot dans le texte.
Pour utiliser le modèle, nous avons besoin de:
- Définissez un dictionnaire de mots connus (jetons).
- Choisissez le degré de présence de mots célèbres.
Toute information sur l'ordre ou la structure des mots est ignorée. C'est pourquoi on l'appelle un SAC de mots. Ce modèle essaie de comprendre si un mot familier apparaît dans un document, mais ne sait pas exactement où il se produit.
L'intuition suggère que
des documents similaires ont
un contenu similaire . De plus, grâce au contenu, nous pouvons apprendre quelque chose sur la signification du document.
Un exemple:Considérez les étapes pour créer ce modèle. Nous utilisons seulement 4 phrases pour comprendre comment fonctionne le modèle. Dans la vraie vie, vous rencontrerez plus de données.
1. Télécharger les données
Imaginez que ce sont nos données et nous voulons les charger sous forme de tableau:
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Pour ce faire, il suffit de lire le fichier et de le diviser par ligne:
| with open("simple movie reviews.txt", "r") as file: |
| documents = file.read().splitlines() |
| |
| print(documents) |
Conclusion:
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.']
2. Définissez un dictionnaire
Nous collecterons tous les mots uniques de 4 phrases chargées, en ignorant la casse, la ponctuation et les jetons à un caractère. Ce sera notre dictionnaire (mots célèbres).
Pour créer un dictionnaire, vous pouvez utiliser la classe
CountVectorizer de la bibliothèque sklearn. Passez à l'étape suivante.
3. Créez des vecteurs de documents
Ensuite, nous devons évaluer les mots du document. À cette étape, notre objectif est de transformer le texte brut en un ensemble de chiffres. Après cela, nous utilisons ces ensembles comme entrée dans le modèle d'apprentissage automatique. La méthode de notation la plus simple consiste à noter la présence de mots, c'est-à-dire mettre 1 s'il y a un mot et 0 s'il est absent.
Nous pouvons maintenant créer un sac de mots en utilisant la classe CountVectorizer susmentionnée.
| # Import the libraries we need |
| from sklearn.feature_extraction.text import CountVectorizer |
| import pandas as pd |
| |
| # Step 2. Design the Vocabulary |
| # The default token pattern removes tokens of a single character. That's why we don't have the "I" and "s" tokens in the output |
| count_vectorizer = CountVectorizer() |
| |
| # Step 3. Create the Bag-of-Words Model |
| bag_of_words = count_vectorizer.fit_transform(documents) |
| |
| # Show the Bag-of-Words Model as a pandas DataFrame |
| feature_names = count_vectorizer.get_feature_names() |
| pd.DataFrame(bag_of_words.toarray(), columns = feature_names) |
Conclusion:
Ce sont nos suggestions. Nous voyons maintenant comment fonctionne le modèle du «sac de mots».
Quelques mots sur le sac de mots
La complexité de ce modèle est de savoir comment déterminer le dictionnaire et comment compter l'occurrence des mots.
Lorsque la taille du dictionnaire augmente, le vecteur du document augmente également. Dans l'exemple ci-dessus, la longueur du vecteur est égale au nombre de mots connus.
Dans certains cas, nous pouvons avoir une quantité incroyablement importante de données, puis le vecteur peut être composé de milliers ou de millions d'éléments. De plus, chaque document ne peut contenir qu'une petite partie des mots du dictionnaire.
Par conséquent, il y aura de nombreux zéros dans la représentation vectorielle. Les vecteurs avec de nombreux zéros sont appelés vecteurs clairsemés, ils nécessitent plus de mémoire et de ressources de calcul.
Cependant, nous pouvons réduire le nombre de mots connus lorsque nous utilisons ce modèle pour réduire les demandes de ressources informatiques. Pour ce faire, vous pouvez utiliser les mêmes techniques que nous avons déjà envisagées avant de créer un sac de mots:
- ignorer la casse des mots;
- ignorer la ponctuation;
- éjection de mots vides;
- réduction des mots à leurs formes de base (lemmatisation et dérivation);
- correction de mots mal orthographiés.
Une autre façon, plus compliquée, de créer un dictionnaire consiste à utiliser des mots groupés. Cela redimensionnera le dictionnaire et donnera au sac de mots plus de détails sur le document. Cette approche est appelée «
N-gramme ».
N-gramme est une séquence de toutes les entités (mots, lettres, chiffres, nombres, etc.). Dans le contexte des corps linguistiques, le N-gramme est généralement compris comme une séquence de mots. Un unigramme est un mot, un bigramme est une séquence de deux mots, un trigramme est trois mots, et ainsi de suite. Le nombre N indique combien de mots groupés sont inclus dans le N-gramme. Tous les N-grammes possibles ne tombent pas dans le modèle, mais seulement ceux qui apparaissent dans le boîtier.
Un exemple:Considérez la phrase suivante:
The office building is open today
Voici ses bigrammes:
- le bureau
- immeuble de bureaux
- le bâtiment est
- est ouvert
- ouvert aujourd'hui
Comme vous pouvez le voir, un sac de bigrammes est une approche plus efficace qu'un sac de mots.
Évaluation (notation) des motsLorsqu'un dictionnaire est créé, la présence de mots doit être évaluée. Nous avons déjà envisagé une approche binaire simple (1 - il y a un mot, 0 - il n'y a pas de mot).
Il existe d'autres méthodes:
- Quantité. Il est calculé combien de fois chaque mot apparaît dans le document.
- La fréquence Il est calculé la fréquence à laquelle chaque mot apparaît dans le texte (par rapport au nombre total de mots).
7. TF-IDF
La notation de fréquence a un problème: les mots avec la fréquence la plus élevée ont respectivement la note la plus élevée. Dans ces mots, il peut y avoir moins de
gain d'information pour le modèle que dans les mots moins fréquents. Une façon de rectifier la situation est d'abaisser le score des mots, que l'on retrouve souvent
dans tous les documents similaires . C'est ce qu'on appelle
TF-IDF .
TF-IDF (abréviation de terme terme - fréquence inverse du document) est une mesure statistique permettant d'évaluer l'importance d'un mot dans un document faisant partie d'une collection ou d'un corpus.
La notation par TF-IDF augmente proportionnellement à la fréquence d'apparition d'un mot dans un document, mais cela est compensé par le nombre de documents contenant ce mot.
Formule de notation du mot X dans le document Y:
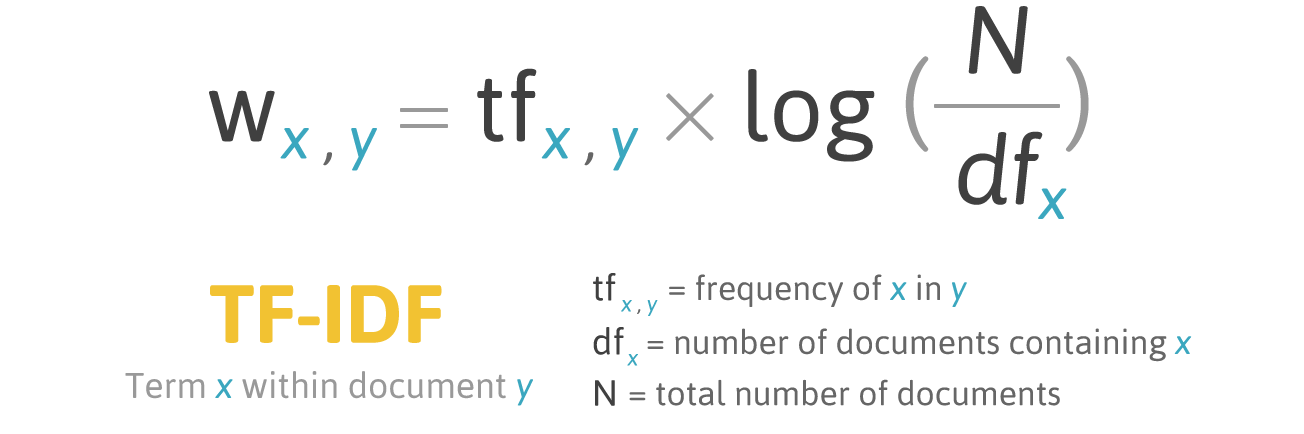 Formule TF-IDF. Source: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
Formule TF-IDF. Source: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlTF (terme fréquence) est le rapport entre le nombre d'occurrences d'un mot et le nombre total de mots dans un document.
IDF (fréquence de document inverse) est l'inverse de la fréquence à laquelle un mot apparaît dans les documents de collection.
Par conséquent, TF-IDF pour le terme
terme peut être calculé comme suit:
Un exemple:Vous pouvez utiliser la classe
TfidfVectorizer de la bibliothèque sklearn pour calculer TF-IDF. Faisons cela avec les mêmes messages que nous avons utilisés dans l'exemple du sac de mots.
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Code:
| from sklearn.feature_extraction.text import TfidfVectorizer |
| import pandas as pd |
| |
| tfidf_vectorizer = TfidfVectorizer() |
| values = tfidf_vectorizer.fit_transform(documents) |
| |
| # Show the Model as a pandas DataFrame |
| feature_names = tfidf_vectorizer.get_feature_names() |
| pd.DataFrame(values.toarray(), columns = feature_names) |
Conclusion:
Conclusion
Cet article a couvert les bases de la PNL pour le texte, à savoir:
- La PNL permet l'utilisation d'algorithmes d'apprentissage automatique pour le texte et la parole;
- NLTK (Natural Language Toolkit) - une plate-forme leader pour la création de programmes NLP en Python;
- la tokenisation des propositions est le processus de division d'une langue écrite en phrases composantes;
- la tokenisation des mots est le processus de division des phrases en mots composants;
- La lemmatisation et la dérivation visent à rassembler toutes les formes de mots rencontrées dans une seule forme de vocabulaire normale;
- les mots vides sont des mots qui sont rejetés du texte avant / après le traitement de texte;
- regex (regex, regexp, regex) est une séquence de caractères qui définit un modèle de recherche;
- un sac de mots est une technique d'extraction de fonctionnalités populaire et simple utilisée lorsque vous travaillez avec du texte. Il décrit les occurrences de chaque mot dans le texte.
Super! Maintenant que vous connaissez les bases de l'extraction de fonctionnalités, vous pouvez utiliser les fonctionnalités comme entrées pour les algorithmes d'apprentissage automatique.
Si vous voulez voir tous les concepts décrits dans un grand exemple, alors
vous êtes ici .