
Dans nos projets, nous utilisons une architecture de microservices. Si des goulots d'étranglement se produisent, une grande partie du temps est consacrée à la surveillance et à l'analyse des journaux. Lors de la journalisation des temporisations des opérations individuelles dans un fichier journal, il est généralement difficile de comprendre ce qui a conduit à l'invocation de ces opérations, de suivre la séquence d'actions ou le décalage temporel d'une opération par rapport à une autre dans différents services.
Pour minimiser le travail manuel, nous avons décidé d'utiliser l'un des outils de traçage. Comment et pour quoi il est possible d'utiliser le traçage et comment nous l'avons fait, et nous discuterons de cet article.
Quels problèmes peuvent être résolus avec trace
- Trouvez les goulots d'étranglement des performances à la fois dans un seul service et dans l'arborescence d'exécution complète entre tous les services participants. Par exemple:
- De nombreux appels courts consécutifs entre services, par exemple, vers le géocodage ou vers une base de données.
- Longue attente pour l'entrée d'entrée, par exemple, le transfert de données sur un réseau ou la lecture à partir du disque.
- Analyse longue des données.
- Opérations longues nécessitant un processeur.
- Morceaux de code qui ne sont pas nécessaires pour obtenir le résultat final et peuvent être supprimés ou exécutés différés.
- Comprenez clairement dans quelle séquence ce qui est appelé et ce qui se passe lorsque l'opération est effectuée.
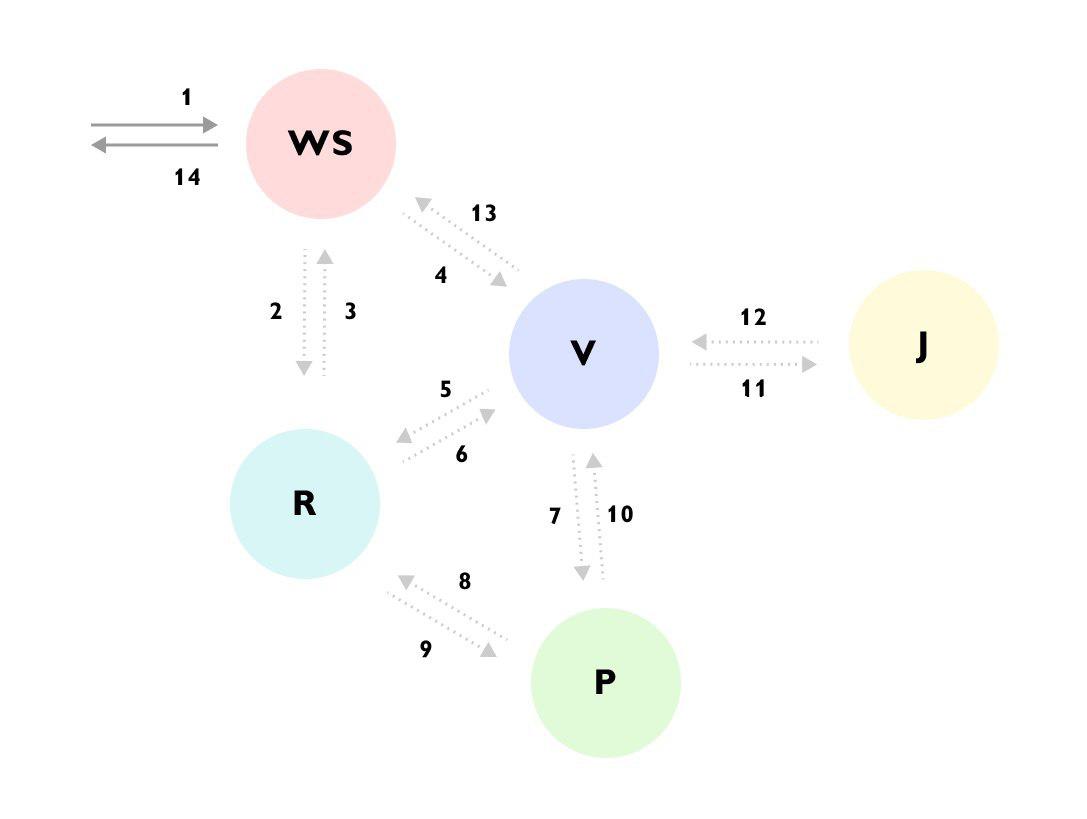
On peut voir que, par exemple, la demande est arrivée au service WS -> le service WS a complété les données via le service R -> puis a envoyé la demande au service V -> le service V a chargé beaucoup de données du service R -> est allé au service P -> le service P est reparti au service R -> service V a ignoré le résultat et est allé au service J -> et n'a ensuite renvoyé la réponse qu'au service WS, tout en continuant à calculer autre chose en arrière-plan.
Sans une telle trace ou documentation détaillée pour l'ensemble du processus, il est très difficile de comprendre ce qui se passe la première fois que vous regardez le code, et le code est dispersé entre différents services et caché derrière un tas de bacs et d'interfaces.
- Collecte d'informations sur l'arbre d'exécution pour une analyse en attente ultérieure. À chaque étape de l'exécution, vous pouvez ajouter des informations à la trace disponible à ce stade, puis déterminer quelles entrées ont conduit à un scénario similaire. Par exemple:
- ID utilisateur
- Les droits
- Type de méthode sélectionné
- Erreur de journal ou d'exécution
- Transformez les traces en un sous-ensemble de mesures et une analyse plus approfondie en tant que mesures.
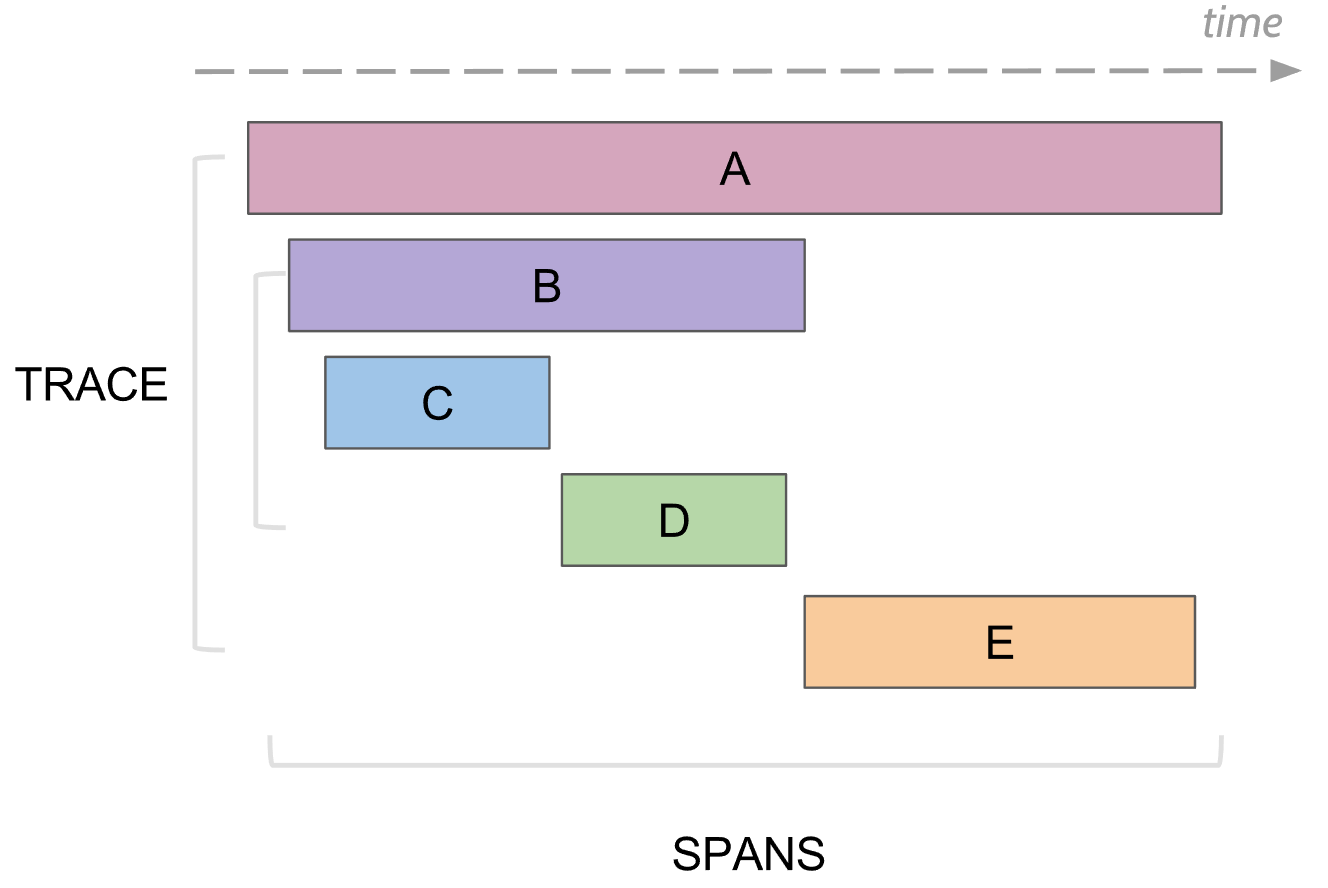
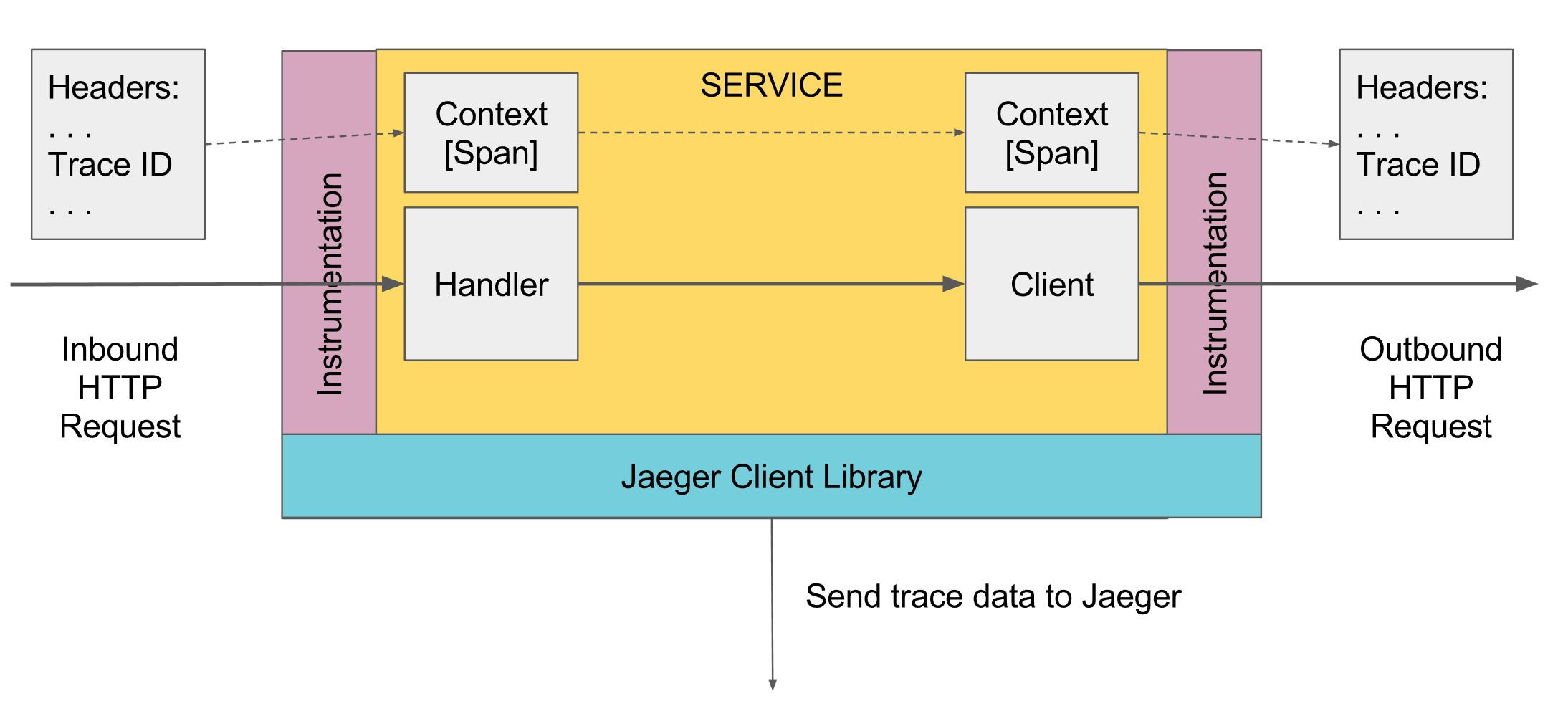
Que peut suivre la journalisation. Span
Dans le traçage, il y a le concept de span, c'est l'analogue d'un journal à la console. La durée a:
- Le nom, généralement le nom de la méthode exécutée
- Le nom du service dans lequel la plage a été générée
- Posséder un identifiant unique
- Certaines méta-informations sous forme de clé / valeur, qui lui ont été promises. Par exemple, les paramètres de la méthode ou la méthode s'est terminée avec une erreur ou non
- Les heures de début et de fin de cette période
- ID d'envergure parent
Chaque plage est envoyée au collecteur de plage pour être enregistrée dans la base de données pour une visualisation ultérieure dès qu'elle a terminé son exécution. À l'avenir, vous pouvez créer une arborescence de toutes les étendues en vous connectant par l'ID du parent. Dans l'analyse, vous pouvez trouver, par exemple, toutes les portées d'un service qui ont pris plus de temps. De plus, en allant à une plage spécifique, voir l'arbre entier au-dessus et en dessous de cette plage.
Opentracing, Jagger et comment nous l'avons implémenté pour nos projets
Il existe une norme
Opentracing générale qui décrit comment et ce qui doit être assemblé sans être lié à une implémentation spécifique dans n'importe quel langage. Par exemple, en Java, tout le travail avec les traces est effectué via l'API Opentracing générale, et en dessous, par exemple, Jaeger ou une implémentation par défaut vide qui ne fait rien peut être masquée.
Nous utilisons
Jaeger comme implémentation d'Opentracing. Il se compose de plusieurs composants:
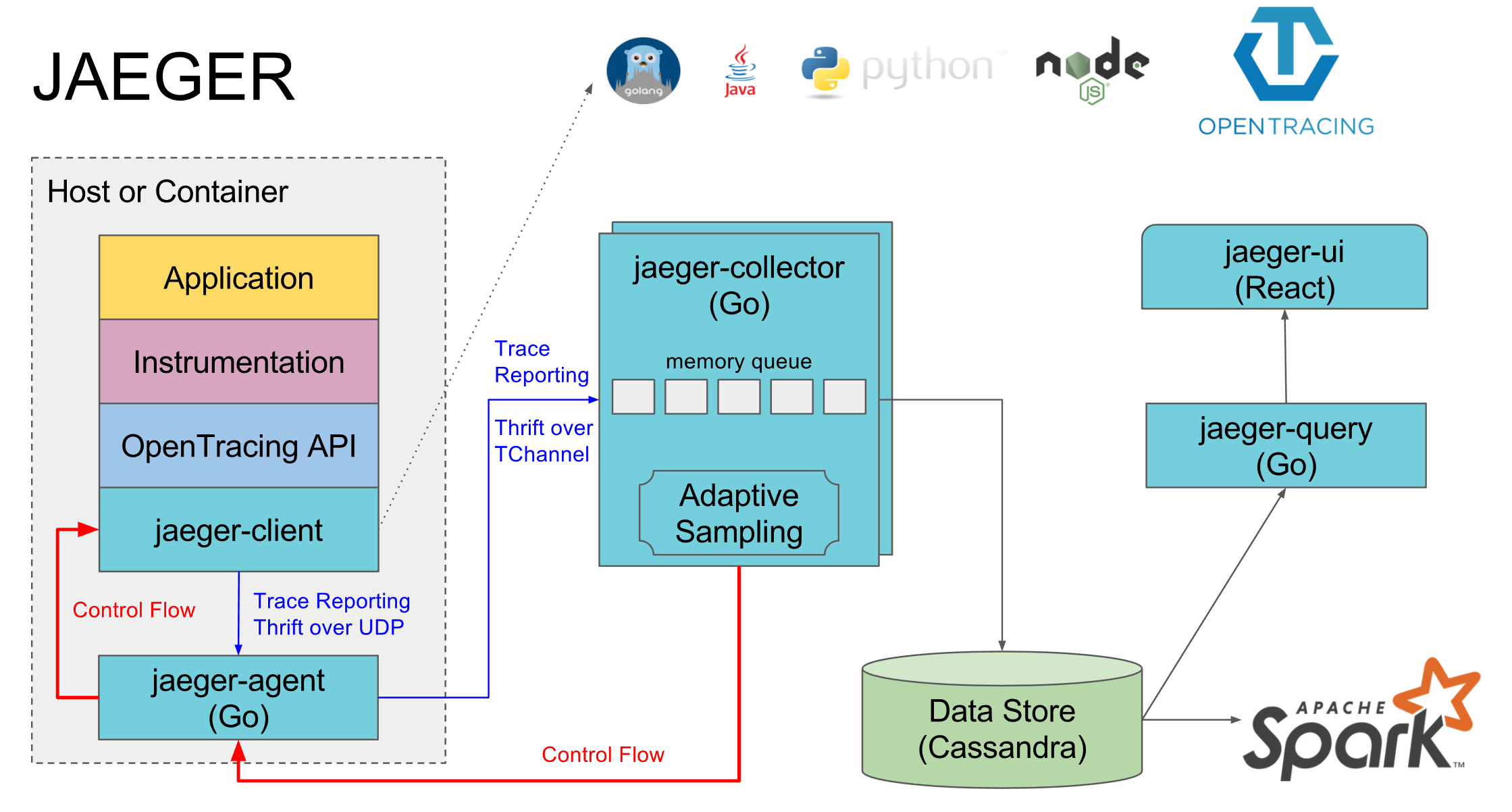
- Jaeger-agent est un agent local qui se trouve généralement sur chaque machine et les services y sont connectés sur le port local par défaut. S'il n'y a pas d'agent, les traces de tous les services sur cette machine sont généralement désactivées
- Jaeger-collector - tous les agents lui envoient des traces collectées, et il les place dans la base de données sélectionnée
- La base de données est leur cassandra préférée, mais nous utilisons elasticsearch, il existe des implémentations pour quelques autres bases de données et en mémoire une implémentation qui ne sauvegarde rien sur le disque
- Jaeger-query est un service qui va à la base de données et donne des traces déjà collectées pour analyse
- Jaeger-ui est une interface web pour rechercher et visualiser des traces, il va à jaeger-query
Un composant distinct est l'implémentation de jaeger opentracing pour des langues spécifiques, à travers lequel les portées sont envoyées à jaeger-agent.
La connexion de Jagger en Java revient à simuler l'interface io.opentracing.Tracer, après quoi toutes les traces qui le traversent s'envoleront vers l'agent réel.
Vous pouvez également connecter
opentracing-spring-cloud-starter et une implémentation de Jaeger
opentracing-spring-jaeger-cloud-starter qui configure le traçage automatique pour tout ce qui passe par ces composants, par exemple, les requêtes http aux contrôleurs, les requêtes de base de données via jdbc etc.
Journalisation du suivi en Java
Quelque part au niveau le plus élevé, la première étendue doit être créée, cela peut être fait automatiquement, par exemple, par le contrôleur de ressort lorsqu'une demande est reçue, ou manuellement s'il n'y en a pas. De plus, il est transmis via Scope ci-dessous. Si une méthode ci-dessous souhaite ajouter un Span, elle prend le activeSpan actuel de Scope, crée un nouveau Span et dit que son parent a reçu activeSpan, et rend le nouveau Span actif. Lorsque des services externes sont appelés, la plage active actuelle leur est transférée et ces services créent de nouvelles plages en référence à cette plage.
Tout le travail passe par l'instance Tracer, vous pouvez l'obtenir via le mécanisme DI ou GlobalTracer.get () en tant que variable globale si le mécanisme DI ne fonctionne pas. Par défaut, si le traceur n'a pas été initialisé, NoopTracer retournera ce qui ne fait rien.
En outre, la portée actuelle est obtenue à partir du traceur via ScopeManager, une nouvelle portée est créée à partir de la portée actuelle avec la liaison de la nouvelle portée, puis la portée créée est fermée, ce qui ferme la portée créée et remet la portée précédente à l'état actif. La portée est liée à un flux, donc lors de la programmation multi-thread, vous ne devez pas oublier de transférer la plage active vers un autre flux, pour une activation ultérieure de la portée d'un autre flux en référence à cette plage.
io.opentracing.Tracer tracer = ...;
Pour la programmation multithread, il existe également un TracedExecutorService et des wrappers similaires qui transfèrent automatiquement la plage actuelle au flux lors du lancement de tâches asynchrones:
private ExecutorService executor = new TracedExecutorService( Executors.newFixedThreadPool(10), GlobalTracer.get() );
Pour les requêtes http externes, il existe
TracingHttpClient HttpClient httpClient = new TracingHttpClientBuilder().build();
Les problèmes auxquels nous sommes confrontés
- Les beans et l'ID ne fonctionnent pas toujours si le traceur n'est pas utilisé dans un service ou un composant, alors Tracer Autowired peut ne pas fonctionner et vous devrez utiliser GlobalTracer.get ().
- Les annotations ne fonctionnent pas s'il ne s'agit pas d'un composant ou d'un service, ou si un appel de méthode provient d'une méthode voisine de la même classe. Vous devez être prudent, vérifier ce qui fonctionne et utiliser la création manuelle de la trace si @Traced ne fonctionne pas. Vous pouvez également visser un compilateur supplémentaire pour les annotations java, puis ils devraient fonctionner partout.
- Dans l'ancien ressort et la botte de printemps, la configuration automatique du nuage de printemps d'ouverture ne fonctionne pas en raison de bogues dans DI, alors si vous voulez que les traces dans les composants du ressort fonctionnent automatiquement, vous pouvez le faire par analogie avec github.com/opentracing-contrib/java-spring-jaeger/blob/ master / opentracing-spring-jaeger-starter / src / main / java / io / opentracing / contrib / java / spring / jaeger / starter / JaegerAutoConfiguration.java
- Essayer avec des ressources ne fonctionne pas en groovy, vous devez enfin utiliser try.
- Chaque service doit avoir son propre nom spring.application.name sous lequel les traces seront enregistrées. Qu'est-ce qu'un nom distinct à vendre et à tester, afin de ne pas les déranger ensemble.
- Si vous utilisez GlobalTracer et tomcat, tous les services exécutés dans ce tomcat ont un GlobalTracer, ils auront donc tous le même nom de service.
- Lors de l'ajout de traces à une méthode, vous devez vous assurer qu'elle n'est pas appelée plusieurs fois dans la boucle. Il est nécessaire d'ajouter une trace commune pour tous les appels, ce qui garantit la durée totale du travail. Sinon, une charge excessive sera créée.
- Une fois à jaeger-ui, ils ont fait trop de demandes pour un grand nombre de traces et comme ils n'ont pas attendu de réponse, ils l'ont fait à nouveau. En conséquence, jaeger-query a commencé à manger beaucoup de mémoire et à ralentir l'élastique. Aide au redémarrage de jaeger-query
Échantillonnage, stockage et visualisation des traces
Il existe trois types d'
échantillonnage de
traces :
- Const qui envoie et enregistre toutes les traces.
- Probabiliste qui filtre les traces avec une certaine probabilité donnée.
- Ratelimiting qui limite le nombre de traces par seconde. Vous pouvez configurer ces options sur le client, soit sur l'agent jaeger, soit dans le collecteur. Maintenant, nous avons const 1 dans la pile des évaluateurs, car il n'y a pas beaucoup de demandes, mais elles prennent beaucoup de temps. À l'avenir, si cela exerce une charge excessive sur le système, vous pouvez la limiter.
Si vous utilisez cassandra, par défaut, il stocke les traces en seulement deux jours. Nous utilisons
elasticsearch et les traces sont stockées pendant tout le temps et ne sont pas supprimées. Un index distinct est créé pour chaque jour, par exemple, jaeger-service-2019-03-04. À l'avenir, vous devrez configurer le nettoyage automatique des anciennes traces.
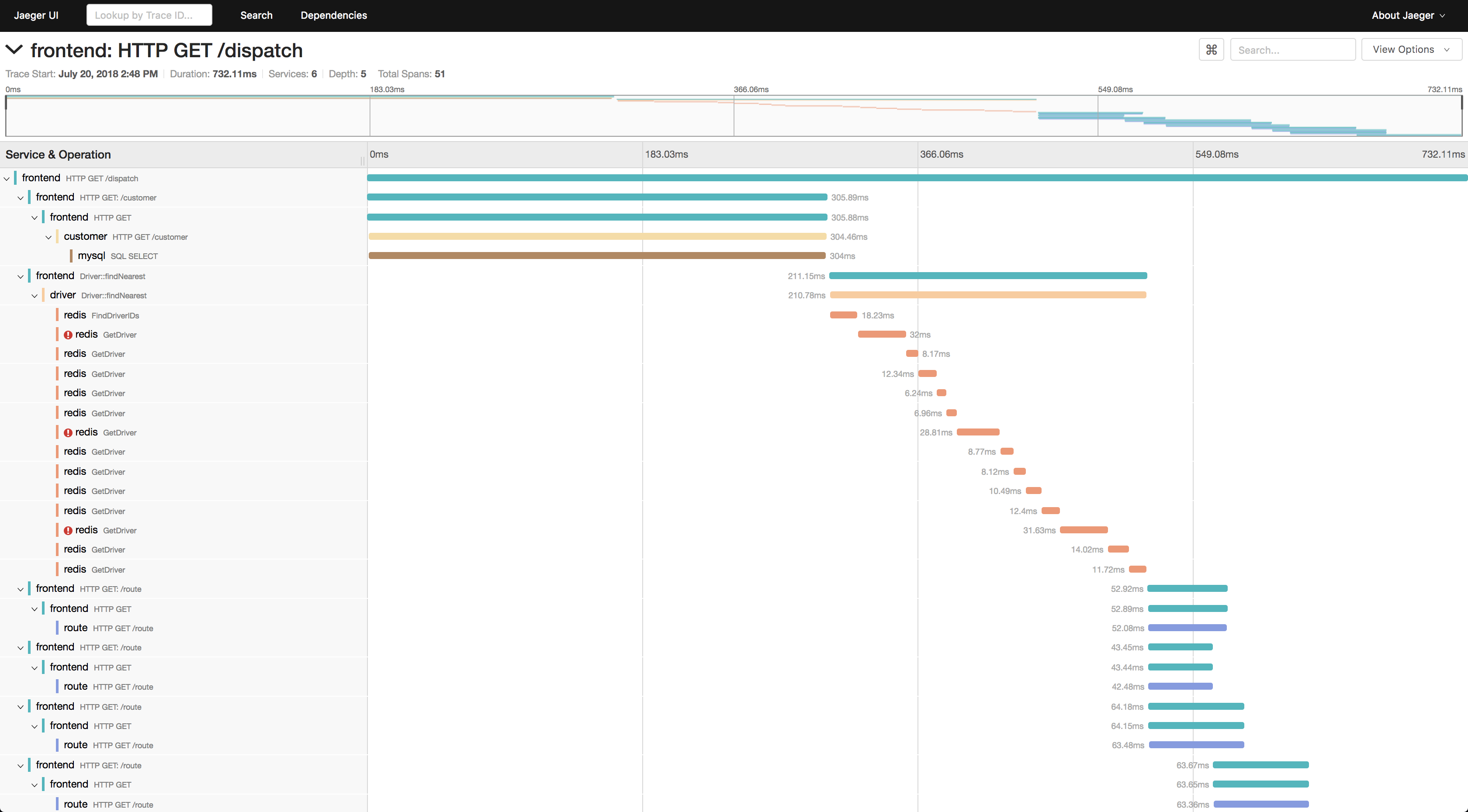
Pour regarder les cours dont vous avez besoin:
- Choisissez un service par lequel vous souhaitez filtrer les traces, par exemple tomcat7-default pour un service qui s'exécute sur une tomate et ne peut pas avoir de nom.
- Ensuite, sélectionnez l'opération, l'intervalle de temps et le temps de fonctionnement minimum, par exemple à partir de 10 secondes, pour ne prendre que de longues séries.
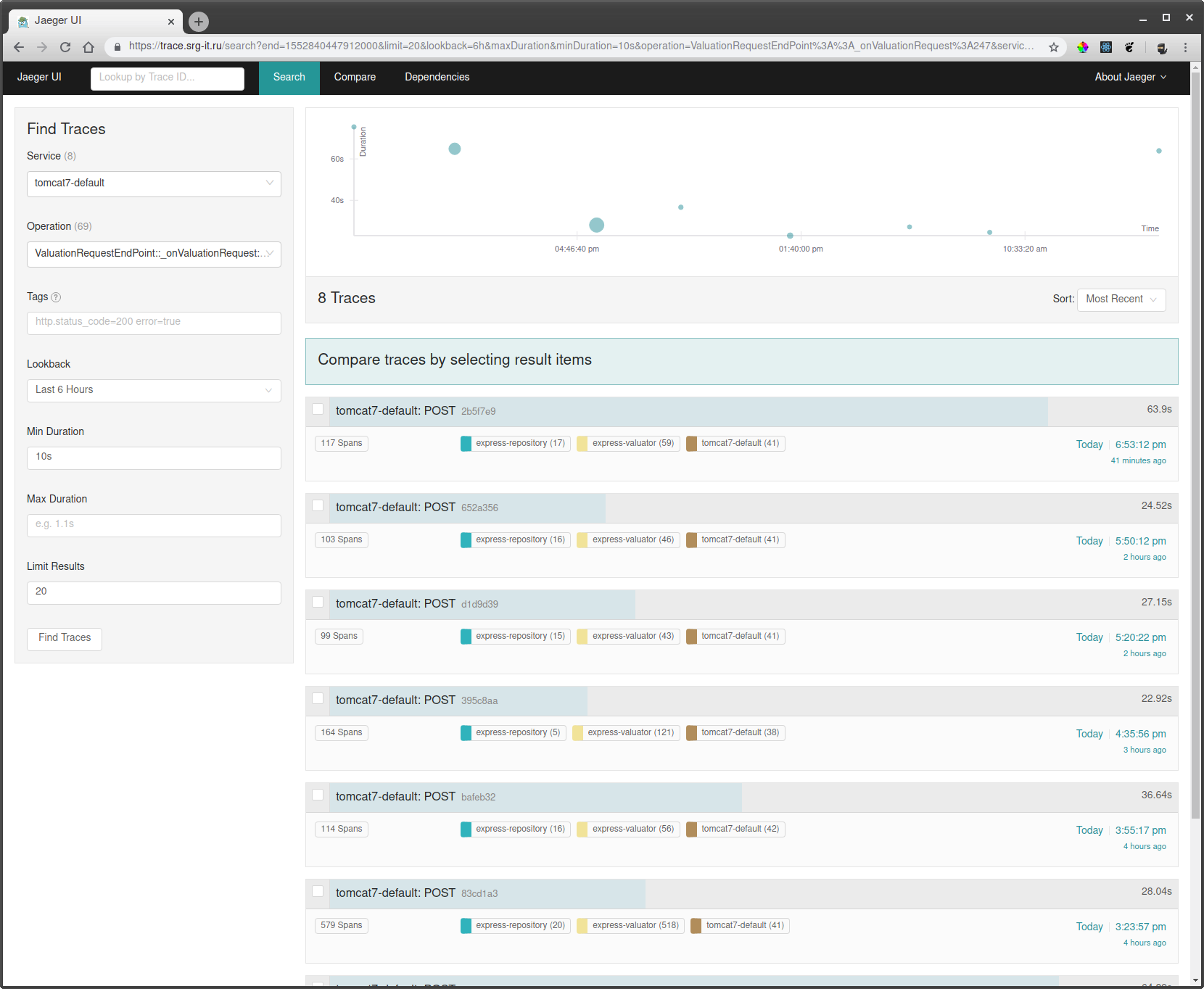
- Allez sur l'une des pistes et voyez ce qui ralentissait là-bas.

De plus, si un ID de demande est connu, vous pouvez trouver une trace par cet ID via une recherche de balise, si cet ID est enregistré dans la plage de suivi.
La documentation
Les articles
Vidéo