Chez
The Economist, nous prenons la visualisation des données très au sérieux. Chaque semaine, nous publions environ 40 graphiques en versions imprimée et en ligne, ainsi que dans les applications. Partout, nous nous efforçons de représenter avec précision les chiffres afin qu'ils illustrent le mieux le sujet. Mais parfois, nous faisons des erreurs. Il est important d'apprendre ces leçons afin de ne pas commettre d'erreurs à l'avenir. Notre expérience vous sera sûrement utile.
En plongeant dans les archives, j'ai trouvé quelques exemples instructifs. Les délits contre la visualisation des données sont regroupés en trois catégories. Ce sont des graphiques qui:
- induire en erreur;
- confus;
- ça n'a pas de sens.
Pour chacun, une version révisée est affichée, qui occupe la même quantité d'espace - un facteur important pour la publication imprimée.
(Remarque: la plupart des cartes «originales» sont publiées avant la refonte. Les cartes améliorées sont compilées conformément aux nouvelles spécifications. Les données sont les mêmes).
Graphiques trompeurs
Commençons par le pire des crimes: présenter les données de manière à ce qu'elles soient trompeuses. Nous ne faisons jamais cela exprès! Mais cela arrive parfois. Prenons trois exemples de nos archives.
Erreur: troncature
 ( données en csv )Ce graphique
( données en csv )Ce graphique montre le nombre moyen de likes Facebook sur les pages de gauche. Le but du tableau était de montrer la différence entre les postes de M. Corbin et d'autres.
Le programme d'origine sous-estime non seulement le nombre de likes de Corbin, mais exagère également les performances des autres participants (voici
un autre exemple d' une telle erreur). Dans la version révisée, la colonne de M. Corbin est entièrement spécifiée. Toutes les autres colonnes sont toujours visibles.
Une autre bizarrerie est le choix de la couleur. Pour essayer d'imiter le jeu de couleurs du travail, nous avons utilisé trois nuances d'orange / rouge attribuées à 1) Corbin, 2) à d'autres députés et 3) à des partis / groupes. Cela n'est expliqué nulle part. Bien que la logique puisse être évidente pour beaucoup, elle n'a guère de sens pour ceux qui ne connaissent pas très bien la politique britannique.
Erreur: l'effet de la relation dû au réglage des échelles
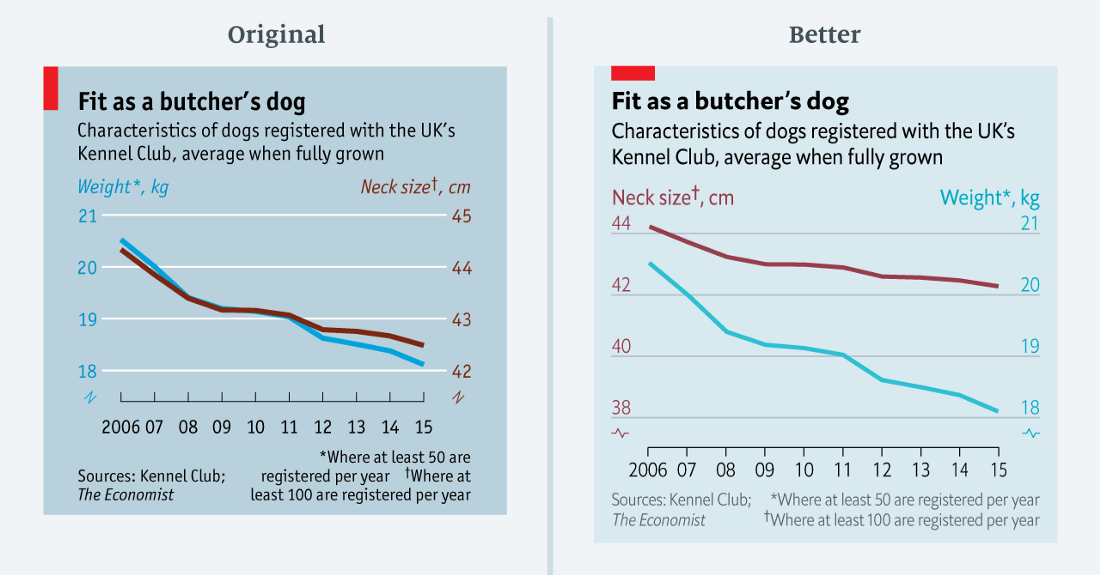 Un rare exemple de parfaite corrélation? En fait non ( données en csv )
Un rare exemple de parfaite corrélation? En fait non ( données en csv )Le tableau ci-dessus provient d'un article de perte de poids pour chien. À première vue, il semble que le poids et la circonférence du cou du chien correspondent parfaitement. Mais est-ce vrai? Seulement dans une certaine mesure.
Sur le graphique, les deux échelles sont réduites de trois unités (de 21 à 18 à gauche; de 45 à 42 à droite). Mais en termes de pourcentage, l'échelle de gauche est réduite de 14%, et la droite - de 7%. Dans le graphique révisé, j'ai conservé la double échelle, mais j'ai ajusté les plages pour refléter un changement proportionnel comparable.
Étant donné le thème amusant de ce diagramme, l'erreur peut sembler relativement mineure. Au final, la signification est la même dans les deux versions. Mais la conclusion est importante: si les deux graphiques sont trop proches l'un de l'autre, vous devrez probablement regarder de plus près les échelles.
Erreur: mauvaise méthode de visualisation
 Les opinions sur le Brexit sont presque aussi instables que les négociations à ce sujet ( données en CSV )
Les opinions sur le Brexit sont presque aussi instables que les négociations à ce sujet ( données en CSV )Nous avons publié ce graphique d'enquête dans notre application de nouvelles Espresso. Il montre la relation avec les résultats du référendum sur l'UE sous la forme d'un graphique linéaire. À en juger par les données, les répondants fluctuent considérablement dans leurs opinions: les résultats bondissent de quelques points de pourcentage.
Au lieu d'une courbe lisse pour l'affichage des tendances, nous avons indiqué les valeurs réelles de chaque enquête. Cela s'est produit principalement parce que notre outil de cartographie ne savait pas comment créer des lignes lisses. Ce n'est que récemment que nous avons maîtrisé des programmes plus avancés pour le traitement de données statistiques (par exemple, R) avec des méthodes de visualisation plus sophistiquées. Aujourd'hui, n'importe qui peut construire une courbe lisse pour les sondages, comme une option améliorée au sommet.
Il y a toujours une violation de l'échelle. Le graphique source diffuse les données plus largement qu'il ne le devrait. Dans la version révisée, j'ai ajouté un peu d'espace entre le début de l'échelle et le point de données minimum. Francis Gagnon propose une
bonne formule pour de telles situations: laisser libre au moins 33% de la surface sous le graphique linéaire, qui ne part pas de zéro.
Graphiques qui prêtent à confusion
Ce n'est pas un crime aussi grave que trompeur, mais si le calendrier est difficile à comprendre, c'est le signe d'un travail de visualisation mal fait.
Erreur: graphiques trop abstraits
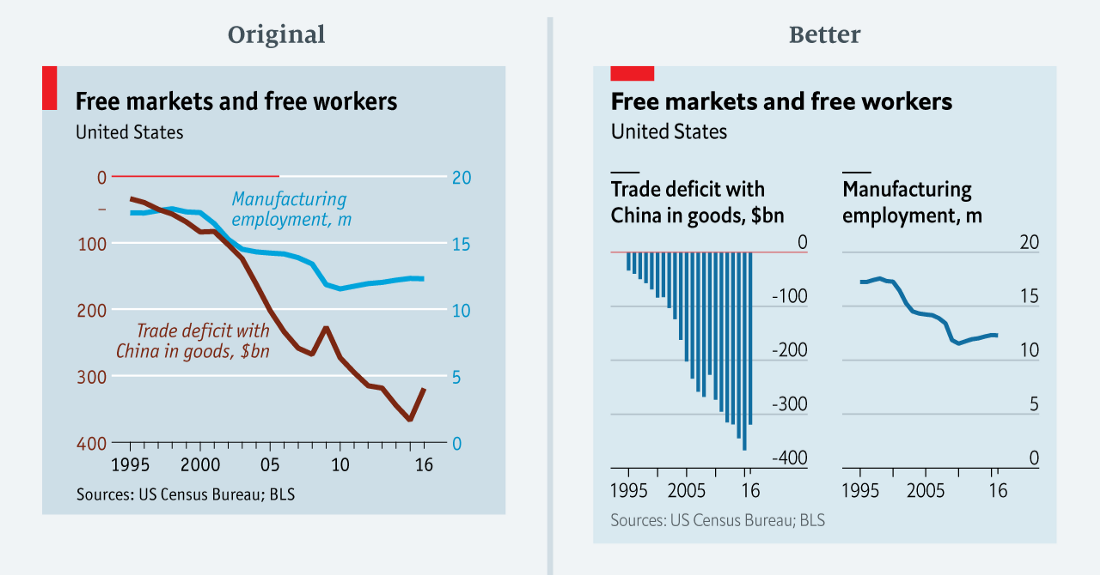 ... quoi? ( données en csv )
... quoi? ( données en csv )Les journalistes de
The Economist cherchent, dans le bon sens, à embrouiller le lecteur. Mais parfois on va trop loin. Le
graphique ci-dessus montre le déficit commercial américain des biens et le nombre de personnes employées dans le secteur manufacturier.
Ce tableau est incroyablement difficile à comprendre. Elle a deux problèmes principaux. Premièrement, les valeurs d'une série (déficit commercial) sont complètement négatives, tandis que d'autres (emploi dans le secteur manufacturier) sont positives. Il est difficile de combiner des données aussi différentes dans un même diagramme. La «solution» évidente conduit à un deuxième problème: deux lignes de données n'ont pas de ligne de base commune. La ligne de base du déficit commercial est en haut du graphique (surlignée en rouge, traverse la moitié du graphique). La ligne de base de l'échelle de droite est en bas.
Le graphique révisé montre qu'il n'était pas nécessaire de combiner les deux séries de données. La relation entre les déficits commerciaux et l'emploi manufacturier reste claire et ne prend qu'un peu plus de place.
Erreur: couleurs enchevêtrées
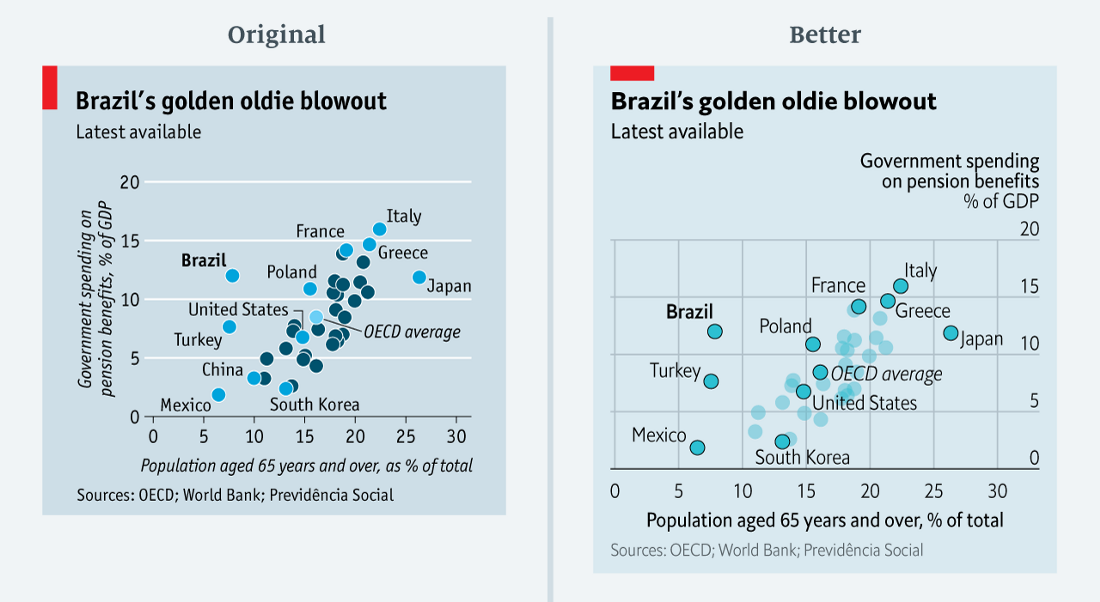 50 nuances de bleu ( données en csv )Ce graphique
50 nuances de bleu ( données en csv )Ce graphique compare les dépenses publiques consacrées aux prestations de retraite à la proportion de personnes de plus de 65 ans dans un certain nombre de pays, en particulier au Brésil. Afin de ne pas gonfler le graphique, le visualiseur n'a signé que certains pays et les a mis en surbrillance en bleu. La moyenne de l'OCDE est surlignée en bleu clair.
Le visualiseur (c'était moi!) A ignoré le fait que le changement de couleur implique souvent un changement de catégorie. Ici aussi, le lecteur peut avoir une telle idée que tous les pays bleus semblent appartenir à un groupe différent des pays bleus. Ce n'est pas le cas. La seule différence est qu'ils ne sont tout simplement pas signés.
Dans la version révisée, la couleur est la même pour tout le monde. Je n'ai changé l'intensité que pour les pays signés. La typographie fait le reste: le Brésil, le pays cible, est en gras, et la moyenne de l'OCDE est en italique.
Des graphiques qui n'ont pas de sens
Les erreurs dans cette dernière catégorie sont moins évidentes. Ces diagrammes ne sont pas trompeurs et ne prêtent pas à confusion. Ils ne peuvent tout simplement pas justifier leur existence. Soit ils ont été mal construits, soit nous avons essayé de compresser trop d'informations dans un espace trop petit.
Erreur: trop de détails.
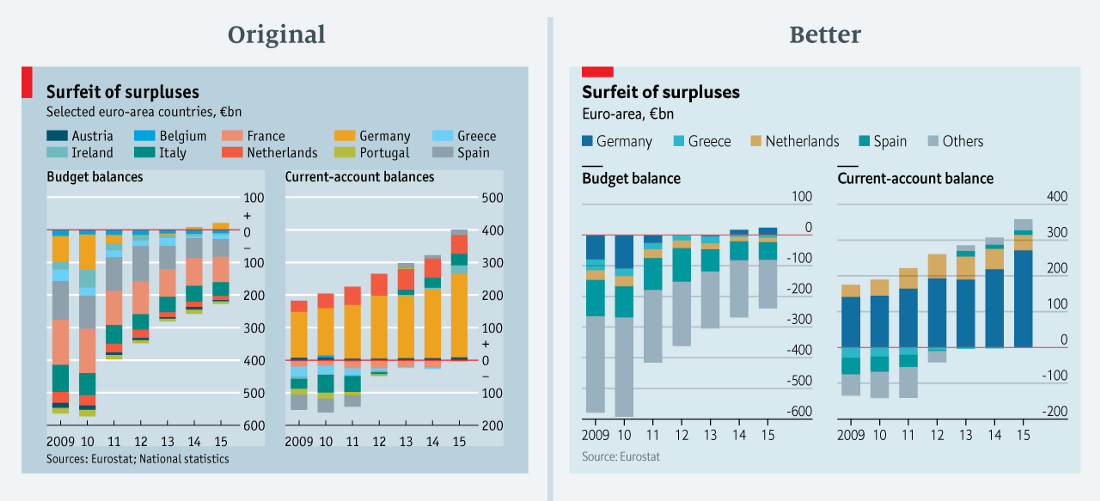 "Plus il y a de fleurs, mieux c'est!" ( données en csv )
"Plus il y a de fleurs, mieux c'est!" ( données en csv )Un vrai arc-en-ciel! Nous avons publié
ce graphique dans la colonne Excédent budgétaire allemand. Il montre le solde budgétaire et le solde actuel de dix pays de la zone euro. Avec autant de couleurs - dont certaines sont assez difficiles à distinguer ou même à voir parce que les valeurs sont trop petites - la signification du graphique est difficile à comprendre. Cela bloque presque le cerveau, obligeant le lecteur à sauter le tableau et à avancer. Et, plus important encore, étant donné que nous ne donnons pas de chiffres pour tous les pays de la zone euro, il est inutile d'ajouter des données.
J'ai relu l'article pour trouver un moyen de simplifier le diagramme. Le texte fait référence à l'Allemagne, la Grèce, les Pays-Bas, l'Espagne et la zone euro. Dans la version révisée du graphique, j'ai décidé de ne les sélectionner que et j'ai placé le reste dans la catégorie «Autres» (le solde total du compte courant sur le graphique traité est inférieur à celui du graphique d'origine, en raison de la révision des données d'Eurostat).
Erreur: beaucoup de données, pas assez d'espace
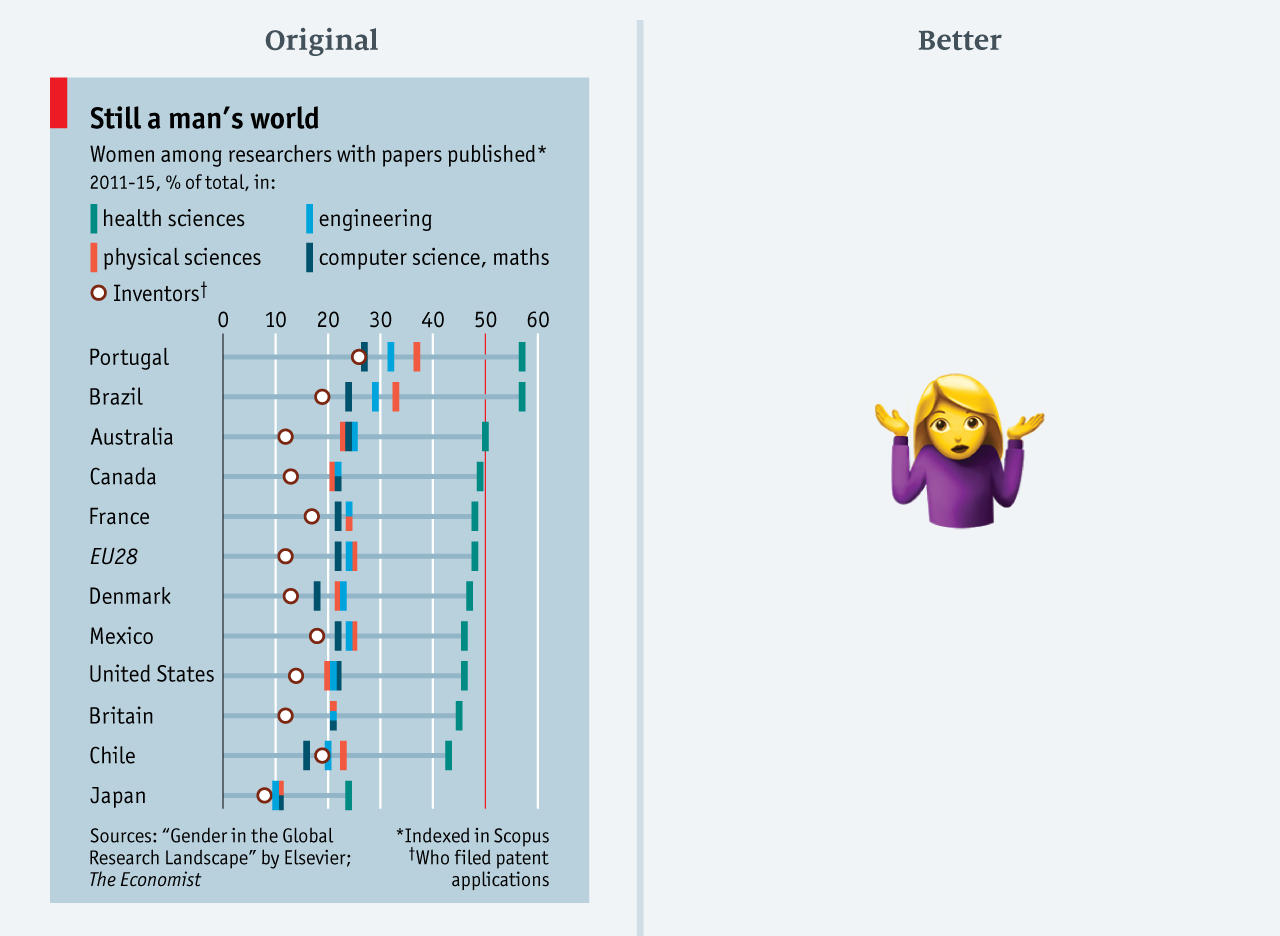 J'abandonne ( données en csv )
J'abandonne ( données en csv )Limité par l'espace sur la page, nous sommes souvent tentés de pousser toutes les données dans un emplacement trop petit. Bien que cela économise un espace précieux sur la page, il y a des conséquences, comme on peut le voir sur ce graphique de
mars 2017 . Il s'agit d'un graphique pour un article indiquant que les hommes dominent la science. Toutes les positions sont également intéressantes et pertinentes pour l'article. Mais une telle quantité de données est difficile à assimiler: voici quatre catégories de domaines de recherche, ainsi que la proportion d'auteurs de brevets dans chaque pays.
Après réflexion, j'ai décidé de ne pas modifier ce schéma. Si vous enregistrez toutes les données, le graphique sera trop grand pour un petit article. Dans de tels cas, il est préférable de couper quelque chose. Alternativement, vous pouvez afficher un certain indicateur moyen: par exemple, la part moyenne d'articles de femmes dans tous les domaines. (Veuillez me faire savoir si vous avez des idées sur la façon de visualiser cela dans un espace confiné!)
Les meilleures pratiques se développent rapidement: ce qui est acceptable aujourd'hui sera condamné demain. Tout le temps, de nouvelles méthodes plus avancées apparaissent. Avez-vous déjà commis un «crime infographique» qui peut être facilement corrigé?