
Bonjour à tous! Avec cet article, AERODISK ouvre un blog sur Habré. Hourra, camarades!
Dans des articles précédents sur Habr, des questions sur l'architecture et la configuration de base des systèmes de stockage ont été examinées. Dans cet article, nous examinerons une question qui n'était pas abordée auparavant, mais qui a souvent été posée - concernant la tolérance aux pannes des systèmes de stockage AERODISK ENGINE. Notre équipe fera tout pour que le système de stockage AERODISK cesse de fonctionner, c'est-à-dire la briser.
Il se trouve que des articles sur l'histoire de notre entreprise, sur nos produits, ainsi qu'un exemple de mise en œuvre réussie s'accrochent déjà à Habré, dont un grand merci à nos partenaires - les sociétés TS Solution et Softline.
Par conséquent, je ne formerai pas les compétences de gestion du copier-coller ici, mais je donnerai simplement des liens vers les originaux de ces articles:
Je veux également partager la bonne nouvelle. Mais je vais bien sûr commencer par le problème. Nous, en tant que jeune fournisseur, entre autres coûts, sommes constamment confrontés au fait que de nombreux ingénieurs et administrateurs ne savent pas comment faire fonctionner correctement nos systèmes de stockage.
Il est clair que la gestion de la plupart des systèmes de stockage est à peu près la même du point de vue de l'administrateur, mais chaque fabricant a ses propres caractéristiques. Et nous ne faisons pas exception.
Par conséquent, afin de simplifier la tâche de formation des professionnels de l'informatique, nous avons décidé de consacrer cette année à l'enseignement gratuit. Pour ce faire, dans de nombreuses grandes villes de Russie, nous ouvrons un réseau de Centres de Compétence AERODISK dans lequel tout spécialiste technique intéressé pourra suivre un cours tout à fait gratuitement et recevoir un certificat d'administration de stockage AERODISK ENGINE.
Dans chaque centre de compétence, nous installerons un stand de démonstration à part entière du système de stockage AERODISK et un serveur physique sur lequel notre professeur dispensera une formation à temps plein. Le calendrier de travail des centres de compétence sera publié dès leur apparition, mais nous avons maintenant ouvert un centre à Nijni Novgorod et la ville de Krasnodar est la prochaine en ligne. Vous pouvez vous inscrire à la formation en utilisant les liens ci-dessous. J'apporte les informations actuellement connues sur les villes et les dates:
- Nizhny Novgorod (DÉJÀ TRAVAILLÉ - vous pouvez vous inscrire ici https://aerodisk.promo/nn/ );
Jusqu'au 16 avril 2019, vous pouvez visiter le centre à toute heure de travail, et le 16 avril 2019 une grande formation sera organisée. - Krasnodar (COMING SOON - inscrivez-vous ici https://aerodisk.promo/krsnd/ );
Du 9 avril au 25 avril 2019, vous pouvez visiter le centre à tout moment et, le 25 avril 2019, une grande formation sera organisée. - Iekaterinbourg (À VENIR, suivez les informations sur notre site Internet ou sur Habré);
Mai-juin 2019. - Novossibirsk (suivez les informations sur notre site Internet ou sur Habré);
Octobre 2019 - Krasnoyarsk (suivez les informations sur notre site Internet ou sur Habré);
Novembre 2019
Et, bien sûr, si Moscou n'est pas loin de vous, vous pouvez à tout moment visiter notre bureau à Moscou et suivre une formation similaire.
C’est tout. Lié au marketing, passez à la technique!
Sur Habré, nous publierons régulièrement des articles techniques sur nos produits, des tests de résistance, des comparaisons, des fonctionnalités d'utilisation et des implémentations intéressantes.
AERODISK ENGINE N2 Tests de crash de stockage, test de résistance
ACHTUNG! Après avoir lu l'article, vous pouvez dire: eh bien, bien sûr, le vendeur va vérifier lui-même pour que tout se passe "avec fracas", les conditions de serre, etc. Je répondrai: rien de tel! Contrairement à nos concurrents étrangers, nous sommes ici, près de vous, et vous pouvez toujours venir chez nous (à Moscou ou tout autre comité central) et tester notre système de stockage de quelque manière que ce soit. Ainsi, il n'est pas très logique d'ajuster les résultats à l'image idéale du monde, car nous sommes très faciles à vérifier. Pour ceux qui sont trop paresseux pour marcher et qui n'ont pas le temps, nous pouvons organiser des tests à distance. Nous avons un laboratoire spécial pour cela. Contact.
ACHTUNG-2! Ce test n'est pas un test de charge car ici, nous ne nous préoccupons que de la tolérance aux pannes. Dans quelques semaines, nous préparerons un stand plus puissant et effectuerons des tests de charge des systèmes de stockage, en publiant les résultats ici (au fait, les souhaits de tests sont acceptés).
Alors, allons faire une pause.
Banc d'essai
Notre stand se compose du fer suivant:
- 1 x stockage Aerodisk Engine N2 (2 contrôleurs, 64 Go de cache, 8 ports CF 8 Gbit / s, 4 ports Ethernet 10 Gbit / s SFP +, 4 ports Ethernet 1 Gbit / s); Les disques suivants sont installés dans le système de stockage:
- 4 disques SAS SSD 900 Go;
- 12 disques SAS 10k de 1,2 To;
- 1 x serveur physique avec Windows Server 2016 (2xXeon E5 2667 v3, 96 Go de RAM, 2x ports CF 8 Gbit / s, 2x ports Ethernet 10 Gbit / s SFP +);
- 2 x commutateur SAN 8G;
- 2 x commutateur LAN 10G;
Nous avons connecté le serveur au stockage via des commutateurs via FC et Ethernet 10G. Schéma du stand ci-dessous.
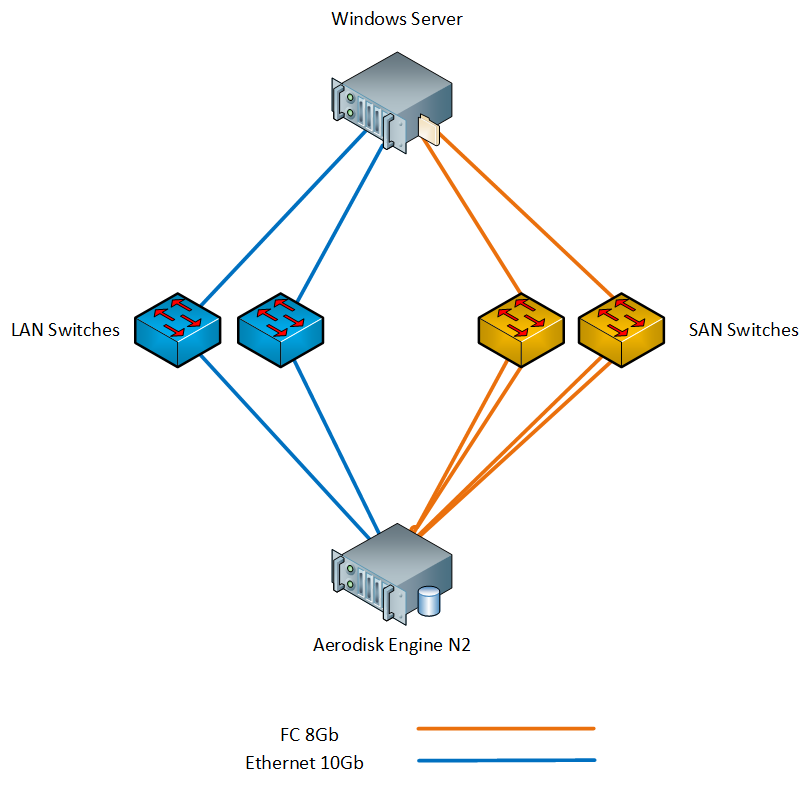
Les composants nécessaires, tels que MPIO et initiateur iSCSI, sont installés sur Windows Server.
Les zones sont configurées sur les commutateurs FC, les VLAN correspondants sont configurés sur les commutateurs LAN et MTU 9000 est installé sur les ports de stockage, les commutateurs et l'hôte (comment faire tout cela est décrit dans notre documentation, nous ne décrirons donc pas ce processus ici).
Méthodologie de test
Le plan de crash test est le suivant:
- Vérification des défaillances des ports FC et Ethernet.
- Vérification de panne de courant.
- Vérification de l'échec du contrôleur.
- Vérifiez l'échec du disque dans un groupe / pool.
Tous les tests seront effectués dans des conditions de charge synthétique, que nous générerons avec IOMETER. En parallèle, nous effectuerons les mêmes tests, mais dans des conditions de copie de gros fichiers sur le système de stockage.
La configuration IOmeter est la suivante:
- Lecture / écriture - 70/30
- Block - 128k (nous avons décidé de mouiller le système de stockage avec de gros blocs)
- Le nombre de threads est de 128 (ce qui est très similaire à la charge de travail)
- Plein aléatoire
- Nombre de travailleurs - 4 (2 pour FC, 2 pour iSCSI)
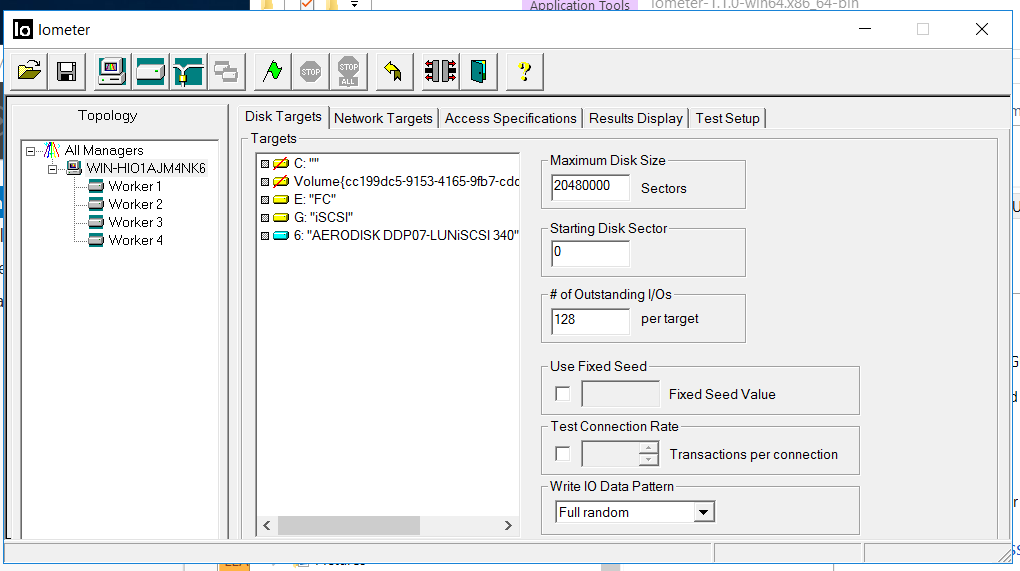
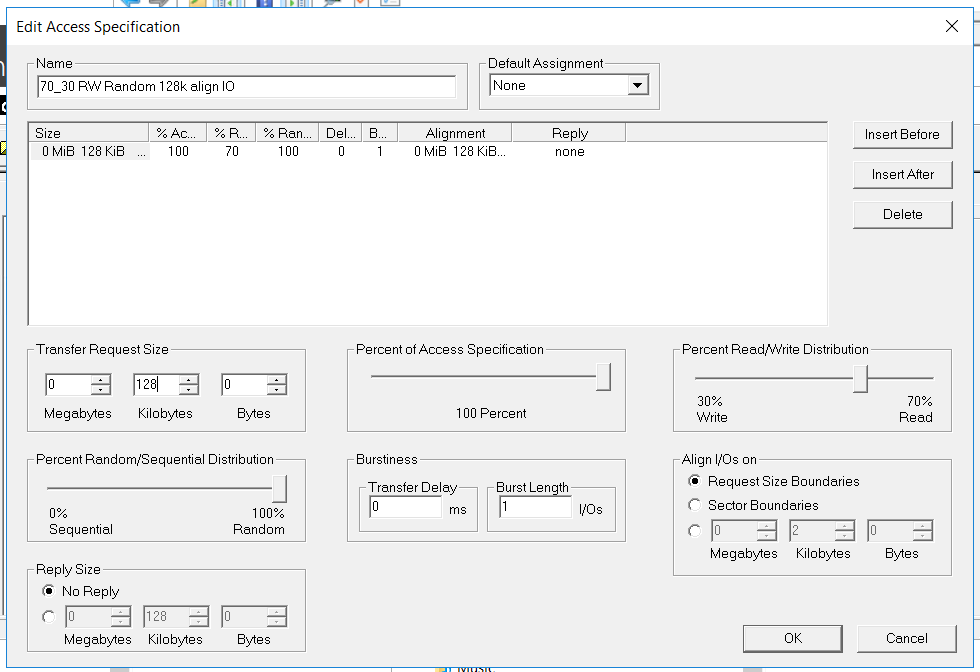 Le test a les tâches suivantes:
Le test a les tâches suivantes:- Assurez-vous que la charge synthétique et le processus de copie ne seront pas interrompus et ne provoqueront pas d'erreurs avec différents modes de défaillance.
- Assurez-vous que le processus de commutation des ports, des contrôleurs, etc., est suffisamment automatisé et ne nécessite pas d'actions d'administrateur en cas de défaillance (c'est-à-dire qu'avec le basculement, bien sûr, il n'est pas question de rétablissement).
- Assurez-vous que les informations s'affichent correctement dans les journaux.
Préparation de l'hôte et du stockage
Nous avons configuré l'accès par blocs sur le stockage à l'aide des ports FC et Ethernet (FC et iSCSI, respectivement). Comment faire cela, les gars de TS Solution ont décrit en détail dans un article précédent ( https://habr.com/en/company/tssolution/blog/432876/ ). Et bien sûr, personne n'a annulé les manuels et les cours.
Nous avons mis en place un groupe hybride en utilisant tous les disques que nous avons. 2 disques SSD sont ajoutés au cache, 2 disques SSD sont ajoutés comme niveau de stockage supplémentaire (niveau en ligne). Nous avons regroupé 12 disques SAS10k en RAID-60P (triple parité) afin de vérifier la défaillance de trois disques dans un groupe à la fois. Un disque a été laissé pour la correction automatique.
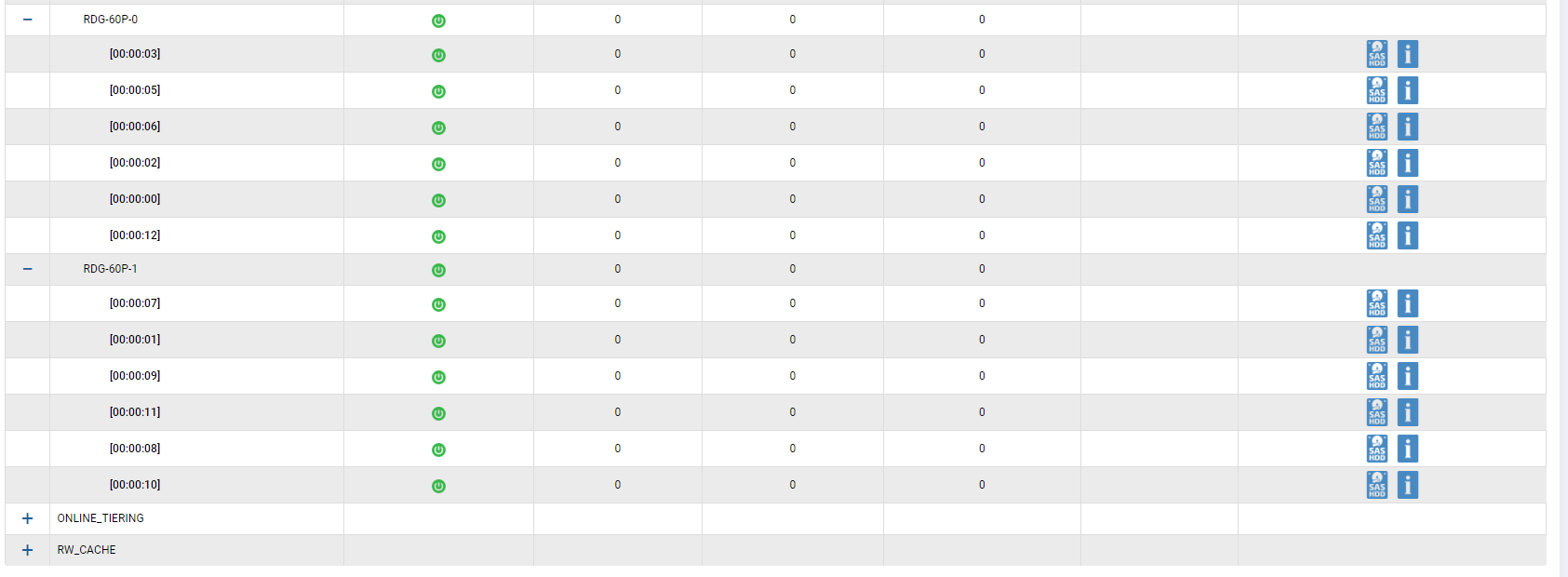
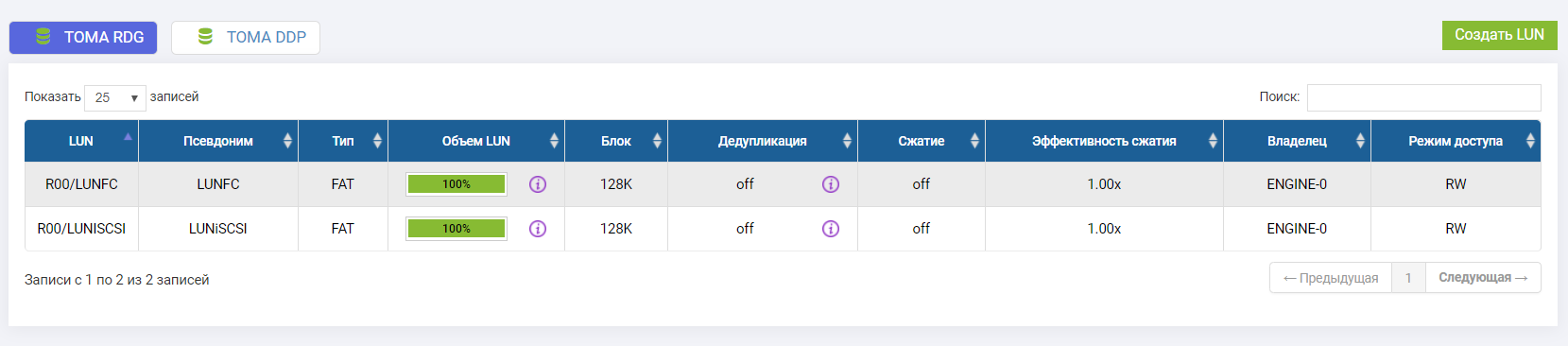
Nous avons connecté deux LUN (un sur FC, un sur iSCSI).
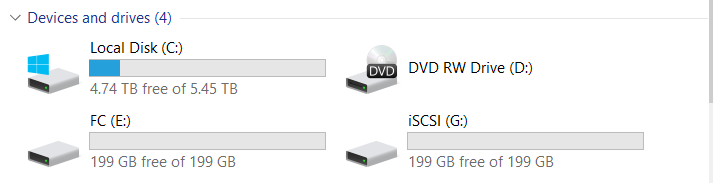
Les deux LUN appartiennent au contrôleur Engine-0.
Lancer le test
Allumez IOMETER avec la configuration ci-dessus.
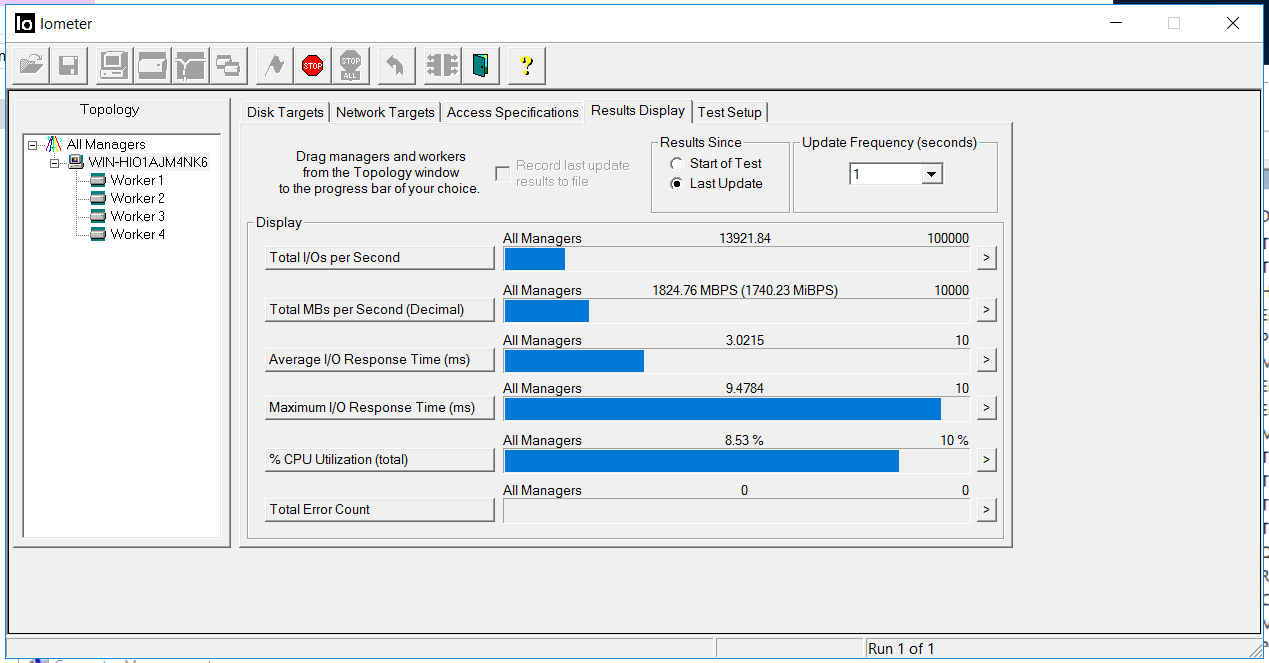
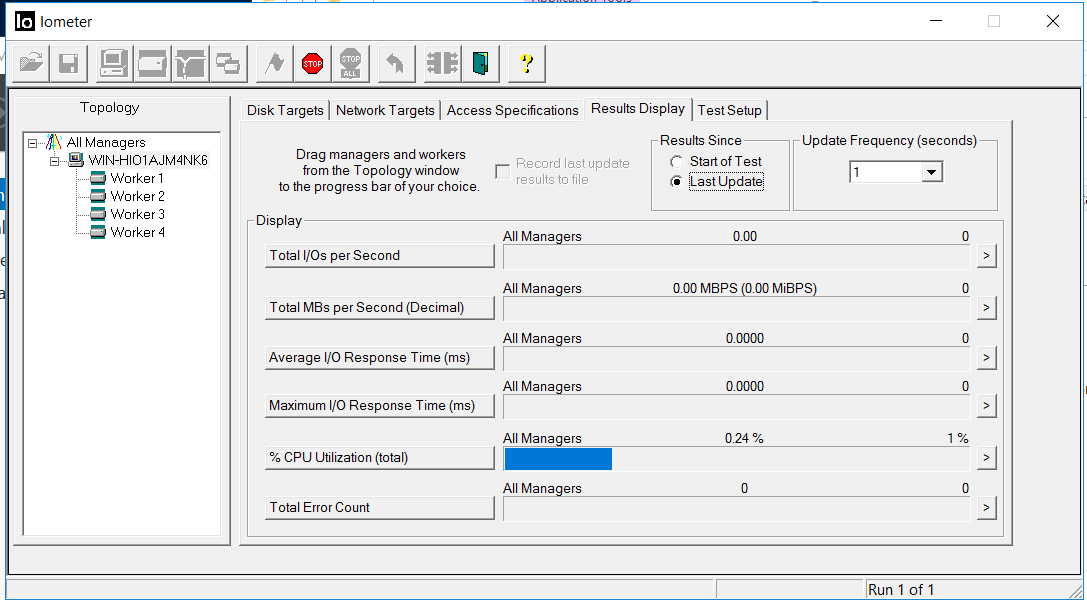
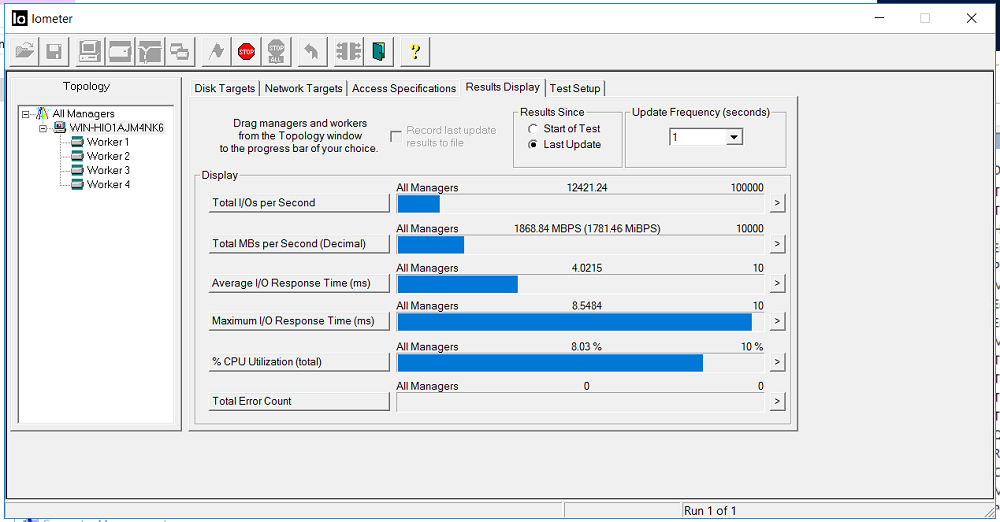
Nous fixons la bande passante de 1,8 Go / s et un retard de 3 millisecondes. Il n'y a aucune erreur (Total Error Count).
Dans le même temps, à partir du lecteur local "C" de notre hôte, nous commençons simultanément à copier deux gros fichiers de 100 Go vers les LUN FC et iSCSI du système de stockage (disques E et G sous Windows) en utilisant d'autres interfaces.
Ci-dessus est le processus de copie vers LUN FC, ci-dessous est iSCSI.

Test n ° 1. Désactivation des ports d'E / S
Nous approchons de l'arrière du système de stockage))) et d'un coup de poignet, nous retirons tous les câbles FC et Ethernet 10G du contrôleur Engine-0. Comme si une femme de ménage avec une vadrouille passait et décidait de laver le sol là où morve couchée les câbles étaient allongés (c'est-à-dire que le contrôleur fonctionne toujours, mais les ports d'E / S sont morts).

Nous regardons IOMETER et la copie de fichiers. La bande passante a chuté à 0,5 Go / s, mais est rapidement revenue à son niveau précédent (en environ 4-5 secondes). Il n'y a aucune erreur.
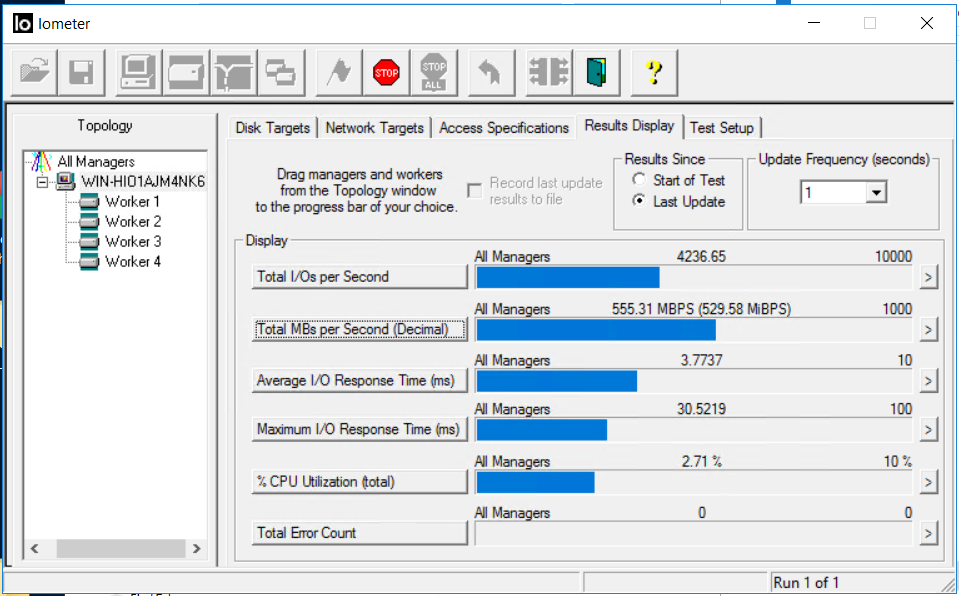
La copie des fichiers ne s'est pas arrêtée, il y a un ralentissement de la vitesse, mais cela n'est absolument pas critique (de 840 Mo / s il est tombé à 720 Mo / s). La copie ne s'est pas arrêtée.
Nous regardons dans les journaux du système de stockage et nous voyons un message sur l'indisponibilité des ports et le déplacement automatique du groupe.

De plus, le tableau de bord nous dit que tout n'est pas très bon avec les ports FC.
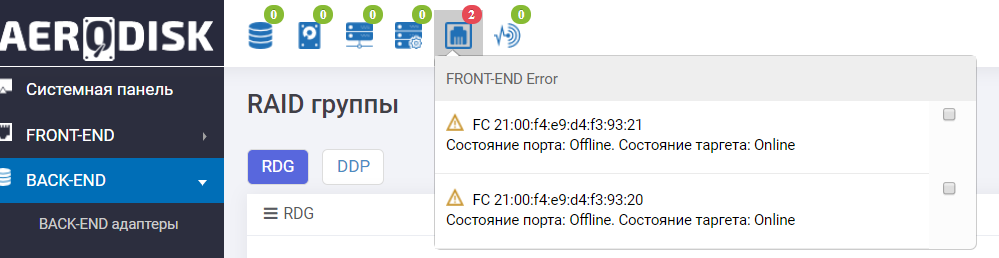
Les ports d'E / S de stockage ont échoué .
Numéro de test 2. Désactivation du contrôleur de stockage
Presque immédiatement (après avoir rebranché les câbles dans le système de stockage), nous avons décidé de terminer le stockage en retirant le contrôleur du châssis.
Encore une fois, nous approchons le système de stockage par derrière (nous l'avons aimé))) et cette fois, nous retirons le contrôleur Engine-1, qui est actuellement le propriétaire de RDG (vers lequel le groupe a déménagé).
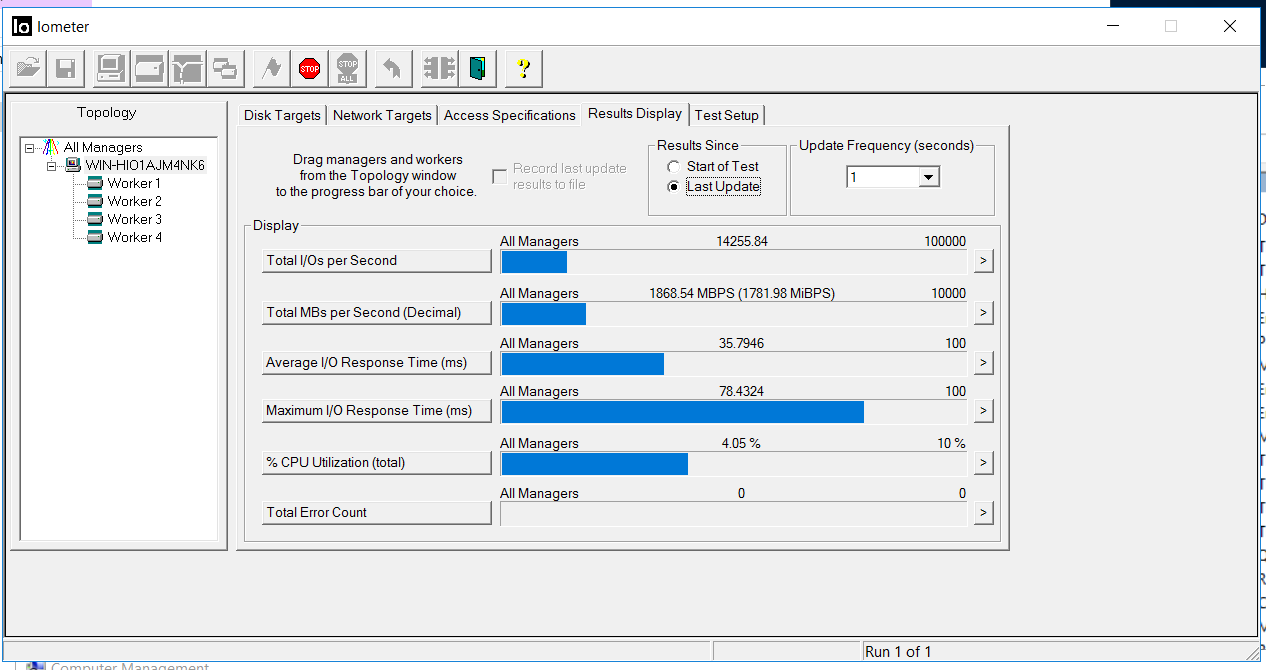
La situation dans IOmeter est la suivante. La sortie d'entrée s'est arrêtée pendant environ 5 secondes. Les erreurs ne s'accumulent pas.
Après 5 secondes, les E / S ont repris, avec à peu près les mêmes débits, mais avec des retards de 35 millisecondes (les retards ont été corrigés au bout de quelques minutes environ). Comme le montrent les captures d'écran, la valeur du nombre total d'erreurs est 0, c'est-à-dire qu'il n'y a eu aucune erreur d'écriture ou de lecture.
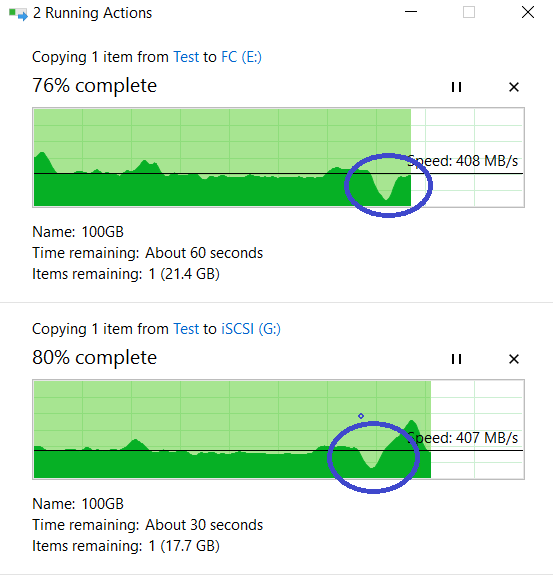
Nous envisageons de copier nos fichiers. Comme vous pouvez le voir, cela n'a pas interrompu, il y a eu un petit ralentissement des performances, mais en général, tout est revenu à la même ~ 800 Mo / s.
Nous allons au système de stockage et voyons des abus dans le panneau d'informations que le contrôleur Engine-1 n'est pas disponible (bien sûr, nous l'avons frappé).
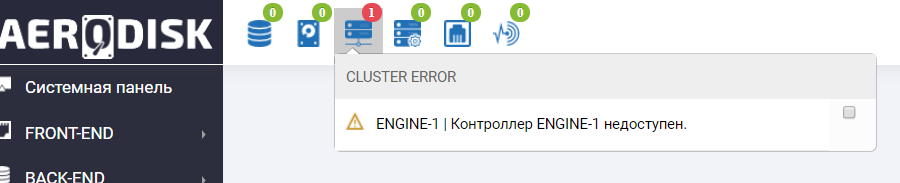
Nous voyons également une entrée similaire dans les journaux.

L'échec du contrôleur de stockage a également survécu avec succès.
Numéro de test 3. Déconnexion de l'alimentation.
Juste au cas où, nous avons recommencé à copier les fichiers, mais IOMETER ne s'est pas arrêté.
Nous tirons le BP-Schnick.

Une autre alerte a été ajoutée au stockage dans le panneau d'informations.

Nous voyons également dans le menu des capteurs que les capteurs associés à l'alimentation retirée deviennent rouges.

SHD continue de fonctionner. La défaillance du BP-Schnick n'affecte en rien le fonctionnement du système de stockage, du point de vue de l'hôte, la vitesse de copie et les indicateurs IOMETER sont restés inchangés.
Le test de panne de courant s'est terminé avec succès.
Avant le test final, nous avons décidé de ramener un peu le SHD à la vie, de remettre le contrôleur et le BP-shnik sous tension, et également de mettre les choses en ordre avec les câbles, que le SHD nous a joyeusement informés avec des icônes vertes dans son panneau de santé.

Test numéro 4. Échec de trois disques dans le groupe
Avant ce test, nous avons effectué une étape préparatoire supplémentaire. Le fait est que le stockage ENGINE fournit une chose très utile - différentes politiques de reconstruction (reconstruction). Auparavant, TS Solution a écrit sur cette fonctionnalité, mais rappelle son essence. L'administrateur de stockage peut spécifier la priorité d'allocation des ressources lors de la reconstruction. Ou dans le sens des performances d'E / S, c'est-à-dire une reconstruction plus longue, mais il n'y a pas de baisse des performances. Ou dans le sens de la vitesse de reconstruction, mais les performances seront réduites. Ou une option équilibrée. Étant donné que les performances de stockage lors d'une reconstruction d'un groupe de disques sont toujours un casse-tête pour l'administrateur, nous testerons la stratégie avec un biais dans le sens des performances d'E / S et au détriment de la vitesse de la reconstruction.

Vérifiez maintenant la panne des disques. Nous permettons également l'enregistrement sur des LUN (fichiers et IOMETER). Étant donné que nous avons un groupe à triple parité (RAID-60P), cela signifie que le système doit résister à la défaillance de trois disques, et après la défaillance, il doit fonctionner en remplacement automatique, un disque doit se tenir dans le RDG à la place de l'un des échecs, et la reconstruction doit commencer sur celui-ci.
Nous commençons. Tout d'abord, via l'interface de stockage, mettez en surbrillance les disques que nous voulons retirer (afin de ne pas manquer et de ne pas tirer le disque à remplacement automatique).

Vérifiez l'indication sur le fer. Tout va bien, nous voyons les trois disques en surbrillance.

Et sortez ces trois disques.

Nous regardons l'hôte. Et là ... rien de spécial n'est arrivé.
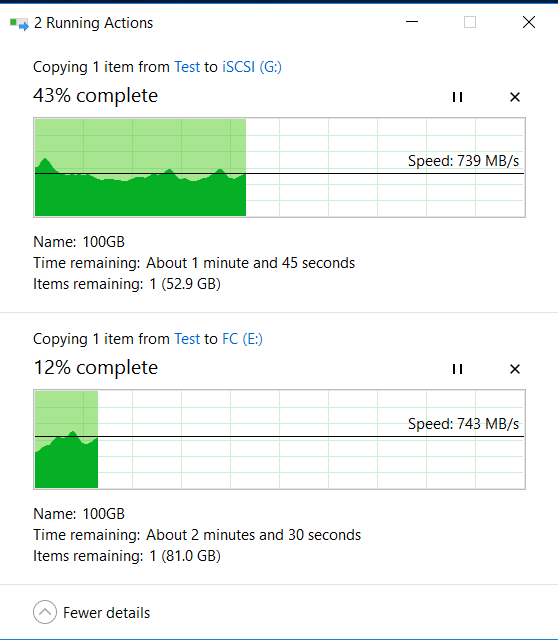
Les indicateurs de copie (ils sont plus élevés qu'au début, car le cache s'est réchauffé) et l'IOMÈTRE ne changent pas beaucoup lors de l'extraction des disques et du démarrage de la reconstruction (dans un délai de 5 à 10%).
Nous regardons le stockage.
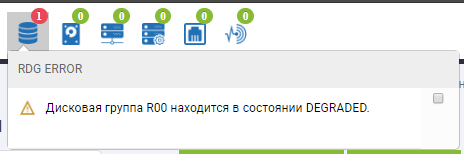
Dans le statut du groupe, nous voyons que le processus de reconstruction a commencé et qu'il est presque terminé.

Le squelette RDG montre que 2 disques sont en statut rouge et qu'un a déjà été remplacé. Le disque de correction automatique n'est plus là, il a remplacé le 3ème disque défectueux. Rebild a été exécuté pendant plusieurs minutes, l'enregistrement de fichiers n'a pas été interrompu lorsque 3 disques ont échoué, les performances d'E / S n'ont pas beaucoup changé.
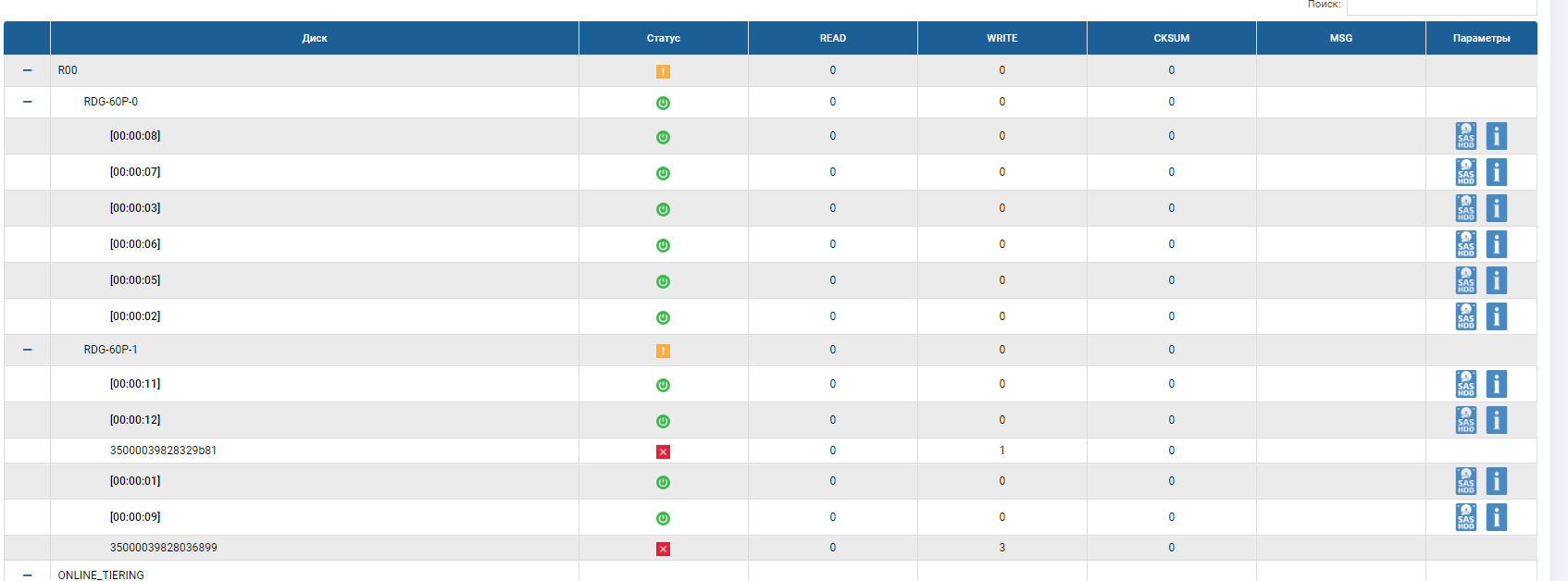
Le test de panne du lecteur a définitivement réussi.
Conclusion
Sur ce point, nous avons décidé de mettre fin à l'abus des systèmes de stockage. Pour résumer:
- Vérification d'échec du port FC - Réussi
- Vérification d'échec du port Ethernet - réussie
- Vérification des échecs du contrôleur - réussie
- Vérification de panne de courant - réussie
- Vérifier l'échec du disque dans le groupe \ pool - avec succès
Aucun des échecs n'a arrêté l'enregistrement et n'a pas causé d'erreurs de charge synthétiques, le ralentissement des performances, bien sûr, a été (et nous savons comment le vaincre, ce que nous ferons bientôt), mais, étant donné qu'il s'agit de quelques secondes, il est tout à fait acceptable. Conclusion: la tolérance aux pannes de tous les composants de stockage AERODISK fonctionnait au niveau, il n'y a pas de points de défaillance.
Évidemment, dans le cadre d'un article, nous ne pouvons pas tester tous les scénarios de défaillance, mais nous avons essayé de couvrir les plus populaires. Par conséquent, veuillez envoyer vos commentaires, souhaits pour les publications suivantes et, bien sûr, les critiques adéquates. Nous serons heureux de discuter (et de mieux venir à la formation, juste au cas où, dupliquer le calendrier)! Jusqu'à de nouveaux tests!
- Nizhny Novgorod (DÉJÀ TRAVAILLÉ - vous pouvez vous inscrire ici https://aerodisk.promo/nn/ );
Jusqu'au 16 avril 2019, vous pouvez visiter le centre à toute heure de travail, et le 16 avril 2019 une grande formation sera organisée. - Krasnodar (COMING SOON - inscrivez-vous ici https://aerodisk.promo/krsnd/ );
Du 9 avril au 25 avril 2019, vous pouvez visiter le centre à tout moment et, le 25 avril 2019, une grande formation sera organisée. - Ekaterinbourg (OUVERTURE BIEN, suivez les informations sur notre site ou sur Habré);
Mai-juin 2019. - Novossibirsk (suivez les informations sur notre site Internet ou sur Habré);
Octobre 2019 - Krasnoyarsk (suivez les informations sur notre site Internet ou sur Habré);
Novembre 2019