L'accumulation de dettes techniques peut conduire votre entreprise à une crise. Mais il peut également devenir un puissant moteur de changements massifs de processus et aider à l'adoption des pratiques d'ingénierie. Je vais vous en parler dans mon propre exemple.
 L'équipe informatique de Dodo Pizza est
L'équipe informatique de Dodo Pizza est passée de 2 développeurs desservant un pays à 60 personnes desservant 12 pays en 7 ans. En tant que Scrum Master et XP Coach, j'ai aidé les équipes à établir des processus et à adopter des pratiques d'ingénierie, mais cette adoption a été trop lente. Il était difficile pour moi de faire en sorte que les équipes conservent une qualité de code élevée lorsque plusieurs équipes travaillent sur un seul produit. Nous sommes tombés dans le piège de la préférence pour les caractéristiques commerciales par rapport à l'excellence technique et avons accumulé trop de dettes techniques architecturales. Lorsque le marketing a lancé une campagne publicitaire massive en 2018, nous n'avons pas pu supporter la charge et sommes tombés. C'était dommage. Mais pendant la crise, nous avons réalisé que nous étions capables de travailler plusieurs fois plus efficacement. La crise nous a poussés vers des changements révolutionnaires dans les processus et l'introduction rapide des pratiques d'ingénierie les plus connues.
Contexte
Vous pensez peut-être que Dodo Pizza est un réseau de pizzeria régulier. Mais en fait,
Dodo Pizza est une entreprise informatique qui vend des pizzas . Notre entreprise est basée sur
Dodo IS - une plateforme basée sur le cloud, qui gère tous les processus commerciaux, depuis la prise de commande, la cuisson et la finition jusqu'à la gestion des stocks, la gestion des personnes et la prise de décisions. En seulement 7 ans, nous sommes passés de 2 développeurs desservant une seule pizzeria à 70+ développeurs desservant 470+ pizzerias dans 12 pays.
Lorsque j'ai rejoint l'entreprise il y a deux ans, nous avions 6 équipes et une trentaine de développeurs. La base de code Dodo IS avait environ 1 million de lignes de code. Il avait une architecture monolithique et très peu de couverture de tests unitaires. Nous n'avions alors aucun test API / UI. La qualité du code du système était décevante. Nous le savions et rêvions d'un avenir brillant en divisant le monolithe en une douzaine de services et en réécrivant les parties les plus hideuses du système. Nous avons même dessiné le diagramme «être l'architecture», mais honnêtement, nous n'avons presque rien fait pour le futur état.
Mon objectif principal était d'enseigner aux développeurs les pratiques d'ingénierie et de construire un processus de développement, faisant travailler 6 équipes sur un seul produit .
À mesure que l'équipe grandissait, nous souffrions davantage d'un manque de processus et de pratiques d'ingénierie clairs. Nos versions sont devenues plus grandes et plus longues car de plus en plus de développeurs ont contribué au système, mais nous n'avions pas de tests de régression automatisés et avons donc perdu plus de temps sur la régression manuelle à chaque version. Nous avons souffert de nombreux changements effectués par 6 équipes dans des succursales distinctes. Lorsqu'une équipe fusionnait ses modifications dans une seule branche avant la publication, nous perdions parfois jusqu'à 4 heures pour résoudre les conflits de fusion.
La merde arrive
En 2018, Marketing a lancé notre première campagne de publicité fédérale à la télévision . Ce fut un événement énorme pour nous. Nous avons dépensé 100 millions de roubles (1,5 million de dollars) pour financer la campagne - un montant assez important pour nous. L'équipe informatique s'est également préparée pour la campagne. Nous avons automatisé et simplifié notre déploiement - maintenant avec un seul bouton dans TeamCity, nous pouvions déployer le monolithe dans 12 pays. Nous avons examiné des tests de performances et effectué une analyse de vulnérabilité. Nous avons fait de notre mieux mais nous avons rencontré des problèmes inattendus.
La campagne publicitaire a été formidable. Nous sommes passés de 100 à 300 commandes / minute. C'était une bonne nouvelle. La mauvaise nouvelle était que Dodo IS ne pouvait pas supporter une telle charge et est mort. Nous avons atteint nos limites d'échelle verticale et ne pouvions plus traiter les commandes. Le système a redémarré toutes les 3 heures. Chaque minute d'arrêt nous a coûté des millions d'argent ainsi que le manque de respect des clients furieux.
Quand je suis arrivé chez Dodo il y a 2 ans en tant que Chief Agile Officer, j'avais un grand désir de faire de notre petite équipe d'alors - environ 12 personnes, une équipe de rêve. J'ai immédiatement commencé à introduire des pratiques d'ingénierie. La plupart des équipes ont adopté la programmation par paires, les tests unitaires et DDD très bientôt. Mais tout n'a pas été facile. J'ai dû surmonter la résistance des développeurs, du Product Owner et de l'équipe de support.
Contrairement aux pratiques d'ingénierie, tout le monde n'était pas favorable à l'idée d'équipes techniques. Les développeurs avaient l'habitude de penser qu'une équipe concentrée sur un composant rédige un meilleur code. Il n'était pas clair comment combiner le développement rapide des fonctionnalités de l'entreprise avec la refonte massive attendue depuis longtemps d'un système complexe. Un flux continu de bogues exigeait également une attention constante. L'équipe de support a préféré que sa propre équipe se concentre uniquement sur la correction des bogues. De nombreuses équipes avaient l'habitude de travailler dans des branches distinctes et avaient peur de s'intégrer fréquemment. Nous ne sortions pas plus d'une fois par semaine, et chaque version prenait un temps assez long, nécessitant une énorme quantité de prise en charge des tests de régression manuelle et d'interface utilisateur. J'ai essayé de le réparer, mais mes changements de processus étaient trop lents et fragmentés.
L'histoire de l'automne et de la montée
État initial: architecture monolithique
À la recherche de la vitesse de développement des fonctionnalités commerciales, nous n'avons pas toujours bien réfléchi aux solutions techniques. Un manque d'expérience nous a également touchés. Au début, l'entreprise ne pouvait pas se permettre d'embaucher les meilleurs développeurs. Nous avons travaillé avec des passionnés qui ont accepté d'aider à la création de Dodo IS, croyaient au fondateur de l'entreprise - Fedor et travaillaient presque pour la nourriture (pizza, bien sûr). Les développeurs qui ont rejoint l'équipe plus tard ont suivi l'architecture établie, qui est devenue obsolète. Nous avions donc une application monolithique avec une seule base de données, contenant toutes les données de tous les composants en un seul endroit. Tracker, checkout, site, API pour les pages de destination - tous les composants du système fonctionnaient avec une seule base de données, qui devient un goulot d'étranglement. Notre architecture monolithique a créé des problèmes monolithiques. Un seul article de blog a entraîné une interruption de paiement au restaurant.
Histoire vraie
Pour illustrer la fragilité de l'architecture monolithique, je ne donnerai qu'un exemple. Une fois que tous nos restaurants sur la Russie ont cessé d'accepter les commandes à cause d'un article de blog. Comment cela peut-il arriver?
Un jour, notre PDG - Fedor a publié un article sur son blog. Ce poste a rapidement gagné en popularité. Il y a un compteur sur le site Web du blog de Fedor indiquant un certain nombre de pizzerias dans notre chaîne et le revenu total de toutes les pizzerias. Chaque fois que quelqu'un lisait le blog de Fedor, le serveur Web envoyait une demande à la base de données principale pour calculer les revenus. Ces demandes ont surchargé la base de données et il a cessé de servir les demandes de la caisse du restaurant. Un article de blog populaire a donc perturbé le travail de toute la chaîne de restaurants. Nous avons rapidement résolu le problème, mais c'était un signe clair (parmi bien d'autres) que notre architecture n'était pas en mesure de répondre aux besoins de l'entreprise et devait être repensée. Mais nous avons ignoré ces signes. Nous avons mis en œuvre des solutions rapides et faciles (comme l'ajout d'une réplique en lecture seule de la base de données principale), mais nous n'avions aucune feuille de route de refonte technique.
L'architecture monolithique est bonne pour commencer car elle est simple. Mais il ne peut pas supporter la charge élevée étant un point de défaillance unique.
Échec précoce en 2017
Le 14 février est la Saint-Valentin . Tout le monde aime ces vacances. Pour que les amoureux se félicitent, le 14 février, nous faisons une pizza spéciale - pepperoni en forme de cœur. Je me souviendrai du 14 février 2017 pour toujours, car ce jour-là, lorsque toutes les pizzerias fonctionnaient à pleine charge, Dodo IS a commencé à tomber. Dans chaque pizzeria, nous avons 4 à 5 comprimés pour suivre la commande d'une pizzeria qui prépare la pâte, met les ingrédients, cuit ou envoie à la livraison. Le nombre de pizzerias a atteint 300+, chaque tablette a mis à jour son état plusieurs fois par minute. Toutes ces demandes ont créé une charge si massive sur la base de données que le serveur SQL a cessé de résister et que la base de données a commencé à échouer. Dodo EST posé au moment le plus inapproprié - pendant le pic des ventes. La saison des fêtes était chargée: le 23 février (Journée de l'armée et de la marine), le 8 mars (Journée internationale de la femme), le 1er mai (Journée de la solidarité internationale des travailleurs) et le 9 mai (Jour de la victoire dans la Seconde Guerre mondiale). Pendant ces vacances, nous nous attendions à une croissance des commandes encore plus importante.
Le jour où tu mourras . Connaissant nos plans de croissance et la limite de la charge que nous pouvons supporter, nous avons compris combien de temps nous pouvons rester en vie, c'est-à-dire lorsque la charge de pointe d'aujourd'hui devient régulière. La date estimée d'Armageddon attendue dans environ six mois - en août ou septembre. Comment vous sentez-vous de vivre, en connaissant la date de votre décès?
Arrêtez le développement des fonctionnalités pendant un an . Avec le PDG Fedor, nous avons dû prendre une décision difficile. Peut-être l'une des décisions les plus difficiles de l'histoire de l'entreprise. Nous avons arrêté le développement de fonctionnalités commerciales. Nous pensions que nous allions arrêter pendant 3 mois, mais nous nous sommes vite rendu compte que le volume de la dette technique était si important que 3 mois ne suffiraient pas et nous devons continuer à travailler sur les questions techniques et reporter l'arriéré d'affaires. En fait, avec 6 équipes, nous n'avons créé qu'une seule fonctionnalité commerciale au cours de la prochaine année. Le reste du temps, les équipes se sont engagées dans le remboursement de la dette technique. Cette dette nous a coûté beaucoup - plus de 1,5 million de dollars.
Quelques améliorations après un an
Au cours de l'année, nous avons réalisé ces réalisations notables:
- Nous avons automatisé et accéléré notre pipeline de déploiement. Auparavant, le déploiement était semi-manuel. Nous avons été déployés dans 10 pays en environ 2 heures.
- A commencé à diviser un monolithe. La partie la plus chargée du système - le tracker - a été divisée en un service distinct, avec sa propre base de données. Maintenant, le tracker communique avec le reste du système via une file d'attente d'événements.
- Nous avons commencé à séparer le caissier de livraison - le deuxième composant qui crée une charge élevée.
- Réécriture du système d'authentification des utilisateurs et des appareils.
Notre architecte a géré l'arriéré technique. Nous avons utilisé les modifications architecturales pour générer l'arriéré. Chaque équipe avait la liberté de faire ce qui était juste pour créer une architecture utile. Pour l'année avec les 6èmes équipes, nous n'avons fait pour les affaires qu'une seule caractéristique précieuse. Le reste du temps, les équipes ont travaillé sur la dette technique. Il semblerait que nous pouvons être fiers de nous. Mais devant nous, il y avait une énorme déception.
Échec lors de la campagne de marketing fédérale. La deuxième crise de confiance.
La dette technique est facile à accumuler, mais très difficile à rembourser. Il est peu probable que vous puissiez comprendre à l'avance combien cela vous coûtera.
Malgré le fait que nous ayons passé une année entière à lutter contre la dette technique, nous n'étions pas prêts pour une campagne de marketing massive et nous avons foiré devant notre entreprise. Vous gagnez la confiance dans les gouttes, vous la perdez dans des seaux. Et nous avons dû le gagner à nouveau.
Nous avons manqué le moment où il fallait ralentir le développement des fonctionnalités de l'entreprise et s'attaquer à la dette technique. Il était trop tard quand nous l'avons remarqué. Nous nous couchons à nouveau sous charge. Le système s'est écrasé et redémarré toutes les 3 heures. Notre entreprise a perdu des dizaines de millions de roubles.

Mais grâce à la crise, nous avons vu que dans des conditions extrêmes, nous pouvons travailler plusieurs fois plus efficacement. Nous sortions 20 fois par jour. Tout le monde a travaillé comme une seule équipe, en se concentrant sur un seul objectif. Pendant deux semaines de crise, nous avons fait ce que nous avions peur de commencer auparavant car nous pensions que cela prendrait des mois de travail. Ordre asynchrone, tests de performances, journaux effacés ne sont qu'une petite partie de ce que nous avons fait. Nous étions impatients de continuer à travailler aussi efficacement, mais sans heures supplémentaires et sans stress.
Leçons apprises
Après la rétrospective, nous avons complètement restructuré nos processus. Nous avons pris le cadre LeSS et l'avons complété par des pratiques d'ingénierie. Au cours des prochains mois, nous avons fait une percée dans l'adoption des pratiques d'ingénierie. Sur la base du framework LeSS, nous avons implémenté et continuons à utiliser:
- carnet de commandes unique;
- équipes de fonctionnalités entièrement interfonctionnelles et multi-composants;
- programmation par paires;
- Essayer la programmation Mob.
- Véritable intégration continue, ce qui signifie plusieurs intégrations de code de 9 équipes dans une seule branche;
- gestion de configuration simplifiée avec développement basé sur les troncs;
- versions fréquentes: déploiement continu pour les microservices, plusieurs versions par jour pour le monolith;
- pas d'équipe QA distincte, les experts QA font partie des équipes de développement.
6 pratiques que nous avons choisies après la crise
1. Le pouvoir de la concentration . Avant la crise, chaque équipe travaillait sur son propre carnet de commandes et se spécialisait dans son domaine. Dans l'arriéré, il y avait des tâches finement décomposées, l'équipe a sélectionné plusieurs tâches pour un sprint. Mais pendant la crise, nous avons travaillé très différemment. Les équipes n'avaient pas de tâches spécifiques, elles avaient plutôt un gros objectif difficile. Par exemple, une application mobile et une API doivent traiter 300 commandes par minute, quoi qu'il arrive. C'est à l'équipe de savoir comment atteindre l'objectif. Les équipes formulent elles-mêmes des hypothèses, les vérifient rapidement en production et les jettent. Et c'est exactement ce que nous voulions continuer à faire. Les équipes ne veulent pas être des codeurs stupides, elles veulent résoudre des problèmes.
Le pouvoir de concentration s'est manifesté dans la résolution de problèmes complexes. Par exemple, pendant la crise, nous avons créé un ensemble de tests de performance malgré que nous n'avions aucune expertise. Nous avons également rendu la logique de réception d'une commande asynchrone. Nous y avons longuement réfléchi et discuté, et il nous a semblé que cette tâche est très difficile et longue. Mais il s'est avéré que l'équipe est tout à fait capable de le faire en 2 semaines, si elle n'est pas distraite et complètement concentrée sur le problème.
2. Hackathons réguliers . Nous aimions travailler dans le mode quand toutes les équipes visent un seul but et nous avons décidé d'organiser parfois de tels «hackathons». On ne peut pas dire que nous les réalisons régulièrement, mais il y en a eu plusieurs fois. Par exemple, il y a eu un hackathon de 500 erreurs lorsque toutes les équipes ont nettoyé les journaux et supprimé les causes de 500 erreurs sur le site et dans l'API. L'objectif était de garder les journaux propres. Lorsque les journaux sont propres, les nouvelles erreurs sont clairement visibles, vous pouvez facilement configurer les valeurs de seuil pour les alertes. C'est similaire aux tests unitaires - ils ne peuvent pas être un peu rouges.
Les bogues sont un autre exemple de hackathon. Nous avions un énorme backlog de bugs, certains des bugs étaient dans le backlog depuis des années. Il semblait qu'ils ne finiraient jamais. Et chaque jour, il y en avait de nouveaux. Vous devez en quelque sorte combiner le travail sur les bogues et les éléments de backlog réguliers.
Nous avons introduit la politique #zerobugspolicy en 4 étapes.- Nettoyage initial des bogues en fonction de la date. Si le bogue est dans le backlog depuis plus de 3 mois, supprimez-le simplement. Très probablement, il était là depuis des siècles.
- Maintenant, triez les défauts restants en fonction de leur incidence sur les clients. Nous avons soigneusement trié les bogues restants. Nous n'avons gardé que les défauts qui rendent la vie difficile à un grand groupe d'utilisateurs. Si c'est juste quelque chose qui cause des inconvénients, mais vous pouvez y faire face - supprimez impitoyablement. Nous avons donc réduit le nombre de bogues à 25, ce qui est acceptable.
- Hackathon. Toutes les équipes pullulent et corrigent tous les bugs. Nous l'avons fait en quelques sprints. Chaque sprint, chaque équipe a pris plusieurs bugs et l'a corrigé. Après 2-3 sprints, nous avions un carnet de commandes clair. Vous pouvez maintenant entrer #zerobugspolicy.
- #zerobugspolicy. Chaque nouveau bug n'a désormais que deux façons. Ether ça tombe dans l'arriéré, ou pas. S'il pénètre dans l'arriéré, nous le corrigeons en premier. Tout bogue dans le backlog a une priorité plus élevée que tout autre élément de backlog. Mais pour entrer dans le backlog, le bug doit être sérieux. Soit elle cause un préjudice irréparable, soit elle affecte un grand nombre d'utilisateurs.
3. Équipes de projet temporaires pour équipes fonctionnelles stables . Il y avait une histoire drôle avec les équipes de projet. Pendant la crise, nous avons formé des équipes de tigres composées des personnes les plus compétentes pour cette tâche. Après la fin de la crise, les équipes ont décidé de poursuivre cette pratique et de dissoudre les équipes. Malgré le fait que je n'aimais pas du tout cette idée, je les ai laissés essayer. En seulement 2 semaines (un sprint), lors de la prochaine rétrospective, les équipes ont abandonné cette pratique (cette décision m'a fait très plaisir). Ils ont essayé et compris pourquoi il est beaucoup plus confortable de travailler dans une équipe technique stable. Même si l'équipe manque de compétences, elle peut progressivement apprendre. Mais l'esprit d'équipe, le soutien et l'entraide se forment depuis longtemps, cela prend des mois. Les équipes de projet à court terme sont constamment en phase de formation et d'assaut. Vous pouvez le supporter pendant quelques semaines, mais vous ne pouvez pas travailler comme ça tout le temps. Il est bon que les équipes aient essayé et compris les avantages des équipes de fonctionnalités stables.
4. Débarrassez-vous de la régression manuelle . Avant la crise, nous sortions une fois par semaine et pendant la crise - des dizaines de fois par jour. Nous avons adoré notre capacité à sortir souvent. Nous avons apprécié à quel point il était pratique de faire un petit changement, de le déployer rapidement et d'obtenir immédiatement des commentaires de la production. Par conséquent, nous avons changé notre approche des versions, ce qui a affecté l'approche de programmation et de conception. Maintenant, nous sortons en continu, tous les 1-2 jours. Tout dans la branche dev est mis en production. Même si certaines fonctionnalités ne sont pas prêtes, ce n'est pas une raison pour ne pas publier le code. Si nous ne voulons pas montrer aux utilisateurs une fonctionnalité qui n'est pas encore prête, nous la cachons avec des bascules de fonctionnalité. Cette approche nous a permis de nous développer par petites étapes.
Nous nous sommes fixé pour objectif de nous débarrasser des régressions manuelles. Il nous a fallu un an et demi pour l'atteindre. Mais avoir un objectif ambitieux à long terme vous fait penser aux étapes menant à l'objectif.
Nous l'avons fait en 3 étapes.- Automatisez le chemin critique. En juin 2017, nous avons formé l'équipe QA. La tâche de l'équipe était d'automatiser la régression de la fonction la plus critique de Dodo IS - la prise de commandes et la production. Pour les 6 prochains mois, une nouvelle équipe AQ de 4 personnes a couvert l'ensemble du chemin critique. Les développeurs des équipes de fonctionnalités les ont activement aidés. Ensemble, nous avons écrit un langage DSL (Domain-Specific Language) beau et compréhensible, qui était lisible même par les clients. Parallèlement aux tests de bout en bout, les développeurs ont couvert le code avec des tests unitaires. Certains nouveaux composants ont été repensés avec TDD. Après cela, nous avons dissous l'équipe QA. Les anciens membres de l'équipe QA ont rejoint les équipes techniques pour partager leur expertise sur la prise en charge et la maintenance des autotests.
- Mode ombre. Ayant des autotests, pendant 5 versions nous avons fait des régressions manuelles en mode shadow. Les équipes ne se sont appuyées que sur une suite de tests automatisés, mais lorsque l'équipe a décidé «Nous sommes prêts à publier», nous exécutons une régression manuelle pour vérifier si nos autotests manquent des bogues. Nous avons suivi le nombre de bogues détectés manuellement et non détectés par les autotests. Après 5 versions, nous avons examiné les données et décidé que nous pouvions faire confiance à nos autotests. Aucun bogue majeur n'a été manqué.
- Supprimez les régressions manuelles. Lorsque nous avons eu suffisamment de tests pour que nous commencions à leur faire confiance, nous avons complètement abandonné les tests manuels. Plus nous effectuons nos tests, plus nous leur faisons confiance. Mais cela n'est arrivé que 1,5 an après que nous ayons commencé à automatiser les tests de régression.
5. Le test de performance fait partie du test de régression . Pendant la crise, nous avons créé un ensemble de tests de performance. C'était un domaine complètement nouveau pour nous. Néanmoins, en seulement 2 semaines, nous avons réussi à créer des tests de performances à l'aide des outils Visual Studio. Ces tests nous ont non seulement permis de détecter la dégradation des performances. Nous les avons utilisés pour ajouter une charge synthétique au serveur de production afin d'identifier les limites de performances. Par exemple, si la charge de production organique est de 100 commandes / min et que nous ajoutons 50 commandes / min supplémentaires à l'aide de nos tests de performances, nous pouvons voir si les serveurs de production peuvent gérer la charge accrue. Dès que nous remarquons des exceptions ou une latence accrue, nous arrêtons le test. En faisant ces expériences, nous avons déterminé la charge maximale que nos serveurs de production peuvent gérer et quel sera le point d'accès.
L'année prochaine, nous avons dépassé les tests de performance à une équipe expérimentée de PerformanceLab. Ils se sont réunis avec nos développeurs et les gens de l'infrastructure et nous ont aidés à créer un ensemble robuste de tests de performances. Maintenant, nous exécutons ces tests chaque semaine et fournissons un retour rapide aux équipes de développement si les performances sont affectées.
Certaines des pratiques d'ingénierie ont été affinées de manière itérative. Par exemple, des versions fréquentes. Nous avons commencé avec des cycles de publication hebdomadaires, soutenus par des tests manuels lents et fragiles. Nous avons développé des fonctionnalités pendant une semaine et testé pendant une autre semaine. Mais il était difficile de maintenir les modifications apportées par plusieurs pendant une semaine. Ensuite, nous avons essayé des versions d'équipe isolées, lorsque seules les modifications apportées par une seule équipe ont été publiées. Mais ce processus a échoué car chaque équipe a dû attendre plusieurs semaines dans la file d'attente. Ensuite, les équipes ont appris les avantages d'une intégration fréquente et nous avons commencé à pratiquer des versions jointes de plusieurs changements d'équipe. Les développeurs ont commencé à expérimenter avec la fonctionnalité bascule et à pousser vers la production de fonctionnalités inachevées. Finalement, nous sommes arrivés à l'intégration continue et à plusieurs versions par jour pour le monolithique et le déploiement continu pour les microservices.
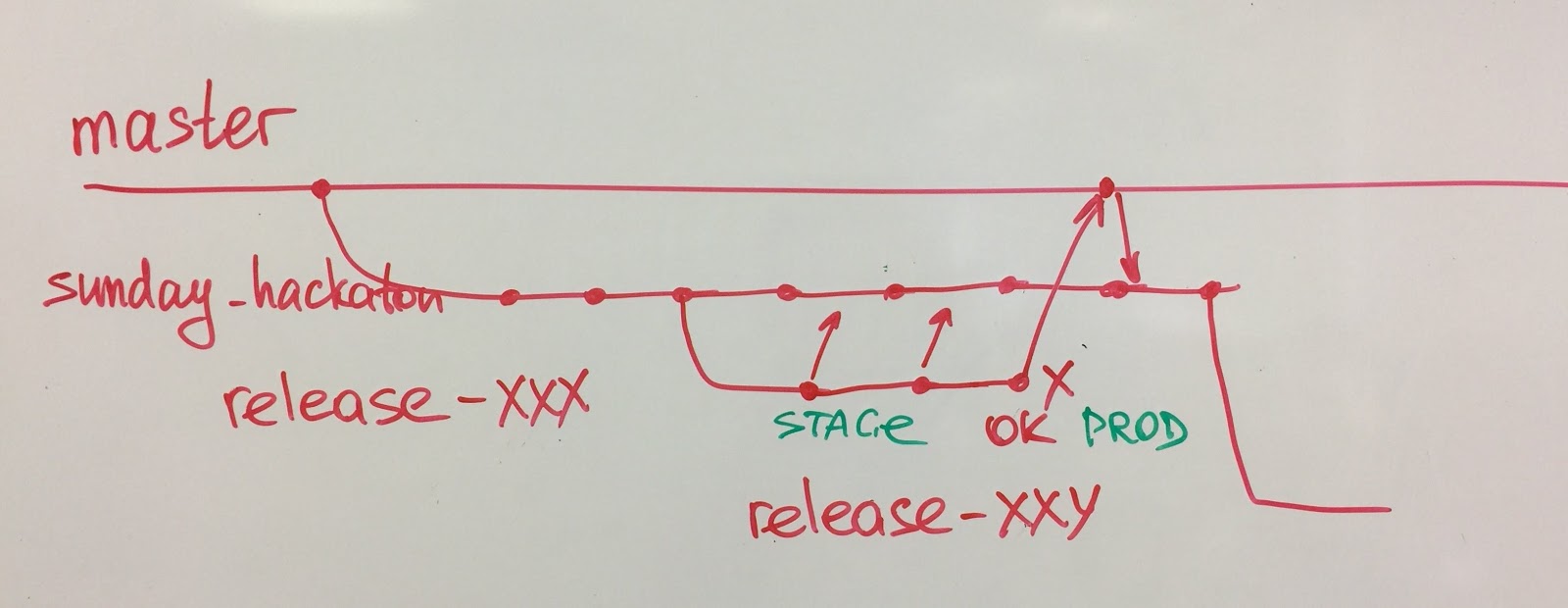
Un autre cas intéressant est celui de notre département AQ. Auparavant, nous n'avions pas d'équipe QA, mais plutôt des testeurs manuels. Réalisant le besoin d'automatisation des tests, nous avons formé une équipe d'assurance qualité, mais dès le premier jour, cette équipe savait qu'elle serait dissoute un jour. Après 6 mois, l'équipe a automatisé nos principaux scénarios commerciaux et, avec l'aide des développeurs, a rédigé un langage DSL (Domain Specific Language) pratique pour l'écriture des tests. L'équipe a éclaté et des ingénieurs de qualité ont rejoint les équipes techniques. Désormais, les équipes elles-mêmes développent et maintiennent des autotests.
Aujourd'hui, nous avons un seul carnet de commandes sur lequel 9 équipes techniques travaillent. Les équipes techniques sont des équipes stables, interfonctionnelles et multi-composants. La plupart de nos équipes sont des équipes spéciales.
6. Focus sur les pratiques d'ingénierie . Toutes nos équipes utilisent la programmation par paires. Je considère la programmation en binôme comme l'une des pratiques les plus simples mais les plus puissantes qui aident à mettre en œuvre d'autres pratiques d'ingénierie. Si vous ne savez pas quelle pratique d'ingénierie commencer, je recommande la programmation par paires.
Résultats
Le principal résultat que la crise nous a donné est un bouleversement. Nous nous sommes réveillés et avons commencé à agir. La crise nous a aidés à voir le maximum de nos opportunités. Nous avons vu que nous pouvons travailler plusieurs fois plus efficacement et atteindre rapidement nos objectifs. Mais cela nécessite de changer la façon de travailler habituelle. Nous avons cessé d'avoir peur de faire des expériences audacieuses. À la suite de ces expériences, au cours de l'année écoulée, nous avons considérablement amélioré la qualité et la stabilité de Dodo IS. Si pendant les vacances de printemps 2018 nos pizzerias ne pouvaient pas fonctionner à cause de Dodo IS, alors en 2019, avec une croissance de 300 à 450 pizzerias, Dodo IS fonctionnait parfaitement. Nous avons tranquillement connu le pic des ventes du nouvel an, lors de la deuxième campagne marketing et des vacances de printemps. Pour la première fois depuis longtemps, nous sommes confiants dans la qualité du système et dormons bien la nuit. Ceci est le résultat de l'utilisation constante des pratiques d'ingénierie et de l'accent mis sur l'excellence technique.
Résultats pour les entreprises
Les pratiques d'ingénierie ne sont pas nécessaires en elles-mêmes si elles ne profitent pas à votre entreprise. Grâce à l'accent mis sur l'excellence technique, nous améliorons la qualité du code et développons des fonctionnalités commerciales à une vitesse prévisible. Les sorties sont devenues un événement régulier pour nous. Nous publions le monolithe tous les 2 jours et des services plus petits toutes les quelques minutes. Cela signifie que nous pouvons rapidement offrir une valeur commerciale à nos utilisateurs et recueillir des commentaires plus rapidement. Grâce à la flexibilité des équipes de fonctionnalités, nous obtenons une vitesse de développement élevée.
Aujourd'hui, nous avons 480 pizzerias en ligne, dont 400 en Russie. Pendant les vacances de mai de cette année, il y a eu des problèmes avec le traitement des commandes dans nos pizzerias. Mais cette fois, le goulot d'étranglement était le service client dans les pizzerias. Dodo IS fonctionnait comme sur des roulettes, malgré le nombre croissant de pizzerias et de commandes.
Résultats pour les équipes
Aujourd'hui, nous utilisons un large éventail de pratiques d'ingénierie:
- Équipes de fonctionnalités entièrement interfonctionnelles et multi-composants.
- Programmation par paire / programmation Mob.
- Véritable intégration continue, ce qui signifie plusieurs intégrations de code de 9 équipes dans une seule branche.
- Gestion de configuration simplifiée avec développement basé sur tronc.
- Objectif commun à plusieurs équipes.
- Expert en la matière est dans l'équipe.
- Pas d'équipe QA distincte, les experts QA font partie des équipes de développement.
- Remplacement manuel éventuel de régression avec autotests.
- Politique zéro bogue.
- Carnet technique de la dette.
- Arrêtez la ligne en tant que pilote pour l'accélération du pipeline de déploiement.
Ils aident 9 équipes à travailler sur un code commun et un produit unique qui comprend des dizaines de composants - un site mobile et de bureau, une application mobile sur iOS et Android, et un back office géant avec caisse enregistreuse, suivi, affichage du restaurant, compte personnel , analyse et prévisions.
Quoi de mieux
Il peut sembler que nous avons déjà bien progressé dans les pratiques d'ingénierie, mais nous n'en sommes qu'au début, nous avons encore de la place pour grandir. Par exemple, nous essayons, mais jusqu'à présent de manière non systématique, la programmation mob. Nous étudions l'approche d'écriture de test BDD. Nous avons encore de la place pour grandir en CI, nous comprenons que l'intégration même une fois par jour ne suffit pas souvent. Et lorsque nous grossirons jusqu'à 30 équipes, il faudra s'intégrer plus souvent. Nous sommes toujours en cours de transition de TDD à ATDD. Nous devons créer un processus décisionnel architectural durable et évolutif.
La chose la plus importante est que nous nous sommes dirigés vers le renforcement de l'excellence technique.
Étant donné que les 9 équipes travaillent sur un carnet de commandes commun et sur un produit, les équipes ont une forte volonté de coopérer les unes avec les autres. Ils ont appris à prendre des décisions fortes eux-mêmes.
Par exemple, les pratiques suivantes ont été proposées et mises en œuvre par les équipes elles-mêmes.- Arrêtez la ligne en tant que pilote pour l'accélération du pipeline de déploiement (voir mon rapport d'expérience «Arrêtez la ligne pour rationaliser votre pipeline de déploiement»).
- Remplacez les tests d'interface utilisateur par des tests d'API.
- Déploiement automatisé en un seul clic.
- Hôte de Kubernetes.
- L'équipe de développement se déploie en production.
Certaines équipes ont manifesté le désir d'utiliser les 12 pratiques XP et m'ont demandé de l'aide en tant que XP Coach et Scrum Master.
Ce que nous avons appris
Je souhaite que je ne laisse pas la crise se produire. En tant que développeur, je me sentais personnellement responsable d'avoir accumulé une dette technique trop importante et de ne pas avoir levé le drapeau rouge plus tôt:
- Les pratiques d'ingénierie protègent les entreprises de la crise.
- N'accumulez pas de dettes techniques. Il peut être trop tard et coûter trop cher.
- Les changements évolutifs prennent plusieurs fois plus de temps que les changements révolutionnaires.
- La crise n'est pas toujours une mauvaise chose. Utilisez la crise pour révolutionner les processus.
- Cependant, une longue préparation évolutive est nécessaire à l'avance.
- N'appliquez pas aveuglément toutes les pratiques que vous aimez. Certaines pratiques attendent dans les coulisses, et quand il viendra, les équipes les utiliseront sans résistance. Attendez le bon moment.
- Affinez et adaptez les pratiques à votre contexte.
- Au fil du temps, les équipes elles-mêmes commencent à prendre des décisions solides et à les mettre en œuvre. Donnez-leur un environnement sûr pour essayer, échouer et apprendre les erreurs.
La dette technique nous conduit à la crise. Mais de la crise, les développeurs et les hommes d'affaires ont appris à quel point l'accent sur l'excellence technique et les pratiques d'ingénierie est important. Nous avons utilisé la crise comme déclencheur d'un changement organisationnel et de processus massif.
Remerciements
Je voudrais dire un grand merci à toutes les personnes qui m'ont aidé dans mon cheminement de la crise à la transformation LeSS. Je ressens constamment votre soutien.
Un grand merci à notre PDG, Fedor Ovchinnikov pour sa confiance. Vous êtes le véritable leader de l'entreprise avec une véritable culture agile.
Un grand merci à Dmitry Pavlov, notre Product Owner, mon vieil ami et co-formateur.
Merci Alex Andronov et Andrey Morevsky de m'avoir soutenu dans mon rôle.
Un grand merci à Dasha Bayanova, notre premier Scrum Master à plein temps, qui m'a cru et m'aide et me soutient toujours dans toutes nos initiatives. Votre aide est difficile à surestimer.
Un grand merci spécial à Johanna Rothman qui m'a aidé à rédiger ce rapport dans n'importe quelle condition: être en vacances, récupérer après une maladie. Johanna, ce fut un grand plaisir de travailler avec vous. Votre aide, vos conseils, votre attention aux détails et votre diligence sont très appréciés.