Introduction aux systèmes d'exploitation
Bonjour, Habr! Je veux attirer votre attention sur une série d'articles-traductions d'une littérature intéressante à mon avis - OSTEP. Cet article décrit assez en profondeur le travail des systèmes d'exploitation de type Unix, à savoir le travail avec les processus, les différents planificateurs, la mémoire et d'autres composants similaires qui composent le système d'exploitation moderne. L'original de tous les matériaux que vous pouvez voir
ici . Veuillez noter que la traduction a été effectuée de manière non professionnelle (assez librement), mais j'espère avoir conservé le sens général.
Les travaux de laboratoire sur ce sujet peuvent être trouvés ici:
Autres parties:
Et vous pouvez regarder ma chaîne en
télégramme =)
Alarme! Il y a un laboratoire pour cette conférence! regarder
githubAPI de processus
Prenons un exemple de création d'un processus sur un système UNIX. Il se produit via deux appels système
fork () et
exec () .
Appel Fork ()

Considérons un programme qui fait un appel fork (). Le résultat de sa mise en œuvre sera le suivant.
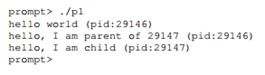
Tout d'abord, nous entrons dans la fonction main () et exécutons la sortie de la chaîne à l'écran. La chaîne contient l'identificateur de processus, qui dans l'original est appelé
PID ou identificateur de processus. Cet identifiant est utilisé sous UNIX pour faire référence à un processus. La prochaine commande appellera fork (). À ce stade, une copie presque exacte du processus est créée. Pour le système d'exploitation, il semble que le système fonctionne comme si 2 copies du même programme, qui à leur tour quitteront la fonction fork (). Le processus enfant nouvellement créé (par rapport au processus parent qui l'a créé) ne sera plus exécuté, à commencer par la fonction main (). Il ne faut pas oublier que le processus enfant n'est pas une copie exacte du processus parent, en particulier, il a son propre espace d'adressage, ses propres registres, son propre pointeur vers des instructions exécutables, etc. Ainsi, la valeur renvoyée à l'appelant de la fonction fork () sera différente. En particulier, le processus parent recevra la valeur PID du processus enfant en retour, et l'enfant recevra une valeur égale à 0. Sur la base de ces codes de retour, il est déjà possible de séparer les processus et de forcer chacun d'eux à faire son travail. De plus, l'exécution de ce programme n'est pas strictement définie. Après s'être divisé en 2 processus, l'OS commence également à les suivre et à planifier leur travail. Dans le cas d'une exécution sur un processeur monocœur, l'un des processus continuera de fonctionner, dans ce cas le parent, puis le processus enfant recevra le contrôle. Lorsque vous redémarrez, la situation peut être différente.
Appel en attente ()
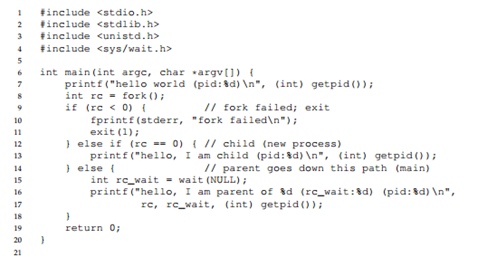
Considérez le programme suivant. Dans ce programme, en raison de la présence de l'appel
wait () , le processus parent attendra toujours que le processus enfant termine son travail. Dans ce cas, nous obtenons une sortie de texte strictement définie à l'écran.

Appelez exec ()

Considérez l'appel à
exec () . Cet appel système est utile lorsque nous voulons exécuter un programme complètement différent. Ici, nous appellerons
execvp () pour exécuter le programme wc, qui est un programme de comptage de mots. Que se passe-t-il lorsque exec () est appelé? Le nom du fichier exécutable et certains paramètres sont passés à cet appel comme arguments. Après cela, le code et les données statiques sont chargés à partir de ce fichier exécutable et effacés de leur propre segment avec le code. Les sections de mémoire restantes, telles que la pile et le tas, sont réinitialisées. Après quoi, le système d'exploitation exécute simplement le programme, en lui passant un ensemble d'arguments. Ainsi, nous n'avons pas créé de nouveau processus, nous avons simplement transformé le programme en cours d'exécution en un autre programme en cours d'exécution. Après l'exécution de exec (), le descendant donne l'impression que le programme d'origine semblait ne pas démarrer en principe.
Cette complication de lancement est tout à fait normale pour le shell Unix, et permet à ce shell d'exécuter du code après avoir appelé
fork () , mais avant d'appeler
exec () . Un exemple d'un tel code peut être de régler l'environnement du shell aux besoins du programme en cours de lancement, avant de le lancer directement.
Shell n'est qu'un programme utilisateur. Elle vous montre la ligne d'invite et attend que vous y écriviez quelque chose. Dans la plupart des cas, si vous y écrivez le nom du programme, le shell trouvera son emplacement, appellera la méthode fork (), puis pour créer un nouveau processus, il appellera certains des types exec () et attendra qu'il soit exécuté en utilisant l'appel wait (). Une fois le processus enfant terminé, le shell revient de l'appel wait () et affiche à nouveau l'invite et attend que la prochaine commande soit entrée.
La séparation de fork () & exec () permet au shell de faire les choses suivantes, par exemple:
fichier wc> nouveau_fichier.Dans cet exemple, la sortie de wc est redirigée vers un fichier. La façon dont le shell y parvient est assez simple - lors de la création d'un processus enfant avant d'appeler
exec () , le shell ferme le flux de sortie standard et ouvre le fichier
new_file , de sorte que toutes les sorties du programme
wc démarré seront redirigées vers le fichier au lieu de l'écran.
Les canaux Unix sont implémentés de la même manière, à la différence près qu'ils utilisent l'appel pipe (). Dans ce cas, le flux de sortie du processus sera connecté à la file d'attente de tuyaux située dans le noyau auquel le flux d'entrée d'un autre processus sera attaché.