L'apprentissage automatique est utilisé tout au long du cycle de commande de voitures Yandex.Taxi, et le nombre de composants de service fonctionnant grâce à ML est en constante augmentation. Pour les construire de manière uniforme, nous avions besoin d'un processus distinct. Roman Khalkachev, responsable du service d'apprentissage automatique et d'analyse des données, a parlé du prétraitement des données, de l'utilisation des modèles en production, du service de prototypage et des outils associés.
- À mon avis, certaines nouvelles choses sont beaucoup plus faciles à percevoir lorsqu'elles sont racontées sur un exemple simple. Par conséquent, afin que le rapport ne soit pas sec, j'ai décidé de parler d'une des tâches que nous résolvons. En utilisant son exemple, je montrerai pourquoi nous agissons de cette façon.
Formulons le problème. Il y a des utilisateurs de taxi qui doivent se rendre du point A au point B, et il y a des chauffeurs qui sont prêts pour un certain montant à livrer ces utilisateurs du point A au point B. L'utilisateur a plusieurs conditions dans lesquelles il se trouve. Il appelle un taxi, sélectionne le point A, le point B, le tarif, etc., fait un atterrissage en taxi, monte et finalement atterrit. Aujourd'hui, je voudrais parler de monter dans une voiture et des problèmes qui peuvent survenir.

En règle générale, ces problèmes sont liés au fait qu'une personne doit choisir un endroit où un taxi doit venir. Et ici, il y a un certain nombre de difficultés. Ces difficultés sont liées à quatre choses que j'ai énumérées sur la diapositive.
Tout d'abord, l'emplacement peut ne pas être familier à l'utilisateur. À titre d'exemple, vous pouvez vous imaginer qui est venu dans un grand centre commercial, dans lequel vous ne visitez pas souvent. Vous voulez partir, et vous ne savez pas vraiment où appeler un taxi ici, où la voiture peut appeler, mais où elle ne peut pas, par exemple, à cause de la barrière. Il y a des problèmes avec le fait que dans certains endroits, il y a beaucoup de monde, beaucoup de voitures et il vous est difficile de trouver votre voiture. Il y a des endroits où les gens montent habituellement dans la voiture, c'est plus facile de s'y rendre. Et vous ne le savez peut-être pas, étant dans un nouvel endroit, pas nécessairement dans le centre commercial, où exactement atterrir. Les difficultés peuvent être liées au fait que le conducteur ne peut pas se rendre à l'endroit où vous avez appelé le taxi: il est interdit de voyager, il y a une grande sortie du centre commercial, en face de laquelle vous ne pouvez pas vous arrêter, etc.
En revanche, vous pouvez avoir des problèmes en tant qu'utilisateur. Le chauffeur est arrivé, tout va bien, mais vous êtes mal à l'aise de vous asseoir, car tout le monde a déterré. Vous demandez au conducteur de conduire ailleurs. Il y a d'autres raisons.
L'exemple le plus illustratif, la quintessence de tout ce qui précède, est l'aéroport, dans lequel presque tout est fait. Même si vous sortez très souvent de Chérémétiévo, c'est toujours un endroit que vous ne connaissez pas, car beaucoup de choses y changent souvent. Il y a beaucoup de gens, beaucoup de voitures, il y a des endroits pratiques pour atterrir, il y en a qui sont inconfortables, mais en règle générale, aucun de nous ne s'en souvient.
La solution est lue à partir du titre de la diapositive. Recommandons à l'utilisateur des endroits dans lesquels, à notre avis, il est pratique d'atterrir. La pensée semble évidente, mais il y a beaucoup de nuances ici.
Pour commencer, «pratique» est un concept subjectif. Il semble qu'avant de résoudre le problème, il est nécessaire de formuler certains critères pour que le problème soit résolu correctement. Nous en avons formulé trois pour nous-mêmes. Le premier critère est comme dans toute tâche de recommandations: probablement, les recommandations sont bonnes si elles sont utilisées. Si nous montrons de tels points à partir desquels l'utilisateur partira vraiment - ce sont probablement de bons points. Mais bien sûr, ce n'est pas tout, car vous pouvez apprendre à recommander quelque chose, à le montrer, à encourager l'utilisateur à l'utiliser, mais vous ne pouvez pas obtenir de profit tangible (nous n'obtiendrons pas en tant que système, ni utilisateur, ni pilote). Par conséquent, il est très important d'examiner d'autres mesures. Nous en avons choisi deux.
Si nous vous parlons d'un lieu d'atterrissage où le conducteur peut facilement se rendre, le délai de livraison du véhicule devrait être réduit. En revanche, s'il est plus facile pour l'utilisateur de trouver une voiture à cet endroit, il est plus facile d'atterrir, alors le temps d'attente du conducteur par le conducteur doit être réduit. C'est une partie de notre hypothèse, que nous tenons pour acquise, et ce sont des paramètres que nous examinons lorsque nous faisons ces recommandations. Mais bien sûr, ce ne sont pas les seules mesures à examiner. Vous pouvez en trouver une douzaine de plus. Je pense que chacun de vous peut proposer une centaine de ces mesures.
Voici quelques exemples supplémentaires. Cela peut être la proportion des annulations avant le voyage. En théorie, il devrait diminuer s'il est plus facile pour l'utilisateur de se poser. Classiquement, il s'agit d'appels lorsqu'un utilisateur appelle le conducteur essayant de le trouver, ou, inversement, le conducteur appelle l'utilisateur avant le début du trajet. Cet appel est en faveur, et avec une dizaine d'autres.
Nous avons formulé le problème. Nous avons approximativement compris le critère que nous pouvons résoudre ce problème. Voyons maintenant comment résoudre ce problème. La première chose qui vous vient à l'esprit: recommandons ces points d'atterrissage éprouvés et compréhensibles. Ici sur la diapositive est un exemple du centre commercial européen. Et nous savons avec certitude que vous pouvez conduire jusqu'aux sorties de ce centre commercial, et c'est une sorte de directive, grâce à laquelle l'utilisateur peut trouver un chauffeur. Il peut s'agir de n'importe quelle organisation. Il y a un exemple avec l'ABC du goût dans un centre commercial. À mon avis, c'est Yerevan Plaza. Il s'agit également d'une sorte de directive pour l'utilisateur et le pilote, à propos de laquelle nous savons que vous pouvez y conduire.
Ce sont peut-être des points de repère dans les aéroports dont j'ai parlé. Conventionnellement, il y a de tels pôles à Sheremetyevo avec des numéros. Il est pratique d'appeler un taxi et de monter dans la voiture. Une bonne solution, mais elle a le moins qu'elle n'est pas très évolutive. Nous avons de nombreux pays, des centaines de villes, un grand nombre de centres commerciaux différents, des aéroports, des échangeurs difficiles, des endroits inconnus pour lesquels ces points sont difficiles à faire manuellement, et les tenir à jour est encore plus difficile. C'est ici que vient à notre secours ce qu'on appelle à haute voix «l'intelligence artificielle». Je préfère l'appeler exploration de données ou apprentissage automatique.
L'apprentissage automatique a besoin d'une sorte de données, et nous avons en fait ces données. Une autre façon de résoudre automatiquement le problème consiste à utiliser ces données. L'idée de haut niveau est que nous avons des données sur le GPS, les journaux des applications et un graphique routier. Et nous pouvons comprendre où les utilisateurs montent réellement dans la voiture. Pas les points où ils appellent la voiture, mais où ils atterrissent. Et sur cette base, faites quelque chose comme ça.

Ce sont déjà des points reçus automatiquement pour le centre d'affaires Aurora, où notre équipe Yandex.Taxi est actuellement assise.
J'ai parlé de haut niveau de notre tâche. Parlons maintenant plus en détail des étapes de la solution à ce problème. Il est clair qu'il y a une étape de préparation des données.

De quelles données disposons-nous? Premièrement, nous avons les données GPS de nos utilisateurs et les données GPS de nos chauffeurs. Lorsqu'ils utilisent notre application, nous connaissons l'emplacement approximatif des utilisateurs. Il est clair que le GPS a une grosse erreur, de l'ordre de 13 à 15 mètres, mais néanmoins, il y a quelque chose. Deuxièmement, nous avons des informations contenues dans les journaux d'application sur le moment où le conducteur est passé de l'état «J'attends l'utilisateur» à l'état «Je prends l'utilisateur». On peut supposer qu'à peu près à ce moment-là, le conducteur a attendu l'utilisateur, l'utilisateur est monté dans la voiture et ils sont partis. Autour de cet endroit, un atterrissage a été effectué. Et nous avons un graphique de route. Un graphique routier n'est pas seulement un ensemble de bords, de rues, mais aussi des méta-informations supplémentaires: barrières, informations sur le stationnement, etc. Sur la base de ces données, vous pouvez déjà obtenir une sorte de points automatiques.
Ce sont les données sources. Et à la sortie, nous voulons deux choses. Ce sont des soi-disant candidats au point d'atterrissage. Comment viennent-ils? Dommage qu’il n’ait pas été possible de montrer la vidéo. Ce qui suit se produit approximativement. Nous avons de nombreux points GPS dans lesquels nous savons que le conducteur est passé du statut «En attente d'un passager» au statut «Allons-y». Nous pouvons, conditionnellement, les dessiner sur le graphique, c'est-à-dire les projeter sur le graphique de la route, car, en règle générale, la voiture commence à se déplacer d'une route. Sur ce graphique, effectuez une sorte de regroupement de ces points. Et pour obtenir un grand nombre de candidats - ce sont des endroits où certains utilisateurs sont montés dans la voiture, et c'était normal, pratique pour eux. Pas où ils ont appelé, mais où ils ont fini par s'asseoir.
Après cela, lorsque nous avons beaucoup de candidats et que nous avons un utilisateur en ligne, nous connaissons son emplacement, alors il a ouvert l'application et veut appeler un taxi, alors nous pouvons choisir les cinq meilleurs parmi un grand nombre de candidats et les montrer. Les cinq meilleurs sont déterminés par un modèle d'apprentissage automatique qui apprend à classer tous les candidats en fonction de la probabilité que l'utilisateur en ce moment, en tenant compte de son emplacement et de son historique de voyage, soit le plus pratique pour quitter. Et approximativement de cette façon, nous pouvons générer automatiquement ces points. De plus, si à un moment donné ils creusent conditionnellement quelque part, c'est-à-dire qu'il devient inconfortable d'appeler un taxi, ou quelque part ils mettent un panneau interdisant un arrêt, et les conducteurs et les utilisateurs arrêtent vraiment d'atterrir à cet endroit, puis à certains moments au moment où l'algorithme comprendra cela et les données seront mises à jour.
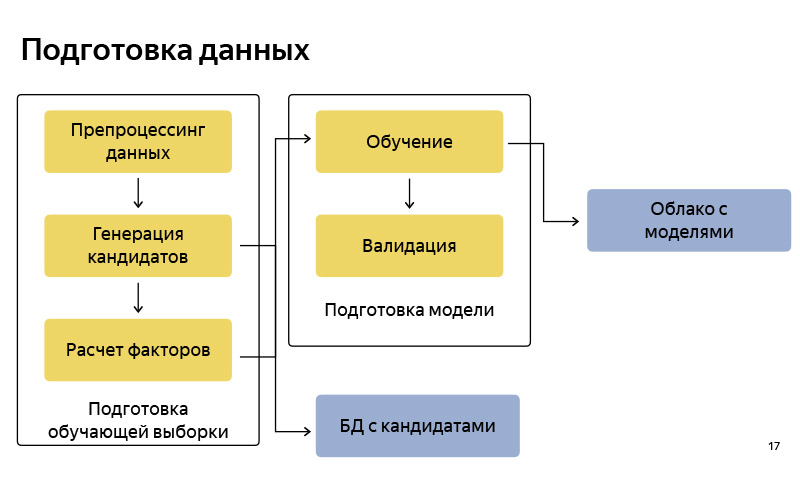
Il s'agit approximativement du schéma fonctionnel de la façon dont nous préparons les données. En conséquence, il est assez standard, comme dans tout pipeline d'apprentissage automatique. Il y a la préparation des données, il y a une génération de candidats selon l'algorithme, ai-je dit une version simplifiée. Nous stockons ces candidats dans une certaine base de données. Après cela, nous préparons un pool de formation (échantillon de formation), dans lequel il y a, conditionnellement, un utilisateur, du temps, des méta-informations, un ensemble de candidats, et on sait à partir de quel point l'utilisateur a finalement quitté. Sur cela, nous formons le modèle de classification. Et puis, selon les prédictions de probabilité, nous classons les candidats. Lorsque le modèle est prêt, nous le téléchargeons sur un cloud, où il est bien stocké.
Quels outils utilisons-nous pour préparer les données? Fondamentalement, toute la préparation des données que nous avons écrite en Python, sur la pile Python: ce sont NumPy standard, Pandas, Scikit-learn, etc. Nous avons beaucoup de données. Nous avons des millions de voyages par mois. Beaucoup de données sur le GPS, sur les traces des pilotes, les journaux d'application, nous devons donc les traiter tous de la même manière sur le cluster. Pour ce faire, nous utilisons MapReduce de notre version intra-Yandex, qui s'appelle YT, et il y a une bibliothèque écrite en Python, qui permet de lancer certains mappeurs et réducteurs, et de faire des calculs sur un grand cluster.
Enfin, lorsque le pipeline est prêt, nous devons l'automatiser pour que les données soient à jour, et pour cela, nous utilisons une chose telle que Nirvana et Hitman. Il s'agit également d'un développement intra-Yandex. Nirvana est un cadre de gestion informatique en grappe. En fait, elle sait comment exécuter à peu près n'importe quel programme, être tolérante aux pannes, être cross DC (00:14:53). Et dans le cas où quelque chose tombe, elle sait comment le redémarrer, pour créer des lancements à la survenance de tout événement. etc.

C'est à peu près à quoi ressemble l'interface Web de notre cluster MapReduce. On peut voir ici que nous avons beaucoup de machines, de tels nœuds sur lesquels des calculs sont effectués.
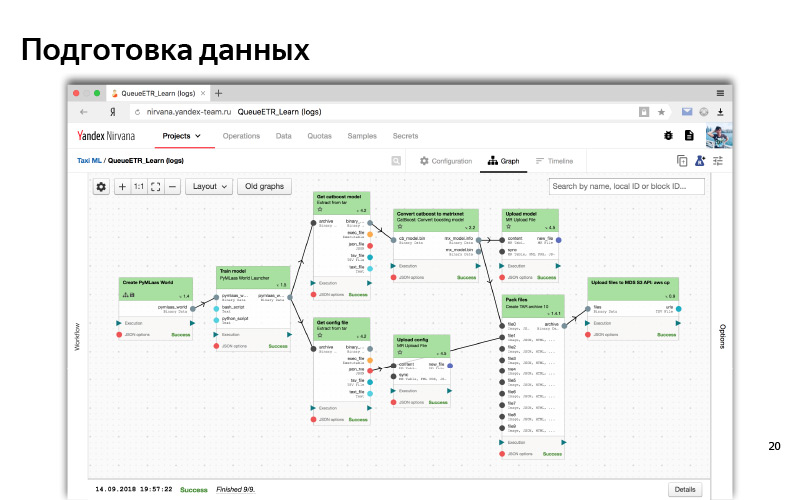
Ainsi, dans l'interface Web, un processus typique de prétraitement des données et de formation aux modèles apparaît. Il s'agit d'un tel graphique de dépendance. Les dépendances sont comme des données, lorsqu'une partie (un cube) attend les données d'un autre cube; et la dépendance logique (nous avons d'abord préparé toutes les données, puis commencé la formation). Il s'agit d'une sorte de système automatisé. Pour tout cela, nous utilisons généralement Python.
Nous avons formulé le problème, formulé des critères de réussite, appris à le résoudre en quelque sorte hors ligne, nous avons même créé une sorte de modèle, et cela semble fonctionner selon certaines mesures hors ligne - il prédit vraiment les points à partir desquels l'utilisateur quitte et trouve ces points ce qui, semble-t-il, devrait réduire le temps d'attente et la livraison de la voiture.

Essayons ces modèles, utilisons ces données. Pour ce faire, imaginez ce qu'est le service Yandex.Taxi.
Un diagramme très superficiel ressemble à ceci. Il y a des utilisateurs, ils ont une application, et il y a des pilotes, ils ont aussi une application appelée «Taximètre». Ces applications communiquent en quelque sorte avec le backend, et le backend est un ensemble de microservices qui communiquent entre eux - Ilya en a
parlé . L'un des microservices est notre service, notre équipe le fait, il s'appelle ML as a Service, MLaaS.

Tout ce que vous devez savoir à son sujet est un MLaaS écrit en C ++, basé sur le soi-disant démon Fastcgi. Il s'agit d'une bibliothèque open source, qui, grosso modo, est un framework pour écrire un serveur web qui peut recevoir et poster des requêtes, tout est standard. Il a été écrit une fois en Yandex, présenté en open source. Nous utilisons la version doppée. Que peut faire ce service? Il sait comment travailler avec des modèles: appliquez-les, gardez-les à la maison et parfois mettez à jour, rendez-vous dans ce merveilleux cloud, où les modèles sont régulièrement mis à jour, enregistrés et téléchargés.
Chaque fonctionnalité, par exemple, ces points d'atterrissage - à l'intérieur, nous les appelons des points de ramassage - ou, par exemple, les pointes des points B dont Ilya a parlé et qui se brisent constamment dans le rapport précédent, chacune de ces fonctionnalités, où il existe une sorte d'apprentissage automatique, correspond à gestionnaire, qui stocke la logique de réception d'une demande, de génération de facteurs d'apprentissage automatique, d'application de modèles et de génération d'une réponse. Bien sûr, ce service n'est pas isolé, car il peut accéder à certaines sources de données, bases de données et autres microservices supplémentaires.
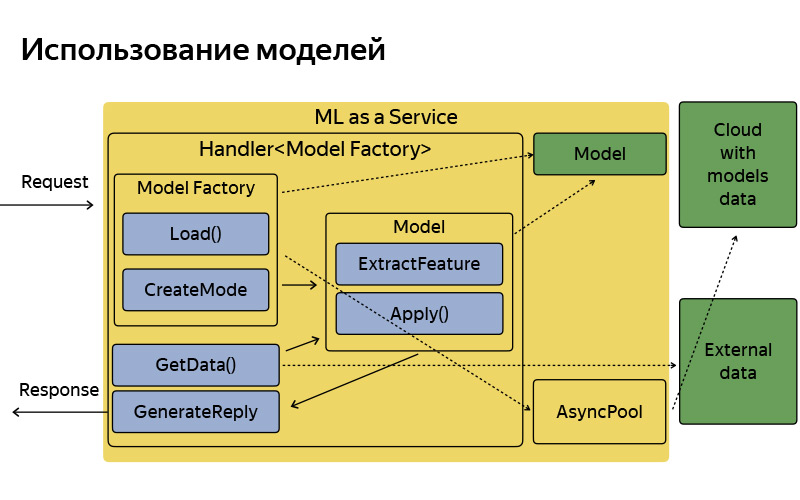
Voilà comment il est organisé, il a une architecture assez simple. Je ne voulais pas m'attarder sur cette diapositive en détail, je voulais juste dire que, par convention, l'architecture est très simple. La demande arrive, il existe une usine de modèles, qui télécharge parfois ces modèles depuis le cloud. En mémoire, ils sont stockés en une seule copie. Pour chaque demande, un objet modèle plutôt léger est créé, qui extrait les fonctionnalités, applique et génère une réponse.

Mais qu'avons-nous pour l'instant? Je vous ai déjà dit que nous avons la préparation des données, la formation, diverses études, expériences, et tout cela est écrit en Python Stack, et il y a une production qui est écrite en C ++, simplement parce que nous avons de grandes exigences d'efficacité et de productivité. Lorsque vous vivez dans un tel écosystème, deux problèmes se posent.
Tout d'abord, c'est un problème d'expériences. Par exemple, un data scientist qui travaille dans notre équipe a eu une idée. Si vous exécutez une sorte d'algorithme de clustering ou de classification avec des paramètres légèrement différents, vous pouvez obtenir une meilleure qualité. Il a essayé de tester son hypothèse hors ligne, intégré à notre processus Python, l'a calculé, et cela se révèle vraiment. Et maintenant, il veut une expérience AB, c'est-à-dire une partie des utilisateurs pour montrer le nouvel algorithme et mesurer certaines métriques déjà en ligne: le temps diminue-t-il vraiment, attendez, l'utilisation augmente. Pour ce faire, il a conditionnellement cinq versions de son algorithme, selon lui, qui offrent une bonne qualité hors ligne: implémenter en C ++ et mener une expérience AB. Et après cette expérience AB, peut-être que tous les cinq iront au rebut, c'est-à-dire que leur qualité en ligne se révélera pire qu'elle ne l'était hors ligne, c'est-à-dire pire qu'en production. Autrement dit, le processus d'expérimentation prend beaucoup de temps en raison du fait que, conditionnellement, deux langues différentes, deux technologies différentes.
C'est pour les fonctionnalités existantes. Et il y en a de nouveaux. Une fois que ces points de ramassage étaient aussi des idées que je voulais vérifier rapidement. N'y passez pas deux mois de développement - il est conseillé d'obtenir quelque chose en trois semaines. Créer un tel prototype est assez laborieux. Tout d'abord, écrivez en Python l'extraction des fonctionnalités, simplement parce que c'est pratique - avancez vite, comme on dit. Vous pouvez construire n'importe quel prototype en Python, il existe de nombreuses bibliothèques pour l'analyse des données. Vous avez expérimenté sur votre ordinateur portable et vous souhaitez maintenant vérifier les utilisateurs. Et faire un prototype s'est avéré assez difficile. Nous sommes arrivés à la conclusion que nous avons besoin d'un service supplémentaire pour assembler ces prototypes assez rapidement - conditionnellement, en une semaine ou même en une journée - et également pour mener des expériences AB.
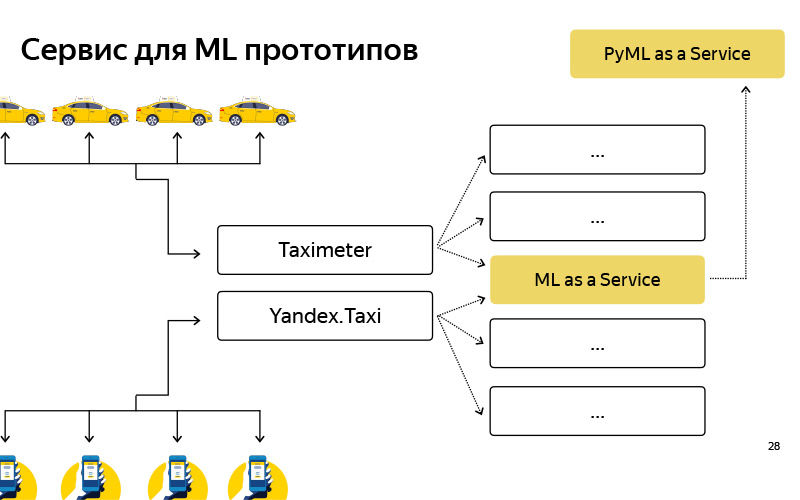
Nous avons créé un tel service, appelé PyMLaaS. Comment est-il? , MLaaS, , Python Flask, nginx Gunicorn. , , MLaaS, - -. nginx, , , MLaaS PyMLaaS .

- , . 5% PyMLaaS, , . , . - , PyMLaaS .
, — ? , , , , 1000 RPS, . . - , - , , , RPS , .

Pour résumer. , . . . , - , , , -, - . - PyMLaaS, AB-, . , MLaaS, , .
pickup points — . . , . 30% , . .