Le 26 février, nous avons organisé le mitap Apache Ignite GreenSource, où les contributeurs du projet open source
Apache Ignite ont joué. Un événement important dans la vie de cette communauté a été la restructuration du composant
Ignite Service Grid , qui vous permet de déployer des microservices personnalisés directement dans le cluster Ignite.
Vyacheslav Daradur , développeur senior de Yandex et contributeur d'Apache Ignite depuis plus de deux ans, a parlé de ce processus difficile lors de la réunion.
Pour commencer, qu'est-ce qu'Apache Ignite en général. Il s'agit d'une base de données qui est un référentiel de clé / valeur distribué avec prise en charge de SQL, transactionnel et de mise en cache. De plus, Ignite vous permet de déployer des services utilisateur directement dans le cluster Ignite. Le développeur devient disponible tous les outils qu'Ignite fournit - structures de données distribuées, messagerie, streaming, calcul et grille de données. Par exemple, lors de l'utilisation de la grille de données, le problème de l'administration d'une infrastructure distincte pour l'entrepôt de données et, par conséquent, la surcharge qui en résulte disparaît.

À l'aide de l'API Service Grid, vous pouvez déployer un service en spécifiant simplement le schéma de déploiement dans la configuration et, en conséquence, le service lui-même.
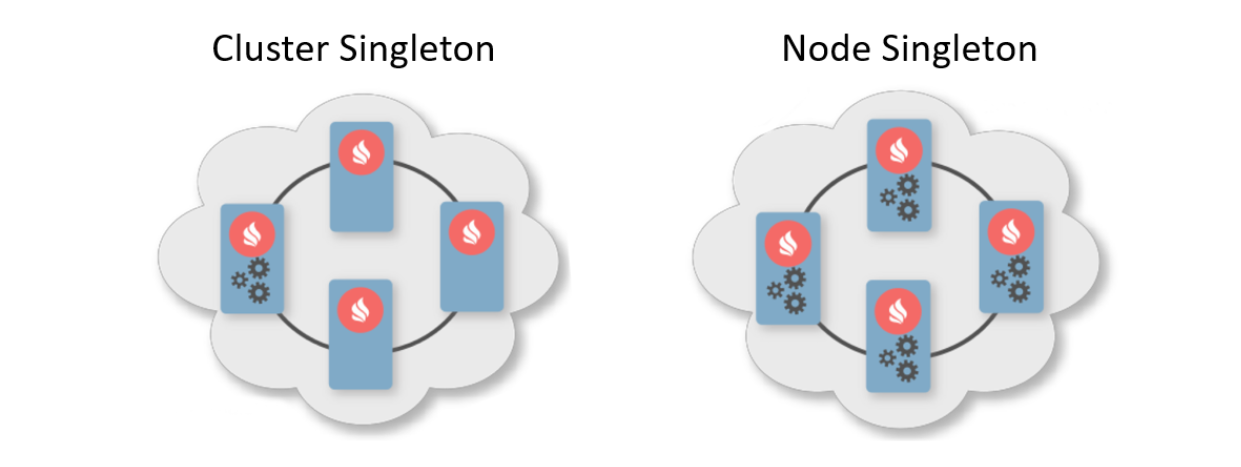
En règle générale, un modèle de déploiement indique le nombre d'instances à déployer sur les nœuds de cluster. Il existe deux modèles de déploiement typiques. Le premier est Cluster Singleton: à tout moment dans le cluster, une instance du service utilisateur sera garantie d'être disponible. Le second est Node Singleton: une instance du service est déployée sur chaque nœud du cluster.
L'utilisateur peut également spécifier le nombre d'instances de service dans l'ensemble du cluster et définir un prédicat pour filtrer les nœuds appropriés. Dans ce scénario, la grille de services calculera elle-même la distribution optimale pour le déploiement des services.
En outre, il existe une fonctionnalité telle que le service d'affinité. L'affinité est une fonction qui définit la relation des clés avec les partitions et la relation des parties avec les nœuds dans la topologie. À l'aide de la clé, vous pouvez déterminer le nœud principal sur lequel les données sont stockées. Ainsi, vous pouvez associer votre propre service à la clé et au cache de la fonction d'affinité. Si la fonction d'affinité change, une nouvelle opération automatique se produit. Ainsi, le service sera toujours placé à côté des données qu'il doit manipuler et, par conséquent, réduira les frais généraux d'accès à l'information. Un tel schéma peut être appelé une sorte d'informatique colocalisée.
Maintenant que nous avons compris la beauté de Service Grid, nous allons vous parler de son historique de développement.
Ce qui était avant
L'implémentation précédente de Service Grid était basée sur le cache système répliqué transactionnel Ignite. Le mot "cache" dans Ignite signifie stockage. Autrement dit, ce n'est pas quelque chose de temporaire, comme vous pourriez le penser. Malgré le fait que le cache est réplicable et que chaque nœud contient l'ensemble de données complet, à l'intérieur du cache, il a une vue partitionnée. Cela est dû à l'optimisation du stockage.

Que s'est-il passé lorsqu'un utilisateur a voulu déployer un service?
- Tous les nœuds du cluster se sont abonnés pour mettre à jour les données dans le référentiel à l'aide du mécanisme de requête continue intégré.
- Un nœud initiateur sous une transaction validée en lecture a effectué un enregistrement dans la base de données qui contenait la configuration du service, y compris l'instance sérialisée.
- Dès réception de la notification d'un nouvel enregistrement, le coordinateur a calculé la distribution en fonction de la configuration. L'objet résultant est réécrit dans la base de données.
- Les nœuds lisent des informations sur la nouvelle distribution et les services déployés pour
si nécessaire.
Ce qui ne nous convenait pas
À un moment donné, nous sommes arrivés à la conclusion: il est impossible de travailler avec des services. Il y avait plusieurs raisons.
Si une sorte d'erreur s'est produite pendant le déploiement, vous ne pouvez le découvrir que dans les journaux du nœud où tout s'est produit. Il n'y avait qu'un déploiement asynchrone, donc après avoir renvoyé le contrôle de la méthode de déploiement à l'utilisateur, il a fallu un certain temps supplémentaire pour démarrer le service - et à ce moment-là, l'utilisateur ne pouvait rien contrôler. Pour développer davantage la Grille de services, voir de nouvelles fonctionnalités, attirer de nouveaux utilisateurs et faciliter la vie de tous, vous devez changer quelque chose.
Lors de la conception d'une nouvelle Grille de Services, nous avons tout d'abord voulu apporter une garantie de déploiement synchrone: dès que l'utilisateur revenait au contrôle de l'API, il pouvait immédiatement utiliser les services. Je voulais également donner à l'initiateur la possibilité de gérer les erreurs de déploiement.
De plus, je souhaitais faciliter la mise en œuvre, à savoir m'éloigner des transactions et du rééquilibrage. Malgré le fait que le cache est réplicable et qu'il n'y a pas d'équilibrage, il y a eu des problèmes lors d'un déploiement important avec de nombreux nœuds. Lors du changement de topologie, les nœuds doivent échanger des informations et avec un déploiement important, ces données peuvent peser beaucoup.
Lorsque la topologie était instable, le coordinateur devait recalculer la distribution des services. Et en général, lorsque vous devez travailler avec des transactions sur une topologie instable, cela peut entraîner des erreurs difficiles à prévoir.
Les problèmes
Quels changements globaux sans problèmes d'accompagnement? Le premier d'entre eux était un changement de topologie. Vous devez comprendre qu'à tout moment, même au moment du déploiement du service, un nœud peut entrer ou sortir d'un cluster. De plus, si au moment du déploiement le nœud entre dans le cluster, il sera nécessaire de transférer systématiquement toutes les informations sur les services vers le nouveau nœud. Et nous parlons non seulement de ce qui a déjà été déployé, mais aussi des déploiements actuels et futurs.
Ce n'est là qu'un des problèmes qui peuvent être regroupés dans une liste distincte:
- Comment déployer des services configurés statiquement lors du démarrage d'un nœud?
- Sortie de nœud du cluster - que faire si les services d'hôte hôte?
- Que faire si le coordinateur a changé?
- Que faire si le client s'est reconnecté au cluster?
- Dois-je traiter les demandes d'activation / désactivation et comment?
- Mais que se passe-t-il s'ils appellent le cache Destroy et que nous avons des services d'affinité qui y sont liés?
Et ce n’est pas tout.
Solution
Comme cible, nous avons choisi l'approche Event Driven avec la mise en place de processus de communication utilisant des messages. Ignite a déjà implémenté deux composants qui permettent aux nœuds de transmettre des messages entre eux - communication-spi et discovery-spi.
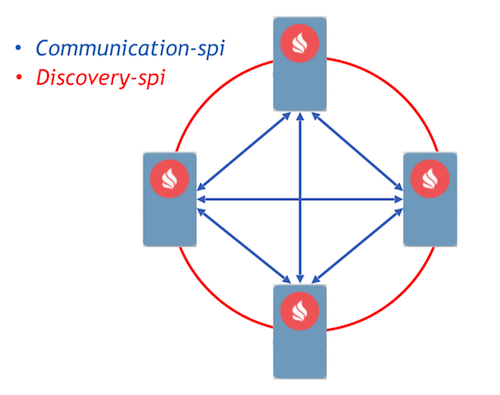
Communication-spi permet aux nœuds de communiquer et de transmettre des messages directement. Il est bien adapté pour l'envoi de grandes quantités de données. Discovery-spi vous permet d'envoyer un message à tous les nœuds du cluster. Dans une implémentation standard, cela se fait selon la topologie en anneau. Il existe également une intégration avec Zookeeper, dans ce cas, la topologie en étoile est utilisée. Un autre point important à noter: discovery-spi garantit que le message sera livré dans le bon ordre à tous les nœuds.
Considérez le protocole de déploiement. Toutes les demandes de déploiement et de distribution des utilisateurs sont envoyées via discovery-spi. Cela donne les
garanties suivantes:
- La demande sera reçue par tous les nœuds du cluster. Cela vous permettra de poursuivre le traitement de la demande lors du changement de coordinateur. Cela signifie également que dans un message, chaque nœud aura toutes les métadonnées nécessaires, telles que la configuration du service et son instance sérialisée.
- Un ordre de livraison de message strict vous permet de résoudre les conflits de configuration et les demandes concurrentes.
- Étant donné que l'entrée du nœud dans la topologie est également traitée par discovery-spi, toutes les données nécessaires pour travailler avec les services parviendront au nouveau nœud.
Dès réception de la demande, les nœuds du cluster la valident et forment des tâches à traiter. Ces tâches sont mises en file d'attente puis traitées dans un autre thread par un travailleur distinct. Ceci est implémenté de cette manière, car un déploiement peut prendre un temps considérable et retarder un flux de découverte coûteux est inacceptable.
Toutes les demandes de la file d'attente sont traitées par le gestionnaire de déploiement. Il a un travailleur spécial qui extrait une tâche de cette file d'attente et l'initialise pour commencer le déploiement. Après cela, les actions suivantes se produisent:
- Chaque nœud calcule indépendamment la distribution grâce à une nouvelle fonction d'affectation déterministe.
- Les nœuds forment un message avec les résultats du déploiement et l'envoient au coordinateur.
- Le coordinateur agrège tous les messages et génère le résultat de l'ensemble du processus de déploiement, qui est envoyé via discovery-spi à tous les nœuds du cluster.
- À la réception du résultat, le processus de déploiement est terminé, après quoi la tâche est supprimée de la file d'attente.
 Nouvelle conception pilotée par les événements: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
Nouvelle conception pilotée par les événements: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.javaSi une erreur s'est produite au moment du déploiement, le nœud inclut immédiatement cette erreur dans le message, qui l'envoie au coordinateur. Après l'agrégation des messages, le coordinateur disposera d'informations sur toutes les erreurs pendant le déploiement et enverra ce message via discovery-spi. Les informations d'erreur seront disponibles sur n'importe quel nœud du cluster.
Selon cet algorithme, tous les événements importants de la grille de service sont traités. Par exemple, un changement de topologie est également un message de découverte-spi. Et en général, par rapport à ce qu'il était, le protocole s'est avéré assez léger et fiable. Autant que pour gérer n'importe quelle situation pendant le déploiement.
Que se passera-t-il ensuite
Maintenant sur les plans. Tout développement majeur dans le projet Ignite est réalisé comme une initiative pour améliorer Ignite, le soi-disant IEP. La refonte de la grille de service a également un IEP -
IEP n ° 17 avec le nom plaisantant «Changement d'huile dans la grille de service». Mais en fait, nous avons changé non pas l'huile dans le moteur, mais l'ensemble du moteur.
Nous avons divisé les tâches dans l'IEP en 2 phases. La première est une phase majeure, qui consiste à modifier le protocole de déploiement. Il est déjà versé dans l'assistant, vous pouvez essayer le nouveau Service Grid, qui apparaîtra dans la version 2.8. La deuxième phase comprend de nombreuses autres tâches:
- Redeep chaud
- Gestion des versions de service
- Résilience accrue
- Client léger
- Outils pour surveiller et compter diverses métriques
Enfin, nous pouvons vous conseiller Service Grid pour la construction de systèmes haute disponibilité à haute disponibilité. Nous vous invitons également à
dev-list et
user-list pour partager votre expérience. Votre expérience est vraiment importante pour la communauté, elle vous aidera à comprendre où aller ensuite, comment développer le composant à l'avenir.