L'ARTICLE EST ACCEPTÉ PAR LA COMMUNAUTÉ HABR COMME UNE DÉSINFORMATION ET N'EST PAS RECOMMANDÉ POUR LA LECTURE!
Dans l'une de mes sociétés sociales, le rôle des développeurs front-end est comparé aux bassistes des groupes musicaux: une fois qu'ils rêvaient de devenir des guitaristes solos avec l'électronique à six cordes dans les mains, ou, dessinant un parallèle, de vrais «hackers», un gourou des technologies de l'information, mais trébuchant les pointeurs ont été obligés de prendre du recul et de rester codeurs. C'est à vous de décider de la véracité de ce point de vue, mais personnellement mes connaissances, les fournisseurs frontaux, ont vraiment essayé d'apprendre l'assembleur et regrettent parfois de ne pas pouvoir faire face à la segmentation de la mémoire. Dans cet article, nous considérerons le cas contraire - lorsqu'un programmeur système ou d'application expérimenté a
soudainement décidé de devenir webmaster. Les raisons peuvent être différentes. C'est peut-être un étudiant comme moi, qui n'a pas encore reçu de diplôme avec lequel vous pouvez obtenir un emploi dans la spécialité, mais vous devez gagner de l'argent maintenant. Ou le patron a ordonné à l'administrateur système de créer le site Web de l'entreprise, car il n'y a personne d'autre. Eh bien, ou peut-être avez-vous été attiré par l'idée d'arrêter de travailler pour un oncle et de devenir pigiste autonome, et sur les échanges indépendants, comme vous le savez, les produits les plus populaires sont les sites Web. D'une manière ou d'une autre, lorsque vous effectuez des tâches à partir de didacticiels en HTML, CSS et JavaScript, vous vous fiez involontairement partiellement à votre expérience passée dans le développement de logiciels d'application et de système, tandis que les didacticiels sont conçus pour les débutants avancés du monde des technologies de l'information. En conséquence, ces nouveaux arrivants obtiennent leurs premiers sites plus rapidement et plus cross-browser que le vôtre. Et tout cela parce qu'ils ne vont pas au monastère de quelqu'un avec leur charte. Je vais vous parler de certaines des erreurs identifiées par ma propre expérience qui hantent les fournisseurs frontaux novices qui ont un portefeuille important avec des algorithmes C ++.

En attente d'un profit facile
La première erreur est économique. Si vous êtes venu à l'avant avec l'objectif de gagner plus que votre patron ne le permet, je vous décevrai immédiatement, vous ne pouvez plus lire. La demande d'atterrissages, d'aménagements et de cartes de visite clé en main sur les échanges est très importante, mais l'offre est élevée. Au lieu de 8 heures de travail au bureau, pendant lesquelles vous effectuez le travail qui vous est assigné, vous devrez passer la majeure partie de la journée à une recherche indépendante de ce travail. Gardez à l'esprit que la plupart des employeurs ne sont disposés à coopérer que si vous leur fournissez des exemples liés aux commandes de votre portefeuille, ce qui signifie que le premier mois, vous êtes assuré de travailler pour la chicha, car vous devez d'abord collecter ce portefeuille, en saisissant toutes les chances de travailler
gratuitement . Et même avec lui, des dizaines d'indépendants comme vous répondront au même projet avec vous. Parmi eux, il y aura des concepteurs de mise en page très expérimentés qui termineront la moitié de la commande immédiatement et fourniront une version de démonstration, et seuls les débutants qui, comme vous, offriront une fois de tout terminer gratuitement. Très probablement, l'employeur choisira l'une de ces deux légions, et les autres devront rester assis pendant plusieurs heures en vain devant le moniteur, en appuyant sur F5. La situation peut être comparée au marché des avocats dans la CEI - une fois qu'ils ont été arrachés de leurs mains, dès qu'ils dépassent le seuil de l'alma mater, mais maintenant l'offre est beaucoup plus élevée que la demande. Dans le même temps, le freelance diffère du travail dans la jurisprudence en danger accru: si vous n'avez pas votre propre entrepreneur privé, l'argent que vous avez gagné en freelance peut être considéré comme illégal en vertu de la loi, et vous regretterez certainement de ne pas être resté dans ce bureau confortable où vous pouviez 8 heures par jour faites votre chose préférée et obtenez un salaire blanc pour cela. Si je ne vous ai toujours pas convaincu, nous allons passer aux erreurs suivantes.

Code de dispersion sur différents fichiers
Nous le faisons dans des langages système de haut niveau - chaque classe - dans un fichier séparé. De bons didacticiels de composition vous apprennent immédiatement comment enregistrer HTML et CSS dans différents fichiers. Il peut sembler que cette technique s'applique à tout. Arrêter Oui, il est préférable de stocker le code CSS séparément du HTML, mais, par exemple, garder les styles réinitialisés ou les modèles séparés de la majeure partie des règles CSS du site est une erreur mortelle. La même chose s'applique à JavaScript - vous n'avez pas besoin de diviser les scripts en centaines de fichiers par classe, il suffit de les regrouper en deux fichiers: ce qui est inclus dans l'en-tête de la page (en-tête) et ce qui est ajouté à la fin du contenu (corps). Nous sommes habitués au fait que les programmes dans les langages compilés sont entièrement liés avant le début de l'exécution. Ici, tout est différent. Chaque lien dans le code de site est une demande supplémentaire adressée au serveur. Vous avez sûrement remarqué la lenteur avec laquelle le réseau social Vkontakte a commencé à fonctionner récemment. Ouvrez le panneau de développement dans n'importe quel navigateur, mettez à jour vk.com et voyez combien il fait des requêtes GET et POST au serveur de réseau social. Une telle demande prend quelques microsecondes de temps, mais en raison de leur nombre, le processus de chargement complet de la page est retardé de quelques secondes. N'oubliez pas: le nombre minimum de demandes est la principale méthode pour augmenter la vitesse d'un site. Sur un serveur local, cela est invisible, mais cela devient évident lorsque vous travaillez avec un hébergement distant. Personne ne vous dérange pour stocker les décharges, les modèles de style, les classes, les bibliothèques dans des fichiers séparés, mais avant la publication, tout cela doit être «collé», laissant un fichier HTML et CSS et quelques fichiers JS de la source. Pour assembler tous les fichiers JS en un seul fichier, le «bundle», il existe des processeurs webpack, browserify, SASS et LESS conçus pour un assemblage CSS similaire. Il existe d'autres méthodes d'optimisation, par exemple, combinant plusieurs images (le plus souvent des listes d'icônes ou d'avatars) dans un fichier, mais c'est le sujet d'un article séparé.

Énumération avec classes et identificateurs
Les didacticiels conseillent d'ajouter des attributs de classe et d'identifiant à tous les éléments de la page afin qu'ils puissent être facilement sélectionnés avec des sélecteurs CSS. C'est un bon conseil, dans une certaine mesure. Quand je commençais à peine à étudier la composition, tout était jonché de cours pour moi. C'est une erreur. Je vais vous donner un exemple.
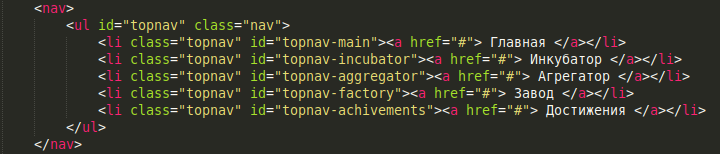
C'est le code que j'ai écrit quand j'étais nouveau sur le Web. Considérez maintenant toutes les erreurs. Premièrement, dans les TdR, il n’est pas indiqué de coloriser les onglets de navigation de différentes couleurs et il n’est pas prévu de l’indiquer. Par conséquent, tous les identificateurs d’onglet ne font que gaspiller la charge du processeur de l’utilisateur du site. N'hésitez pas à nettoyer. Deuxièmement, tous les éléments de la classe «topnav» sont des éléments <li> et sont incorporés dans le <ul>, de plus, l'élément <ul> ne peut contenir que des éléments <li>, donc notre classe «topnav» est identique au sélecteur «#topnav li» . Effacez les classes topnav. Et troisièmement, dans le TOR, la seule barre de navigation est indiquée, ce qui signifie qu'il ne devrait y avoir qu'un seul élément <nav> sur toute la page. Oui, les savoirs traditionnels peuvent changer, mais ajouter un identifiant est beaucoup plus facile que de lire le code de quelqu'un d'autre à la recherche du bon mot. De plus, les éléments de la classe <nav> que nous obtenons également sont identiques au sélecteur nav ul. Nous supprimons tout.
Voici le résultat final:
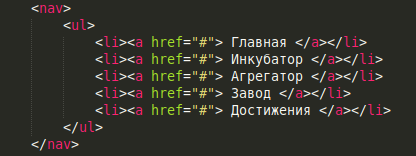
Pas une seule classe ou identifiant! Mais en même temps, tout ce dont vous avez besoin est mis en évidence par des sélecteurs.
Les deux codes suivants appliquent les mêmes règles:D'abordnav { position: -webkit-sticky; position: sticky; top: 0; } #topnav { list-style: none; overflow: hidden; } .topnav a { display: block; float: left; width: 20%; height: 6vh; font-family: RMS, monospace, sans-serif; font-size: 2vw; text-align: center; line-height: 6vh; color: black; background-color: #FF0; border-left: 3px dotted red; transition: border .2s ease 0s; } .topnav:last-of-type a { border-right: 3px dotted red; } .topnav a:hover { border-left-style: solid; border-top: 3px solid red; } .topnav a:focus { border-top: 3px solid red; } .topnav:hover + li a { border-left-style: solid; } .topnav:focus + li a { border-left-style: solid; } .topnav:last-of-type a:hover { border-right-style: solid; } .topnav:last-of-type a:focus { border-right-style: solid; }
Deuxième nav { position: -webkit-sticky; position: sticky; top: 0; } nav ul { list-style: none; overflow: hidden; } nav ul li a { display: block; float: left; width: 20%; height: 6vh; font-family: RMS, monospace, sans-serif; font-size: 2vw; text-align: center; line-height: 6vh; color: black; background-color: #FF0; border-left: 3px dotted red; transition: border .2s ease 0s; } nav ul li:last-of-type a { border-right: 3px dotted red; } nav ul li a:hover { border-left-style: solid; border-top: 3px solid red; } nav ul li a:focus { border-top: 3px solid red; } nav ul li:hover + li a { border-left-style: solid; } nav ul li:focus + li a { border-left-style: solid; } nav ul li:last-of-type a:hover { border-right-style: solid; } nav ul li:last-of-type a:focus { border-right-style: solid; }
Mais le second est moins contraignant pour vous et le processeur, et celui qui lira votre code, car vous n'avez pas besoin de rechercher l'identifiant ou la classe sur la page et de penser à ce que son nom signifie.Tout est correct. Les informations barrées ci-dessus sont incorrectes et constituent également un exemple d'erreur. Contrairement aux didacticiels, à un certain stade de compréhension de la mise en page, il semble que les classes et identifiants supplémentaires sont inutiles et que le deuxième exemple charge moins le processeur de l'utilisateur du site, car le navigateur n'a pas besoin de passer complètement l'arborescence DOM à la recherche de tous les éléments de la classe ".topnav". Cependant, une telle simplification entraînera au contraire une augmentation du temps de recherche et n'est pas optimisante. En effet, les sélecteurs de style s'étendent de droite à gauche: dans le deuxième code, tous les éléments <a> de la page entière sont trouvés en premier, puis leurs parents seront vérifiés pour la conformité avec l'élément <li>, puis les parents des éléments <li>, etc. seront vérifiés. Par conséquent, la divulgation du sélecteur souhaité nécessitera une passe d'arborescence complète plus trois vérifications de la liste de sélection au lieu d'une passe à la recherche d'éléments de la classe ".topnav". De plus, le rejet des classes et des identifiants va à l'encontre du principe «HTML - pour la structuration, CSS - pour la présentation», car les sélecteurs CSS ne doivent pas dépendre du type d'éléments sélectionnés. Autrement dit, lors du remplacement de <ul> et <li> par <div> et <span>, ils doivent rester inchangés. Ne négligez pas les classes et les identifiants. La meilleure solution dans notre exemple serait peut-être:
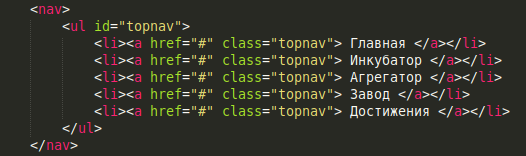
Soit dit en passant, sur les noms. Peu importe à quel point vous avez plongé dans la mise en page, si vous ne connaissez toujours pas les
microformats - maintenant google et étudiez pour ne pas inventer des noms de classe fantaisistes et faciliter le travail des moteurs de recherche.
Éviter les fonctions anonymes
Nous sommes habitués au fait que lors de l'écriture de programmes, nos noms de fonction, variables et objets n'ont que trois restrictions: ils doivent commencer par une lettre, ne contenir que des lettres et des chiffres et ne doivent pas coïncider avec les mots-clés du langage de programmation. Les noms des bibliothèques tierces sont généralement inclus dans des espaces de noms pratiques, donc nous n'utilisons généralement pas de fonctions lambda dans nos programmes d'application. Sur le web, avec les noms, les choses sont plus compliquées. Ici, JavaScript n'a qu'un seul espace global - l'espace de la page chargée. Rien ne se passera si vous écrivez personnellement tous les scripts du site. Mais pour les projets importants et sérieux, vous avez besoin de solutions tierces. Et puis ils peuvent littéralement «gâcher» ce seul espace de noms, vous limitant sérieusement dans le choix de nouveaux identifiants. La sortie est des fonctions lambda anonymes, qui, bien qu'elles prennent un peu plus de temps, nécessitent un peu plus de ressources, mais elles ont leur propre espace personnel à l'intérieur, indépendant de l'espace global externe.
Utilisation de bibliothèques complexes pour résoudre des problèmes simples
jQuery, React, Vue, Angular, Backbone ... La liste continue. La chose commune à toutes ces bibliothèques JavaScript est qu'elles sont utilisées pour travailler avec des projets complexes lorsque la taille du code compte vraiment. Afin de sélectionner simplement un élément sur la page par son identifiant, il est préférable d'utiliser l'habituel getElementById (). Cela fonctionne non seulement plus rapidement, mais fonctionne essentiellement sur des navigateurs plus anciens. Si votre script accède à deux ou trois éléments sur une page pendant tout le temps de travail, pensez, peut-être qu'il est logique de ne pas charger le navigateur et le réseau d'utilisateurs avec une bibliothèque lourde.
Matériel d'apprentissage obsolète
Pour les développeurs C ++, les travaux de Straustrup resteront pertinents après plusieurs décennies. Les outils Web se développent simplement à une vitesse incroyable. HTML, CSS, JavaScript, mises en page, frameworks, bibliothèques - pendant que vous lisez cet article, ils sortent tous avec de nouvelles versions, souvent rayées d'anciens manuels. Conclusion - lors du choix du matériel de formation pour le front-end, il est important de regarder les dates de sortie et les versions des outils utilisés (HTML au moins 5.1, CSS au moins 3.0, ECMAScript au moins 6). Peut-être que la mise en page de HTML n'est pas allée très loin depuis la sortie de HTML 5, mais il est trop tard pour regarder les cours vidéo JS 2016 en 2019. Choisissez 2018. C'est encore mieux si vous parlez anglais au moins au niveau de la traduction d'un texte technique avec un dictionnaire. Ensuite, je recommanderai immédiatement le livre en ligne
Eloquent JavaScript .
Manque de support pour les anciens navigateurs
Paradoxalement, si vous avez la chance de trouver la dernière sélection de manuels sur le frontend, vous pouvez tomber dans un autre piège - le manque de support pour les navigateurs plus anciens. Bien que les éléments <video> et <audio> soient effectivement pris en charge par tous, même les versions très anciennes des navigateurs, de nombreux effets CSS causent des problèmes, et il ne s'agit pas uniquement d'Internet Explorer absolu. Il n'y a qu'un seul moyen de sortir du piège: lisez attentivement les savoirs traditionnels à l'endroit où les navigateurs pris en charge sont indiqués et comparez les balises HTML, les règles CSS et les méthodes JS utilisées par leurs versions.
Cet article est une sorte de cahier de râteau et sera mis à jour avec l'expérience de l'auteur.