Salut À la fin de l'année dernière, nous avons commencé à masquer automatiquement les numéros de véhicules sur les photos des cartes d'annonce d'Avito. Pour savoir pourquoi nous avons fait cela et quelles sont les façons de résoudre ces problèmes, lisez l'article.

Défi
Sur Avito en 2018, 2,5 millions de voitures ont été vendues. C'est presque 7 000 par jour. Toutes les annonces à vendre ont besoin d'une illustration - photo d'une voiture. Mais par le numéro de l'État sur celui-ci, vous pouvez trouver beaucoup d'informations supplémentaires sur la voiture. Et certains de nos utilisateurs essaient de fermer eux-mêmes la plaque d'immatriculation.
Les raisons pour lesquelles les utilisateurs souhaitent masquer le numéro de plaque d'immatriculation peuvent être différentes. Pour notre part, nous voulons les aider à protéger leurs données. Et nous essayons d'améliorer les processus de vente et d'achat pour les utilisateurs. Par exemple, un service de numéro anonyme travaille avec nous depuis longtemps: lorsque vous vendez une voiture, un numéro de téléphone cellulaire temporaire est créé pour vous. Eh bien, afin de protéger les données sur les plaques d'immatriculation, nous anonymisons les photos.

Présentation de la solution
Pour automatiser le processus de protection des photos des utilisateurs, vous pouvez utiliser des réseaux de neurones convolutifs pour détecter un polygone avec une plaque d'immatriculation.
Maintenant, pour la détection d'objets, les architectures de deux groupes sont utilisées: les réseaux à deux étages, par exemple, Faster RCNN et Mask RCNN; en une seule étape (single-shot) - SSD, YOLO, RetinaNet. La détection d'un objet est la dérivation des quatre coordonnées du rectangle dans lequel l'objet d'intérêt est inscrit.
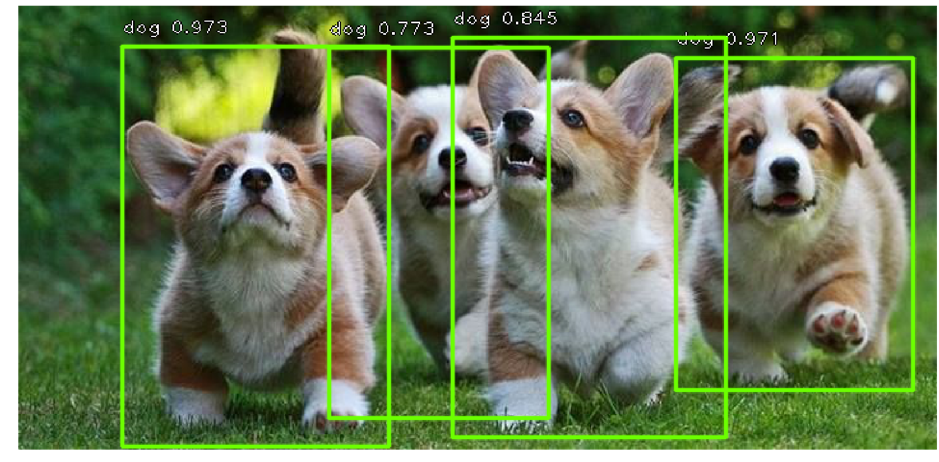
Les réseaux mentionnés ci-dessus sont capables de trouver de nombreux objets de différentes classes sur les photos, ce qui est déjà redondant pour résoudre le problème de recherche de plaque d'immatriculation, car nous n'avons généralement qu'une seule voiture sur les photos (il y a des exceptions lorsque les gens prennent des photos de leur voiture vendue et de son voisin aléatoire , mais cela arrive assez rarement, cela pourrait donc être négligé).
Une autre caractéristique de ces réseaux est que, par défaut, ils produisent une boîte englobante avec des côtés parallèles aux axes de coordonnées. Cela se produit car un ensemble de types prédéfinis de cadres rectangulaires appelés boîtes d'ancrage est utilisé pour la détection. Plus précisément, en utilisant d'abord un réseau convolutionnel (par exemple, resnet34), une matrice d'attributs est obtenue à partir de l'image. Ensuite, pour chaque sous-ensemble d'attributs obtenus à l'aide de la fenêtre coulissante, une classification se produit: existe-t-il un objet pour la boîte d'ancrage k ou non, et une régression est effectuée dans les quatre coordonnées du cadre, qui ajustent sa position.
En savoir plus à ce sujet
ici .
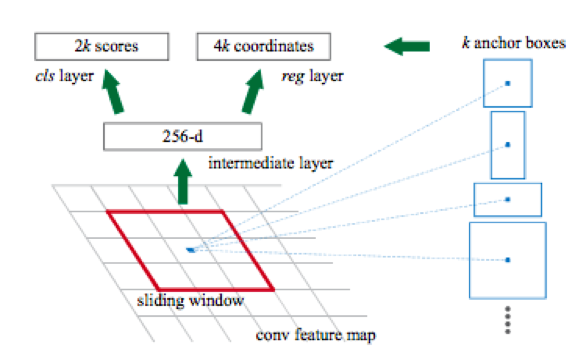
Après cela, il y a deux têtes de plus:
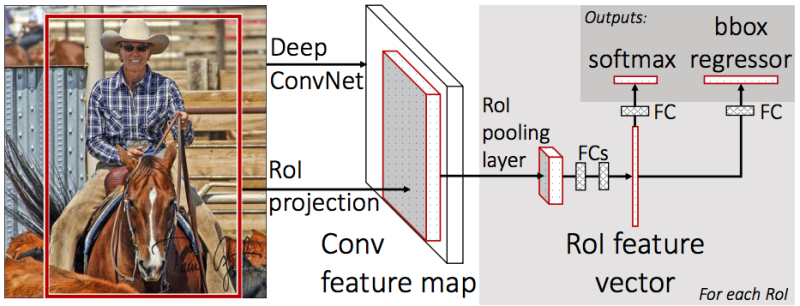
un pour classer l'objet (chien / chat / plante, etc.),
le second (régresseur bbox) - pour la régression des coordonnées du cadre obtenues à l'étape précédente afin d'augmenter le rapport de la zone de l'objet à la zone du cadre.
Afin de prédire le cadre de boxe pivoté, vous devez modifier le régresseur bbox afin d'obtenir également l'angle de rotation du cadre. Si cela n'est pas fait, cela se révélera d'une manière ou d'une autre.

En plus du Faster R-CNN à deux étages, il existe des détecteurs à un étage, tels que RetinaNet. Il diffère de l'architecture précédente en ce qu'il prédit immédiatement la classe et le cadre, sans l'étape préliminaire de proposer des sections de l'image pouvant contenir des objets. Pour prévoir les masques pivotés, vous devez également changer la tête du sous-réseau de la boîte.
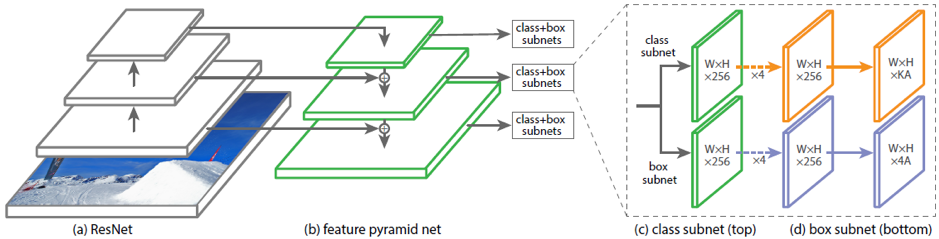
Un exemple d'architectures existantes pour prédire les boîtes englobantes tournées est DRBOX. Ce réseau n’utilise pas l’étape préliminaire de la proposition de la région, comme dans le RCRN plus rapide; il s’agit donc d’une modification des méthodes en une étape. Pour former ce réseau, on utilise K en rotation à certains angles, le cadre de délimitation (rbox). Le réseau prédit les probabilités pour chacune des K rbox de contenir l'objet cible, les coordonnées, la taille de la bbox et l'angle de rotation.

Modifier l'architecture et recycler l'un des réseaux considérés sur les données avec des boîtes englobantes tournées est une tâche réalisable. Mais notre objectif peut être atteint plus facilement, car la portée du réseau que nous avons est beaucoup plus étroite - uniquement pour cacher les plaques d'immatriculation.
Par conséquent, nous avons décidé de commencer avec un réseau simple pour prédire les quatre points du nombre, et par la suite, il sera possible de compliquer l'architecture.
Les données
L'assemblage de l'ensemble de données est divisé en deux étapes: recueillir des photos de voitures et marquer la zone avec une plaque d'immatriculation dessus. La première tâche a déjà été résolue dans notre infrastructure: nous stockons soigneusement toutes les annonces qui ont déjà été placées sur Avito. Pour résoudre le deuxième problème, nous utilisons Toloka. Sur
toloka.yandex.ru/requester nous créons une tâche:
La tâche a donné une photo de la voiture. Il est nécessaire de mettre en évidence la plaque d'immatriculation de la voiture à l'aide d'un quadrilatère. Dans ce cas, le numéro d'état doit être attribué aussi précisément que possible.

À l'aide de Toloka, vous pouvez créer des tâches pour baliser les données. Par exemple, évaluer la qualité des résultats de recherche, baliser différentes classes d'objets (textes et images), baliser des vidéos, etc. Ils seront effectués par les utilisateurs de Toloka, pour les frais que vous facturez. Par exemple, dans notre cas, les tolokers doivent mettre en évidence la décharge avec le numéro de plaque d'immatriculation de la voiture sur la photo. En général, c'est très pratique pour baliser un grand ensemble de données, mais obtenir une haute qualité est assez difficile. Il y a beaucoup de robots dans la foule, dont la tâche est d'obtenir de l'argent de votre part en donnant des réponses au hasard ou en utilisant une sorte de stratégie. Pour contrer ces robots, il existe un système de règles et de contrôles. La vérification principale est le mélange des questions de contrôle: vous marquez manuellement une partie des tâches à l'aide de l'interface Toloki, puis les mélangez dans la tâche principale. Si le balisage se trompe souvent sur des questions de contrôle, vous le bloquez et ne tenez pas compte du balisage.
Pour la tâche de classification, il est très simple de déterminer si le marquage est incorrect ou non, et pour le problème de la mise en évidence d'une région, ce n'est pas si simple. La méthode classique consiste à compter IoU.
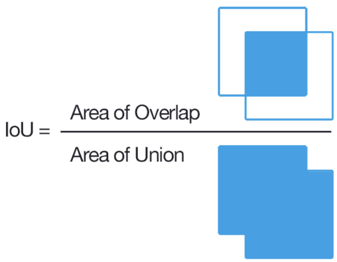
Si ce rapport est inférieur à un certain seuil pour plusieurs tâches, alors un tel utilisateur est bloqué. Cependant, pour deux quadrangles arbitraires, le calcul de l'IoU n'est pas si simple, d'autant plus que dans Tolok, il est nécessaire de l'implémenter en JavaScript. Nous avons fait un petit hack, et nous pensons que l'utilisateur ne s'est pas trompé si pour chaque point du polygone source dans un petit quartier il y a un point marqué d'un scribe. Il existe également une règle de réponse rapide pour bloquer les utilisateurs qui répondent trop rapidement, captcha, divergence avec l'opinion majoritaire, etc. Après avoir mis en place ces règles, vous pouvez vous attendre à un assez bon balisage, mais si vous avez vraiment besoin d'un balisage complexe et de haute qualité, vous devez embaucher spécifiquement des pigistes-scribers. En conséquence, notre ensemble de données s'élève à 4 000 images marquées, et tout cela coûte 28 $ à Tolok.
Modèle
Faisons maintenant un réseau pour prédire les quatre points de la zone. Nous obtiendrons les signes en utilisant resnet18 (paramètres 11,7 millions contre 21,8 millions pour resnet34), puis nous ferons une tête pour la régression à quatre points (huit coordonnées) et une tête pour la classification s'il y a une plaque d'immatriculation dans l'image ou non. La deuxième tête est nécessaire, car dans les annonces pour la vente de voitures, pas toutes les photos avec des voitures. La photo peut être un détail de la voiture.

Comme pour nous, bien sûr, il n'est pas nécessaire de détecter.
Nous effectuons l'entraînement de deux objectifs en même temps en ajoutant à l'ensemble de données une photo sans plaque d'immatriculation avec une cible de boîte englobante (0,0,0,0,0,0,0,0,0,0) et une valeur pour le classificateur "image avec / sans plaque d'immatriculation" - (0, 1).
Ensuite, vous pouvez créer une fonction de perte unique pour les deux objectifs comme la somme des pertes suivantes. Pour la régression aux coordonnées du polygone de plaque d'immatriculation, nous utilisons une perte L1 lisse.
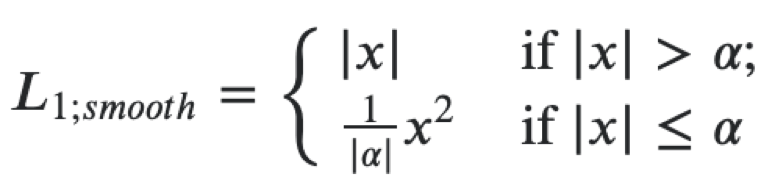
Il peut être interprété comme une combinaison de L1 et L2, qui se comporte comme L1 lorsque la valeur absolue de l'argument est grande et comme L2 lorsque la valeur de l'argument est proche de zéro. Pour la classification, nous utilisons softmax et crossentropy loss. L'extracteur de fonctionnalités est resnet18, nous utilisons des poids pré-formés sur ImageNet, puis nous formerons davantage l'extracteur et les têtes sur notre jeu de données. Dans ce problème, nous avons utilisé le framework mxnet, car il est le principal pour la vision par ordinateur dans Avito. En général, l'architecture de microservice vous permet de ne pas être lié à un framework spécifique, mais lorsque vous avez une grande base de code, il est préférable de l'utiliser et de ne pas réécrire le même code.
Ayant reçu une qualité acceptable sur notre jeu de données, nous nous sommes tournés vers les concepteurs pour nous obtenir une plaque d'immatriculation avec le logo Avito. Au début, nous avons essayé de le faire nous-mêmes, bien sûr, mais ce n'était pas très beau. Ensuite, vous devez changer la luminosité de la plaque d'immatriculation Avito à la luminosité de la zone d'origine avec la plaque d'immatriculation et vous pouvez superposer le logo sur l'image.

Lancement en prod
Le problème de la reproductibilité des résultats, du support et du développement de projets, résolu avec quelques erreurs dans le monde du développement backend et frontend, reste ouvert là où il est nécessaire d'utiliser des modèles d'apprentissage automatique. Vous avez probablement dû comprendre le modèle de code hérité. C'est bien si le fichier Lisez-moi contient des liens vers des articles ou des référentiels open source sur lesquels la solution était basée. Le script pour démarrer le recyclage peut échouer avec des erreurs, par exemple, la version de cudnn a changé, et cette version de tensorflow ne fonctionne plus avec cette version de cudnn, et cudnn ne fonctionne pas avec cette version des pilotes nvidia. Peut-être pour la formation, nous avons utilisé un itérateur en fonction des données, et pour tester en production un autre. Cela peut durer un certain temps. En général, des problèmes de reproductibilité existent.
Nous essayons de les supprimer en utilisant l'environnement nvidia-docker pour les modèles de formation, il a toutes les dépendances nécessaires pour suda, et nous y installons également des dépendances pour python. La version de la bibliothèque avec un itérateur selon les données, les augmentations et les modèles d'inférence est courante pour la phase de formation / expérimentation et pour la production. Ainsi, afin de former le modèle sur de nouvelles données, vous devez pomper le référentiel vers le serveur, exécuter le script shell qui collectera l'environnement docker, à l'intérieur duquel le bloc-notes jupyter se lèvera. À l'intérieur, vous aurez tous les cahiers de formation et de test, qui ne manqueront certainement pas avec une erreur due à l'environnement. Il est préférable, bien sûr, d'avoir un fichier train.py, mais la pratique montre que vous devez toujours regarder avec les yeux ce que le modèle donne et changer quelque chose dans le processus d'apprentissage, donc à la fin vous exécuterez toujours jupyter.
Les poids des modèles sont stockés dans git lfs - il s'agit d'une technologie spéciale pour stocker des fichiers volumineux dans un git. Avant cela, nous utilisions des artefacteurs, mais l'utilisation de git lfs est plus pratique, car en téléchargeant le référentiel avec le service, vous obtenez immédiatement la version actuelle des échelles, comme en production. Les autotests sont écrits pour l'inférence de modèle, vous ne pourrez donc pas déployer un service avec des poids qui ne les dépassent pas. Le service lui-même est lancé dans le docker à l'intérieur de l'infrastructure de microservices sur le cluster kubernetes. Pour surveiller les performances, nous utilisons grafana. Après le roulement, nous augmentons progressivement la charge sur les instances de service avec un nouveau modèle. Lors du déploiement d'une nouvelle fonctionnalité, nous créons des tests a / b et émettons un verdict sur le sort futur de la fonctionnalité, basé sur des tests statistiques.
En conséquence: nous avons lancé le glissement des nombres sur les annonces de la catégorie auto pour les commerçants privés, le 95e centile du temps de traitement d'une image pour masquer le nombre est de 250 ms.