Les gens apprennent l'architecture à partir de vieux livres écrits pour Java. Les livres sont bons, mais ils apportent une solution aux problèmes de l'époque avec des instruments de l'époque. Le temps a changé, C # ressemble plus à Scala léger qu'à Java, et il y a peu de nouveaux bons livres.
Dans cet article, nous examinerons les critères de bon code et de mauvais code, comment et quoi mesurer. Nous verrons un aperçu des tâches et des approches typiques, nous analyserons les avantages et les inconvénients. À la fin, il y aura des recommandations et des meilleures pratiques pour la conception d'applications Web.
Cet article est une transcription de mon rapport de la conférence DotNext 2018 à Moscou. En plus du texte, il y a une vidéo et un lien vers les diapositives sous la coupe.

Diapositives et page de rapport sur le site .
En bref: je viens de Kazan, je travaille pour le groupe High Tech. Nous développons des logiciels pour les entreprises. Récemment, j'ai enseigné à l'Université fédérale de Kazan un cours intitulé Développement de logiciels d'entreprise. De temps en temps, j'écris toujours des articles sur Habr sur les pratiques d'ingénierie, sur le développement de logiciels d'entreprise.
Comme vous l'avez probablement deviné, je parlerai aujourd'hui du développement de logiciels d'entreprise, à savoir comment structurer des applications web modernes:
- les critères
- une brève histoire du développement de la pensée architecturale (ce qui était, ce qui est devenu, quels sont les problèmes);
- aperçu des défauts de l'architecture de bouffée classique
- la décision
- analyse étape par étape de la mise en œuvre sans plonger dans les détails
- résultats.
Critères
Nous formulons les critères. Je n'aime vraiment pas quand on parle de design dans le style de "mon kung-fu est plus fort que votre kung-fu". Une entreprise a, en principe, un critère spécifique appelé argent. Tout le monde sait que le temps c'est de l'argent, donc ces deux composantes sont le plus souvent les plus importantes.

Donc, les critères. En principe, l'entreprise nous demande le plus souvent «autant de fonctionnalités que possible par unité de temps», mais avec une mise en garde - ces fonctionnalités devraient fonctionner. Et la première étape où il pourrait se casser est la révision du code. Autrement dit, il semble que le programmeur a dit: "Je le ferai dans trois heures." Trois heures se sont écoulées, l'examen est entré dans le code, et le chef d'équipe a dit: "Oh, non, refaites-le." Il y en a trois de plus - et combien d'itérations la revue de code a passé, tellement vous devez multiplier trois heures.
Le point suivant est le retour de l'étape du test d'acceptation. La même chose. Si la fonction ne fonctionne pas, alors ce n'est pas fait, ces trois heures s'étendent sur une semaine, deux - enfin, comme d'habitude. Le dernier critère est le nombre de régressions et de bugs qui, malgré les tests et l'acceptation, ont néanmoins traversé la production. C'est aussi très mauvais. Il y a un problème avec ce critère. Il est difficile de suivre, car le lien entre le fait que nous poussions quelque chose dans le référentiel et le fait que quelque chose s'est cassé après deux semaines peut être difficile à suivre. Mais, néanmoins, c'est possible.
Développement d'architecture
Il était une fois, quand les programmeurs commençaient à peine à écrire des programmes, il n'y avait toujours pas d'architecture, et tout le monde faisait tout ce qu'il voulait.

Par conséquent, nous avons obtenu un tel style architectural. C'est ce qu'on appelle le «code de nouilles» ici, ils disent «code de spaghetti» à l'étranger. Tout est lié à tout: on change quelque chose au point A - ça casse au point B, il est complètement impossible de comprendre ce qui est connecté à quoi. Naturellement, les programmeurs ont rapidement réalisé que cela ne fonctionnerait pas, et une certaine structure devait être faite, et ont décidé que certaines couches nous aideraient. Maintenant, si vous imaginez que la viande hachée est du code et que la lasagne est de telles couches, voici une illustration de l'architecture en couches. La viande hachée est restée hachée, mais maintenant la viande hachée de la couche n ° 1 ne peut pas simplement aller parler à la viande hachée de la couche n ° 2. Nous avons donné une forme au code: même sur l'image, vous pouvez voir que l'escalade est plus cadrée.
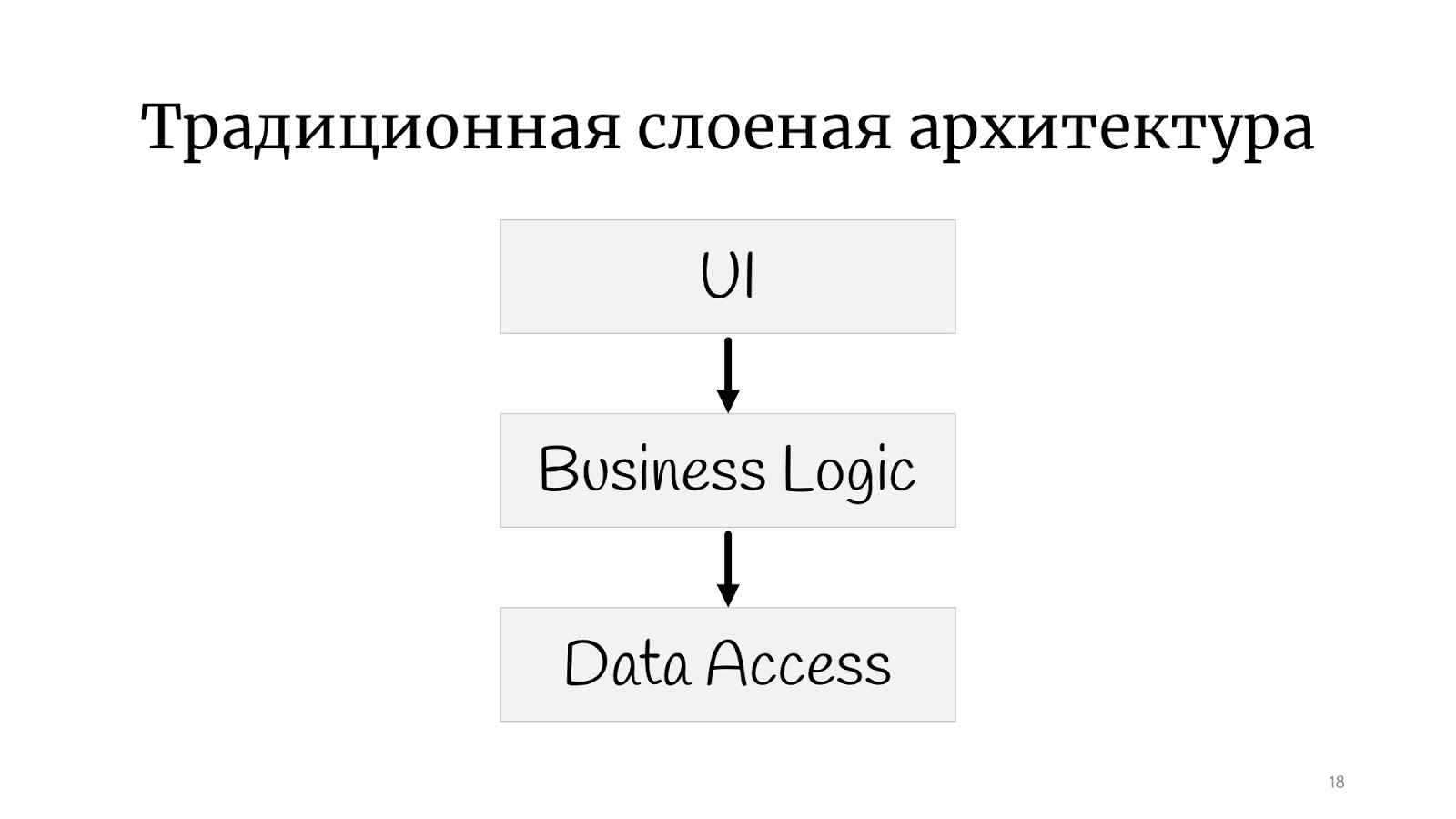
Tout le monde connaît probablement l'
architecture en couches classique : il existe une interface utilisateur, une logique métier et une couche d'accès aux données. Il existe encore toutes sortes de services, façades et couches, du nom de l'architecte qui a quitté l'entreprise, il peut y en avoir un nombre illimité.

L'étape suivante a été la soi-disant
architecture de l'oignon . Il semblerait qu'il y ait une énorme différence: avant cela, il y avait un petit carré, et ici il y avait des cercles. Cela semble être complètement différent.
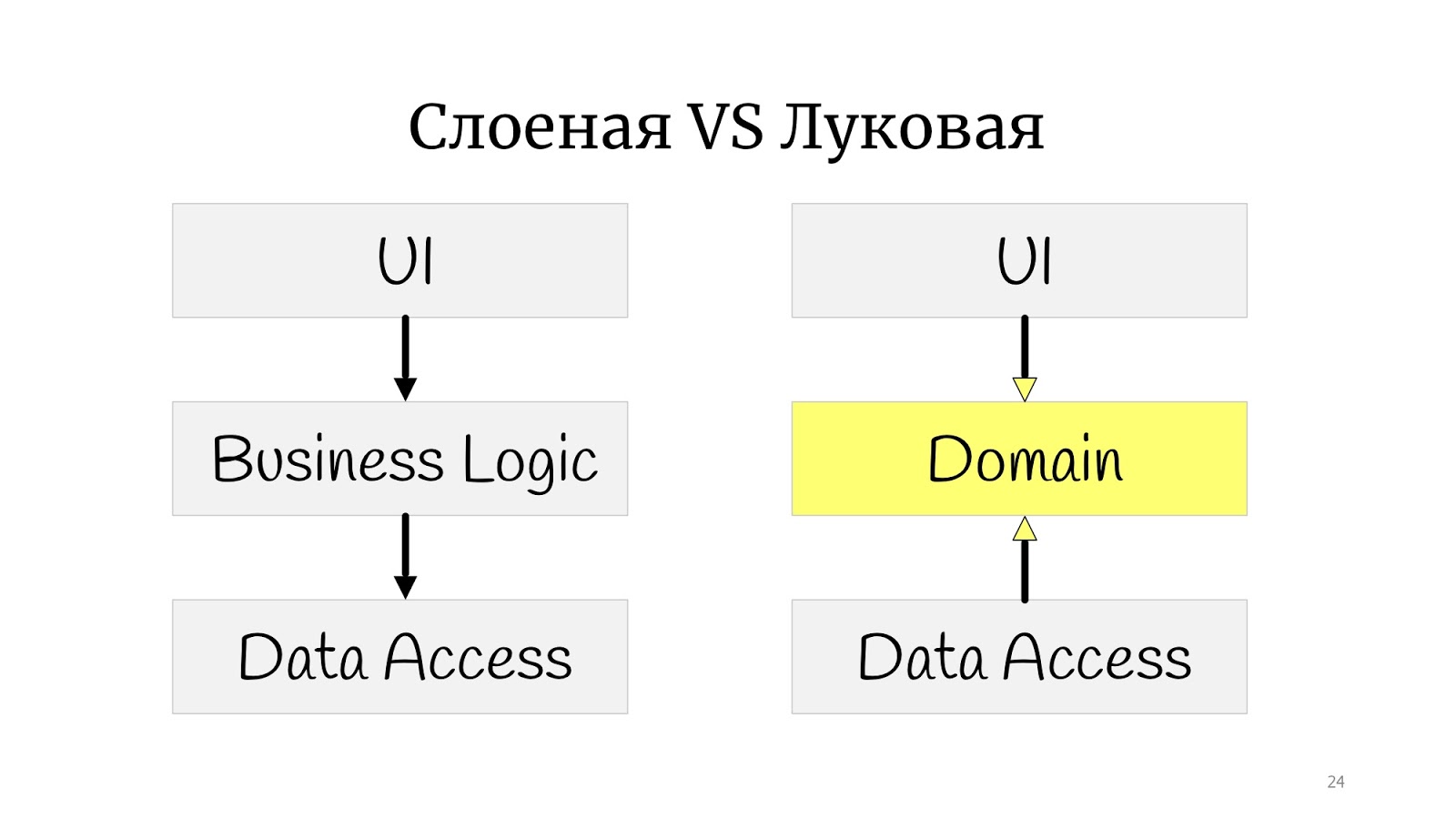
Pas vraiment. La différence est que quelque part à cette époque, les principes de SOLID ont été formulés, et il s'est avéré que dans l'oignon classique, il y a un problème avec l'inversion de dépendance, car le code de domaine abstrait dépend pour une raison quelconque de la mise en œuvre, de l'accès aux données, nous avons donc décidé de déployer l'accès aux données et que l'accès aux données dépend du domaine.

Ici, j'ai pratiqué le dessin et dessiné l'architecture de l'oignon, mais pas de façon classique avec les «anneaux». J'ai quelque chose entre un polygone et des cercles. Je l'ai fait pour montrer simplement que si vous rencontriez les mots «oignon», «hexagonal» ou «ports et adaptateurs» - ce sont tous une seule et même chose. Le fait est que le domaine est au centre, il est enveloppé dans des services, ils peuvent être des services de domaine ou d'application, comme vous le souhaitez. Et le monde extérieur sous forme d'interface utilisateur, de tests et d'infrastructure où DAL a déménagé - ils communiquent avec le domaine via cette couche de service.
Un exemple simple. Mise à jour par e-mail
Voyons à quoi ressemblerait un cas d'utilisation simple dans un tel paradigme - la mise à jour de l'adresse e-mail de l'utilisateur.
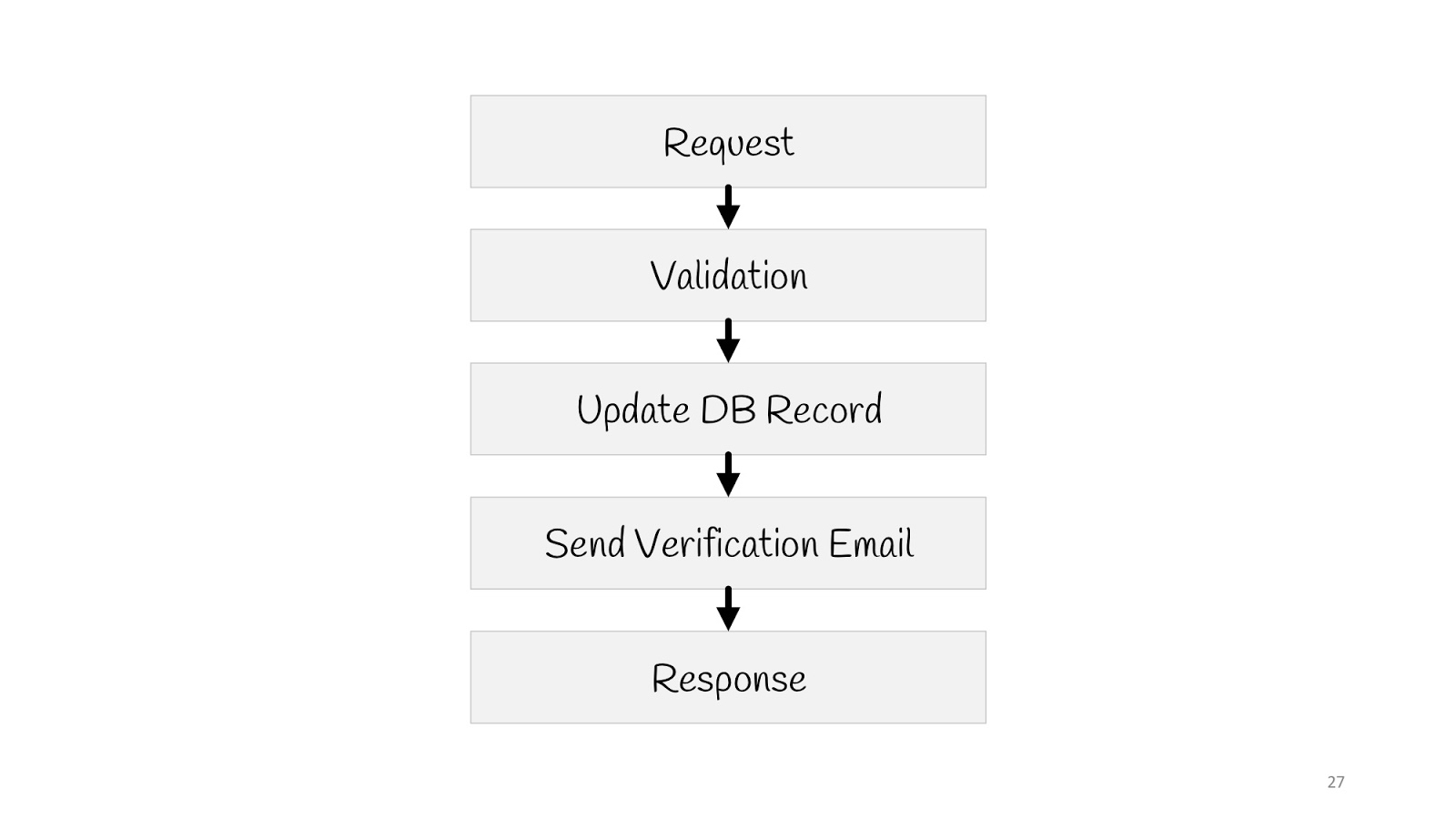
Nous devons envoyer une demande, valider, mettre à jour la valeur dans la base de données, envoyer une notification à un nouvel e-mail: "Tout est en ordre, vous avez changé votre e-mail, nous savons que tout va bien", et répondre au navigateur "200" - tout va bien.
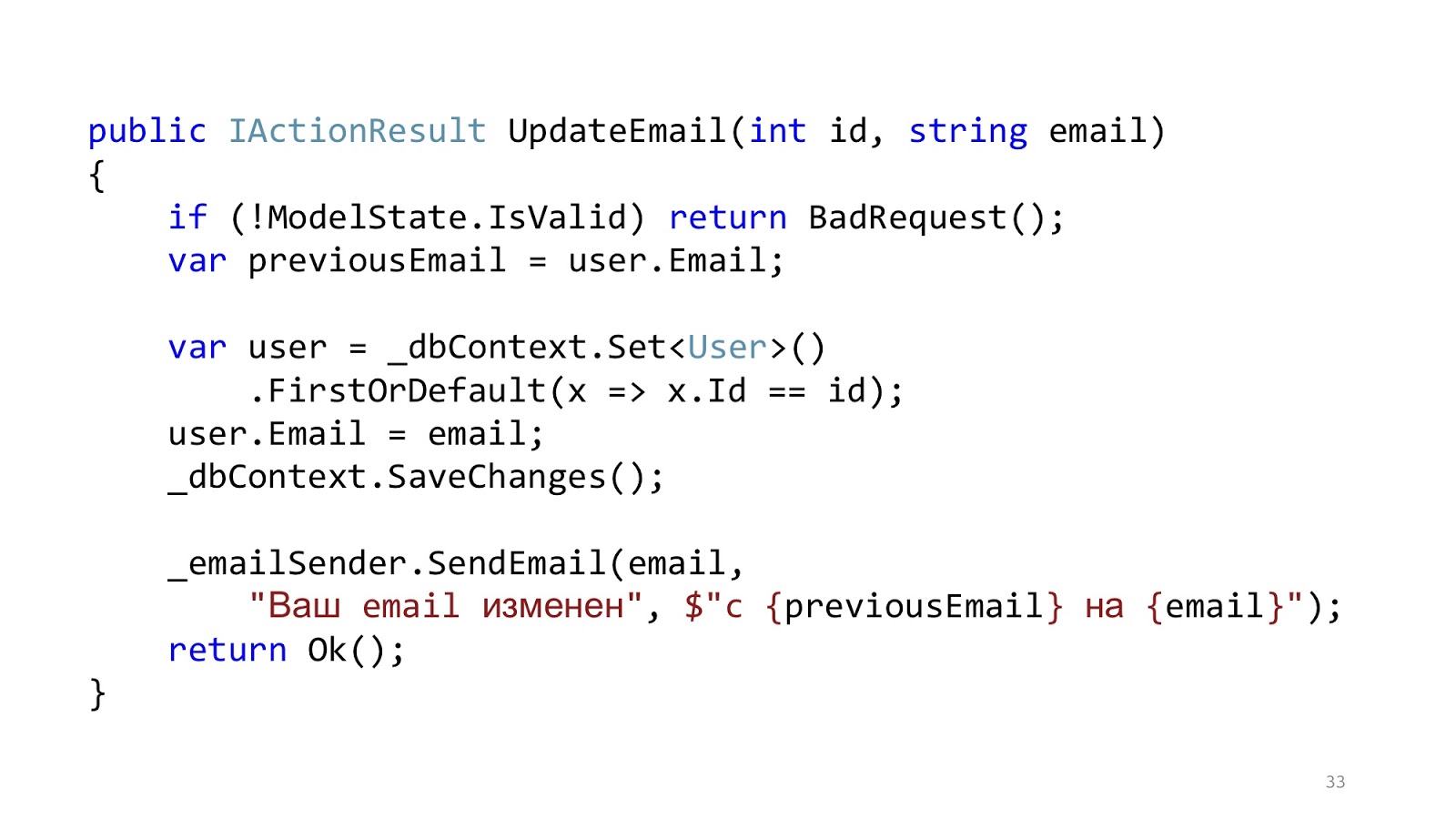
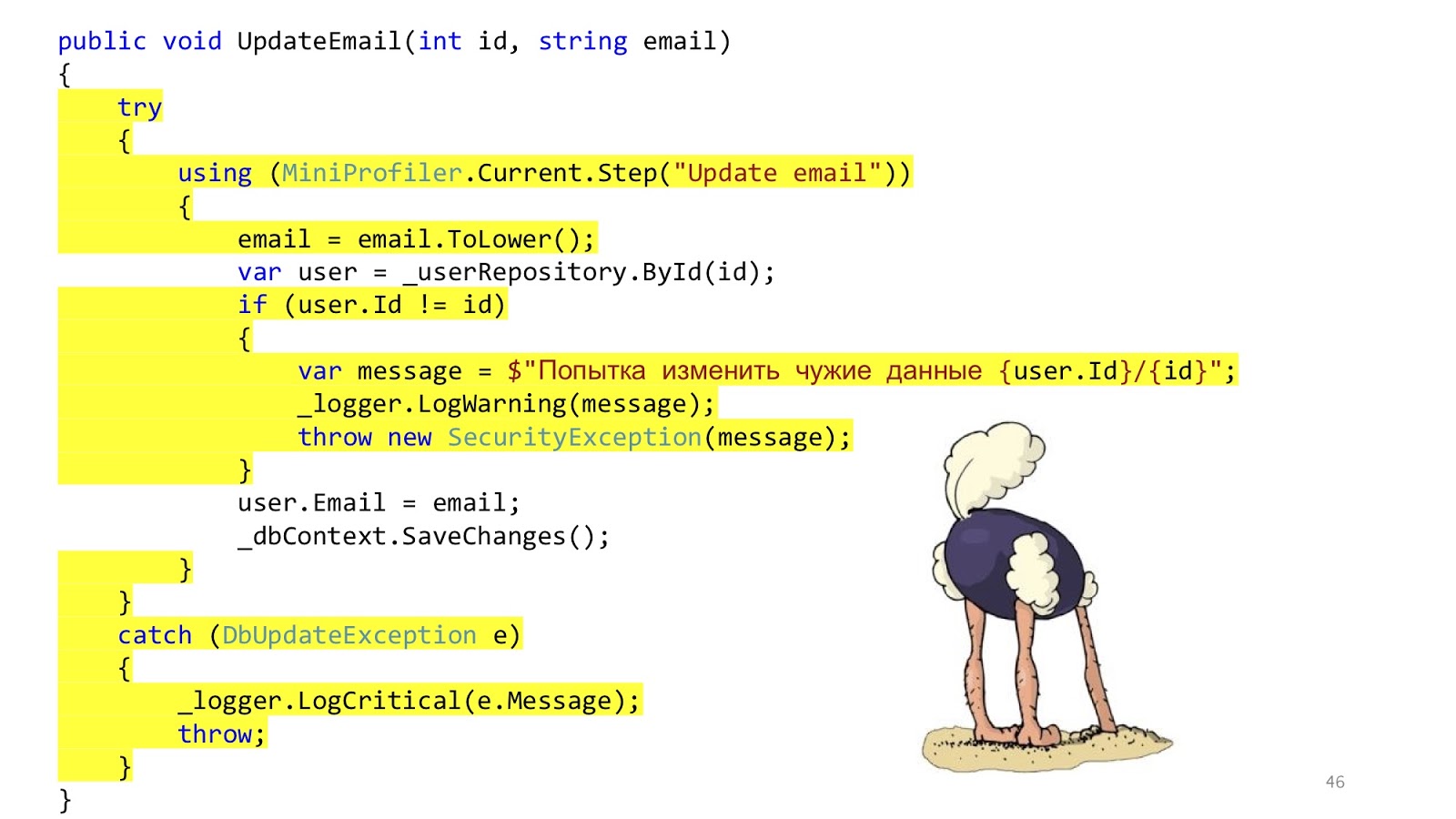
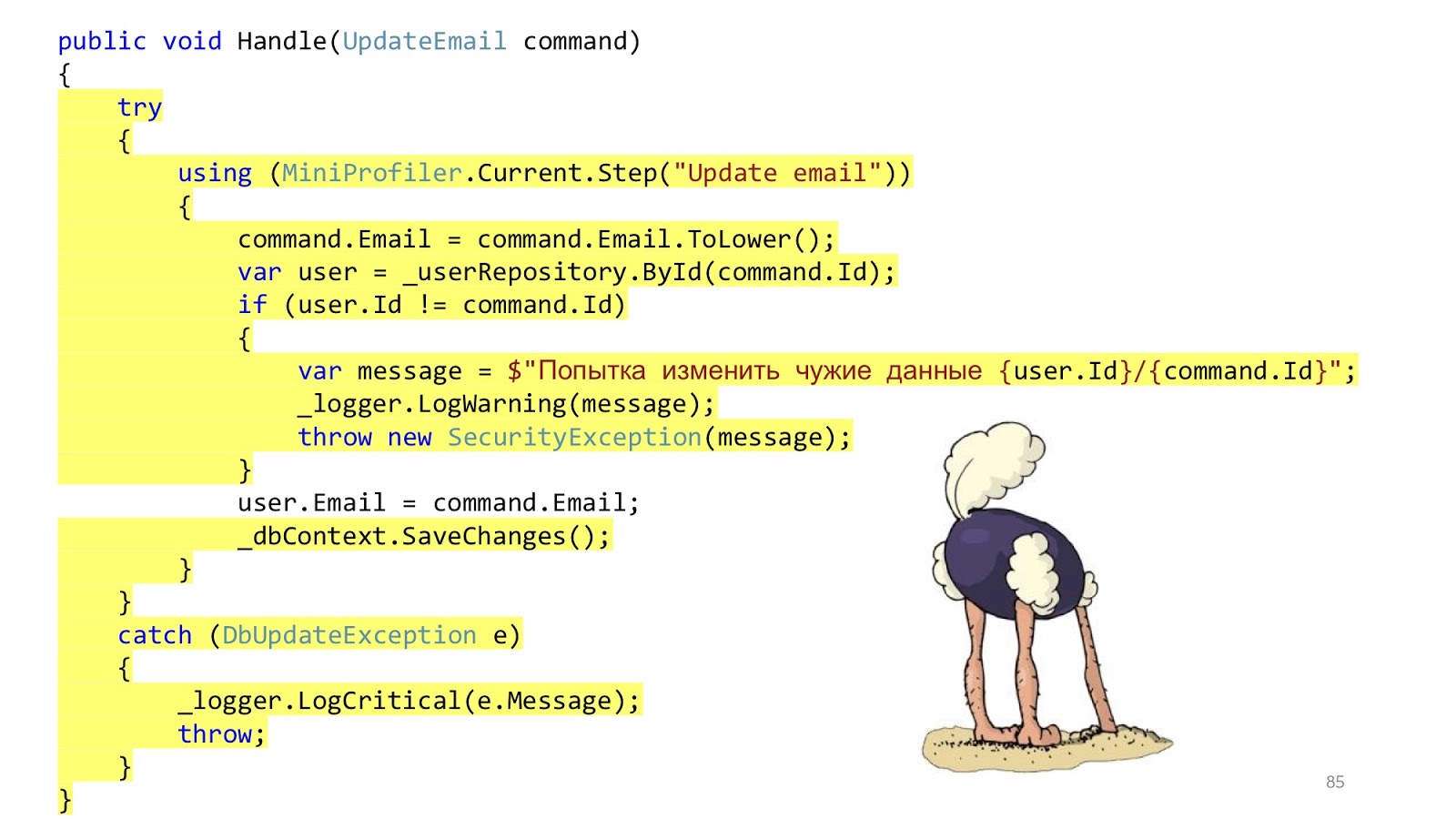
Le code peut ressembler à ceci. Ici, nous avons la validation
ASP.NET MVC standard, il y a ORM pour lire et mettre à jour les données, et il y a une sorte d'expéditeur d'email qui envoie une notification. Il semble que tout va bien, non? Une mise en garde - dans un monde idéal.
Dans le monde réel, la situation est légèrement différente. Le but est d'ajouter l'autorisation, la vérification des erreurs, le formatage, la journalisation et le profilage. Tout cela n'a rien à voir avec notre cas d'utilisation, mais cela devrait l'être. Et ce petit morceau de code est devenu gros et effrayant: avec beaucoup d'imbrication, avec beaucoup de code, avec le fait qu'il est difficile à lire, et surtout, qu'il y a plus de code d'infrastructure que de code de domaine.

"Où sont les services?" - dites-vous. J'ai écrit toute la logique aux contrôleurs. Bien sûr, c'est un problème, maintenant j'ajouterai des services, et tout ira bien.

Nous ajoutons des services, et ça va vraiment mieux, parce qu'au lieu d'un grand footcloth, nous avons obtenu une petite belle ligne.
Cela s'est-il amélioré? C'est devenu! Et maintenant, nous pouvons réutiliser cette méthode dans différents contrôleurs. Le résultat est évident. Examinons la mise en œuvre de cette méthode.
Mais ici, tout n'est pas si bon. Ce code est toujours là. Nous venons de transférer la même chose aux services. Nous avons décidé de ne pas résoudre le problème, mais simplement de le déguiser et de le transférer dans un autre endroit. C’est tout.

En plus de cela, d'autres questions se posent. Faut-il faire la validation dans le contrôleur ou ici? Eh bien, un peu comme dans le contrôleur. Et si vous devez aller dans la base de données et voir qu'il existe un tel ID ou qu'il n'y a pas d'autre utilisateur avec un tel e-mail? Hmm, enfin au service. Mais la gestion des erreurs ici? Cette gestion des erreurs est probablement là, et la gestion des erreurs qui répondra au navigateur du contrôleur. Et la méthode SaveChanges, est-elle dans le service ou devez-vous la transférer vers le contrôleur? Il peut en être ainsi, car si un service est appelé, il est plus logique d'appeler le service, et si vous avez trois méthodes de services dans le contrôleur qui doivent être appelées, vous devez l'appeler en dehors de ces services pour que la transaction soit une. Ces réflexions suggèrent que les couches ne résolvent peut-être aucun problème.

Et cette idée est venue à plus d'une personne. Si vous google, au moins trois de ces maris respectables écrivent sur la même chose. De haut en bas: Stephen .NET Junkie (malheureusement, je ne connais pas son nom de famille, car elle n'apparaît nulle part sur Internet), l'auteur du conteneur IoC
Simple Injector . Jimmy Bogard est l'auteur d'
AutoMapper . Et en bas se trouve Scott Vlashin, auteur de
F # pour le plaisir et le profit .
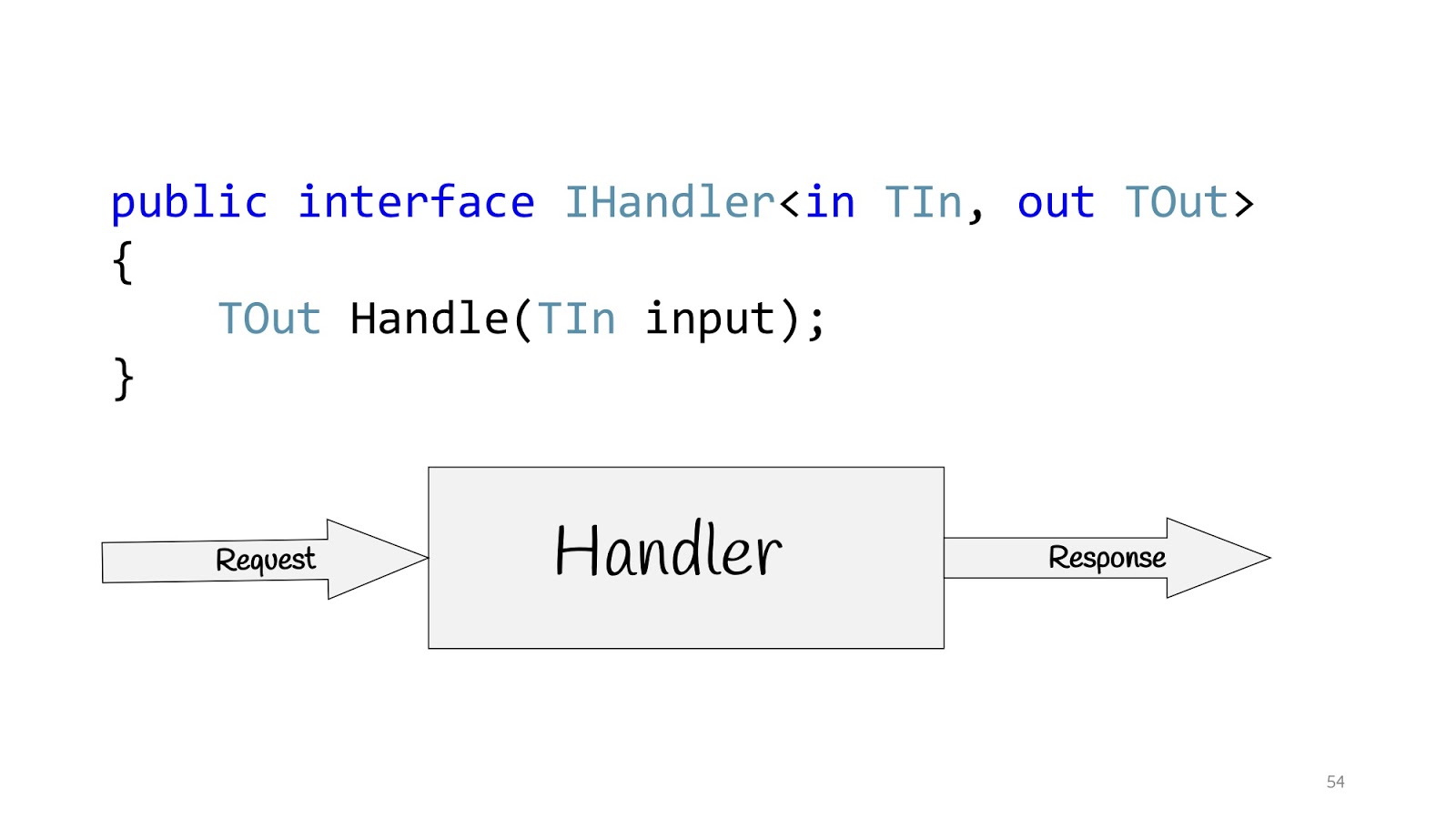
Toutes ces personnes parlent de la même chose et suggèrent de créer des applications non pas sur la base de couches, mais sur la base de cas d'utilisation, c'est-à-dire des exigences que l'entreprise nous demande. Par conséquent, le cas d'utilisation en C # peut être déterminé à l'aide de l'interface IHandler. Il a des valeurs d'entrée, il y a des valeurs de sortie et il y a une méthode elle-même qui exécute réellement ce cas d'utilisation.

Et à l'intérieur de cette méthode, il peut y avoir soit un modèle de domaine, soit un modèle dénormalisé pour la lecture, peut-être avec Dapper ou avec Elastic Search, si vous avez besoin de chercher quelque chose, et peut-être que vous avez Legacy -système avec des procédures stockées - pas de problème, ainsi que des requêtes réseau - enfin, en général, tout ce dont vous pourriez avoir besoin. Mais s'il n'y a pas de couches, que faire?

Pour commencer, débarrassons-nous de UserService. Nous supprimons la méthode et créons une classe. Et nous allons le supprimer, et nous le supprimerons à nouveau. Et puis prenez et retirez la classe.

Pensons, ces classes sont-elles équivalentes ou non? La classe GetUser renvoie des données et ne change rien sur le serveur. Ceci, par exemple, à propos de la demande "Donnez-moi l'ID utilisateur". Les classes UpdateEmail et BanUser renvoient le résultat de l'opération et modifient l'état. Par exemple, lorsque nous disons au serveur: "Veuillez changer l'état, vous devez changer quelque chose."
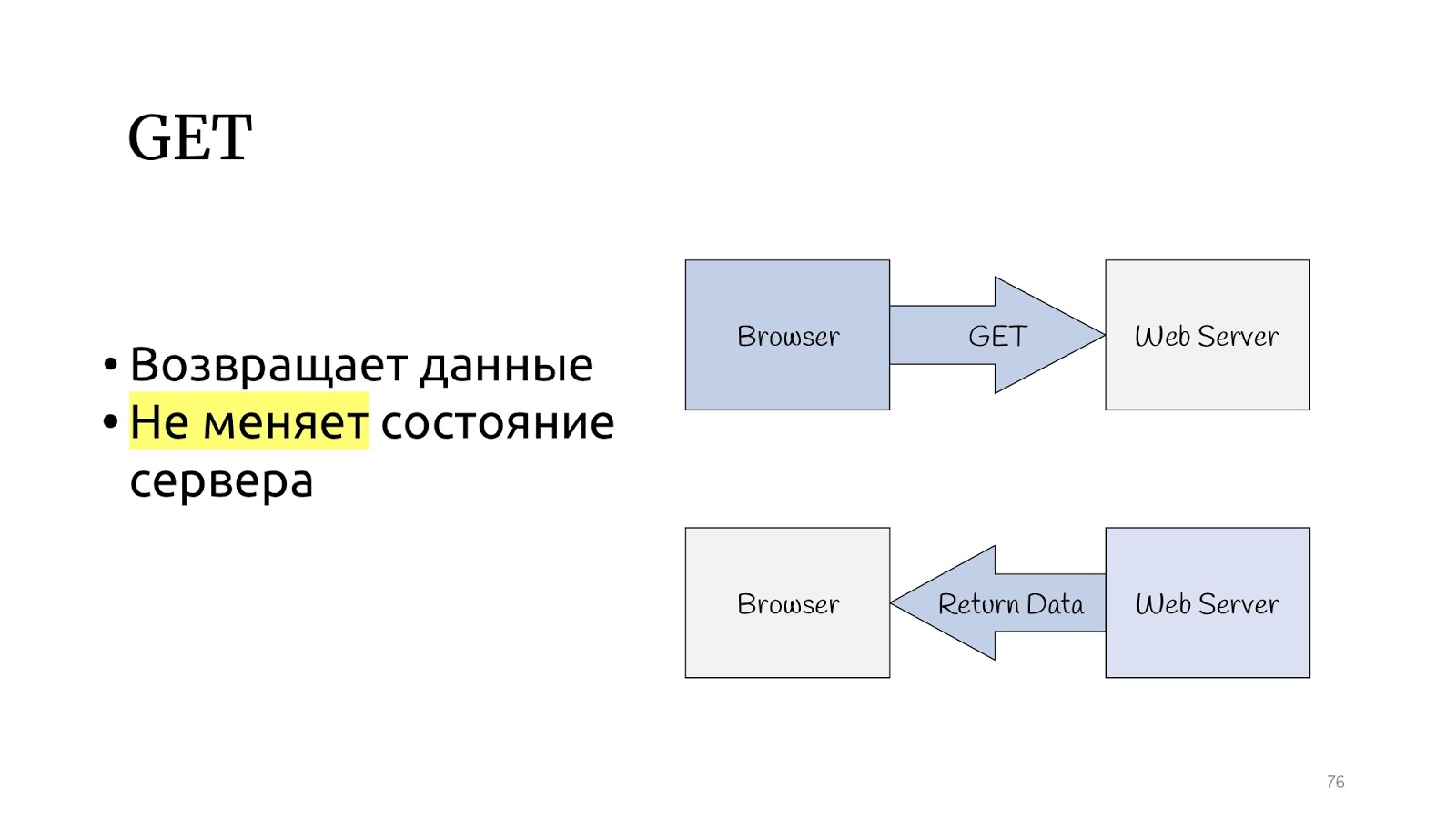
Regardons le protocole HTTP. Il existe une méthode GET qui, selon la spécification du protocole HTTP, devrait renvoyer des données et ne pas changer l'état du serveur.

Et il existe d'autres méthodes qui peuvent modifier l'état du serveur et renvoyer le résultat de l'opération.

Le paradigme CQRS semble être spécifiquement conçu pour le protocole HTTP. Les requêtes sont des opérations GET et les commandes sont PUT, POST, DELETE - pas besoin d'inventer quoi que ce soit.
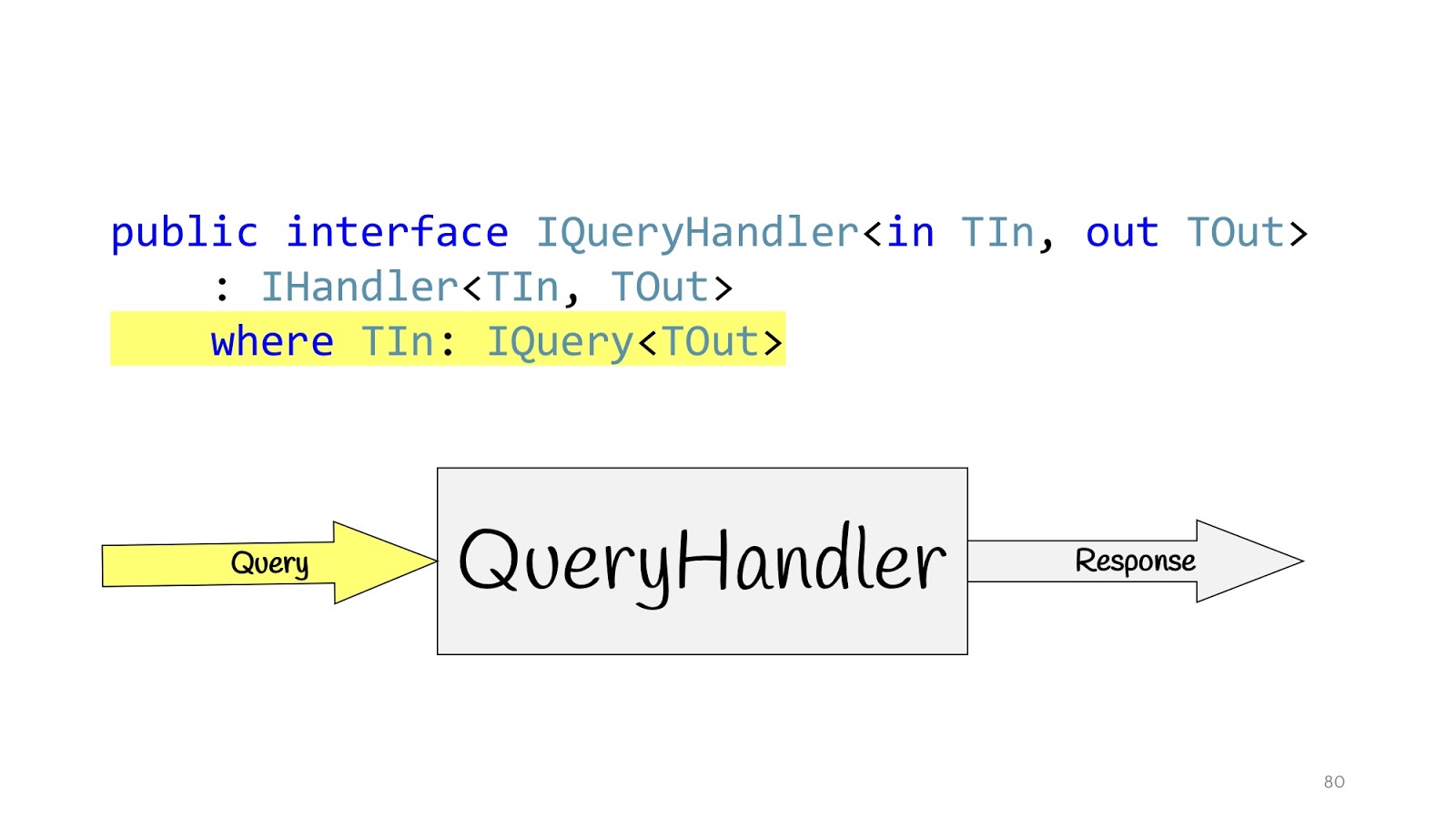
Nous redéfinissons notre gestionnaire et définissons des interfaces supplémentaires. IQueryHandler, qui ne diffère que par le fait que nous avons suspendu la contrainte que le type de valeurs d'entrée est IQuery. IQuery est une interface de marqueur, il n'y a rien d'autre que ce générique. Nous avons besoin du générique afin de mettre une contrainte dans le QueryHandler, et maintenant, en déclarant QueryHandler, nous ne pouvons pas y passer pas Query, mais en passant l'objet Query là, nous connaissons sa valeur de retour. C'est pratique si vous n'avez qu'une seule interface, vous n'avez donc pas à chercher leur implémentation dans le code, et encore pour ne pas gâcher. Vous écrivez IQueryHandler, y écrivez une implémentation et dans TOut vous ne pouvez pas remplacer un autre type de valeur de retour. Il ne compile tout simplement pas. Ainsi, vous pouvez immédiatement voir quelles valeurs d'entrée correspondent à quelles données d'entrée.

La situation est complètement similaire pour CommandHandler à une exception près: ce générique est nécessaire pour une autre astuce, que nous verrons un peu plus loin.
Implémentation du gestionnaire
Les gestionnaires, avons-nous annoncé, quelle est leur mise en œuvre?
Y a-t-il un problème, oui? Quelque chose semble avoir échoué.
Les décorateurs se précipitent à la rescousse
Mais cela n'a pas aidé, parce que nous sommes encore au milieu de la route, nous devons finaliser un peu plus, et cette fois nous devons utiliser le motif de décoration, à savoir sa merveilleuse fonctionnalité de mise en page. Le décorateur peut être enveloppé dans un décorateur, enveloppé dans un décorateur, enveloppé dans un décorateur - continuez jusqu'à ce que vous vous ennuyiez.
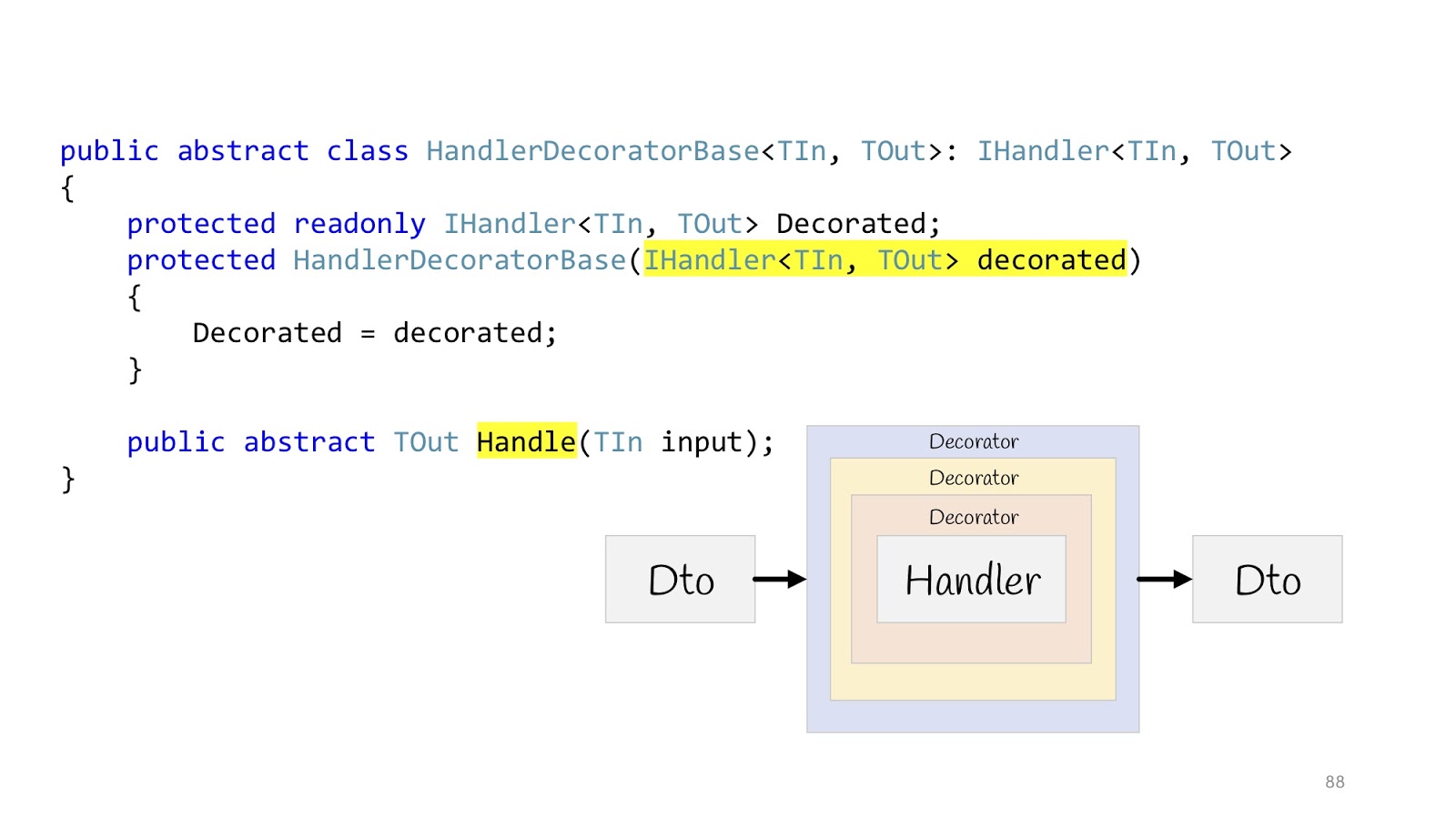
Ensuite, tout ressemblera à ceci: il y a une entrée Dto, elle entre dans le premier décorateur, la deuxième, la troisième, puis nous entrons dans le gestionnaire et la quittons également, parcourons tous les décorateurs et retournons Dto dans le navigateur. Nous déclarons une classe de base abstraite afin d'hériter plus tard, le corps de Handler est passé au constructeur, et nous déclarons la méthode abstraite Handle, dans laquelle une logique de décorateur supplémentaire sera suspendue.
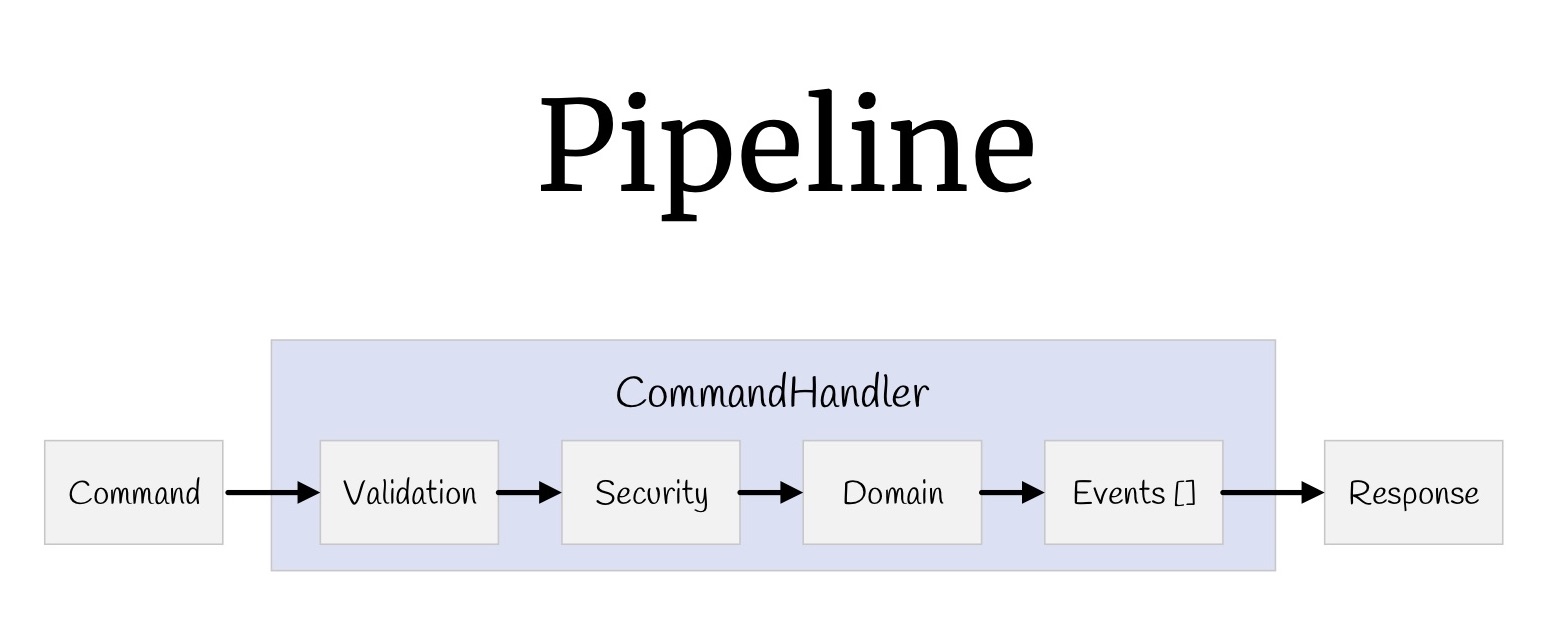
Maintenant, avec l'aide de décorateurs, vous pouvez construire un pipeline entier. Commençons par les équipes. Qu'avions-nous? Valeurs d'entrée, validation, vérification des droits d'accès, la logique elle-même, certains événements qui se produisent à la suite de cette logique et valeurs de retour.

Commençons par la validation. Nous déclarons un décorateur. IEnumerable des validateurs de type T entre dans le constructeur de ce décorateur. Nous les exécutons tous, vérifions si la validation échoue et le type de retour est
IEnumerable<validationresult> , puis nous pouvons le renvoyer car les types correspondent. Et s'il s'agit d'un autre Hander, eh bien, vous devez lever une exception, car il n'y a pas de résultat ici, le type d'une autre valeur de retour.
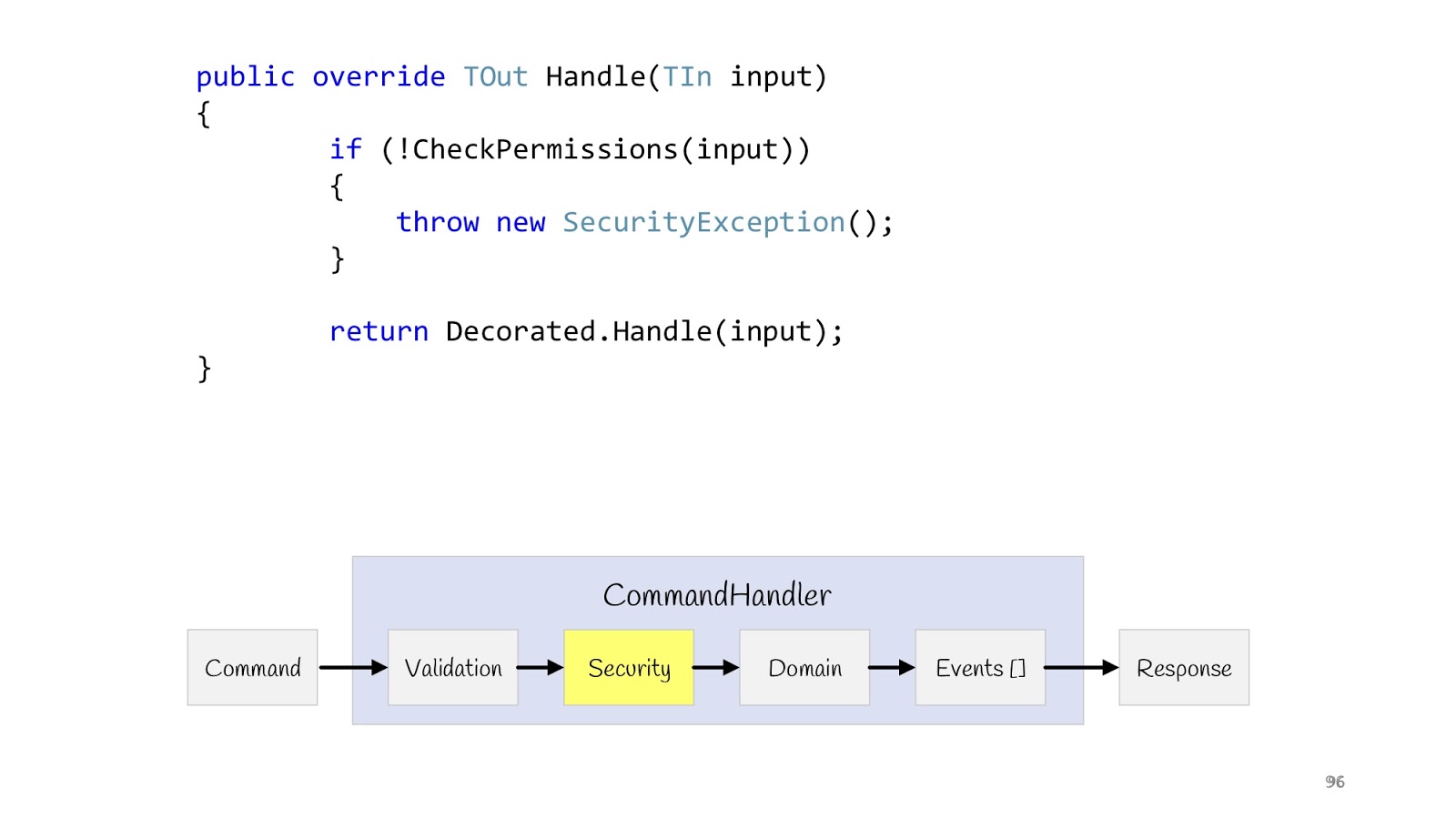
La prochaine étape est la sécurité. Nous déclarons également le décorateur, réalisons la méthode CheckPermission et vérifions. Si tout à coup quelque chose tournait mal, tout, on ne continue pas. Maintenant, après avoir terminé tous les contrôles et être sûrs que tout va bien, nous pouvons remplir notre logique.
Avant de montrer l'implémentation de la logique, je veux commencer un peu plus tôt, à savoir avec les valeurs d'entrée qui y viennent.
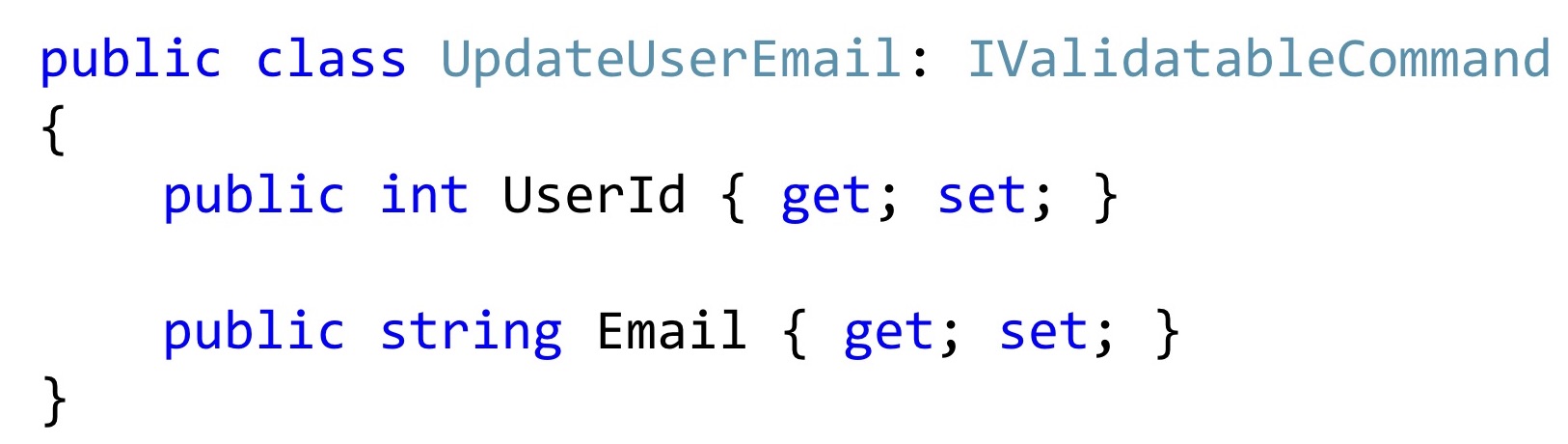
Maintenant, si nous choisissons une telle classe, alors le plus souvent, elle peut ressembler à ceci. Au moins le code que je vois dans le travail quotidien.
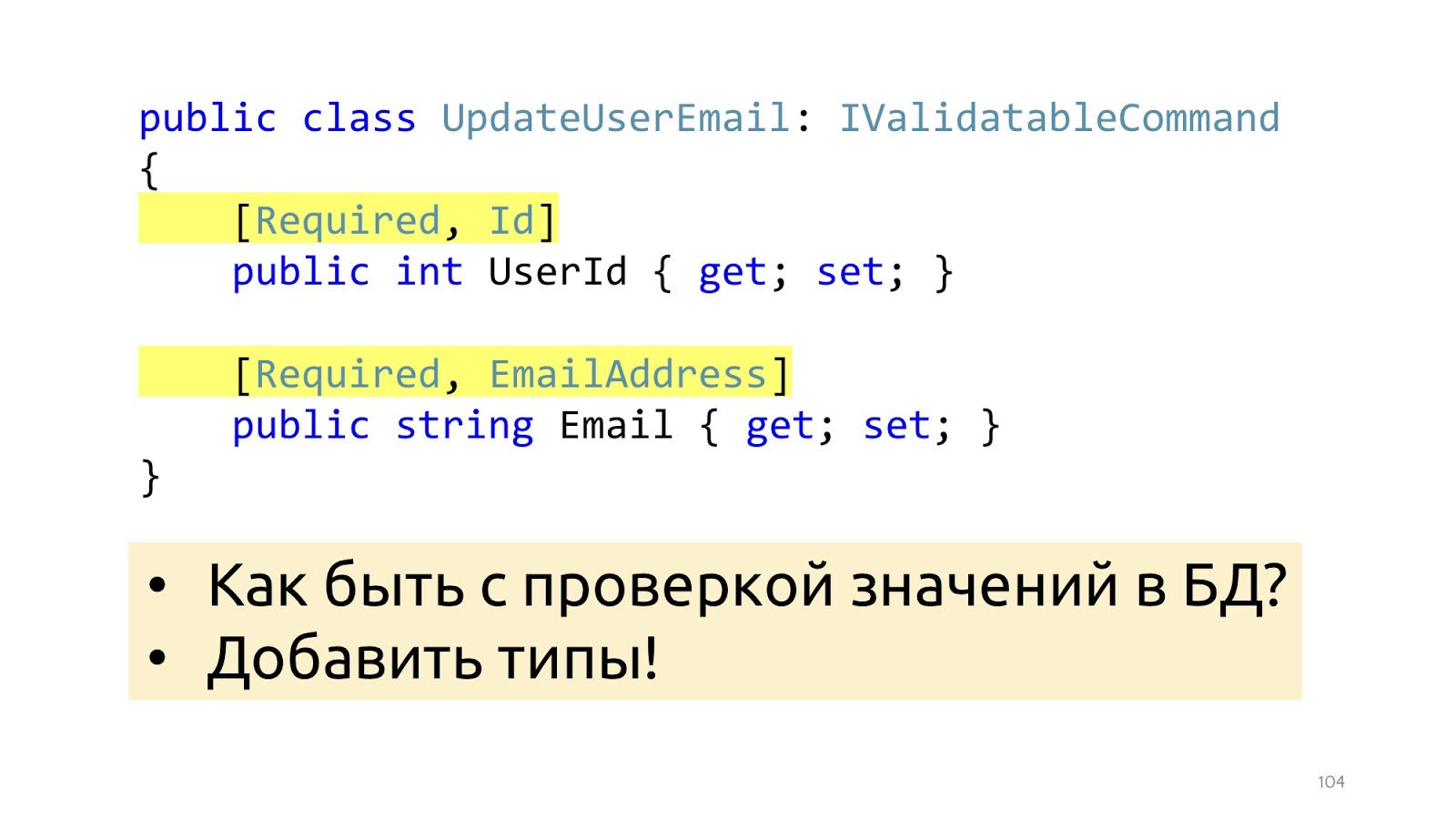
Pour que la validation fonctionne, nous ajoutons ici quelques attributs qui vous indiquent de quel type de validation il s'agit. Cela aidera du point de vue de la structure des données, mais ne facilitera pas une telle validation comme la vérification des valeurs dans la base de données. C'est simplement EmailAddress, on ne sait pas comment, où vérifier comment utiliser ces attributs pour accéder à la base de données. Au lieu d'attributs, vous pouvez passer à des types spéciaux, puis ce problème sera résolu.

Au lieu de la primitive
int , nous déclarons un type Id qui a un générique que c'est une certaine entité avec une clé int. Et nous passons cette entité au constructeur, ou passons son Id, mais en même temps nous devons passer une fonction que par Id peut prendre et retourner, vérifier si elle est nulle là ou non nulle.
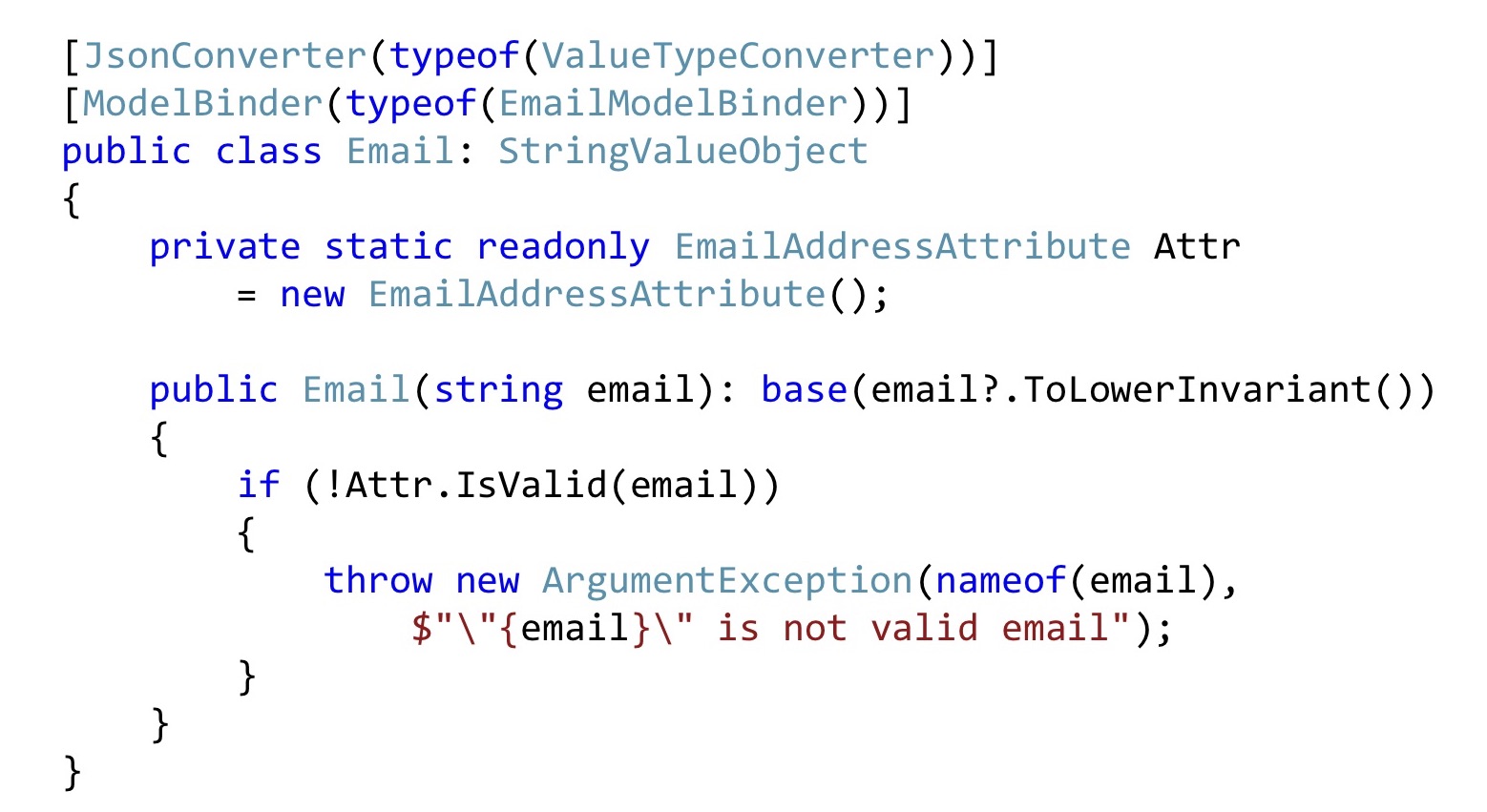
Nous faisons de même avec le courrier électronique. Convertissez tous les e-mails en ligne de fond afin que tout se ressemble pour nous. Ensuite, nous prenons l'attribut Email, le déclarons statique pour la compatibilité avec la validation ASP.NET, et ici nous l'appelons simplement. Autrement dit, cela peut également être fait. Pour que l'infrastructure ASP.NET intercepte tout cela, vous devez modifier légèrement la sérialisation et / ou ModelBinding. Il n'y a pas beaucoup de code, c'est relativement simple, donc je ne m'arrêterai pas là.
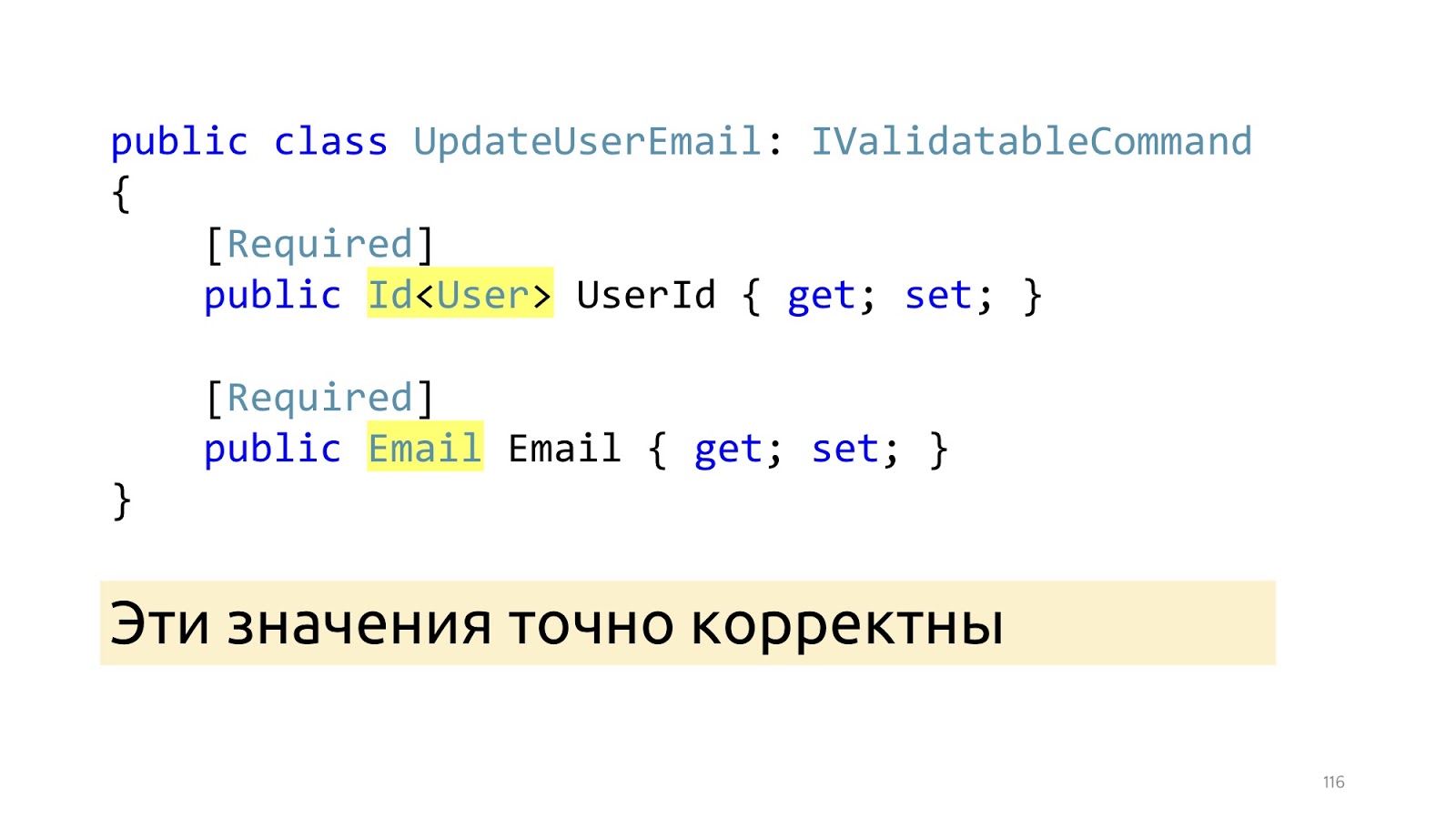
Après ces modifications, au lieu des types primitifs, des types spécialisés apparaissent ici: Id et Email. Et après que ces ModelBinder et le désérialiseur mis à jour ont fonctionné, nous savons avec certitude que ces valeurs sont correctes, y compris que ces valeurs sont dans la base de données. "Invariants"

Le point suivant sur lequel je voudrais m'attarder est l'état des invariants dans la classe, car très souvent un
modèle anémique est utilisé, dans lequel il n'y a qu'une classe, de nombreux getter-setters, on ne sait pas très bien comment ils devraient travailler ensemble. Nous travaillons avec une logique métier complexe, il est donc important pour nous que le code soit auto-documenté. Au lieu de cela, il est préférable de déclarer le vrai constructeur avec vide pour ORM, il peut être déclaré protégé de sorte que les programmeurs dans leur code d'application ne puissent pas l'appeler, et ORM le pourrait. Ici, nous ne transmettons pas le type primitif, mais le type Email, il est déjà correctement correct, s'il est nul, nous lançons toujours une exception. Vous pouvez utiliser un peu de Fody, PostSharp, mais C # 8 arrive bientôt. Par conséquent, il y aura un type de référence non nul, et il est préférable d'attendre son support dans le langage. Le moment suivant, si nous voulons changer le nom et le prénom, nous voulons très probablement les changer ensemble, donc il doit y avoir une méthode publique appropriée qui les change ensemble.

Dans cette méthode publique, nous vérifions également que la longueur de ces lignes correspond à ce que nous utilisons dans la base de données. Et si quelque chose ne va pas, arrêtez l'exécution. Ici, j'utilise la même astuce. Je déclare un attribut spécial et je l'appelle simplement dans le code d'application.
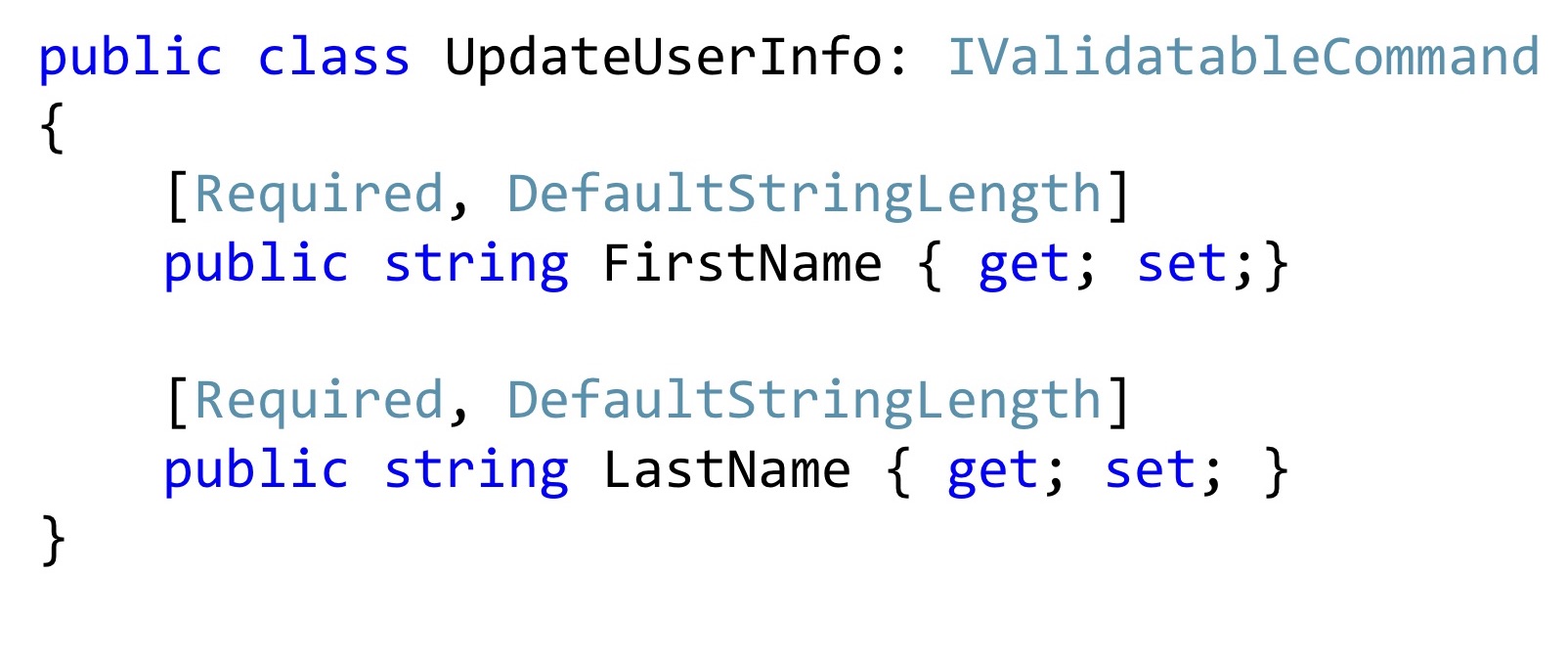
De plus, ces attributs peuvent être réutilisés dans Dto. Maintenant, si je veux changer le nom et le prénom, je peux avoir une telle commande de changement. Vaut-il la peine d'ajouter un constructeur spécial ici? Cela semble valoir le coup. Cela ira mieux, personne ne changera ces valeurs, ne les cassera pas, elles auront exactement raison.

En fait, pas vraiment. Le fait est que les Dto ne sont pas vraiment des objets. C'est un tel dictionnaire dans lequel nous mettons des données désérialisées. Autrement dit, ils prétendent être des objets, bien sûr, mais ils n'ont qu'une seule responsabilité - c'est d'être sérialisé et désérialisé. Si nous essayons de lutter contre cette structure, nous commencerons à annoncer des ModelBinders avec les concepteurs, faire quelque chose comme ça est incroyablement fatigant et, surtout, cela rompra avec les nouvelles versions de nouveaux frameworks. Tout cela a été bien décrit par Mark Simon dans l'article
«Aux frontières du programme ne sont pas orientés objet» , si c'est intéressant, il vaut mieux lire son billet, là c'est décrit en détail.

En bref, nous avons un monde externe sale, nous mettons des vérifications à l'entrée, le convertissons en notre modèle propre, puis le transférons tous à la sérialisation, au navigateur, à nouveau au monde externe sale.
Gestionnaire
Après tous ces changements, à quoi ressemblera le Hander ici?

J'ai écrit deux lignes ici afin de le rendre plus pratique à lire, mais en général, il peut être écrit en une seule. Les données sont exactement correctes, car nous avons un système de type, il y a une validation, c'est-à-dire que les données sont en béton armé, vous n'avez pas besoin de les vérifier à nouveau. Un tel utilisateur existe également, il n'y a pas d'autre utilisateur avec un email aussi chargé, tout peut être fait. Cependant, il n'y a toujours pas d'appel à la méthode SaveChanges, il n'y a pas de notification et il n'y a pas de journaux et de profileurs, non? Nous continuons.
Les événements
Événements de domaine.

Probablement la première fois que ce concept a été popularisé par Udi Dahan dans son article
«Événements de domaine - Salut» . Là, il suggère simplement de déclarer une classe statique avec la méthode Raise et de lancer de tels événements. Un peu plus tard, Jimmy Bogard a proposé une meilleure implémentation, elle s'appelle
"Un meilleur modèle d'événements de domaine" .
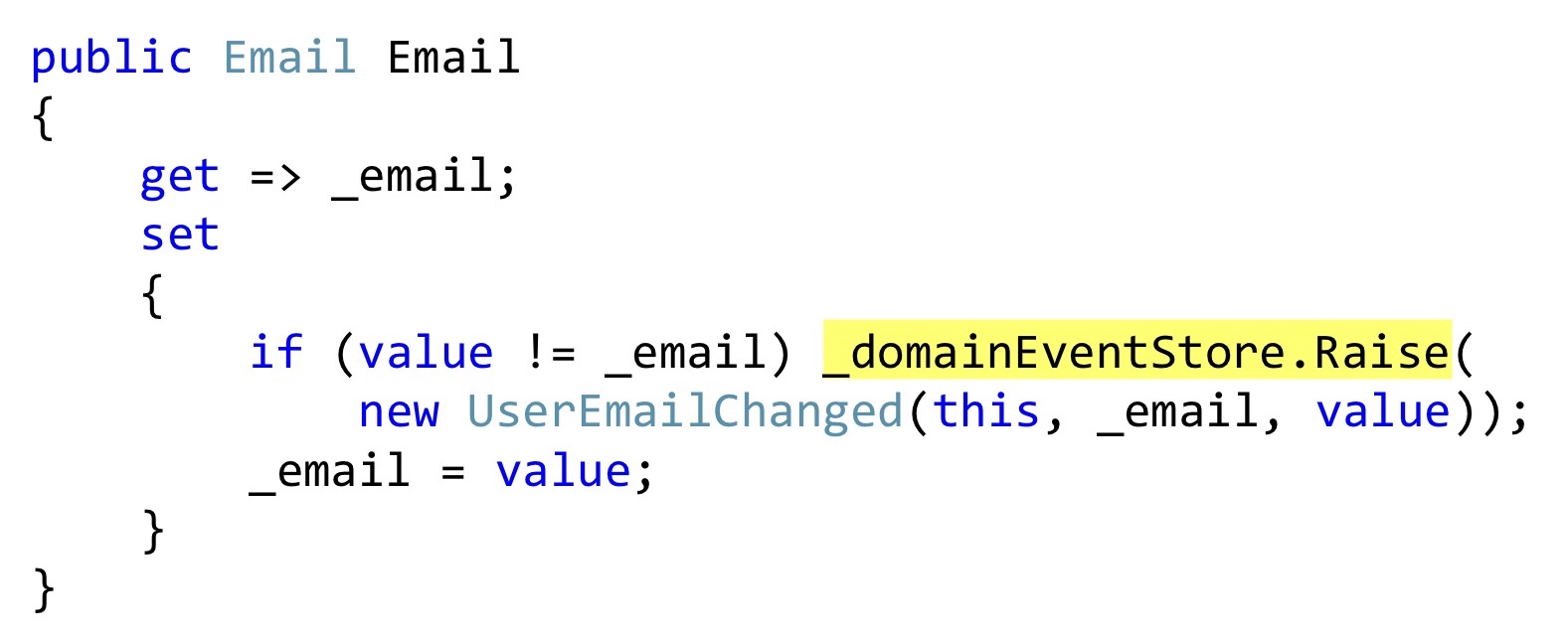
Je vais montrer la sérialisation de Bogard avec un petit changement, mais important. Au lieu de lancer des événements, nous pouvons déclarer une liste, et dans les endroits où une sorte de réaction devrait avoir lieu, directement à l'intérieur de l'entité pour enregistrer ces événements. Dans ce cas, cet getter de
email est également une classe User, et cette classe, cette propriété ne prétend pas être une propriété avec des getters et des setters automatiques, mais ajoute vraiment quelque chose à cela. Autrement dit, il s'agit d'une véritable encapsulation, pas de blasphèmes. Lors du changement, nous vérifions que l'e-mail est différent et lançons un événement. Cet événement n'est encore arrivé nulle part, nous ne l'avons que dans la liste interne des entités.

De plus, au moment où nous appellerons la méthode SaveChanges, nous prenons ChangeTracker, voir s'il existe des entités qui implémentent l'interface, si elles ont des événements de domaine. Et s'il y en a, prenons tous ces événements de domaine et envoyons-les à un répartiteur qui sait quoi en faire.
L'implémentation de ce répartiteur est un sujet pour une autre discussion, il y a quelques difficultés avec la répartition multiple en C #, mais cela se fait également. Avec cette approche, il y a un autre avantage non évident. Maintenant, si nous avons deux développeurs, l'un peut écrire du code qui modifie cet e-mail, et l'autre peut faire un module de notification. Ils ne sont absolument pas connectés entre eux, ils écrivent un code différent, ils ne sont connectés qu'au niveau de cet événement de domaine d'une classe Dto. Le premier développeur jette simplement cette classe à un moment donné, le second y répond et sait qu'elle doit être envoyée par e-mail, SMS, notifications push au téléphone et tous les autres millions de notifications, en tenant compte des préférences des utilisateurs qui se produisent généralement.
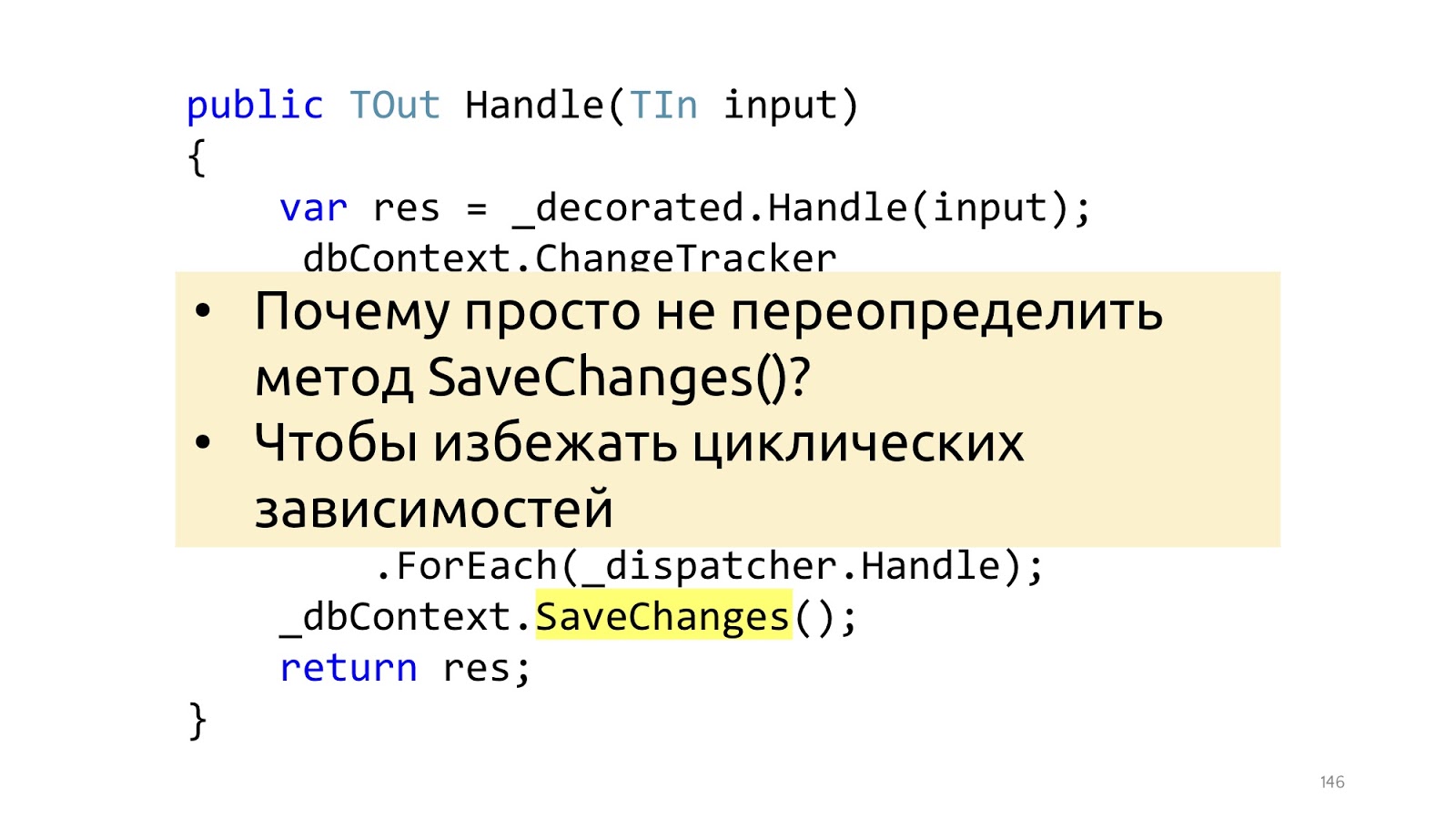
Voici le point le plus petit mais le plus important. L'article de Jimmy utilise une surcharge de la méthode SaveChanges, et il vaut mieux ne pas le faire. Et il vaut mieux le faire dans le décorateur, car si nous surchargeons la méthode SaveChanges et que nous avions besoin de dbContext dans le gestionnaire, nous obtiendrons des dépendances circulaires. Vous pouvez travailler avec cela, mais les solutions sont un peu moins pratiques et un peu moins belles. Par conséquent, si le pipeline est construit sur des décorateurs, je ne vois aucune raison de le faire différemment.
Journalisation et profilage

L'imbrication du code est restée, mais dans l'exemple initial, nous avons d'abord utilisé MiniProfiler, puis essayez catch, puis if. Au total, il y avait trois niveaux d'imbrication, maintenant chacun ce niveau d'imbrication est dans son propre décorateur. Et à l'intérieur du décorateur, qui est responsable du profilage, nous n'avons qu'un seul niveau d'imbrication, le code est parfaitement lu. De plus, il est clair que chez ces décorateurs il n'y a qu'une seule responsabilité. Si le décorateur est responsable de la journalisation, il ne se connectera que, si pour le profilage, respectivement, uniquement le profil, tout le reste est ailleurs.
Réponse
Une fois que tout le pipeline a fonctionné, nous ne pouvons que prendre Dto et l'envoyer au navigateur, sérialiser JSON.
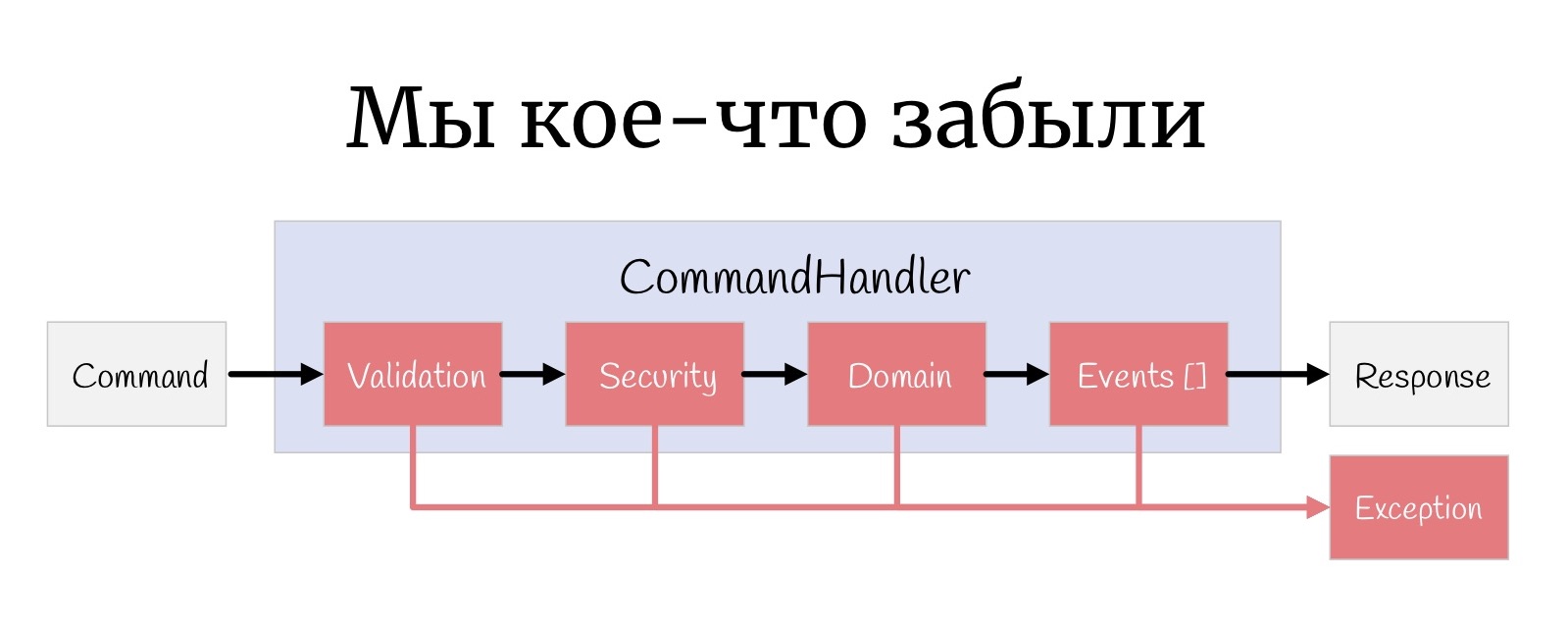
Mais encore une petite chose, une chose qui est parfois oubliée: à chaque étape, une exception peut se produire ici, et en fait vous devez en quelque sorte les gérer.

Je ne peux pas ne pas mentionner encore Scott Vlashin et son rapport
«Programmation axée sur les chemins de fer» . Pourquoi? Le rapport original est entièrement consacré à travailler avec les erreurs dans le langage F #, comment organiser le flux un peu différemment et pourquoi une telle approche peut être préférable à l'utilisation d'Exception'ov. En F #, cela fonctionne vraiment très bien, car F # est un langage fonctionnel, et Scott utilise les fonctionnalités d'un langage fonctionnel.

Puisque, probablement, la plupart d'entre vous écrivent toujours en C #, si vous écrivez
un analogue en C # , cette approche ressemblera à ceci. Au lieu de lever des exceptions, nous déclarons une classe Result qui a une branche réussie et une branche non réussie. En conséquence, deux designers. Une classe ne peut être que dans un seul état. Cette classe est un cas particulier de type union, union discriminée de F #, mais réécrite en C #, car il n'y a pas de support intégré en C #.

Au lieu de déclarer des getters publics que quelqu'un pourrait ne pas vérifier la null dans le code, la correspondance de modèle est utilisée. Encore une fois, en F #, ce serait un langage de correspondance de motifs intégré, en C #, nous devons écrire une méthode distincte dans laquelle nous passerons une fonction qui sait quoi faire avec le résultat réussi de l'opération, comment le convertir plus loin dans la chaîne, et cela avec une erreur. Autrement dit, quelle que soit la branche qui a fonctionné pour nous, nous devons convertir cela en un seul résultat renvoyé. En F #, tout cela fonctionne très bien, car il y a une composition fonctionnelle, eh bien, et tout le reste que j'ai déjà répertorié. Dans .NET, cela fonctionne un peu moins bien, car dès que vous avez plusieurs résultats, mais beaucoup - et presque toutes les méthodes peuvent échouer pour une raison ou une autre - presque tous vos types de fonctions résultants deviennent des types de résultats, et vous en avez besoin en tant que pour combiner quelque chose.

La façon la plus simple de les combiner consiste à
utiliser LINQ , car en fait LINQ fonctionne non seulement avec IEnumerable, si vous redéfinissez les méthodes SelectMany et Select de la bonne manière, le compilateur C # verra que vous pouvez utiliser la syntaxe LINQ pour ces types. En général, il s'avère que du papier calque avec la notation Haskell do ou avec les mêmes expressions de calcul en F #. Comment lire cela? Ici, nous avons trois résultats de l'opération, et si tout va bien dans les trois cas, prenez ces résultats r1 + r2 + r3 et ajoutez-les. Le type de la valeur résultante sera également Result, mais le nouveau Result, que nous déclarons dans Select. En général, c'est même une approche de travail, sinon une, mais.

Pour tous les autres développeurs, dès que vous commencez à écrire un tel code en C #, vous commencez à ressembler à ceci. «Ce sont de mauvaises exceptions effrayantes, ne les écrivez pas! Ils sont mauvais! Mieux vaut écrire du code que personne ne comprend et ne peut pas déboguer! »

C # n'est pas F #, il est quelque peu différent, il n'y a pas de concepts différents sur la base desquels cela se fait, et lorsque nous essayons de tirer un hibou sur le globe, il s'avère, pour le dire doucement, inhabituel.

Au lieu de cela, vous pouvez utiliser les
outils normaux intégrés qui sont documentés, que tout le monde connaît et qui ne provoqueront pas de dissonance cognitive chez les développeurs. ASP.NET a une exception de gestionnaire globale.

Nous savons que s'il y a des problèmes de validation, vous devez retourner le code 400 ou 422 (Entité non traitable). S'il y a un problème d'authentification et d'autorisation, il y a 401 et 403. Si quelque chose s'est mal passé, alors quelque chose s'est mal passé. Et si quelque chose s'est mal passé et que vous voulez dire exactement à l'utilisateur quoi, définissez votre type d'exception, dites que c'est IHasUserMessage, déclarez un getter de message dans cette interface et vérifiez simplement: si cette interface est implémentée, alors vous pouvez prendre un message d'Exception et le transmettre en JSON à l'utilisateur. Si cette interface n'est pas implémentée, il y a une sorte d'erreur système, et nous disons simplement aux utilisateurs que quelque chose s'est mal passé, nous le faisons déjà, nous le savons tous - comme d'habitude.
Pipeline de requête
Nous concluons cela avec les équipes et examinons ce que nous avons dans la pile de lecture. Quant à la demande, la validation, la réponse directe - c'est à peu près la même chose, nous ne nous arrêterons pas séparément. Il peut toujours y avoir un cache supplémentaire, mais en général il n'y a pas non plus de gros problèmes avec le cache.
La sécurité
Regardons mieux un contrôle de sécurité. Il peut également y avoir le même décorateur de sécurité, qui vérifie si cette demande peut être faite ou non:

Mais il y a un autre cas où nous affichons plus d'un enregistrement et affichons des listes, et pour certains utilisateurs, nous devons afficher une liste complète (par exemple, pour certains super administrateurs), et pour d'autres utilisateurs, nous devons répertorier des listes limitées, troisième - limité à l'autre, et comme c'est souvent le cas dans les applications d'entreprise, les droits d'accès peuvent être extrêmement sophistiqués, vous devez donc être sûr que les données qui ne ciblent pas ces utilisateurs ne se glissent pas dans ces listes.
Le problème est résolu
tout simplement . Nous pouvons redéfinir l'interface (IPermissionFilter) dans laquelle arrive la requête originale et renvoie la requête. La différence est que pour l'interrogable qui retourne, nous avons déjà imposé des conditions supplémentaires où, vérifié l'utilisateur actuel et dit: «Ici, ne renvoyez que ces données à cet utilisateur ...» - et puis toute votre logique liée aux autorisations . Encore une fois, si vous avez deux programmeurs, un programmeur va écrire des autorisations, il sait qu'il a besoin d'écrire juste beaucoup de permissionFilters et de vérifier qu'ils fonctionnent correctement pour toutes les entités. Et d'autres programmeurs ne savent rien de l'autorisation, dans leur liste, les données correctes passent toujours, c'est tout. Parce qu'ils reçoivent à l'entrée non plus la requête originale de dbContext, mais limitée aux filtres. Un tel permissionFilter a également une propriété de mise en page, nous pouvons ajouter et appliquer tous les permissionFilters. Par conséquent, nous obtenons le permissionFilter résultant, qui restreindra la sélection des données au maximum, en tenant compte de toutes les conditions qui conviennent à cette entité.

Pourquoi ne pas le faire avec les outils intégrés ORM, par exemple, les filtres globaux dans un framework d'entité? Encore une fois, afin de ne pas créer de dépendances cycliques pour vous-même et de ne pas faire glisser d'historique supplémentaire sur votre couche métier dans son contexte.
Pipeline de requête. Lire le modèle
Reste à regarder le modèle de lecture. Le paradigme CQRS n'utilise pas le modèle de domaine dans la pile de lecture, au lieu de cela, nous créons juste immédiatement le Dto dont le navigateur a besoin pour le moment.

Si nous écrivons en C #, il est fort probable que nous utilisons LINQ, s'il n'y a pas que des exigences de performance monstrueuses, et s'il y en a, alors vous n'aurez peut-être pas d'application d'entreprise. En général, ce problème peut être résolu une fois pour toutes avec un tel LinqQueryHandler. Voici une contrainte assez effrayante sur le générique: c'est Query, qui renvoie une liste de projections, et il peut toujours filtrer ces projections et trier ces projections. Elle ne travaille également qu'avec certains types d'entités et sait comment convertir ces entités en projections et renvoyer la liste de ces projections sous forme de Dto au navigateur.

La mise en œuvre de la méthode Handle peut être assez simple. Au cas où, vérifiez si ce filtre TQuery implémente pour l'entité d'origine. De plus, nous faisons une projection, c'est l'extension interrogeable AutoMapper. Si quelqu'un ne le sait toujours pas, AutoMapper peut créer des projections dans LINQ, c'est-à-dire celles qui créeront la méthode Select et ne la mapperont pas en mémoire.
Ensuite, nous appliquons le filtrage, le tri et affichons le tout dans le navigateur.
Comment exactement tout cela est fait, j'ai dit à Saint-Pétersbourg sur DotNext, ceci est un autre rapport entier, il est déjà disponible gratuitement et déchiffré dans le Habré , vous pouvez écouter, voir, lire comment écrire le filtrage, le tri et la projection en utilisant expression'ov pour quoi que ce soit une fois, puis réutilisé.Toutes les expressions ne sont pas également utiles traduites en SQL
. , DotNext', — SQL. Select , , , queryable- .
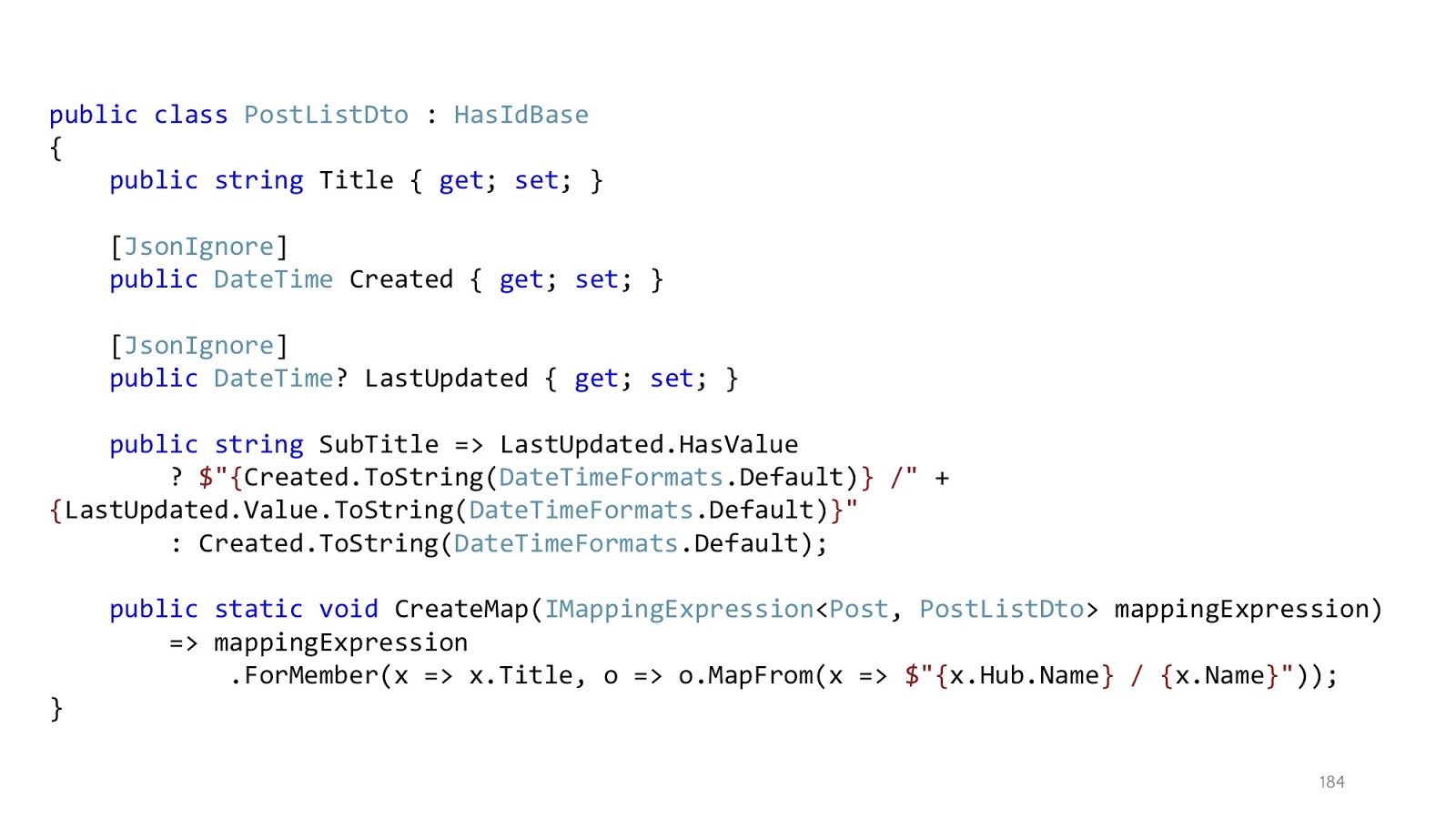
, . , Title, Title , . , . SubTitle, , , - , queryable- . , .
, . , , . , , . «JsonIgnore», . , , Dto. , , . JSON, , Created LastUpdated , SubTitle — , . , , , , , . , - .

. , -, , . , pipeline, . — , , . , SaveChanges, Query SaveChanges. , , , NuGet, .
. , - , , . , , , , , — . , , : « », — . .
, ?

- . .

, , , . MediatR , . , , — , MediatR pipeline behaviour. , Request/Response, RequestHandler' . Simple Injector, — .

, , , , TIn: ICommand.

Simple Injector' constraint' . , , , constraint', Handler', constraint. , constraint ICommand, SaveChanges constraint' ICommand, Simple Injector , constraint' , Handler'. , , , .
? Simple Injector MeriatR — , , Autofac', -, , , . , .
,
, «».
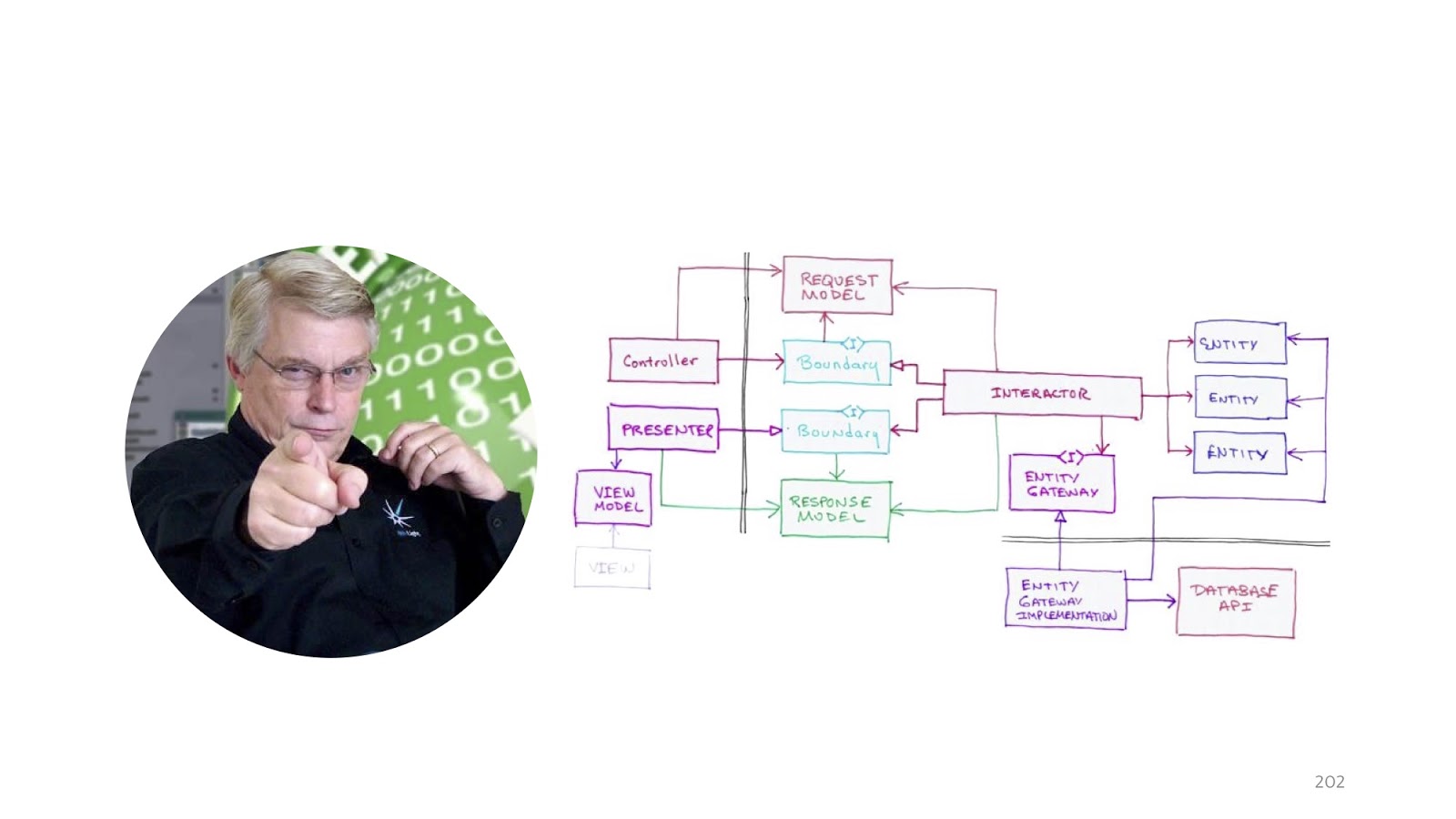
, «Clean architecture». .

- - , MVC, , .

, , , Angular, , , , . , : « — MVC-», : « Features, : , Blog - Import, - ».
, , , , MVC-, , - , . MVC . , , — . .


- , - -, .
-, , . , . , - , User Service, pull request', , User Service , . , - , - , . - , .
. , . , , , . , , , , , , , - . , ( , ), , «Delete»: , , . .
— «», , , , . , : , , , . , . , , . , , .
: . « », : , , . , , , , , , , . , . , - pull request , — , — - , . VCS : - , ? , - , , .

, , , . : . , . , , , , . , , , . , , . « », , . , , — , , .
: , - , . . - , , , , . - , - , , , , . .

. , IHandler . .
IHandler ICommandHandler IQueryHandler , . , , . , CommandHandler, CommandHandler', .
Pourquoi , Query , Query — . , , , Hander, CommandHandler QueryHandler, - use case, .
— , , , , : , .
, . , . , -.
C# 8, nullable reference type . , , , , .
ChangeTracker' ORM.
Exception' — , F#, C#. , - , - , . , , Exception', , LINQ, , , , , , Dapper - , , , .NET.
, LINQ, , permission' — . , , - , , . , — .
. :
- Vertical Slices
- Domain Events
- DDD
- ROP
- LINQ Expressions:
- Clean Architecture

— . . — «Domain Modeling Made Functional», F#, F#, , , , , . C# , , Exception'.
, , — «Entity Framework Core In Action». , Entity Framework, , DDD ORM, , ORM DDD .
Minute de publicité. 15-16 2019 .NET- DotNext Piter, . , .