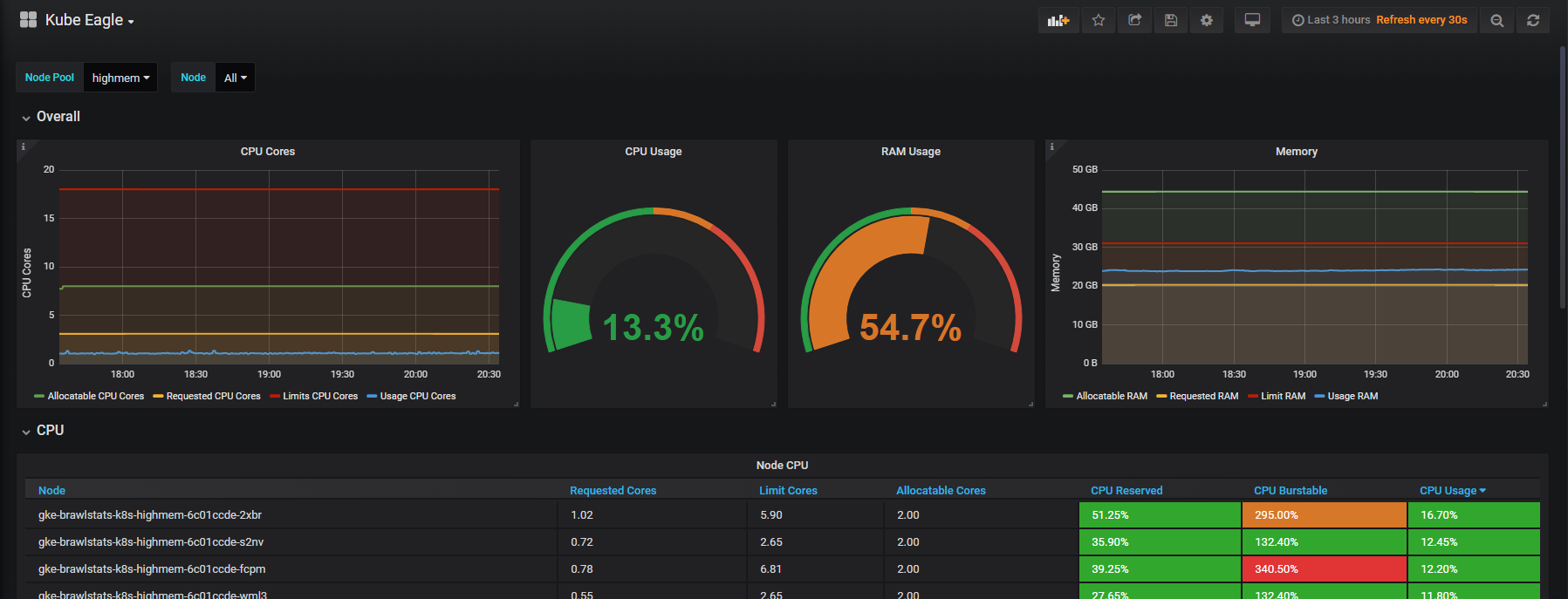
J'ai créé Kube Eagle - un exportateur de Prométhée. Cela s'est avéré être une chose intéressante qui aide à mieux comprendre les ressources des grappes petites et moyennes. En conséquence, j'ai économisé plus de cent dollars, car j'ai sélectionné les bons types de machines et configuré les limites de ressources d'application pour les charges de travail.
Je vais parler des avantages du Kube Eagle , mais je vais d'abord expliquer pourquoi l'agitation est sortie et pourquoi un contrôle de la qualité était nécessaire.
J'ai géré plusieurs clusters de 4 à 50 nœuds. Dans chaque cluster - jusqu'à 200 microservices et applications. Pour mieux utiliser le matériel disponible, la plupart des déploiements ont été configurés avec des ressources de RAM et de CPU éclatables. Les pods peuvent donc prendre les ressources disponibles, si nécessaire, et en même temps ne pas interférer avec d'autres applications sur ce nœud. Eh bien, n'est-ce pas génial?
Et bien que le cluster ait consommé relativement peu de CPU (8%) et de RAM (40%), nous avons constamment eu des problèmes d'éviction des foyers lorsqu'ils essayaient d'allouer plus de mémoire que ce qui est disponible sur le nœud. Ensuite, nous n'avions qu'un seul tableau de bord pour surveiller les ressources Kubernetes. En voici un:
Tableau de bord Grafana avec mesures cAdvisor uniquement
Avec un tel panneau, les nœuds qui consomment beaucoup de mémoire et de CPU ne sont pas un problème. Le problème est de comprendre la raison. Pour garder les pods en place, vous pouvez bien sûr configurer des ressources garanties sur tous les pods (les ressources demandées sont égales à la limite). Mais ce n'est pas l'utilisation la plus intelligente du fer. Il y avait plusieurs centaines de gigaoctets de mémoire sur le cluster, tandis que certains nœuds étaient affamés, tandis que d'autres avaient 4 à 10 Go en réserve.
Il s'avère que le planificateur Kubernetes répartit les charges de travail de manière inégale sur les ressources disponibles. Le planificateur Kubernetes prend en compte différentes configurations: règles d'affinité, de taintes et de tolérances, sélecteurs de nœuds pouvant limiter les nœuds disponibles. Mais dans mon cas, il n'y avait rien de tel, et les pods étaient planifiés en fonction des ressources demandées sur chaque nœud.
Pour le foyer, un nœud a été sélectionné qui dispose des ressources les plus libres et qui satisfait aux conditions de la demande. Il s'est avéré que les ressources demandées sur les nœuds ne correspondent pas à l'utilisation réelle, et ici Kube Eagle et sa capacité à surveiller les ressources sont venus à la rescousse.
J'ai presque tous les clusters Kubernetes suivis uniquement avec l' exportateur de nœuds et les métriques d'état Kube . Node Exporter fournit des statistiques d'utilisation des E / S et du disque, du processeur et de la RAM, et les métriques d'état du Kube affichent les métriques des objets Kubernetes, telles que les demandes et les limites des ressources CPU et mémoire.
Nous devons combiner les mesures d'utilisation avec les mesures de demande et de limite dans Grafana, puis nous obtenons toutes les informations sur le problème. Cela semble simple, mais en fait, dans ces deux outils, les étiquettes sont appelées différemment, et certaines métriques n'ont pas du tout d'étiquettes de métadonnées. Kube Eagle fait tout par lui-même et le panneau ressemble à ceci:
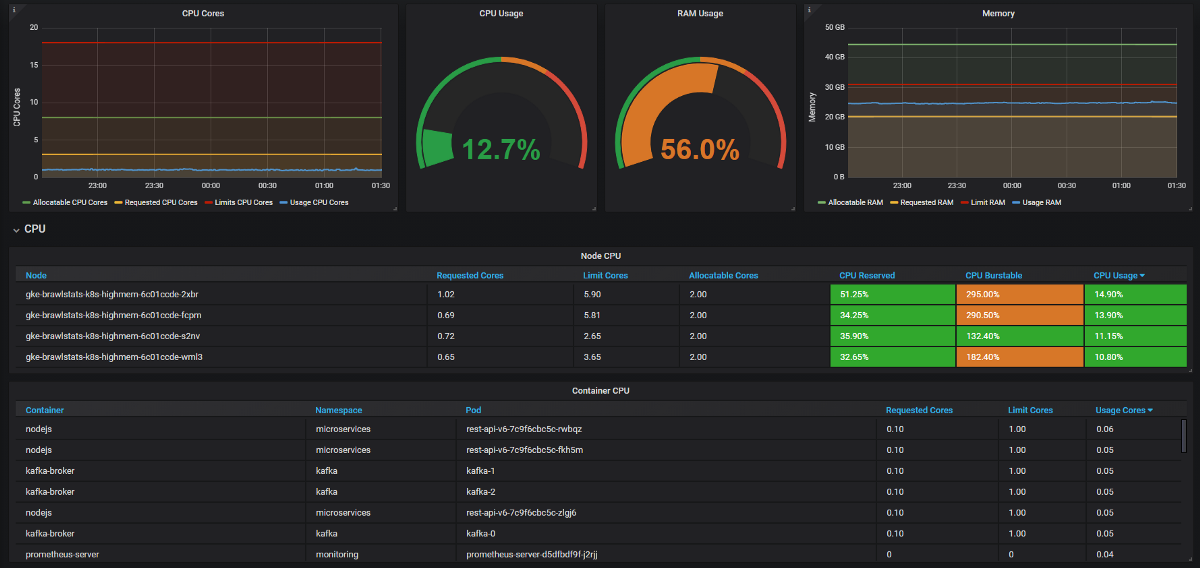
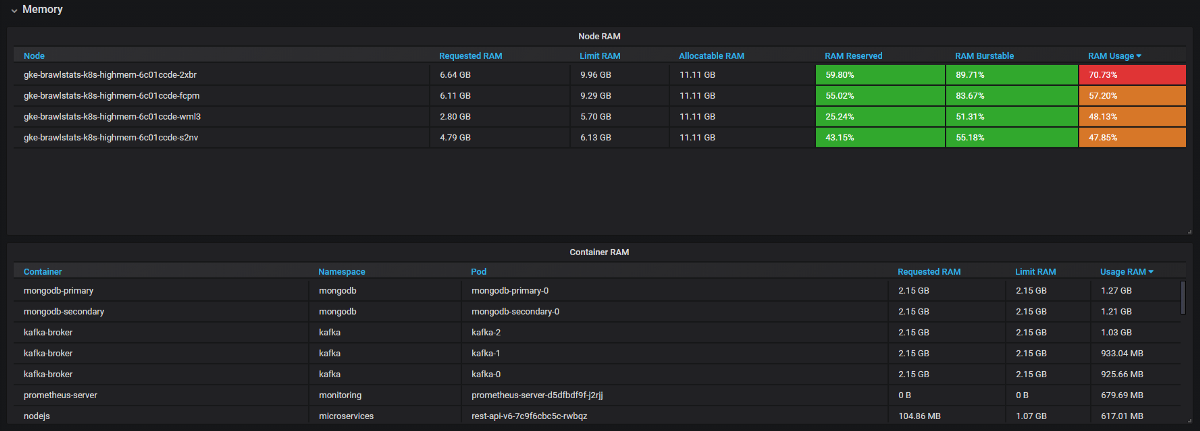
Tableau de bord Kube Eagle
Nous avons réussi à résoudre de nombreux problèmes de ressources et à économiser du matériel:
- Certains développeurs ne savaient pas combien de ressources les microservices avaient besoin (ou n'ont tout simplement pas pris la peine). Nous n'avions rien pour trouver les mauvaises demandes de ressources - pour cela, nous devons connaître la consommation plus les demandes et les limites. Maintenant, ils voient les métriques de Prometheus, surveillent l'utilisation réelle et affinent les requêtes et les limites.
- Les applications JVM prennent autant de RAM qu'elles n'en prennent. Le garbage collector ne libère de la mémoire que si plus de 75% est impliqué. Et comme la plupart des services ont une mémoire éclatable, la JVM l'a toujours occupée. Par conséquent, tous ces services Java ont consommé beaucoup plus de RAM que prévu.
- Certaines applications ont demandé trop de mémoire et le planificateur Kubernetes n'a pas donné ces nœuds à d'autres applications, bien qu'en fait ils soient plus libres que d'autres nœuds. Un développeur a accidentellement ajouté un chiffre supplémentaire dans la demande et a saisi un gros morceau de RAM: 20 Go au lieu de 2. Personne ne l'a remarqué. L'application avait 3 répliques, donc 3 nœuds ont été affectés.
- Nous avons introduit des limites de ressources, replanifié les pods avec les demandes correctes et obtenu l'équilibre parfait de l'utilisation du fer sur tous les nœuds. Deux nœuds peuvent généralement être fermés. Et puis nous avons vu que nous avions les mauvaises machines (orientées CPU, pas orientées mémoire). Nous avons changé le type et supprimé quelques nœuds supplémentaires.
Résumé
Avec des ressources éclatables dans un cluster, vous utilisez le matériel existant plus efficacement, mais le planificateur Kubernetes planifie les pods sur les demandes de ressources, ce qui est lourd. Pour tuer deux oiseaux avec une pierre: pour éviter les problèmes et utiliser au maximum les ressources, une bonne surveillance est nécessaire. Kube Eagle (exportateur Prometheus et tableau de bord Grafana) est utile pour cela.