En février-mars 2019, il y a eu un concours pour classer le flux du réseau social SNA Hackathon 2019 , dans lequel notre équipe a pris la première place. Dans cet article, je parlerai de l'organisation du concours, des méthodes que nous avons essayées et des paramètres catboost pour la formation sur le big data.

Hackathon SNA
Le hackathon sous ce nom a lieu pour la troisième fois. Il est organisé par le réseau social ok.ru, respectivement, la tâche et les données sont directement liées à ce réseau social.
Dans ce cas, la SNA (analyse des réseaux sociaux) est mieux comprise non pas comme une analyse d'un graphe social, mais plutôt comme une analyse d'un réseau social.
- En 2014, la tâche consistait à prédire le nombre de likes que le poste gagnerait.
- En 2016, l'objectif de la VVZ (peut-être vous êtes familier), plus proche de l'analyse du graphe social.
- En 2019 - classement du flux d'un utilisateur selon la probabilité que l'utilisateur aime le message.
Je ne peux pas dire pour 2014, mais en 2016 et 2019, en plus de la capacité d'analyser les données, des compétences pour travailler avec le big data étaient également nécessaires. Je pense que c'est la combinaison de l'apprentissage automatique et des tâches de traitement des mégadonnées qui m'a attiré dans ces concours, et l'expérience dans ces domaines a contribué à gagner.
mlbootcamp
En 2019, le concours était organisé sur la plateforme https://mlbootcamp.ru .
Le concours a commencé en ligne le 7 février et comprenait 3 tâches. Tout le monde pouvait s'inscrire sur le site, télécharger la base de référence et télécharger sa voiture pendant plusieurs heures. À la fin de la scène en ligne le 15 mars, les 15 meilleurs de chaque émission ont été invités au bureau Mail.ru pour la scène hors ligne, qui s'est déroulée du 30 mars au 1er avril.
Défi
Les données source fournissent des identifiants utilisateur (userId) et des post-identifiants (objectId). Si l'utilisateur a vu un message, les données contiennent une ligne contenant userId, objectId, les réactions de l'utilisateur à ce message (rétroaction) et un ensemble de divers signes ou liens vers des images et des textes.
| userId | objectId | ownerId | rétroaction | des images |
|---|
| 3555 | 22 | 5677 | [aimé, cliqué] | [hash1] |
| 12842 | 55 | 32144 | [détesté] | [hash2, hash3] |
| 13145 | 35 | 5677 | [cliqué, partagé] | [hash2] |
L'ensemble de données de test contient une structure similaire, mais le champ de rétroaction est manquant. L'objectif est de prédire la présence d'une réaction «aimée» dans le champ de rétroaction.
Le fichier de soumission a la structure suivante:
| userId | SortedList [objectId] |
|---|
| 123 | 78.13.54.22 |
| 128 | 35.61.55 |
| 131 | 35,68,129,11 |
Métrique - ROC AUC moyen par les utilisateurs.
Une description plus détaillée des données peut être trouvée sur le site de perfection . Vous pouvez également y télécharger des données, y compris des tests et des photos.
Étape en ligne
Au stade en ligne, la tâche était divisée en 3 parties
- Système collaboratif - comprend tous les signes, à l'exception des images et des textes;
- Images - comprend uniquement des informations sur les images;
- Textes - comprend des informations uniquement sur les textes.
Étape hors ligne
À l'étape hors ligne, les données comprenaient tous les attributs, tandis que les textes et les images étaient rares. Il y avait 1,5 fois plus de lignes dans l'ensemble de données, dont il y en avait déjà beaucoup.
Résolution de problèmes
Depuis que je fais du cv au travail, j’ai commencé mon parcours dans ce concours avec la tâche «Images». Les données fournies sont userId, objectId, ownerId (le groupe dans lequel la publication est publiée), les horodatages de création et d'affichage de la publication, et, bien sûr, l'image de cette publication.
Après avoir généré plusieurs fonctionnalités basées sur l'horodatage, l'idée suivante était de prendre l'avant-dernière couche d'un neurone pré-formé par imagenet et d'envoyer ces intégrations pour booster.
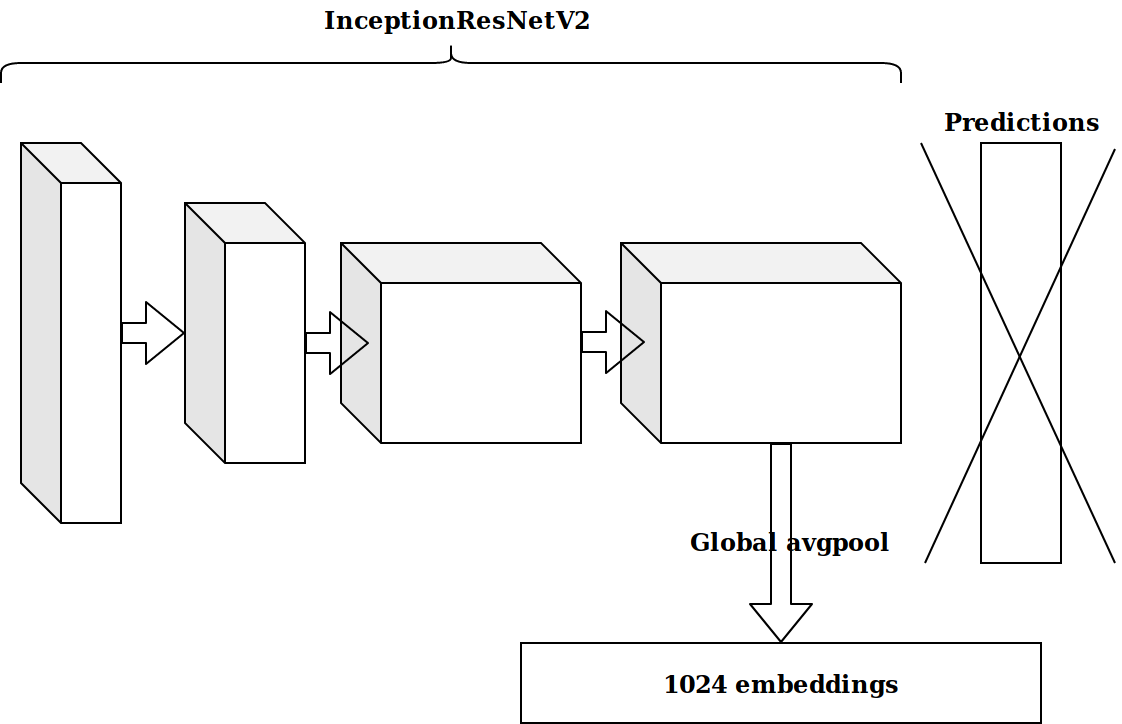
Les résultats n'étaient pas impressionnants. Les intégrations à partir du neurone imagenet ne sont pas pertinentes, je pensais, je dois déposer mon encodeur automatique.
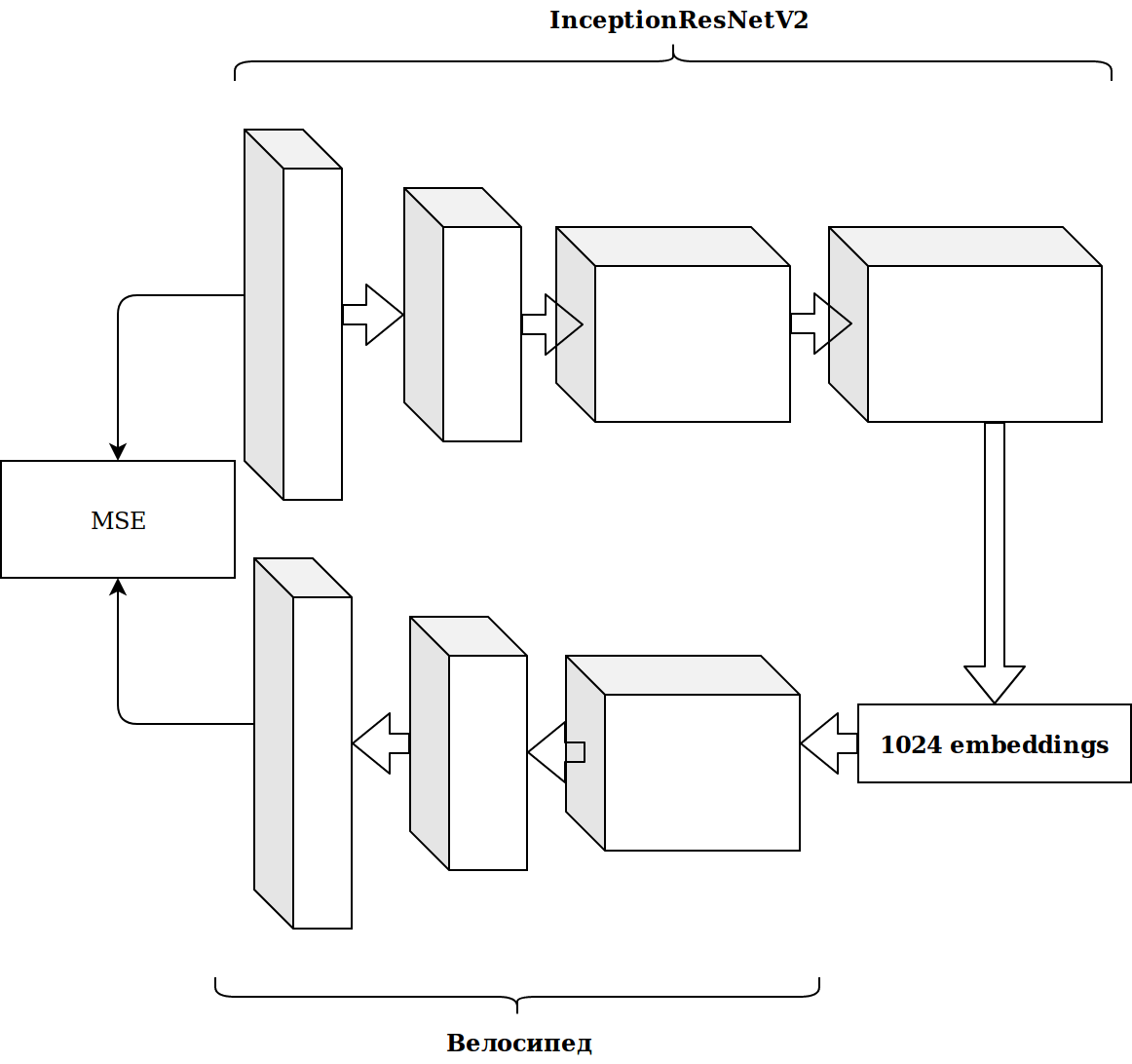
Cela a pris beaucoup de temps et le résultat ne s'est pas amélioré.
Génération de fonctionnalités
Travailler avec des images prend beaucoup de temps et j'ai décidé de faire quelque chose de plus simple.
Comme vous pouvez le voir tout de suite, il y a plusieurs signes catégoriques dans l'ensemble de données, et pour ne pas déranger beaucoup, je viens de prendre catboost. La solution était excellente, sans aucun réglage, j'ai immédiatement atteint la première ligne du classement.
Il y a beaucoup de données et elles sont disposées au format parquet, donc sans y réfléchir à deux fois, j'ai pris scala et j'ai commencé à tout écrire avec étincelle.
Les fonctionnalités les plus simples, qui ont donné plus de croissance que les incorporations d'images:
- combien de fois objectId, userId et ownerId se sont rencontrés dans les données (devraient correspondre à la popularité);
- combien de userId publie le ownerId vu (devrait être en corrélation avec l'intérêt de l'utilisateur pour le groupe);
- le nombre de messages uniques regardés par userId par ownerId (reflète la taille de l'audience du groupe).
À partir des horodatages, il était possible d'obtenir l'heure à laquelle l'utilisateur regardait la bande (matin / jour / soir / nuit). En combinant ces catégories, vous pouvez continuer à générer des fonctionnalités:
- combien de fois userId s'est connecté en soirée;
- à quelle heure ce message est-il souvent affiché (objectId) et ainsi de suite.
Tout cela a progressivement amélioré la métrique. Mais la taille de l'ensemble de données de formation est d'environ 20 millions d'enregistrements, donc l'ajout de fonctionnalités a considérablement ralenti l'apprentissage.
J'ai redéfini l'approche d'utilisation des données. Bien que les données dépendent du temps, je n'ai pas vu de fuites d'informations explicites à l'avenir, néanmoins, juste au cas où, je les ai cassées comme ceci:
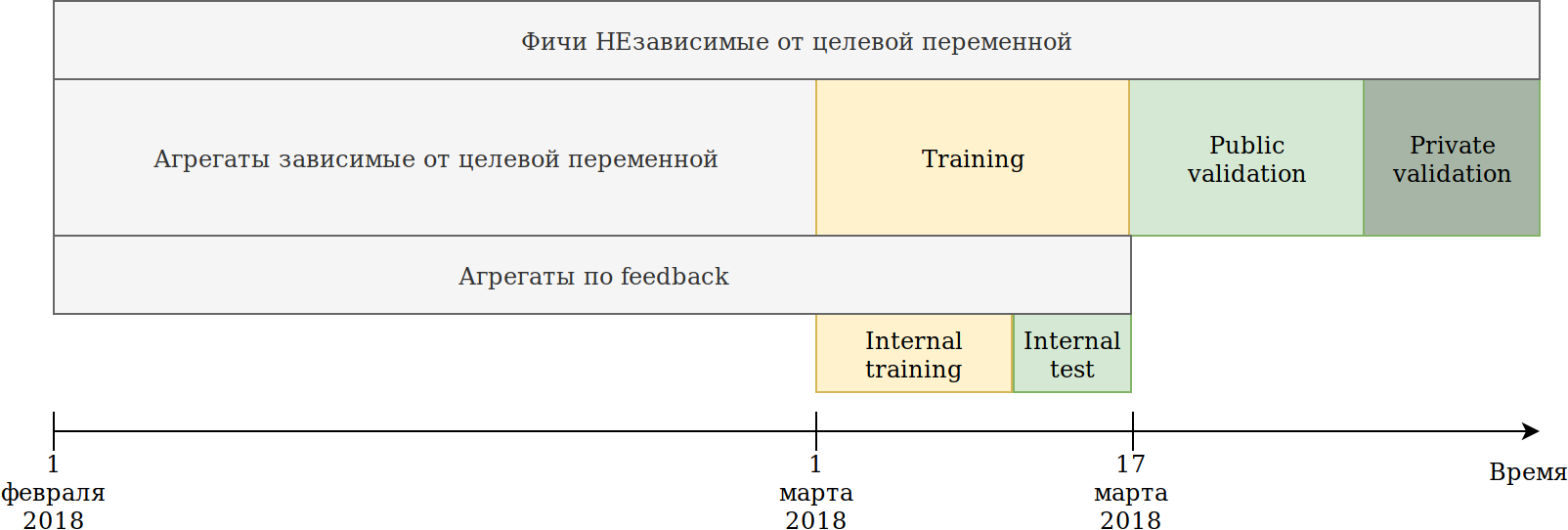
L'ensemble de formation qui nous a été fourni (février et 2 semaines de mars) était divisé en 2 parties.
Sur les données des N derniers jours, il a formé le modèle. Les agrégations décrites ci-dessus ont été construites sur toutes les données, y compris le test. Dans le même temps, des données sont apparues sur lesquelles différents encodeurs de la variable cible peuvent être construits. L'approche la plus simple consiste à réutiliser le code qui crée déjà de nouvelles fonctionnalités et à lui fournir simplement des données qui ne seront pas entraînées et cibleront = 1.
Ainsi, nous avons obtenu des fonctionnalités similaires:
- Combien de fois userId a vu un message dans le groupe ownerId;
- Le nombre de fois où userId a aimé le message sur ownerId;
- Pourcentage de publications que userId aimait ownerId.
Autrement dit, il s'est avéré un encodage cible moyen de la part de l'ensemble de données selon diverses combinaisons de caractéristiques catégorielles. En principe, catboost construit également l'encodage cible, et de ce point de vue, il n'y a aucun avantage, mais, par exemple, il est devenu possible de compter le nombre d'utilisateurs uniques qui aiment les publications dans ce groupe. Dans le même temps, l'objectif principal a été atteint - mon ensemble de données a diminué plusieurs fois et il a été possible de continuer à générer des entités.
Alors que catboost ne peut construire des encodeurs qu'en fonction de la réaction souhaitée, le feedback a d'autres réactions: partagé, détesté, non aimé, cliqué, ignoré, ce qui peut être fait manuellement. J'ai raconté toutes sortes d'agrégats et filtré les entités de faible importance, afin de ne pas gonfler l'ensemble de données.
À ce moment-là, j'étais à la première place par une large marge. Le seul embarras était que l'intégration des images ne donnait presque pas de gain. L'idée est venue de tout donner à catboost. Cluster Kmeans images et obtenir une nouvelle fonctionnalité catégorielle imageCat.
Voici quelques classes après avoir filtré et fusionné manuellement les clusters obtenus à partir de KMeans.

Sur la base d’imageCat, nous générons:
- Nouvelles fonctionnalités catégoriques:
- Quelle imageCat ressemblait le plus souvent à userId;
- Quelle imageCat est le plus souvent affichée par ownerId;
- Quelle imageCat a le plus aimé userId;
- Divers compteurs:
- Combien d'imagesCat uniques paraissaient userId;
- Environ 15 fonctionnalités similaires plus un encodage cible comme décrit ci-dessus.
Textes
Les résultats du concours d'image me convenaient et j'ai décidé de m'essayer dans les textes. Auparavant, je ne travaillais pas beaucoup avec les textes et, par stupidité, j'ai tué un jour sur tf-idf et svd. Ensuite, j'ai vu une base de référence avec doc2vec, qui fait exactement ce dont j'ai besoin. Après avoir légèrement ajusté les paramètres de doc2vec, j'ai reçu des intégrations de texte.
Et puis il a simplement réutilisé le code pour les images, dans lequel il a remplacé les incorporations d'images par des incorporations de texte. En conséquence, je suis arrivé à la 2e place dans le concours de texte.
Système collaboratif
Il n'y avait qu'une seule compétition dans laquelle je n'avais pas encore «enfoncé un bâton», mais à en juger par l'AUC dans le classement, les résultats de cette compétition particulière auraient dû avoir le plus grand impact sur la scène hors ligne.
J'ai pris tous les signes qui se trouvaient dans les données source, j'ai sélectionné les signes catégoriques et calculé les mêmes agrégats que pour les images, à l'exception des caractéristiques des images elles-mêmes. Juste en le mettant dans catboost, je suis arrivé à la 2e place.
Les premières étapes pour optimiser catboost
Une première et deux deuxièmes places m'ont plu, mais il était entendu que je n'avais rien fait de spécial, ce qui signifie que nous pouvons nous attendre à une perte de position.
La tâche du concours est de classer les postes dans le cadre de l'utilisateur, et pendant tout ce temps, j'ai résolu le problème de classification, c'est-à-dire que j'ai optimisé la mauvaise métrique.
Je vais donner un exemple simple:
| userId | objectId | prédiction | vérité fondamentale |
|---|
| 1 | 10 | 0,9 | 1 |
| 1 | 11 | 0,8 | 1 |
| 1 | 12 | 0,7 | 1 |
| 1 | 13 | 0,6 | 1 |
| 1 | 14 | 0,5 | 0 |
| 2 | 15 | 0,4 | 0 |
| 2 | 16 | 0,3 | 1 |
On fait une petite permutation
| userId | objectId | prédiction | vérité fondamentale |
|---|
| 1 | 10 | 0,9 | 1 |
| 1 | 11 | 0,8 | 1 |
| 1 | 12 | 0,7 | 1 |
| 1 | 13 | 0,6 | 0 |
| 2 | 16 | 0,5 | 1 |
| 2 | 15 | 0,4 | 0 |
| 1 | 14 | 0,3 | 1 |
Nous obtenons les résultats suivants:
| Modèle | Auc | Utilisateur1 AUC | User2 AUC | ASC moyenne |
|---|
| Option 1 | 0,8 | 1,0 | 0,0 | 0,5 |
| Option 2 | 0,7 | 0,75 | 1,0 | 0,875 |
Comme vous pouvez le voir, l'amélioration de la métrique AUC globale ne signifie pas l'amélioration de la métrique AUC moyenne au sein de l'utilisateur.
Catboost peut optimiser les mesures de classement hors de la boîte. J'ai lu sur le classement des métriques, des histoires de réussite lors de l'utilisation de catboost et réglé YetiRankPairwise pour étudier la nuit. Le résultat n'était pas impressionnant. Ayant décidé que je n'avais pas bien appris, j'ai changé la fonction d'erreur en QueryRMSE, qui, à en juger par la documentation de catboost, converge plus rapidement. En conséquence, j'ai obtenu les mêmes résultats que lors de la formation au classement, mais les ensembles de ces deux modèles ont donné une bonne augmentation, ce qui m'a amené à la première place dans les trois compétitions.
5 minutes avant la fermeture de la scène en ligne du concours Collaborative Systems, Sergey Shalnov m'a propulsé à la deuxième place. La façon dont nous sommes allés ensemble.
Préparation pour la phase hors ligne
La victoire sur la scène en ligne nous a été garantie sur la carte vidéo RTX 2080 TI, mais le prix principal de 300 000 roubles et, même, même la première place finale nous ont obligés à travailler ces 2 semaines.
Il s'est avéré que Sergey a également utilisé catboost. Nous avons échangé des idées et des fonctionnalités, et j'ai découvert le rapport d'Anna Veronika Dorogush dans lequel il y avait des réponses à bon nombre de mes questions, et même à celles auxquelles je n'avais pas encore comparu.
La visualisation du rapport m'a conduit à l'idée qu'il est nécessaire de ramener tous les paramètres à la valeur par défaut, et de régler les paramètres très soigneusement et seulement après avoir fixé un ensemble de signes. Maintenant, une formation a pris environ 15 heures, mais un modèle a réussi à obtenir une meilleure vitesse que dans l'ensemble avec classement.
Génération de fonctionnalités
Dans le cadre du concours "Systèmes collaboratifs", un grand nombre de fonctionnalités sont jugées importantes pour le modèle. Par exemple, auditweights_spark_svd est l'attribut le plus important, et il n'y a aucune information sur ce que cela signifie. J'ai pensé qu'il valait la peine de compter les différentes unités en fonction de signes importants. Par exemple, la moyenne d'auditweights_spark_svd par utilisateur, par groupe, par objet. La même chose peut être calculée à partir des données sur lesquelles la formation n'est pas effectuée et de la cible = 1, c'est-à-dire, la moyenne des auditweights_spark_svd par utilisateur pour les objets qu'il a aimés. Il y avait plusieurs signes importants, outre auditweights_spark_svd . En voici quelques uns:
- auditweightsCtrGender
- auditweightsCtrHigh
- userOwnerCounterCreateLikes
Par exemple, la valeur moyenne de auditweightsCtrGender par userId s'est avérée être une fonctionnalité importante, ainsi que la valeur moyenne de userOwnerCounterCreateLikes par userId + ownerId. Cela aurait dû nous faire réfléchir sur la façon de comprendre la signification des champs.
Les autres fonctionnalités importantes étaient auditweightsLikesCount et auditweightsShowsCount . En les divisant les uns les autres, une caractéristique encore plus importante a été obtenue.
Fuites de données
Les modèles de concurrence et de production sont des tâches très différentes. Lors de la préparation des données, il est très difficile de prendre en compte tous les détails et de ne pas transférer certaines informations non triviales sur la variable cible sur le test. Si nous créons une solution de production, nous essaierons d'éviter l'utilisation de fuites de données lors de la formation du modèle. Mais si nous voulons gagner le concours, les fuites de données sont les meilleures fonctionnalités.
Après avoir examiné les données, vous pouvez voir que, selon objectId, les valeurs de auditweightsLikesCount et auditweightsShowsCount changent, ce qui signifie que le ratio des valeurs maximales de ces signes reflètera la conversion postérieure bien mieux que le ratio au moment de la livraison.
La première fuite que nous avons découverte a été auditweightsLikesCountMax / auditweightsShowsCountMax .
Mais que se passe-t-il si vous examinez les données de plus près? Triez par date de livraison et obtenez:
| objectId | userId | auditweightsShowsCount | auditweightsLikesCount | cible (est aimé) |
|---|
| 1 | 1 | 12 | 3 | probablement pas |
| 1 | 2 | 15 | 3 | probablement oui |
| 1 | 3 | 16 | 4 | |
C'était surprenant quand j'ai trouvé le premier exemple et il s'est avéré que ma prédiction ne s'est pas réalisée. Mais, étant donné que les valeurs maximales de ces signes dans le cadre de l'objet ont augmenté, nous n'avons pas été trop paresseux et avons décidé de trouver auditweightsShowsCountNext et auditweightsLikesCountNext , c'est-à-dire des valeurs au prochain instant. Ajout d'une fonctionnalité
(auditweightsShowsCountNext-auditweightsShowsCount) / (auditweightsLikesCount-auditweightsLikesCountNext) nous avons fait un bond en avant 24h / 24.
Des fuites similaires pourraient être utilisées si les valeurs suivantes étaient trouvées pour userOwnerCounterCreateLikes dans userId + ownerId et, par exemple, auditweightsCtrGender dans objectId + userGender. Nous avons trouvé 6 champs similaires avec des fuites et tiré des informations d'eux autant que possible.
À ce moment-là, nous avions extrait un maximum d'informations des attributs collaboratifs, mais nous ne sommes pas revenus aux concours d'images et de textes. Il y avait une bonne idée à vérifier: combien les fonctionnalités donnent-elles directement sur les images ou les textes dans les compétitions correspondantes?
Il n'y avait aucune fuite dans les concours d'images et de textes, mais à ce moment-là, j'avais retourné les paramètres par défaut de catboost, peigné le code et ajouté quelques fonctionnalités. Résultat total:
| Solution | vitesse |
|---|
| Maximum avec images | 0,6411 |
| Maximum aucune image | 0,6297 |
| Résultat de la deuxième place | 0,6295 |
| Solution | vitesse |
|---|
| Maximum avec textes | 0,666 |
| Maximum sans texte | 0,660 |
| Résultat de la deuxième place | 0,656 |
| Solution | vitesse |
|---|
| Maximum en collaboration | 0,745 |
| Résultat de la deuxième place | 0,723 |
Il est devenu évident que beaucoup de textes et d'images étaient peu susceptibles d'être évincés, et après avoir essayé quelques-unes des idées les plus intéressantes, nous avons cessé de travailler avec eux.
La nouvelle génération de fonctionnalités dans les systèmes collaboratifs n'a pas donné de croissance, et nous avons commencé le classement. À l'étape en ligne, l'ensemble de la classification et du classement m'a donné une petite augmentation, car il s'est avéré que j'avais une classification insuffisamment formée. Aucune des fonctions d'erreur, y compris YetiRanlPairwise, n'a même donné de résultats proches que LogLoss a donné (0,745 contre 0,725). Il y avait de l'espoir pour un QueryCrossEntropy qui ne pourrait pas être lancé.
Étape hors ligne
À l'étape hors ligne, la structure des données est restée la même, mais il y a eu de petits changements:
- les identifiants userId, objectId, ownerId ont été re-randomisés;
- plusieurs panneaux ont été supprimés et plusieurs ont été renommés;
- les données sont devenues environ 1,5 fois plus.
En plus des difficultés listées, il y avait un gros plus: un gros serveur avec RTX 2080TI a été alloué à l'équipe. J'ai apprécié le htop pendant longtemps.
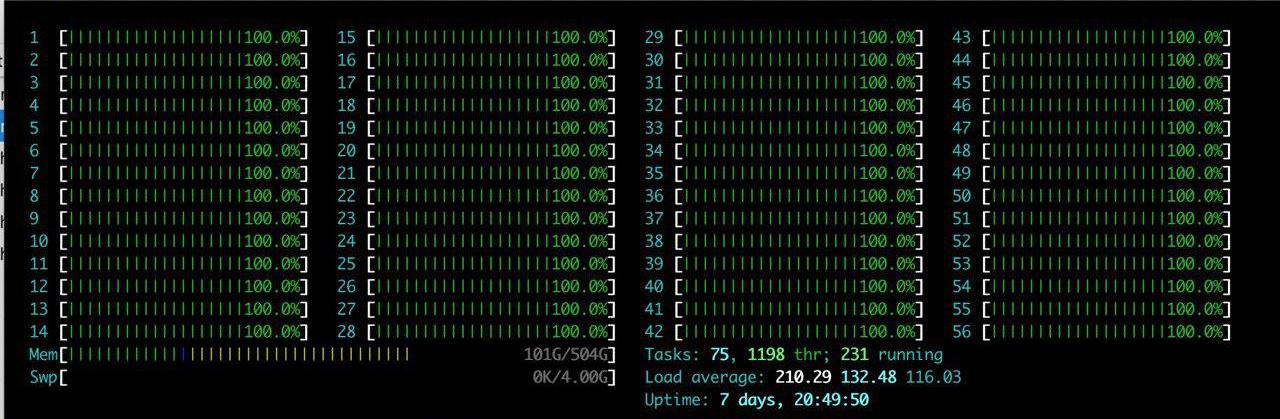
L'idée en était une - juste pour reproduire ce qui existe déjà. Après avoir passé quelques heures à configurer l'environnement sur le serveur, nous avons progressivement commencé à vérifier que les résultats étaient reproduits. Le principal problème auquel nous sommes confrontés est l'augmentation du volume de données. Nous avons décidé de réduire légèrement la charge et de définir le paramètre catboost ctr_complexity = 1. Cela réduit un peu la vitesse, mais mon modèle a commencé à fonctionner, le résultat était bon - 0,733. Sergei, contrairement à moi, n'a pas divisé les données en 2 parties et s'est entraîné sur toutes les données, bien que cela ait donné le meilleur résultat au stade en ligne, il y avait beaucoup de difficultés au stade hors ligne. Si nous prenons toutes les fonctionnalités que nous avons générées et essayons de les mettre en catboost «sur le front», alors rien ne se serait produit au stade en ligne. Sergey a fait l'optimisation de type, par exemple, en convertissant les types float64 en float32. Dans cet article, vous pouvez trouver des informations sur l'optimisation de la mémoire chez les pandas. En conséquence, Sergey s'est entraîné sur le CPU sur toutes les données et il s'est avéré environ 0,735.
Ces résultats ont été suffisants pour gagner, mais nous avons caché notre vitesse réelle et nous ne pouvions pas être sûrs que les autres équipes ne faisaient pas de même.
Bataille jusqu'au dernier
Tuning catboost
Notre solution a été entièrement reproduite, nous avons ajouté des fonctionnalités de données de texte et d'images, il ne restait plus qu'à régler les paramètres de catboost. Sergey a étudié sur le CPU avec un petit nombre d'itérations, et j'ai étudié avec ctr_complexity = 1. Il ne restait qu'un jour, et si vous ajoutez simplement des itérations ou augmentez la ctr_complexity, alors le matin, vous pourriez obtenir une vitesse encore meilleure et marcher toute la journée.
Au stade hors ligne, les scores peuvent être très faciles à masquer, simplement en ne choisissant pas la meilleure solution sur le site. Nous nous attendions à de brusques changements dans le classement dans les dernières minutes avant la clôture des soumissions et avons décidé de ne pas arrêter.
De la vidéo d'Anna, j'ai appris que pour améliorer la qualité du modèle, il est préférable de sélectionner les paramètres suivants:
- learning_rate - La valeur par défaut est calculée en fonction de la taille de l'ensemble de données. Avec une diminution de learning_rate, pour maintenir la qualité, il est nécessaire d'augmenter le nombre d'itérations.
- l2_leaf_reg - Coefficient de régularisation, valeur par défaut de 3, de préférence de 2 à 30. Une diminution de la valeur entraîne une augmentation de l'overfit.
- bagging_temperature - Ajoute la randomisation aux poids des objets dans la sélection. La valeur par défaut est 1, à laquelle les poids sont sélectionnés dans la distribution exponentielle. Une baisse de valeur entraîne une augmentation de la sur-tenue.
- random_strength - Affecte le choix des divisions pour une itération particulière. Plus la valeur random_strength est élevée, plus les chances qu'une division de faible importance soit sélectionnée sont élevées. À chaque itération suivante, le caractère aléatoire diminue. Une baisse de valeur entraîne une augmentation de la sur-tenue.
D'autres paramètres affectent beaucoup moins le résultat final, donc je n'ai pas essayé de les sélectionner. Une itération de la formation sur mon jeu de données GPU avec ctr_complexity = 1 a pris 20 minutes, et les paramètres sélectionnés sur le jeu de données réduit étaient légèrement différents de ceux optimaux sur le jeu de données complet. Par conséquent, j'ai effectué environ 30 itérations sur 10% des données, puis environ 10 itérations supplémentaires sur toutes les données. Il s'est avéré approximativement ce qui suit:
- J'ai augmenté learning_rate de 40% par rapport à la valeur par défaut;
- l2_leaf_reg a laissé la même chose;
- bagging_temperature et random_strength réduits à 0,8.
Nous pouvons conclure qu'avec des paramètres par défaut, le modèle est sous-formé.
J'ai été très surpris en voyant le résultat au classement:
| Modèle | modèle 1 | modèle 2 | modèle 3 | ensemble |
|---|
| Pas de réglage | 0,7403 | 0,7404 | 0,7404 | 0,7407 |
| Avec réglage | 0,7406 | 0,7405 | 0,7406 | 0,7408 |
J'ai conclu pour moi-même que si vous n'avez pas besoin d'une application rapide du modèle, alors il vaut mieux remplacer la sélection des paramètres par un ensemble de plusieurs modèles sur des paramètres non optimisés.
Sergey était engagé dans l'optimisation de la taille de l'ensemble de données pour l'exécuter sur le GPU. — , :
- ( ), ;
- ;
- userId, ;
- userId, .
— .
, 0,742. ctr_complexity=2 30 5 . 4 , , 0,7433.
, , . predict(prediction_type='RawFormulaVal') scale_pos_weight=neg_count/pos_count.
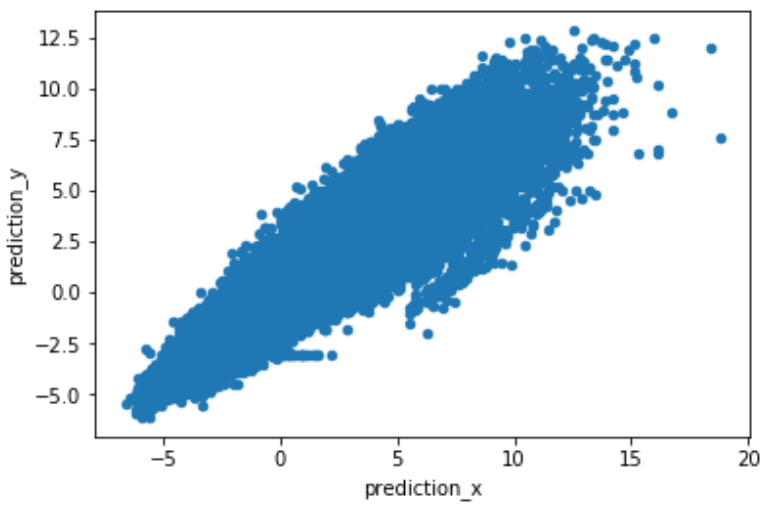
.
. , , , 2 .
Conclusion
:
- , target encoding, catboost.
- , , learning_rate iterations. — .
- GPU. Catboost GPU, .
- rsm~=0.2 (CPU only) ctr_complexity=1.
- , . . , , .
- , .
- , .

, .