Dans cet article, je voudrais parler des fonctionnalités de toutes les baies Flash AccelStor fonctionnant avec l'une des plates-formes de virtualisation les plus populaires - VMware vSphere. En particulier, se concentrer sur les paramètres qui aideront à obtenir le maximum d'effet en utilisant un outil aussi puissant que All Flash.

Toutes les baies Flash AccelStor NeoSapphire ™ sont des périphériques à un ou deux nœuds basés sur des SSD avec une approche fondamentalement différente pour implémenter le concept de stockage des données et organiser l'accès à celles-ci en utilisant sa propre technologie FlexiRemap® au lieu des algorithmes RAID très populaires. Les baies fournissent un accès en bloc aux hôtes via des interfaces Fibre Channel ou iSCSI. Pour être honnête, nous notons que les modèles avec l'interface ISCSI ont également un accès aux fichiers en tant que bon bonus. Mais dans cet article, nous nous concentrerons sur l'utilisation des protocoles de bloc comme les plus productifs pour All Flash.
L'ensemble du processus de déploiement puis de configuration de la collaboration entre la baie AccelStor et le système de virtualisation VMware vSphere peut être divisé en plusieurs étapes:
- Implémentation de la topologie de connexion et configuration du réseau SAN;
- Configuration de la matrice All Flash;
- Configurer les hôtes ESXi;
- Configurez les machines virtuelles.
Les matrices AccelStor NeoSapphire ™ avec Fibre Channel et iSCSI ont été utilisées comme exemples d'équipements. Le logiciel de base est VMware vSphere 6.7U1.
Avant de déployer les systèmes décrits dans cet article, il est fortement recommandé de vous familiariser avec la documentation de VMware concernant les problèmes de performances ( Meilleures pratiques de performance pour VMware vSphere 6.7 ) et les paramètres iSCSI ( Meilleures pratiques pour exécuter VMware vSphere sur iSCSI )
Topologie de connexion et configuration SAN
Les principaux composants d'un réseau SAN sont les HBA sur les hôtes ESXi, les commutateurs SAN et les nœuds de baie. Une topologie typique d'un tel réseau ressemblerait à ceci:
Le terme Switch désigne ici soit un seul commutateur physique ou un ensemble de commutateurs (Fabric), soit un périphérique partagé entre différents services (VSAN dans le cas de Fibre Channel et VLAN dans le cas d'iSCSI). L'utilisation de deux commutateurs / Fabric indépendants élimine un éventuel point de défaillance.
La connexion directe des hôtes à la baie, bien que prise en charge, est fortement déconseillée. Les performances de toutes les baies Flash sont assez élevées. Et pour une vitesse maximale, vous devez utiliser tous les ports de la baie. Par conséquent, au moins un commutateur entre les hôtes et NeoSapphire ™ est requis.
La présence de deux ports sur l'hôte HBA est également une condition préalable pour des performances maximales et une tolérance aux pannes.
Si vous utilisez l'interface Fibre Channel, vous devez configurer le zonage pour éviter d'éventuels conflits entre les initiateurs et les cibles. Les zones sont construites sur le principe de «un port initiateur - un ou plusieurs ports de baie».
Si vous utilisez une connexion iSCSI si vous utilisez un commutateur partagé avec d'autres services, vous devez isoler le trafic iSCSI à l'intérieur d'un VLAN distinct. Il est également fortement recommandé d'activer la prise en charge des trames Jumbo (MTU = 9000) pour augmenter la taille des paquets sur le réseau et, par conséquent, réduire la quantité de surcharge pendant la transmission. Cependant, il convient de rappeler que pour un fonctionnement correct, il est nécessaire de modifier le paramètre MTU sur tous les composants du réseau le long de la chaîne initiateur-commutateur-cible.
Configuration de tous les tableaux Flash
La baie est livrée aux clients avec des groupes FlexiRemap® déjà constitués. Par conséquent, aucune action n'est nécessaire pour intégrer les disques dans une structure unique. Il suffit de créer des volumes de la taille et de la quantité requises.
Pour plus de commodité, il existe une fonctionnalité pour la création par lots de plusieurs volumes d'un volume donné à la fois. Les volumes «minces» sont créés par défaut, car cela permet une utilisation plus rationnelle de l'espace de stockage disponible (y compris grâce au support de Space Reclamation). En termes de performances, la différence entre volumes fins et épais ne dépasse pas 1%. Cependant, si vous voulez "extraire tous les jus" de la matrice, vous pouvez toujours convertir n'importe quel volume "fin" en "épais". Mais il ne faut pas oublier qu'une telle opération est irréversible.
Il ne reste plus qu'à «publier» les volumes créés et à définir les droits d'accès à ceux-ci à partir des hôtes à l'aide de l'ACL (adresses IP pour iSCSI et WWPN pour FC) et la séparation physique des ports sur la baie. Pour les modèles iSCSI, cela se fait par la création de Target.
Pour les modèles FC, la publication s'effectue via la création d'un LUN pour chaque port de la baie.
Pour accélérer le processus de configuration, les hôtes peuvent être regroupés. De plus, si l'hôte utilise le HBA FC à ports multiples (ce qui arrive le plus souvent en pratique), le système détermine automatiquement que les ports de ce HBA appartiennent au même hôte en raison du WWPN, qui diffèrent d'un. De plus, la création par lots de Target / LUN est prise en charge pour les deux interfaces.
Un point important lors de l'utilisation de l'interface iSCSI est de créer plusieurs cibles pour les volumes à la fois pour augmenter les performances, car la file d'attente cible ne peut pas être modifiée, et ce sera en fait un goulot d'étranglement.
Configurer les hôtes ESXi
Côté ESXi, la configuration de base se fait selon le scénario tout à fait attendu. Procédure de connexion iSCSI:
- Ajouter un adaptateur iSCSI logiciel (non requis s'il a déjà été ajouté ou si vous utilisez l'adaptateur matériel iSCSI);
- Créer vSwitch, par lequel le trafic iSCSI passera, et y ajouter une liaison montante physique et VMkernal;
- Ajout d'adresses de tableau à Dynamic Discovery;
- Création d'une banque de données
Quelques notes importantes:
- Dans le cas général, bien sûr, vous pouvez utiliser le vSwitch existant, mais dans le cas d'un vSwitch séparé, la gestion des paramètres de l'hôte sera beaucoup plus simple.
- Il est nécessaire de séparer le trafic de gestion et iSCSI en liaisons physiques et / ou VLAN séparés afin d'éviter des problèmes de performances.
- Les adresses IP de VMkernal et les ports correspondants de la baie All Flash doivent se trouver sur le même sous-réseau, toujours en raison de problèmes de performances.
- Pour garantir la tolérance aux pannes de VMware, vSwitch doit avoir au moins deux liaisons montantes physiques
- Si vous utilisez des trames Jumbo, vous devez changer le MTU de vSwitch et VMkernal
- Il ne sera pas inutile de rappeler que selon les recommandations VMware pour les adaptateurs physiques qui seront utilisés pour travailler avec le trafic iSCSI, il est nécessaire de configurer Teaming et Failover. En particulier, chaque VMkernal ne devrait fonctionner que via une seule liaison montante, la deuxième liaison montante doit être commutée en mode inutilisé. Pour la tolérance aux pannes, vous devez ajouter deux VMkernal, dont chacun fonctionnera via sa liaison montante.
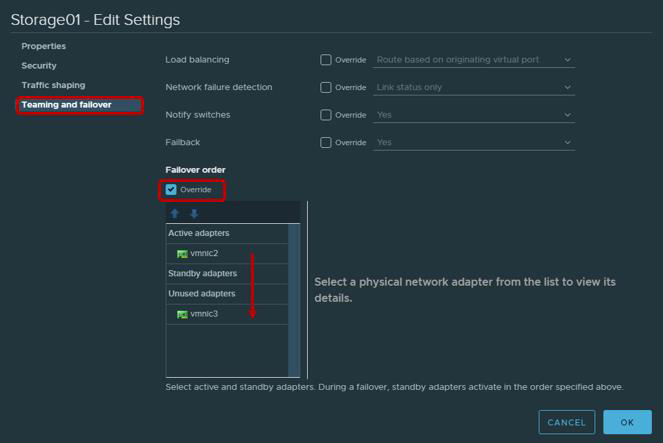
| Adaptateur VMkernel (vmk #) | Carte réseau physique (vmnic #) |
|---|
| vmk1 (Storage01) | Adaptateurs actifs
vmnic2
Adaptateurs inutilisés
vmnic3
|
| vmk2 (Storage02) | Adaptateurs actifs
vmnic3
Adaptateurs inutilisés
vmnic2
|
Aucune connexion Fibre Channel requise. Vous pouvez immédiatement créer un magasin de données.
Après avoir créé le magasin de données, vous devez vous assurer que la stratégie Round Robin est utilisée pour les chemins vers Target / LUN comme les plus productifs.
Par défaut, les paramètres VMware prévoient l'utilisation de cette stratégie selon le schéma: 1000 requêtes via le premier chemin, 1000 requêtes suivantes via le deuxième chemin, etc. Cette interaction de l'hôte avec une baie à deux contrôleurs sera déséquilibrée. Par conséquent, nous vous recommandons de définir le paramètre Round Robin policy = 1 via Esxcli / PowerCLI.
ParamètresPour Esxcli:
- Imprimer les LUN disponibles
liste des périphériques nmp de stockage esxcli
- Copier le nom du périphérique
- Changer la politique du tournoi à la ronde
esxcli storage nmp psp roundrobin deviceconfig set --type = iops --iops = 1 --device = "Device_ID"
La plupart des applications modernes sont conçues pour échanger de gros paquets de données afin de maximiser l'utilisation de la bande passante et de réduire la charge du processeur. Par conséquent, ESXi transfère par défaut les demandes d'E / S vers le périphérique de stockage par lots jusqu'à 32 767 Ko. Cependant, pour un certain nombre de scénarios, l'échange de petites portions sera plus productif. Pour les baies AccelStor, voici les scénarios suivants:
- La machine virtuelle utilise UEFI au lieu du BIOS hérité
- Utilisé par vSphere Replication
Pour de tels scénarios, il est recommandé de modifier la valeur du paramètre Disk.DiskMaxIOSize à 4096.
Pour les connexions iSCSI, il est recommandé de modifier le paramètre Délai d'expiration de connexion sur 30 (valeur par défaut 5) pour augmenter la stabilité de la connexion et désactiver le délai d'acquittement des paquets DelayedAck transférés. Les deux options sont dans vSphere Client: Hôte → Configurer → Stockage → Adaptateurs de stockage → Options avancées pour l'adaptateur iSCSI
Un point assez subtil est le nombre de volumes utilisés pour la banque de données. Il est clair que pour faciliter la gestion, il existe un désir de créer un grand volume pour tout le volume de la baie. Cependant, la présence de plusieurs volumes et, par conséquent, du magasin de données a un effet bénéfique sur les performances globales (plus sur les files d'attente un peu plus loin dans le texte). Par conséquent, nous vous recommandons de créer au moins deux volumes.
Plus récemment, VMware a conseillé de limiter le nombre de machines virtuelles sur un même magasin de données, afin d'obtenir les meilleures performances possibles. Cependant, maintenant, surtout avec la propagation de la VDI, ce problème n'est plus aussi aigu. Mais cela n'annule pas la règle de longue date - pour distribuer des machines virtuelles qui nécessitent des E / S intensives sur différentes banques de données. Il n'y a rien de mieux pour déterminer le nombre optimal de machines virtuelles par volume que de tester la baie All Flash d'AccelStor au sein de son infrastructure.
Configurer des machines virtuelles
Il n'y a pas d'exigences particulières lors de la configuration des machines virtuelles, ou plutôt, elles sont assez ordinaires:
- Utilisation de la version la plus élevée possible de VM (compatibilité)
- Il est plus précis de définir la taille de la RAM lorsque les machines virtuelles sont densément placées, par exemple, dans VDI (car par défaut, au démarrage, un fichier d'échange est créé qui est comparable à la taille de la RAM, ce qui consomme de la capacité utile et a un effet sur les performances finales)
- Utilisez les versions d'E / S les plus efficaces des adaptateurs: type de réseau VMXNET 3 et type SCSI PVSCSI
- Utilisez le type de lecteur Heavy Provision Eager Zeroed pour des performances maximales et Thin Provisioning pour une utilisation maximale du stockage
- Si possible, limitez le travail des machines d'E / S non critiques à l'aide de Virtual Disk Limit
- Assurez-vous d'installer VMware Tools
Notes de file d'attente
Une file d'attente (ou E / S en attente) est le nombre de demandes d'E / S (commandes SCSI) en attente de traitement à un moment donné à partir d'un périphérique / d'une application particulière. En cas de dépassement de file d'attente, des erreurs QFULL sont générées, ce qui se traduit finalement par une augmentation du paramètre de latence. Lors de l'utilisation de systèmes de stockage sur disque (broche), théoriquement, plus la file d'attente est élevée, plus leurs performances sont élevées. Cependant, vous ne devez pas en abuser, car il est facile de s'exécuter dans QFULL. Dans le cas des systèmes All Flash, d'une part, tout est un peu plus simple: le tableau a des retards inférieurs de plusieurs ordres de grandeur et donc le plus souvent il n'est pas nécessaire d'ajuster séparément la taille des files d'attente. Mais d'un autre côté, dans certains scénarios d'utilisation (un fort biais dans les exigences d'E / S pour des machines virtuelles spécifiques, des tests de performances maximales, etc.), si vous ne modifiez pas les paramètres de file d'attente, alors comprenez au moins quels indicateurs peuvent être atteints, et, surtout, de quelles manières.
L'All Flash Array d'AccelStor lui-même n'a pas de limites sur les volumes ou les ports d'E / S. Si nécessaire, même un seul volume peut obtenir toutes les ressources de la baie. La seule restriction de file d'attente concerne les cibles iSCSI. C'est pour cette raison que la nécessité de créer plusieurs (idéalement jusqu'à 8 pièces) cibles pour chaque volume pour dépasser cette limite a été indiquée ci-dessus. De plus, les baies AccelStor sont des solutions hautement productives. Par conséquent, vous devez utiliser tous les ports d'interface du système pour atteindre la vitesse maximale.
Du côté ESXi de l'hôte, la situation est complètement différente. L'hôte lui-même applique la pratique de l'égalité d'accès aux ressources pour tous les participants. Par conséquent, il existe des files d'attente d'E / S distinctes pour le système d'exploitation invité et le HBA. Les files d'attente vers le système d'exploitation invité sont combinées des files d'attente à l'adaptateur SCSI virtuel et au disque virtuel:
La file d'attente pour HBA dépend du type / fournisseur spécifique:
Les performances finales de la machine virtuelle seront déterminées par la limite de profondeur de file d'attente la plus basse parmi les composants hôtes.
Grâce à ces valeurs, vous pouvez évaluer les indicateurs de performance que l'on peut obtenir dans l'une ou l'autre configuration. Par exemple, nous voulons connaître les performances théoriques d'une machine virtuelle (sans liaison à un bloc) avec une latence de 0,5 ms. Puis son IOPS = (1000 / latence) * E / S exceptionnelles (limite de profondeur de file d'attente)
Des exemplesExemple 1
- Adaptateur HBA FC Emulex
- Une machine virtuelle sur le magasin de données
- Adaptateur SCSI paravirtuel VMware
Ici, la limite de profondeur de file d'attente est déterminée par le Hul Emulex. Par conséquent, IOPS = (1000 / 0,5) * 32 = 64 Ko
Exemple 2
- Adaptateur logiciel VMware iSCSI
- Une machine virtuelle sur le magasin de données
- Adaptateur SCSI paravirtuel VMware
Ici, la limite de profondeur de file d'attente est déjà définie par l'adaptateur paravirtuel SCSI. Par conséquent, IOPS = (1000 / 0,5) * 64 = 128 Ko
Les meilleures baies All AccelStor All Flash (comme le P710 ) sont capables de fournir des performances IOPS de 700K pour l'enregistrement en bloc 4K. Avec une telle taille de bloc, il est évident qu'une seule machine virtuelle n'est pas capable de charger un tel tableau. Pour ce faire, vous aurez besoin de 11 (par exemple 1) ou 6 (par exemple 2) machines virtuelles.
En conséquence, avec la configuration correcte de tous les composants décrits du centre de données virtuel, vous pouvez obtenir des résultats très impressionnants en termes de performances.
4K aléatoire, 70% lecture / 30% écriture
En fait, le monde réel est beaucoup plus difficile à décrire avec une formule simple. Un hôte unique possède toujours de nombreuses machines virtuelles avec différentes configurations et exigences d'E / S. Oui, et le processeur hôte est engagé dans un traitement d'entrée / sortie, dont la puissance n'est pas infinie. Ainsi, afin de libérer tout le potentiel du même modèle, le P710 aura en réalité besoin de trois hôtes. De plus, les applications s'exécutant dans des machines virtuelles effectuent des ajustements. Par conséquent, pour un dimensionnement précis, nous vous suggérons d' utiliser un test dans le cas de modèles de test de toutes les baies Flash AccelStor à l'intérieur de l'infrastructure du client pour les tâches actuelles réelles.