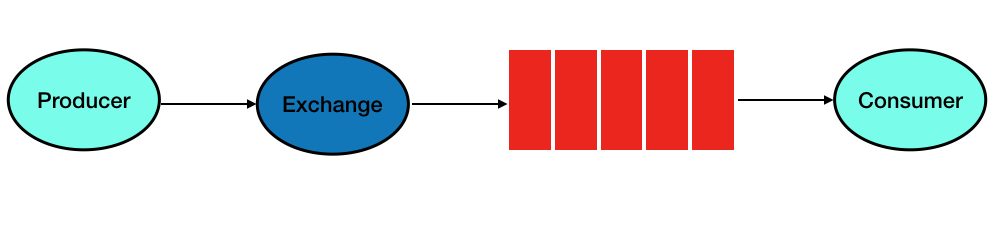
Considérez le schéma de conception de pipeline de messages RabbitMQ classique composé d'éléments Producer, Exchange, Queue et Consumer.
La tâche consiste à organiser la surveillance de ce qui se passe dans la file d'attente et à ne pas affecter le logiciel principal (logiciel), à ajouter la possibilité flexible de créer des rapports et en même temps à éviter des coûts supplémentaires. La conception finale devrait vous permettre de créer rapidement des rapports pour analyser le flux de données sur le pipeline sans utiliser les capacités du serveur principal (ce qui évitera une charge supplémentaire) et le logiciel principal. L'approche devrait être facilement transposable dans une architecture plus complexe.
Tout d'abord, nous organiserons un stand de démonstration, pour cela nous apporterons les modifications suivantes au fonctionnement du convoyeur:
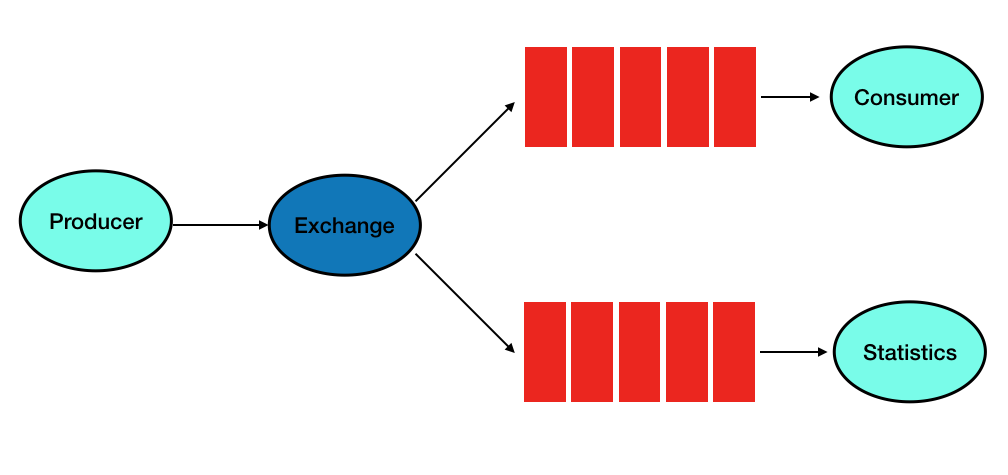
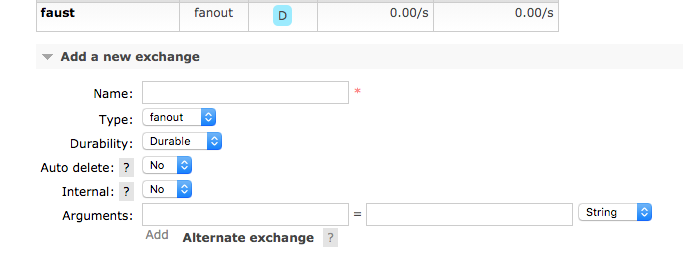
Initialement, la configuration suivante a été définie pour Exchange (faust), qui ne change pas dans l'exemple considéré lors de la modification:
Un paramètre important est le type fanaut - qui vous permet de créer deux files d'attente d'égal à égal et de dupliquer l'intégralité du flux de messages dans la nouvelle file d'attente Statistics:
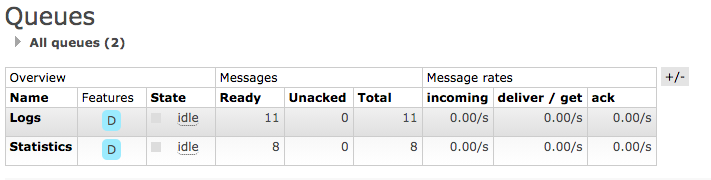
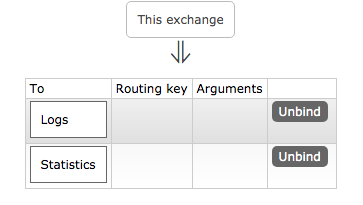
sans aucune interférence avec le processus principal dans la file d'attente des journaux. Commençons à traiter le flux de messages. Tout d'abord, nous créons une table sur le serveur MS SQL pour stocker des informations statistiques. Vous pouvez utiliser n'importe quelle autre approche, par exemple, enregistrer des messages dans un fichier au format xml ou de toute autre manière, dans cet exemple, le serveur SQL est sélectionné afin d'éviter une programmation supplémentaire
create table RabbitMsg( id int PRIMARY KEY IDENTITY(1000,1), [Message] nvarchar(1000) DEFAULT '', RegDate datetime default GETDATE())
Comme vous pouvez le voir dans la requête SQL, il s'agit d'un tableau avec un numéro d'enregistrement, du texte et la date à laquelle l'enregistrement a été inséré dans la table.
Créons un client qui contactera RabbitMQ dans la file d'attente Statistiques, collectera les données reçues et les transférera dans la table RabbitMsg
using System; using RabbitMQ.Client; using RabbitMQ.Client.Events; using System.Text; using System.Data.SqlClient; namespace Getter { class Program { static void Main(string[] args) { var factory = new ConnectionFactory() { HostName = "192.168.1.241", Port = 30672, UserName = "robotics01", Password = "" }; using (var connection = factory.CreateConnection()) using (var channel = connection.CreateModel()) { channel.ExchangeDeclare(exchange: "faust", type: "fanout", durable: true); var queueName = "Statistics"; channel.QueueBind(queue: queueName, exchange: "faust", routingKey: ""); Console.WriteLine(" [*] Waiting for logs."); var consumer = new EventingBasicConsumer(channel); consumer.Received += (model, ea) => { var body = ea.Body; var message = Encoding.UTF8.GetString(body); Console.WriteLine(" [x] {0}", message); SqlConnection sqlconnection = new SqlConnection("Server=tcp:fastreportsql,1433;Initial Catalog=FastReportSQL;Persist Security Info=False;User ID=ufocombat;Password=;MultipleActiveResultSets=False;Encrypt=True;TrustServerCertificate=False;Connection Timeout=30;"); sqlconnection.Open(); SqlCommand cmd = new SqlCommand($"INSERT INTO RabbitMsg(Message) VALUES (@msg)", sqlconnection); cmd.Parameters.AddWithValue("msg", message); cmd.ExecuteNonQuery(); sqlconnection.Close(); }; channel.BasicConsume(queue: queueName, autoAck: false, consumer: consumer); Console.WriteLine(" Press [enter] to exit."); Console.ReadLine(); } Console.WriteLine("Hello World!"); } } }
Voyons comment cela fonctionne en temps réel.
Pendant ce temps, sur MS SQL Server
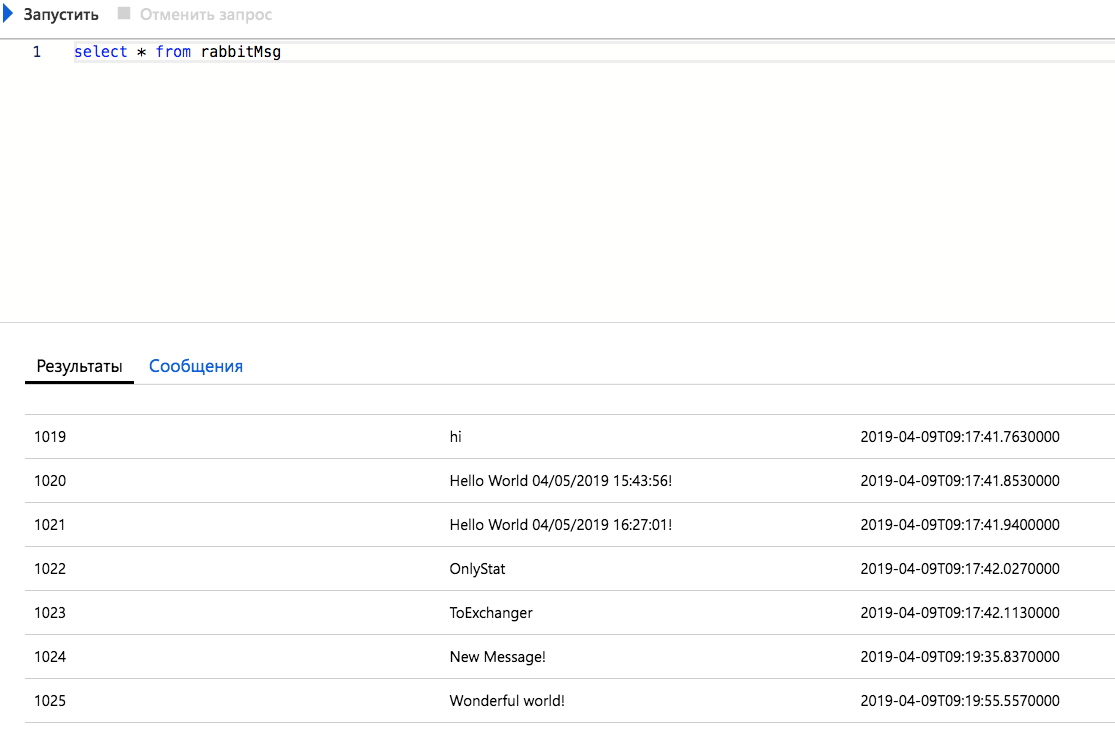
Créer un rapport basé sur la file d'attente Statistiques
Voici ce qui s'est passé:
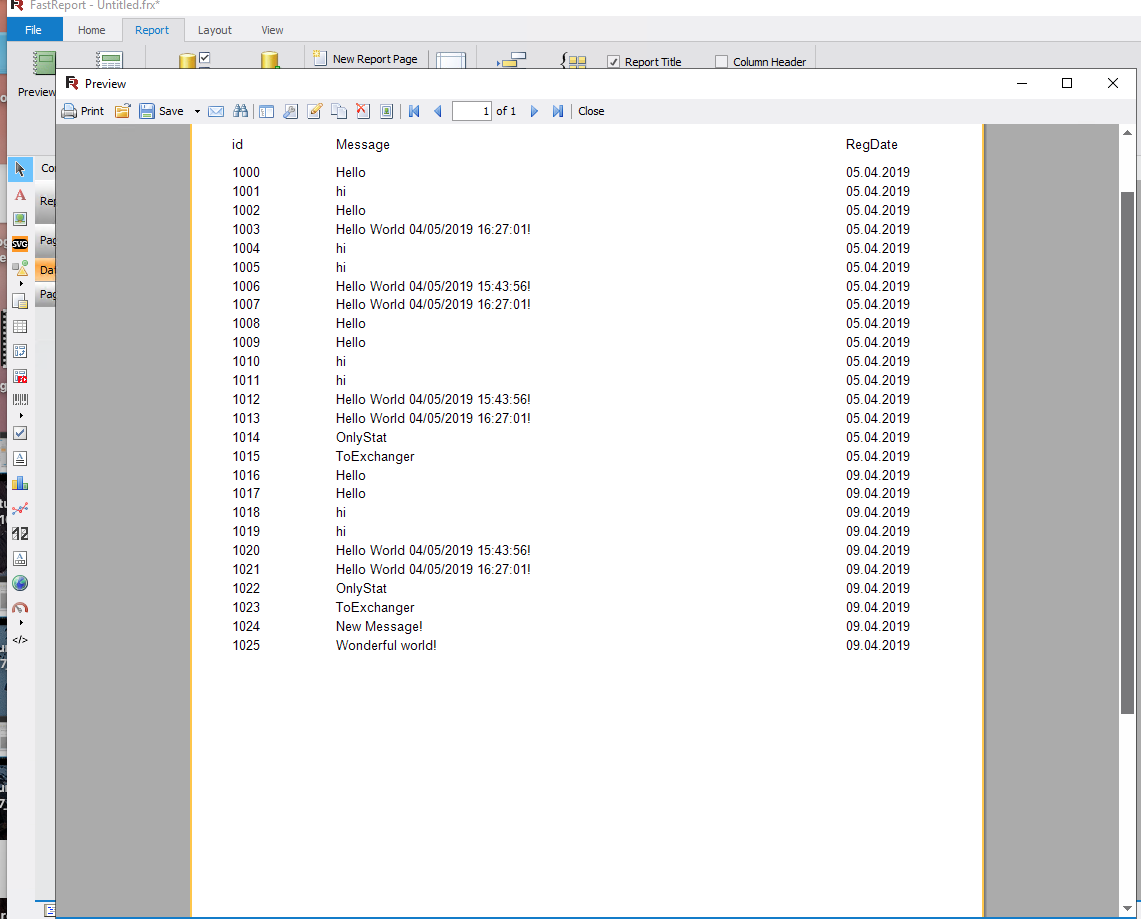
Conclusion
L'exemple considéré montre comment collecter rapidement des statistiques et même créer un rapport qui peut être enregistré au format PDF et envoyé par courrier électronique selon le pipeline RabbitMQ et une file d'attente supplémentaire. Il est facile de trouver des exemples de tâches lorsque des informations sont collectées sur les processus et les rapports sont créés sans développer le côté serveur. Étant donné que FastReports propose une version open source, il est possible de réduire considérablement les coûts de développement sans frais supplémentaires. Le convoyeur lui-même est également facilement reconfigurable et peut être adapté pour des tâches plus complexes.