
Bonjour, Habr! Je continue de publier le cycle sur l'intérieur de la plate-forme de paiement RBK.money, qui a commencé dans ce post . Aujourd'hui, nous allons parler du schéma de traitement logique, des microservices spécifiques et de leur relation les uns avec les autres, comment les services qui traitent chaque élément de la logique métier sont logiquement séparés, pourquoi le noyau de traitement ne sait rien du nombre de vos cartes de paiement et comment les paiements s'exécutent à l'intérieur de la plateforme. Aussi, un peu plus en détail, je vais révéler le sujet de la façon dont nous fournissons une haute disponibilité et une mise à l'échelle pour gérer des charges élevées.
Aperçu de la logique et des approches générales
En général, le schéma des éléments de base de la partie du traitement responsable des paiements ressemble à ceci.
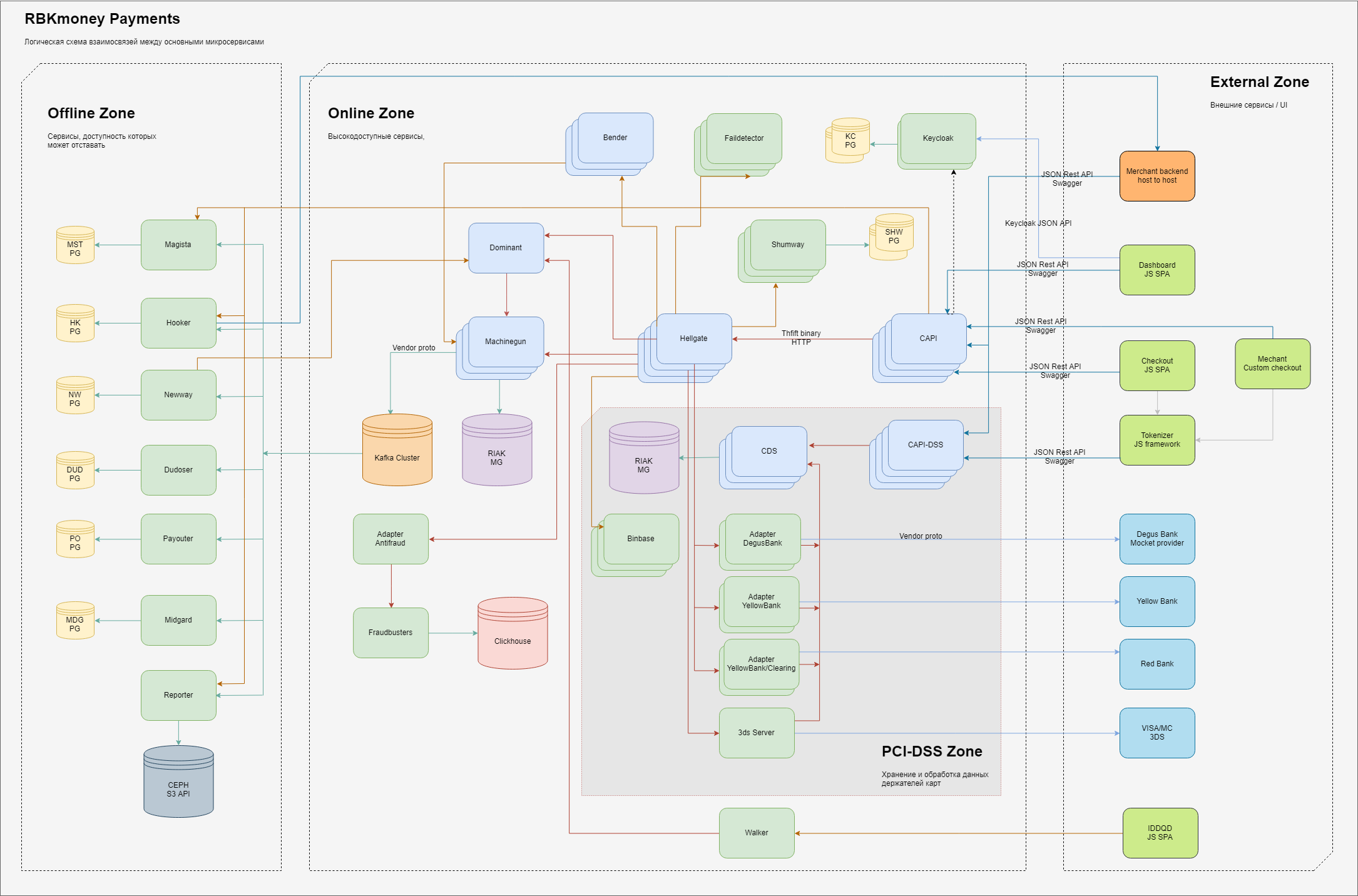
Logiquement en nous-mêmes, nous divisons les domaines de responsabilité en 3 domaines:
- zone externe, les entités qui sont sur Internet, telles que les applications JS de notre formulaire de paiement (vous y entrez les détails de votre carte), les backends de nos clients marchands, ainsi que les passerelles de traitement de nos banques partenaires et fournisseurs d'autres modes de paiement;
- une zone interne hautement accessible, des microservices y vivent, qui fournissent directement le travail de la passerelle de paiement et gèrent le débit de l'argent, en les prenant en compte dans notre système et d'autres services en ligne, qui se caractérisent par l'exigence `` devrait toujours être disponible, malgré les défaillances à l'intérieur de nos DC '';
- il existe un domaine distinct de services qui fonctionne directement avec les données complètes des titulaires de carte; ces services ont des exigences distinctes proposées par le ministère des Chemins de fer et soumises à une certification obligatoire en vertu des normes PCI-DSS. Nous expliquerons plus en détail pourquoi une telle séparation ci-dessous;
- la zone intérieure, où il y a des exigences moindres pour la disponibilité des services fournis ou le temps de leur réponse, au sens classique - c'est un back office. Bien que, bien sûr, nous essayons également ici de garantir le principe du «toujours disponible», nous y consacrons simplement moins d'efforts;
À l'intérieur de chaque zone, il existe des microservices qui exécutent leurs parties de traitement de la logique métier. Ils reçoivent des appels RPC en entrée et en sortie, ils génèrent des données traitées à l'aide d'algorithmes intégrés, qui sont également exécutés en tant qu'appels d'autres microservices le long de la chaîne.
Pour garantir l'évolutivité, nous essayons de stocker les états dans le moins d'endroits possible. Les services sans état dans le diagramme n'ont pas de connexions avec des magasins persistants, avec état, respectivement, qui leur sont connectés. En général, nous utilisons plusieurs services limités pour le stockage d'état persistant - pour la partie principale du traitement, ce sont les clusters Riak KV, pour les services connexes - PostgreSQL, pour le traitement des files d'attente asynchrones, nous utilisons Kafka.
Pour garantir une haute disponibilité, nous déployons des services dans plusieurs instances, généralement de 3 à 5.
Il est facile de faire évoluer les services sans état, nous augmentons simplement le nombre d'instances dont nous avons besoin sur différentes machines virtuelles, ils sont enregistrés dans Consul, ils sont disponibles pour la résolution via le DNS de la console et commencent à recevoir des appels d'autres services, en traitant les données reçues et en les envoyant plus loin.
Les services avec état, ou plutôt c'est notre principal et montré dans le diagramme comme Machinegun, implémentent une interface hautement accessible (l'architecture distribuée est basée sur Erlang Distribution), et la synchronisation via Consul KV est utilisée pour assurer la mise en file d'attente et le verrouillage distribué. Il s'agit d'une brève description détaillée dans un article séparé.
Hors de la boîte, Riak fournit un stockage sans maître persistant hautement accessible, nous ne le préparons en aucune façon, la configuration est presque par défaut. Avec le profil de charge actuel, nous avons 5 nœuds dans le cluster déployés sur des hôtes distincts. Remarque importante - nous n'utilisons pratiquement pas d'index et de grands échantillons de données, nous travaillons avec des clés spécifiques.
Lorsque la mise en œuvre du schéma KV est trop coûteuse, nous utilisons des bases de données PostgeSQL avec réplication, ou même des solutions monomodes, car nous pouvons toujours télécharger les événements nécessaires en cas de défaillance de la partie en ligne via Machinegun.
La séparation des couleurs des microservices dans le diagramme indique les langages dans lesquels ils sont écrits - vert clair - ce sont des applications Java, bleu clair - Erlang.
Tous les services fonctionnent dans des conteneurs Docker, qui sont des artefacts de génération CI et sont situés dans le registre Docker local. Déploie des services sur la production SaltStack, dont la configuration se trouve dans le référentiel Github privé.
Les développeurs effectuent indépendamment des demandes de modifications dans ce référentiel, où ils décrivent les exigences du service - indiquent la version et les paramètres souhaités, tels que la taille de la mémoire allouée au conteneur, transférée aux variables d'environnement et autres. De plus, après confirmation manuelle de la demande de changement par les employés autorisés (nous avons DevOps, support et sécurité de l'information), le CD déploie automatiquement les instances de conteneur avec les nouvelles versions vers les hôtes de l'environnement du produit.
De plus, chaque service écrit des journaux dans un format compréhensible par Elasticsearch. Les fichiers journaux sont récupérés par Filebeat, qui les écrit dans le cluster Elasticsearch. Ainsi, malgré le fait que les développeurs n'aient pas accès à l'environnement du produit, ils ont toujours la possibilité de déboguer et de voir ce qui arrive à leurs services.
Interaction avec le monde extérieur

Tout changement dans l'état de la plateforme avec nous se produit exclusivement par le biais d'appels aux méthodes correspondantes des API publiques. Nous n'utilisons pas d'applications Web classiques et de génération de contenu côté serveur, en fait, tout ce que vous voyez comme une interface utilisateur est des vues JS sur nos API publiques. En principe, toute action dans la plate-forme peut être effectuée avec une chaîne d'appels de boucle à partir de la console, que nous utilisons. En particulier, pour écrire des tests d'intégration (nous les avons écrits en JS en tant que bibliothèque), qui en CI, lors de chaque assemblage, vérifient toutes les méthodes publiques.
De plus, une telle approche résout tous les problèmes d'intégration externe avec notre plate-forme, vous permettant d'obtenir un protocole unique pour l'utilisateur final sous la forme d'une belle forme de saisie des données de paiement et d'hôte à hôte pour une intégration directe avec un traitement tiers utilisant exclusivement une interaction interserveur.
En plus de la couverture complète des tests d'intégration, nous utilisons les approches de mise à jour intermédiaire, dans une architecture distribuée, il est assez facile de le faire, par exemple, en déployant un seul service de chaque groupe en un seul passage, suivi d'une pause et d'une analyse des journaux et des graphiques.
Cela nous permet de déployer presque 24 heures sur 24, y compris les vendredis soirs, de déployer quelque chose d'inopérant sans trop de crainte, ou de revenir rapidement en arrière, en effectuant un simple retour en arrière avec un changement, jusqu'à ce que personne ne le remarque.

Avant tout appel à la méthode publique, nous devons autoriser et authentifier le client. Pour qu'un client apparaisse sur la plateforme, vous avez besoin d'un service qui prendra en charge toutes les interactions avec l'utilisateur final, fournira des interfaces pour l'enregistrement, la saisie et la réinitialisation des mots de passe, le contrôle de sécurité et d'autres liaisons.
Ici, nous n'avons pas inventé un vélo, mais simplement intégré la solution open source de Redhat - Keycloak . Avant de commencer toute interaction avec nous, vous devrez vous inscrire sur la plateforme, ce qui, en fait, se fait via Keycloak.
Après une authentification réussie dans le service, le client reçoit un JWT. Nous l'utiliserons plus tard pour l'autorisation - du côté de Keycloak, vous pouvez spécifier des champs arbitraires qui décrivent les rôles qui seront incorporés comme une structure json simple dans JWT et signés avec la clé privée du service.
L'une des caractéristiques de JWT est que cette structure est signée par la clé privée du serveur; en conséquence, pour autoriser la liste des rôles et ses autres objets, nous n'avons pas besoin d'accéder au service d'autorisation, le processus est complètement découplé. Les services CAPI au démarrage lisent la clé publique Keycloak et l'utilisent pour autoriser les appels aux méthodes API publiques.
Lorsque nous avons élaboré le schéma de révocation clé, l'histoire est distincte et mérite son propre article.
Donc, nous avons reçu le JWT, nous pouvons l'utiliser pour l'authentification. Ici, le groupe de microservices Common API entre en jeu, sur le diagramme indiqué comme CAPI et CAPI-DSS, qui implémentent les fonctions suivantes:
- autorisation des messages reçus. Chaque appel d'API public est précédé d'un en-tête HTTP Authorizaion: Bearer {JWT}. Les services du groupe Common API l'utilisent pour vérifier les données signées avec la clé publique existante du service d'autorisation;
- validation des données reçues. Étant donné que le schéma est décrit comme une spécification OpenAPI, également connue sous le nom de Swagger, la validation des données peut être très facile et avec peu de chances de recevoir des commandes de contrôle dans le flux de données. Cela a un effet positif sur la sécurité du service dans son ensemble;
- traduction des formats de données du REST JSON public en Thrift binaire interne;
- encadrer la liaison de transport avec des données telles qu'un trace_id unique et transmettre l'événement plus loin à l'intérieur de la plate-forme à un service qui gère la logique métier et sait ce qu'est, par exemple, le paiement.
Nous avons de nombreux services de ce type, ils sont assez simples et en chêne, ne stockent aucun état, donc pour une mise à l'échelle linéaire des performances, nous les déployons simplement à pleine capacité dans les quantités dont nous avons besoin.
PCI-DSS et données de carte ouvertes

Comme vous pouvez le voir dans le diagramme, nous avons deux de ces groupes de services - le principal, l'API commune, est responsable du traitement de tous les flux de données qui n'ont pas de données de titulaire de carte ouvertes, et le second, l'API commune PCI-DSS, qui fonctionne directement avec ces cartes. À l'intérieur, ils sont exactement les mêmes, mais nous les avons séparés physiquement et disposés sur différents morceaux de fer.
Ceci est fait afin de minimiser le nombre d'emplacements de stockage et de traitement des données de carte, de réduire les risques de fuite de ces données et la zone de certification PCI-DSS. Et cela, croyez-moi, est un processus assez long et coûteux - en tant qu'entreprise de paiement, nous sommes tenus de subir une certification payante pour la conformité aux normes MPS chaque année, et moins il y a de serveurs et de services impliqués, plus il est rapide et facile de terminer ce processus. Eh bien, sur la sécurité, cela se reflète de la manière la plus positive.
Facturation et tokenisation
Nous voulons donc commencer le paiement et radier l'argent de la carte du payeur.
Imaginez que la demande se fasse sous la forme d'une chaîne d'appels aux méthodes de notre API publique, qui a été initiée par vous en tant que payeur après que vous soyez allé sur la boutique en ligne, récupéré un panier de marchandises, cliqué sur "Acheter", saisi les détails de votre carte dans notre paiement formulaire et cliqué sur le bouton "Payer".
Nous fournissons divers processus commerciaux pour radier de l'argent, mais le plus intéressant est le processus utilisant des comptes créditeurs. Dans notre plateforme, vous pouvez créer une facture pour le paiement, ou une facture qui sera un conteneur pour les paiements.
Dans une même facture, vous pouvez essayer de la payer une par une, c'est-à-dire créer des paiements jusqu'à ce que le prochain paiement soit réussi. Par exemple, vous pouvez essayer de payer une facture à partir de différentes cartes, portefeuilles et autres modes de paiement. S'il n'y a pas d'argent sur l'une des cartes, vous pouvez en essayer une autre et ainsi de suite.
Cela a un effet positif sur la conversion et l'expérience utilisateur.
Machine d'état de facture

À l'intérieur de la plate-forme, cette chaîne se transforme en interactions le long de l'itinéraire suivant:
- Avant de livrer du contenu à votre navigateur, notre client-commerçant intégré à notre plateforme, s'est enregistré auprès de nous et a reçu un JWT pour autorisation;
- à partir de son backend, le commerçant a appelé la méthode createInvoice () , c'est-à-dire qu'il a créé une facture pour le paiement dans notre plateforme. En fait, le backend marchand a envoyé une requête HTTP POST du contenu suivant à notre point de terminaison:
curl -X POST \ https://api.rbk.money/v2/processing/invoices \ -H 'Authorization: Bearer {JWT}' \ -H 'Content-Type: application/json; charset=utf-8' \ -H 'X-Request-ID: 1554417367' \ -H 'cache-control: no-cache' \ -d '{ "shopID": "TEST", "dueDate": "2019-03-28T17:41:32.569Z", "amount": 6000, "currency": "RUB", "product": "Order num 12345", "description": "Delicious meals", "cart": [ { "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "metadata": { "order_id": "Internal order num 13123298761" } }'
La demande était équilibrée sur l'une des applications erlang du groupe Common API, qui a vérifié sa validité, s'est rendue au service Bender, où elle a reçu la clé d'idempotency, l'a transférée au tift et a envoyé une demande au groupe de services Hellgate. L'instance Hellgate a effectué des vérifications commerciales, par exemple, s'est assurée que le propriétaire de ce JWT n'est pas en principe bloqué, peut créer des factures et généralement interagir avec la plate-forme et a commencé à créer une facture.
Nous pouvons dire que Hellgate est au cœur de notre traitement, car il opère avec des entités commerciales, sait comment lancer un paiement, qui doit être viré pour que ce paiement se transforme en une somme d'argent réelle, comment calculer l'itinéraire de ce paiement, à qui il faudrait dire de l'annuler reflétées dans les bilans, calculer les commissions et autres consolidations.
En règle générale, il ne stocke aucun état et est également facilement évolutif. Mais nous ne voudrions pas perdre la facture ou recevoir une double charge d'argent de la carte en cas de rupture de réseau ou de défaillance de Hellgate pour une raison quelconque. Il est nécessaire de sauvegarder ces données de manière persistante.
Voici le troisième microservice, à savoir Machinegun. Hellgate envoie à Machinegun un appel pour "créer un automate" avec une charge utile sous forme de paramètres de requête. Machinegun organise les demandes simultanées et, à l'aide de Hellgate, crée le premier événement à partir des paramètres - InvoiceCreated. Ce qui alors lui-même et écrit dans Riak et les files d'attente. Après cela, une réponse réussie est renvoyée dans l'ordre inverse à la demande initiale de la chaîne.
En bref, Machinegun est un tel SGBD avec des temporisateurs sur tout autre SGBD, dans la version actuelle de la plate-forme - sur Riak. Il fournit une interface qui vous permet de contrôler des machines indépendantes et fournit des garanties d'idempotence et d'ordre d'enregistrement. C'est MG qui ne permettra pas que l'événement soit automatiquement supprimé de la file d'attente si plusieurs HG lui parviennent soudainement avec une telle demande.
Un automate est une entité unique au sein de la plate-forme, composée d'un identifiant, d'un ensemble de données sous la forme d'une liste d'événements et d'un temporisateur. L'état final de l'automate est calculé à partir du traitement de tous ses événements qui déclenchent sa transition vers l'état correspondant. Nous utilisons cette approche pour travailler avec des entités commerciales, en les décrivant comme des machines à états finis. En fait, toutes les factures créées par nos marchands, ainsi que leurs paiements, sont des machines à états finis avec leur propre logique de transition entre les états.
L'interface pour travailler avec des minuteries dans Machinegun vous permet de recevoir une demande du formulaire "Je veux continuer à traiter cette machine dans 15 ans" d'un autre service avec des événements pour l'enregistrement. Ces tâches en attente sont implémentées sur des minuteries intégrées. En pratique, ils sont très souvent utilisés - appels périodiques à la banque, actions automatiques avec paiements dus à une longue inactivité, etc.
Soit dit en passant, les codes source de Machinegun sont ouverts sous la licence Apache 2.0 dans notre référentiel public . Nous espérons que ce service pourra être utile à la communauté.
Une description détaillée du travail de Machinegun et, en général, de la façon dont nous préparons le système de distribution, est tirée vers un autre poste important, donc je ne m'arrêterai pas ici plus en détail.
Les nuances de l'autorisation des clients externes

Après une sauvegarde réussie, Hellgate renvoie les données au CAPI, il convertit la structure binaire de trift en un JSON magnifiquement conçu, prêt à être envoyé au backend marchand:
{ "invoice": { "amount": 6000, "cart": [ { "cost": 5000, "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "cost": 1000, "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "createdAt": "2019-04-04T23:00:31.565518Z", "currency": "RUB", "description": "Delicious meals", "dueDate": "2019-04-05T00:00:30.889000Z", "id": "18xtygvzFaa", "metadata": { "order_id": "Internal order num 13123298761" }, "product": "Order num 12345", "shopID": "TEST", "status": "unpaid" }, "invoiceAccessToken": { "payload": "{JWT}" } }
Il semblerait que vous puissiez envoyer du contenu au payeur dans le navigateur et démarrer le processus de paiement, mais ici, nous pensions que tous les commerçants ne seraient pas prêts à mettre en œuvre indépendamment l'autorisation côté client, nous l'avons donc mise en œuvre nous-mêmes. L'approche est que CAPI génère un autre JWT qui vous permet de démarrer des processus de tokenisation de carte et de gérer une facture spécifique et l'ajoute à la structure de facture retournée.
Un exemple des rôles décrits dans un JWT similaire:
"resource_access": { "common-api": { "roles": [ "invoices.18xtygvzFaa.payments:read", "invoices.18xtygvzFaa.payments:write", "invoices.18xtygvzFaa:read", "payment_resources:write" ] } }
Ce JWT a un nombre limité de tentatives d'utilisation et la durée de vie que nous configurons, ce qui vous permet de le publier dans le navigateur du payeur. Même s'il est intercepté, le maximum qu'un attaquant puisse faire est de payer la facture de quelqu'un d'autre ou de lire ses données. De plus, étant donné que la machine de paiement ne fonctionne pas avec des données de carte ouvertes, le maximum qu'un attaquant peut voir est un numéro de carte masqué du formulaire 4242 42** **** 4242 , le montant du paiement et, éventuellement, un panier de marchandises.
La facture créée et sa clé d'accès vous permettent de démarrer le processus commercial de paiement. Nous donnons l'ID de facture et son JWT au navigateur du payeur et transférons le contrôle à nos applications JS.
Notre application Checkout JS met en œuvre une interface pour interagir avec vous en tant que payeur - dessine un formulaire de saisie des données de paiement, démarre un paiement, reçoit son statut final, affiche un point drôle ou triste.
Tokenisation et données de carte

Mais Checkout ne fonctionne pas avec les données de la carte. Comme mentionné ci-dessus, nous souhaitons stocker des données sensibles sous forme de données de titulaire de carte dans le moins d'endroits possible. Pour ce faire, nous implémentons la tokenisation.
C'est là que la bibliothèque Tokenizer JS entre en jeu. Lorsque vous entrez votre carte dans les champs de saisie et cliquez sur "Payer", elle intercepte ces données et nous les envoie de manière asynchrone pour traitement en appelant la méthode createPaymentResource () .
Cette demande est équilibrée pour les applications CAPI-DSS individuelles, qui autorisent également la demande, uniquement en vérifiant la facture JWT, en validant les données et en les envoyant par tront au service de stockage des données de la carte. Dans le diagramme, il est indiqué comme CDS - Stockage de données sur carte.
Les principaux objectifs de ce service:
- recevoir des données sensibles sur une entrée, dans notre cas - les données de votre carte;
- crypter ces données avec une clé de cryptage des données;
- générer une valeur aléatoire utilisée comme clé;
- enregistrez les données chiffrées sur cette clé dans votre cluster Riak;
- retourner la clé sous forme de jeton de données de paiement au service CAPI-DSS.
En cours de route, le service résout un tas de tâches importantes, telles que la génération de clés pour le chiffrement de clés, la saisie sécurisée de ces clés, le rechiffrement des données, le contrôle de l'effacement de CVV après le paiement, etc., mais cela dépasse le cadre de cet article.
Ce n'était pas sans protection contre la possibilité de se tirer une balle dans le pied. Il existe une probabilité non nulle qu'un JWT privé, conçu pour autoriser les demandes du backend, soit publié sur le Web dans le navigateur du client. Pour éviter cela, nous avons intégré une protection - vous ne pouvez appeler la méthode createPaymentResource () qu'avec la clé d'autorisation de facturation. Lorsque vous essayez d'utiliser une plateforme JWT privée, une erreur HTTP / 401 sera renvoyée.
Après avoir terminé la demande de tokenisation, le Tokenizer renvoie le jeton reçu à Checkout et termine son travail à ce sujet.
Processus opérationnel de la machine de paiement

Checkout démarre le processus de paiement, à savoir, il appelle la méthode createPayment () , en passant le jeton de carte précédemment reçu comme argument et démarre le processus d'interrogation des événements, en fait, en appelant la méthode API getInvoiceEvents () une fois par seconde.
Ces demandes via CAPI tombent dans Hellgate, qui commence à mettre en œuvre un processus commercial de paiement, sans utiliser les données de la carte:
- tout d'abord, Hellgate passe au service de gestion de configuration - Dominant et reçoit la révision actuelle de la configuration du domaine. Il contient toutes les règles selon lesquelles ce paiement sera effectué, pour quelle banque il ira à l'autorisation, quels frais de transaction seront enregistrés, etc.
- du service de gestion des membres, qui fait maintenant partie de HG, apprend des données sur les numéros internes des comptes du commerçant en faveur desquels le paiement est effectué, applique le montant des frais, prépare un plan d'affichage et le met dans le service Shumway. Ce service est responsable de la gestion des informations sur les mouvements d'argent sur les comptes des participants à une transaction lors d'un paiement. Le plan de détachement contient l'instruction "de geler les éventuels mouvements de fonds sur les comptes des participants à la transaction spécifiée dans le plan";
- enrichit les données de paiement en se référant à des services supplémentaires, par exemple, dans Binbase afin de connaître le pays de la banque émettrice qui a émis la carte et son type, par exemple, «or, crédit»;
- appelle le service de l'inspecteur, en règle générale, il s'agit d'Antifraud afin de recevoir la notation de paiement et de décider du choix d'un terminal qui couvre le niveau de risque émis par la notation. Par exemple, un terminal sans 3D-Secure peut être utilisé pour les paiements à faible risque, et un paiement qui a reçu un niveau de risque fatal mettra fin à sa vie à ce sujet;
- appelle le service de détection d'erreurs, le Faultdetector, et sur la base des données reçues, il sélectionne la voie de paiement - l'adaptateur de protocole bancaire, qui présente actuellement le moins d'erreurs et la plus grande probabilité de paiement réussi;
- envoie une demande à l'adaptateur de protocole bancaire sélectionné, que ce soit l'adaptateur YellowBank, "autorisez le montant spécifié à partir de ce jeton" dans ce cas.
L'adaptateur de protocole pour le jeton reçu va à CDS, reçoit les données de la carte déchiffrée, les transfère vers un protocole spécifique à la banque et, en général, reçoit l'autorisation - confirmation de la banque acquéreuse que le montant indiqué a été gelé sur le compte du payeur.
C'est à ce moment que vous recevez un SMS avec un message sur le débit des fonds de votre carte de votre banque, bien qu'en fait les fonds n'aient été gelés que sur votre compte.
L'adaptateur informe HG de l'autorisation réussie, votre code CVV est supprimé du service CDS et c'est la fin de l'étape d'interaction. La direction revient à HG.

Selon le processus de paiement spécifié par l'appel createPayment () par le commerçant du processus commercial de paiement, HG attend des appels de l'API externe vers la méthode de capture d'autorisation, c'est-à-dire la confirmation du retrait d'argent de votre carte, ou le fait immédiatement de lui-même, si le commerçant a choisi le schéma paiement en une seule étape.
En règle générale, la plupart des commerçants utilisent un paiement en une seule étape, mais il existe des catégories d'entreprises qui, au moment de l'autorisation, ne connaissent pas encore le montant total facturé. Cela se produit souvent dans l'industrie du tourisme lorsque vous réservez une visite pour un montant, et après confirmation de la réservation, le montant est spécifié et peut différer de celui qui était autorisé au début.
Malgré le fait que le montant de la confirmation peut être exclusivement égal ou inférieur au montant de l'autorisation, il y a des écueils ici. Imaginez que vous payez un produit ou un service à partir d'une carte dans une devise différente de la devise de votre compte bancaire auquel la carte est liée.
Au moment de l'autorisation, le montant bloqué sur votre compte en fonction du taux de change au jour de l'autorisation. Étant donné que le paiement peut avoir le statut «autorisé» (malgré le fait que le ministère des Chemins de fer a des recommandations pour une période maximale et est maintenant de 3 jours) pendant plusieurs jours, la capture de l'autorisation sera effectuée au rythme du jour où elle a été faite.
Ainsi, vous portez des risques de change, qui peuvent être à la fois en votre faveur et contre vous, notamment dans une situation de forte volatilité sur le marché des devises.
Pour capturer l'autorisation, le même processus de communication avec l'adaptateur de protocole se produit que pour la recevoir, et en cas de succès, HG applique le plan de comptabilisation du compte à l'intérieur de Shumway et transfère le paiement au statut "Payé". C'est à ce moment que nous, en tant que système de paiement, avons des obligations financières envers les participants à la transaction.
Il convient également de noter que tout changement dans l'état de la machine à facture, y compris le processus de paiement, est enregistré par Hellgate dans Machinegun, garantissant la persistance des données et enrichissant la facture avec de nouveaux événements.
Synchronisation d'état d'une machine de paiement et de l'interface utilisateur
Pendant que le processus de paiement en arrière-plan se déroule à l'intérieur de la plateforme, Checkout verse le traitement en demandant des événements. À la réception de certains événements, il dessine l'état actuel du paiement sous une forme compréhensible pour une personne - dessine un préchargeur, affiche l'écran `` Votre paiement a été traité avec succès '' ou `` Le paiement n'a pas pu être effectué '' ou redirige le navigateur vers la page de votre banque émettrice pour saisir le mot de passe 3D-Secure;
En cas d'échec, Checkout vous proposera de choisir un autre mode de paiement ou de réessayer, commençant ainsi un nouveau paiement dans le cadre de la facture.
Un tel schéma avec interrogation des événements permet de restaurer l'état même après la fermeture de l'onglet du navigateur - en cas de lancement répété, Checkout recevra la liste actuelle des événements et dessinera le scénario actuel d'interaction avec l'utilisateur, par exemple, suggérera d'entrer le code 3D-Secure ou montrera que le paiement a déjà été effectué avec succès.
Réplication des événements dans la zone hors ligne
Parallèlement aux interfaces de contrôle des machines, Machinegun implémente un service chargé de faire déborder le flux d'événements vers des services chargés d'autres tâches moins en ligne de la plateforme.
En tant que courtier de file d'attente en finale, nous nous sommes installés sur Kafka, bien que nous ayons précédemment implémenté cette fonctionnalité en utilisant Machinegun lui-même. Dans le cas général, ce service est la préservation d'un flux d'événements ordonné garanti, ou l'émission d'une liste spécifique d'événements sur demande à d'autres consommateurs.
Nous avons également initialement mis en œuvre un système de déduplication des événements, offrant des garanties que le même événement ne serait pas répliqué deux fois, cependant, la charge sur Riak, qui a été générée par un similaire, nous a forcé à l'abandonner - après tout, la recherche d'index n'est pas la meilleure chose Capacité de stockage KV. Désormais, chaque consommateur de services est responsable de la déduplication des événements de manière indépendante.
En général, la réplication des événements par Machinegun se termine par la confirmation du stockage des données dans Kafka, et les consommateurs sont déjà connectés aux sujets Kafka et téléchargent les listes d'événements qui les intéressent.
Modèle d'application de zone hors ligne typique
Par exemple, le service Dudoser est chargé de vous envoyer une notification par e-mail d'un paiement réussi. Au démarrage, il génère une liste d'événements de paiements réussis, prend des informations sur l'adresse et le montant à partir de là, l'enregistre dans une instance PostgreSQL locale et l'utilise pour un traitement ultérieur de la logique métier.
Tous les autres services similaires fonctionnent selon la même logique, par exemple le service Magista, qui est chargé de rechercher les factures et les paiements dans le compte personnel du commerçant ou le service Hooker, qui envoie des rappels asynchrones au backend aux commerçants qui, pour une raison ou une autre, ne peuvent pas organiser des événements de sondage en contactant directement à l'API de traitement.
Cette approche nous permet de libérer la charge de traitement, d'allouer des ressources maximales et de fournir une vitesse et une disponibilité élevées du traitement des paiements, offrant une conversion élevée. Les requêtes lourdes telles que «les clients professionnels veulent voir des statistiques sur les paiements au cours de la dernière année» sont traitées par des services qui n'affectent pas la charge actuelle de la partie de traitement en ligne et ne vous affectent donc pas, en tant que payeurs et commerçants, en tant que clients.
Peut-être que nous nous arrêterons à cela pour ne pas transformer le message en un trop long. Dans les prochains articles, je vais certainement vous parler des nuances d'assurer l'atomicité des changements, des garanties et de l'ordre dans un système distribué chargé en utilisant Machinegun, Bender, CAPI et Hellgate comme exemples.
Eh bien, à propos de Salt Stack la prochaine fois ¯\_(ツ)_/¯