Dans la
première partie de l' article, en utilisant Ghidra, nous avons automatiquement analysé un programme de crack simple (que nous avons téléchargé depuis crackmes.one). Nous avons compris comment renommer les fonctions "incompréhensibles" directement dans la liste des décompilateurs, et avons également compris l'algorithme du programme "de haut niveau", c'est-à-dire ce qui est fait par
main () .
Dans cette partie, comme je l'ai promis, nous allons reprendre l'analyse de la fonction
_construct_key () , qui, comme nous l'avons découvert, est responsable de la lecture du fichier binaire transféré au programme et de la vérification des données lues.
Étape 5 - Présentation de la fonction _construct_key ()
Regardons tout de suite la liste complète de cette fonction:
Liste _construct_key ()char ** __cdecl _construct_key(FILE *param_1) { int iVar1; size_t sVar2; uint uVar3; uint local_3c; byte local_36; char local_35; int local_34; char *local_30 [4]; char *local_20; undefined4 local_19; undefined local_15; char **local_14; int local_10; local_14 = (char **)__prepare_key(); if (local_14 == (char **)0x0) { local_14 = (char **)0x0; } else { local_19 = 0; local_15 = 0; _text(&local_19,1,4,param_1); iVar1 = _text((char *)&local_19,*(char **)local_14[1],4); if (iVar1 == 0) { _text(local_14[1] + 4,2,1,param_1); _text(local_14[1] + 6,2,1,param_1); if ((*(short *)(local_14[1] + 6) == 4) && (*(short *)(local_14[1] + 4) == 5)) { local_30[0] = *local_14; local_30[1] = *local_14 + 0x10c; local_30[2] = *local_14 + 0x218; local_30[3] = *local_14 + 0x324; local_20 = *local_14 + 0x430; local_10 = 0; while (local_10 < 5) { local_35 = 0; _text(&local_35,1,1,param_1); if (*local_30[local_10] != local_35) { _free_key(local_14); return (char **)0x0; } local_36 = 0; _text(&local_36,1,1,param_1); if (local_36 == 0) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x104) = (uint)local_36; _text(local_30[local_10] + 1,1,*(size_t *)(local_30[local_10] + 0x104),param_1); sVar2 = _text(local_30[local_10] + 1); if (sVar2 != *(size_t *)(local_30[local_10] + 0x104)) { _free_key(local_14); return (char **)0x0; } local_3c = 0; _text(&local_3c,1,1,param_1); local_3c = local_3c + 7; uVar3 = _text(param_1); if (local_3c < uVar3) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x108) = local_3c; _text(param_1,local_3c,0); local_10 = local_10 + 1; } local_34 = 0; _text(&local_34,4,1,param_1); if (*(int *)(*local_14 + 0x53c) == local_34) { _text("Markers seem to still exist"); } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } return local_14; }
Avec cette fonction, nous ferons la même chose qu'avant avec
main () - pour commencer, nous passerons en revue les appels de fonction «voilés». Comme prévu, toutes ces fonctions proviennent des bibliothèques standard C. Je ne décrirai pas la procédure pour renommer des fonctions à nouveau - revenez à la première partie de l'article, si nécessaire. À la suite du changement de nom, les fonctions standard suivantes ont été «trouvées»:
- fread ()
- strncmp ()
- strlen ()
- ftell ()
- fseek ()
- met ()
Nous avons renommé les fonctions d'encapsulation correspondantes dans notre code (celles que le décompilateur a effrontément cachées derrière le mot
_text ) en ajoutant l'index 2 (afin qu'il n'y ait pas de confusion avec les fonctions C d'origine). Presque toutes ces fonctions permettent de travailler avec des flux de fichiers. Il n'est pas surprenant - un rapide coup d'œil au code suffit pour comprendre qu'il lit séquentiellement les données d'un fichier (dont le descripteur est transmis à la fonction en tant que paramètre unique) et compare les données lues avec un certain tableau bidimensionnel de
local_14 octets.
Supposons que ce tableau contient des données pour la vérification des clés. Appelez-le, dites
key_array . Étant donné qu'Hydra vous permet de renommer non seulement des fonctions, mais également des variables, nous l'utiliserons et renommerons le
local_14 incompréhensible en un
tableau de clés plus compréhensible. Cela se fait de la même manière que pour les fonctions: via le menu du bouton droit de la souris (
Renommer local ) ou par la touche
L du clavier.
Ainsi, immédiatement après la déclaration des variables locales, une certaine fonction
_prepare_key () est
appelée :
key_array = (char **)__prepare_key(); if (key_array == (char **)0x0) { key_array = (char **)0x0; }
Nous reviendrons sur
_prepare_key () , c'est le 3ème niveau d'imbrication dans notre hiérarchie d'appels:
main () -> _construct_key () -> _prepare_key () . En attendant, nous acceptons qu'il crée et initialise en quelque sorte ce tableau bidimensionnel «test». Et seulement si ce tableau n'est pas vide, la fonction continue son travail, comme en témoigne le bloc
else immédiatement après la condition.
Ensuite, le programme lit les 4 premiers octets du fichier et compare avec la section correspondante du tableau
key_array . (Le code ci-dessous est après avoir renommé, y compris la variable
local_19, j'ai renommé
first_4bytes .)
first_4bytes = 0; fread2(&first_4bytes,1,4,param_1); iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4); if (iVar1 == 0) { ... }
Ainsi, une exécution ultérieure ne se produit que si les 4 premiers octets coïncident (rappelez-vous ceci). Ensuite, nous lisons 2 blocs de 2 octets du fichier (et le même
key_array est utilisé comme tampon pour l'écriture des données):
fread2(key_array[1] + 4,2,1,param_1); fread2(key_array[1] + 6,2,1,param_1);
Et encore - en outre, la fonction ne fonctionne que si la condition suivante est vraie:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) {
Il est facile de voir que le premier des blocs de 2 octets lu ci-dessus doit être le numéro 5, et le second doit être le numéro 4 (le type de données
court occupe seulement 2 octets sur les plates-formes 32 bits).
Le suivant est le suivant:
local_30[0] = *key_array;
Nous voyons ici que le tableau
local_30 (déclaré comme char * local_30 [4]) contient les décalages du pointeur
key_array . Autrement dit,
local_30 est un tableau de lignes de marqueur dans lequel les données du fichier seront probablement lues. Dans cette hypothèse, j'ai renommé
local_30 en
marqueurs . Dans cette section de code, seule la dernière ligne semble un peu suspecte, où l'affectation du dernier décalage (à l'index 0x430, c'est-à-dire 1072) est effectuée non par l'élément de
marqueurs suivant, mais par une variable
locale_20 distincte (
char * ). Mais nous allons le découvrir encore, mais pour l'instant - passons à autre chose!
Ensuite, nous attendons un cycle:
i = 0;
C'est-à-dire Seulement 5 itérations de 0 à 4 inclus. Dans la boucle, la lecture du fichier et la vérification de la conformité avec notre tableau de
marqueurs commencent immédiatement:
char c_marker = 0;
C'est-à-dire que l'octet suivant du fichier est lu dans la variable
c_marker (dans le code décompilé d'origine -
local_35 ) et vérifié la conformité avec le premier caractère du ième élément
marqueurs . En cas de non-concordance, le tableau
key_array est annulé et un double pointeur vide est renvoyé. Plus loin dans le code, nous voyons que cela se fait chaque fois que les données lues ne correspondent pas aux données de vérification.
Mais ici, comme on dit, "le chien est enterré". Examinons de plus près ce cycle. Il a 5 itérations, comme nous l'avons découvert. Vous pouvez vérifier cela si vous le souhaitez en consultant le code assembleur:


En effet, la commande CMP compare la valeur de la variable
local_10 (nous avons déjà
i ) avec le nombre 4 et si la valeur est
inférieure ou égale à 4 (la commande JLE), la transition vers le label
LAB_004017eb est effectuée , c'est-à-dire début du corps du cycle. C'est-à-dire la condition sera remplie pour
i = 0, 1, 2, 3 et 4 - seulement 5 itérations! Tout irait bien, mais les
marqueurs sont également indexés par cette variable dans une boucle, et après tout, ce tableau est déclaré avec seulement 4 éléments:
char *markers [4];
Donc, quelqu'un essaie clairement de tromper quelqu'un :) Rappelez-vous, j'ai dit que cette ligne est douteuse?
local_20 = *key_array + 0x430;
Comme ça! Regardez simplement la liste complète de la fonction et essayez de trouver au moins une référence supplémentaire à la variable
local_20 . Elle n'est pas là! Nous concluons de ceci: ce décalage devrait également être stocké dans le tableau des
marqueurs , et le tableau lui-même devrait contenir 5 éléments. Corrigeons-le. Accédez à la déclaration de variable,
appuyez sur Ctrl + L (Retaper la variable) et changez audacieusement la taille du tableau en 5:
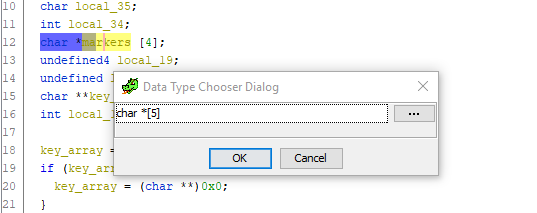
C'est fait. Faites défiler jusqu'au code pour attribuer des décalages de pointeur aux
marqueurs , et - et voilà! - une variable supplémentaire incompréhensible disparaît et tout se met en place:
markers[0] = *key_array; markers[1] = *key_array + 0x10c; markers[2] = *key_array + 0x218; markers[3] = *key_array + 0x324; markers[4] = *key_array + 0x430;
Nous revenons à notre
boucle while (dans le code source, ce sera très probablement
pour , mais peu nous importe). Ensuite, l'octet du fichier est relu et sa valeur est vérifiée:
byte n_strlen1 = 0;
OK, ce
n_strlen1 doit être différent de zéro. Pourquoi? Vous verrez maintenant, mais en même temps, vous comprendrez pourquoi j'ai donné à cette variable le nom suivant:
*(uint *)(markers[i] + 0x104) = (uint)n_strlen1; fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1); n_strlen2 = strlen2(markers[i] + 1);
J'ai ajouté des commentaires sur lesquels tout devrait être clair.
N_strlen1 octets sont lus à partir du fichier et enregistrés sous forme de séquence de caractères (c'est-à-dire une chaîne) dans le tableau des
marqueurs [i] - c'est-à-dire après le «stop-symbol» correspondant, qui y sont déjà écrits à partir de
key_array . L'enregistrement de la valeur
n_strlen1 dans les
marqueurs [i] à l'offset 0x104 (260) ne joue aucun rôle ici (voir la première ligne du code ci-dessus). En fait, ce code peut être optimisé comme suit (et c'est certainement le cas dans le code source):
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1); n_strlen2 = strlen2(markers[i] + 1); if (n_strlen2 != (size_t) n_strlen1) { ... }
Il vérifie également que la longueur de la ligne de lecture est
n_strlen1 . Cela peut sembler inutile, étant donné que ce paramètre a été transmis à la fonction
fread , mais
fread ne lit
pas plus de tant d'octets spécifiés et peut lire moins que ce qui est indiqué, par exemple, dans le cas de la réunion du marqueur de fin de fichier (EOF). Autrement dit, tout est strict: la longueur de la ligne (en octets) est indiquée dans le fichier, puis la ligne elle-même va - et exactement 5 fois. Mais nous prenons de l'avance sur nous-mêmes.
Arrose encore ce code (que j'ai aussi immédiatement commenté):
uint n_pos = 0;
C'est encore plus simple ici: nous prenons l'octet suivant du fichier, ajoutons 7 et comparons la valeur résultante avec la position actuelle du curseur dans le flux de fichier obtenu par la fonction
ftell () . La valeur de
n_pos ne doit pas être inférieure à la position du curseur (c'est-à-dire décalage en octets depuis le début du fichier).
La dernière ligne de la boucle:
fseek2(param_1,n_pos,0);
C'est-à-dire réorganiser le curseur de fichier (depuis le début) à la position indiquée par
n_pos par la fonction
fseek () . OK, nous effectuons toutes ces opérations dans la boucle 5 fois. La fonction
_construct_key () se termine par le code suivant:
int i_lastmarker = 0;
Ainsi, le dernier bloc de données dans le fichier doit être une valeur entière de 4 octets et il doit être égal à la valeur dans
key_array [0] [1340] . Dans ce cas, nous recevrons un message de félicitations dans la console. Sinon, le tableau vide revient toujours sans éloge :)
Étape 6 - Présentation de la fonction __prepare_key ()
Il ne nous reste qu'une fonction non assemblée -
__prepare_key () . Nous avons déjà deviné que c'est en elle que les données de vérification sont générées sous la forme du tableau
key_array , qui est ensuite utilisé dans la fonction
_construct_key () pour vérifier les données du fichier. Reste à savoir quel genre de données là-bas!
Je n'analyserai pas cette fonction en détail et donnerai immédiatement une liste complète avec des commentaires après tout le renommage nécessaire des variables:
Liste des fonctions de __Prepare_key () void ** __prepare_key(void) { void **key_array; void *pvVar1; key_array = (void **)calloc2(1,8); if (key_array == (void **)0x0) { key_array = (void **)0x0; } else { pvVar1 = calloc2(1,0x540); *key_array = pvVar1; pvVar1 = calloc2(1,8); key_array[1] = pvVar1; *(undefined4 *)key_array[1] = 0x404024; *(undefined2 *)((int)key_array[1] + 4) = 5; *(undefined2 *)((int)key_array[1] + 6) = 4; *(undefined *)*key_array = 0x62; *(undefined4 *)((int)*key_array + 0x104) = 3; *(undefined *)((int)*key_array + 0x218) = 0x57; *(undefined *)((int)*key_array + 0x324) = 0x70; *(undefined *)((int)*key_array + 0x10c) = 0x6c; *(undefined *)((int)*key_array + 0x430) = 0x98; *(undefined4 *)((int)*key_array + 0x53c) = 0x462; } return key_array; }
Le seul endroit à considérer est cette ligne:
*(undefined4 *)key_array[1] = 0x404024;
Comment puis-je comprendre que se trouve ici la ligne "VOID"? Le fait est que 0x404024 est l'adresse dans l'espace d'adressage du programme menant à la section
.rdata . Un double-clic sur cette valeur nous permet de voir clairement ce qui s'y trouve:

Par ailleurs, la même chose peut être comprise à partir du code assembleur de cette ligne:
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
Les données correspondant à la ligne VOID se
trouvent au tout début de la section
.rdata (à décalage zéro par rapport à l'adresse correspondante).
Ainsi, à la sortie de cette fonction, un tableau à deux dimensions doit être formé avec les données suivantes:
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
Étape 7 - Préparez le binaire pour la fissure
Nous pouvons maintenant commencer la synthèse du fichier binaire. Toutes les données initiales entre nos mains:
1) les données de vérification («symboles d'arrêt») et leurs positions dans le tableau de vérification;
2) la séquence de données dans le fichier
Restaurons la structure du fichier recherché selon l'algorithme de la fonction
_construct_key () . Ainsi, la séquence de données dans le fichier sera la suivante:
Structure des fichiers- 4 octets == key_array [1] [0 ... 3] == "VOID"
- 2 octets == key_array [1] [4] == 5
- 2 octets == key_array [1] [6] == 4
- 1 octet == key_array [0] [0] == 'b' (jeton)
- 1 octet == (longueur de ligne suivante) == n_strlen1
- n_strlen1 octets == (n'importe quelle chaîne) == n_strlen1
- 1 octet == (+7 == jeton suivant) == n_pos
- 1 octet == key_array [0] [0] == 'l' (jeton)
- 1 octet == (longueur de ligne suivante) == n_strlen1
- n_strlen1 octets == (n'importe quelle chaîne) == n_strlen1
- 1 octet == (+7 == jeton suivant) == n_pos
- 1 octet == key_array [0] [0] == 'W' (jeton)
- 1 octet == (longueur de ligne suivante) == n_strlen1
- n_strlen1 octets == (n'importe quelle chaîne) == n_strlen1
- 1 octet == (+7 == jeton suivant) == n_pos
- 1 octet == key_array [0] [0] == 'p' (jeton)
- 1 octet == (longueur de ligne suivante) == n_strlen1
- n_strlen1 octets == (n'importe quelle chaîne) == n_strlen1
- 1 octet == (+7 == jeton suivant) == n_pos
- 1 octet == tableau_clé [0] [0] == 152 (jeton)
- 1 octet == (longueur de ligne suivante) == n_strlen1
- n_strlen1 octets == (n'importe quelle chaîne) == n_strlen1
- 1 octet == (+7 == jeton suivant) == n_pos
- 4 octets == (tableau_clé [1340]) == 1122
Pour plus de clarté, j'ai réalisé dans Excel une telle tablette avec les données du fichier souhaité:

Ici, à la 7e ligne - les données elles-mêmes sous forme de caractères et de chiffres, à la 6e ligne - leurs représentations hexadécimales, à la 8e ligne - la taille de chaque élément (en octets), à la 9e ligne - le décalage par rapport au début du fichier. Cette vue est très pratique car vous permet d'entrer toutes les lignes dans le futur fichier (marquées d'un remplissage jaune), tandis que les valeurs des longueurs de ces lignes, ainsi que les décalages de position du prochain symbole d'arrêt sont calculés automatiquement par des formules, comme l'algorithme du programme l'exige. Ci-dessus (aux lignes 1 à 4), la structure du tableau de contrôle
key_array est
affichée .
L'excel lui-même ainsi que d'autres sources de l'article peuvent être téléchargés
ici .
Génération et validation de fichiers binaires
Il ne reste plus qu'à générer le fichier souhaité au format binaire et à le nourrir avec notre crack. Pour générer le fichier, j'ai écrit un simple script Python:
Script pour générer le fichier import sys, os import struct import subprocess out_str = ['!', 'I', ' solved', ' this', ' crackme!'] def write_file(file_path): try: with open(file_path, 'wb') as outfile: outfile.write('VOID'.encode('ascii')) outfile.write(struct.pack('2h', 5, 4)) outfile.write('b'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[0]))) outfile.write(out_str[0].encode('ascii')) pos = 10 + len(out_str[0]) outfile.write(struct.pack('B', pos - 6)) outfile.write('l'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[1]))) outfile.write(out_str[1].encode('ascii')) pos += 3 + len(out_str[1]) outfile.write(struct.pack('B', pos - 6)) outfile.write('W'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[2]))) outfile.write(out_str[2].encode('ascii')) pos += 3 + len(out_str[2]) outfile.write(struct.pack('B', pos - 6)) outfile.write('p'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[3]))) outfile.write(out_str[3].encode('ascii')) pos += 3 + len(out_str[3]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('B', 152)) outfile.write(struct.pack('B', len(out_str[4]))) outfile.write(out_str[4].encode('ascii')) pos += 3 + len(out_str[4]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('i', 1122)) except Exception as err: print(err) raise def main(): if len(sys.argv) != 2: print('USAGE: {this_script.py} path_to_crackme[.exe]') return if not os.path.isfile(sys.argv[1]): print('File "{}" unavailable!'.format(sys.argv[1])) return file_path = os.path.splitext(sys.argv[1])[0] + '.dat' try: write_file(file_path) except: return try: outputstr = subprocess.check_output('"{}" -f "{}"'.format(sys.argv[1], file_path), stderr=subprocess.STDOUT) print(outputstr.decode('utf-8')) except Exception as err: print(err) if __name__ == '__main__': main()
Le script prend le chemin d'accès aux fissures en tant que paramètre unique, puis génère un fichier binaire avec la clé dans le même répertoire et appelle les fissures avec le paramètre correspondant, traduisant la sortie du programme vers la console.
Pour convertir des données texte en binaire, utilisez le package
struct . La méthode
pack () vous permet d'écrire des données binaires dans un format dans lequel le type de données est indiqué ("B" = "byte", "i" = int, etc.), et vous pouvez également spécifier la séquence (">" = "Big -endian "," <"=" Little-endian "). L'ordre par défaut est Little-endian. Parce que nous avons déjà déterminé dans le premier article que c'est exactement notre cas, nous n'indiquons alors que le type.
Tout le code dans son ensemble reproduit l'algorithme de programme que nous avons trouvé. En tant que ligne à imprimer en cas de succès, j'ai spécifié "J'ai résolu ce crackme!" (vous pouvez modifier ce script pour qu'il soit possible de spécifier n'importe quelle ligne).
Vérifiez la sortie:

Hourra, tout fonctionne! Ainsi, après avoir transpiré un peu et trié quelques fonctions, nous avons pu restaurer complètement l'algorithme du programme et le «casser». Bien sûr, ce n'est qu'un simple crack, un programme de test, et même celui du 2ème niveau de difficulté (sur 5 proposés sur ce site). En réalité, nous traiterons une hiérarchie complexe d'appels et de dizaines - des centaines de fonctions, et dans certains cas - des sections chiffrées de données, du code poubelle et d'autres techniques d'obscurcissement, jusqu'à l'utilisation de machines virtuelles internes et de code P ... Mais cela, comme on dit, est déjà une histoire complètement différente.
Matériaux pour l'article.