En continuant à considérer les technologies d'accélération des opérations d'E / S appliquées aux systèmes de stockage, qui ont commencé dans l' article précédent , on ne peut s'empêcher de s'attarder sur une option aussi populaire que la hiérarchisation automatique. Bien que l'idéologie de cette fonction soit très proche de celle de divers fabricants de systèmes de stockage, nous considérerons les caractéristiques de l'implémentation de la déchirure en utilisant le système de stockage Qsan comme exemple.
Malgré la variété des données stockées sur le stockage, ces mêmes données peuvent être divisées en plusieurs groupes en fonction de leur pertinence (fréquence d'utilisation). Les données les plus populaires ("chaudes") sont extrêmement importantes pour organiser l'accès le plus rapide, tandis que le traitement des données moins populaires ("froides") peut être effectué avec une priorité inférieure.
Pour organiser un tel schéma, la fonction de déchirement est utilisée. Dans ce cas, la matrice de données ne se compose pas du même type de disques, mais de plusieurs groupes de lecteurs qui forment différents niveaux de stockage de niveau. À l'aide d'un algorithme spécial, les données sont automatiquement déplacées entre les niveaux afin d'assurer des performances finales maximales.
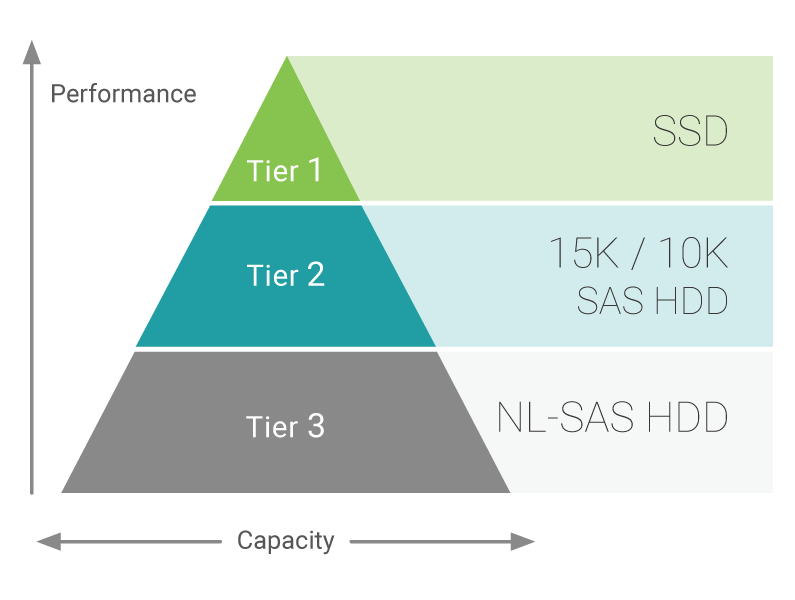
Les systèmes de stockage Qsan prennent en charge jusqu'à trois niveaux de stockage:
- Niveau 1: Performances maximales SSD
- Niveau 2: disque dur SAS 10K / 15K, hautes performances
- Niveau 3: HDD NL-SAS 7.2K, capacité maximale
Le pool de hiérarchisation automatique peut contenir les trois niveaux et seulement deux dans n'importe quelle combinaison. À l'intérieur de chaque niveau, les disques sont combinés en groupes RAID familiers. Pour une flexibilité maximale, le niveau RAID de chaque niveau peut être différent. Autrement dit, rien ne vous empêche d'organiser une structure comme 4x SSD RAID10 + 6x HDD 10K RAID5 + 12 HDD 7.2K RAID6
Après avoir créé des volumes (disques virtuels) dans le pool de hiérarchisation automatique , la collecte en arrière-plan de statistiques sur toutes les opérations d'E / S commence. Pour ce faire, l'espace est «découpé» en blocs de 1 Go (ce que l'on appelle le sous-LUN). Chaque fois que vous accédez à un tel bloc, un coefficient lui est attribué. Puis, au fil du temps, ce coefficient diminue. Après 24 heures, en l'absence de demandes d'entrée / sortie pour cet appareil, il sera déjà égal à 0,5 et continuera de baisser après chaque heure suivante.
À un certain moment (par défaut tous les jours à minuit), les résultats collectés sont classés par activité sous LUN en fonction de leurs coefficients. Sur cette base, il est décidé quels blocs se déplacer et dans quelle direction. Après quoi, en fait, il y a une délocalisation des données entre les niveaux.
Le système de stockage Qsan met parfaitement en œuvre le contrôle du processus de déchirement à l'aide d'une variété de paramètres, ce qui vous permettra de configurer de manière très flexible les performances finales de la matrice.
Pour déterminer l'emplacement initial des données et la direction prioritaire de leur mouvement, des stratégies sont utilisées qui sont définies séparément pour chaque volume:
- Auto Tiering - la politique par défaut, le placement initial et la direction des mouvements sont déterminés automatiquement, c.-à-d. Les données «chaudes» ont tendance à atteindre le niveau le plus élevé et les données «froides» diminuent. Le placement initial est sélectionné en fonction de l'espace disponible à chaque niveau. Mais vous devez comprendre que le système cherche principalement à maximiser l'utilisation des disques les plus rapides. Par conséquent, s'il y a de l'espace libre, les données seront placées aux niveaux supérieurs. Cette stratégie convient à la plupart des scénarios lorsque la demande de données ne peut pas être prédite à l'avance.
- Commencez haut, puis Auto Tiering - la différence par rapport à la précédente se trouve uniquement dans l'emplacement de données d'origine (au niveau le plus rapide)
- Le plus haut niveau - les données s'efforcent toujours d'occuper le niveau le plus rapide. Si dans le processus, ils sont déplacés vers le bas, alors dès que possible, ils sont reculés. Cette politique convient aux données qui nécessitent l'accès le plus rapide.
- Niveau minimum - les données s'efforcent toujours d'occuper le niveau le plus bas. Cette politique est parfaite pour les données rarement utilisées (par exemple, les archives).
- Aucun mouvement - le système détermine automatiquement l'emplacement initial des données et ne les déplace pas. Cependant, des statistiques continuent d'être collectées au cas où leur réinstallation serait ultérieurement nécessaire.
Il convient de noter qu'en dépit du fait que les politiques sont définies lors de la création de chaque volume, elles peuvent être modifiées à plusieurs reprises à la volée pendant le cycle de vie du système.
En plus des stratégies pour le mécanisme de déchirement, la fréquence et le rythme des mouvements de données entre les niveaux sont également configurés. Vous pouvez définir une heure de mouvement spécifique: quotidiennement ou certains jours de la semaine, ainsi que réduire l'intervalle de collecte des statistiques à plusieurs heures (la fréquence minimale est de 2 heures). S'il est nécessaire de limiter le temps d'exécution de l'opération de déplacement de données, vous pouvez définir le délai (fenêtre de déplacement). De plus, la vitesse de relocalisation est également indiquée - 3 modes: rapide, moyen, lent.
En cas de besoin de relocalisation immédiate des données, il est possible de l'exécuter en mode manuel à tout moment sur commande de l'administrateur.
Il est clair que plus les données seront déplacées entre les niveaux plus souvent et plus rapidement, plus le système de stockage s'adaptera aux conditions de fonctionnement actuelles. Mais en même temps, il convient de se rappeler que le déplacement est une charge supplémentaire (principalement sur les disques), donc absolument pas besoin de «piloter» les données sans besoin extrême. Il est préférable de planifier le mouvement pour des moments de charge minimale. Si le travail de stockage nécessite constamment de hautes performances 24h / 24 et 7j / 7, alors il vaut la peine de réduire le taux de relocalisation au minimum.
L'abondance des paramètres de déchirement plaira sans aucun doute aux utilisateurs avancés. Cependant, pour ceux qui sont confrontés à une telle technologie pour la première fois, il n'y a rien à craindre. Il est tout à fait possible de faire confiance aux paramètres par défaut (politique de hiérarchisation automatique, se déplaçant à une vitesse maximale une fois par jour la nuit) et, à mesure que les statistiques s'accumulent, d'ajuster certains paramètres pour obtenir le résultat souhaité.
En comparant le peering avec une technologie non moins populaire pour augmenter les performances comme la mise en cache SSD , il faut garder à l'esprit les différents principes de leurs algorithmes.
| Mise en cache SSD | Nivellement automatique |
|---|
| Taux de début d'effet | Presque instantanément. Mais un effet notable seulement après que le cache se "réchauffe" (minutes-heures) | Après avoir collecté des statistiques (à partir de 2 heures, idéalement une journée), plus le temps de déplacer les données |
| Durée de l'effet | Jusqu'à ce que les données soient remplacées par une nouvelle portion (minutes-heures) | Bien que la demande de données soit pertinente (jour ou plus) |
| Indications d'utilisation | Augmentez instantanément la productivité pendant une courte période (bases de données, environnements de virtualisation) | Productivité accrue sur une longue période (fichiers, web, serveurs de messagerie) |
En outre, l'une des caractéristiques de la déchirure est la possibilité de l'utiliser non seulement pour des scénarios comme «SSD + HDD», mais aussi «HDD rapide + HDD lent» ou les trois niveaux en général, ce qui est impossible en principe si la mise en cache SSD est utilisée.
Test
Pour tester le fonctionnement des algorithmes de déchirement, nous avons effectué un test simple. Un pool de deux niveaux de SSD (RAID 1) + HDD 7.2K (RAID1) a été créé, sur lequel le volume avec la politique de "niveau minimum" a été placé. C'est-à-dire les données doivent toujours se trouver sur des disques lents.
L'interface de contrôle montre clairement le placement des données entre les niveaux
Après avoir rempli le volume de données, nous avons modifié la politique de placement en Auto Tiering et exécuté le test IOmeter.
Après plusieurs heures de test, lorsque le système a pu accumuler des statistiques, le processus de relocalisation a commencé.
À la fin du mouvement des données, notre volume de test a complètement rampé jusqu'au niveau supérieur (SSD).
Le verdict
La hiérarchisation automatique est une merveilleuse technologie qui vous permet d'augmenter la productivité du système de stockage avec un minimum de coûts de matériel et de temps en raison de l'utilisation plus intensive des lecteurs haute vitesse. En ce qui concerne Qsan, le seul investissement est une licence, qui est acquise une fois pour toutes sans limitation de volume / nombre de disques / étagères / etc. Cette fonctionnalité est équipée de paramètres si riches qu'elle peut satisfaire presque toutes les tâches professionnelles. Et la visualisation des processus dans l'interface vous permettra de gérer efficacement l'appareil.