
Le 28 février, j'ai fait une présentation lors de la rencontre SphinxSearch , qui s'est tenue dans nos bureaux. Il a expliqué comment nous venions de la reconstruction régulière des index pour la recherche en texte intégral et l'envoi de mises à jour dans le code «en place» aux index horaires ferroviaires et la synchronisation automatique de l'état de l'index et de la base de données MariaDB. Un enregistrement vidéo de mon reportage est disponible via le lien , et pour ceux qui préfèrent lire plutôt que regarder la vidéo, j'ai écrit cet article.
Je vais commencer par la façon dont notre recherche a été organisée et pourquoi nous avons commencé tout cela.
Notre recherche a été organisée selon un schéma tout à fait standard.
Depuis le front-end, les demandes des utilisateurs arrivent sur le serveur d'applications écrites en PHP, et lui, à son tour, communique avec la base de données (nous avons MariaDB). Si nous devons effectuer une recherche, le serveur d'applications se tourne vers l'équilibreur (nous avons un haproxy), qui le connecte à l'un des serveurs sur lesquels searchd s'exécute, et ce serveur effectue déjà une recherche et renvoie le résultat.
Les données de la base de données entrent dans l'index d'une manière assez traditionnelle: selon le calendrier, nous reconstruisons l'index toutes les quelques minutes avec les documents qui ont été mis à jour relativement récemment, et reconstruisons l'index avec les documents dits «archivés» (c'est-à-dire ceux avec lesquels Pendant longtemps, rien ne s'est passé). Il y a quelques machines allouées pour l'indexation, un script y est exécuté selon un calendrier, qui construit d'abord l'index, puis renomme les fichiers d'index d'une manière spéciale, puis le place dans un dossier séparé. Et sur chacun des serveurs avec searchd, rsync est démarré une fois par minute, qui à partir de ce dossier copie les fichiers dans le dossier index searchd, puis, si quelque chose a été copié, il exécute la requête RELOAD INDEX.
Cependant, pour certains changements dans les curriculum vitae et les postes vacants, il était nécessaire qu'ils «atteignent» l'indice le plus tôt possible. Par exemple, si un poste vacant qui a été publié dans le domaine public est supprimé de la publication, il est raisonnable de s'attendre du point de vue de l'utilisateur qu'il disparaîtra du problème en quelques secondes, pas plus. Par conséquent, ces types de modifications sont envoyés directement via searchd à l'aide de requêtes UPDATE. Et pour que ces modifications soient appliquées à toutes les copies d'index sur tous nos serveurs, un index distribué est configuré sur chaque searchd, qui envoie des mises à jour d'attributs à toutes les instances de searchd. Le serveur d'applications se connecte toujours à l'équilibreur et envoie une demande de mise à jour de l'index distribué; ainsi, il n'a pas besoin de connaître à l'avance ni la liste des serveurs avec searchd, ni de savoir exactement à quel serveur avec searchd.
Tout cela a plutôt bien fonctionné, mais il y a eu des problèmes.
- Le délai moyen entre la création du document (nous avons ce curriculum vitae ou vacance) et son entrée dans l'index était directement proportionnel à leur nombre dans notre base de données.
- Puisque nous avons utilisé l'index distribué pour distribuer les mises à jour d'attributs, nous n'avions aucune garantie que ces mises à jour étaient appliquées à toutes les copies de l'index.
- Les modifications «urgentes» qui se sont produites lors de la reconstruction de l'index ont été perdues lorsque la commande
RELOAD INDEX été exécutée (simplement parce qu'elles n'étaient pas encore dans l'index nouvellement construit) et ne sont entrées dans l'index qu'après la prochaine réindexation. 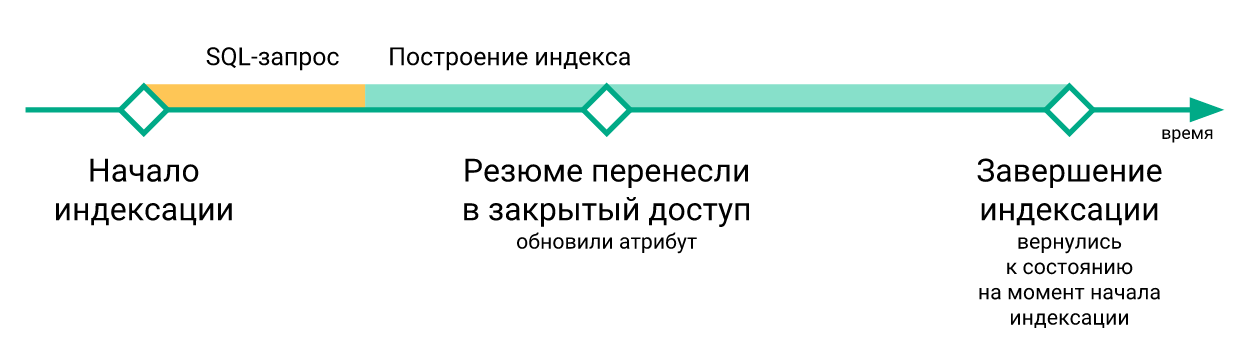
- Les scripts de mise à jour des index sur les serveurs avec searchd ont été exécutés indépendamment les uns des autres, il n'y avait pas de synchronisation entre eux. De ce fait, le délai entre la mise à jour de l'index sur différents serveurs peut atteindre plusieurs minutes.
- S'il était nécessaire de tester quelque chose lié à la recherche, il était nécessaire de reconstruire l'index après chaque modification.
Chacun de ces problèmes séparément ne valait pas une retouche cardinale de l'infrastructure de recherche, mais pris ensemble, ils ont gâché la vie de manière assez tangible.
Nous avons décidé de traiter les problèmes ci-dessus en utilisant des index en temps réel Sphinx. De plus, le passage aux indices RT ne nous a pas suffi. Afin de se débarrasser enfin de toute course aux données, il fallait s'assurer que toutes les mises à jour de l'application vers l'index passaient par le même canal. De plus, il était nécessaire de sauvegarder quelque part les modifications apportées à la base de données pendant la reconstruction de l'index (car après tout, il est parfois nécessaire de le reconstruire, mais la procédure n'est pas instantanée).
Nous avons décidé d'établir la connexion en utilisant le protocole de réplication MySQL comme un canal de transfert de données, et le binlog MySQL est l'endroit idéal pour enregistrer les modifications lors de la reconstruction de l'index. Cette solution nous a permis de nous débarrasser de l'écriture sur Sphinx à partir du code d'application. Et puisque nous avions déjà utilisé la réplication basée sur les lignes avec un identifiant de transaction global à ce moment-là, le basculement entre les répliques de base de données pouvait se faire tout simplement.
L'idée de se connecter directement à la base de données afin d'en obtenir des modifications pour les envoyer à l'index n'est bien sûr pas nouvelle: en 2016, des collègues d'Avito ont fait une présentation où ils ont décrit en détail comment ils ont résolu le problème de la synchronisation des données dans Sphinx avec la base de données principale. Nous avons décidé d'utiliser leur expérience et de créer un système similaire pour nous-mêmes, à la différence que nous n'avons pas PostgreSQL, mais MariaDB et l'ancienne branche Sphinx (à savoir, la version 2.3.2).
Nous avons fait un service qui s'abonne aux changements dans MariaDB et met à jour l'index dans Sphinx. Ses responsabilités sont les suivantes:
- connexion au serveur MariaDB via le protocole de réplication et réception d'événements du binlog;
- suivre la position actuelle du journal des transactions et le numéro de la dernière transaction terminée;
- filtrage des événements binlog;
- trouver quels documents doivent être ajoutés, supprimés ou mis à jour dans l'index, et pour les documents mis à jour - quels champs doivent être mis à jour;
- demande de données manquantes à MariaDB;
- génération et exécution de demandes de mise à jour d'index;
- reconstruire l'index si nécessaire.
Nous avons établi une connexion en utilisant le protocole de réplication en utilisant la bibliothèque go-mysql . Elle est chargée d'établir une connexion avec MariaDB, de lire les événements de réplication et de les transmettre à un gestionnaire. Ce gestionnaire démarre dans goroutine, qui est contrôlé par la bibliothèque, mais nous écrivons nous-mêmes le code du gestionnaire. Dans le code du gestionnaire, les événements sont vérifiés avec une liste de tables qui nous intéressent et les modifications apportées à ces tables sont envoyées pour traitement. Notre gestionnaire stocke également l'état des transactions. En effet, les événements du protocole de réplication sont en ordre: GTID (début de transaction) -> ROW (changement de données) -> XID (fin de transaction), et seul le premier d'entre eux contient des informations sur le numéro de transaction. Il est plus pratique pour nous de transférer le numéro de transaction avec son achèvement afin d'enregistrer des informations sur la position dans le binlog où les modifications ont été appliquées, et pour cela, nous devons nous souvenir du numéro de la transaction en cours entre son début et son achèvement.
MySQL [(none)]> describe sync_state; +-----------------+--------+ | Field | Type | +-----------------+--------+ | id | bigint | | dummy_field | field | | binlog_position | uint | | binlog_name | string | | gtid | string | | flavor | string | +-----------------+--------+
Nous enregistrons le numéro de la dernière transaction terminée dans un index spécial à partir d'un document sur chaque serveur avec searchd. Au début du service, nous vérifions que les index sont initialisés et ont la structure attendue, ainsi que la position enregistrée sur tous les serveurs est présente et la même sur tous les serveurs. Ensuite, si ces vérifications ont réussi et que nous avons pu commencer à lire le binlog à partir de la position enregistrée, nous commençons la procédure de synchronisation. Si les vérifications échouent, ou s'il n'a pas été possible de commencer la lecture du binlog à partir de la position enregistrée, nous réinitialisons la position enregistrée à la position actuelle du serveur MariaDB et reconstruisons l'index.
Le traitement des événements de réplication commence par déterminer quels documents sont affectés par un changement particulier dans la base de données. Pour ce faire, dans la configuration de notre service, nous avons fait quelque chose comme le routage des événements de changement de ligne dans les tables qui nous intéressent, c'est-à-dire un ensemble de règles pour déterminer comment les changements dans la base de données doivent être indexés.
[[ingest]] table = "vacancy" id_field = "id" index = "vacancy" [ingest.column_map] user_id = ["user_id"] edited_at = ["date_edited"] profession = ["profession"] latitude = ["latitude_deg", "latitude_rad"] longitude = ["longitude_deg", "longitude_rad"] [[ingest]] table = "vacancy_language" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] language_id = ["languages"] level = ["languages"] [[ingest]] table = "vacancy_metro_station" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] metro_station_id = ["metro"]
Par exemple, avec cet ensemble de règles, les modifications apportées aux vacancy_metro_station vacancy , vacancy_language et vacancy_metro_station doivent figurer dans l'index de vacancy . Le numéro de document peut être pris dans le champ id pour la table des vacancy et dans le champ vacancy_id pour les deux autres tables. Le champ column_map est une table de la dépendance des champs d'index sur les champs de différentes tables de base de données.
De plus, lorsque nous avons reçu la liste des documents concernés par les modifications, nous devons les mettre à jour dans l'index, mais pas immédiatement. Tout d'abord, nous accumulons les modifications pour chaque document et envoyons les modifications à l'index dès qu'un court laps de temps (nous avons 100 millisecondes) à partir de la dernière modification de ce document.
Nous avons décidé de le faire afin d'éviter de nombreuses mises à jour d'index inutiles, car dans de nombreux cas, une seule modification logique d'un document se produit à l'aide de plusieurs requêtes SQL qui affectent différentes tables et sont parfois exécutées dans des transactions complètement différentes.
Je vais donner un exemple simple. Supposons qu'un utilisateur ait modifié un poste vacant. Le code responsable de l'enregistrement des modifications est souvent écrit pour plus de simplicité de cette façon:
BEGIN; UPDATE vacancy SET edited_at = NOW() WHERE id = 123; DELETE FROM vacancy_language WHERE vacancy_id = 123; INSERT INTO vacancy_language (vacancy_id, language_id, level) VALUES (123, 1, "fluent"), (123, 2, "technical"); DELETE FROM vacancy_metro_station WHERE vacancy_id = 123; INSERT INTO vacancy_metro_station (vacancy_id, metro_station_id) VALUES (123, 55); ... COMMIT;
En d'autres termes, tous les anciens enregistrements sont d'abord supprimés des tables liées, puis de nouveaux sont insérés. Dans le même temps, il y aura toujours des entrées dans le binlog au sujet de ces suppressions et insertions, même si rien n'a changé dans le document.
Afin de ne mettre à jour que ce qui est nécessaire, nous avons fait ce qui suit: trier les lignes modifiées afin que pour chaque paire index-document, toutes les modifications puissent être récupérées dans l'ordre chronologique. Ensuite, nous pouvons les appliquer à leur tour pour déterminer quels champs dans lesquels les tables ont finalement changé et lesquels ne le sont pas, après quoi nous pouvons utiliser la table column_map obtenir une liste des champs et des attributs d'index qui doivent être mis à jour pour chaque document affecté. De plus, les événements liés à un document peuvent ne pas arriver l'un après l'autre, mais comme «différemment» s'ils sont exécutés dans des transactions différentes. Mais, sur notre capacité à déterminer quels documents ont changé, cela n'affectera pas.
Dans le même temps, cette approche nous a permis de mettre à jour uniquement les attributs de l'index, s'il n'y avait pas de modifications dans les champs de texte, ainsi que de combiner l'envoi de modifications à Sphinx.
Ainsi, nous pouvons maintenant découvrir quels documents doivent être mis à jour dans l'index.
Dans de nombreux cas, les données du binlog ne sont pas suffisantes pour générer une demande de mise à jour de l'index, nous obtenons donc les données manquantes du même serveur d'où nous lisons le binlog. Pour cela, il existe un modèle de demande de réception de données dans la configuration de notre service.
[data_source.vacancy] # # - id parts = 4 query = """ SELECT vacancy.id AS `:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """
Dans ce modèle, tous les champs sont marqués avec des alias spéciaux: [___]:___ .
Il est utilisé à la fois dans la formation d'une demande de réception des données manquantes et dans la construction de l'index (plus de détails plus loin).
Nous formons une demande de ce type:
SELECT vacancy.id AS `id`, vacancy.profession AS `profession_text`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id WHERE vacancy.id IN (< id , >) GROUP BY vacancy.id
Ensuite, pour chaque document, nous vérifions si c'est à la suite de cette demande. Sinon, cela signifie qu'il a été supprimé de la table principale et qu'il peut donc également être supprimé de l'index (nous exécutons la requête DELETE pour ce document). Si c'est le cas, voyez si nous devons mettre à jour les champs de texte pour ce document. Si les champs de texte n'ont pas besoin d'être mis à jour, nous effectuons une requête UPDATE pour ce document, sinon REPLACE .
Il convient de noter ici que la logique de maintien de la position à partir de laquelle vous pouvez commencer à lire le binlog en cas de défaillance devait être compliquée, car maintenant une situation est possible lorsque nous n'appliquons pas toutes les modifications lues dans le binlog.
Pour que la reprise de la lecture du binlog fonctionne correctement, nous avons fait ce qui suit: pour chaque événement de changement de ligne dans la base de données, souvenez-vous de l'id de la dernière transaction terminée au moment où cet événement s'est produit. Après avoir envoyé les modifications à Sphinx, nous mettons à jour le numéro de transaction à partir duquel vous pouvez commencer à lire en toute sécurité, comme suit. Si nous n'avons pas traité toutes les modifications accumulées (car certains documents n'ont pas été «suivis» dans la file d'attente), nous prenons le numéro de la transaction la plus ancienne parmi ceux liés aux modifications que nous n'avons pas encore réussi à appliquer. Et s'il arrivait que nous appliquions toutes les modifications accumulées, nous prenons simplement le numéro de la dernière transaction terminée.
Ce qui s'est passé en conséquence nous convenait, mais il y avait un autre point assez important: pour que les performances de l'index en temps réel restent à un niveau acceptable dans le temps, il était nécessaire que la taille et le nombre de «morceaux» de cet index restent faibles. Pour ce faire, Sphinx a une demande FLUSH RAMCHUNK , qui crée un nouveau bloc de disque, et une demande OPTIMIZE INDEX , qui fusionne tous les blocs de disque en un seul. Au départ, nous pensions que nous le ferions périodiquement et c'est tout. Mais, malheureusement, il s'est avéré que dans la version 2.3.2 OPTIMIZE INDEX ne fonctionne pas (à savoir, avec une probabilité assez élevée conduit à une baisse de la recherche). Par conséquent, nous avons décidé une seule fois par jour de reconstruire complètement l'index, d'autant plus que de temps en temps nous devons encore le faire (par exemple, si le schéma d'index ou les paramètres du tokenizer changent).
La procédure de reconstruction de l'index se déroule en plusieurs étapes.
Nous générons une configuration pour l'indexeur
Comme mentionné ci-dessus, il existe un modèle de requête SQL dans la configuration du service. Il est également utilisé pour former la configuration de l'indexeur.
Dans la configuration, il existe également d'autres paramètres nécessaires à la construction de l'index (paramètres du tokenizer, dictionnaires, diverses restrictions sur la consommation des ressources).
Enregistrer la position actuelle de MariaDB
À partir de cette position, nous commencerons la lecture du binlog, une fois que le nouvel index sera disponible sur tous les serveurs avec searchd.
Nous commençons l'indexeur
indexer --config tmp.vacancy.indexer.0.conf --all commandes du formulaire indexer --config tmp.vacancy.indexer.0.conf --all et attendons indexer --config tmp.vacancy.indexer.0.conf --all terminées. De plus, si l'indice est divisé en parties, alors nous commençons la construction de toutes les parties en parallèle.
Nous chargeons les fichiers d'index sur les serveurs
Le téléchargement sur chaque serveur se produit également en parallèle, mais nous attendons naturellement que tous les fichiers soient téléchargés sur tous les serveurs. Pour télécharger des fichiers dans la configuration du service, il y a une section avec un modèle de commande pour télécharger des fichiers.
[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative", "--times", "--delay-updates", ".", "rsync://<<.Host>>/index/vacancy/", ]
Pour chaque serveur, nous substituons simplement son nom dans la variable Host et exécutons la commande résultante. Nous utilisons rsync pour le téléchargement, mais en principe tout programme ou script qui accepte une liste de fichiers dans stdin et télécharge ces fichiers dans le dossier où searchd s'attend à voir les fichiers d'index fera l'affaire.
Nous arrêtons la synchronisation
On arrête de lire le binlog, on arrête le goroutine responsable de l'accumulation des changements.
Remplacez l'ancien index par un nouveau
Pour chaque serveur avec searchd, nous effectuons des requêtes séquentielles RELOAD INDEX vacancy_plain , TRUNCATE INDEX vacancy_plain , ATTACH INDEX vacancy_plain TO vacancy . Si l'index est divisé en parties, nous exécutons ces requêtes de manière séquentielle pour chaque partie. En même temps, si nous sommes dans un environnement de production, puis avant d'exécuter ces requêtes sur n'importe quel serveur, nous en supprimons la charge via l'équilibreur (afin que personne ne fasse de requêtes SELECT vers les index entre TRUNCATE et ATTACH ), et dès que la dernière requête ATTACH est terminée, nous renvoyons la charge à ce serveur.
Reprise de la synchronisation à partir d'une position enregistrée
Dès que nous remplaçons tous les index en temps réel par des index nouvellement construits, nous reprenons la lecture du binlog et synchronisons les événements du binlog, à partir de la position que nous avons enregistrée avant le début de l'indexation.
Voici un exemple de graphique du décalage de l'index du serveur MariaDB.

Ici, vous pouvez voir que bien que l'état de l'index après la reconstruction revienne dans le temps, cela se produit très brièvement.
Maintenant que tout est plus ou moins prêt, il est temps de sortir. Nous l'avons fait progressivement. Tout d'abord, nous avons versé un index en temps réel sur quelques serveurs, et le reste à l'époque fonctionnait de la même manière. Dans le même temps, la structure des index sur les «nouveaux» serveurs ne diffère pas des anciens, donc notre application PHP peut toujours se connecter à l'équilibreur sans se soucier de savoir si la requête sera traitée sur un index en temps réel ou sur un index simple.
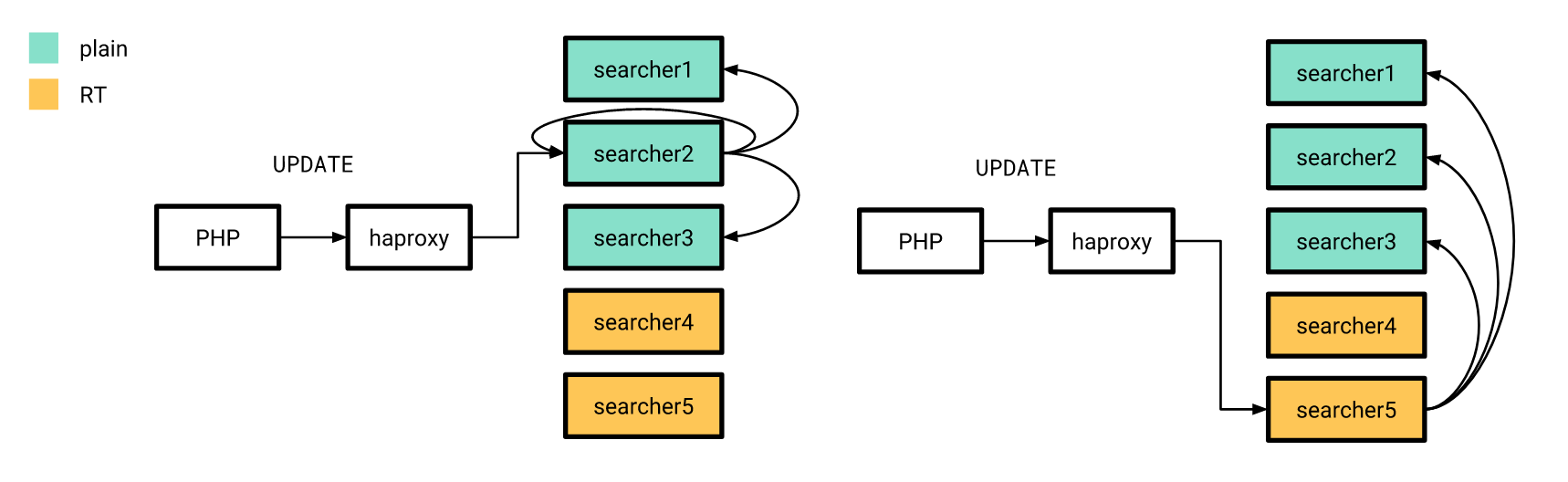
Les mises à jour d'attributs, dont j'ai parlé plus tôt, ont également été envoyées selon l'ancien schéma, à la différence que l'index distribué sur tous les serveurs a été configuré pour envoyer des requêtes UPDATE uniquement aux serveurs avec des index simples. De plus, si la demande UPDATE de l'application atteint le serveur avec des index en temps réel, elle ne remplit pas cette demande à la maison, mais l'envoie aux serveurs configurés à l'ancienne.
Après la publication, comme nous l'espérions, il s'est avéré réduire considérablement le délai entre la façon dont un curriculum vitae ou un poste vacant change dans la base de données et la façon dont les changements correspondants entrent dans l'index.
Après le passage à un index en temps réel, il n'était pas nécessaire de reconstruire l'index après chaque modification sur les serveurs de test. Ainsi, il est devenu possible d'écrire des autotests de bout en bout avec la participation de la recherche à peu de frais. Cependant, comme nous traitons les modifications du binlog de manière asynchrone (du point de vue des clients qui écrivent dans la base de données), nous avons dû permettre d'attendre que les modifications concernant le document participant à l'autotest soient traitées par notre service et envoyées à searchd .
Pour ce faire, nous avons créé un point de terminaison dans notre service, qui ne fait que cela, c'est-à-dire qu'il attend que toutes les modifications soient appliquées au numéro de transaction spécifié. Pour ce faire, immédiatement après avoir apporté les modifications nécessaires à la base de données, nous demandons à MariaDB @@gtid_current_pos et la transférons au point final de notre service. Si nous avons déjà appliqué toutes les transactions à ce poste à ce moment, le service répond immédiatement que nous pouvons continuer. Sinon, dans le goroutine responsable de l'application des modifications, nous créons un abonnement à ce GTID, et dès qu'il (ou celui qui le suit) est appliqué, nous permettons également au client de continuer l'autotest.
En code PHP, cela ressemble à ceci:
<?php declare(strict_types=1); use GuzzleHttp\ClientInterface; use GuzzleHttp\RequestOptions; use PDO; class RiverClient { private const REQUEST_METHOD = 'post'; /** * @var ClientInterface */ private $httpClient; public function __construct(ClientInterface $httpClient) { $this->httpClient = $httpClient; } public function waitForSync(PDO $mysqlConnection, PDO $sphinxConnection, string $riverAddr): void { $masterGTID = $mysqlConnection->query('SELECT @@gtid_current_pos')->fetchColumn(); $this->httpClient->request( self::REQUEST_METHOD, "http://{$riverAddr}/wait", [RequestOptions::FORM_PARAMS => ['gtid' => $masterGTID]] ); } }
Résultats
En conséquence, nous avons pu réduire considérablement le délai entre la mise à jour de MariaDB et de Sphinx.


Nous sommes également devenus beaucoup plus confiants que toutes les mises à jour atteignent tous nos serveurs Sphinx à temps.
De plus, les tests de recherche (manuels et automatiques) sont devenus beaucoup plus agréables.
Malheureusement, cela ne nous a pas été donné gratuitement: les performances de l'indice en temps réel par rapport à l'indice ordinaire se sont révélées légèrement moins bonnes.
La répartition du temps de traitement des requêtes de recherche en fonction du temps pour un index simple est indiquée ci-dessous.

Et voici le même graphique pour l'index en temps réel.

Vous pouvez voir que la part des demandes «rapides» a légèrement diminué, tandis que la part des demandes «lentes» a augmenté.
Au lieu d'une conclusion
Reste à dire que le code du service décrit dans cet article, nous l'avons posté dans le domaine public . Malheureusement, il n'y a pas encore de documentation détaillée, mais si vous le souhaitez, vous pouvez exécuter un exemple d'utilisation de ce service via docker-compose .
Les références
- Diapositives vidéo et rapport
- Reportage vidéo d'Andrey Smirnov et Vyacheslav Kryukov sur Highload ++
- Bibliothèque Go-mysql
- Code de service avec exemple d'utilisation