Aujourd'hui, la plupart des produits logiciels sont développés en équipes. Les conditions de réussite du développement d'une équipe peuvent être présentées sous la forme d'un schéma simple.
Après avoir écrit le code, vous devez vous assurer qu'il:
- Ça marche.
- Cela ne casse rien, y compris le code que vos collègues ont écrit.
Si les deux conditions sont remplies, vous êtes sur la voie du succès. Afin de vérifier facilement ces conditions et de ne pas fermer une voie rentable, ils ont proposé une intégration continue.
CI est un workflow dans lequel vous intégrez votre code dans le code produit général aussi souvent que possible. Et pas seulement intégrer, mais aussi vérifier en permanence que tout fonctionne. Étant donné que vous devez vérifier souvent et souvent, vous devriez penser à l'automatisation. Vous pouvez tout vérifier sur la traction manuelle, mais cela n'en vaut pas la peine, et c'est pourquoi.
- Les gens sont chers . Une heure de travail d'un programmeur coûte plus cher qu'une heure de travail d'un serveur.
- Les gens ont tort . Par conséquent, des situations peuvent survenir lorsqu'elles exécutent des tests sur la mauvaise branche ou collectent le mauvais commit pour les testeurs.
- Les gens sont paresseux . Périodiquement, lorsque je termine une tâche, j'ai la pensée: «Mais qu'y a-t-il à vérifier? J'ai écrit deux lignes - stopudovo tout fonctionne! » Je pense que pour certains d'entre vous, de telles pensées me viennent parfois à l'esprit. Mais vous devez toujours vérifier.
Comment Nikolaï Nesterov (
nnesterov ), participant à tous les changements évolutifs de l'application Android CI / CD, explique comment l'intégration continue a été introduite et développée dans l'équipe de développement mobile Avito, comment ils ont atteint 0 à 450 assemblages par jour et que les machines de construction collectent 200 heures par jour. .
L'histoire est construite sur l'exemple de l'équipe Android, mais la plupart des approches s'appliquent également sur iOS.
Il était une fois, une personne travaillait dans l'équipe Avito Android. Par définition, il n'avait besoin de rien de l'intégration continue: il n'y avait personne avec qui s'intégrer.
Mais l'application a grandi, de plus en plus de nouvelles tâches sont apparues, respectivement, l'équipe a grandi. À un moment donné, il était temps d'établir plus formellement le processus d'intégration du code. Il a été décidé d'utiliser Git flow.

Le concept de flux Git est connu: il existe une branche de développement commune dans le projet, et pour chaque nouvelle fonctionnalité, les développeurs coupent une branche distincte, la valident, la poussent, et lorsqu'ils veulent injecter leur code dans la branche de développement, ouvrent la demande de tirage. Pour partager les connaissances et discuter des approches, nous avons introduit une révision du code, c'est-à-dire que les collègues doivent vérifier et confirmer le code de chacun.
Chèques
Regarder le code avec vos yeux est cool, mais pas suffisant. Par conséquent, des contrôles automatiques sont introduits.
- Tout d'abord, nous vérifions le montage de l'ARC .
- Beaucoup de tests Junit .
- Nous considérons la couverture du code , car nous exécutons les tests.
Pour comprendre comment ces contrôles doivent être exécutés, regardons le processus de développement dans Avito.
Schématiquement, il peut être représenté comme suit:
- Le développeur écrit le code sur son ordinateur portable. Vous pouvez exécuter des vérifications d'intégration ici - avec un crochet de validation ou simplement exécuter des vérifications en arrière-plan.
- Une fois que le développeur a exécuté le code, il ouvre la demande d'extraction. Pour que son code entre dans la branche develop, vous devez passer par une revue de code et collecter le nombre requis de confirmations. Vous pouvez activer les vérifications et les builds ici: jusqu'à ce que toutes les builds réussissent, la demande de pull ne peut pas être fusionnée.
- Une fois la demande d'extraction fusionnée et le code en cours de développement, vous pouvez choisir un moment opportun: par exemple, la nuit, lorsque tous les serveurs sont libres, et effectuez les contrôles à votre guise.
Personne n'aimait faire des tests sur son ordinateur portable. Lorsque le développeur a terminé la fonctionnalité, il souhaite la lancer rapidement et ouvrir la demande d'extraction. Si à ce moment de longues vérifications sont lancées, ce n'est pas seulement très agréable, mais cela ralentit également le développement: pendant que l'ordinateur portable vérifie quelque chose, il est impossible de travailler normalement dessus.
Nous avons vraiment aimé faire des vérifications la nuit, car il y a beaucoup de temps et de serveurs, vous pouvez vous promener. Mais, malheureusement, lorsque le code de fonctionnalité est entré en développement, le développeur a déjà beaucoup moins de motivation pour réparer les erreurs trouvées par CI. Je me surprenais périodiquement à penser quand je regardais dans le rapport du matin sur toutes les erreurs trouvées que je les corrigerais un peu plus tard, car maintenant à Jira se trouve une nouvelle tâche cool que je veux juste commencer à faire.
Si les vérifications bloquent la demande d'extraction, la motivation est suffisante, car jusqu'à ce que les versions deviennent vertes, le code ne se développe pas, ce qui signifie que la tâche ne sera pas terminée.
En conséquence, nous avons choisi cette stratégie: la nuit, nous effectuons le maximum de contrôles possibles, les plus critiques d'entre eux et, surtout, rapidement, nous exécutons sur une demande de tirage. Mais nous ne nous arrêtons pas là - nous optimisons simultanément la vitesse de réussite des contrôles afin qu'ils passent du mode nuit aux contrôles sur demande de traction.
À cette époque, tous nos assemblages sont allés assez rapidement, nous avons donc simplement inclus l'assemblage ARC, les tests Junit et le calcul de la couverture de code avec le bloqueur de demande d'extraction. Ils l'ont allumé, y ont réfléchi et ont abandonné la couverture du code parce qu'ils pensaient que nous n'en avions pas besoin.
Il nous a fallu deux jours pour terminer la configuration de base du CI (ci-après, une estimation temporaire est approximative, nécessaire pour l'échelle).Après cela, ils ont commencé à réfléchir davantage - vérifions-nous correctement? Lançons-nous correctement les builds sur demande pull?
Nous avons commencé la construction sur le dernier commit de la branche avec laquelle la demande de tirage est ouverte. Mais la vérification de cette validation ne peut que montrer que le code que le développeur a écrit fonctionne. Mais ils ne prouvent pas qu'il n'a rien cassé. En fait, vous devez vérifier l'état de la branche de développement après que la fonctionnalité y a été injectée.
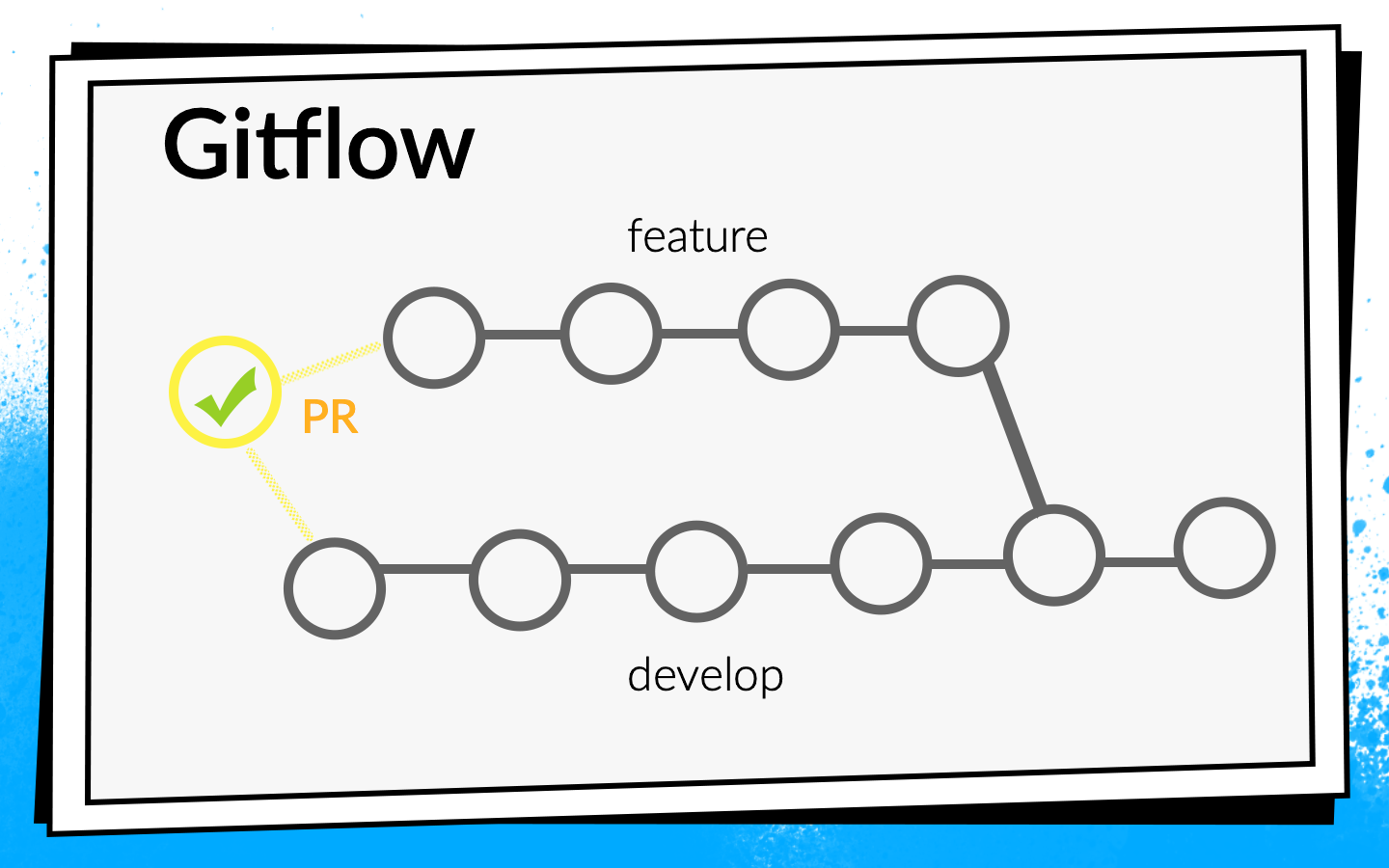
Pour ce faire, nous avons écrit un simple script bash
premerge.sh:
Ici, tous les derniers changements de develop sont simplement remontés et fusionnés dans la branche actuelle. Nous avons ajouté le script premerge.sh comme première étape de toutes les générations et avons commencé à vérifier exactement ce que nous voulons, à savoir l'
intégration .
Il a fallu trois jours pour localiser le problème, trouver une solution et écrire ce script.L'application s'est développée, de plus en plus de tâches sont apparues, l'équipe s'est agrandie et premerge.sh a parfois commencé à nous laisser tomber. En développement pénétrèrent des changements conflictuels qui brisèrent l'assemblée.
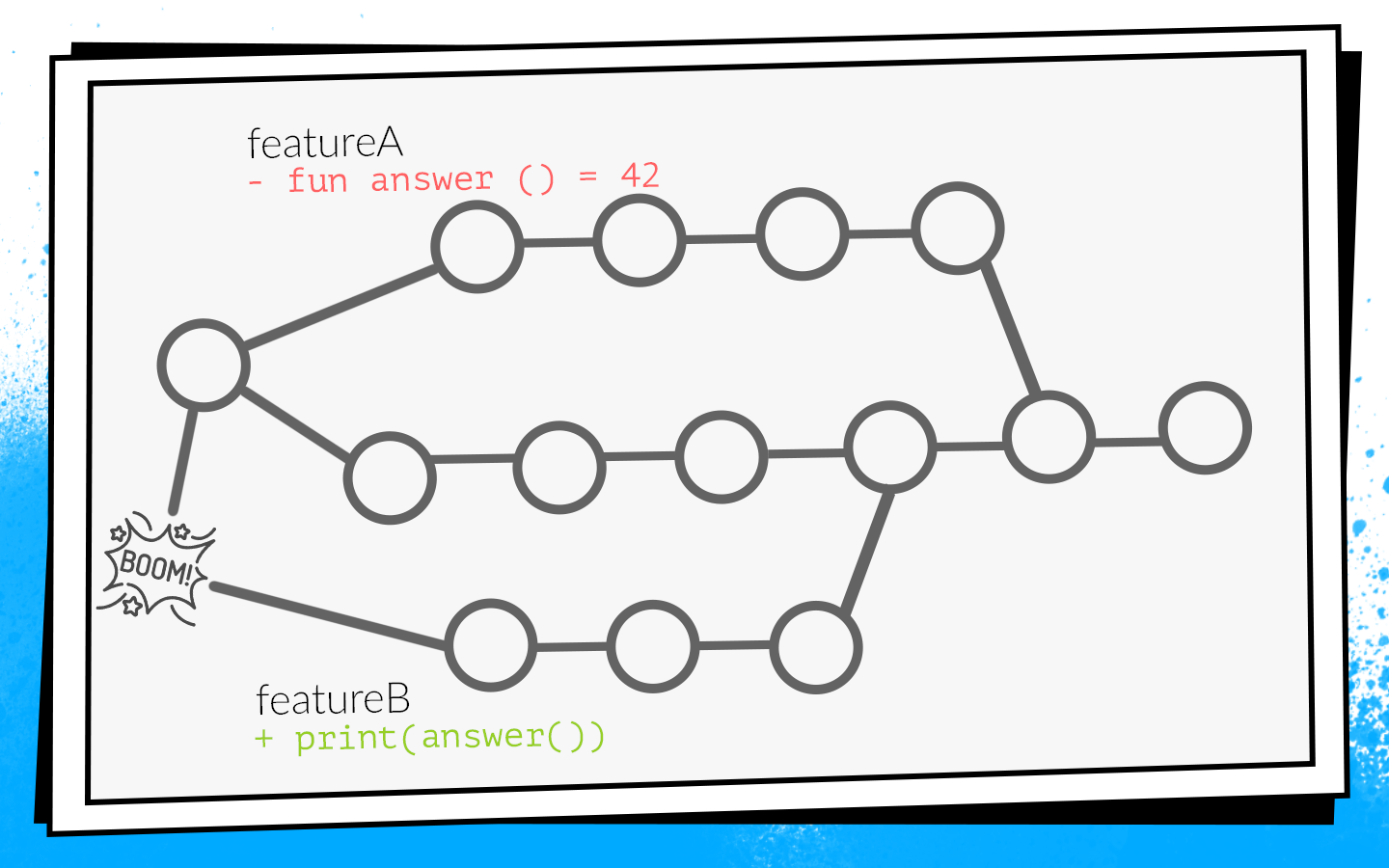
Un exemple de la façon dont cela se produit:

Deux développeurs commencent en même temps à scier les fonctionnalités A et B. Le développeur de la fonctionnalité A découvre la fonction
answer() inutilisée dans le projet et, comme un bon éclaireur, la supprime. Dans le même temps, le développeur de la fonctionnalité B ajoute un nouvel appel à cette fonction dans sa branche.
Les développeurs terminent le travail et en même temps ouvrent la demande de pull. Les builds démarrent, premerge.sh vérifie les deux requêtes pull pour un nouvel état de développement - toutes les vérifications sont vertes. Après que les fonctionnalités de demande de tirage A sont fusionnées, les fonctionnalités de demande de tirage B sont fusionnées ... Boom! Développer des pauses car dans le code de développement, il existe un appel à une fonction inexistante.
Lorsqu'il ne va pas se développer, c'est une
catastrophe locale . Toute l'équipe ne peut pas collecter et donner quoi que ce soit pour les tests.
Il se trouve que j'ai été le plus souvent impliqué dans des tâches d'infrastructure: analyse, réseau, bases de données. Autrement dit, j'ai écrit les fonctions et les classes que les autres développeurs utilisent. Pour cette raison, je me suis très souvent retrouvé dans de telles situations. J'ai même eu une telle photo en même temps.

Comme cela ne nous convenait pas, nous avons commencé à élaborer des options sur la façon de prévenir cela.
Comment ne pas casser le développement
Première option:
reconstruire toutes les demandes d'extraction lors du développement de la mise à niveau. Si, dans notre exemple, une demande d'extraction avec la fonctionnalité A commence par se développer, la demande d'extraction de la fonctionnalité B sera reconstruite et, en conséquence, les vérifications échoueront en raison d'une erreur de compilation.
Pour comprendre combien de temps cela prendra, considérons un exemple avec deux RP. Nous ouvrons deux PR: deux builds, deux lancements de tests. Une fois le premier PR versé dans le développement, le second doit être reconstruit. Au total, deux lancements de chèques PR nécessitent trois PR: 2 + 1 = 3.
En principe, c'est normal. Mais nous avons examiné les statistiques, et une situation typique dans notre équipe était de 10 RP ouverts, puis le nombre de contrôles est la somme de la progression: 10 + 9 + ... + 1 = 55. Autrement dit, pour accepter 10 RP, vous devez reconstruire 55 fois. Et c'est dans une situation idéale, lorsque tous les contrôles passent la première fois, lorsque personne n'ouvre une demande d'extraction supplémentaire pendant que ces dix sont en cours de traitement.
Imaginez-vous un développeur qui doit d'abord avoir le temps d'appuyer sur le bouton «fusionner», car si cela est fait par un voisin, vous devrez attendre jusqu'à ce que tous les assemblages recommencent ... Non, cela ne fonctionnera pas, cela ralentira sérieusement le développement.
La deuxième façon possible:
collecter la demande de tirage après la révision du code. Autrement dit, ouvrez la demande d'extraction, collectez le nombre de mises à jour nécessaires auprès de vos collègues, corrigez ce dont vous avez besoin, puis exécutez les versions. S'ils réussissent, la pull pull fusionne avec develop. Dans ce cas, il n'y a pas de redémarrage supplémentaire, mais le retour ralentit beaucoup. En tant que développeur, lorsque j'ouvre une demande de pull, je veux immédiatement voir s'il va le faire. Par exemple, si un test se bloque, vous devez le corriger rapidement. Dans le cas d'une construction retardée, le feedback ralentit, ce qui signifie tout le développement. Cela ne nous convenait pas non plus.
En conséquence, il ne restait que la troisième option - faire du
vélo . Tout notre code, toutes nos sources sont stockées dans le référentiel du serveur Bitbucket. En conséquence, nous avons dû développer un plugin pour Bitbucket.

Ce plugin remplace le mécanisme de fusion des demandes de tirage. Le début est standard: PR s'ouvre, tous les assemblages démarrent, la révision du code passe. Mais une fois la révision du code terminée et le développeur décidant de cliquer sur «fusionner», le plugin vérifie pour voir dans quel état les vérifications de développement ont été exécutées. Si, après les builds, développez réussi à mettre à jour, le plugin ne vous permettra pas de fusionner une telle requête pull dans la branche principale. Il redémarrera simplement les builds par rapport au nouveau développement.

Dans notre exemple avec des modifications conflictuelles, ces versions échoueront en raison d'une erreur de compilation. En conséquence, le développeur de la fonctionnalité B devra corriger le code, redémarrer les vérifications, puis le plugin appliquera automatiquement la demande de pull.
Avant d'implémenter ce plugin, nous avions en moyenne 2,7 tests par demande de pull. Avec le plugin, il y a eu 3,6 lancements. Cela nous convenait.
Il est à noter que ce plugin a un inconvénient: il ne redémarre la build qu'une seule fois. C'est-à-dire, de toute façon, une petite fenêtre reste à travers laquelle des changements conflictuels peuvent entrer dans se développer. Mais la probabilité de cela n'est pas élevée, et nous avons fait ce compromis entre le nombre de démarrages et la probabilité d'échec. Pendant deux ans, il n'a tourné qu'une seule fois, donc probablement pas en vain.
Il nous a fallu deux semaines pour écrire la première version du plugin pour Bitbucket.Nouveaux chèques
Pendant ce temps, notre équipe a continué de croître. De nouveaux chèques ont été ajoutés.
Nous avons pensé: pourquoi réparer les erreurs si elles peuvent être évitées? Et ils ont donc introduit
l'analyse de code statique . Nous avons commencé avec lint, qui est inclus dans le SDK Android. Mais à cette époque, il ne savait pas du tout comment travailler avec le code Kotlin, et nous avons déjà 75% de l'application écrite en Kotlin. Par conséquent,
les vérifications intégrées d'
Android Studio ont été ajoutées aux peluches
.Pour ce faire, je devais être très pervers: prendre Android Studio, l'emballer dans Docker et l'exécuter sur CI avec un moniteur virtuel pour qu'il pense qu'il fonctionnait sur un vrai ordinateur portable. Mais ça a marché.
Toujours à cette époque, nous avons commencé à écrire de nombreux
tests d'instrumentation et à mettre en œuvre des
tests de capture d'écran . C'est quand une capture d'écran de référence est générée pour une petite vue séparée, et le test est qu'une capture d'écran est prise de la vue et comparée directement avec la référence pixel par pixel. S'il y a un écart, cela signifie qu'une mise en page est partie quelque part ou que quelque chose ne va pas dans les styles.
Mais les tests d'instrumentation et les tests de capture d'écran doivent être exécutés sur des appareils: sur des émulateurs ou sur des appareils réels. Étant donné qu'il existe de nombreux tests et qu'ils poursuivent souvent, vous avez besoin d'une ferme entière. Pour démarrer votre propre ferme est trop laborieux, nous avons donc trouvé une option prête à l'emploi - Firebase Test Lab.
Laboratoire de test Firebase
Il a été choisi parce que Firebase est un produit Google, c'est-à-dire qu'il doit être fiable et ne mourra probablement jamais. Les prix sont abordables: 5 $ de l'heure pour un vrai appareil, 1 $ de l'heure pour un émulateur.
Il a fallu environ trois semaines pour mettre en œuvre le Firebase Test Lab dans notre CI.Mais l'équipe a continué de grandir et Firebase, malheureusement, a commencé à nous laisser tomber. A cette époque, il n'avait pas de SLA. Parfois, Firebase nous faisait attendre que le nombre requis d'appareils pour les tests devienne gratuit et ne commençait pas à les exécuter tout de suite, comme nous le voulions. L'attente en ligne a pris jusqu'à une demi-heure, et c'est très long. Les tests d'instrumentation ont fonctionné à chaque PR, les retards ont beaucoup ralenti le développement, puis une facture mensuelle est venue avec un montant rond. En général, il a été décidé d'abandonner Firebase et de voir en interne, puisque l'équipe s'est suffisamment développée.
Docker + python + bash
Nous avons pris docker, rempli d'émulateurs, écrit un programme Python simple qui, au bon moment, augmente le bon nombre d'émulateurs dans la bonne version et les arrête lorsque cela est nécessaire. Et, bien sûr, quelques scripts bash - où sans eux?
Il a fallu cinq semaines pour créer notre propre environnement de test.Par conséquent, chaque demande d'extraction comportait une liste de vérifications de fusion complète et bloquante:
- Assemblée de l'ARC;
- Tests Junit
- Lint;
- Chèques Android Studio;
- Tests d'instrumentation;
- Tests de capture d'écran.
Cela a empêché de nombreuses pannes possibles. Techniquement, tout a fonctionné, mais les développeurs se sont plaints que l'attente des résultats était trop longue.
Trop longtemps, c'est combien? Nous avons téléchargé les données de Bitbucket et TeamCity vers le système d'analyse et nous avons réalisé que le
temps d'attente moyen était de 45 minutes . Autrement dit, un développeur, ouvrant une demande d'extraction, s'attend en moyenne à des résultats de construction de 45 minutes. À mon avis, c'est beaucoup et vous ne pouvez pas travailler comme ça.
Bien sûr, nous avons décidé d'accélérer toutes nos versions.
Accélérez
Étant donné que les versions sont souvent alignées, la première chose que nous avons
achetée est le fer - un développement approfondi est le plus simple. Les builds ont cessé de faire la queue, mais le temps d'attente n'a diminué que légèrement, car certains chèques à eux seuls étaient en déroute depuis très longtemps.
Nous supprimons les chèques trop longs
Notre intégration continue pourrait détecter ces types d'erreurs et de problèmes.
- Je ne vais pas . CI peut détecter une erreur de compilation lorsque, en raison de modifications contradictoires, quelque chose ne va pas. Comme je l'ai dit, alors personne ne peut rien collecter, le développement augmente et tout le monde devient nerveux.
- Un bug de comportement . Par exemple, lorsque l'application est créée, mais lorsque vous cliquez sur le bouton, elle se bloque ou le bouton n'est pas appuyé du tout. C'est mauvais car un tel bug peut atteindre l'utilisateur.
- Bug dans la mise en page . Par exemple, un bouton est enfoncé, mais déplacé de 10 pixels vers la gauche.
- Augmentation de la dette technique .
En regardant cette liste, nous avons réalisé que seuls les deux premiers points sont critiques. Nous voulons d'abord attraper de tels problèmes. Les bogues dans la mise en page sont détectés au stade de la révision de la conception, puis facilement corrigés. Travailler avec la dette technique nécessite un processus et une planification distincts, nous avons donc décidé de ne pas vérifier la demande de pull.
Sur la base de cette classification, nous avons secoué toute la liste des chèques.
Biffé Lint et reporté son lancement pour la nuit: juste pour qu'il fasse état du nombre de problèmes dans le projet. Nous avons accepté de travailler séparément avec la dette technique, mais nous avons
complètement refusé les contrôles Android Studio . Android Studio de Docker pour lancer des inspections semble intéressant, mais il apporte beaucoup de problèmes de support. Toute mise à jour des versions d'Android Studio est un combat contre les bugs obscurs. Il était également difficile de maintenir les tests de capture d'écran, car la bibliothèque ne fonctionnait pas de manière très stable, il y avait des faux positifs.
Les tests de capture d'écran ont été supprimés de la liste des vérifications .
En conséquence, nous avons laissé:
- Assemblée de l'ARC;
- Tests Junit
- Tests d'instrumentation.
Cache distant Gradle
Sans de lourds contrôles, les choses se sont améliorées. Mais il n'y a pas de limite à la perfection!
Notre application a déjà été divisée en environ 150 modules gradle. Habituellement, dans ce cas, le cache distant Gradle fonctionne bien, et nous avons décidé de l'essayer.
Le cache distant Gradle est un service qui peut mettre en cache des artefacts de construction pour des tâches individuelles dans des modules distincts. Gradle, au lieu de réellement compiler le code, renverse le cache distant via HTTP et demande si quelqu'un a déjà effectué cette tâche. Si oui, téléchargez simplement le résultat.
Le démarrage du cache distant Gradle est facile car Gradle fournit une image Docker. Nous avons réussi à le faire en trois heures.Il suffisait de lancer Docker et d'enregistrer une ligne dans le projet. Mais bien que vous puissiez le démarrer rapidement pour que tout fonctionne bien, cela prendra beaucoup de temps.
Voici un graphique des échecs de cache.

Au tout début, le pourcentage de ratés après le cache était d'environ 65. Trois semaines plus tard, nous avons réussi à porter cette valeur à 20%. Il s'est avéré que les tâches collectées par l'application Android ont d'étranges dépendances transitoires, à cause desquelles Gradle a raté le cache.
En connectant le cache, nous avons considérablement accéléré l'assemblage. Mais en dehors de l'assemblage, les tests d'instrumentation sont toujours à la poursuite, et ils la poursuivent depuis longtemps. Peut-être que tous les tests ne doivent pas être poursuivis pour chaque demande d'extraction. Pour le savoir, nous utilisons l'analyse d'impact.
Analyse d'impact
Sur demande pull, nous construisons git diff et trouvons les modules Gradle modifiés.

Il est logique d'exécuter uniquement les tests d'instrumentation qui testent les modules modifiés et tous les modules qui en dépendent. Il ne sert à rien d'exécuter des tests pour les modules voisins: le code n'y a pas changé et rien ne peut casser.
Les tests d'instrumentation ne sont pas si simples, car ils doivent être situés dans le module d'application de niveau supérieur. Nous avons appliqué une heuristique d'analyse de bytecode pour comprendre à quel module chaque test appartient.
Il a fallu environ huit semaines pour mettre à niveau les tests d'instrumentation afin de tester uniquement les modules impliqués.Les mesures d'accélération de la vérification ont fonctionné avec succès. De 45 minutes, nous avons atteint environ 15. Un quart d'heure pour attendre la construction est déjà normal.
Mais maintenant, les développeurs ont commencé à se plaindre qu'il ne leur est pas clair quelles versions sont lancées, où le journal se penchera, pourquoi la construction est rouge, quel test est tombé, etc.
Les problèmes de feedback ralentissent le développement, nous avons donc essayé de fournir les informations les plus compréhensibles et détaillées sur chaque PR et build. Nous avons commencé par des commentaires sur Bitbucket pour PR, indiquant quelle version est tombée et pourquoi, avons écrit des messages ciblés dans Slack. En fin de compte, ils ont créé un tableau de bord pour la page PR avec une liste de toutes les versions en cours d'exécution et leur état: en ligne, démarrages, plantages ou fins. Vous pouvez cliquer sur la construction et accéder à son journal.
 Six semaines ont été consacrées à des commentaires détaillés.
Six semaines ont été consacrées à des commentaires détaillés.Plans
Nous passons à la dernière histoire. Après avoir résolu la question du feedback, nous sommes passés à un nouveau niveau - nous avons décidé de construire notre propre ferme d'émulateurs. Lorsqu'il existe de nombreux tests et émulateurs, ils sont difficiles à gérer. En conséquence, tous nos émulateurs sont passés à un cluster k8s avec une gestion flexible des ressources.
De plus, il existe d'autres plans.
- Retour Lint (et autres analyses statiques). Nous travaillons déjà dans ce sens.
- Exécutez tous les tests de bout en bout sur le bloqueur de relations publiques sur toutes les versions du SDK.
Nous avons donc retracé l'histoire du développement de l'intégration continue dans Avito. Maintenant, je veux donner quelques conseils du point de vue de l'expérimenté.
Astuces
Si je pouvais donner un seul conseil, ce serait ceci:
Veuillez faire attention aux scripts shell!
Bash est un outil très flexible et puissant, il est très pratique et rapide d'y écrire des scripts. Mais avec lui, vous pouvez tomber dans le piège et nous y sommes malheureusement tombés.
Tout a commencé avec des scripts simples qui s'exécutaient sur nos machines de génération:
Mais, comme vous le savez, tout se développe et se complique avec le temps - exécutons un script à partir d'un autre, passons-y quelques paramètres - à la fin, j'ai dû écrire une fonction qui détermine à quel niveau de bash d'imbrication nous sommes maintenant pour remplacer les guillemets nécessaires, pour que tout commence.

Vous pouvez imaginer le travail impliqué dans le développement de tels scripts. Je vous conseille de ne pas tomber dans ce piège.
Que peut-on remplacer?
- Tout langage de script. L'écriture en Python ou Kotlin Script est plus pratique car c'est de la programmation, pas des scripts.
- Ou décrivez toute la logique de construction sous la forme de tâches Gradle personnalisées pour votre projet.
Nous avons décidé de choisir la deuxième option, et maintenant nous supprimons systématiquement tous les scripts bash et écrivons beaucoup de shuffles gradle personnalisés.
Astuce n ° 2: conservez votre infrastructure dans le code.Cela est pratique lorsque la configuration d'intégration continue n'est pas stockée dans l'interface Jenkins ou TeamCity UI, etc., mais sous forme de fichiers texte directement dans le référentiel du projet. Cela donne la possibilité de version. Il ne sera pas difficile de revenir en arrière ou de collecter du code sur une autre branche.
Les scripts peuvent être stockés dans le projet. Et que faire de l'environnement?
Conseil n ° 3: Docker peut vous aider avec l'environnement.Cela aidera certainement les développeurs Android, iOS pas encore, malheureusement.
Voici un exemple de fichier docker simple contenant jdk et android-sdk:
FROM openjdk:8 ENV SDK_URL="https://dl.google.com/android/repository/sdk-tools-linux-3859397.zip" \ ANDROID_HOME="/usr/local/android-sdk" \ ANDROID_VERSION=26 \ ANDROID_BUILD_TOOLS_VERSION=26.0.2 # Download Android SDK RUN mkdir "$ANDROID_HOME" .android \ && cd "$ANDROID_HOME" \ && curl -o sdk.zip $SDK_URL \ && unzip sdk.zip \ && rm sdk.zip \ && yes | $ANDROID_HOME/tools/bin/sdkmanager --licenses # Install Android Build Tool and Libraries RUN $ANDROID_HOME/tools/bin/sdkmanager --update RUN $ANDROID_HOME/tools/bin/sdkmanager "build-tools;${ANDROID_BUILD_TOOLS_VERSION}" \ "platforms;android-${ANDROID_VERSION}" \ "platform-tools" RUN mkdir /application WORKDIR /application
Après avoir écrit ce fichier docker (je vais vous dire un secret, vous ne pouvez pas l'écrire, mais le tirer prêt de GitHub) et collecter l'image, vous obtenez une machine virtuelle sur laquelle vous pouvez créer l'application et exécuter des tests Junit.
Les deux principaux arguments expliquant pourquoi cela a du sens sont l'évolutivité et la répétabilité. En utilisant docker, vous pouvez rapidement lever une douzaine d'agents de build qui auront exactement le même environnement que l'ancien. Cela facilite la vie des ingénieurs CI. Pousser android-sdk dans docker est assez simple, avec des émulateurs un peu plus compliqués: vous devez travailler un peu (enfin, ou télécharger à nouveau le fichier fini depuis GitHub).
Astuce numéro 4: n'oubliez pas que les contrôles sont effectués non pas pour le plaisir des chèques, mais pour les personnes.Un retour rapide et, surtout, clair est très important pour les développeurs: ce qu'ils ont cassé, quel test est tombé, où le journal de construction.
Conseil n ° 5: Soyez pragmatique avec l'intégration continue.Comprenez clairement quels types d'erreurs vous souhaitez éviter, combien vous êtes prêt à dépenser en ressources, en temps, en temps d'ordinateur. Des contrôles trop longs peuvent, par exemple, être reprogrammés du jour au lendemain. Et ceux qui commettent des erreurs peu importantes devraient être complètement abandonnés.
Astuce numéro 6: utilisez des outils prêts à l'emploi.Maintenant, il existe de nombreuses entreprises qui fournissent des CI de cloud.

Pour les petites équipes, c'est une bonne issue. Vous n'avez rien à entretenir, payez simplement de l'argent, récupérez votre application et même effectuez des tests d'instrumentation.
Conseil n ° 7: dans une grande équipe, les solutions internes sont plus rentables.Mais tôt ou tard, avec la croissance de l'équipe, les solutions internes deviendront plus rentables. Il y a un point avec ces décisions. En économie, il existe une loi des rendements décroissants: dans tout projet, chaque amélioration ultérieure est de plus en plus difficile, nécessite de plus en plus d'investissement.
L'économie décrit toute notre vie, y compris l'intégration continue. J'ai construit un horaire de travail pour chaque étape de notre développement d'intégration continue.

On voit que toute amélioration est de plus en plus difficile. En regardant ce graphique, nous pouvons comprendre que le développement de l'intégration continue doit être cohérent avec la croissance de la taille de l'équipe. Pour une équipe de deux personnes, passer 50 jours à développer une batterie d'émulateurs internes est une idée insensée. Mais en même temps, pour une grande équipe, ne pas faire du tout d'intégration continue est également une mauvaise idée, en raison de problèmes d'intégration, de correction des communications, etc. cela prendra encore plus de temps.
Nous avons commencé avec le fait que l'automatisation est nécessaire parce que les gens sont chers, ils se trompent et sont paresseux. Mais les gens automatisent aussi. Par conséquent, tous ces mêmes problèmes s'appliquent à l'automatisation.
- L'automatisation coûte cher. N'oubliez pas l'horaire de travail.
- Dans l'automatisation, les gens font des erreurs.
- L'automatisation est parfois très paresseuse, car tout fonctionne comme ça. Sinon, pourquoi améliorer, pourquoi toute cette intégration continue?
: 20% . , . , , , - , develop, . , , - .
Continuous Integration. ., , AppsConf . . 22-23 .