
Comment changer l'architecture d'un produit monolithique afin d'accélérer son développement, et comment diviser une équipe en plusieurs, tout en conservant la cohérence du travail? Pour nous, la réponse à ces questions a été la création d'une nouvelle API. Sous la coupe, vous trouverez une histoire détaillée sur le chemin vers une telle solution et un aperçu des technologies sélectionnées, mais pour commencer - une petite digression.
Il y a quelques années, j'ai lu dans un article scientifique que de plus en plus de temps est nécessaire pour une formation à part entière, et dans un proche avenir, il faudra quatre-vingts ans pour acquérir des connaissances. Apparemment, en informatique, cet avenir est déjà venu.
J'ai eu la chance de commencer la programmation pendant ces années où il n'y avait pas de division en programmeurs principaux et frontaux, lorsque les mots «prototype», «ingénieur produit», «UX» et «QA» ne sonnaient pas. Le monde était plus simple, les arbres étaient plus grands et plus verts, l'air était plus pur et les enfants jouaient dans les cours, au lieu de garer les voitures. Peu importe comment je veux revenir à ce moment-là, je dois admettre que tout cela n'est pas l'intention du supervillain, mais le développement évolutif de la société. Oui, la société pourrait évoluer différemment, mais, comme vous le savez, l'histoire ne tolère pas l'humeur subjonctive.
Contexte
BILLmanager est apparu juste au moment où il n'y avait pas de séparation rigide des directions. Il avait une architecture cohérente, était capable de contrôler le comportement des utilisateurs et il pouvait même être étendu avec des plugins. Le temps a passé, l'équipe a développé le produit, et tout semblait aller bien, mais des phénomènes étranges ont commencé à être observés. Par exemple, lorsqu'un programmeur était engagé dans la logique métier, il a commencé à mal créer des formulaires, ce qui les rend peu pratiques et difficiles à comprendre. Ou l'ajout de fonctionnalités apparemment simples a pris plusieurs semaines: architecturalement, les modules étaient étroitement couplés, donc lors du changement de l'un, l'autre devait être ajusté.
La commodité, l'ergonomie et le développement global de produits en général peuvent être oubliés lorsque l'application plante avec une erreur inconnue. Si auparavant un programmeur avait réussi à travailler dans des directions différentes, alors avec la croissance du produit et ses exigences, cela devenait impossible. Le développeur a vu toute l'image et a compris que si la fonction ne fonctionne pas correctement et de manière stable, les formulaires, les boutons, les tests et la promotion ne seront pas utiles. Par conséquent, il a tout remis et s'est assis pour corriger l'erreur malheureuse. Il a fait son petit exploit, qui n'a été apprécié par personne (il n'y avait tout simplement plus de force pour une livraison correcte au client), mais la fonction a commencé à fonctionner. En fait, pour que ces petits exploits atteignent les clients, l'équipe comprendra des personnes responsables de différents domaines: frontend et backend, tests, conception, support, promotion.
Mais ce n'était que la première étape. L'équipe a changé et l'architecture du produit est restée étroitement couplée techniquement. Pour cette raison, il n'a pas été possible de développer l'application au rythme requis; lors du changement d'interface, la logique du backend a dû être modifiée, bien que la structure des données elle-même soit souvent restée inchangée. Il fallait faire quelque chose avec tout ça.
Frontend et backend
Devenir un professionnel dans tout est long et coûteux, donc le monde moderne des programmeurs appliqués est divisé, pour la plupart, en un front-end et un back-end.
Tout semble clair ici: nous recrutons des programmeurs front-end, ils seront responsables de l'interface utilisateur, et le backend pourra enfin se concentrer sur la logique métier, les modèles de données et autres capots moteur. Dans le même temps, le backend, le frontend, les testeurs et les concepteurs resteront dans une même équipe (car ils fabriquent un produit commun, ils se concentrent simplement sur différentes parties de celui-ci). Faire partie d'une équipe signifie avoir un espace informatif et, de préférence, territorial; discuter de nouvelles fonctionnalités ensemble et démonter celles qui sont terminées; coordonner le travail sur une grande tâche.
Pour certains nouveaux projets abstraits, cela suffira, mais nous avions déjà écrit la candidature, et les volumes des travaux prévus et le calendrier de leur mise en œuvre indiquaient clairement qu'une équipe ne pouvait pas le faire. Il y a cinq personnes dans l'équipe de basket-ball, 11 dans l'équipe de football, et nous en avions environ 30. Cela ne convenait pas à l'équipe de mêlée parfaite de cinq à neuf personnes. Il fallait diviser, mais comment maintenir la cohérence? Pour bouger, il fallait résoudre les problèmes architecturaux et organisationnels.

"Nous ferons tout en un seul projet, ce sera plus pratique", ont-ils déclaré ...
L'architecture
Lorsqu'un produit est obsolète, il semble logique de l'abandonner et d'en écrire un nouveau. C'est une bonne décision si vous pouvez prédire l'heure et elle conviendra à tout le monde. Mais dans notre cas, même dans des conditions idéales, le développement d'un nouveau produit prendrait des années. De plus, les spécificités de l'application sont telles qu'il serait extrêmement difficile de passer de l'ancien au nouveau avec toute leur différence. La compatibilité descendante est très importante pour nos clients, et si elle n’existe pas, ils refuseront de passer à la nouvelle version. La possibilité de développer à partir de zéro dans ce cas est douteuse. Par conséquent, nous avons décidé de mettre à niveau l'architecture du produit existant tout en maintenant une compatibilité descendante maximale.
Notre application est un monolithe dont l'interface a été construite côté serveur. Le frontend n'a implémenté que les instructions reçues. En d'autres termes, le backend n'était pas responsable de l'interface utilisateur . Sur le plan architectural, le front-end et le back-end fonctionnaient comme un, donc, en changeant l'un, nous avons été obligés de changer l'autre. Et ce n'est pas la pire chose, ce qui est bien pire - il était impossible de développer une interface utilisateur sans une connaissance approfondie de ce qui se passe sur le serveur.
Il était nécessaire de séparer le front-end et le back-end, pour créer des applications logicielles distinctes: la seule façon de commencer à les développer était au rythme et au volume requis. Mais comment faire deux projets en parallèle, changer de structure s'ils sont très dépendants l'un de l'autre?
La solution était un système supplémentaire - une couche . L'idée de l'intercalaire est extrêmement simple: elle doit coordonner le travail du backend et du frontend et assumer tous les coûts supplémentaires. Par exemple, pour que lorsque la fonction de paiement est décomposée du côté backend, la couche combine les données et du côté frontal, rien ne doit être changé; ou de sorte que pour la conclusion au tableau de bord de tous les services commandés par l'utilisateur, nous ne faisons pas de fonction supplémentaire sur le backend, mais agrégons les données dans la couche.
En plus de cela, la couche devait ajouter une certitude à ce qui peut être appelé depuis le serveur et qui reviendra éventuellement. Je voulais que la demande d'opérations soit possible sans connaître la structure interne des fonctions qui les exécutent.

Stabilité accrue en divisant les domaines de responsabilité.
Les communications
En raison de la forte dépendance entre le frontend et le backend, il était impossible de faire le travail en parallèle, ce qui ralentissait les deux parties de l'équipe. Divisant par programme un grand projet en plusieurs, nous avons eu la liberté d'action dans chacun, mais en même temps, nous devions maintenir la cohérence du travail.
Quelqu'un dira que la cohérence est obtenue en améliorant les compétences générales. Oui, ils doivent être développés, mais ce n'est pas une panacée. Regardez le trafic, il est également important que les conducteurs soient polis, sachent éviter les obstacles aléatoires et s'entraident dans les situations difficiles. Mais! Sans règles de circulation, même avec les meilleures communications, nous aurions des accidents à chaque intersection et le risque de ne pas arriver à temps à l'endroit.
Nous avions besoin de règles difficiles à enfreindre. Comme on dit, pour faciliter la mise en conformité plutôt que la violation. Mais la mise en œuvre de toute loi comporte non seulement des avantages, mais aussi des frais généraux, et nous ne voulions vraiment pas ralentir le travail principal, entraînant tout le monde dans le processus. Nous avons donc créé un groupe de coordination, puis une équipe dont l'objectif était de créer les conditions d'un développement réussi des différentes parties du produit. Elle a mis en place les interfaces permettant à différents projets de fonctionner dans leur ensemble - les règles mêmes qui sont plus faciles à suivre qu'à enfreindre.
Nous appelons cette commande «API», bien que la mise en œuvre technique de la nouvelle API ne représente qu'une petite partie de ses tâches. Comme les sections communes de code sont placées dans une fonction distincte, l'équipe API analyse les problèmes généraux des équipes produit. C'est là que la connexion de notre frontend et de notre backend a lieu, donc les membres de cette équipe doivent comprendre les spécificités de chaque direction.
Peut-être que l '«API» n'est pas le nom le plus approprié pour l'équipe, quelque chose sur l'architecture ou la vision à grande échelle serait plus approprié, mais, je pense, cette bagatelle ne change pas l'essence.
API
L'interface d'accès aux fonctions sur le serveur existait dans notre application initiale, mais elle semblait chaotique pour le consommateur. La séparation du frontend et du backend nécessitait plus de certitude.
Les objectifs de la nouvelle API sont nés des difficultés quotidiennes de mise en œuvre de nouvelles idées de produits et de conception. Nous avions besoin de:
- Faible connectivité des composants du système afin que le backend et le frontend puissent être développés en parallèle.
- Haute évolutivité pour que la nouvelle API n'interfère pas avec la fonctionnalité de construction.
- Stabilité et cohérence.
La recherche d'une solution pour l'API n'a pas commencé avec le backend, comme cela est généralement accepté, mais, au contraire, a pensé aux besoins des utilisateurs.
Les plus courantes sont toutes sortes d'API REST. Ces dernières années, des modèles descriptifs leur ont été ajoutés via des outils comme swagger, mais vous devez comprendre qu'il s'agit du même REST. Et, en fait, ses principaux avantages et inconvénients sont en même temps les règles, qui sont exclusivement descriptives. Autrement dit, personne n'interdit au créateur d'une telle API de s'écarter des postulats REST lors de la mise en œuvre de composants individuels.
Une autre solution courante est GraphQL. Elle n'est pas non plus parfaite, mais contrairement à REST, l'API GraphQL n'est pas seulement un modèle descriptif, mais de vraies règles.
Plus tôt, j'ai parlé du système, qui était censé coordonner le travail du frontend et du backend. L'intercalaire est exactement ce niveau intermédiaire. Après avoir considéré les options possibles pour travailler avec le serveur, nous avons opté pour GraphQL comme API pour le frontend . Mais, puisque le backend est écrit en C ++, l'implémentation du serveur GraphQL s'est avérée être une tâche non triviale. Je ne décrirai pas toutes les difficultés et les trucs auxquels nous sommes allés pour les surmonter, cela n'a pas apporté de vrai résultat. Nous avons examiné le problème de l'autre côté et décidé que la simplicité est la clé du succès. Par conséquent, nous avons opté pour des solutions éprouvées: un serveur Node.js séparé avec Express.js et Apollo Server.
Ensuite, vous deviez décider comment accéder à l'API backend. Au début, nous avons cherché à augmenter l'API REST, puis nous avons essayé d'utiliser des modules complémentaires en C ++ pour Node.js. En conséquence, nous avons réalisé que tout cela ne nous convenait pas, et après une analyse détaillée pour le backend, nous avons choisi une API basée sur les services gRPC .
Après avoir rassemblé l'expérience acquise dans l'utilisation de C ++, TypeScript, GraphQL et gRPC, nous avons obtenu une architecture d'application qui permet un développement flexible du backend et du frontend, tout en continuant à créer un seul logiciel.
Le résultat est un schéma dans lequel le frontal communique avec un serveur intermédiaire à l'aide de requêtes GraphQL (sait quoi demander et ce qu'il obtiendra en retour). Le serveur graphQL dans les résolveurs appelle les fonctions API du serveur gRPC, et pour cela, il utilise des schémas Protobuf pour la communication. Le serveur d'API basé sur gRPC sait à partir de quel microservice prendre les données ou à qui envoyer la demande. Les microservices eux-mêmes sont également construits sur gRPC, ce qui garantit la vitesse de traitement des requêtes, le typage des données et la possibilité d'utiliser divers langages de programmation pour leur développement.
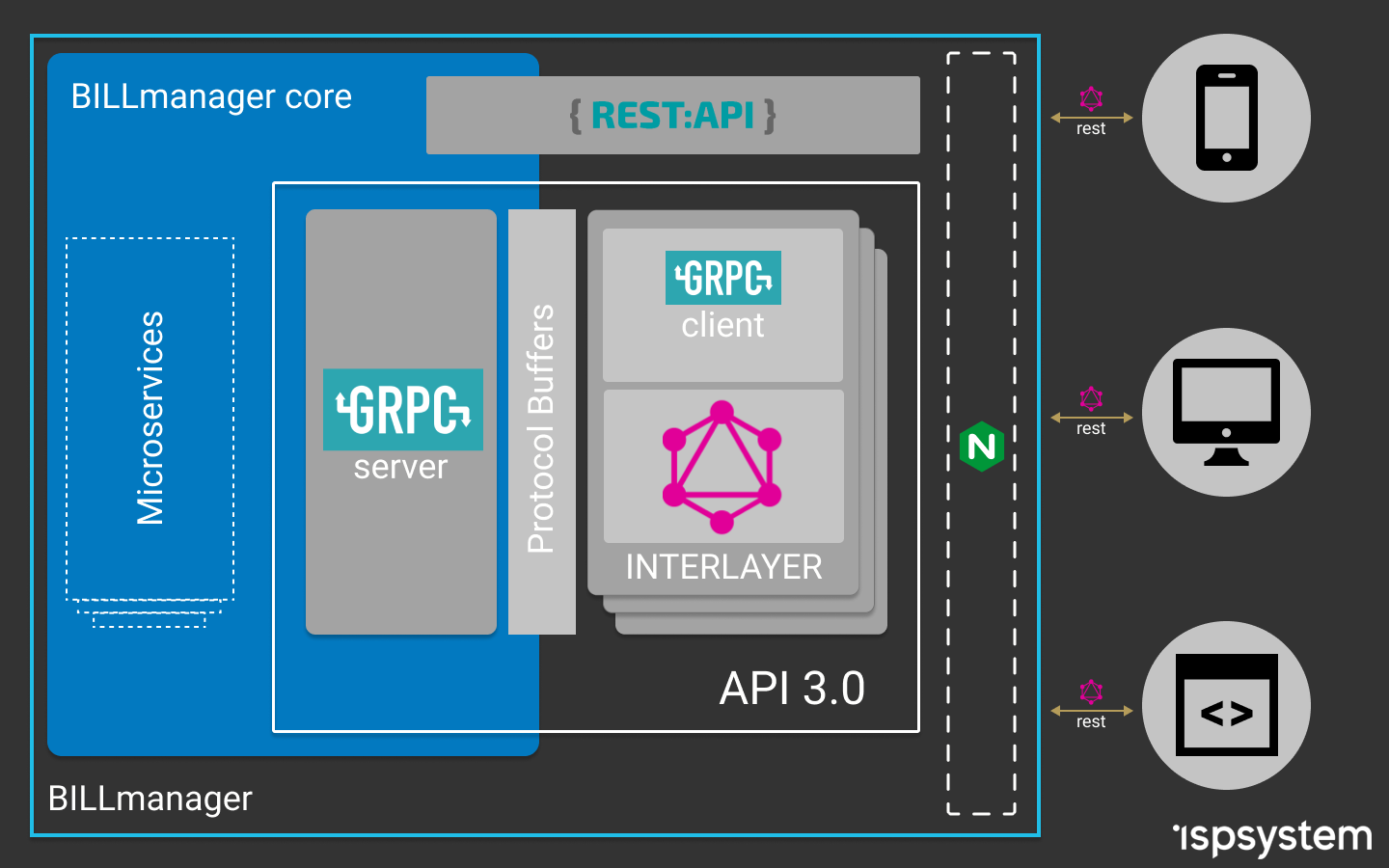
Schéma général de travail après un changement d'architecture
Cette approche présente un certain nombre d'inconvénients, dont le principal est le travail supplémentaire de mise en place et de coordination des circuits, ainsi que la rédaction de fonctions auxiliaires. Mais ces coûts seront payants lorsqu'il y aura plus d'utilisateurs d'API.
Résultat
Nous avons suivi la voie évolutive du développement d'un produit et d'une équipe. Succès atteint ou entreprise transformée en échec, il est probablement tôt pour juger, mais des résultats intermédiaires peuvent se résumer. Ce que nous avons maintenant:
- Le frontend est responsable de l'affichage et le backend est responsable des données.
- À l'avant, la flexibilité est restée en termes d'interrogation et de réception de données. L'interface sait ce que vous pouvez demander au serveur et quelles devraient être les réponses.
- Le backend a la possibilité de changer le code avec la certitude que l'interface utilisateur continuera de fonctionner. Il est devenu possible de passer à l'architecture de microservice sans avoir à refaire l'intégralité du frontend.
- Vous pouvez maintenant utiliser des données factices pour le frontend lorsque le backend n'est pas encore prêt.
- La création de schémas de collaboration a éliminé les problèmes d'interaction lorsque les équipes ont compris la même tâche différemment. Le nombre d'itérations pour modifier les formats de données a été réduit: nous agissons sur le principe de «mesurer sept fois, couper une fois».
- Vous pouvez maintenant planifier le travail de sprint en parallèle.
- Pour implémenter des microservices individuels, vous pouvez désormais recruter des développeurs qui ne sont pas familiers avec C ++.
De tout cela, j'appellerais l'opportunité de développer consciemment l'équipe et le projet comme la principale réalisation. Je pense que nous avons pu créer des conditions dans lesquelles chaque participant peut améliorer plus délibérément ses compétences, se concentrer sur les tâches et ne pas disperser son attention. Chacun est obligé de travailler uniquement sur son propre site, et maintenant c'est possible avec une forte implication et sans changement constant. Il est impossible de devenir un professionnel dans tout, mais maintenant ce n'est plus nécessaire pour nous .
L'article s'est avéré être une critique et très général. Son objectif était de montrer le chemin et les résultats de recherches complexes sur le sujet de la façon de changer l'architecture d'un point de vue technique pour continuer le développement de produits, ainsi que de démontrer les difficultés organisationnelles de diviser une équipe en parties convenues.
Ici, j'ai abordé superficiellement les problèmes de travail d'équipe et d'équipe sur un produit, le choix de la technologie API (REST vs GraphQL), la connexion des applications Node.js avec C ++, etc. Chacun de ces sujets dessine un article séparé, et si vous êtes intéressé, alors nous les écrirons.