Dans cet article, nous aimerions partager une manière intéressante de gérer la configuration d'un système distribué.
La configuration est représentée directement en langage Scala de manière sécurisée. Un exemple d'implémentation est décrit en détail. Divers aspects de la proposition sont discutés, y compris l'influence sur le processus de développement global.
( en russe )
Présentation
La construction de systèmes distribués robustes nécessite l'utilisation d'une configuration correcte et cohérente sur tous les nœuds. Une solution typique consiste à utiliser une description textuelle du déploiement (terraform, ansible ou quelque chose de similaire) et des fichiers de configuration générés automatiquement (souvent - dédiés à chaque nœud / rôle). Nous voudrions également utiliser les mêmes protocoles des mêmes versions sur chaque nœud communiquant (sinon nous rencontrerions des problèmes d'incompatibilité). Dans le monde JVM, cela signifie qu'au moins la bibliothèque de messagerie doit être de la même version sur tous les nœuds communicants.
Qu'en est-il du test du système? Bien sûr, nous devrions avoir des tests unitaires pour tous les composants avant de passer aux tests d'intégration. Pour pouvoir extrapoler les résultats des tests à l'exécution, nous devons nous assurer que les versions de toutes les bibliothèques sont conservées identiques dans les environnements d'exécution et de test.
Lors de l'exécution de tests d'intégration, il est souvent beaucoup plus facile d'avoir le même chemin de classe sur tous les nœuds. Nous devons simplement nous assurer que le même chemin de classe est utilisé lors du déploiement. (Il est possible d'utiliser différents chemins de classe sur différents nœuds, mais il est plus difficile de représenter cette configuration et de la déployer correctement.) Donc, pour garder les choses simples, nous ne considérerons que des chemins de classe identiques sur tous les nœuds.
La configuration a tendance à évoluer avec le logiciel. Nous utilisons généralement des versions pour identifier divers
étapes de l'évolution du logiciel. Il semble raisonnable de couvrir la configuration sous la gestion des versions et d'identifier différentes configurations avec certaines étiquettes. S'il n'y a qu'une seule configuration en production, nous pouvons utiliser la version unique comme identifiant. Parfois, nous pouvons avoir plusieurs environnements de production. Et pour chaque environnement, nous pourrions avoir besoin d'une branche de configuration distincte. Ainsi, les configurations peuvent être étiquetées avec une branche et une version pour identifier de manière unique différentes configurations. Chaque étiquette et version de branche correspond à une combinaison unique de nœuds distribués, de ports, de ressources externes et de versions de bibliothèque de chemin de classe sur chaque nœud. Ici, nous couvrirons uniquement la branche unique et identifierons les configurations par une version décimale à trois composants (1.2.3), de la même manière que les autres artefacts.
Dans les environnements modernes, les fichiers de configuration ne sont plus modifiés manuellement. En règle générale, nous générons
configurer les fichiers au moment du déploiement et ne jamais les toucher par la suite. On pourrait donc se demander pourquoi utilisons-nous toujours le format texte pour les fichiers de configuration? Une option viable consiste à placer la configuration à l'intérieur d'une unité de compilation et à bénéficier de la validation de la configuration au moment de la compilation.
Dans cet article, nous examinerons l'idée de conserver la configuration dans l'artefact compilé.
Configuration compilable
Dans cette section, nous allons discuter d'un exemple de configuration statique. Deux services simples - le service d'écho et le client du service d'écho sont en cours de configuration et d'implémentation. Ensuite, deux systèmes distribués différents avec les deux services sont instanciés. L'un est pour une configuration à nœud unique et l'autre pour une configuration à deux nœuds.
Un système distribué typique se compose de quelques nœuds. Les nœuds pourraient être identifiés en utilisant un certain type:
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
ou juste
case class NodeId(hostName: String)
ou même
object Singleton type NodeId = Singleton.type
Ces nœuds remplissent différents rôles, exécutent certains services et devraient pouvoir communiquer avec les autres nœuds au moyen de connexions TCP / HTTP.
Pour la connexion TCP, au moins un numéro de port est requis. Nous voulons également nous assurer que le client et le serveur parlent le même protocole. Afin de modéliser une connexion entre des nœuds, déclarons la classe suivante:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
où Port est juste un Int dans la plage autorisée:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Types raffinésVoir la bibliothèque raffinée . En bref, cela permet d'ajouter des contraintes de temps de compilation à d'autres types. Dans ce cas, Int ne peut avoir que des valeurs 16 bits pouvant représenter le numéro de port. Il n'est pas nécessaire d'utiliser cette bibliothèque pour cette approche de configuration. Cela semble juste très bien.
Pour HTTP (REST), nous pourrions également avoir besoin d'un chemin d'accès au service:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
Type fantômeAfin d'identifier le protocole lors de la compilation, nous utilisons la fonction Scala de déclaration de l'argument de type Protocol qui n'est pas utilisé dans la classe. C'est un soi-disant type fantôme . Au moment de l'exécution, nous avons rarement besoin d'une instance d'identifiant de protocole, c'est pourquoi nous ne la stockons pas. Pendant la compilation, ce type fantôme offre une sécurité de type supplémentaire. Nous ne pouvons pas passer le port avec un protocole incorrect.
L'un des protocoles les plus utilisés est l'API REST avec sérialisation Json:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
où RequestMessage est le type de base des messages que le client peut envoyer au serveur et ResponseMessage est le message de réponse du serveur. Bien sûr, nous pouvons créer d'autres descriptions de protocole qui spécifient le protocole de communication avec la précision souhaitée.
Aux fins de cet article, nous utiliserons une version plus simple du protocole:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
Dans ce protocole, le message de demande est ajouté à l'URL et le message de réponse est renvoyé sous forme de chaîne ordinaire.
Une configuration de service peut être décrite par le nom du service, une collection de ports et certaines dépendances. Il existe plusieurs façons de représenter tous ces éléments dans Scala (par exemple, HList , types de données algébriques). Aux fins de cet article, nous utiliserons Cake Pattern et représenterons des pièces combinables (modules) comme traits. (Cake Pattern n'est pas une exigence pour cette approche de configuration compilable. C'est juste une implémentation possible de l'idée.)
Les dépendances pourraient être représentées en utilisant le modèle de gâteau comme points de terminaison d'autres nœuds:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
Le service d'écho n'a besoin que d'un port configuré. Et nous déclarons que ce port prend en charge le protocole d'écho. Notez que nous n'avons pas besoin de spécifier un port particulier pour le moment, car les traits permettent les déclarations de méthodes abstraites. Si nous utilisons des méthodes abstraites, le compilateur nécessitera une implémentation dans une instance de configuration. Ici, nous avons fourni l'implémentation ( 8081 ) et elle sera utilisée comme valeur par défaut si nous la sautons dans une configuration concrète.
Nous pouvons déclarer une dépendance dans la configuration du client du service d'écho:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
La dépendance a le même type que echoService . En particulier, il exige le même protocole. Par conséquent, nous pouvons être sûrs que si nous connectons ces deux dépendances, elles fonctionneront correctement.
Mise en place des servicesUn service a besoin d'une fonction pour démarrer et s'arrêter normalement. (La possibilité d'arrêter un service est essentielle pour les tests.) Encore une fois, il existe quelques options pour spécifier une telle fonction pour une configuration donnée (par exemple, nous pourrions utiliser des classes de type). Pour cet article, nous utiliserons à nouveau Cake Pattern. Nous pouvons représenter un service utilisant cats.Resource qui fournit déjà le bracketing et la libération des ressources. Afin d'acquérir une ressource, nous devons fournir une configuration et un certain contexte d'exécution. Ainsi, la fonction de démarrage du service pourrait ressembler à:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
où
Config - type de configuration requis par ce démarreur de serviceAddressResolver - un objet d'exécution qui a la capacité d'obtenir des adresses réelles d'autres nœuds (continuez à lire pour plus de détails).
les autres types proviennent de cats :
F[_] - type d'effet (dans le cas le plus simple, F[A] pourrait être juste () => A Dans cet article, nous utiliserons cats.IO )Reader[A,B] - est plus ou moins synonyme d'une fonction A => Bcats.Resource - a des moyens d'acquérir et de libérerTimer - permet de dormir / mesurer le tempsContextShift - analogue d' ExecutionContextApplicative - wrapper de fonctions en vigueur (presque une monade) (nous pourrions éventuellement le remplacer par autre chose)
En utilisant cette interface, nous pouvons implémenter quelques services. Par exemple, un service qui ne fait rien:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Voir le code source pour d'autres implémentations de services - service d'écho ,
écho client et contrôleurs à vie .)
Un nœud est un objet unique qui exécute quelques services (le démarrage d'une chaîne de ressources est activé par Cake Pattern):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Notez que dans le nœud, nous spécifions le type exact de configuration requis par ce nœud. Le compilateur ne nous permet pas de construire l'objet (Cake) avec un type insuffisant, car chaque trait de service déclare une contrainte sur le type Config . De plus, nous ne pourrons pas démarrer le nœud sans fournir une configuration complète.
Résolution d'adresse de nœudAfin d'établir une connexion, nous avons besoin d'une véritable adresse d'hôte pour chaque nœud. Il peut être connu plus tard que d'autres parties de la configuration. Par conséquent, nous avons besoin d'un moyen de fournir un mappage entre l'identifiant du nœud et son adresse réelle. Ce mappage est une fonction:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Il existe plusieurs façons d'implémenter une telle fonction.
- Si nous connaissons les adresses réelles avant le déploiement, pendant l'instanciation des hôtes de nœuds, nous pouvons générer du code Scala avec les adresses réelles et exécuter la génération par la suite (qui effectue des vérifications de temps de compilation puis exécute la suite de tests d'intégration). Dans ce cas, notre fonction de mappage est connue statiquement et peut être simplifiée en quelque chose comme une
Map[NodeId, NodeAddress] . - Parfois, nous n'obtenons des adresses réelles qu'à un moment ultérieur lorsque le nœud est réellement démarré, ou nous n'avons pas d'adresses de nœuds qui n'ont pas encore été démarrés. Dans ce cas, nous pourrions avoir un service de découverte qui est démarré avant tous les autres nœuds et chaque nœud peut publier son adresse dans ce service et s'abonner aux dépendances.
- Si nous pouvons modifier
/etc/hosts , nous pouvons utiliser des noms d'hôte prédéfinis (comme my-project-main-node et echo-backend ) et simplement associer ce nom à l'adresse IP au moment du déploiement.
Dans cet article, nous ne couvrons pas ces cas plus en détail. En fait, dans notre exemple de jouet, tous les nœuds auront la même adresse IP - 127.0.0.1 .
Dans cet article, nous considérerons deux configurations de système réparties:
- Disposition à nœud unique, où tous les services sont placés sur le nœud unique.
- Disposition à deux nœuds, où le service et le client sont sur des nœuds différents.
La configuration pour une disposition à nœud unique est la suivante:
Configuration à nœud unique object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
Ici, nous créons une configuration unique qui étend la configuration du serveur et du client. Nous configurons également un contrôleur de cycle de vie qui terminera normalement le client et le serveur après un intervalle de lifetime .
Le même ensemble d'implémentations et de configurations de service peut être utilisé pour créer la configuration d'un système avec deux nœuds distincts. Nous avons juste besoin de créer deux configurations de nœuds distinctes avec les services appropriés:
Configuration à deux nœuds object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Voyez comment nous spécifions la dépendance. Nous mentionnons le service fourni par l'autre nœud comme une dépendance du nœud actuel. Le type de dépendance est vérifié car il contient un type fantôme qui décrit le protocole. Et à l'exécution, nous aurons l'ID de nœud correct. C'est l'un des aspects importants de l'approche de configuration proposée. Il nous permet de définir le port une seule fois et de nous assurer que nous référençons le bon port.
Implémentation à deux nœudsPour cette configuration, nous utilisons exactement les mêmes implémentations de services. Aucun changement. Cependant, nous créons deux implémentations de nœuds différentes qui contiennent différents ensembles de services:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Le premier nœud implémente le serveur et n'a besoin que d'une configuration côté serveur. Le deuxième nœud implémente le client et a besoin d'une autre partie de la configuration. Les deux nœuds nécessitent une spécification de durée de vie. Aux fins de ce poste de service, le nœud aura une durée de vie infinie qui pourrait être terminée à l'aide de SIGTERM , tandis que le client d'écho se terminera après la durée finie configurée. Voir l' application de démarrage pour plus de détails.
Processus de développement global
Voyons comment cette approche change la façon dont nous travaillons avec la configuration.
La configuration en tant que code sera compilée et produit un artefact. Il semble raisonnable de séparer l'artefact de configuration des autres artefacts de code. Souvent, nous pouvons avoir une multitude de configurations sur la même base de code. Et bien sûr, nous pouvons avoir plusieurs versions de différentes branches de configuration. Dans une configuration, nous pouvons sélectionner des versions particulières de bibliothèques et cela restera constant chaque fois que nous déploierons cette configuration.
Un changement de configuration devient un changement de code. Il devrait donc être couvert par le même processus d'assurance qualité:
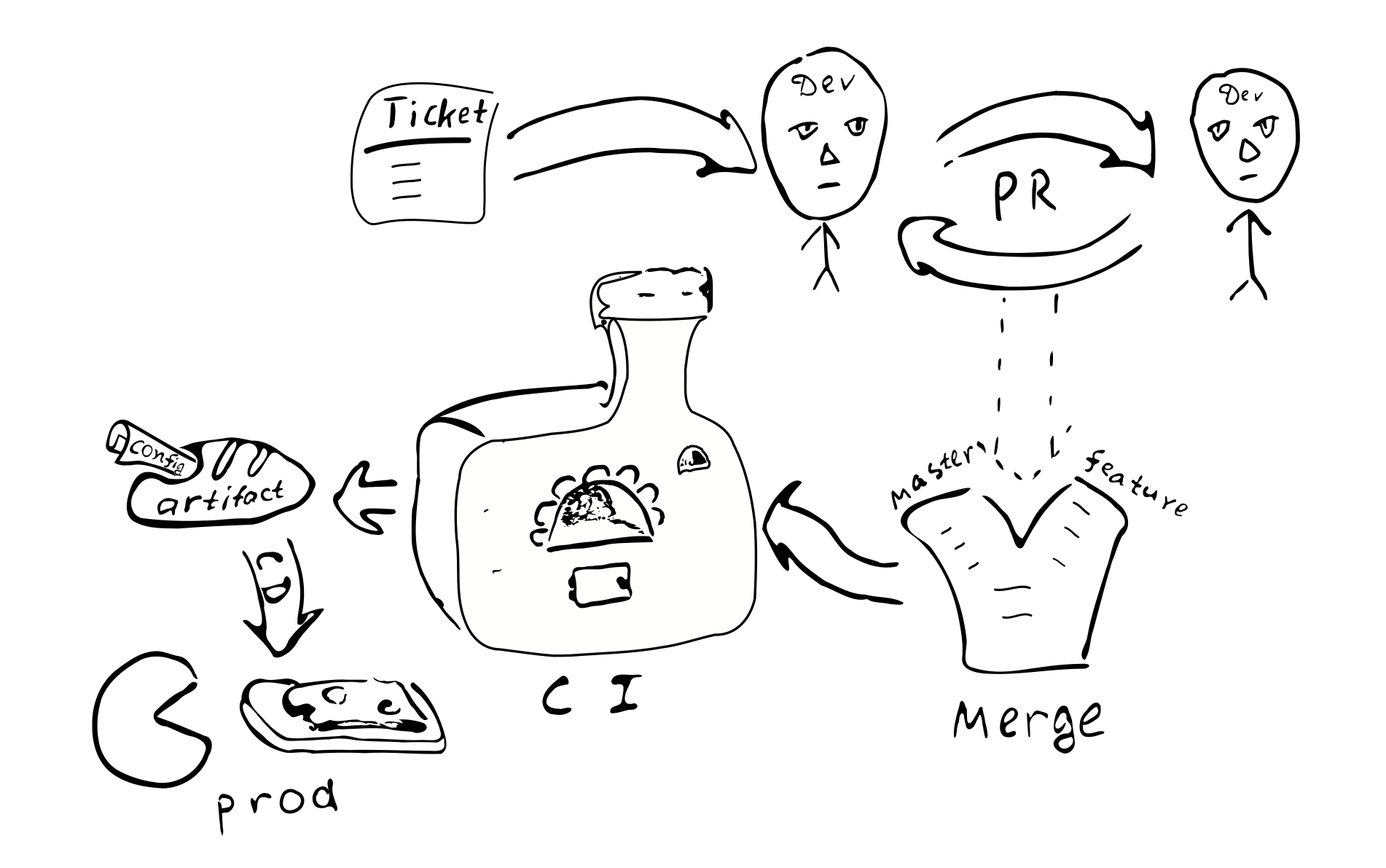
Ticket -> PR -> revue -> fusion -> intégration continue -> déploiement continu
Il y a les conséquences suivantes de l'approche:
La configuration est cohérente pour l'instance d'un système particulier. Il semble qu'il n'y ait aucun moyen d'avoir une connexion incorrecte entre les nœuds.
Il n'est pas facile de modifier la configuration dans un seul nœud. Il semble déraisonnable de se connecter et de modifier certains fichiers texte. La dérive de la configuration devient donc moins possible.
Les petits changements de configuration ne sont pas faciles à faire.
La plupart des changements de configuration suivront le même processus de développement et passeront un certain examen.
Avons-nous besoin d'un référentiel séparé pour la configuration de production? La configuration de production peut contenir des informations sensibles que nous aimerions garder hors de portée de nombreuses personnes. Il peut donc être utile de conserver un référentiel séparé avec un accès restreint qui contiendra la configuration de production. Nous pouvons diviser la configuration en deux parties - une qui contient la plupart des paramètres de production ouverts et une qui contient la partie secrète de la configuration. Cela permettrait à la plupart des développeurs d'accéder à la grande majorité des paramètres tout en restreignant l'accès aux choses vraiment sensibles. Il est facile d'accomplir cela en utilisant des traits intermédiaires avec des valeurs de paramètres par défaut.
Variations
Voyons les avantages et les inconvénients de l'approche proposée par rapport aux autres techniques de gestion de configuration.
Tout d'abord, nous énumérons quelques alternatives aux différents aspects de la manière proposée de gérer la configuration:
- Fichier texte sur la machine cible.
- Stockage de valeurs-clés centralisé (comme
etcd / etcd ). - Composants de sous-processus qui pourraient être reconfigurés / redémarrés sans redémarrer le processus.
- Configuration hors contrôle d'artefact et de version.
Le fichier texte donne une certaine flexibilité en termes de correctifs ad hoc. L'administrateur d'un système peut se connecter au nœud cible, apporter une modification et simplement redémarrer le service. Ce n'est peut-être pas aussi bon pour les systèmes plus gros. Aucune trace n'est laissée derrière le changement. Le changement n'est pas examiné par une autre paire d'yeux. Il pourrait être difficile de déterminer la cause du changement. Il n'a pas été testé. Du point de vue d'un système distribué, un administrateur peut simplement oublier de mettre à jour la configuration dans l'un des autres nœuds.
(Btw, si finalement il sera nécessaire de commencer à utiliser des fichiers de configuration de texte, nous n'aurons qu'à ajouter un analyseur + validateur qui pourrait produire le même type de Config et qui serait suffisant pour commencer à utiliser des configurations de texte. Cela montre également que le la complexité de la configuration au moment de la compilation est un peu plus petite que la complexité des configurations basées sur du texte, car dans la version basée sur le texte, nous avons besoin de code supplémentaire.)
Le stockage centralisé des valeurs-clés est un bon mécanisme de distribution des méta-paramètres d'application. Ici, nous devons réfléchir à ce que nous considérons comme des valeurs de configuration et à ce qui ne sont que des données. Étant donné une fonction C => A => B nous appelons généralement les valeurs rarement changeantes C "configuration", tandis que les données fréquemment modifiées A - ne sont que des données d'entrée. La configuration doit être fournie à la fonction plus tôt que les données A Compte tenu de cette idée, nous pouvons dire que c'est la fréquence attendue des changements qui pourrait être utilisée pour distinguer les données de configuration des seules données. De plus, les données proviennent généralement d'une source (utilisateur) et la configuration provient d'une source différente (admin). Le traitement des paramètres qui peuvent être modifiés après l'initialisation du processus entraîne une augmentation de la complexité de l'application. Pour ces paramètres, nous devrons gérer leur mécanisme de livraison, l'analyse et la validation, en gérant les valeurs incorrectes. Par conséquent, afin de réduire la complexité du programme, nous ferions mieux de réduire le nombre de paramètres qui peuvent changer au moment de l'exécution (ou même les éliminer complètement).
Du point de vue de ce post, nous devrions faire une distinction entre les paramètres statiques et dynamiques. Si la logique de service nécessite une modification rare de certains paramètres lors de l'exécution, nous pouvons les appeler des paramètres dynamiques. Sinon, ils sont statiques et pourraient être configurés en utilisant l'approche proposée. Pour la reconfiguration dynamique, d'autres approches pourraient être nécessaires. Par exemple, certaines parties du système peuvent être redémarrées avec les nouveaux paramètres de configuration d'une manière similaire au redémarrage de processus séparés d'un système distribué.
(Mon humble avis est d'éviter la reconfiguration du runtime car cela augmente la complexité du système.
Il serait peut-être plus simple de simplement compter sur la prise en charge par le système d'exploitation des processus de redémarrage. Cependant, cela pourrait ne pas toujours être possible.)
Un aspect important de l'utilisation de la configuration statique qui fait parfois penser à la configuration dynamique (sans autres raisons) est le temps d'arrêt du service pendant la mise à jour de la configuration. En effet, si nous devons apporter des modifications à la configuration statique, nous devons redémarrer le système pour que les nouvelles valeurs deviennent effectives. Les exigences pour les temps d'arrêt varient selon les systèmes, il n'est donc pas si critique que cela. Si c'est critique, nous devons planifier à l'avance les redémarrages du système. Par exemple, nous pourrions implémenter le drainage de connexion AWS ELB . Dans ce scénario, chaque fois que nous devons redémarrer le système, nous démarrons une nouvelle instance du système en parallèle, puis nous y basculons ELB, tout en laissant l'ancien système terminer la maintenance des connexions existantes.
Qu'en est-il de conserver la configuration à l'intérieur de l'artefact versionné ou à l'extérieur? Conserver la configuration à l'intérieur d'un artefact signifie dans la plupart des cas que cette configuration a passé le même processus d'assurance qualité que les autres artefacts. On peut donc être sûr que la configuration est de bonne qualité et fiable. Au contraire, la configuration dans un fichier séparé signifie qu'il n'y a aucune trace de qui et pourquoi a apporté des modifications à ce fichier. Est-ce important? Nous pensons que pour la plupart des systèmes de production, il est préférable d'avoir une configuration stable et de haute qualité.
La version de l'artefact permet de savoir quand il a été créé, quelles valeurs il contient, quelles fonctionnalités sont activées / désactivées, qui était responsable de chaque modification de la configuration. Cela peut nécessiter des efforts pour conserver la configuration à l'intérieur d'un artefact et c'est un choix de conception à faire.
Avantages et inconvénients
Ici, nous aimerions souligner certains avantages et discuter de certains inconvénients de l'approche proposée.
Les avantages
Caractéristiques de la configuration compilable d'un système distribué complet:
- Contrôle statique de la configuration. Cela donne un haut niveau de confiance, que la configuration est correcte compte tenu des contraintes de type.
- Langage de configuration riche. En règle générale, d'autres approches de configuration sont limitées à au plus la substitution de variables.
En utilisant Scala on peut utiliser un large éventail de fonctionnalités linguistiques pour améliorer la configuration. Par exemple, nous pouvons utiliser des traits pour fournir des valeurs par défaut, des objets pour définir une portée différente, nous pouvons nous référer à des valeurs définies une seule fois dans la portée externe (DRY). Il est possible d'utiliser des séquences littérales ou des instances de certaines classes ( Seq , Map , etc.). - DSL Scala a un support décent pour les écrivains DSL. On peut utiliser ces fonctionnalités pour établir un langage de configuration plus pratique et convivial pour l'utilisateur final, de sorte que la configuration finale soit au moins lisible par les utilisateurs du domaine.
- Intégrité et cohérence entre les nœuds. L'un des avantages d'avoir la configuration pour l'ensemble du système distribué en un seul endroit est que toutes les valeurs sont définies strictement une fois puis réutilisées dans tous les endroits où nous en avons besoin. Saisissez également des déclarations de port sûrs pour garantir que dans toutes les configurations correctes possibles, les nœuds du système parleront la même langue. Il existe des dépendances explicites entre les nœuds, ce qui rend difficile d'oublier de fournir certains services.
- Haute qualité des changements. L'approche globale consistant à transmettre les modifications de configuration par le biais d'un processus de relations publiques normal établit des normes de qualité élevées également dans la configuration.
- Changements de configuration simultanés. Chaque fois que nous apportons des modifications à la configuration, le déploiement automatique garantit que tous les nœuds sont mis à jour.
- Simplification d'application. L'application n'a pas besoin d'analyser et de valider la configuration et de gérer les valeurs de configuration incorrectes. Cela simplifie l'application globale. (Une certaine augmentation de la complexité se trouve dans la configuration elle-même, mais c'est un compromis conscient vers la sécurité.) Il est assez simple de revenir à la configuration ordinaire - ajoutez simplement les pièces manquantes. Il est plus facile de commencer avec la configuration compilée et de reporter la mise en œuvre de pièces supplémentaires à une date ultérieure.
- Configuration versionnée. Du fait que les changements de configuration suivent le même processus de développement, nous obtenons ainsi un artefact avec une version unique. Cela nous permet de changer de configuration si nécessaire. Nous pouvons même déployer une configuration utilisée il y a un an et elle fonctionnera exactement de la même manière. Une configuration stable améliore la prévisibilité et la fiabilité du système distribué. La configuration est fixe au moment de la compilation et ne peut pas être facilement altérée sur un système de production.
- Modularité Le cadre proposé est modulaire et les modules pourraient être combinés de diverses manières pour
prendre en charge différentes configurations (configurations / mises en page). En particulier, il est possible d'avoir une disposition à nœud unique à petite échelle et un paramètre à nœuds multiples à grande échelle. Il est raisonnable d'avoir plusieurs configurations de production. - Test À des fins de test, on peut implémenter un service fictif et l'utiliser comme dépendance de manière sûre. Quelques dispositions de test différentes avec différentes pièces remplacées par des maquettes pourraient être maintenues simultanément.
- Test d'intégration. Parfois, dans les systèmes distribués, il est difficile d'exécuter des tests d'intégration. En utilisant l'approche décrite pour taper la configuration sûre du système distribué complet, nous pouvons exécuter toutes les pièces distribuées sur un seul serveur de manière contrôlable. Il est facile d'imiter la situation
lorsque l'un des services devient indisponible.
Inconvénients
L'approche de configuration compilée est différente de la configuration "normale" et peut ne pas convenir à tous les besoins. Voici certains des inconvénients de la configuration compilée:
- Configuration statique. Il pourrait ne pas convenir à toutes les applications. Dans certains cas, il est nécessaire de fixer rapidement la configuration en production en contournant toutes les mesures de sécurité. Cette approche rend la tâche plus difficile. La compilation et le redéploiement sont requis après toute modification de configuration. C'est à la fois la caractéristique et le fardeau.
- Génération de configuration. Lorsque la configuration est générée par un outil d'automatisation, cette approche nécessite une compilation ultérieure (qui peut à son tour échouer). Cela peut nécessiter des efforts supplémentaires pour intégrer cette étape supplémentaire dans le système de génération.
- Instruments. Il existe de nombreux outils utilisés aujourd'hui qui reposent sur des configurations basées sur du texte. Certains d'entre eux
ne sera pas applicable lors de la compilation de la configuration. - Un changement de mentalité est nécessaire. Les développeurs et DevOps connaissent bien les fichiers de configuration de texte. L'idée de compiler la configuration peut leur paraître étrange.
- Avant d'introduire une configuration compilable, un processus de développement logiciel de haute qualité est requis.
Il y a quelques limites à l'exemple implémenté:
- Si nous fournissons une configuration supplémentaire qui n'est pas demandée par l'implémentation du nœud, le compilateur ne nous aidera pas à détecter l'implémentation absente. Cela pourrait être résolu en utilisant
HList ou ADT (classes de cas) pour la configuration des nœuds au lieu des traits et du modèle de gâteau. - Nous devons fournir un passe-partout dans le fichier de configuration: (
package , import , déclarations d' object ;
override def pour les paramètres qui ont des valeurs par défaut). Cela pourrait être partiellement résolu en utilisant une DSL. - Dans cet article, nous ne couvrons pas la reconfiguration dynamique de clusters de nœuds similaires.
Conclusion
Dans cet article, nous avons discuté de l'idée de représenter la configuration directement dans le code source d'une manière sûre. L'approche pourrait être utilisée dans de nombreuses applications en remplacement des configurations XML et autres configurations basées sur du texte. Bien que notre exemple ait été implémenté dans Scala, il pourrait également être traduit dans d'autres langages compilables (comme Kotlin, C #, Swift, etc.). On pourrait essayer cette approche dans un nouveau projet et, au cas où cela ne conviendrait pas bien, passer à l'ancienne.
Bien sûr, la configuration compilable nécessite un processus de développement de haute qualité. En retour, il promet de fournir une configuration robuste de haute qualité.
Cette approche pourrait être étendue de différentes manières:
- On pourrait utiliser des macros pour effectuer la validation de la configuration et échouer au moment de la compilation en cas d'échec de contraintes de logique métier.
- Un DSL pourrait être implémenté pour représenter la configuration d'une manière conviviale pour le domaine.
- Gestion dynamique des ressources avec ajustements de configuration automatiques. Par exemple, lorsque nous ajustons le nombre de nœuds de cluster, nous pouvons souhaiter (1) que les nœuds obtiennent une configuration légèrement modifiée; (2) gestionnaire de cluster pour recevoir les nouvelles informations sur les nœuds.
Merci
Je voudrais remercier Andrey Saksonov, Pavel Popov, Anton Nehaev pour leurs commentaires inspirants sur le brouillon de ce post qui m'ont aidé à le rendre plus clair.