Je voudrais vous dire un mécanisme intéressant pour travailler avec une configuration de système distribué. La configuration est présentée directement dans un langage compilé (Scala) en utilisant des types sûrs. Dans cet article, un exemple d'une telle configuration est analysé et divers aspects de l'introduction d'une configuration compilée dans le processus de développement global sont examinés.
( anglais )
Présentation
La construction d'un système distribué fiable implique que tous les nœuds utilisent la configuration correcte, synchronisée avec les autres nœuds. En règle générale, les technologies DevOps (terraform, ansible ou quelque chose comme ça) sont utilisées pour générer automatiquement des fichiers de configuration (souvent les leurs pour chaque nœud). Nous aimerions également être sûrs que tous les nœuds en interaction utilisent des protocoles identiques (y compris la même version). Sinon, l'incompatibilité sera intégrée dans notre système distribué. Dans le monde JVM, l'une des conséquences de cette exigence est la nécessité d'utiliser partout la même version d'une bibliothèque contenant des messages de protocole.
Qu'en est-il des tests de systèmes distribués? Bien entendu, nous supposons que des tests unitaires sont fournis pour tous les composants avant de passer aux tests d'intégration. (Pour que nous puissions extrapoler les résultats des tests à l'exécution, nous devons également fournir un ensemble identique de bibliothèques au stade des tests et à l'exécution.)
Lorsque vous travaillez avec des tests d'intégration, il est souvent plus facile partout d'utiliser un seul chemin de classe sur tous les nœuds. Nous n'aurons qu'à nous assurer que le même chemin de classe est impliqué dans le runtime. (Malgré le fait qu'il soit tout à fait possible d'exécuter différents nœuds avec des chemins de classe différents, cela entraîne des complications de la configuration entière et des difficultés avec les tests de déploiement et d'intégration.) Dans le cadre de cette publication, nous supposons que le même chemin de classe sera utilisé sur tous les nœuds.
La configuration évolue avec l'application. Pour identifier les différentes étapes de l'évolution des programmes, nous utilisons des versions. Il semble logique d'identifier également différentes versions des configurations. Et la configuration elle-même doit être placée dans le système de contrôle de version. S'il n'y a qu'une seule configuration en production, alors nous pouvons simplement utiliser le numéro de version. Si de nombreuses instances de production sont utilisées, nous avons besoin de plusieurs
branches de configuration et une étiquette supplémentaire en plus de la version (par exemple, le nom de la branche). Ainsi, nous pouvons identifier de manière unique la configuration exacte. Chaque identificateur de configuration correspond de manière unique à une certaine combinaison de nœuds distribués, de ports, de ressources externes et de versions de bibliothèque. Dans le cadre de cet article, nous partirons du fait qu'il n'y a qu'une seule branche, et nous pouvons identifier la configuration de la manière habituelle en utilisant trois nombres séparés par un point (1.2.3).
Dans les environnements modernes, les fichiers de configuration sont créés manuellement assez rarement. Le plus souvent, ils sont générés lors du déploiement et ils ne sont plus touchés (pour ne rien casser ). Une question logique se pose, pourquoi utilisons-nous toujours un format texte pour stocker la configuration? Une alternative tout à fait viable est la possibilité d'utiliser du code normal pour la configuration et de bénéficier des contrôles lors de la compilation.
Dans cet article, nous explorons simplement l'idée de représenter une configuration à l'intérieur d'un artefact compilé.
Configuration compilée
Cette section décrit un exemple de configuration compilée statique. Deux services simples sont mis en œuvre - le service d'écho et le service d'écho client. Sur la base de ces deux services, deux versions du système sont assemblées. Dans un mode de réalisation, les deux services sont situés sur le même nœud, dans un autre mode de réalisation, sur des nœuds différents.
En règle générale, un système distribué contient plusieurs nœuds. Les nœuds peuvent être identifiés à l'aide de valeurs d'un certain type NodeId :
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
ou
case class NodeId(hostName: String)
ou même
object Singleton type NodeId = Singleton.type
Les nœuds jouent différents rôles, des services y sont lancés et des communications TCP / HTTP peuvent être établies entre eux.
Pour décrire les communications TCP, nous avons besoin d'au moins un numéro de port. Nous aimerions également refléter le protocole pris en charge sur ce port afin de garantir que le client et le serveur utilisent le même protocole. Nous décrirons la connexion en utilisant cette classe:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
où Port est juste un entier Int avec une plage de valeurs valides:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Types raffinésVoir la bibliothèque raffinée et mon rapport . En bref, la bibliothèque vous permet d'ajouter des types de contraintes vérifiées lors de la compilation. Dans ce cas, les valeurs de numéro de port valides sont des nombres entiers de 16 bits. Pour une configuration compilée, l'utilisation de la bibliothèque raffinée est facultative, mais elle peut améliorer la capacité du compilateur à vérifier la configuration.
Pour les protocoles HTTP (REST), en plus du numéro de port, nous pouvons également avoir besoin d'un chemin d'accès au service:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
Types fantômesPour identifier le protocole au stade de la compilation, nous utilisons un paramètre de type qui n'est pas utilisé à l'intérieur de la classe. Cette décision est due au fait qu'à l'exécution, nous n'utilisons pas d'instance de protocole, mais nous aimerions que le compilateur vérifie la compatibilité du protocole. Grâce au protocole, nous ne pourrons pas transférer le service inadapté comme dépendance.
Un protocole commun est l'API REST avec la sérialisation Json:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
où RequestMessage est le type de demande, ResponseMessage est le type de réponse.
Bien sûr, vous pouvez utiliser d'autres descriptions de protocoles qui fournissent la précision dont nous avons besoin.
Aux fins de cet article, nous utiliserons une version simplifiée du protocole:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
Ici, la demande est une chaîne ajoutée à l'URL et la réponse est la chaîne renvoyée dans le corps de la réponse HTTP.
La configuration du service est décrite par le nom du service, les ports et les dépendances. Ces éléments peuvent être représentés dans Scala de plusieurs manières (par exemple, HList , types de données algébriques). Aux fins de cet article, nous utiliserons le modèle de gâteau et représenterons les modules en utilisant les trait . (Cake Pattern n'est pas un élément nécessaire de l'approche décrite. Ce n'est qu'une des implémentations possibles.)
Les dépendances entre les services peuvent être représentées comme des méthodes qui renvoient EndPoint ports EndPoint d'autres nœuds:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
Pour créer un service d'écho, seuls un numéro de port et une indication que ce port prend en charge le protocole d'écho sont suffisants. Nous n'avons pas pu indiquer de port spécifique, car les traits vous permettent de déclarer des méthodes sans implémentation (méthodes abstraites). Dans ce cas, lors de la création d'une configuration spécifique, le compilateur nous obligerait à fournir une implémentation de méthode abstraite et à fournir un numéro de port. Depuis que nous avons implémenté la méthode, lors de la création d'une configuration spécifique, nous ne pouvons pas spécifier un autre port. La valeur par défaut sera utilisée.
Dans la configuration client, nous déclarons une dépendance au service d'écho:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
La dépendance est du même type que le service exporté echoService . En particulier, dans le client d'écho, nous avons besoin du même protocole. Par conséquent, lors de la connexion des deux services, nous pouvons être sûrs que tout fonctionnera correctement.
Implémentation des servicesPour démarrer et arrêter le service, une fonction est requise. (La possibilité d'arrêter le service est essentielle pour les tests.) Encore une fois, il existe plusieurs options pour implémenter cette fonction (par exemple, nous pourrions utiliser des classes de type basées sur le type de configuration). Aux fins de cet article, nous utiliserons le modèle de gâteau. Nous représenterons le service à l'aide de la classe cats.Resource , car Dans cette classe, les moyens de libération sûre et sécurisée des ressources en cas de problème sont déjà fournis. Pour obtenir la ressource, nous devons fournir une configuration et un contexte d'exécution prêt. La fonction de démarrage du service peut prendre la forme suivante:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
où
Config - type de configuration pour ce serviceAddressResolver - un objet d'exécution qui vous permet de trouver les adresses d'autres nœuds (voir ci-dessous)
et d'autres types de la bibliothèque des cats :
F[_] - type d'effet (dans le cas le plus simple, F[A] peut simplement être une fonction () => A Dans ce post, nous utiliserons cats.IO )Reader[A,B] - plus ou moins synonyme de la fonction A => Bcats.Resource - une ressource qui peut être obtenue et publiéeTimer - minuterie (vous permet de vous endormir pendant un certain temps et de mesurer les intervalles de temps)ContextShift - analogue d' ExecutionContextApplicative - une classe de type d'effet qui vous permet de combiner des effets individuels (presque une monade). Dans les applications plus complexes, il semble préférable d'utiliser Monad / ConcurrentEffect .
En utilisant cette signature de fonction, nous pouvons implémenter plusieurs services. Par exemple, un service qui ne fait rien:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Voir le code source pour d'autres services - service d' écho, client d'écho
et contrôleurs à vie .)
Un nœud est un objet qui peut démarrer plusieurs services (le lancement de la chaîne de ressources est assuré par le Cake Pattern):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Veuillez noter que nous indiquons le type exact de configuration requis pour ce nœud. Si nous oublions de spécifier l'un des types de configuration requis par un service distinct, il y aura une erreur de compilation. De plus, nous ne pourrons pas démarrer le nœud si nous ne fournissons pas un objet du type approprié avec toutes les données nécessaires.
Résolution du nom d'hôtePour se connecter à un hôte distant, nous avons besoin d'une véritable adresse IP. Il est possible que l'adresse soit connue plus tard que le reste de la configuration. Par conséquent, nous avons besoin d'une fonction qui mappe l'identifiant du nœud à l'adresse:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Vous pouvez proposer plusieurs façons de mettre en œuvre une telle fonction:
- Si les adresses nous sont connues avant le déploiement, nous pouvons générer un code Scala avec
adresses, puis démarrez l'assemblage. Cela compilera et exécutera les tests.
Dans ce cas, la fonction sera connue statiquement et pourra être représentée dans le code comme un affichage de carte Map[NodeId, NodeAddress] . - Dans certains cas, une adresse valide n'est connue qu'après le démarrage du nœud.
Dans ce cas, nous pouvons implémenter un «service de découverte» (découverte), qui s'exécute avant que les autres nœuds et tous les nœuds s'enregistrent dans ce service et demandent les adresses des autres nœuds. - Si nous pouvons modifier
/etc/hosts , alors nous pouvons utiliser des noms d'hôte prédéfinis (comme my-project-main-node et echo-backend ) et simplement lier ces noms
avec des adresses IP pendant le déploiement.
Dans le cadre de cet article, nous ne traiterons pas ces cas plus en détail. Pour nos
Dans un exemple de jouet, tous les nœuds auront une adresse IP - 127.0.0.1 .
Ensuite, nous considérons deux options pour un système distribué:
- Placement de tous les services sur un nœud.
- Et le placement du service d'écho et du client d'écho sur différents nœuds.
Configuration pour un seul nœud :
Configuration à nœud unique object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
L'objet implémente la configuration du client et du serveur. La configuration de la durée de vie est également utilisée afin de terminer le programme après une lifetime . (Ctrl-C fonctionne également et libère correctement toutes les ressources.)
Le même ensemble de traits de configuration et d'implémentations peut être utilisé pour créer un système composé de deux nœuds distincts :
Configuration pour deux nœuds object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Important! Notez comment la liaison de service est effectuée. Nous indiquons le service implémenté par un nœud comme l'implémentation de la méthode de dépendance d'un autre nœud. Le type de dépendance est vérifié par le compilateur, car contient le type de protocole. Une fois lancée, la dépendance contiendra l'identifiant correct du nœud cible. Grâce à ce schéma, nous indiquons le numéro de port exactement une fois et nous garantissons toujours de faire référence au port correct.
Implémentation de deux nœuds systèmePour cette configuration, nous utilisons la même implémentation de service sans modifications. La seule différence est que nous avons maintenant deux objets qui implémentent différents ensembles de services:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Le premier nœud implémente le serveur et n'a besoin que de la configuration du serveur. Le deuxième nœud est implémenté par le client et utilise une autre partie de la configuration. Les deux nœuds doivent également gérer la durée de vie. Le nœud serveur s'exécute indéfiniment jusqu'à ce qu'il soit arrêté par SIGTERM , et le nœud client se termine après un certain temps. Voir l' application de lancement .
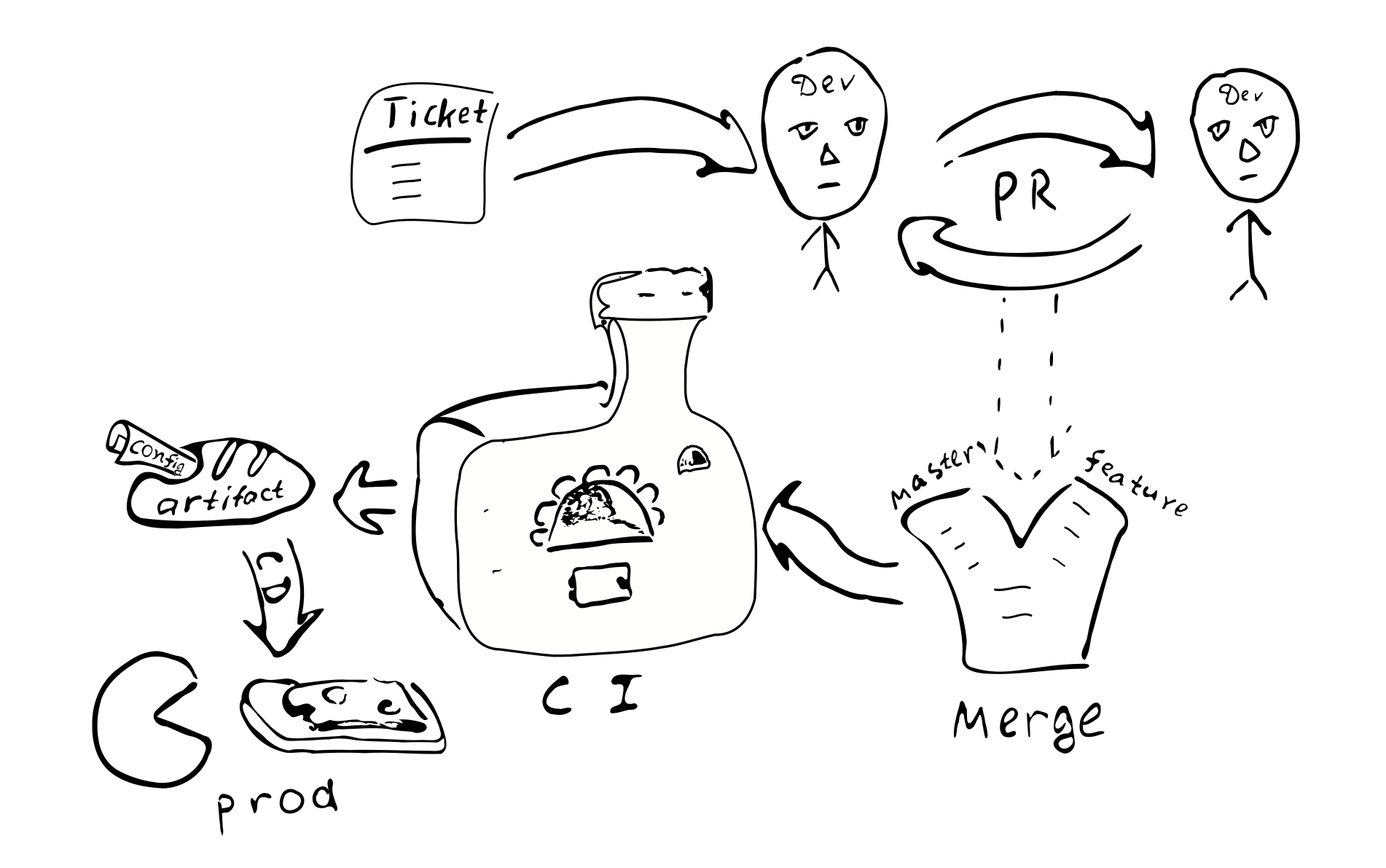
Processus de développement général
Voyons comment cette approche de configuration affecte le processus de développement global.
La configuration sera compilée avec le reste du code et un artefact (.jar) sera généré. Apparemment, il est logique de placer la configuration dans un artefact séparé. Cela est dû au fait que nous pouvons avoir de nombreuses configurations basées sur le même code. Encore une fois, vous pouvez générer des artefacts qui correspondent à différentes branches de configuration. Avec la configuration, les dépendances sur des versions spécifiques des bibliothèques sont préservées et ces versions sont préservées pour toujours, chaque fois que nous décidons de déployer cette version de la configuration.
Tout changement de configuration se transforme en un changement de code. Et donc, chacun de ces
Le changement sera couvert par le processus habituel d'assurance qualité:
Un ticket dans le bugtracker -> PR -> revue -> fusion avec les branches correspondantes ->
intégration -> déploiement
Les principales conséquences de l'implémentation d'une configuration compilée:
La configuration sera coordonnée sur tous les nœuds du système distribué. En raison du fait que tous les nœuds reçoivent la même configuration d'une seule source.
Il est problématique de modifier la configuration dans un seul des nœuds. Par conséquent, une «dérive de configuration» est peu probable.
Il devient plus difficile de faire de petits changements de configuration.
La plupart des modifications de configuration se produiront dans le cadre du processus de développement global et seront examinées.
Ai-je besoin d'un référentiel séparé pour stocker la configuration de production? Une telle configuration peut contenir des mots de passe et d'autres informations secrètes, auxquelles nous aimerions restreindre. Sur cette base, il semble logique de stocker la configuration finale dans un référentiel séparé. Vous pouvez diviser la configuration en deux parties - l'une contenant les paramètres de configuration publics et l'autre contenant les paramètres d'accès restreint. Cela permettra à la plupart des développeurs d'avoir accès à des paramètres communs. Cette séparation est facile à réaliser en utilisant des traits intermédiaires contenant des valeurs par défaut.
Variations possibles
Essayons de comparer la configuration compilée avec quelques alternatives courantes:
- Un fichier texte sur la machine cible.
- Stockage centralisé de valeurs-clés (
etcd / etcd ). - Composants de processus qui peuvent être reconfigurés / redémarrés sans redémarrer le processus.
- Stockage de la configuration en dehors de l'artefact et du contrôle de version.
Les fichiers texte offrent une grande flexibilité en termes de petits changements. L'administrateur système peut accéder au nœud distant, apporter des modifications aux fichiers correspondants et redémarrer le service. Pour les grands systèmes, cependant, une telle flexibilité peut être indésirable. Des modifications apportées, il n'y a aucune trace dans d'autres systèmes. Personne n'examine les modifications. Il est difficile de déterminer qui a effectué les changements et pour quelle raison. Les modifications ne sont pas testées. Si le système est distribué, l'administrateur peut oublier d'effectuer la modification correspondante sur d'autres nœuds.
(Il convient également de noter que l'utilisation d'une configuration compilée ne bloque pas la possibilité d'utiliser des fichiers texte à l'avenir. Il suffira d'ajouter un analyseur et un validateur qui donnent le même type de Config en sortie, et vous pouvez utiliser des fichiers texte. Il s'ensuit immédiatement que la complexité du système avec la configuration compilée est quelque peu moins que la complexité d'un système utilisant des fichiers texte, car les fichiers texte nécessitent du code supplémentaire.)
Le stockage centralisé des valeurs-clés est un bon mécanisme de distribution des méta-paramètres d'une application distribuée. Nous devons décider quels sont les paramètres de configuration et quelles sont simplement les données. Supposons que nous ayons une fonction C => A => B , les paramètres C changeant rarement et les données A souvent. Dans ce cas, nous pouvons dire que C est les paramètres de configuration et A les données. Il semble que les paramètres de configuration diffèrent des données en ce qu'ils changent généralement moins fréquemment que les données. De plus, les données proviennent généralement d'une source (de l'utilisateur) et les paramètres de configuration d'une autre (de l'administrateur système).
Si des paramètres rarement modifiés doivent être mis à jour sans redémarrer le programme, cela peut souvent entraîner une complication du programme, car nous devrons en quelque sorte livrer les paramètres, stocker, analyser et vérifier, traiter les valeurs incorrectes. Par conséquent, du point de vue de la réduction de la complexité du programme, il est logique de réduire le nombre de paramètres qui peuvent changer pendant le programme (ou de ne pas prendre en charge ces paramètres du tout).
Du point de vue de cet article, nous distinguerons les paramètres statiques et dynamiques. Si la logique du service nécessite de changer les paramètres pendant le programme, alors nous appellerons ces paramètres dynamiques. Sinon, les paramètres sont statiques et peuvent être configurés à l'aide d'une configuration compilée. Pour la reconfiguration dynamique, nous pouvons avoir besoin d'un mécanisme pour redémarrer des parties du programme avec de nouveaux paramètres, semblable à la façon dont les processus du système d'exploitation sont redémarrés. (À notre avis, il est conseillé d'éviter la reconfiguration en temps réel, car la complexité du système augmente. Si possible, il est préférable d'utiliser les capacités standard du système d'exploitation pour redémarrer les processus.)
Un aspect important de l'utilisation d'une configuration statique qui oblige les utilisateurs à envisager une reconfiguration dynamique est le temps nécessaire au redémarrage du système après une mise à jour de la configuration (temps d'arrêt). En fait, si nous devons apporter des modifications à la configuration statique, nous devrons redémarrer le système pour que les nouvelles valeurs prennent effet. Le problème de temps d'arrêt a une gravité différente pour différents systèmes. Dans certains cas, vous pouvez planifier un redémarrage à un moment où la charge est minimale. Si vous souhaitez fournir un service continu, vous pouvez implémenter les "connexions de drainage" (drainage de connexion AWS ELB) . Dans le même temps, lorsque nous devons redémarrer le système, nous lançons une instance parallèle de ce système, basculons vers l'équilibreur et attendons que les anciennes connexions soient terminées. Une fois toutes les anciennes connexions terminées, nous désactivons l'ancienne instance du système.
Examinons maintenant la question du stockage de la configuration à l'intérieur ou à l'extérieur de l'artefact. Si nous stockons la configuration à l'intérieur de l'artefact, au moins nous avons eu l'occasion lors de l'assemblage de l'artefact de s'assurer que la configuration était correcte. Si la configuration est en dehors de l'artefact contrôlé, il est difficile de suivre qui et pourquoi ont apporté des modifications à ce fichier. Est-ce important? À notre avis, pour de nombreux systèmes de production, il est important d'avoir une configuration stable et de haute qualité.
La version de l'artefact vous permet de déterminer quand il a été créé, quelles valeurs il contient, quelles fonctions sont activées / désactivées, qui est responsable de tout changement dans la configuration. Bien sûr, le stockage de la configuration à l'intérieur de l'artefact nécessite un certain effort, vous devez donc prendre une décision éclairée.
Le pour et le contre
Je voudrais m'attarder sur les avantages et les inconvénients de la technologie proposée.
Les avantages
Voici une liste des principales caractéristiques d'une configuration de système distribué compilé:
- Vérification de la configuration statique. Vous permet d'être sûr que
La configuration est correcte. - . . Scala , . ,
trait' , , val', (DRY) . ( Seq , Map , ). - DSL. Scala , DSL. , , , . , , .
- . , , , , . , . , .
- . , , .
- . , .
- . , . . ( , , , , -.) — . , , , , .
- . , . , , . . . , production'.
- . , . , , — . production- .
- Test. mock-, , .
- . . , , , .
. :
- . production', . . . .
- . , , .
- . , , . / .
- . DevOps . .
- . (CI/CD). .
, :
- , , . , Cake Pattern' , ,
HList (case class') . - , : (
package , import , ; override def ' , ). , DSL. , (, XML), . - .
Conclusion
Scala. xml- . , Scala, ( Kotlin, C#, Swift, ...). , , , , , .
, . .
:
- .
- DSL .
- . , , (1) ; (2) .
, .