Avec les progrès récents dans les réseaux neuronaux en général et la reconnaissance d'image en particulier, il pourrait sembler que la création d'une application basée sur NN pour la reconnaissance d'image est une opération de routine simple. Eh bien, dans une certaine mesure, c'est vrai: si vous pouvez imaginer une application de reconnaissance d'image, alors très probablement, quelqu'un a déjà fait quelque chose de similaire. Tout ce que vous devez faire est de le rechercher sur Google et de le répéter.
Cependant, il y a encore d'innombrables petits détails qui ... ils ne sont pas insolubles, non. Ils prennent simplement trop de temps, surtout si vous êtes débutant. Ce qui serait utile, c'est un projet étape par étape, fait juste devant vous, du début à la fin. Un projet qui ne contient pas «cette partie est évidente alors sautons-la». Enfin, presque :)
Dans ce tutoriel, nous allons parcourir un identifiant de race de chien: nous allons créer et enseigner un réseau de neurones, puis nous le porterons sur Java pour Android et le publierons sur Google Play.
Pour ceux d'entre vous qui veulent voir un résultat final, voici le lien vers l'
application NeuroDog sur Google Play.
Site Web avec ma robotique:
robotics.snowcron.com .
Site Web avec:
Guide de l'utilisateur NeuroDog .
Voici une capture d'écran du programme:
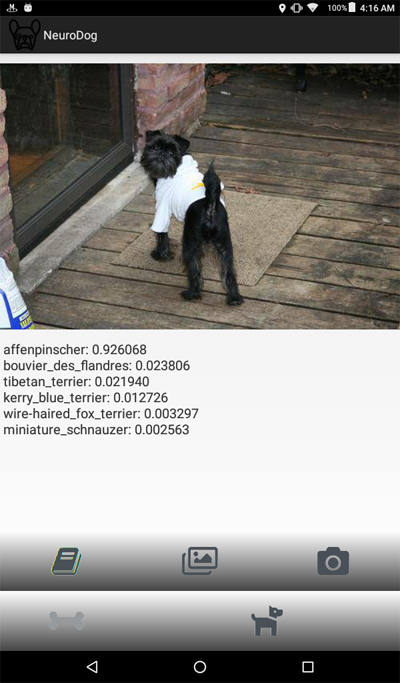
Un aperçu
Nous allons utiliser Keras: la bibliothèque de Google pour travailler avec Neural Networks. Il est de haut niveau, ce qui signifie que la courbe d'apprentissage sera abrupte, nettement plus rapide qu'avec d'autres bibliothèques que je connais. Familiarisez-vous avec elle: il existe de nombreux tutoriels de haute qualité en ligne.
Nous utiliserons CNN - Convolutional Neural Networks. Les CNN (et les réseaux plus avancés basés sur eux) sont de facto la norme en matière de reconnaissance d'images. Cependant, enseigner correctement peut devenir une tâche formidable: la structure du réseau, les paramètres d'apprentissage (tous ces taux d'apprentissage, les moments, L1 et L2 et ainsi de suite) doivent être soigneusement ajustés, et comme la tâche nécessite beaucoup de ressources informatiques, nous ne peut pas simplement essayer toutes les combinaisons possibles.
C'est l'une des rares raisons pour lesquelles, dans la plupart des cas, nous préférons utiliser l'approche "transfert de connaissances" à l'approche dite "vanille". Transfer Knowlege utilise un réseau de neurones formé par quelqu'un d'autre (pensez à Google) pour une autre tâche. Ensuite, nous en supprimons les dernières couches, ajoutons nos propres couches ... et cela fait des miracles.
Cela peut sembler étrange: nous avons suivi une formation du réseau de Google pour reconnaître les chats, les fleurs et les meubles, et maintenant il identifie la race de chiens! Pour comprendre comment cela fonctionne, examinons le fonctionnement des réseaux de neurones profonds, y compris ceux utilisés pour la reconnaissance d'images.
Nous lui fournissons une image en entrée. La première couche d'un réseau analyse l'image à la recherche de motifs simples, comme une "ligne horizontale courte", "une arche", etc. La couche suivante prend ces motifs (et où ils se trouvent sur l'image) et produit des motifs de niveau supérieur, comme "fourrure", "coin d'un œil", etc. À la fin, nous avons un puzzle qui peut être combiné dans une description d'un chien: fourrure, deux yeux, jambe humaine dans la bouche et ainsi de suite.
Maintenant, tout cela a été fait par un ensemble de couches pré-entraînées que nous avons obtenues (de Google ou d'un autre grand joueur). Enfin, nous ajoutons nos propres couches par-dessus et nous lui apprenons à travailler avec ces modèles pour reconnaître les races de chiens. Cela semble logique.
Pour résumer, dans ce tutoriel, nous allons créer CNN «vanille» et quelques réseaux de «transfert d'apprentissage» de différents types. Quant à "vanilla": je ne vais l'utiliser que comme un exemple de la façon dont cela peut être fait, mais je ne vais pas l'affiner, car les réseaux "pré-formés" sont beaucoup plus faciles à utiliser. Keras est livré avec quelques réseaux pré-formés, je vais choisir quelques configurations et les comparer.
Comme nous voulons que notre réseau neuronal soit capable de reconnaître les races de chiens, nous devons le "montrer" des images d'échantillons de différentes races. Heureusement, un
grand ensemble de données a été créé pour une tâche similaire (
original ici ). Dans cet article, je vais utiliser la
version de KaggleEnsuite, je vais porter le "gagnant" sur Android. Le portage de Keras NN sur Android est relativement facile, et nous allons parcourir toutes les étapes requises.
Ensuite, nous le publierons sur Google Play. Comme on pouvait s'y attendre, Google ne va pas coopérer, donc quelques astuces supplémentaires seront nécessaires. Par exemple, notre réseau neuronal dépasse la taille autorisée d'APK Android: nous devrons utiliser le bundle. De plus, Google ne montrera pas notre application dans les résultats de recherche, sauf si nous faisons certaines choses magiques.
À la fin, nous aurons une application "commerciale" entièrement fonctionnelle (entre guillemets, car elle est gratuite mais prête à être mise sur le marché) sous Android NN.
Environnement de développement
Il existe peu d'approches différentes de la programmation Keras, selon le système d'exploitation que vous utilisez (Ubuntu est recommandé), la carte vidéo que vous avez (ou non) et ainsi de suite. Il n'y a rien de mal à configurer l'environnement de développement sur votre ordinateur local et à installer toutes les bibliothèques nécessaires, etc. Sauf que ... il existe un moyen plus simple.
Tout d'abord, l'installation et la configuration de plusieurs outils de développement prennent du temps et vous devrez y passer de nouveau lorsque de nouvelles versions seront disponibles. Deuxièmement, la formation des réseaux neuronaux nécessite beaucoup de puissance de calcul. Vous pouvez accélérer votre ordinateur en utilisant le GPU ... au moment d'écrire ces lignes, un GPU de pointe pour les calculs liés à NN coûte entre 2000 et 7000 dollars. Et la configuration prend aussi du temps.
Nous allons donc utiliser une approche différente. Voir, Google permet aux gens d'utiliser ses GPU gratuitement pour les calculs liés à NN, il a également créé un environnement entièrement configuré; tout cela s'appelle Google Colab. Le service vous donne accès à un ordinateur portable Jupiter avec Python, Keras et des tonnes de bibliothèques supplémentaires déjà installées. Tout ce que vous devez faire est d'obtenir un compte Google (obtenez un compte Gmail, et vous aurez accès à tout le reste) et c'est tout.
Au moment d'écrire ces lignes, Colab est accessible
par ce lien , mais il peut changer. Accédez simplement à Google "Google Colab".
Un problème évident avec Colab est qu'il s'agit d'un service WEB. Comment allez-vous y accéder VOS fichiers? Enregistrer les réseaux de neurones une fois la formation terminée, charger des données spécifiques à votre tâche, etc.?
Il existe peu (au moment de la rédaction de ce document - trois) d'approches différentes; nous allons utiliser ce que je pense être le meilleur: utiliser Google Drive.
Google Drive est un stockage cloud qui fonctionne à peu près comme un disque dur, et il peut être mappé à Google Colab (voir le code ci-dessous). Ensuite, vous travaillez avec lui comme vous le feriez avec un disque dur local. Ainsi, par exemple, si vous souhaitez accéder à des photos de chiens à partir du réseau neuronal que vous avez créé dans Colab, vous devez télécharger ces photos sur votre Google Drive, c'est tout.
Création et formation du NN
Ci-dessous, je vais parcourir le code Python, un bloc de code de Jupiter Notebook après l'autre. Vous pouvez copier ce code sur votre ordinateur portable et l'exécuter, car les blocs peuvent être exécutés indépendamment les uns des autres.
Initialisation
Tout d'abord, montons le Google Drive. Juste deux lignes de code. Ce code doit être exécuté une seule fois par session Colab (disons, une fois par six heures de travail). Si vous l'exécutez la deuxième fois, il sera ignoré car le lecteur est déjà monté.
from google.colab import drive drive.mount('/content/drive/')
La première fois, il vous sera demandé de confirmer le montage - rien de compliqué ici. Cela ressemble à ceci:
>>> Go to this URL in a browser: ... >>> Enter your authorization code: >>> ·········· >>> Mounted at /content/drive/
Une section d'
inclusion assez standard; très probablement, certaines des inclusions ne sont pas requises. De plus, comme je vais tester différentes configurations NN, vous devrez commenter / décommenter certaines d'entre elles pour un type particulier de NN: par exemple, pour utiliser le type NN InceptionV3, décommenter InceptionV3 et commenter, disons, ResNet50. Ou pas: vous pouvez garder ces inclus sans commentaires, cela utilisera plus de mémoire, mais c'est tout.
import datetime as dt import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from tqdm import tqdm import cv2 import numpy as np import os import sys import random import warnings from sklearn.model_selection import train_test_split import keras from keras import backend as K from keras import regularizers from keras.models import Sequential from keras.models import Model from keras.layers import Dense, Dropout, Activation from keras.layers import Flatten, Conv2D from keras.layers import MaxPooling2D from keras.layers import BatchNormalization, Input from keras.layers import Dropout, GlobalAveragePooling2D from keras.callbacks import Callback, EarlyStopping from keras.callbacks import ReduceLROnPlateau from keras.callbacks import ModelCheckpoint import shutil from keras.applications.vgg16 import preprocess_input from keras.preprocessing import image from keras.preprocessing.image import ImageDataGenerator from keras.models import load_model from keras.applications.resnet50 import ResNet50 from keras.applications.resnet50 import preprocess_input from keras.applications.resnet50 import decode_predictions from keras.applications import inception_v3 from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input as inception_v3_preprocessor from keras.applications.mobilenetv2 import MobileNetV2 from keras.applications.nasnet import NASNetMobile
Sur Google Drive, nous allons créer un dossier pour nos fichiers. La deuxième ligne affiche son contenu:
working_path = "/content/drive/My Drive/DeepDogBreed/data/" !ls "/content/drive/My Drive/DeepDogBreed/data" >>> all_images labels.csv models test train valid
Comme vous pouvez le voir, les photos de chiens (ceux copiés du jeu de données de Stanford (voir ci-dessus) vers Google Drive, sont initialement stockées dans le dossier
all_images . Plus tard, nous allons les copier pour
former, valider et
tester des dossiers. Nous allons enregistrer modèles formés dans le dossier
modèles . Quant au fichier labels.csv, il fait partie d'un ensemble de données, il mappe les fichiers image aux races de chiens.
Il existe de nombreux tests que vous pouvez exécuter pour déterminer ce que vous avez, exécutons-en un seul:
Ok, le GPU est connecté. Sinon, recherchez-le dans les paramètres de Jupiter Notebook et activez-le.
Maintenant, nous devons déclarer certaines constantes que nous allons utiliser, comme la taille d'une image à laquelle le réseau neuronal devrait s'attendre, etc. Notez que nous utilisons une image 256x256, car elle est assez grande d'un côté et tient en mémoire de l'autre. Cependant, certains types de réseaux de neurones que nous nous apprêtons à utiliser attendent une image de 224x224. Pour gérer cela, si nécessaire, commentez l'ancienne taille d'image et décommentez une nouvelle.
La même approche (commentaire l'un - décommenter l'autre) s'applique aux noms des modèles que nous enregistrons, simplement parce que nous ne voulons pas écraser le résultat d'un test précédent lorsque nous essayons une nouvelle configuration.
warnings.filterwarnings("ignore") os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' np.random.seed(7) start = dt.datetime.now() BATCH_SIZE = 16 EPOCHS = 15 TESTING_SPLIT=0.3
Chargement des données
Tout d'abord,
chargeons le fichier
labels.csv et
divisons son contenu en parties de formation et de validation. Notez qu'il n'y a pas encore de partie test, car je vais tricher un peu, afin d'obtenir plus de données pour la formation.
labels = pd.read_csv(working_path + 'labels.csv') print(labels.head()) train_ids, valid_ids = train_test_split(labels, test_size = TESTING_SPLIT) print(len(train_ids), 'train ids', len(valid_ids), 'validation ids') print('Total', len(labels), 'testing images') >>> id breed >>> 0 000bec180eb18c7604dcecc8fe0dba07 boston_bull >>> 1 001513dfcb2ffafc82cccf4d8bbaba97 dingo >>> 2 001cdf01b096e06d78e9e5112d419397 pekinese >>> 3 00214f311d5d2247d5dfe4fe24b2303d bluetick >>> 4 0021f9ceb3235effd7fcde7f7538ed62 golden_retriever >>> 7155 train ids 3067 validation ids >>> Total 10222 testing images
Ensuite, nous devons copier les fichiers image réels dans des dossiers de formation / validation / test, en fonction du tableau de noms de fichiers que nous transmettons. La fonction suivante copie les fichiers avec les noms fournis dans un dossier spécifié.
def copyFileSet(strDirFrom, strDirTo, arrFileNames): arrBreeds = np.asarray(arrFileNames['breed']) arrFileNames = np.asarray(arrFileNames['id']) if not os.path.exists(strDirTo): os.makedirs(strDirTo) for i in tqdm(range(len(arrFileNames))): strFileNameFrom = strDirFrom + arrFileNames[i] + ".jpg" strFileNameTo = strDirTo + arrBreeds[i] + "/" + arrFileNames[i] + ".jpg" if not os.path.exists(strDirTo + arrBreeds[i] + "/"): os.makedirs(strDirTo + arrBreeds[i] + "/")
Comme vous pouvez le voir, nous ne copions qu'un fichier pour chaque race de chiens dans un dossier de
test . Lorsque nous copions des fichiers, nous créons également des sous-dossiers - un sous-dossier pour chaque race de chiens. Les images de chaque race particulière sont copiées dans son sous-dossier.
La raison en est que Keras peut travailler avec une structure de répertoires organisée de cette façon, en chargeant les fichiers image au besoin, en économisant de la mémoire. Ce serait une très mauvaise idée de charger les 15 000 images en même temps.
Appeler cette fonction chaque fois que nous exécutons notre code serait une exagération: les images sont déjà copiées, pourquoi devrions-nous les recopier. Donc, commentez-le après la première utilisation:
De plus, nous avons besoin d'une liste de races de chiens:
breeds = np.unique(labels['breed']) map_characters = {}
Traitement d'images
Nous allons utiliser une fonctionnalité de Keras appelée ImageDataGenerators. ImageDataGenerator peut traiter une image, la redimensionner, la faire tourner, etc. Il peut également prendre une fonction de
traitement qui effectue des manipulations d'images personnalisées.
def preprocess(img): img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE), interpolation = cv2.INTER_AREA)
Notez la ligne suivante:
Nous pouvons effectuer la normalisation (ajustement de la plage 0-255 du canal image à 0-1) dans ImageDataGenerator lui-même. Alors pourquoi aurions-nous besoin d'un préprocesseur? À titre d'exemple, j'ai fourni la fonction de
flou (commenté): c'est une manipulation d'image personnalisée. Vous pouvez utiliser n'importe quoi, de la netteté au HDR ici.
Nous allons utiliser deux ImageDataGenerators différents, un pour la formation et un pour la validation. La différence est que nous avons besoin de rotations et de zooms pour la formation, pour rendre les images plus "diverses", mais nous n'en avons pas besoin pour la validation (pas dans cette tâche).
train_datagen = ImageDataGenerator( preprocessing_function=preprocess,
Création d'un réseau de neurones
Comme mentionné ci-dessus, nous allons créer quelques types de réseaux de neurones. Chaque fois que nous utilisons une fonction différente, différentes bibliothèques d'inclusion et, dans certains cas, différentes tailles d'image. Donc, pour passer d'un type de réseau neuronal à l'autre, vous devez commenter / décommenter le code correspondant.
Tout d'abord, créons CNN "vanille". Il fonctionne mal, car je ne l'ai pas optimisé, mais au moins il fournit un cadre que vous pourriez utiliser pour créer votre propre réseau (généralement, c'est une mauvaise idée, car il existe des réseaux pré-formés disponibles).
def createModelVanilla(): model = Sequential()
Lorsque nous créons un réseau neuronal à l'aide de l'
apprentissage par
transfert , la procédure change:
def createModelMobileNetV2():
La création d'autres types de NN pré-formés est très similaire:
def createModelResNet50(): base_model = ResNet50(weights='imagenet', include_top=False, pooling='avg', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)) x = base_model.output x = Dense(512)(x) x = Activation('relu')(x) x = Dropout(0.5)(x) predictions = Dense(NUM_CLASSES, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions)
Attn: le gagnant! Ce NN a démontré les meilleurs résultats:
def createModelInceptionV3():
Un de plus:
def createModelNASNetMobile():
Différents types de NN sont utilisés dans différentes situations. En plus des problèmes de précision, de la taille (le NN mobile est 5 fois plus petit que le premier) et de la vitesse (si nous avons besoin d'une analyse en temps réel d'un flux vidéo, nous devrons peut-être sacrifier la précision).
Former le réseau neuronal
Tout d'abord, nous
expérimentons , nous devons donc pouvoir supprimer les NN que nous avons enregistrés auparavant, mais dont nous n'avons plus besoin. La fonction suivante supprime NN si le fichier existe:
La façon dont nous créons et supprimons les NN est simple. Tout d'abord, nous supprimons. Maintenant, si vous ne voulez pas appeler
supprimer , n'oubliez pas que Jupiter Notebook a une fonction "exécuter la sélection" - sélectionnez uniquement ce dont vous avez besoin et exécutez-le.
Ensuite, nous créons le NN si son fichier n'existe pas ou le
chargeons si le fichier existe: bien sûr, nous ne pouvons pas appeler "supprimer" et nous nous attendons à ce que le NN existe, donc pour utiliser un réseau précédemment enregistré, n'appelez pas
supprimer .
En d'autres termes, nous pouvons créer un nouveau NN ou utiliser un existant, selon ce que nous expérimentons en ce moment. Un scénario simple: nous avons formé le NN, puis nous sommes partis en vacances. Google nous a déconnectés, nous devons donc recharger le NN: commentez la partie "supprimer" et décommentez la partie "charger".
deleteSavedNet(working_path + strModelFileName)
Les points de contrôle sont très importants lors de l'enseignement aux NN. Vous pouvez créer un tableau de fonctions à appeler à la fin de chaque période de formation, par exemple, vous pouvez enregistrer le NN
si s'il affiche de meilleurs résultats que le dernier enregistré.
checkpoint = ModelCheckpoint(working_path + strModelFileName, monitor='val_acc', verbose=1, save_best_only=True, mode='auto', save_weights_only=False) callbacks_list = [ checkpoint ]
Enfin, nous enseignerons notre NN en utilisant l'ensemble de formation:
Voici les tableaux de précision et de perte pour le gagnant NN:
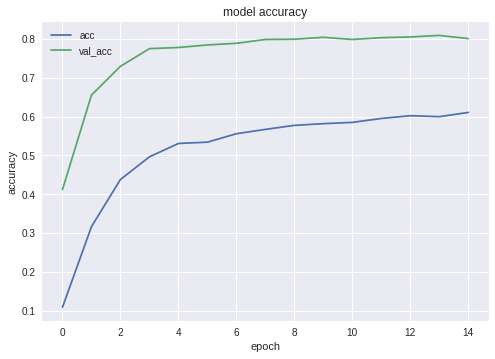

Comme vous pouvez le voir, le Réseau apprend bien.
Test du réseau neuronal
Une fois la phase de formation terminée, nous devons effectuer des tests; pour le faire, NN se voit présenter des images qu'il n'a jamais vues. s vous vous souvenez, nous avons mis de côté une image pour chaque espèce de chien.
Exportation de NN vers Java
Tout d'abord, nous devons charger le NN. La raison en est que l'exportation est un bloc de code séparé, nous sommes donc susceptibles de l'exécuter séparément, sans réentraîner le NN. Comme vous utilisez mon code, vous ne vous en souciez pas vraiment, mais si vous faisiez votre propre développement, vous essayez d'éviter de recycler
le même réseau une fois après l'autre.
Pour la même raison - il s'agit en quelque sorte d'un bloc de code distinct - nous utilisons des inclusions supplémentaires ici. Rien ne nous empêche bien sûr de les remonter:
from keras.models import Model from keras.models import load_model from keras.layers import * import os import sys import tensorflow as tf
Un petit test, juste pour nous assurer que nous avons tout chargé correctement:
img = image.load_img(working_path + "test/affenpinscher.jpg")

Ensuite, nous devons obtenir les noms des couches d'entrée et de sortie de notre réseau (sauf si nous avons utilisé le paramètre "name" lors de la création du réseau, ce que nous n'avons pas fait).
model.summary() >>> Layer (type) >>> ====================== >>> input_7 (InputLayer) >>> ______________________ >>> conv2d_283 (Conv2D) >>> ______________________ >>> ... >>> dense_14 (Dense) >>> ====================== >>> Total params: 22,913,432 >>> Trainable params: 1,110,648 >>> Non-trainable params: 21,802,784
Nous allons utiliser les noms des couches d'entrée et de sortie plus tard, lors de l'importation du NN dans l'application Java Android.
Nous pouvons également utiliser le code suivant pour obtenir ces informations:
def print_graph_nodes(filename): g = tf.GraphDef() g.ParseFromString(open(filename, 'rb').read()) print() print(filename) print("=======================INPUT===================") print([n for n in g.node if n.name.find('input') != -1]) print("=======================OUTPUT==================") print([n for n in g.node if n.name.find('output') != -1]) print("===================KERAS_LEARNING==============") print([n for n in g.node if n.name.find('keras_learning_phase') != -1]) print("===============================================") print()
Cependant, la première approche est préférée.
La fonction suivante exporte Keras Neural Network au format
pb , celui que nous allons utiliser dans Android.
def keras_to_tensorflow(keras_model, output_dir, model_name,out_prefix="output_", log_tensorboard=True): if os.path.exists(output_dir) == False: os.mkdir(output_dir) out_nodes = [] for i in range(len(keras_model.outputs)): out_nodes.append(out_prefix + str(i + 1)) tf.identity(keras_model.output[i], out_prefix + str(i + 1)) sess = K.get_session() from tensorflow.python.framework import graph_util from tensorflow.python.framework graph_io init_graph = sess.graph.as_graph_def() main_graph = graph_util.convert_variables_to_constants( sess, init_graph, out_nodes) graph_io.write_graph(main_graph, output_dir, name=model_name, as_text=False) if log_tensorboard: from tensorflow.python.tools import import_pb_to_tensorboard import_pb_to_tensorboard.import_to_tensorboard( os.path.join(output_dir, model_name), output_dir)
Utilisons ces fonctions pour créer un NN d'exportation:
model = load_model(working_path + strModelFileName) keras_to_tensorflow(model, output_dir=working_path + strModelFileName, model_name=working_path + "models/dogs.pb") print_graph_nodes(working_path + "models/dogs.pb")
La dernière ligne imprime la structure de notre NN.
Création d'une application Android compatible NN
Exportation de NN vers l'application Android. est bien formalisé et ne devrait pas poser de problème. Il y a, comme d'habitude, plus d'une façon de le faire; nous allons utiliser le plus populaire (au moins, pour le moment).
Tout d'abord, utilisez Android Studio pour créer un nouveau projet. Nous allons couper un peu les coins, donc il ne contiendra qu'une seule activité.

Comme vous pouvez le voir, nous avons ajouté le dossier "assets" et y avons copié notre fichier Neural Network.
Fichier Gradle
Il y a quelques changements que nous devons faire pour classer le fichier. Tout d'abord, nous devons importer la bibliothèque
tensorflow-android . Il est utilisé pour gérer Tensorflow (et Keras, en conséquence) à partir de Java:
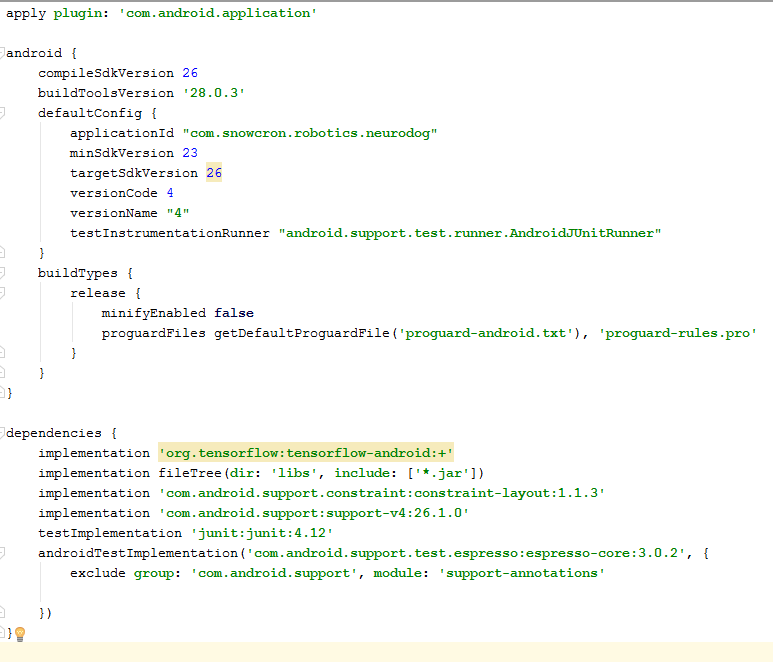
Comme détail supplémentaire "difficile à trouver", notez les versions:
versionCode et
versionName . Pendant que vous travaillez sur votre application, vous devrez télécharger de nouvelles versions sur Google Play. Sans mettre à jour les versions (quelque chose comme 1 -> 2 -> 3 ...), vous ne pourrez pas le faire.
Manifeste
Tout d'abord, notre application. va être «lourd» - un réseau neuronal de 100 Mo tient facilement dans la mémoire des téléphones modernes, mais en ouvrir une instance distincte chaque fois que l'utilisateur «partage» une image de Facebook n'est certainement pas une bonne idée.
Nous allons donc nous assurer qu'il n'y a qu'une seule instance de notre application:
<activity android:name=".MainActivity" android:launchMode="singleTask">
En ajoutant
android: launchMode = "singleTask" à MainActivity, nous demandons à Android d'ouvrir une application existante, plutôt que de lancer une autre instance.
Ensuite, nous nous assurons que notre application. apparaît dans une liste d'applications capables de gérer
des images
partagées :
<intent-filter> <action android:name="android.intent.action.SEND" /> <category android:name="android.intent.category.DEFAULT" /> <data android:mimeType="image/*" /> </intent-filter>
Enfin, nous devons demander des fonctionnalités et des autorisations, afin que l'application puisse accéder aux fonctionnalités système dont elle a besoin:
<uses-feature android:name="android.hardware.camera" android:required="true" /> <uses-permission android:name= "android.permission.WRITE_EXTERNAL_STORAGE" /> <uses-permission android:name="android.permission.READ_PHONE_STATE" tools:node="remove" />
Si vous connaissez la programmation Android, cette partie ne devrait poser aucune question.
Disposition de l'application.
Nous allons créer deux dispositions, une pour le mode Portrait et une pour le mode Paysage. Voici la
mise en page Portrait .
Ce que nous avons ici: une grande vue pour montrer une image, une liste plutôt ennuyeuse de publicités (affichée lorsque le bouton "os" est enfoncé), les boutons "Aide", les boutons pour charger une image à partir de Fichier / Galerie et de la Caméra, et enfin, un bouton (initialement masqué) "Processus".
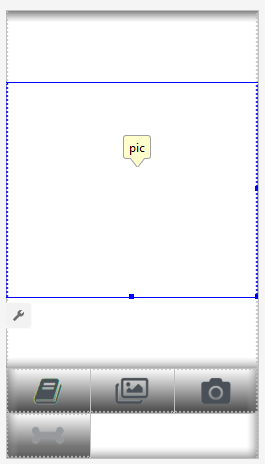
Dans l'activité elle-même, nous allons implémenter une logique affichant / masquant et activant / désactivant les boutons en fonction de l'état de l'application.
Activité principale
L'activité étend une activité Android standard:
public class MainActivity extends Activity
Jetons un coup d'œil au code responsable des opérations NN.
Tout d'abord, NN accepte un bitmap. À l'origine, il s'agit d'un grand bitmap à partir d'un fichier ou d'une caméra (m_bitmap), puis nous le transformons en un bitmap standard 256x256 (m_bitmapForNn). Nous gardons également les dimensions de l'image (256) dans une constante:
static Bitmap m_bitmap = null; static Bitmap m_bitmapForNn = null; private int m_nImageSize = 256;
Nous devons dire au NN quels sont les noms des couches d'entrée et de sortie; si vous consultez la liste ci-dessus, vous constaterez que les noms sont (dans notre cas! votre cas peut être différent!):
private String INPUT_NAME = "input_7_1"; private String OUTPUT_NAME = "output_1";
Ensuite, nous déclarons la variable pour contenir l'objet TensofFlow. En outre, nous stockons le chemin d'accès au fichier NN dans les actifs:
privé TensorFlowInferenceInterface tf;
chaîne privée MODEL_PATH =
"fichier: ///android_asset/dogs.pb";
Races de chiens, pour présenter à l'utilisateur une information significative, au lieu d'index dans le tableau:
private String[] m_arrBreedsArray;
Initialement, nous chargeons un Bitmap. Cependant, NN lui-même attend un tableau de valeurs RVB, et sa sortie est un tableau de probabilités de l'image présentée étant une race particulière. Nous devons donc ajouter deux tableaux supplémentaires (notez que 120 est le nombre de races dans notre ensemble de données d'entraînement):
private float[] m_arrPrediction = new float[120]; private float[] m_arrInput = null;
Charger la bibliothèque d'inférence tensorflow
static { System.loadLibrary("tensorflow_inference"); }
Comme le fonctionnement de NN est long, nous devons l'exécuter dans un thread séparé, sinon il y a de bonnes chances de toucher l'application "system". ne répond pas », sans parler de ruiner l'expérience utilisateur.
class PredictionTask extends AsyncTask<Void, Void, Void> { @Override protected void onPreExecute() { super.onPreExecute(); }
Dans onCreate () de MainActivity, nous devons ajouter le onClickListener pour le bouton "Process": m_btn_process.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { processImage(); } });
Ce que le processusImage () appelle simplement le thread que nous avons vu ci-dessus: private void processImage() { try { enableControls(false);
Détails supplémentaires
Nous n'allons pas discuter du code lié à l'interface utilisateur dans ce tutoriel, car il est trivial et ne fait certainement pas partie de la tâche de "portage NN". Cependant, il y a peu de choses qui devraient être clarifiées.Quand nous avons prévalu notre application. de lancer plusieurs instances, nous avons empêché, dans le même temps, un flux normal de contrôle: si vous partagez une image de Facebook, puis en partagez une autre, l'application ne sera pas redémarrée. Cela signifie que la manière "traditionnelle" de gérer les données partagées en les interceptant dans onCreate n'est pas suffisante dans notre cas, car onCreate n'est pas appelé dans un scénario que nous venons de créer.Voici une façon de gérer la situation:1. Dans onCreate of MainActivity, appelez la fonction onSharedIntent: protected void onCreate( Bundle savedInstanceState) { super.onCreate(savedInstanceState); .... onSharedIntent(); ....
Ajoutez également un gestionnaire pour onNewIntent: @Override protected void onNewIntent(Intent intent) { super.onNewIntent(intent); setIntent(intent); onSharedIntent(); }
La fonction onSharedIntent elle-même: private void onSharedIntent() { Intent receivedIntent = getIntent(); String receivedAction = receivedIntent.getAction(); String receivedType = receivedIntent.getType(); if (receivedAction.equals(Intent.ACTION_SEND)) {
Maintenant, nous traitons soit l'image partagée à partir de onCreate (si l'application vient de démarrer) ou de onNewIntent si une instance a été trouvée en mémoire.Bonne chance! Si vous aimez cet article, veuillez «l'aimer» dans les réseaux sociaux, il y a aussi des boutons sociaux sur un site lui-même.