Bonjour à tous, nous partageons avec vous la deuxième partie de la publication "Systèmes de fichiers virtuels sous Linux: pourquoi sont-ils nécessaires et comment fonctionnent-ils?" La première partie peut être lue
ici . Rappelons que cette série de publications est dédiée au lancement d'un nouveau thread au cours
Administrateur Linux , qui débutera très prochainement.
Comment regarder VFS avec les outils eBPF et CciLe moyen le plus simple de comprendre comment le noyau fonctionne sur les fichiers
sysfs est de le regarder dans la pratique, et le moyen le plus simple d'observer ARM64 est d'utiliser eBPF. eBPF (abréviation de Berkeley Packet Filter) consiste en une machine virtuelle exécutée dans le
noyau que les utilisateurs privilégiés peuvent
query partir de la ligne de commande. Les sources du noyau indiquent au lecteur ce que le noyau peut faire; l'exécution des outils eBPF sur un système occupé montre ce que fait réellement le noyau.

Heureusement, commencer à utiliser eBPF est assez facile avec les outils
bcc , qui sont disponibles sous forme de packages à partir de la
distribution Linux générale et sont documentés en détail par
Bernard Gregg .
bcc outils
bcc sont des scripts Python avec de petites insertions de code C, ce qui signifie que toute personne familière avec les deux langues peut facilement les modifier. Il y a 80 scripts Python dans
bcc/tools , ce qui signifie que le développeur ou l'administrateur système sera probablement en mesure de choisir quelque chose qui convient pour résoudre le problème.
Pour avoir une idée même superficielle de ce que fait VFS sur un système en cours d'exécution, essayez
vfscount ou
vfsstat . Cela montrera, par exemple, que des dizaines d'appels à
vfs_open() et «ses amis» se produisent littéralement chaque seconde.
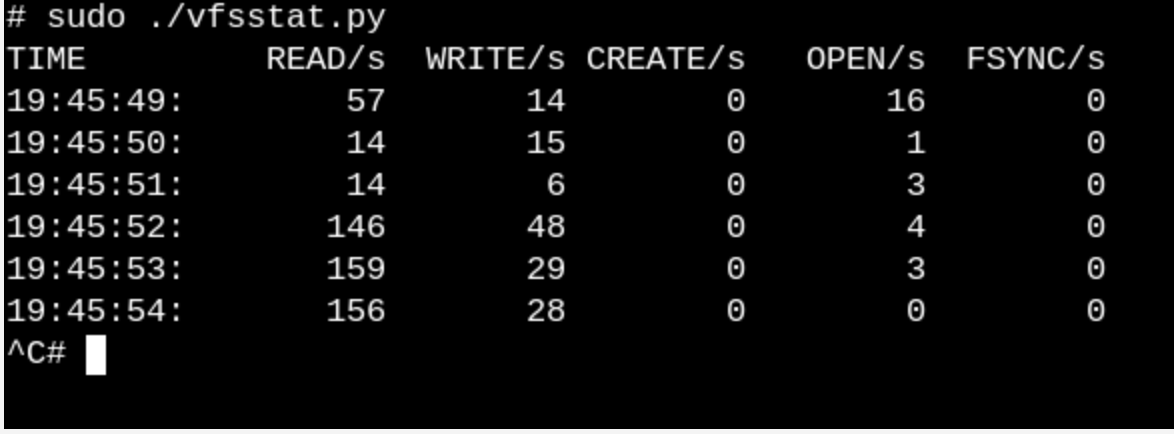
vfsstat.py est un script Python avec des insertions de code C qui compte simplement les appels de fonction VFS.
Nous donnons un exemple plus trivial et voyons ce qui se passe lorsque nous insérons une clé USB dans un ordinateur et que le système le détecte.
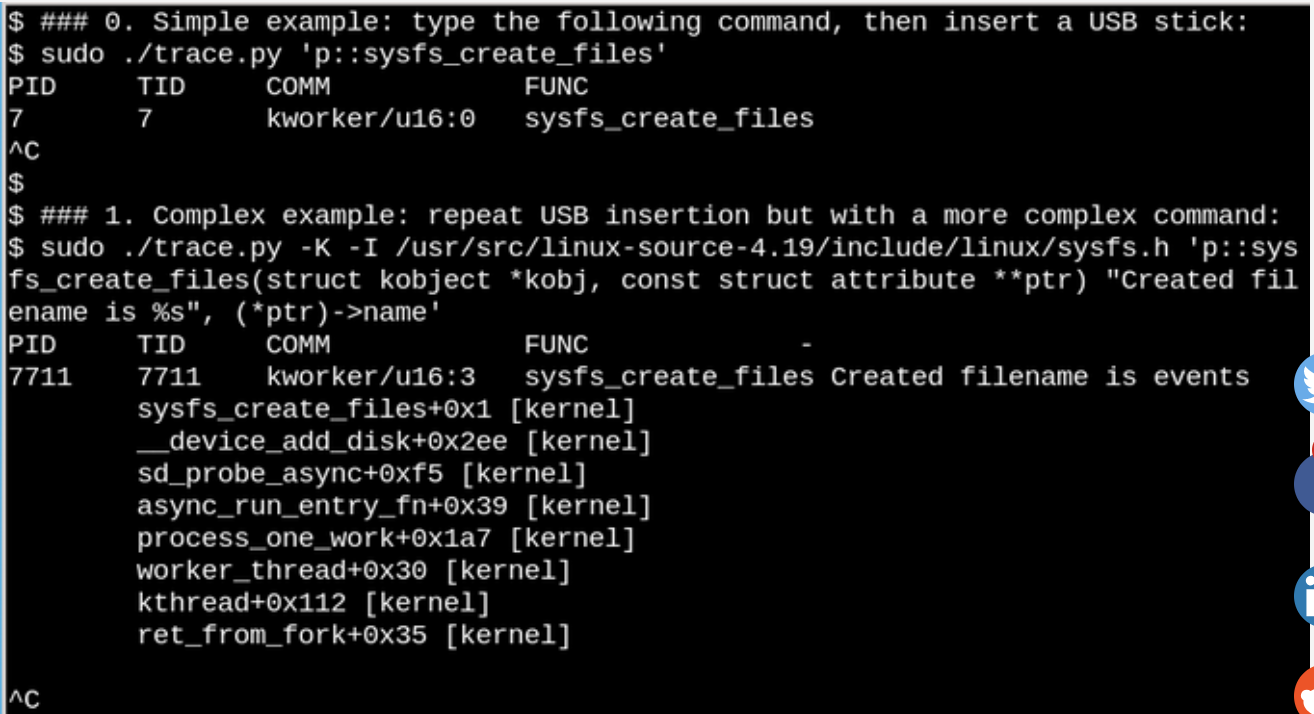
En utilisant eBPF, vous pouvez voir ce qui se passe dans /sys lorsqu'un lecteur flash USB est inséré. Un exemple simple et complexe est présenté ici.
Dans l'exemple ci-dessus, l'outil
bcc trace.py affiche un message lorsque la commande
sysfs_create_files() est
sysfs_create_files() . Nous voyons que
sysfs_create_files() été lancé en utilisant le flux
kworker en réponse à l'insertion du lecteur flash, mais quel fichier a été créé? Le deuxième exemple montre la pleine puissance de eBPF. Ici
trace.py affiche la trace du noyau (option -K) et le nom du fichier qui a été créé par
sysfs_create_files() . L'insertion d'une instruction unique est du code C qui inclut une chaîne de format facilement reconnaissable fournie par un script Python qui exécute le compilateur
juste à temps LLVM. Il compile et exécute cette ligne dans une machine virtuelle à l'intérieur du noyau. La signature complète de la fonction
sysfs_create_files () doit être reproduite dans la deuxième commande afin que la chaîne de format puisse faire référence à l'un des paramètres. Les erreurs dans ce fragment de code C entraînent des erreurs de compilateur C reconnaissables. Par exemple, si vous omettez l'option -l, vous verrez «Échec de la compilation du texte BPF». Les développeurs familiarisés avec C et Python trouveront les outils
bcc faciles à développer et à modifier.
Lorsqu'une clé USB est insérée, un
kworker noyau montrera que le PID 7711 est le flux
kworker qui a créé le fichier
«events» dans
sysfs . Par conséquent, un appel avec
sysfs_remove_files() montrera que la suppression du lecteur a supprimé le fichier d'
events , ce qui est conforme au concept général du comptage de références. Dans le même temps, l'affichage de
sysfs_create_link () avec eBPF lors de l'insertion d'un lecteur USB montrera qu'au moins 48 liens symboliques ont été créés.
Quelle est donc la signification du fichier d'événements? L'utilisation de
cscope pour rechercher
__device_add_disk () montre qu'il appelle
disk_add_events () et que
"media_change" ou
"eject_request" peut être écrit dans le fichier d'événements. Ici, la couche de bloc noyau informe l'espace utilisateur de l'apparition et de l'extraction du «disque». Veuillez noter à quel point cette méthode de recherche est informative par l'exemple de l'insertion d'une clé USB par rapport à essayer de comprendre comment tout fonctionne, exclusivement à partir de la source.
Les systèmes de fichiers racine en lecture seule activent les périphériques intégrésBien sûr, personne ne met le serveur ou son ordinateur hors tension, débranchant la fiche de la prise. Mais pourquoi? Et tout cela parce que les systèmes de fichiers montés sur les périphériques de stockage physiques peuvent avoir des enregistrements en attente, et les structures de données enregistrant leur état peuvent ne pas être synchronisées avec les enregistrements du stockage. Lorsque cela se produit, les propriétaires du système doivent attendre le prochain démarrage pour exécuter l'utilitaire de
fsck filesystem-recovery et, dans le pire des cas, perdre des données.
Cependant, nous savons tous que de nombreux appareils IoT, ainsi que des routeurs, des thermostats et des voitures fonctionnent désormais sous Linux. Beaucoup de ces appareils n'ont pratiquement pas d'interface utilisateur, et il n'y a aucun moyen de les désactiver "proprement". Imaginez démarrer une voiture avec une batterie déchargée, lorsque la puissance du dispositif de contrôle sur
Linux monte et descend constamment. Comment se fait-il que le système démarre sans un
fsck long lorsque le moteur commence enfin à fonctionner? Et la réponse est simple. Les périphériques intégrés reposent sur un système de fichiers racine en lecture seule (abrégé en
ro-rootfs (système de fichiers racine en lecture seule)).
ro-rootfs offre de nombreux avantages moins évidents qu'authentiques. Un avantage est que les logiciels malveillants ne peuvent pas écrire dans
/usr ou
/lib si aucun processus Linux ne peut y écrire. Un autre est qu'un système de fichiers largement immuable est essentiel pour la prise en charge sur le terrain des périphériques distants, car le personnel de support utilise des systèmes locaux qui sont nominalement identiques aux systèmes locaux. L'avantage peut-être le plus important (mais aussi le plus insidieux) est que ro-rootfs oblige les développeurs à décider quels objets système seront inchangés, même au stade de la conception du système. Travailler avec ro-rootfs peut être inconfortable et pénible, comme c'est souvent le cas avec les variables const dans les langages de programmation, mais leurs avantages peuvent facilement couvrir la surcharge supplémentaire.
La création de
rootfs seule nécessite un effort supplémentaire pour les développeurs intégrés, et c'est là que VFS entre en scène. Linux nécessite que les fichiers dans
/var soient accessibles en écriture, et en outre, de nombreuses applications populaires qui exécutent des systèmes intégrés essaieront de créer des
dot-files configuration dans
$HOME . L'une des solutions pour les fichiers de configuration dans le répertoire personnel est généralement leur génération préliminaire et leur assemblage dans
rootfs . Pour
/var une des approches possibles consiste à le monter dans une section distincte accessible en écriture, tandis que le
/ mount lui-même est en lecture seule. Une autre alternative populaire consiste à utiliser des montures de liaison ou de superposition.
Supports montables et chevauchants, leur utilisation par des conteneursL'exécution de la commande
man mount est la meilleure façon d'en savoir plus sur la liaison et les montages qui se chevauchent, ce qui donne aux développeurs et aux administrateurs système la possibilité de créer un système de fichiers d'une manière, puis de le fournir aux applications d'une autre. Pour les systèmes embarqués, cela signifie la possibilité de stocker des fichiers dans
/var sur un lecteur flash en lecture seule, mais la superposition ou la liaison du chemin de
tmpfs vers
/var au démarrage permettra aux applications d'y écrire des notes (scrawl). La prochaine fois que vous l'activez, les modifications apportées à
/var seront perdues. Un montage en superposition crée une union entre
tmpfs et le système de fichiers sous-jacent et vous permet d'apporter soi-disant des modifications aux fichiers existants dans
ro-tootf tandis qu'un montage lié peut rendre de nouveaux dossiers
tmpfs vides visibles en écriture dans
ro-rootfs chemins
ro-rootfs . Bien que
overlayfs soit le type de système de fichiers
proper , les montages de liaison sont implémentés dans l'
espace de noms VFS .
Sur la base de la description des montages superposés et liés, personne n'est surpris que les
conteneurs Linux les utilisent activement. Observons ce qui se passe lorsque nous utilisons
systemd-nspawn pour démarrer le conteneur à l'aide de l'outil
bcc mountsnoop .

Un appel à
system-nspawn démarre le conteneur pendant que
mountsnoop.py .
Voyons ce qui s'est passé:
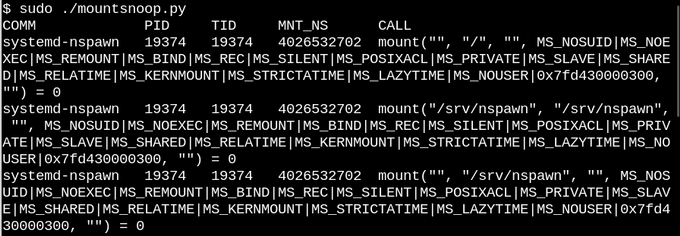
L'exécution de
mountsnoop pendant le «démarrage» du conteneur indique que le temps d'exécution du conteneur dépend fortement du montage connecté (seul le début de la sortie longue est affiché).
Ici,
systemd-nspawn fournit les fichiers sélectionnés dans les
procfs et
sysfs hôte au conteneur comme chemins vers ses
rootfs . Outre l'indicateur
MS_BIND , qui définit le montage de liaison, certains autres indicateurs du système monté déterminent la relation entre les modifications dans l'espace de noms d'hôte et le conteneur. Par exemple, un montage de liaison peut ignorer les modifications dans
/proc et
/sys dans un conteneur, ou les masquer en fonction de l'appel.
ConclusionComprendre la structure interne de Linux peut sembler une tâche impossible, car le noyau lui-même contient une énorme quantité de code, laissant de côté les applications d'espace utilisateur Linux et les interfaces d'appel système dans les bibliothèques C comme la
glibc . Une façon de progresser consiste à lire le code source d'un sous-système du noyau en mettant l'accent sur la compréhension des appels système et des en-têtes face à l'espace utilisateur, ainsi que les principales interfaces internes du noyau, par exemple, la table
file_operations . Les opérations de fichiers fournissent le principe de «tout est un fichier», donc leur gestion est particulièrement agréable. Les fichiers source C dans le répertoire de niveau supérieur
fs/ représentent l'implémentation de systèmes de fichiers virtuels, qui sont une couche shell qui offre une compatibilité large et relativement simple des systèmes de fichiers et des périphériques de stockage populaires. Le montage avec liaison et superposition via des espaces de noms Linux est une magie VFS qui permet de créer des conteneurs en lecture seule et des systèmes de fichiers racine. Combiné avec l'apprentissage du code source, l'outil de base eBPF et son interface
bccrendre la recherche sur le noyau plus facile que jamais.
Amis, écrire cet article vous a été utile? Peut-être avez-vous des commentaires ou des commentaires? Et pour ceux qui sont intéressés par le cours Administrateur Linux, nous vous invitons à la
journée portes ouvertes , qui aura lieu le 18 avril.
La première partie.